This is the Buildbot documentation for Buildbot version 4.3.0.
If you are evaluating Buildbot and would like to get started quickly, start with the Tutorial. Regular users of Buildbot should consult the Manual, and those wishing to modify Buildbot directly will want to be familiar with the Developer’s Documentation.
Table Of Contents
1. Buildbot Tutorial
Contents:
1.1. First Run
1.1.1. Goal
This tutorial will take you from zero to running your first buildbot master and worker as quickly as possible, without changing the default configuration.
This tutorial is all about instant gratification and the five minute experience: in five minutes we want to convince you that this project works, and that you should seriously consider spending time learning the system. In this tutorial no configuration or code changes are done.
This tutorial assumes that you are running Unix, but might be adaptable to Windows.
Thanks to virtualenv, installing buildbot in a standalone environment is very easy. For those more familiar with Docker, there also exists a docker version of these instructions.
You should be able to cut and paste each shell block from this tutorial directly into a terminal.
1.1.2. Simple introduction to BuildBot
Before trying to run BuildBot it’s helpful to know what BuildBot is.
BuildBot is a continuous integration framework written in Python. It consists of a master daemon and potentially many worker daemons that usually run on other machines. The master daemon runs a web server that allows the end user to start new builds and to control the behaviour of the BuildBot instance. The master also distributes builds to the workers. The worker daemons connect to the master daemon and execute builds whenever master tells them to do so.
In this tutorial we will run a single master and a single worker on the same machine.
A more thorough explanation can be found in the manual section of the Buildbot documentation.
1.1.3. Getting ready
There are many ways to get the code on your machine.
We will use the easiest one: via pip in a virtualenv.
It has the advantage of not polluting your operating system, as everything will be contained in the virtualenv.
To make this work, you will need the following installed:
Python and the development packages for it
Preferably, use your distribution package manager to install these.
You will also need a working Internet connection, as virtualenv and pip will need to download other
projects from the Internet. The master and builder daemons will need to be able to connect to
github.com via HTTPS to fetch the repo we’re testing.
If you need to use a proxy for this ensure that either the HTTPS_PROXY or ALL_PROXY
environment variable is set to your proxy, e.g., by executing export
HTTPS_PROXY=http://localhost:9080 in the shell before starting each daemon.
Note
Buildbot does not require root access. Run the commands in this tutorial as a normal, unprivileged user.
1.1.4. Creating a master
The first necessary step is to create a virtualenv for our master. We first create a separate directory to demonstrate the distinction between a master and worker:
mkdir -p ~/buildbot-test/master_root
cd ~/buildbot-test/master_root
Then we create the virtual environment. On Python 3:
python3 -m venv sandbox
source sandbox/bin/activate
Next, we need to install several build dependencies to make sure we can install buildbot and its supporting packages. These build dependencies are:
GCC build tools (
gccfor RHEL/CentOS/Fedora based distributions, orbuild-essentialfor Ubuntu/Debian based distributions).Python development library (
python3-develfor RHEL/CentOS/Fedora based distributions, orpython3-devfor Ubuntu/Debian based distributions).OpenSSL development library (
openssl-develfor RHEL/CentOS/Fedora based distributions, orlibssl-devfor Ubuntu/Debian based distributions).libffi development library (
libffi-develfor RHEL/CentOS/Fedora based distributions, orlibffi-devfor Ubuntu/Debian based distributions).
Install these build dependencies:
# if in Ubuntu/Debian based distributions:
sudo apt-get install build-essential python3-dev libssl-dev libffi-dev
# if in RHEL/CentOS/Fedora based distributions:
sudo yum install gcc python3-devel openssl-devel libffi-devel
or refer to your distribution’s documentation on how to install these packages.
Now that we are ready, we need to install buildbot:
pip install --upgrade pip
pip install 'buildbot[bundle]'
Now that buildbot is installed, it’s time to create the master.
my_master represents a path to a directory, where future master will be created:
buildbot create-master my_master
Buildbot’s activity is controlled by a configuration file. Buildbot by default uses configuration
from file at master.cfg, but its installation comes with a sample configuration file named
master.cfg.sample. We will use the sample configuration file unchanged, but we have to rename
it to master.cfg:
mv my_master/master.cfg.sample my_master/master.cfg
Finally, start the master:
buildbot start my_master
You will now see some log information from the master in this terminal. It should end with lines like these:
2014-11-01 15:52:55+0100 [-] BuildMaster is running
The buildmaster appears to have (re)started correctly.
From now on, feel free to visit the web status page running on the port 8010: http://localhost:8010/
Our master now needs (at least) one worker to execute its commands. For that, head on to the next section!
1.1.5. Creating a worker
The worker will be executing the commands sent by the master. In this tutorial, we are using the buildbot/hello-world project as an example. As a consequence of this, your worker will need access to the git command in order to checkout some code. Be sure that it is installed, or the builds will fail.
Same as we did for our master, we will create a virtualenv for our worker next to the master’s one. It would however be completely ok to do this on another computer - as long as the worker computer is able to connect to the master’s . We first create a new directory for the worker:
mkdir -p ~/buildbot-test/worker_root
cd ~/buildbot-test/worker_root
Again, we create a virtual environment. On Python 3:
python3 -m venv sandbox
source sandbox/bin/activate
Install the buildbot-worker command:
pip install --upgrade pip
pip install buildbot-worker
# required for `runtests` build
pip install setuptools-trial
Now, create the worker:
buildbot-worker create-worker my_worker localhost example-worker pass
Note
If you decided to create this from another computer, you should replace localhost with the
name of the computer where your master is running.
The username (example-worker), and password (pass) should be the same as those in
my_master/master.cfg; verify this is the case by looking at the section for
c['workers']:
cat ../master_root/my_master/master.cfg
And finally, start the worker:
buildbot-worker start my_worker
Check the worker’s output. It should end with lines like these:
2014-11-01 15:56:51+0100 [-] Connecting to localhost:9989
2014-11-01 15:56:51+0100 [Broker,client] message from master: attached
The worker appears to have (re)started correctly.
Meanwhile, from the other terminal, in the master log (twisted.log in the master
directory), you should see lines like these:
2014-11-01 15:56:51+0100 [Broker,1,127.0.0.1] worker 'example-worker' attaching from
IPv4Address(TCP, '127.0.0.1', 54015)
2014-11-01 15:56:51+0100 [Broker,1,127.0.0.1] Got workerinfo from 'example-worker'
2014-11-01 15:56:51+0100 [-] bot attached
1.1.6. Wrapping up
Your directory tree now should look like this:
~/buildbot-test/master_root/my_master # master base directory
~/buildbot-test/master_root/sandbox # virtualenv for master
~/buildbot-test/worker_root/my_worker # worker base directory
~/buildbot-test/worker_root/sandbox # virtualenv for worker
You should now be able to go to http://localhost:8010, where you will see a web page similar to:
