This is the BuildBot manual.
Copyright (C) 2005,2006 Brian Warner
Copying and distribution of this file, with or without modification, are permitted in any medium without royalty provided the copyright notice and this notice are preserved.
--- The Detailed Node Listing ---
Introduction
System Architecture
Installation
Creating a buildslave
Troubleshooting
Concepts
Version Control Systems
Users
Configuration
Listing Change Sources and Schedulers
Getting Source Code Changes
Change Sources
Build Process
Build Steps
Source Checkout
Simple ShellCommand Subclasses
Writing New BuildSteps
Build Factories
BuildStep Objects
BuildFactory
Process-Specific build factories
Status Delivery
Command-line tool
Developer Tools
Other Tools
The BuildBot is a system to automate the compile/test cycle required by most software projects to validate code changes. By automatically rebuilding and testing the tree each time something has changed, build problems are pinpointed quickly, before other developers are inconvenienced by the failure. The guilty developer can be identified and harassed without human intervention. By running the builds on a variety of platforms, developers who do not have the facilities to test their changes everywhere before checkin will at least know shortly afterwards whether they have broken the build or not. Warning counts, lint checks, image size, compile time, and other build parameters can be tracked over time, are more visible, and are therefore easier to improve.
The overall goal is to reduce tree breakage and provide a platform to run tests or code-quality checks that are too annoying or pedantic for any human to waste their time with. Developers get immediate (and potentially public) feedback about their changes, encouraging them to be more careful about testing before checkin.
Features:
The Buildbot was inspired by a similar project built for a development
team writing a cross-platform embedded system. The various components
of the project were supposed to compile and run on several flavors of
unix (linux, solaris, BSD), but individual developers had their own
preferences and tended to stick to a single platform. From time to
time, incompatibilities would sneak in (some unix platforms want to
use string.h, some prefer strings.h), and then the tree
would compile for some developers but not others. The buildbot was
written to automate the human process of walking into the office,
updating a tree, compiling (and discovering the breakage), finding the
developer at fault, and complaining to them about the problem they had
introduced. With multiple platforms it was difficult for developers to
do the right thing (compile their potential change on all platforms);
the buildbot offered a way to help.
Another problem was when programmers would change the behavior of a library without warning its users, or change internal aspects that other code was (unfortunately) depending upon. Adding unit tests to the codebase helps here: if an application's unit tests pass despite changes in the libraries it uses, you can have more confidence that the library changes haven't broken anything. Many developers complained that the unit tests were inconvenient or took too long to run: having the buildbot run them reduces the developer's workload to a minimum.
In general, having more visibility into the project is always good, and automation makes it easier for developers to do the right thing. When everyone can see the status of the project, developers are encouraged to keep the tree in good working order. Unit tests that aren't run on a regular basis tend to suffer from bitrot just like code does: exercising them on a regular basis helps to keep them functioning and useful.
The current version of the Buildbot is additionally targeted at distributed free-software projects, where resources and platforms are only available when provided by interested volunteers. The buildslaves are designed to require an absolute minimum of configuration, reducing the effort a potential volunteer needs to expend to be able to contribute a new test environment to the project. The goal is for anyone who wishes that a given project would run on their favorite platform should be able to offer that project a buildslave, running on that platform, where they can verify that their portability code works, and keeps working.
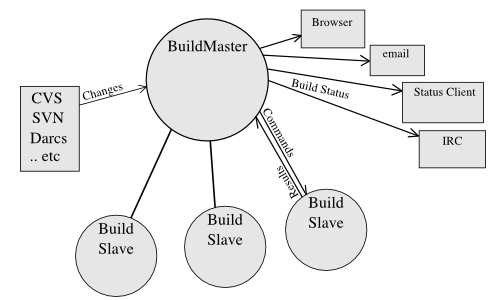
The Buildbot consists of a single buildmaster and one or more
buildslaves, connected in a star topology. The buildmaster
makes all decisions about what, when, and how to build. It sends
commands to be run on the build slaves, which simply execute the
commands and return the results. (certain steps involve more local
decision making, where the overhead of sending a lot of commands back
and forth would be inappropriate, but in general the buildmaster is
responsible for everything).
The buildmaster is usually fed Changes by some sort of version
control system (see Change Sources), which may cause builds to be
run. As the builds are performed, various status messages are
produced, which are then sent to any registered Status Targets
(see Status Delivery).
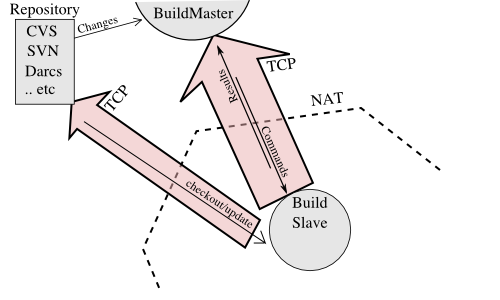
The buildmaster is configured and maintained by the “buildmaster admin”, who is generally the project team member responsible for build process issues. Each buildslave is maintained by a “buildslave admin”, who do not need to be quite as involved. Generally slaves are run by anyone who has an interest in seeing the project work well on their favorite platform.
The buildslaves are typically run on a variety of separate machines, at least one per platform of interest. These machines connect to the buildmaster over a TCP connection to a publically-visible port. As a result, the buildslaves can live behind a NAT box or similar firewalls, as long as they can get to buildmaster. The TCP connections are initiated by the buildslave and accepted by the buildmaster, but commands and results travel both ways within this connection. The buildmaster is always in charge, so all commands travel exclusively from the buildmaster to the buildslave.
To perform builds, the buildslaves must typically obtain source code from a CVS/SVN/etc repository. Therefore they must also be able to reach the repository. The buildmaster provides instructions for performing builds, but does not provide the source code itself.
The Buildmaster consists of several pieces:
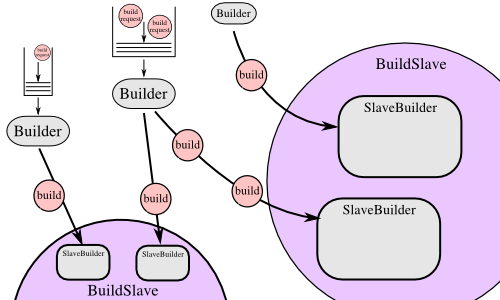
Each Builder is configured with a list of BuildSlaves that it will use for its builds. These buildslaves are expected to behave identically: the only reason to use multiple BuildSlaves for a single Builder is to provide a measure of load-balancing.
Within a single BuildSlave, each Builder creates its own SlaveBuilder instance. These SlaveBuilders operate independently from each other. Each gets its own base directory to work in. It is quite common to have many Builders sharing the same buildslave. For example, there might be two buildslaves: one for i386, and a second for PowerPC. There may then be a pair of Builders that do a full compile/test run, one for each architecture, and a lone Builder that creates snapshot source tarballs if the full builders complete successfully. The full builders would each run on a single buildslave, whereas the tarball creation step might run on either buildslave (since the platform doesn't matter when creating source tarballs). In this case, the mapping would look like:
Builder(full-i386) -> BuildSlaves(slave-i386)
Builder(full-ppc) -> BuildSlaves(slave-ppc)
Builder(source-tarball) -> BuildSlaves(slave-i386, slave-ppc)
and each BuildSlave would have two SlaveBuilders inside it, one for a full builder, and a second for the source-tarball builder.
Once a SlaveBuilder is available, the Builder pulls one or more BuildRequests off its incoming queue. (It may pull more than one if it determines that it can merge the requests together; for example, there may be multiple requests to build the current HEAD revision). These requests are merged into a single Build instance, which includes the SourceStamp that describes what exact version of the source code should be used for the build. The Build is then assigned to a SlaveBuilder and the build begins.
The buildmaster maintains a central Status object, to which various status plugins are connected. Through this Status object, a full hierarchy of build status objects can be obtained.
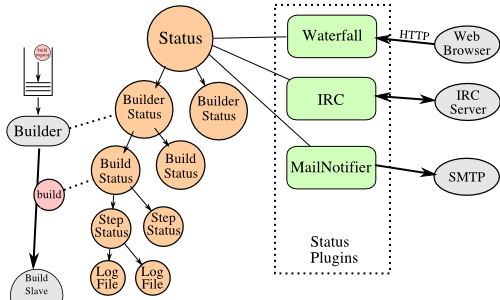
The configuration file controls which status plugins are active. Each status plugin gets a reference to the top-level Status object. From there they can request information on each Builder, Build, Step, and LogFile. This query-on-demand interface is used by the html.Waterfall plugin to create the main status page each time a web browser hits the main URL.
The status plugins can also subscribe to hear about new Builds as they occur: this is used by the MailNotifier to create new email messages for each recently-completed Build.
The Status object records the status of old builds on disk in the buildmaster's base directory. This allows it to return information about historical builds.
There are also status objects that correspond to Schedulers and BuildSlaves. These allow status plugins to report information about upcoming builds, and the online/offline status of each buildslave.
A day in the life of the buildbot:
At a bare minimum, you'll need the following (for both the buildmaster and a buildslave):
Buildbot requires python-2.2 or later, and is primarily developed against python-2.3. The buildmaster uses generators, a feature which is not available in python-2.1, and both master and slave require a version of Twisted which only works with python-2.2 or later. Certain features (like the inclusion of build logs in status emails) require python-2.2.2 or later. The IRC “force build” command requires python-2.3 (for the shlex.split function).
Both the buildmaster and the buildslaves require Twisted-1.3.0 or later. It has been mainly developed against Twisted-2.0.1, but has been tested against Twisted-2.1.0 (the most recent as of this writing), and might even work on versions as old as Twisted-1.1.0, but as always the most recent version is recommended.
Twisted-1.3.0 and earlier were released as a single monolithic package. When you run Buildbot against Twisted-2.0.0 or later (which are split into a number of smaller subpackages), you'll need at least "Twisted" (the core package), and you'll also want TwistedMail, TwistedWeb, and TwistedWords (for sending email, serving a web status page, and delivering build status via IRC, respectively).
Certain other packages may be useful on the system running the buildmaster:
If your buildmaster uses FreshCVSSource to receive change notification from a cvstoys daemon, it will require CVSToys be installed (tested with CVSToys-1.0.10). If the it doesn't use that source (i.e. if you only use a mail-parsing change source, or the SVN notification script), you will not need CVSToys.
And of course, your project's build process will impose additional requirements on the buildslaves. These hosts must have all the tools necessary to compile and test your project's source code.
The Buildbot is installed using the standard python distutils
module. After unpacking the tarball, the process is:
python setup.py build
python setup.py install
where the install step may need to be done as root. This will put the
bulk of the code in somewhere like
/usr/lib/python2.3/site-packages/buildbot . It will also install the
buildbot command-line tool in /usr/bin/buildbot.
To test this, shift to a different directory (like /tmp), and run:
buildbot --version
If it shows you the versions of Buildbot and Twisted, the install went
ok. If it says no such command or it gets an ImportError
when it tries to load the libaries, then something went wrong.
pydoc buildbot is another useful diagnostic tool.
Windows users will find these files in other places. You will need to
make sure that python can find the libraries, and will probably find
it convenient to have buildbot on your PATH.
If you wish, you can run the buildbot unit test suite like this:
PYTHONPATH=. trial buildbot.test
This should run up to 192 tests, depending upon what VC tools you have installed. On my desktop machine it takes about five minutes to complete. Nothing should fail, a few might be skipped. If any of the tests fail, you should stop and investigate the cause before continuing the installation process, as it will probably be easier to track down the bug early.
If you cannot or do not wish to install the buildbot into a site-wide location like /usr or /usr/local, you can also install it into the account's home directory. Do the install command like this:
python setup.py install --home=~
That will populate ~/lib/python and create
~/bin/buildbot. Make sure this lib directory is on your
PYTHONPATH.
As you learned earlier (see System Architecture), the buildmaster
runs on a central host (usually one that is publically visible, so
everybody can check on the status of the project), and controls all
aspects of the buildbot system. Let us call this host
buildbot.example.org.
You may wish to create a separate user account for the buildmaster,
perhaps named buildmaster. This can help keep your personal
configuration distinct from that of the buildmaster and is useful if
you have to use a mail-based notification system (see Change Sources). However, the Buildbot will work just fine with your regular
user account.
You need to choose a directory for the buildmaster, called the
basedir. This directory will be owned by the buildmaster, which
will use configuration files therein, and create status files as it
runs. ~/Buildbot is a likely value. If you run multiple
buildmasters in the same account, or if you run both masters and
slaves, you may want a more distinctive name like
~/Buildbot/master/gnomovision or
~/Buildmasters/fooproject. If you are using a separate user
account, this might just be ~buildmaster/masters/fooproject.
Once you've picked a directory, use the buildbot create-master command to create the directory and populate it with startup files:
buildbot create-master basedir
You will need to create a configuration file (see Configuration) before starting the buildmaster. Most of the rest of this manual is dedicated to explaining how to do this. A sample configuration file is placed in the working directory, named master.cfg.sample, which can be copied to master.cfg and edited to suit your purposes.
(Internal details: This command creates a file named
buildbot.tac that contains all the state necessary to create
the buildmaster. Twisted has a tool called twistd which can use
this .tac file to create and launch a buildmaster instance. twistd
takes care of logging and daemonization (running the program in the
background). /usr/bin/buildbot is a front end which runs twistd
for you.)
In addition to buildbot.tac, a small Makefile.sample is installed. This can be used as the basis for customized daemon startup, See Launching the daemons.
Typically, you will be adding a buildslave to an existing buildmaster, to provide additional architecture coverage. The buildbot administrator will give you several pieces of information necessary to connect to the buildmaster. You should also be somewhat familiar with the project being tested, so you can troubleshoot build problems locally.
The buildbot exists to make sure that the project's stated “how to build it” process actually works. To this end, the buildslave should run in an environment just like that of your regular developers. Typically the project build process is documented somewhere (README, INSTALL, etc), in a document that should mention all library dependencies and contain a basic set of build instructions. This document will be useful as you configure the host and account in which the buildslave runs.
Here's a good checklist for setting up a buildslave:
It is recommended (although not mandatory) to set up a separate user
account for the buildslave. This account is frequently named
buildbot or buildslave. This serves to isolate your
personal working environment from that of the slave's, and helps to
minimize the security threat posed by letting possibly-unknown
contributors run arbitrary code on your system. The account should
have a minimum of fancy init scripts.
Follow the instructions given earlier (see Installing the code).
If you use a separate buildslave account, and you didn't install the
buildbot code to a shared location, then you will need to install it
with --home=~ for each account that needs it.
Make sure the host can actually reach the buildmaster. Usually the buildmaster is running a status webserver on the same machine, so simply point your web browser at it and see if you can get there. Install whatever additional packages or libraries the project's INSTALL document advises. (or not: if your buildslave is supposed to make sure that building without optional libraries still works, then don't install those libraries).
Again, these libraries don't necessarily have to be installed to a site-wide shared location, but they must be available to your build process. Accomplishing this is usually very specific to the build process, so installing them to /usr or /usr/local is usually the best approach.
Follow the instructions in the INSTALL document, in the buildslave's account. Perform a full CVS (or whatever) checkout, configure, make, run tests, etc. Confirm that the build works without manual fussing. If it doesn't work when you do it by hand, it will be unlikely to work when the buildbot attempts to do it in an automated fashion.
This should be somewhere in the buildslave's account, typically named after the project which is being tested. The buildslave will not touch any file outside of this directory. Something like ~/Buildbot or ~/Buildslaves/fooproject is appropriate.
When the buildbot admin configures the buildmaster to accept and use your buildslave, they will provide you with the following pieces of information:
Now run the 'buildbot' command as follows:
buildbot create-slave BASEDIR MASTERHOST:PORT SLAVENAME PASSWORD
This will create the base directory and a collection of files inside,
including the buildbot.tac file that contains all the
information you passed to the buildbot command.
When it first connects, the buildslave will send a few files up to the buildmaster which describe the host that it is running on. These files are presented on the web status display so that developers have more information to reproduce any test failures that are witnessed by the buildbot. There are sample files in the info subdirectory of the buildbot's base directory. You should edit these to correctly describe you and your host.
BASEDIR/info/admin should contain your name and email address. This is the “buildslave admin address”, and will be visible from the build status page (so you may wish to munge it a bit if address-harvesting spambots are a concern).
BASEDIR/info/host should be filled with a brief description of the host: OS, version, memory size, CPU speed, versions of relevant libraries installed, and finally the version of the buildbot code which is running the buildslave.
If you run many buildslaves, you may want to create a single ~buildslave/info file and share it among all the buildslaves with symlinks.
There are a handful of options you might want to use when creating the buildslave with the buildbot create-slave <options> DIR <params> command. You can type buildbot create-slave --help for a summary. To use these, just include them on the buildbot create-slave command line, like this:
buildbot create-slave --umask=022 ~/buildslave buildmaster.example.org:42012 myslavename mypasswd
--usepty--usepty=0 to disable the use of PTYs. Note that
windows buildslaves never use PTYs.
--umask--umask=022 to tell
the buildslave to fix the umask after twistd clobbers it. If you want
build products to be writable by other accounts too, use
--umask=000, but this is likely to be a security problem.
--keepalive--keepalive=120.
If the buildslave is behind a NAT box or stateful firewall, these messages may help to keep the connection alive: some NAT boxes tend to forget about a connection if it has not been used in a while. When this happens, the buildmaster will think that the buildslave has disappeared, and builds will time out. Meanwhile the buildslave will not realize than anything is wrong.
Both the buildmaster and the buildslave run as daemon programs. To
launch them, pass the working directory to the buildbot
command:
buildbot start BASEDIR
This command will start the daemon and then return, so normally it will not produce any output. To verify that the programs are indeed running, look for a pair of files named twistd.log and twistd.pid that should be created in the working directory. twistd.pid contains the process ID of the newly-spawned daemon.
When the buildslave connects to the buildmaster, new directories will start appearing in its base directory. The buildmaster tells the slave to create a directory for each Builder which will be using that slave. All build operations are performed within these directories: CVS checkouts, compiles, and tests.
Once you get everything running, you will want to arrange for the
buildbot daemons to be started at boot time. One way is to use
cron, by putting them in a @reboot crontab entry1:
@reboot buildbot start BASEDIR
When you run crontab to set this up, remember to do it as the buildmaster or buildslave account! If you add this to your crontab when running as your regular account (or worse yet, root), then the daemon will run as the wrong user, quite possibly as one with more authority than you intended to provide.
It is important to remember that the environment provided to cron jobs
and init scripts can be quite different that your normal runtime.
There may be fewer environment variables specified, and the PATH may
be shorter than usual. It is a good idea to test out this method of
launching the buildslave by using a cron job with a time in the near
future, with the same command, and then check twistd.log to
make sure the slave actually started correctly. Common problems here
are for /usr/local or ~/bin to not be on your
PATH, or for PYTHONPATH to not be set correctly.
Sometimes HOME is messed up too.
To modify the way the daemons are started (perhaps you want to set some environment variables first, or perform some cleanup each time), you can create a file named Makefile.buildbot in the base directory. When the buildbot front-end tool is told to start the daemon, and it sees this file (and /usr/bin/make exists), it will do make -f Makefile.buildbot start instead of its usual action (which involves running twistd). When the buildmaster or buildslave is installed, a Makefile.sample is created which implements the same behavior as the the buildbot tool uses, so if you want to customize the process, just copy Makefile.sample to Makefile.buildbot and edit it as necessary.
While a buildbot daemon runs, it emits text to a logfile, named
twistd.log. A command like tail -f twistd.log is useful
to watch the command output as it runs.
The buildmaster will announce any errors with its configuration file in the logfile, so it is a good idea to look at the log at startup time to check for any problems. Most buildmaster activities will cause lines to be added to the log.
To stop a buildmaster or buildslave manually, use:
buildbot stop BASEDIR
This simply looks for the twistd.pid file and kills whatever process is identified within.
At system shutdown, all processes are sent a SIGKILL. The
buildmaster and buildslave will respond to this by shutting down
normally.
The buildmaster will respond to a SIGHUP by re-reading its
config file. The following shortcut is available:
buildbot sighup BASEDIR
When you update the Buildbot code to a new release, you will need to
restart the buildmaster and/or buildslave before it can take advantage
of the new code. You can do a buildbot stop BASEDIR and
buildbot start BASEDIR in quick succession, or you can
use the restart shortcut, which does both steps for you:
buildbot restart BASEDIR
It is a good idea to check the buildmaster's status page every once in a while, to see if your buildslave is still online. Eventually the buildbot will probably be enhanced to send you email (via the info/admin email address) when the slave has been offline for more than a few hours.
If you find you can no longer provide a buildslave to the project, please let the project admins know, so they can put out a call for a replacement.
The Buildbot records status and logs output continually, each time a
build is performed. The status tends to be small, but the build logs
can become quite large. Each build and log are recorded in a separate
file, arranged hierarchically under the buildmaster's base directory.
To prevent these files from growing without bound, you should
periodically delete old build logs. A simple cron job to delete
anything older than, say, two weeks should do the job. The only trick
is to leave the buildbot.tac and other support files alone, for
which find's -mindepth argument helps skip everything in the
top directory. You can use something like the following:
@weekly cd BASEDIR && find . -mindepth 2 -type f -mtime +14 -exec rm {} \;
@weekly cd BASEDIR && find twistd.log* -mtime +14 -exec rm {} \;
Here are a few hints on diagnosing common problems.
Cron jobs are typically run with a minimal shell (/bin/sh, not
/bin/bash), and tilde expansion is not always performed in such
commands. You may want to use explicit paths, because the PATH
is usually quite short and doesn't include anything set by your
shell's startup scripts (.profile, .bashrc, etc). If
you've installed buildbot (or other python libraries) to an unusual
location, you may need to add a PYTHONPATH specification (note
that python will do tilde-expansion on PYTHONPATH elements by
itself). Sometimes it is safer to fully-specify everything:
@reboot PYTHONPATH=~/lib/python /usr/local/bin/buildbot start /usr/home/buildbot/basedir
Take the time to get the @reboot job set up. Otherwise, things will work fine for a while, but the first power outage or system reboot you have will stop the buildslave with nothing but the cries of sorrowful developers to remind you that it has gone away.
If the buildslave cannot connect to the buildmaster, the reason should be described in the twistd.log logfile. Some common problems are an incorrect master hostname or port number, or a mistyped bot name or password. If the buildslave loses the connection to the master, it is supposed to attempt to reconnect with an exponentially-increasing backoff. Each attempt (and the time of the next attempt) will be logged. If you get impatient, just manually stop and re-start the buildslave.
When the buildmaster is restarted, all slaves will be disconnected,
and will attempt to reconnect as usual. The reconnect time will depend
upon how long the buildmaster is offline (i.e. how far up the
exponential backoff curve the slaves have travelled). Again,
buildbot stop BASEDIR; buildbot start BASEDIR will
speed up the process.
From the buildmaster's main status web page, you can force a build to
be run on your build slave. Figure out which column is for a builder
that runs on your slave, click on that builder's name, and the page
that comes up will have a “Force Build” button. Fill in the form,
hit the button, and a moment later you should see your slave's
twistd.log filling with commands being run. Using pstree
or top should also reveal the cvs/make/gcc/etc processes being
run by the buildslave. Note that the same web page should also show
the admin and host information files that you configured
earlier.
This chapter defines some of the basic concepts that the Buildbot uses. You'll need to understand how the Buildbot sees the world to configure it properly.
These source trees come from a Version Control System of some kind.
CVS and Subversion are two popular ones, but the Buildbot supports
others. All VC systems have some notion of an upstream
repository which acts as a server2, from which clients
can obtain source trees according to various parameters. The VC
repository provides source trees of various projects, for different
branches, and from various points in time. The first thing we have to
do is to specify which source tree we want to get.
For the purposes of the Buildbot, we will try to generalize all VC systems as having repositories that each provide sources for a variety of projects. Each project is defined as a directory tree with source files. The individual files may each have revisions, but we ignore that and treat the project as a whole as having a set of revisions. Each time someone commits a change to the project, a new revision becomes available. These revisions can be described by a tuple with two items: the first is a branch tag, and the second is some kind of timestamp or revision stamp. Complex projects may have multiple branch tags, but there is always a default branch. The timestamp may be an actual timestamp (such as the -D option to CVS), or it may be a monotonically-increasing transaction number (such as the change number used by SVN and P4, or the revision number used by Arch, or a labeled tag used in CVS)3. The SHA1 revision ID used by Monotone and Mercurial is also a kind of revision stamp, in that it specifies a unique copy of the source tree, as does a Darcs “context” file.
When we aren't intending to make any changes to the sources we check out (at least not any that need to be committed back upstream), there are two basic ways to use a VC system:
Build personnel or CM staff typically use the first approach: the build that results is (ideally) completely specified by the two parameters given to the VC system: repository and revision tag. This gives QA and end-users something concrete to point at when reporting bugs. Release engineers are also reportedly fond of shipping code that can be traced back to a concise revision tag of some sort.
Developers are more likely to use the second approach: each morning the developer does an update to pull in the changes committed by the team over the last day. These builds are not easy to fully specify: it depends upon exactly when you did a checkout, and upon what local changes the developer has in their tree. Developers do not normally tag each build they produce, because there is usually significant overhead involved in creating these tags. Recreating the trees used by one of these builds can be a challenge. Some VC systems may provide implicit tags (like a revision number), while others may allow the use of timestamps to mean “the state of the tree at time X” as opposed to a tree-state that has been explicitly marked.
The Buildbot is designed to help developers, so it usually works in terms of the latest sources as opposed to specific tagged revisions. However, it would really prefer to build from reproducible source trees, so implicit revisions are used whenever possible.
So for the Buildbot's purposes we treat each VC system as a server which can take a list of specifications as input and produce a source tree as output. Some of these specifications are static: they are attributes of the builder and do not change over time. Others are more variable: each build will have a different value. The repository is changed over time by a sequence of Changes, each of which represents a single developer making changes to some set of files. These Changes are cumulative4.
For normal builds, the Buildbot wants to get well-defined source trees that contain specific Changes, and exclude other Changes that may have occurred after the desired ones. We assume that the Changes arrive at the buildbot (through one of the mechanisms described in see Change Sources) in the same order in which they are committed to the repository. The Buildbot waits for the tree to become “stable” before initiating a build, for two reasons. The first is that developers frequently make multiple related commits in quick succession, even when the VC system provides ways to make atomic transactions involving multiple files at the same time. Running a build in the middle of these sets of changes would use an inconsistent set of source files, and is likely to fail (and is certain to be less useful than a build which uses the full set of changes). The tree-stable-timer is intended to avoid these useless builds that include some of the developer's changes but not all. The second reason is that some VC systems (i.e. CVS) do not provide repository-wide transaction numbers, so that timestamps are the only way to refer to a specific repository state. These timestamps may be somewhat ambiguous, due to processing and notification delays. By waiting until the tree has been stable for, say, 10 minutes, we can choose a timestamp from the middle of that period to use for our source checkout, and then be reasonably sure that any clock-skew errors will not cause the build to be performed on an inconsistent set of source files.
The Schedulers always use the tree-stable-timer, with a timeout that is configured to reflect a reasonable tradeoff between build latency and change frequency. When the VC system provides coherent repository-wide revision markers (such as Subversion's revision numbers, or in fact anything other than CVS's timestamps), the resulting Build is simply performed against a source tree defined by that revision marker. When the VC system does not provide this, a timestamp from the middle of the tree-stable period is used to generate the source tree5.
For CVS, the static specifications are repository and
module. In addition to those, each build uses a timestamp (or
omits the timestamp to mean the latest) and branch tag
(which defaults to HEAD). These parameters collectively specify a set
of sources from which a build may be performed.
Subversion combines the
repository, module, and branch into a single Subversion URL
parameter. Within that scope, source checkouts can be specified by a
numeric revision number (a repository-wide
monotonically-increasing marker, such that each transaction that
changes the repository is indexed by a different revision number), or
a revision timestamp. When branches are used, the repository and
module form a static baseURL, while each build has a
revision number and a branch (which defaults to a
statically-specified defaultBranch). The baseURL and
branch are simply concatenated together to derive the
svnurl to use for the checkout.
Perforce is similar. The server
is specified through a P4PORT parameter. Module and branch
are specified in a single depot path, and revisions are
depot-wide. When branches are used, the p4base and
defaultBranch are concatenated together to produce the depot
path.
Arch and
Bazaar specify a repository by
URL, as well as a version which is kind of like a branch name.
Arch uses the word archive to represent the repository. Arch
lets you push changes from one archive to another, removing the strict
centralization required by CVS and SVN. It retains the distinction
between repository and working directory that most other VC systems
use. For complex multi-module directory structures, Arch has a
built-in build config layer with which the checkout process has
two steps. First, an initial bootstrap checkout is performed to
retrieve a set of build-config files. Second, one of these files is
used to figure out which archives/modules should be used to populate
subdirectories of the initial checkout.
Builders which use Arch and Bazaar therefore have a static archive
url, and a default “branch” (which is a string that specifies
a complete category–branch–version triple). Each build can have its
own branch (the category–branch–version string) to override the
default, as well as a revision number (which is turned into a
–patch-NN suffix when performing the checkout).
Darcs doesn't really have the
notion of a single master repository. Nor does it really have
branches. In Darcs, each working directory is also a repository, and
there are operations to push and pull patches from one of these
repositories to another. For the Buildbot's purposes, all you
need to do is specify the URL of a repository that you want to build
from. The build slave will then pull the latest patches from that
repository and build them. Multiple branches are implemented by using
multiple repositories (possibly living on the same server).
Builders which use Darcs therefore have a static repourl which
specifies the location of the repository. If branches are being used,
the source Step is instead configured with a baseURL and a
defaultBranch, and the two strings are simply concatenated
together to obtain the repository's URL. Each build then has a
specific branch which replaces defaultBranch, or just uses the
default one. Instead of a revision number, each build can have a
“context”, which is a string that records all the patches that are
present in a given tree (this is the output of darcs changes
--context, and is considerably less concise than, e.g. Subversion's
revision number, but the patch-reordering flexibility of Darcs makes
it impossible to provide a shorter useful specification).
Mercurial is like Darcs, in that
each branch is stored in a separate repository. The repourl,
baseURL, and defaultBranch arguments are all handled the
same way as with Darcs. The “revision”, however, is the hash
identifier returned by hg identify.
Each Change has a who attribute, which specifies which
developer is responsible for the change. This is a string which comes
from a namespace controlled by the VC repository. Frequently this
means it is a username on the host which runs the repository, but not
all VC systems require this (Arch, for example, uses a fully-qualified
Arch ID, which looks like an email address, as does Darcs).
Each StatusNotifier will map the who attribute into something
appropriate for their particular means of communication: an email
address, an IRC handle, etc.
It also has a list of files, which are just the tree-relative
filenames of any files that were added, deleted, or modified for this
Change. These filenames are used by the isFileImportant
function (in the Scheduler) to decide whether it is worth triggering a
new build or not, e.g. the function could use
filename.endswith(".c") to only run a build if a C file were
checked in. Certain BuildSteps can also use the list of changed files
to run a more targeted series of tests, e.g. the
step_twisted.Trial step can run just the unit tests that
provide coverage for the modified .py files instead of running the
full test suite.
The Change also has a comments attribute, which is a string
containing any checkin comments.
Each Change can have a revision attribute, which describes how
to get a tree with a specific state: a tree which includes this Change
(and all that came before it) but none that come after it. If this
information is unavailable, the .revision attribute will be
None. These revisions are provided by the ChangeSource, and
consumed by the computeSourceRevision method in the appropriate
step.Source class.
revision is an int, seconds since the epoch
revision is an int, a transation number (r%d)
revision is a large string, the output of darcs changes --context
revision is a short string (a hash ID), the output of hg identify
revision is the full revision ID (ending in –patch-%d)
revision is an int, the transaction number
The Change might also have a branch attribute. This indicates
that all of the Change's files are in the same named branch. The
Schedulers get to decide whether the branch should be built or not.
For VC systems like CVS, Arch, and Monotone, the branch name is
unrelated to the filename. (that is, the branch name and the filename
inhabit unrelated namespaces). For SVN, branches are expressed as
subdirectories of the repository, so the file's “svnurl” is a
combination of some base URL, the branch name, and the filename within
the branch. (In a sense, the branch name and the filename inhabit the
same namespace). Darcs branches are subdirectories of a base URL just
like SVN. Mercurial branches are the same as Darcs.
Finally, the Change might have a links list, which is intended
to provide a list of URLs to a viewcvs-style web page that
provides more detail for this Change, perhaps including the full file
diffs.
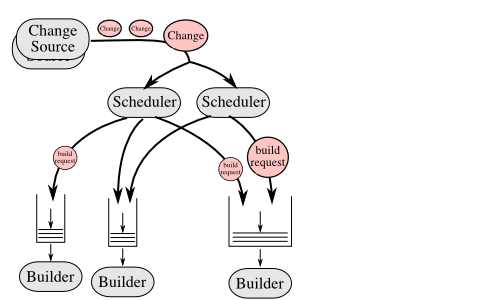
Each Buildmaster has a set of Scheduler objects, each of which
gets a copy of every incoming Change. The Schedulers are responsible
for deciding when Builds should be run. Some Buildbot installations
might have a single Scheduler, while others may have several, each for
a different purpose.
For example, a “quick” scheduler might exist to give immediate
feedback to developers, hoping to catch obvious problems in the code
that can be detected quickly. These typically do not run the full test
suite, nor do they run on a wide variety of platforms. They also
usually do a VC update rather than performing a brand-new checkout
each time. You could have a “quick” scheduler which used a 30 second
timeout, and feeds a single “quick” Builder that uses a VC
mode='update' setting.
A separate “full” scheduler would run more comprehensive tests a
little while later, to catch more subtle problems. This scheduler
would have a longer tree-stable-timer, maybe 30 minutes, and would
feed multiple Builders (with a mode= of 'copy',
'clobber', or 'export').
The tree-stable-timer and isFileImportant decisions are
made by the Scheduler. Dependencies are also implemented here.
Periodic builds (those which are run every N seconds rather than after
new Changes arrive) are triggered by a special Periodic
Scheduler subclass. The default Scheduler class can also be told to
watch for specific branches, ignoring Changes on other branches. This
may be useful if you have a trunk and a few release branches which
should be tracked, but when you don't want to have the Buildbot pay
attention to several dozen private user branches.
Some Schedulers may trigger builds for other reasons, other than recent Changes. For example, a Scheduler subclass could connect to a remote buildmaster and watch for builds of a library to succeed before triggering a local build that uses that library.
Each Scheduler creates and submits BuildSet objects to the
BuildMaster, which is then responsible for making sure the
individual BuildRequests are delivered to the target
Builders.
Scheduler instances are activated by placing them in the
c['schedulers'] list in the buildmaster config file. Each
Scheduler has a unique name.
A BuildSet is the name given to a set of Builds that all
compile/test the same version of the tree on multiple Builders. In
general, all these component Builds will perform the same sequence of
Steps, using the same source code, but on different platforms or
against a different set of libraries.
The BuildSet is tracked as a single unit, which fails if any of
the component Builds have failed, and therefore can succeed only if
all of the component Builds have succeeded. There are two kinds
of status notification messages that can be emitted for a BuildSet:
the firstFailure type (which fires as soon as we know the
BuildSet will fail), and the Finished type (which fires once
the BuildSet has completely finished, regardless of whether the
overall set passed or failed).
A BuildSet is created with a source stamp tuple of
(branch, revision, changes, patch), some of which may be None, and a
list of Builders on which it is to be run. They are then given to the
BuildMaster, which is responsible for creating a separate
BuildRequest for each Builder.
There are a couple of different likely values for the
SourceStamp:
(revision=None, changes=[CHANGES], patch=None)SourceStamp used when a series of Changes have
triggered a build. The VC step will attempt to check out a tree that
contains CHANGES (and any changes that occurred before CHANGES, but
not any that occurred after them).
(revision=None, changes=None, patch=None)SourceStamp that would be used on a Build that was
triggered by a user request, or a Periodic scheduler. It is also
possible to configure the VC Source Step to always check out the
latest sources rather than paying attention to the Changes in the
SourceStamp, which will result in same behavior as this.
(branch=BRANCH, revision=None, changes=None, patch=None)(revision=REV, changes=None, patch=(LEVEL, DIFF))diff -pLEVEL <DIFF). The try feature uses
this kind of SourceStamp. If patch is None, the patching
step is bypassed.
The buildmaster is responsible for turning the BuildSet into a
set of BuildRequest objects and queueing them on the
appropriate Builders.
A BuildRequest is a request to build a specific set of sources
on a single specific Builder. Each Builder runs the
BuildRequest as soon as it can (i.e. when an associated
buildslave becomes free).
The BuildRequest contains the SourceStamp specification.
The actual process of running the build (the series of Steps that will
be executed) is implemented by the Build object. In this future
this might be changed, to have the Build define what
gets built, and a separate BuildProcess (provided by the
Builder) to define how it gets built.
The BuildRequest may be mergeable with other compatible
BuildRequests. Builds that are triggered by incoming Changes
will generally be mergeable. Builds that are triggered by user
requests are generally not, unless they are multiple requests to build
the latest sources of the same branch.
The Builder is a long-lived object which controls all Builds of
a given type. Each one is created when the config file is first
parsed, and lives forever (or rather until it is removed from the
config file). It mediates the connections to the buildslaves that do
all the work, and is responsible for creating the Build objects
that decide how a build is performed (i.e., which steps are
executed in what order).
Each Builder gets a unique name, and the path name of a
directory where it gets to do all its work (there is a
buildmaster-side directory for keeping status information, as well as
a buildslave-side directory where the actual checkout/compile/test
commands are executed). It also gets a BuildFactory, which is
responsible for creating new Build instances: because the
Build instance is what actually performs each build, choosing
the BuildFactory is the way to specify what happens each time a
build is done.
Each Builder is associated with one of more BuildSlaves.
A Builder which is used to perform OS-X builds (as opposed to
Linux or Solaris builds) should naturally be associated with an
OS-X-based buildslave.
Buildbot has a somewhat limited awareness of users. It assumes the world consists of a set of developers, each of whom can be described by a couple of simple attributes. These developers make changes to the source code, causing builds which may succeed or fail.
Each developer is primarily known through the source control system. Each
Change object that arrives is tagged with a who field that
typically gives the account name (on the repository machine) of the user
responsible for that change. This string is the primary key by which the
User is known, and is displayed on the HTML status pages and in each Build's
“blamelist”.
To do more with the User than just refer to them, this username needs to be mapped into an address of some sort. The responsibility for this mapping is left up to the status module which needs the address. The core code knows nothing about email addresses or IRC nicknames, just user names.
Each Change has a single User who is responsible for that Change. Most Builds have a set of Changes: the Build represents the first time these Changes have been built and tested by the Buildbot. The build has a “blamelist” that consists of a simple union of the Users responsible for all the Build's Changes.
The Build provides (through the IBuildStatus interface) a list of Users who are “involved” in the build. For now this is equal to the blamelist, but in the future it will be expanded to include a “build sheriff” (a person who is “on duty” at that time and responsible for watching over all builds that occur during their shift), as well as per-module owners who simply want to keep watch over their domain (chosen by subdirectory or a regexp matched against the filenames pulled out of the Changes). The Involved Users are those who probably have an interest in the results of any given build.
In the future, Buildbot will acquire the concept of “Problems”, which last longer than builds and have beginnings and ends. For example, a test case which passed in one build and then failed in the next is a Problem. The Problem lasts until the test case starts passing again, at which point the Problem is said to be “resolved”.
If there appears to be a code change that went into the tree at the same time as the test started failing, that Change is marked as being resposible for the Problem, and the user who made the change is added to the Problem's “Guilty” list. In addition to this user, there may be others who share responsibility for the Problem (module owners, sponsoring developers). In addition to the Responsible Users, there may be a set of Interested Users, who take an interest in the fate of the Problem.
Problems therefore have sets of Users who may want to be kept aware of the condition of the problem as it changes over time. If configured, the Buildbot can pester everyone on the Responsible list with increasing harshness until the problem is resolved, with the most harshness reserved for the Guilty parties themselves. The Interested Users may merely be told when the problem starts and stops, as they are not actually responsible for fixing anything.
The buildbot.status.mail.MailNotifier class provides a
status target which can send email about the results of each build. It
accepts a static list of email addresses to which each message should be
delivered, but it can also be configured to send mail to the Build's
Interested Users. To do this, it needs a way to convert User names into
email addresses.
For many VC systems, the User Name is actually an account name on the system which hosts the repository. As such, turning the name into an email address is a simple matter of appending “@repositoryhost.com”. Some projects use other kinds of mappings (for example the preferred email address may be at “project.org” despite the repository host being named “cvs.project.org”), and some VC systems have full separation between the concept of a user and that of an account on the repository host (like Perforce). Some systems (like Arch) put a full contact email address in every change.
To convert these names to addresses, the MailNotifier uses an EmailLookup
object. This provides a .getAddress method which accepts a name and
(eventually) returns an address. The default MailNotifier
module provides an EmailLookup which simply appends a static string,
configurable when the notifier is created. To create more complex behaviors
(perhaps using an LDAP lookup, or using “finger” on a central host to
determine a preferred address for the developer), provide a different object
as the lookup argument.
In the future, when the Problem mechanism has been set up, the Buildbot will need to send mail to arbitrary Users. It will do this by locating a MailNotifier-like object among all the buildmaster's status targets, and asking it to send messages to various Users. This means the User-to-address mapping only has to be set up once, in your MailNotifier, and every email message the buildbot emits will take advantage of it.
Like MailNotifier, the buildbot.status.words.IRC class
provides a status target which can announce the results of each build. It
also provides an interactive interface by responding to online queries
posted in the channel or sent as private messages.
In the future, the buildbot can be configured map User names to IRC
nicknames, to watch for the recent presence of these nicknames, and to
deliver build status messages to the interested parties. Like
MailNotifier does for email addresses, the IRC object
will have an IRCLookup which is responsible for nicknames. The
mapping can be set up statically, or it can be updated by online users
themselves (by claiming a username with some kind of “buildbot: i am
user warner” commands).
Once the mapping is established, the rest of the buildbot can ask the
IRC object to send messages to various users. It can report on
the likelihood that the user saw the given message (based upon how long the
user has been inactive on the channel), which might prompt the Problem
Hassler logic to send them an email message instead.
The Buildbot also offers a PB-based status client interface which can display real-time build status in a GUI panel on the developer's desktop. This interface is normally anonymous, but it could be configured to let the buildmaster know which developer is using the status client. The status client could then be used as a message-delivery service, providing an alternative way to deliver low-latency high-interruption messages to the developer (like “hey, you broke the build”).
The buildbot's behavior is defined by the “config file”, which
normally lives in the master.cfg file in the buildmaster's base
directory (but this can be changed with an option to the
buildbot create-master command). This file completely specifies
which Builders are to be run, which slaves they should use, how
Changes should be tracked, and where the status information is to be
sent. The buildmaster's buildbot.tac file names the base
directory; everything else comes from the config file.
A sample config file was installed for you when you created the buildmaster, but you will need to edit it before your buildbot will do anything useful.
This chapter gives an overview of the format of this file and the various sections in it. You will need to read the later chapters to understand how to fill in each section properly.
The config file is, fundamentally, just a piece of Python code which
defines a dictionary named BuildmasterConfig, with a number of
keys that are treated specially. You don't need to know Python to do
basic configuration, though, you can just copy the syntax of the
sample file. If you are comfortable writing Python code,
however, you can use all the power of a full programming language to
achieve more complicated configurations.
The BuildmasterConfig name is the only one which matters: all
other names defined during the execution of the file are discarded.
When parsing the config file, the Buildmaster generally compares the
old configuration with the new one and performs the minimum set of
actions necessary to bring the buildbot up to date: Builders which are
not changed are left untouched, and Builders which are modified get to
keep their old event history.
Basic Python syntax: comments start with a hash character (“#”),
tuples are defined with (parenthesis, pairs), arrays are
defined with [square, brackets], tuples and arrays are mostly
interchangeable. Dictionaries (data structures which map “keys” to
“values”) are defined with curly braces: {'key1': 'value1',
'key2': 'value2'} . Function calls (and object instantiation) can use
named parameters, like w = html.Waterfall(http_port=8010).
The config file starts with a series of import statements,
which make various kinds of Steps and Status targets available for
later use. The main BuildmasterConfig dictionary is created,
then it is populated with a variety of keys. These keys are broken
roughly into the following sections, each of which is documented in
the rest of this chapter:
The config file can use a few names which are placed into its namespace:
basediros.path.expanduser(os.path.join(basedir, 'master.cfg'))
The config file is only read at specific points in time. It is first
read when the buildmaster is launched. Once it is running, there are
various ways to ask it to reload the config file. If you are on the
system hosting the buildmaster, you can send a SIGHUP signal to
it: the buildbot tool has a shortcut for this:
buildbot sighup BASEDIR
The debug tool (buildbot debugclient --master HOST:PORT) has a
“Reload .cfg” button which will also trigger a reload. In the
future, there will be other ways to accomplish this step (probably a
password-protected button on the web page, as well as a privileged IRC
command).
There are a couple of basic settings that you use to tell the buildbot what project it is working on. This information is used by status reporters to let users find out more about the codebase being exercised by this particular Buildbot installation.
c['projectName'] = "Buildbot"
c['projectURL'] = "http://buildbot.sourceforge.net/"
c['buildbotURL'] = "http://localhost:8010/"
projectName is a short string will be used to describe the
project that this buildbot is working on. For example, it is used as
the title of the waterfall HTML page.
projectURL is a string that gives a URL for the project as a
whole. HTML status displays will show projectName as a link to
projectURL, to provide a link from buildbot HTML pages to your
project's home page.
The buildbotURL string should point to the location where the
buildbot's internal web server (usually the html.Waterfall
page) is visible. This typically uses the port number set when you
create the Waterfall object: the buildbot needs your help to
figure out a suitable externally-visible host name.
When status notices are sent to users (either by email or over IRC),
buildbotURL will be used to create a URL to the specific build
or problem that they are being notified about. It will also be made
available to queriers (over IRC) who want to find out where to get
more information about this buildbot.
The c['sources'] key is a list of ChangeSource
instances6.
This defines how the buildmaster learns about source code changes.
More information about what goes here is available in See Getting Source Code Changes.
import buildbot.changes.pb
c['sources'] = [buildbot.changes.pb.PBChangeSource()]
c['schedulers'] is a list of Scheduler instances, each of which
causes builds to be started on a particular set of Builders. The two
basic Scheduler classes you are likely to start with are
Scheduler and Periodic, but you can write a customized
subclass to implement more complicated build scheduling.
The docstring for buildbot.scheduler.Scheduler is the best
place to see all the options that can be used. Type pydoc
buildbot.scheduler.Scheduler to see it, or look in
buildbot/scheduler.py directly.
The basic Scheduler takes four arguments:
namebranchbranch equal to the
special value of None means it should only pay attention to the
default branch. Note that None is a keyword, not a string, so
you want to use None and not "None".
treeStableTimerbuilderNames from buildbot import scheduler
quick = scheduler.Scheduler("quick", None, 60,
["quick-linux", "quick-netbsd"])
full = scheduler.Scheduler("full", None, 5*60,
["full-linux", "full-netbsd", "full-OSX"])
nightly = scheduler.Periodic("nightly", ["full-solaris"], 24*60*60)
c['schedulers'] = [quick, full, nightly]
In this example, the two “quick” builds are triggered 60 seconds after the tree has been changed. The “full” builds do not run quite so quickly (they wait 5 minutes), so hopefully if the quick builds fail due to a missing file or really simple typo, the developer can discover and fix the problem before the full builds are started. Both Schedulers only pay attention to the default branch: any changes on other branches are ignored by these Schedulers. Each Scheduler triggers a different set of Builders, referenced by name.
The third Scheduler in this example just runs the full solaris build once per day. (note that this Scheduler only lets you control the time between builds, not the absolute time-of-day of each Build, so this could easily wind up a “daily” or “every afternoon” scheduler depending upon when it was first activated).
Here is a brief catalog of the available Scheduler types. All these
Schedulers are classes in buildbot.scheduler, and the
docstrings there are the best source of documentation on the arguments
taken by each one.
SchedulerfileIsImportant function
which can be used to ignore some Changes if they do not affect any
“important” files.
AnyBranchSchedulerDependentPeriodicNightlycrontab
format, in which you provide values for minute, hour, day, and month
(some of which can be wildcards), and a build is triggered whenever
the current time matches the given constraints. This can run a build
every night, every morning, every weekend, alternate Thursdays, on
your boss's birthday, etc.
Try_Jobdir / Try_Userpassbuildbot try
command to trigger builds of code they have not yet committed. See
try for complete details.
It is common to wind up with one kind of build which should only be performed if the same source code was successfully handled by some other kind of build first. An example might be a packaging step: you might only want to produce .deb or RPM packages from a tree that was known to compile successfully and pass all unit tests. You could put the packaging step in the same Build as the compile and testing steps, but there might be other reasons to not do this (in particular you might have several Builders worth of compiles/tests, but only wish to do the packaging once). Another example is if you want to skip the “full” builds after a failing “quick” build of the same source code. Or, if one Build creates a product (like a compiled library) that is used by some other Builder, you'd want to make sure the consuming Build is run after the producing one.
You can use Dependencies to express this relationship to the
Buildbot. There is a special kind of Scheduler named
scheduler.Dependent that will watch an “upstream” Scheduler
for builds to complete successfully (on all of its Builders). Each
time that happens, the same source code (i.e. the same
SourceStamp) will be used to start a new set of builds, on a
different set of Builders. This “downstream” scheduler doesn't pay
attention to Changes at all, it only pays attention to the upstream
scheduler.
If the SourceStamp fails on any of the Builders in the upstream set, the downstream builds will not fire.
from buildbot import scheduler
tests = scheduler.Scheduler("tests", None, 5*60,
["full-linux", "full-netbsd", "full-OSX"])
package = scheduler.Dependent("package",
tests, # upstream scheduler
["make-tarball", "make-deb", "make-rpm"])
c['schedulers'] = [tests, package]
Note that Dependent's upstream scheduler argument is given as a
Scheduler instance, not a name. This makes it impossible
to create circular dependencies in the config file.
The buildmaster will listen on a TCP port of your choosing for connections from buildslaves. It can also use this port for connections from remote Change Sources, status clients, and debug tools. This port should be visible to the outside world, and you'll need to tell your buildslave admins about your choice.
It does not matter which port you pick, as long it is externally visible, however you should probably use something larger than 1024, since most operating systems don't allow non-root processes to bind to low-numbered ports. If your buildmaster is behind a firewall or a NAT box of some sort, you may have to configure your firewall to permit inbound connections to this port.
c['slavePortnum'] = 10000
c['slavePortnum'] is a strports specification string,
defined in the twisted.application.strports module (try
pydoc twisted.application.strports to get documentation on
the format). This means that you can have the buildmaster listen on a
localhost-only port by doing:
c['slavePortnum'] = "tcp:10000:interface=127.0.0.1"
This might be useful if you only run buildslaves on the same machine,
and they are all configured to contact the buildmaster at
localhost:10000.
The c['bots'] key is a list of known buildslaves. Each
buildslave is defined by a tuple of (slavename, slavepassword). These
are the same two values that need to be provided to the buildslave
administrator when they create the buildslave.
c['bots'] = [('bot-solaris', 'solarispasswd'),
('bot-bsd', 'bsdpasswd'),
]
The slavenames must be unique, of course. The password exists to prevent evildoers from interfering with the buildbot by inserting their own (broken) buildslaves into the system and thus displacing the real ones.
Buildslaves with an unrecognized slavename or a non-matching password will be rejected when they attempt to connect, and a message describing the problem will be put in the log file (see Logfiles).
The c['builders'] key is a list of dictionaries which specify
the Builders. The Buildmaster runs a collection of Builders, each of
which handles a single type of build (e.g. full versus quick), on a
single build slave. A Buildbot which makes sure that the latest code
(“HEAD”) compiles correctly across four separate architecture will
have four Builders, each performing the same build but on different
slaves (one per platform).
Each Builder gets a separate column in the waterfall display. In general, each Builder runs independently (although various kinds of interlocks can cause one Builder to have an effect on another).
Each Builder specification dictionary has several required keys:
nameslavenameslavename must appear in the c['bots'] list. Each
buildslave can accomodate multiple Builders.
slavenamesslavenames instead of slavename, you can
give a list of buildslaves which are capable of running this Builder.
If multiple buildslaves are available for any given Builder, you will
have some measure of redundancy: in case one slave goes offline, the
others can still keep the Builder working. In addition, multiple
buildslaves will allow multiple simultaneous builds for the same
Builder, which might be useful if you have a lot of forced or “try”
builds taking place.
If you use this feature, it is important to make sure that the
buildslaves are all, in fact, capable of running the given build. The
slave hosts should be configured similarly, otherwise you will spend a
lot of time trying (unsuccessfully) to reproduce a failure that only
occurs on some of the buildslaves and not the others. Different
platforms, operating systems, versions of major programs or libraries,
all these things mean you should use separate Builders.
builddirfactorybuildbot.process.factory.BuildFactory instance which
controls how the build is performed. Full details appear in their own
chapter, See Build Process. Parameters like the location of the CVS
repository and the compile-time options used for the build are
generally provided as arguments to the factory's constructor.
Other optional keys may be set on each Builder:
categoryThe Buildmaster has a variety of ways to present build status to
various users. Each such delivery method is a “Status Target” object
in the configuration's status list. To add status targets, you
just append more objects to this list:
c['status'] = []
from buildbot.status import html
c['status'].append(html.Waterfall(http_port=8010))
from buildbot.status import mail
m = mail.MailNotifier(fromaddr="buildbot@localhost",
extraRecipients=["builds@lists.example.com"],
sendToInterestedUsers=False)
c['status'].append(m)
from buildbot.status import words
c['status'].append(words.IRC(host="irc.example.com", nick="bb",
channels=["#example"]))
Status delivery has its own chapter, See Status Delivery, in which all the built-in status targets are documented.
If you set c['debugPassword'], then you can connect to the
buildmaster with the diagnostic tool launched by buildbot
debugclient MASTER:PORT. From this tool, you can reload the config
file, manually force builds, and inject changes, which may be useful
for testing your buildmaster without actually commiting changes to
your repository (or before you have the Change Sources set up). The
debug tool uses the same port number as the slaves do:
c['slavePortnum'], and is authenticated with this password.
c['debugPassword'] = "debugpassword"
If you set c['manhole'] to an instance of one of the classes in
buildbot.manhole, you can telnet or ssh into the buildmaster
and get an interactive Python shell, which may be useful for debugging
buildbot internals. It is probably only useful for buildbot
developers. It exposes full access to the buildmaster's account
(including the ability to modify and delete files), so it should not
be enabled with a weak or easily guessable password.
There are three separate Manhole classes. Two of them use SSH,
one uses unencrypted telnet. Two of them use a username+password
combination to grant access, one of them uses an SSH-style
authorized_keys file which contains a list of ssh public keys.
manhole.AuthorizedKeysManholemanhole.PasswordManholemanhole.TelnetManhole # some examples:
from buildbot import manhole
c['manhole'] = manhole.AuthorizedKeysManhole(1234, "authorized_keys")
c['manhole'] = manhole.PasswordManhole(1234, "alice", "mysecretpassword")
c['manhole'] = manhole.TelnetManhole(1234, "bob", "snoop_my_password_please")
The Manhole instance can be configured to listen on a specific
port. You may wish to have this listening port bind to the loopback
interface (sometimes known as “lo0”, “localhost”, or 127.0.0.1) to
restrict access to clients which are running on the same host.
from buildbot.manhole import PasswordManhole
c['manhole'] = PasswordManhole("tcp:9999:interface=127.0.0.1","admin","passwd")
To have the Manhole listen on all interfaces, use
"tcp:9999" or simply 9999. This port specification uses
twisted.application.strports, so you can make it listen on SSL
or even UNIX-domain sockets if you want.
Note that using any Manhole requires that the TwistedConch package be installed, and that you be using Twisted version 2.0 or later.
The buildmaster's SSH server will use a different host key than the normal sshd running on a typical unix host. This will cause the ssh client to complain about a “host key mismatch”, because it does not realize there are two separate servers running on the same host. To avoid this, use a clause like the following in your .ssh/config file:
Host remotehost-buildbot
HostName remotehost
HostKeyAlias remotehost-buildbot
Port 9999
# use 'user' if you use PasswordManhole and your name is not 'admin'.
# if you use AuthorizedKeysManhole, this probably doesn't matter.
User admin
The most common way to use the Buildbot is centered around the idea of
Source Trees: a directory tree filled with source code of some form
which can be compiled and/or tested. Some projects use languages that don't
involve any compilation step: nevertheless there may be a build phase
where files are copied or rearranged into a form that is suitable for
installation. Some projects do not have unit tests, and the Buildbot is
merely helping to make sure that the sources can compile correctly. But in
all of these cases, the thing-being-tested is a single source tree.
A Version Control System mantains a source tree, and tells the buildmaster when it changes. The first step of each Build is typically to acquire a copy of some version of this tree.
This chapter describes how the Buildbot learns about what Changes have occurred. For more information on VC systems and Changes, see Version Control Systems.
Each Buildmaster watches a single source tree. Changes can be provided by a variety of ChangeSource types, however any given project will typically have only a single ChangeSource active. This section provides a description of all available ChangeSource types and explains how to set up each of them.
There are a variety of ChangeSources available, some of which are meant to be used in conjunction with other tools to deliver Change events from the VC repository to the buildmaster.
As a quick guide, here is a list of VC systems and the ChangeSources
that might be useful with them. All of these ChangeSources are in the
buildbot.changes module.
CVSbuildbot
sendchange run in a loginfo script)
contrib/viewcvspoll.py polling process which examines the ViewCVS
database directly
SVNcontrib/svn_buildbot.py run in a postcommit script)
contrib/svn_watcher.py or contrib/svnpoller.py polling
process
Darcscontrib/darcs_buildbot.py in a commit script
Mercurialcontrib/hg_buildbot.py run in an 'incoming' hook)
Arch/Bazaarcontrib/arch_buildbot.py run in a commit hook)
All VC systems can be driven by a PBChangeSource and the
buildbot sendchange tool run from some form of commit script.
If you write an email parsing function, they can also all be driven by
a suitable MaildirSource.
The master.cfg configuration file has a dictionary key named
BuildmasterConfig['sources'], which holds a list of
IChangeSource objects. The config file will typically create an
object from one of the classes described below and stuff it into the
list.
s = FreshCVSSourceNewcred(host="host", port=4519,
user="alice", passwd="secret",
prefix="Twisted")
BuildmasterConfig['sources'] = [s]
Each source tree has a nominal top. Each Change has a list of
filenames, which are all relative to this top location. The
ChangeSource is responsible for doing whatever is necessary to
accomplish this. Most sources have a prefix argument: a partial
pathname which is stripped from the front of all filenames provided to
that ChangeSource. Files which are outside this sub-tree are
ignored by the changesource: it does not generate Changes for those
files.
The CVSToys package provides a
server which runs on the machine that hosts the CVS repository it
watches. It has a variety of ways to distribute commit notifications,
and offers a flexible regexp-based way to filter out uninteresting
changes. One of the notification options is named PBService and
works by listening on a TCP port for clients. These clients subscribe
to hear about commit notifications.
The buildmaster has a CVSToys-compatible PBService client built
in. There are two versions of it, one for old versions of CVSToys
(1.0.9 and earlier) which used the oldcred authentication
framework, and one for newer versions (1.0.10 and later) which use
newcred. Both are classes in the
buildbot.changes.freshcvs package.
FreshCVSSourceNewcred objects are created with the following
parameters:
host and port’user and passwd’freshcvs). These must match the server's values, which are
defined in the freshCfg configuration file (which lives in the
CVSROOT directory of the repository).
prefix’To set up the freshCVS server, add a statement like the following to your freshCfg file:
pb = ConfigurationSet([
(None, None, None, PBService(userpass=('foo', 'bar'), port=4519)),
])
This will announce all changes to a client which connects to port 4519 using a username of 'foo' and a password of 'bar'.
Then add a clause like this to your buildmaster's master.cfg:
BuildmasterConfig['sources'] = [FreshCVSSource("cvs.example.com", 4519,
"foo", "bar",
prefix="glib/")]
where "cvs.example.com" is the host that is running the FreshCVS daemon, and "glib" is the top-level directory (relative to the repository's root) where all your source code lives. Most projects keep one or more projects in the same repository (along with CVSROOT/ to hold admin files like loginfo and freshCfg); the prefix= argument tells the buildmaster to ignore everything outside that directory, and to strip that common prefix from all pathnames it handles.
CVSToys also provides a MailNotification action which will send
email to a list of recipients for each commit. This tends to work
better than using /bin/mail from within the CVSROOT/loginfo
file directly, as CVSToys will batch together all files changed during
the same CVS invocation, and can provide more information (like
creating a ViewCVS URL for each file changed).
The Buildbot's FCMaildirSource is a ChangeSource which knows
how to parse these CVSToys messages and turn them into Change objects.
It watches a Maildir for new messages. The usually installation
process looks like:
projectname-commits.
MailNotification action to
send commit mail to this mailing list.
FCMaildirSource to
watch the maildir for commit messages.
The FCMaildirSource is created with two parameters: the
directory name of the maildir root, and the prefix to strip.
There are other types of maildir-watching ChangeSources, which only differ in the function used to parse the message body.
SyncmailMaildirSource knows how to parse the message format
used in mail sent by Syncmail.
BonsaiMaildirSource parses messages sent out by Bonsai.
The last kind of ChangeSource actually listens on a TCP port for
clients to connect and push change notices into the
Buildmaster. This is used by the built-in buildbot sendchange
notification tool, as well as the VC-specific
contrib/svn_buildbot.py and contrib/arch_buildbot.py
tools. These tools are run by the repository (in a commit hook
script), and connect to the buildmaster directly each time a file is
comitted. This is also useful for creating new kinds of change sources
that work on a push model instead of some kind of subscription
scheme, for example a script which is run out of an email .forward
file.
This ChangeSource can be configured to listen on its own TCP port, or
it can share the port that the buildmaster is already using for the
buildslaves to connect. (This is possible because the
PBChangeSource uses the same protocol as the buildslaves, and
they can be distinguished by the username attribute used when
the initial connection is established). It might be useful to have it
listen on a different port if, for example, you wanted to establish
different firewall rules for that port. You could allow only the SVN
repository machine access to the PBChangeSource port, while
allowing only the buildslave machines access to the slave port. Or you
could just expose one port and run everything over it. Note:
this feature is not yet implemented, the PBChangeSource will always
share the slave port and will always have a user name of
change, and a passwd of changepw. These limitations will
be removed in the future..
The PBChangeSource is created with the following arguments. All
are optional.
port’None (which is the default), it
shares the port used for buildslave connections. Not
Implemented, always set to None.
user and passwd’change and changepw. Not
Implemented, user is currently always set to change,
passwd is always set to changepw.
prefix’This is useful for changes coming from version control systems that represent branches as parent directories within the repository (like SVN and Perforce). Use a prefix of 'trunk/' or 'project/branches/foobranch/' to only follow one branch and to get correct tree-relative filenames. Without a prefix, the PBChangeSource will probably deliver Changes with filenames like trunk/foo.c instead of just foo.c. Of course this also depends upon the tool sending the Changes in (like buildbot sendchange) and what filenames it is delivering: that tool may be filtering and stripping prefixes at the sending end.
The P4Source periodically polls a Perforce depot for changes. It accepts the following arguments:
p4base’p4port’p4user’p4passwd’split_file’p4base, to a
(branch, filename) tuple. The default just returns (None, branchfile),
which effectively disables branch support. You should supply a function
which understands your repository structure.
pollinterval’histmax’This configuration uses the P4PORT, P4USER, and P4PASSWD
specified in the buildmaster's environment. It watches a project in which the
branch name is simply the next path component, and the file is all path
components after.
import buildbot.changes.p4poller
c['sources'].append(p4poller.P4Source(
p4base='//depot/project/',
split_file=lambda branchfile: branchfile.split('/',1)
))
A Build object is responsible for actually performing a build.
It gets access to a remote SlaveBuilder where it may run
commands, and a BuildStatus object where it must emit status
events. The Build is created by the Builder's
BuildFactory.
The default Build class is made up of a fixed sequence of
BuildSteps, executed one after another until all are complete
(or one of them indicates that the build should be halted early). The
default BuildFactory creates instances of this Build
class with a list of BuildSteps, so the basic way to configure
the build is to provide a list of BuildSteps to your
BuildFactory.
More complicated Build subclasses can make other decisions:
execute some steps only if certain files were changed, or if certain
previous steps passed or failed. The base class has been written to
allow users to express basic control flow without writing code, but
you can always subclass and customize to achieve more specialized
behavior.
BuildSteps are usually specified in the buildmaster's
configuration file, in a list of “step specifications” that is used
to create the BuildFactory. These “step specifications” are
not actual steps, but rather a tuple of the BuildStep subclass
to be created and a dictionary of arguments. (the actual
BuildStep instances are not created until the Build is started,
so that each Build gets an independent copy of each BuildStep). The
preferred way to create these step specifications is with the
BuildFactory's addStep method:
from buildbot.process import step, factory
f = factory.BuildFactory()
f.addStep(step.SVN, svnurl="http://svn.example.org/Trunk/")
f.addStep(step.ShellCommand, command=["make", "all"])
f.addStep(step.ShellCommand, command=["make", "test"])
The rest of this section lists all the standard BuildStep objects available for use in a Build, and the parameters which can be used to control each.
The standard Build runs a series of BuildSteps in order,
only stopping when it runs out of steps or if one of them requests
that the build be halted. It collects status information from each one
to create an overall build status (of SUCCESS, WARNINGS, or FAILURE).
All BuildSteps accept some common parameters. Some of these control
how their individual status affects the overall build. Others are used
to specify which Locks (see see Interlocks) should be
acquired before allowing the step to run.
Arguments common to all BuildStep subclasses:
namehaltOnFailureflunkOnWarningsflunkOnFailurewarnOnWarningswarnOnFailurelocksbuildbot.locks.SlaveLock or
buildbot.locks.MasterLock) that should be acquired before
starting this Step. The Locks will be released when the step is
complete. Note that this is a list of actual Lock instances, not
names. Also note that all Locks must have unique names.
The first step of any build is typically to acquire the source code from which the build will be performed. There are several classes to handle this, one for each of the different source control system that Buildbot knows about. For a description of how Buildbot treats source control in general, see Version Control Systems.
All source checkout steps accept some common parameters to control how they get the sources and where they should be placed. The remaining per-VC-system parameters are mostly to specify where exactly the sources are coming from.
modeupdate.
updatecopyclobberexportclobber, except that the 'cvs export' command is
used to create the working directory. This command removes all CVS
metadata files (the CVS/ directories) from the tree, which is
sometimes useful for creating source tarballs (to avoid including the
metadata in the tar file).
workdiralwaysUseLatestretry(delay, repeats) which means
that when a full VC checkout fails, it should be retried up to
repeats times, waiting delay seconds between attempts. If
you don't provide this, it defaults to None, which means VC
operations should not be retried. This is provided to make life easier
for buildslaves which are stuck behind poor network connections.
My habit as a developer is to do a cvs update and make each
morning. Problems can occur, either because of bad code being checked in, or
by incomplete dependencies causing a partial rebuild to fail where a
complete from-scratch build might succeed. A quick Builder which emulates
this incremental-build behavior would use the mode='update'
setting.
On the other hand, other kinds of dependency problems can cause a clean build to fail where a partial build might succeed. This frequently results from a link step that depends upon an object file that was removed from a later version of the tree: in the partial tree, the object file is still around (even though the Makefiles no longer know how to create it).
“official” builds (traceable builds performed from a known set of
source revisions) are always done as clean builds, to make sure it is
not influenced by any uncontrolled factors (like leftover files from a
previous build). A “full” Builder which behaves this way would want
to use the mode='clobber' setting.
Each VC system has a corresponding source checkout class: their arguments are described on the following pages.
The CVS build step performs a CVS checkout or update. It takes the following arguments:
cvsroot:pserver:anonymous@cvs.sourceforge.net:/cvsroot/buildbot
cvsmodulemodule, which is generally a
subdirectory of the CVSROOT. The cvsmodule for the Buildbot source
code is buildbot.
branch-r argument. This is most
useful for specifying a branch to work on. Defaults to HEAD.
global_optionscheckoutDelay-D option. Defaults to
half of the parent Build's treeStableTimer.
The SVN build step performs a
Subversion checkout or update.
There are two basic ways of setting up the checkout step, depending
upon whether you are using multiple branches or not.
If all of your builds use the same branch, then you should create the
SVN step with the svnurl argument:
svnurlURL argument that will be given
to the svn checkout command. It dictates both where the
repository is located and which sub-tree should be extracted. In this
respect, it is like a combination of the CVS cvsroot and
cvsmodule arguments. For example, if you are using a remote
Subversion repository which is accessible through HTTP at a URL of
http://svn.example.com/repos, and you wanted to check out the
trunk/calc sub-tree, you would use
svnurl="http://svn.example.com/repos/trunk/calc" as an argument
to your SVN step.
If, on the other hand, you are building from multiple branches, then
you should create the SVN step with the baseURL and
defaultBranch arguments instead:
baseURLdefaultBranchbaseURL to
create the string that will be passed to the svn checkout
command.
If you are using branches, you must also make sure your
ChangeSource will report the correct branch names.
Let's suppose that the “MyProject” repository uses branches for the trunk, for various users' individual development efforts, and for several new features that will require some amount of work (involving multiple developers) before they are ready to merge onto the trunk. Such a repository might be organized as follows:
svn://svn.example.org/MyProject/trunk
svn://svn.example.org/MyProject/branches/User1/foo
svn://svn.example.org/MyProject/branches/User1/bar
svn://svn.example.org/MyProject/branches/User2/baz
svn://svn.example.org/MyProject/features/newthing
svn://svn.example.org/MyProject/features/otherthing
Further assume that we want the Buildbot to run tests against the trunk and against all the feature branches (i.e., do a checkout/compile/build of branch X when a file has been changed on branch X, when X is in the set [trunk, features/newthing, features/otherthing]). We do not want the Buildbot to automatically build any of the user branches, but it should be willing to build a user branch when explicitly requested (most likely by the user who owns that branch).
There are three things that need to be set up to accomodate this
system. The first is a ChangeSource that is capable of identifying the
branch which owns any given file. This depends upon a user-supplied
function, in an external program that runs in the SVN commit hook and
connects to the buildmaster's PBChangeSource over a TCP
connection. (you can use the “buildbot sendchange” utility
for this purpose, but you will still need an external program to
decide what value should be passed to the --branch= argument).
For example, a change to a file with the SVN url of
“svn://svn.example.org/MyProject/features/newthing/src/foo.c” should
be broken down into a Change instance with
branch='features/newthing' and file='src/foo.c'.
The second piece is an AnyBranchScheduler which will pay
attention to the desired branches. It will not pay attention to the
user branches, so it will not automatically start builds in response
to changes there. The AnyBranchScheduler class requires you to
explicitly list all the branches you want it to use, but it would not
be difficult to write a subclass which used
branch.startswith('features/' to remove the need for this
explicit list. Or, if you want to build user branches too, you can use
AnyBranchScheduler with branches=None to indicate that you want
it to pay attention to all branches.
The third piece is an SVN checkout step that is configured to
handle the branches correctly, with a baseURL value that
matches the way the ChangeSource splits each file's URL into base,
branch, and file.
from buildbot.changes.pb import PBChangeSource
from buildbot.scheduler import AnyBranchScheduler
from buildbot.process import step, factory
c['sources'] = [PBChangeSource()]
s1 = AnyBranchScheduler('main',
['trunk', 'features/newthing', 'features/otherthing'],
10*60, ['test-i386', 'test-ppc'])
c['schedulers'] = [s1]
f = factory.BuildFactory()
f.addStep(step.SVN, mode='update',
baseURL='svn://svn.example.org/MyProject/',
defaultBranch='trunk')
f.addStep(step.Compile, command="make all")
f.addStep(step.Test, command="make test")
c['builders'] = [
{'name':'test-i386', 'slavename':'bot-i386', 'builddir':'test-i386',
'factory':f },
{'name':'test-ppc', 'slavename':'bot-ppc', 'builddir':'test-ppc',
'factory':f },
]
In this example, when a change arrives with a branch attribute
of “trunk”, the resulting build will have an SVN step that
concatenates “svn://svn.example.org/MyProject/” (the baseURL) with
“trunk” (the branch name) to get the correct svn command. If the
“newthing” branch has a change to “src/foo.c”, then the SVN step
will concatenate “svn://svn.example.org/MyProject/” with
“features/newthing” to get the svnurl for checkout.
The Darcs build step performs a
Darcs checkout or update.
Like See SVN, this step can either be configured to always check
out a specific tree, or set up to pull from a particular branch that
gets specified separately for each build. Also like SVN, the
repository URL given to Darcs is created by concatenating a
baseURL with the branch name, and if no particular branch is
requested, it uses a defaultBranch. The only difference in
usage is that each potential Darcs repository URL must point to a
fully-fledged repository, whereas SVN URLs usually point to sub-trees
of the main Subversion repository. In other words, doing an SVN
checkout of baseURL is legal, but silly, since you'd probably
wind up with a copy of every single branch in the whole repository.
Doing a Darcs checkout of baseURL is just plain wrong, since
the parent directory of a collection of Darcs repositories is not
itself a valid repository.
The Darcs step takes the following arguments:
repourlbaseURL is provided): the URL at which the
Darcs source repository is available.
baseURLrepourl is provided): the base repository URL,
to which a branch name will be appended. It should probably end in a
slash.
defaultBranchbaseURL is provided): this specifies
the name of the branch to use when a Build does not provide one of its
own. This will be appended to baseURL to create the string that
will be passed to the darcs get command.
The Mercurial build step performs a
Mercurial (aka “hg”) checkout
or update.
Branches are handled just like See Darcs.
The Mercurial step takes the following arguments:
repourlbaseURL is provided): the URL at which the
Mercurial source repository is available.
baseURLrepourl is provided): the base repository URL,
to which a branch name will be appended. It should probably end in a
slash.
defaultBranchbaseURL is provided): this specifies
the name of the branch to use when a Build does not provide one of its
own. This will be appended to baseURL to create the string that
will be passed to the hg clone command.
The Arch build step performs an Arch checkout or update using the tla client. It takes the
following arguments:
urlversionarchiveBazaar
step, below.
Bazaar is an alternate implementation of the Arch VC system,
which uses a client named baz. The checkout semantics are just
different enough from tla that there is a separate BuildStep for
it.
It takes exactly the same arguments as Arch, except that the
archive= parameter is required. (baz does not emit the archive
name when you do baz register-archive, so we must provide it
ourselves).
The P4 build step creates a Perforce client specification and performs an update.
p4basedefaultBranchp4portp4userp4passwdp4extra_viewsp4clientThis is a useful base class for just about everything you might want to do during a build (except for the initial source checkout). It runs a single command in a child shell on the buildslave. All stdout/stderr is recorded into a LogFile. The step finishes with a status of FAILURE if the command's exit code is non-zero, otherwise it has a status of SUCCESS.
The preferred way to specify the command is with a list of argv strings, since this allows for spaces in filenames and avoids doing any fragile shell-escaping. You can also specify the command with a single string, in which case the string is given to '/bin/sh -c COMMAND' for parsing.
All ShellCommands are run by default in the “workdir”, which
defaults to the “build” subdirectory of the slave builder's
base directory. The absolute path of the workdir will thus be the
slave's basedir (set as an option to buildbot create-slave,
see Creating a buildslave) plus the builder's basedir (set in the
builder's c['builddir'] key in master.cfg) plus the workdir
itself (a class-level attribute of the BuildFactory, defaults to
“build”).
ShellCommand arguments:
commandenv f.addStep(ShellCommand, command=["make", "test"],
env={'LANG': 'fr_FR'})
These variable settings will override any existing ones in the buildslave's environment. The exception is PYTHONPATH, which is merged with (actually prepended to) any existing $PYTHONPATH setting. The value is treated as a list of directories to prepend, and a single string is treated like a one-item list. For example, to prepend both /usr/local/lib/python2.3 and /home/buildbot/lib/python to any existing $PYTHONPATH setting, you would do something like the following:
f.addStep(ShellCommand, command=["make", "test"],
env={'PYTHONPATH': ["/usr/local/lib/python2.3",
"/home/buildbot/lib/python"] })
want_stdoutwant_stderrwant_stdout but for stderr. Note that commands run through
a PTY do not have separate stdout/stderr streams: both are merged into
stdout.
logfilesThe logfiles= argument allows you to collect data from these
secondary logfiles in near-real-time, as the step is running. It
accepts a dictionary which maps from a local Log name (which is how
the log data is presented in the build results) to a remote filename
(interpreted relative to the build's working directory). Each named
file will be polled on a regular basis (every couple of seconds) as
the build runs, and any new text will be sent over to the buildmaster.
f.addStep(ShellCommand, command=["make", "test"],
logfiles={"triallog": "_trial_temp/test.log"})
timeoutdescriptiondescriptionDonedescription, this may either be a list of short strings or a
single string.
If neither description nor descriptionDone are set, the
actual command arguments will be used to construct the description.
This may be a bit too wide to fit comfortably on the Waterfall
display.
f.addStep(ShellCommand, command=["make", "test"],
description=["testing"],
descriptionDone=["tests"])
Several subclasses of ShellCommand are provided as starting points for common build steps. These are all very simple: they just override a few parameters so you don't have to specify them yourself, making the master.cfg file less verbose.
This is intended to handle the ./configure step from
autoconf-style projects, or the perl Makefile.PL step from perl
MakeMaker.pm-style modules. The default command is ./configure
but you can change this by providing a command= parameter.
This is meant to handle compiling or building a project written in C. The
default command is make all. When the compile is finished, the
log file is scanned for GCC error/warning messages and a summary log is
created with any problems that were seen (TODO: the summary is not yet
created).
This is meant to handle unit tests. The default command is make
test, and the warnOnFailure flag is set.
Each build has a set of “Build Properties”, which can be used by its BuildStep to modify their actions. For example, the SVN revision number of the source code being built is available as a build property, and a ShellCommand step could incorporate this number into a command which create a numbered release tarball.
Some build properties are set when the build starts, such as the
SourceStamp information. Other properties can be set by BuildSteps as
they run, for example the various Source steps will set the
got_revision property to the source revision that was actually
checked out (which can be useful when the SourceStamp in use merely
requested the “latest revision”: got_revision will tell you
what was actually built).
In custom BuildSteps, you can get and set the build properties with
the getProperty/setProperty methods. Each takes a string
for the name of the property, and returns or accepts an
arbitrary7 object. For example:
class MakeTarball(step.ShellCommand):
def start(self):
self.setCommand(["tar", "czf",
"build-%s.tar.gz" % self.getProperty("revision"),
"source"])
step.ShellCommand.start(self)
You can use build properties in ShellCommands by using the
WithProperties wrapper when setting the arguments of the
ShellCommand. This interpolates the named build properties into the
generated shell command.
from buildbot.process.step import ShellCommand, WithProperties
f.addStep(ShellCommand,
command=["tar", "czf",
WithProperties("build-%s.tar.gz", "revision"),
"source"])
If this BuildStep were used in a tree obtained from Subversion, it would create a tarball with a name like build-1234.tar.gz.
The WithProperties function does printf-style string
interpolation, using strings obtained by calling
build.getProperty(propname). Note that for every %s (or
%d, etc), you must have exactly one additional argument to
indicate which build property you want to insert.
You can also use python dictionary-style string interpolation by using
the %(propname)s syntax. In this form, the property name goes
in the parentheses, and WithProperties takes no additional
arguments:
f.addStep(ShellCommand,
command=["tar", "czf",
WithProperties("build-%(revision)s.tar.gz"),
"source"])
Don't forget the extra “s” after the closing parenthesis! This is the cause of many confusing errors.
Note that, like python, you can either do positional-argument
interpolation or keyword-argument interpolation, not both. Thus
you cannot use a string like
WithProperties("foo-%(revision)s-%s", "branch").
At the moment, the only way to set build properties is by writing a custom BuildStep.
The following build properties are set when the build is started, and are available to all steps.
branchNone (which interpolates into
WithProperties as an empty string) if the build is on the
default branch, which is generally the trunk. Otherwise it will be a
string like “branches/beta1.4”. The exact syntax depends upon the VC
system being used.
revisionIf the “force build” button was pressed, the revision will be
None, which means to use the most recent revision available.
This is a “trunk build”. This will be interpolated as an empty
string.
got_revisionrevision, except for
trunk builds, where got_revision indicates what revision was
current when the checkout was performed. This can be used to rebuild
the same source code later.
Note that for some VC systems (Darcs in particular), the revision is a
large string containing newlines, and is not suitable for
interpolation into a filename.
buildernamebuildnumberslavenameWhile it is a good idea to keep your build process self-contained in the source code tree, sometimes it is convenient to put more intelligence into your Buildbot configuration. One was to do this is to write a custom BuildStep. Once written, this Step can be used in the master.cfg file.
The best reason for writing a custom BuildStep is to better parse the
results of the command being run. For example, a BuildStep that knows
about JUnit could look at the logfiles to determine which tests had
been run, how many passed and how many failed, and then report more
detailed information than a simple rc==0 -based “good/bad”
decision.
TODO: add more description of BuildSteps.
Each BuildStep has a collection of “logfiles”. Each one has a short name, like “stdio” or “warnings”. Each LogFile contains an arbitrary amount of text, usually the contents of some output file generated during a build or test step, or a record of everything that was printed to stdout/stderr during the execution of some command.
These LogFiles are stored to disk, so they can be retrieved later.
Each can contain multiple “channels”, generally limited to three basic ones: stdout, stderr, and “headers”. For example, when a ShellCommand runs, it writes a few lines to the “headers” channel to indicate the exact argv strings being run, which directory the command is being executed in, and the contents of the current environment variables. Then, as the command runs, it adds a lot of “stdout” and “stderr” messages. When the command finishes, a final “header” line is added with the exit code of the process.
Status display plugins can format these different channels in different ways. For example, the web page shows LogFiles as text/html, with header lines in blue text, stdout in black, and stderr in red. A different URL is available which provides a text/plain format, in which stdout and stderr are collapsed together, and header lines are stripped completely. This latter option makes it easy to save the results to a file and run grep or whatever against the output.
Each BuildStep contains a mapping (implemented in a python dictionary) from LogFile name to the actual LogFile objects. Status plugins can get a list of LogFiles to display, for example, a list of HREF links that, when clicked, provide the full contents of the LogFile.
The most common way for a custom BuildStep to use a LogFile is to summarize the results of a ShellCommand (after the command has finished running). For example, a compile step with thousands of lines of output might want to create a summary of just the warning messages. If you were doing this from a shell, you would use something like:
grep "warning:" output.log >warnings.log
In a custom BuildStep, you could instead create a “warnings” LogFile
that contained the same text. To do this, you would add code to your
createSummary method that pulls lines from the main output log
and creates a new LogFile with the results:
def createSummary(self, log):
warnings = []
for line in log.readlines():
if "warning:" in line:
warnings.append()
self.addCompleteLog('warnings', "".join(warnings))
This example uses the addCompleteLog method, which creates a
new LogFile, puts some text in it, and then “closes” it, meaning
that no further contents will be added. This LogFile will appear in
the HTML display under an HREF with the name “warnings”, since that
is the name of the LogFile.
You can also use addHTMLLog to create a complete (closed)
LogFile that contains HTML instead of plain text. The normal LogFile
will be HTML-escaped if presented through a web page, but the HTML
LogFile will not. At the moment this is only used to present a pretty
HTML representation of an otherwise ugly exception traceback when
something goes badly wrong during the BuildStep.
In contrast, you might want to create a new LogFile at the beginning
of the step, and add text to it as the command runs. You can create
the LogFile and attach it to the build by calling addLog, which
returns the LogFile object. You then add text to this LogFile by
calling methods like addStdout and addHeader. When you
are done, you must call the finish method so the LogFile can be
closed. It may be useful to create and populate a LogFile like this
from a LogObserver method See Adding LogObservers.
The logfiles= argument to ShellCommand (see
see ShellCommand) creates new LogFiles and fills them in realtime
by asking the buildslave to watch a actual file on disk. The
buildslave will look for additions in the target file and report them
back to the BuildStep. These additions will be added to the LogFile by
calling addStdout. These secondary LogFiles can be used as the
source of a LogObserver just like the normal “stdio” LogFile.
Most shell commands emit messages to stdout or stderr as they operate,
especially if you ask them nicely with a --verbose flag of some
sort. They may also write text to a log file while they run. Your
BuildStep can watch this output as it arrives, to keep track of how
much progress the command has made. You can get a better measure of
progress by counting the number of source files compiled or test cases
run than by merely tracking the number of bytes that have been written
to stdout. This improves the accuracy and the smoothness of the ETA
display.
To accomplish this, you will need to attach a LogObserver to
one of the log channels, most commonly to the “stdio” channel but
perhaps to another one which tracks a log file. This observer is given
all text as it is emitted from the command, and has the opportunity to
parse that output incrementally. Once the observer has decided that
some event has occurred (like a source file being compiled), it can
use the setProgress method to tell the BuildStep about the
progress that this event represents.
There are a number of pre-built LogObserver classes that you
can choose from, and of course you can subclass them to add further
customization. The LogLineObserver class handles the grunt work
of buffering and scanning for end-of-line delimiters, allowing your
parser to operate on complete stdout/stderr lines.
For example, let's take a look at the TrialTestCaseCounter,
which is used by the Trial step to count test cases as they are run.
As Trial executes, it emits lines like the following:
buildbot.test.test_config.ConfigTest.testDebugPassword ... [OK]
buildbot.test.test_config.ConfigTest.testEmpty ... [OK]
buildbot.test.test_config.ConfigTest.testIRC ... [FAIL]
buildbot.test.test_config.ConfigTest.testLocks ... [OK]
When the tests are finished, trial emits a long line of “======” and then some lines which summarize the tests that failed. We want to avoid parsing these trailing lines, because their format is less well-defined than the “[OK]” lines.
The parser class looks like this:
class TrialTestCaseCounter(step.LogLineObserver):
_line_re = re.compile(r'^([\w\.]+) \.\.\. \[([^\]]+)\]$')
numTests = 0
finished = False
def outLineReceived(self, line):
if self.finished:
return
if line.startswith("=" * 40):
self.finished = True
return
m = self._line_re.search(line.strip())
if m:
testname, result = m.groups()
self.numTests += 1
self.step.setProgress('tests', self.numTests)
This parser only pays attention to stdout, since that's where trial
writes the progress lines. It has a mode flag named finished to
ignore everything after the “====” marker, and a scary-looking
regular expression to match each line while hopefully ignoring other
messages that might get displayed as the test runs.
Each time it identifies a test has been completed, it increments its
counter and delivers the new progress value to the step with
self.step.setProgress. This class is specifically measuring
progress along the “tests” metric, in units of test cases (as
opposed to other kinds of progress like the “output” metric, which
measures in units of bytes). The Progress-tracking code uses each
progress metric separately to come up with an overall completion
percentage and an ETA value.
To connect this parser into the Trial BuildStep,
Trial.__init__ ends with the following clause:
# this counter will feed Progress along the 'test cases' metric
counter = TrialTestCaseCounter()
self.addLogObserver('stdio', counter)
This creates a TrialTestCaseCounter and tells the step that the
counter wants to watch the “stdio” log. The observer is
automatically given a reference to the step in its .step
attribute.
Each BuildStep has a collection of “links”. Like its collection of LogFiles, each link has a name and a target URL. The web status page creates HREFs for each link in the same box as it does for LogFiles, except that the target of the link is the external URL instead of an internal link to a page that shows the contents of the LogFile.
These external links can be used to point at build information hosted
on other servers. For example, the test process might produce an
intricate description of which tests passed and failed, or some sort
of code coverage data in HTML form, or a PNG or GIF image with a graph
of memory usage over time. The external link can provide an easy way
for users to navigate from the buildbot's status page to these
external web sites or file servers. Note that the step itself is
responsible for insuring that there will be a document available at
the given URL (perhaps by using scp to copy the HTML output
to a ~/public_html/ directory on a remote web server). Calling
addURL does not magically populate a web server.
To set one of these links, the BuildStep should call the addURL
method with the name of the link and the target URL. Multiple URLs can
be set.
In this example, we assume that the make test command causes a collection of HTML files to be created and put somewhere on the coverage.example.org web server, in a filename that incorporates the build number.
class TestWithCodeCoverage(BuildStep):
command = ["make", "test",
WithProperties("buildnum=%s" % "buildnumber")]
def createSummary(self, log):
buildnumber = self.getProperty("buildnumber")
url = "http://coverage.example.org/builds/%s.html" % buildnumber
self.addURL("coverage", url)
You might also want to extract the URL from some special message output by the build process itself:
class TestWithCodeCoverage(BuildStep):
command = ["make", "test",
WithProperties("buildnum=%s" % "buildnumber")]
def createSummary(self, log):
output = StringIO(log.getText())
for line in output.readlines():
if line.startswith("coverage-url:"):
url = line[len("coverage-url:"):].strip()
self.addURL("coverage", url)
return
Note that a build process which emits both stdout and stderr might cause this line to be split or interleaved between other lines. It might be necessary to restrict the getText() call to only stdout with something like this:
output = StringIO("".join([c[1]
for c in log.getChunks()
if c[0] == LOG_CHANNEL_STDOUT]))
Of course if the build is run under a PTY, then stdout and stderr will be merged before the buildbot ever sees them, so such interleaving will be unavoidable.
For various reasons, you may want to prevent certain Steps (or perhaps entire Builds) from running simultaneously. Limited CPU speed or network bandwidth to the VC server, problems with simultaneous access to a database server used by unit tests, or multiple Builds which access shared state may all require some kind of interlock to prevent corruption, confusion, or resource overload.
Locks are the mechanism used to express these kinds of
constraints on when Builds or Steps can be run. There are two kinds of
Locks, each with their own scope: SlaveLocks are scoped
to a single buildslave, while MasterLock instances are scoped
to the buildbot as a whole. Each Lock is created with a unique
name.
To use a lock, simply include it in the locks= argument of the
BuildStep object that should obtain the lock before it runs.
This argument accepts a list of Lock objects: the Step will
acquire all of them before it runs.
To claim a lock for the whole Build, add a 'locks' key to the
builder specification dictionary with the same list of Lock
objects. (This is the dictionary that has the 'name',
'slavename', 'builddir', and 'factory' keys). The
Build object also accepts a locks= argument, but unless
you are writing your own BuildFactory subclass then it will be
easier to set the locks in the builder dictionary.
Note that there are no partial-acquire or partial-release semantics:
this prevents deadlocks caused by two Steps each waiting for a lock
held by the other8. This also means
that waiting to acquire a Lock can take an arbitrarily long
time: if the buildmaster is very busy, a Step or Build which requires
only one Lock may starve another that is waiting for that
Lock plus some others.
In the following example, we run the same build on three different
platforms. The unit-test steps of these builds all use a common
database server, and would interfere with each other if allowed to run
simultaneously. The Lock prevents more than one of these builds
from happening at the same time.
from buildbot import locks
from buildbot.process import step, factory
db_lock = locks.MasterLock("database")
f = factory.BuildFactory()
f.addStep(step.SVN, svnurl="http://example.org/svn/Trunk")
f.addStep(step.ShellCommand, command="make all")
f.addStep(step.ShellCommand, command="make test", locks=[db_lock])
b1 = {'name': 'full1', 'slavename': 'bot-1', builddir='f1', 'factory': f}
b2 = {'name': 'full2', 'slavename': 'bot-2', builddir='f2', 'factory': f}
b3 = {'name': 'full3', 'slavename': 'bot-3', builddir='f3', 'factory': f}
c['builders'] = [b1, b2, b3]
In the next example, we have one buildslave hosting three separate
Builders (each running tests against a different version of Python).
The machine which hosts this buildslave is not particularly fast, so
we want to prevent the builds from all happening at the same time. We
use a SlaveLock because the builds happening on the slow slave
do not affect builds running on other slaves, and we use the lock on
the build as a whole because the slave is so slow that even multiple
SVN checkouts would be taxing.
from buildbot import locks
from buildbot.process import s, step, factory
slow_lock = locks.SlaveLock("cpu")
source = s(step.SVN, svnurl="http://example.org/svn/Trunk")
f22 = factory.Trial(source, trialpython=["python2.2"])
f23 = factory.Trial(source, trialpython=["python2.3"])
f24 = factory.Trial(source, trialpython=["python2.4"])
b1 = {'name': 'p22', 'slavename': 'bot-1', builddir='p22', 'factory': f22,
'locks': [slow_lock] }
b2 = {'name': 'p23', 'slavename': 'bot-1', builddir='p23', 'factory': f23,
'locks': [slow_lock] }
b3 = {'name': 'p24', 'slavename': 'bot-1', builddir='p24', 'factory': f24,
'locks': [slow_lock] }
c['builders'] = [b1, b2, b3]
In the last example, we use two Locks at the same time. In this case, we're concerned about both of the previous constraints, but we'll say that only the tests are computationally intensive, and that they have been split into those which use the database and those which do not. In addition, two of the Builds run on a fast machine which does not need to worry about the cpu lock, but which still must be prevented from simultaneous database access.
from buildbot import locks
from buildbot.process import step, factory
db_lock = locks.MasterLock("database")
cpu_lock = locks.SlaveLock("cpu")
slow_f = factory.BuildFactory()
f.addStep(step.SVN, svnurl="http://example.org/svn/Trunk")
f.addStep(step.ShellCommand, command="make all", locks=[cpu_lock])
f.addStep(step.ShellCommand, command="make test", locks=[cpu_lock])
f.addStep(step.ShellCommand, command="make db-test",
locks=[db_lock, cpu_lock])
fast_factory = factory.BuildFactory()
f.addStep(step.SVN, svnurl="http://example.org/svn/Trunk")
f.addStep(step.ShellCommand, command="make all", locks=[])
f.addStep(step.ShellCommand, command="make test", locks=[])
f.addStep(step.ShellCommand, command="make db-test", locks=[db_lock])
b1 = {'name': 'full1', 'slavename': 'bot-slow', builddir='full1',
'factory': slow_factory}
b2 = {'name': 'full2', 'slavename': 'bot-slow', builddir='full2',
'factory': slow_factory}
b3 = {'name': 'full3', 'slavename': 'bot-fast', builddir='full3',
'factory': fast_factory}
b4 = {'name': 'full4', 'slavename': 'bot-fast', builddir='full4',
'factory': fast_factory}
c['builders'] = [b1, b2, b3, b4]
As a final note, remember that a unit test system which breaks when
multiple people run it at the same time is fragile and should be
fixed. Asking your human developers to serialize themselves when
running unit tests will just discourage them from running the unit
tests at all. Find a way to fix this: change the database tests to
create a new (uniquely-named) user or table for each test run, don't
use fixed listening TCP ports for network tests (instead listen on
port 0 to let the kernel choose a port for you and then query the
socket to find out what port was allocated). MasterLocks can be
used to accomodate broken test systems like this, but are really
intended for other purposes: build processes that store or retrieve
products in shared directories, or which do things that human
developers would not (or which might slow down or break in ways that
require human attention to deal with).
SlaveLockss can be used to keep automated performance tests
from interfering with each other, when there are multiple Builders all
using the same buildslave. But they can't prevent other users from
running CPU-intensive jobs on that host while the tests are running.
Each Builder is equipped with a “build factory”, which is
responsible for producing the actual Build objects that perform
each build. This factory is created in the configuration file, and
attached to a Builder through the factory element of its
dictionary.
The standard BuildFactory object creates Build objects
by default. These Builds will each execute a collection of BuildSteps
in a fixed sequence. Each step can affect the results of the build,
but in general there is little intelligence to tie the different steps
together. You can create subclasses of Build to implement more
sophisticated build processes, and then use a subclass of
BuildFactory (or simply set the buildClass attribute) to
create instances of your new Build subclass.
The steps used by these builds are all subclasses of BuildStep.
The standard ones provided with Buildbot are documented later,
See Build Steps. You can also write your own subclasses to use in
builds.
The basic behavior for a BuildStep is to:
More sophisticated steps may produce additional information and provide it to later build steps, or store it in the factory to provide to later builds.
The default BuildFactory, provided in the
buildbot.process.factory module, contains a list of “BuildStep
specifications”: a list of (step_class, kwargs) tuples for
each. When asked to create a Build, it loads the list of steps into
the new Build object. When the Build is actually started, these step
specifications are used to create the actual set of BuildSteps, which
are then executed one at a time. For example, a build which consists
of a CVS checkout followed by a make build would be constructed
as follows:
from buildbot.process import step, factory
f = factory.BuildFactory()
f.addStep(step.CVS, cvsroot=CVSROOT, cvsmodule="project", mode="update")
f.addStep(step.Compile, command=["make", "build"])
It is also possible to pass a list of step specifications into the
BuildFactory when it is created. Using addStep is
usually simpler, but there are cases where is is more convenient to
create the list of steps ahead of time. To make this approach easier,
a convenience function named s is available:
from buildbot.process import step, factory
from buildbot.factory import s
# s is a convenience function, defined with:
# def s(steptype, **kwargs): return (steptype, kwargs)
all_steps = [s(step.CVS, cvsroot=CVSROOT, cvsmodule="project", mode="update"),
s(step.Compile, command=["make", "build"]),
]
f = factory.BuildFactory(all_steps)
Each step can affect the build process in the following ways:
haltOnFailure attribute is True, then a failure
in the step (i.e. if it completes with a result of FAILURE) will cause
the whole build to be terminated immediately: no further steps will be
executed. This is useful for setup steps upon which the rest of the
build depends: if the CVS checkout or ./configure process
fails, there is no point in trying to compile or test the resulting
tree.
flunkOnFailure or flunkOnWarnings flag is set,
then a result of FAILURE or WARNINGS will mark the build as a whole as
FAILED. However, the remaining steps will still be executed. This is
appropriate for things like multiple testing steps: a failure in any
one of them will indicate that the build has failed, however it is
still useful to run them all to completion.
warnOnFailure or warnOnWarnings flag
is set, then a result of FAILURE or WARNINGS will mark the build as
having WARNINGS, and the remaining steps will still be executed. This
may be appropriate for certain kinds of optional build or test steps.
For example, a failure experienced while building documentation files
should be made visible with a WARNINGS result but not be serious
enough to warrant marking the whole build with a FAILURE.
In addition, each Step produces its own results, may create logfiles, etc. However only the flags described above have any effect on the build as a whole.
The pre-defined BuildSteps like CVS and Compile have
reasonably appropriate flags set on them already. For example, without
a source tree there is no point in continuing the build, so the
CVS class has the haltOnFailure flag set to True. Look
in buildbot/process/step.py to see how the other Steps are
marked.
Each Step is created with an additional workdir argument that
indicates where its actions should take place. This is specified as a
subdirectory of the slave builder's base directory, with a default
value of build. This is only implemented as a step argument (as
opposed to simply being a part of the base directory) because the
CVS/SVN steps need to perform their checkouts from the parent
directory.
Some attributes from the BuildFactory are copied into each Build.
useProgress
The difference between a “full build” and a “quick build” is that
quick builds are generally done incrementally, starting with the tree
where the previous build was performed. That simply means that the
source-checkout step should be given a mode='update' flag, to
do the source update in-place.
In addition to that, the useProgress flag should be set to
False. Incremental builds will (or at least the ought to) compile as
few files as necessary, so they will take an unpredictable amount of
time to run. Therefore it would be misleading to claim to predict how
long the build will take.
Many projects use one of a few popular build frameworks to simplify the creation and maintenance of Makefiles or other compilation structures. Buildbot provides several pre-configured BuildFactory subclasses which let you build these projects with a minimum of fuss.
GNU Autoconf is a software portability tool, intended to make it possible to write programs in C (and other languages) which will run on a variety of UNIX-like systems. Most GNU software is built using autoconf. It is frequently used in combination with GNU automake. These tools both encourage a build process which usually looks like this:
% CONFIG_ENV=foo ./configure --with-flags
% make all
% make check
# make install
(except of course the Buildbot always skips the make install
part).
The Buildbot's buildbot.process.factory.GNUAutoconf factory is
designed to build projects which use GNU autoconf and/or automake. The
configuration environment variables, the configure flags, and command
lines used for the compile and test are all configurable, in general
the default values will be suitable.
Example:
# use the s() convenience function defined earlier
f = factory.GNUAutoconf(source=s(step.SVN, svnurl=URL, mode="copy"),
flags=["--disable-nls"])
Required Arguments:
sourceOptional Arguments:
configure./configure. Accepts either a string or a list of shell argv
elements.
configureEnvCFLAGS="-O2 -g" (to turn off debug symbols during the compile).
Defaults to an empty dictionary.
configureFlags["--without-x"] to
disable windowing support. Defaults to an empty list.
compilemake all. If set to
None, the compile step is skipped.
testmake check. If set to
None, the test step is skipped.
Most Perl modules available from the CPAN
archive use the MakeMaker module to provide configuration,
build, and test services. The standard build routine for these modules
looks like:
% perl Makefile.PL
% make
% make test
# make install
(except again Buildbot skips the install step)
Buildbot provides a CPAN factory to compile and test these
projects.
Arguments:
sourceperlperl executable to use. Defaults
to just perl.
Most Python modules use the distutils package to provide
configuration and build services. The standard build process looks
like:
% python ./setup.py build
% python ./setup.py install
Unfortunately, although Python provides a standard unit-test framework
named unittest, to the best of my knowledge distutils
does not provide a standardized target to run such unit tests. (please
let me know if I'm wrong, and I will update this factory).
The Distutils factory provides support for running the build
part of this process. It accepts the same source= parameter as
the other build factories.
Arguments:
sourcepythonpython executable to use. Defaults
to just python.
test
Twisted provides a unit test tool named trial which provides a
few improvements over Python's built-in unittest module. Many
python projects which use Twisted for their networking or application
services also use trial for their unit tests. These modules are
usually built and tested with something like the following:
% python ./setup.py build
% PYTHONPATH=build/lib.linux-i686-2.3 trial -v PROJECTNAME.test
% python ./setup.py install
Unfortunately, the build/lib directory into which the
built/copied .py files are placed is actually architecture-dependent,
and I do not yet know of a simple way to calculate its value. For many
projects it is sufficient to import their libraries “in place” from
the tree's base directory (PYTHONPATH=.).
In addition, the PROJECTNAME value where the test files are
located is project-dependent: it is usually just the project's
top-level library directory, as common practice suggests the unit test
files are put in the test sub-module. This value cannot be
guessed, the Trial class must be told where to find the test
files.
The Trial class provides support for building and testing
projects which use distutils and trial. If the test module name is
specified, trial will be invoked. The library path used for testing
can also be set.
One advantage of trial is that the Buildbot happens to know how to parse trial output, letting it identify which tests passed and which ones failed. The Buildbot can then provide fine-grained reports about how many tests have failed, when individual tests fail when they had been passing previously, etc.
Another feature of trial is that you can give it a series of source
.py files, and it will search them for special test-case-name
tags that indicate which test cases provide coverage for that file.
Trial can then run just the appropriate tests. This is useful for
quick builds, where you want to only run the test cases that cover the
changed functionality.
Arguments:
sourcebuildpythonpython
executable to use when building the package. Defaults to just
['python']. It may be useful to add flags here, to supress
warnings during compilation of extension modules. This list is
extended with ['./setup.py', 'build'] and then executed in a
ShellCommand.
testpathPYTHONPATH when running the unit
tests, if tests are being run. Defaults to . to include the
project files in-place. The generated build library is frequently
architecture-dependent, but may simply be build/lib for
pure-python modules.
trialpythontrial argument
below. It may be useful to add -W flags here to supress
warnings that occur while tests are being run. Defaults to an empty
list, meaning trial will be run without an explicit
interpreter, which is generally what you want if you're using
/usr/bin/trial instead of, say, the ./bin/trial that
lives in the Twisted source tree.
trialtrial command. It is occasionally
useful to use an alternate executable, such as trial2.2 which
might run the tests under an older version of Python. Defaults to
trial.
testsPROJECTNAME.test, or a
list of strings. Defaults to None, indicating that no tests should be
run. You must either set this or useTestCaseNames to do anyting
useful with the Trial factory.
useTestCaseNamesrandomlyTrue, tells Trial (with the --random=0 argument) to
run the test cases in random order, which sometimes catches subtle
inter-test dependency bugs. Defaults to False.
recurseTrue, tells Trial (with the --recurse argument) to
look in all subdirectories for additional test cases. It isn't clear
to me how this works, but it may be useful to deal with the
unknown-PROJECTNAME problem described above, and is currently used in
the Twisted buildbot to accomodate the fact that test cases are now
distributed through multiple twisted.SUBPROJECT.test directories.
Unless one of trialModule or useTestCaseNames
are set, no tests will be run.
Some quick examples follow. Most of these examples assume that the target python code (the “code under test”) can be reached directly from the root of the target tree, rather than being in a lib/ subdirectory.
# Trial(source, tests="toplevel.test") does:
# python ./setup.py build
# PYTHONPATH=. trial -to toplevel.test
# Trial(source, tests=["toplevel.test", "other.test"]) does:
# python ./setup.py build
# PYTHONPATH=. trial -to toplevel.test other.test
# Trial(source, useTestCaseNames=True) does:
# python ./setup.py build
# PYTHONPATH=. trial -to --testmodule=foo/bar.py.. (from Changes)
# Trial(source, buildpython=["python2.3", "-Wall"], tests="foo.tests"):
# python2.3 -Wall ./setup.py build
# PYTHONPATH=. trial -to foo.tests
# Trial(source, trialpython="python2.3", trial="/usr/bin/trial",
# tests="foo.tests") does:
# python2.3 -Wall ./setup.py build
# PYTHONPATH=. python2.3 /usr/bin/trial -to foo.tests
# For running trial out of the tree being tested (only useful when the
# tree being built is Twisted itself):
# Trial(source, trialpython=["python2.3", "-Wall"], trial="./bin/trial",
# tests="foo.tests") does:
# python2.3 -Wall ./setup.py build
# PYTHONPATH=. python2.3 -Wall ./bin/trial -to foo.tests
If the output directory of ./setup.py build is known, you can
pull the python code from the built location instead of the source
directories. This should be able to handle variations in where the
source comes from, as well as accomodating binary extension modules:
# Trial(source,tests="toplevel.test",testpath='build/lib.linux-i686-2.3')
# does:
# python ./setup.py build
# PYTHONPATH=build/lib.linux-i686-2.3 trial -to toplevel.test
More details are available in the docstrings for each class, use
pydoc buildbot.status.html.Waterfall to see them. Most status
delivery objects take a categories= argument, which can contain
a list of “category” names: in this case, it will only show status
for Builders that are in one of the named categories.
(implementor's note: each of these objects should be a
service.MultiService which will be attached to the BuildMaster object
when the configuration is processed. They should use
self.parent.getStatus() to get access to the top-level IStatus
object, either inside startService or later. They may call
status.subscribe() in startService to receive
notifications of builder events, in which case they must define
builderAdded and related methods. See the docstrings in
buildbot/interfaces.py for full details.)
from buildbot.status import html
w = html.Waterfall(http_port=8080)
c['status'].append(w)
The buildbot.status.html.Waterfall status target creates an
HTML “waterfall display”, which shows a time-based chart of events.
This display provides detailed information about all steps of all
recent builds, and provides hyperlinks to look at individual build
logs and source changes. If the http_port argument is provided,
it provides a strports specification for the port that the web server
should listen on. This can be a simple port number, or a string like
tcp:8080:interface=127.0.0.1 (to limit connections to the
loopback interface, and therefore to clients running on the same
host)9.
If instead (or in addition) you provide the distrib_port
argument, a twisted.web distributed server will be started either on a
TCP port (if distrib_port is like "tcp:12345") or more
likely on a UNIX socket (if distrib_port is like
"unix:/path/to/socket").
The distrib_port option means that, on a host with a
suitably-configured twisted-web server, you do not need to consume a
separate TCP port for the buildmaster's status web page. When the web
server is constructed with mktap web --user, URLs that point to
http://host/~username/ are dispatched to a sub-server that is
listening on a UNIX socket at ~username/.twisted-web-pb. On
such a system, it is convenient to create a dedicated buildbot
user, then set distrib_port to
"unix:"+os.path.expanduser("~/.twistd-web-pb"). This
configuration will make the HTML status page available at
http://host/~buildbot/ . Suitable URL remapping can make it
appear at http://host/buildbot/, and the right virtual host
setup can even place it at http://buildbot.host/ .
Other arguments:
allowForcefaviconfavicon.ico file,
and should point to a .png or .ico image file. The default value uses
the buildbot/buildbot.png image (a small hex nut) contained in the
buildbot distribution. You can set this to None to avoid using a
favicon at all.
robots_txt User-agent: *
Disallow: /
will prevent most search engines from trawling the (voluminous) generated status pages.
The buildbot.status.words.IRC status target creates an IRC bot
which will attach to certain channels and be available for status
queries. It can also be asked to announce builds as they occur, or be
told to shut up.
from twisted.status import words
irc = words.IRC("irc.example.org", "botnickname",
channels=["channel1", "channel2"],
password="mysecretpassword")
c['status'].append(irc)
Take a look at the docstring for words.IRC for more details on
configuring this service. The password argument, if provided,
will be sent to Nickserv to claim the nickname: some IRC servers will
not allow clients to send private messages until they have logged in
with a password.
To use the service, you address messages at the buildbot, either
normally (botnickname: status) or with private messages
(/msg botnickname status). The buildbot will respond in kind.
Some of the commands currently available:
list buildersstatus BUILDERstatus allwatch BUILDERlast BUILDERhelp COMMANDhelp commands to get a list of known
commands.
sourceversionIf the allowForce=True option was used, some addtional commands
will be available:
force build BUILDER REASONstop build BUILDER REASON import buildbot.status.client
pbl = buildbot.status.client.PBListener(port=int, user=str,
passwd=str)
c['status'].append(pbl)
This sets up a PB listener on the given TCP port, to which a PB-based
status client can connect and retrieve status information.
buildbot statusgui (see statusgui) is an example of such a
status client. The port argument can also be a strports
specification string.
TODO: this needs a lot more examples
Each status plugin is an object which provides the
twisted.application.service.IService interface, which creates a
tree of Services with the buildmaster at the top [not strictly true].
The status plugins are all children of an object which implements
buildbot.interfaces.IStatus, the main status object. From this
object, the plugin can retrieve anything it wants about current and
past builds. It can also subscribe to hear about new and upcoming
builds.
Status plugins which only react to human queries (like the Waterfall display) never need to subscribe to anything: they are idle until someone asks a question, then wake up and extract the information they need to answer it, then they go back to sleep. Plugins which need to act spontaneously when builds complete (like the Mail plugin) need to subscribe to hear about new builds.
If the status plugin needs to run network services (like the HTTP
server used by the Waterfall plugin), they can be attached as Service
children of the plugin itself, using the IServiceCollection
interface.
The buildbot command-line tool can be used to start or stop a buildmaster or buildbot, and to interact with a running buildmaster. Some of its subcommands are intended for buildmaster admins, while some are for developers who are editing the code that the buildbot is monitoring.
The following buildbot sub-commands are intended for buildmaster administrators:
This creates a new directory and populates it with files that allow it to be used as a buildmaster's base directory.
buildbot create-master BASEDIR
This creates a new directory and populates it with files that let it be used as a buildslave's base directory. You must provide several arguments, which are used to create the initial buildbot.tac file.
buildbot create-slave BASEDIR MASTERHOST:PORT SLAVENAME PASSWORD
This starts a buildmaster or buildslave which was already created in the given base directory. The daemon is launched in the background, with events logged to a file named twistd.log.
buildbot start BASEDIR
This terminates the daemon (either buildmaster or buildslave) running in the given directory.
buildbot stop BASEDIR
This sends a SIGHUP to the buildmaster running in the given directory, which causes it to re-read its master.cfg file.
buildbot sighup BASEDIR
These tools are provided for use by the developers who are working on the code that the buildbot is monitoring.
buildbot statuslog --master MASTERHOST:PORT
This command starts a simple text-based status client, one which just prints out a new line each time an event occurs on the buildmaster.
The --master option provides the location of the
client.PBListener status port, used to deliver build
information to realtime status clients. The option is always in the
form of a string, with hostname and port number separated by a colon
(HOSTNAME:PORTNUM). Note that this port is not the same
as the slaveport (although a future version may allow the same port
number to be used for both purposes).
The --master option can also be provided by the
masterstatus name in .buildbot/options (see .buildbot config directory).
If you have set up a PBListener (see PBListener), you will be able
to monitor your Buildbot using a simple Gtk+ application invoked with
the buildbot statusgui command:
buildbot statusgui --master MASTERHOST:PORT
This command starts a simple Gtk+-based status client, which contains a few boxes for each Builder that change color as events occur. It uses the same --master argument as the buildbot statuslog command (see statuslog).
This lets a developer to ask the question “What would happen if I committed this patch right now?”. It runs the unit test suite (across multiple build platforms) on the developer's current code, allowing them to make sure they will not break the tree when they finally commit their changes.
The buildbot try command is meant to be run from within a developer's local tree, and starts by figuring out the base revision of that tree (what revision was current the last time the tree was updated), and a patch that can be applied to that revision of the tree to make it match the developer's copy. This (revision, patch) pair is then sent to the buildmaster, which runs a build with that SourceStamp. If you want, the tool will emit status messages as the builds run, and will not terminate until the first failure has been detected (or the last success).
For this command to work, several pieces must be in place:
The buildmaster must have a scheduler.Try instance in
the config file's c['schedulers'] list. This lets the
administrator control who may initiate these “trial” builds, which
branches are eligible for trial builds, and which Builders should be
used for them.
The TryScheduler has various means to accept build requests:
all of them enforce more security than the usual buildmaster ports do.
Any source code being built can be used to compromise the buildslave
accounts, but in general that code must be checked out from the VC
repository first, so only people with commit privileges can get
control of the buildslaves. The usual force-build control channels can
waste buildslave time but do not allow arbitrary commands to be
executed by people who don't have those commit privileges. However,
the source code patch that is provided with the trial build does not
have to go through the VC system first, so it is important to make
sure these builds cannot be abused by a non-committer to acquire as
much control over the buildslaves as a committer has. Ideally, only
developers who have commit access to the VC repository would be able
to start trial builds, but unfortunately the buildmaster does not, in
general, have access to VC system's user list.
As a result, the TryScheduler requires a bit more
configuration. There are currently two ways to set this up:
buildbot try command creates
a special file containing the source stamp information and drops it in
the jobdir, just like a standard maildir. When the buildmaster notices
the new file, it unpacks the information inside and starts the builds.
The config file entries used by 'buildbot try' either specify a local queuedir (for which write and mv are used) or a remote one (using scp and ssh).
The advantage of this scheme is that it is quite secure, the disadvantage is that it requires fiddling outside the buildmaster config (to set the permissions on the jobdir correctly). If the buildmaster machine happens to also house the VC repository, then it can be fairly easy to keep the VC userlist in sync with the trial-build userlist. If they are on different machines, this will be much more of a hassle. It may also involve granting developer accounts on a machine that would not otherwise require them.
To implement this, the buildslave invokes 'ssh -l username host
buildbot tryserver ARGS', passing the patch contents over stdin. The
arguments must include the inlet directory and the revision
information.
buildbot try, their machine connects to the
buildmaster via PB and authenticates themselves using that username
and password, then sends a PB command to start the trial build.
The advantage of this scheme is that the entire configuration is performed inside the buildmaster's config file. The disadvantages are that it is less secure (while the “cred” authentication system does not expose the password in plaintext over the wire, it does not offer most of the other security properties that SSH does). In addition, the buildmaster admin is responsible for maintaining the username/password list, adding and deleting entries as developers come and go.
For example, to set up the “jobdir” style of trial build, using a
command queue directory of MASTERDIR/jobdir (and assuming that
all your project developers were members of the developers unix
group), you would first create that directory (with mkdir
MASTERDIR/jobdir MASTERDIR/jobdir/new MASTERDIR/jobdir/cur
MASTERDIR/jobdir/tmp; chgrp developers MASTERDIR/jobdir
MASTERDIR/jobdir/*; chmod g+rwx,o-rwx MASTERDIR/jobdir
MASTERDIR/jobdir/*), and then use the following scheduler in the
buildmaster's config file:
from buildbot.scheduler import Try_Jobdir
s = Try_Jobdir("try1", ["full-linux", "full-netbsd", "full-OSX"],
jobdir="jobdir")
c['schedulers'] = [s]
Note that you must create the jobdir before telling the buildmaster to use this configuration, otherwise you will get an error. Also remember that the buildmaster must be able to read and write to the jobdir as well. Be sure to watch the twistd.log file (see Logfiles) as you start using the jobdir, to make sure the buildmaster is happy with it.
To use the username/password form of authentication, create a
Try_Userpass instance instead. It takes the same
builderNames argument as the Try_Jobdir form, but
accepts an addtional port argument (to specify the TCP port to
listen on) and a userpass list of username/password pairs to
accept. Remember to use good passwords for this: the security of the
buildslave accounts depends upon it:
from buildbot.scheduler import Try_Userpass
s = Try_Userpass("try2", ["full-linux", "full-netbsd", "full-OSX"],
port=8031, userpass=[("alice","pw1"), ("bob", "pw2")] )
c['schedulers'] = [s]
Like most places in the buildbot, the port argument takes a
strports specification. See twisted.application.strports for
details.
The try command needs to be told how to connect to the
TryScheduler, and must know which of the authentication
approaches described above is in use by the buildmaster. You specify
the approach by using --connect=ssh or --connect=pb
(or try_connect = 'ssh' or try_connect = 'pb' in
.buildbot/options).
For the PB approach, the command must be given a --master
argument (in the form HOST:PORT) that points to TCP port that you
picked in the Try_Userpass scheduler. It also takes a
--username and --passwd pair of arguments that match
one of the entries in the buildmaster's userpass list. These
arguments can also be provided as try_master,
try_username, and try_password entries in the
.buildbot/options file.
For the SSH approach, the command must be given --tryhost,
--username, and optionally --password (TODO:
really?) to get to the buildmaster host. It must also be given
--trydir, which points to the inlet directory configured
above. The trydir can be relative to the user's home directory, but
most of the time you will use an explicit path like
~buildbot/project/trydir. These arguments can be provided in
.buildbot/options as try_host, try_username,
try_password, and try_dir.
In addition, the SSH approach needs to connect to a PBListener status
port, so it can retrieve and report the results of the build (the PB
approach uses the existing connection to retrieve status information,
so this step is not necessary). This requires a --master
argument, or a masterstatus entry in .buildbot/options,
in the form of a HOSTNAME:PORT string.
A trial build is performed on multiple Builders at the same time, and
the developer gets to choose which Builders are used (limited to a set
selected by the buildmaster admin with the TryScheduler's
builderNames= argument). The set you choose will depend upon
what your goals are: if you are concerned about cross-platform
compatibility, you should use multiple Builders, one from each
platform of interest. You might use just one builder if that platform
has libraries or other facilities that allow better test coverage than
what you can accomplish on your own machine, or faster test runs.
The set of Builders to use can be specified with multiple
--builder arguments on the command line. It can also be
specified with a single try_builders option in
.buildbot/options that uses a list of strings to specify all
the Builder names:
try_builders = ["full-OSX", "full-win32", "full-linux"]
The try command also needs to know how to take the
developer's current tree and extract the (revision, patch)
source-stamp pair. Each VC system uses a different process, so you
start by telling the try command which VC system you are
using, with an argument like --vc=cvs or --vc=tla.
This can also be provided as try_vc in
.buildbot/options.
The following names are recognized: cvs svn baz
tla hg darcs
Some VC systems (notably CVS and SVN) track each directory
more-or-less independently, which means the try command
needs to move up to the top of the project tree before it will be able
to construct a proper full-tree patch. To accomplish this, the
try command will crawl up through the parent directories
until it finds a marker file. The default name for this marker file is
.buildbot-top, so when you are using CVS or SVN you should
touch .buildbot-top from the top of your tree before running
buildbot try. Alternatively, you can use a filename like
ChangeLog or README, since many projects put one of
these files in their top-most directory (and nowhere else). To set
this filename, use --try-topfile=ChangeLog, or set it in the
options file with try_topfile = 'ChangeLog'.
You can also manually set the top of the tree with
--try-topdir=~/trees/mytree, or try_topdir =
'~/trees/mytree'. If you use try_topdir, in a
.buildbot/options file, you will need a separate options file
for each tree you use, so it may be more convenient to use the
try_topfile approach instead.
Other VC systems which work on full projects instead of individual directories (tla, baz, darcs, monotone, mercurial) do not require try to know the top directory, so the --try-topfile and --try-topdir arguments will be ignored.
If the try command cannot find the top directory, it will abort with an error message.
Some VC systems record the branch information in a way that “try” can locate it, in particular Arch (both tla and baz). For the others, if you are using something other than the default branch, you will have to tell the buildbot which branch your tree is using. You can do this with either the --branch argument, or a try_branch entry in the .buildbot/options file.
Each VC system has a separate approach for determining the tree's base revision and computing a patch.
CVS-D time specification, uses it as the base
revision, and computes the diff between the upstream tree as of that
point in time versus the current contents. This works, more or less,
but requires that the local clock be in reasonably good sync with the
repository.
SVNsvn status -u to find the latest
repository revision number (emitted on the last line in the “Status
against revision: NN” message). It then performs an svn diff
-rNN to find out how your tree differs from the repository version,
and sends the resulting patch to the buildmaster. If your tree is not
up to date, this will result in the “try” tree being created with
the latest revision, then backwards patches applied to bring it
“back” to the version you actually checked out (plus your actual
code changes), but this will still result in the correct tree being
used for the build.
bazbaz tree-id to determine the
fully-qualified version and patch identifier for the tree
(ARCHIVE/VERSION–patch-NN), and uses the VERSION–patch-NN component
as the base revision. It then does a baz diff to obtain the
patch.
tlatla tree-version to get the
fully-qualified version identifier (ARCHIVE/VERSION), then takes the
first line of tla logs --reverse to figure out the base
revision. Then it does tla changes --diffs to obtain the patch.
Darcsdarcs changes --context emits a text file that contains a list
of all patches back to and including the last tag was made. This text
file (plus the location of a repository that contains all these
patches) is sufficient to re-create the tree. Therefore the contents
of this “context” file are the revision stamp for a
Darcs-controlled source tree.
So try does a darcs changes --context to determine
what your tree's base revision is, and then does a darcs diff
-u to compute the patch relative to that revision.
Mercurialhg identify emits a short revision ID (basically a truncated
SHA1 hash of the current revision's contents), which is used as the
base revision. hg diff then provides the patch relative to that
revision. For try to work, your working directory must only
have patches that are available from the same remotely-available
repository that the build process' step.Mercurial will use.
If you provide the --wait option (or try_wait = True
in .buildbot/options), the buildbot try command will
wait until your changes have either been proven good or bad before
exiting. Unless you use the --quiet option (or
try_quiet=True), it will emit a progress message every 60
seconds until the builds have completed.
These tools are generally used by buildmaster administrators.
This command is used to tell the buildmaster about source changes. It is intended to be used from within a commit script, installed on the VC server.
buildbot sendchange --master MASTERHOST:PORT --username USER FILENAMES..
There are other (optional) arguments which can influence the
Change that gets submitted:
--branch--revision_number--revision--revision_file--comments--logfile- as the filename, the tool will read the
change comments from stdin.
buildbot debugclient --master MASTERHOST:PORT --passwd DEBUGPW
This launches a small Gtk+/Glade-based debug tool, connecting to the
buildmaster's “debug port”. This debug port shares the same port
number as the slaveport (see Setting the slaveport), but the
debugPort is only enabled if you set a debug password in the
buildmaster's config file (see Debug options). The
--passwd option must match the c['debugPassword']
value.
--master can also be provided in .debug/options by the
master key. --passwd can be provided by the
debugPassword key.
The Connect button must be pressed before any of the other
buttons will be active. This establishes the connection to the
buildmaster. The other sections of the tool are as follows:
Reload .cfgRebuild .pypoke IRCwords.IRC status target and causes it to emit a
message on all the channels to which it is currently connected. This
was used to debug a problem in which the buildmaster lost the
connection to the IRC server and did not attempt to reconnect.
CommitForce BuildCurrentlyMany of the buildbot tools must be told how to contact the
buildmaster that they interact with. This specification can be
provided as a command-line argument, but most of the time it will be
easier to set them in an “options” file. The buildbot
command will look for a special directory named .buildbot,
starting from the current directory (where the command was run) and
crawling upwards, eventually looking in the user's home directory. It
will look for a file named options in this directory, and will
evaluate it as a python script, looking for certain names to be set.
You can just put simple name = 'value' pairs in this file to
set the options.
For a description of the names used in this file, please see the documentation for the individual buildbot sub-commands. The following is a brief sample of what this file's contents could be.
# for status-reading tools
masterstatus = 'buildbot.example.org:12345'
# for 'sendchange' or the debug port
master = 'buildbot.example.org:18990'
debugPassword = 'eiv7Po'
masterstatusclient.PBListener status port, used by
statuslog and statusgui.
masterdebugPort (for debugclient). Also the
location of the pb.PBChangeSource (for sendchange).
Usually shares the slaveport, but a future version may make it
possible to have these listen on a separate port number.
debugPasswordc['debugPassword'], used to protect the
debug port, for the debugclient command.
usernameThe Buildbot's home page is at http://buildbot.sourceforge.net/
For configuration questions and general discussion, please use the
buildbot-devel mailing list. The subscription instructions and
archives are available at
http://lists.sourceforge.net/lists/listinfo/buildbot-devel
This appendix contains random notes about the implementation of the Buildbot, and is likely to only be of use to people intending to extend the Buildbot's internals.
The buildmaster consists of a tree of Service objects, which is shaped as follows:
BuildMaster
ChangeMaster (in .change_svc)
[IChangeSource instances]
[IScheduler instances] (in .schedulers)
BotMaster (in .botmaster)
[IStatusTarget instances] (in .statusTargets)
The BotMaster has a collection of Builder objects as values of its
.builders dictionary.
This is a list of all user-visible classes. There are the ones that are useful in master.cfg, the buildmaster's configuration file. Classes that are not listed here are generally internal things that admins are unlikely to have much use for.
buildbot.changes.freshcvs.FreshCVSSource: CVSToys - PBServicebuildbot.changes.mail.BonsaiMaildirSource: Other mail notification ChangeSourcesbuildbot.changes.mail.FCMaildirSource: CVSToys - mail notificationbuildbot.changes.mail.SyncmailMaildirSource: Other mail notification ChangeSourcesbuildbot.changes.p4poller.P4Source: P4Sourcebuildbot.changes.pb.PBChangeSource: PBChangeSourcebuildbot.locks.MasterLock: Interlocksbuildbot.locks.SlaveLock: Interlocksbuildbot.scheduler.AnyBranchScheduler: Scheduler Typesbuildbot.scheduler.Dependent: Build Dependenciesbuildbot.scheduler.Nightly: Scheduler Typesbuildbot.scheduler.Periodic: Scheduler Typesbuildbot.scheduler.Scheduler: Scheduler Typesbuildbot.scheduler.Try_Jobdir: trybuildbot.scheduler.Try_Userpass: trybuildbot.process.factory.BasicBuildFactory: BuildFactorybuildbot.process.factory.BasicSVN: BuildFactorybuildbot.process.factory.BuildFactory: BuildFactorybuildbot.process.factory.CPAN: CPANbuildbot.process.factory.Distutils: Python distutilsbuildbot.process.factory.GNUAutoconf: GNUAutoconfbuildbot.process.factory.QuickBuildFactory: Quick buildsbuildbot.process.factory.Trial: Python/Twisted/trial projectsbuildbot.process.maxq.MaxQ: Index of Useful Classesbuildbot.process.step.Arch: Archbuildbot.process.step.Bazaar: Bazaarbuildbot.process.step.Compile: Compilebuildbot.process.step.Configure: Configurebuildbot.process.step.CVS: CVSbuildbot.process.step.Darcs: Darcsbuildbot.process.step.Git: Index of Useful Classesbuildbot.process.step.Mercurial: Mercurialbuildbot.process.step.P4: P4buildbot.process.step.ShellCommand: ShellCommandbuildbot.process.step.SVN: SVNbuildbot.process.step.Test: Testbuildbot.process.step_twisted.BuildDebs: Python/Twisted/trial projectsbuildbot.process.step_twisted.HLint: Python/Twisted/trial projectsbuildbot.process.step_twisted.ProcessDocs: Python/Twisted/trial projectsbuildbot.process.step_twisted.RemovePYCs: Python/Twisted/trial projectsbuildbot.process.step_twisted.Trial: Python/Twisted/trial projectsbuildbot.status.client.PBListener: PBListenerbuildbot.status.html.Waterfall: HTML Waterfallbuildbot.status.mail.MailNotifier: Index of Useful Classesbuildbot.status.words.IRC: IRC BotThis is a list of all of the significant keys in master.cfg . Recall
that master.cfg is effectively a small python program one
responsibility: create a dictionary named BuildmasterConfig.
The keys of this dictionary are listed here. The beginning of the
master.cfg file typically starts with something like:
BuildmasterConfig = c = {}
Therefore a config key of sources will usually appear in
master.cfg as c['sources'].
c['bots']: Buildslave Specifiersc['buildbotURL']: Defining the Projectc['builders']: Defining Buildersc['debugPassword']: Debug optionsc['manhole']: Debug optionsc['projectName']: Defining the Projectc['projectURL']: Defining the Projectc['schedulers']: Listing Change Sources and Schedulersc['slavePortnum']: Setting the slaveportc['sources']: Listing Change Sources and Schedulersc['status']: Defining Status Targets[1] this @reboot syntax is understood by Vixie cron, which is the flavor usually provided with linux systems. Other unices may have a cron that doesn't understand @reboot
[2] except Darcs, but since the Buildbot never modifies its local source tree we can ignore the fact that Darcs uses a less centralized model
[3] many VC systems provide more complexity than this: in particular the local views that P4 and ClearCase can assemble out of various source directories are more complex than we're prepared to take advantage of here
[4] Monotone's multiple heads feature violates this assumption of cumulative Changes, but in most situations the changes don't occur frequently enough for this to be a significant problem
[5] this checkoutDelay defaults
to half the tree-stable timer, but it can be overridden with an
argument to the Source Step
[6] To be precise, it is a list of objects which all
implement the buildbot.interfaces.IChangeSource Interface
[7] Build properties are serialized along with the build results, so they must be serializable. For this reason, the value of any build property should be simple inert data: strings, numbers, lists, tuples, and dictionaries. They should not contain class instances.
[8] Also note that a clever buildmaster admin could still create the opportunity for deadlock: Build A obtains Lock 1, inside which Step A.two tries to acquire Lock 2 at the Step level. Meanwhile Build B obtains Lock 2, and has a Step B.two which wants to acquire Lock 1 at the Step level. Don't Do That.
[9] It may even be possible to provide SSL access by using
a specification like
"ssl:12345:privateKey=mykey.pen:certKey=cert.pem", but this is
completely untested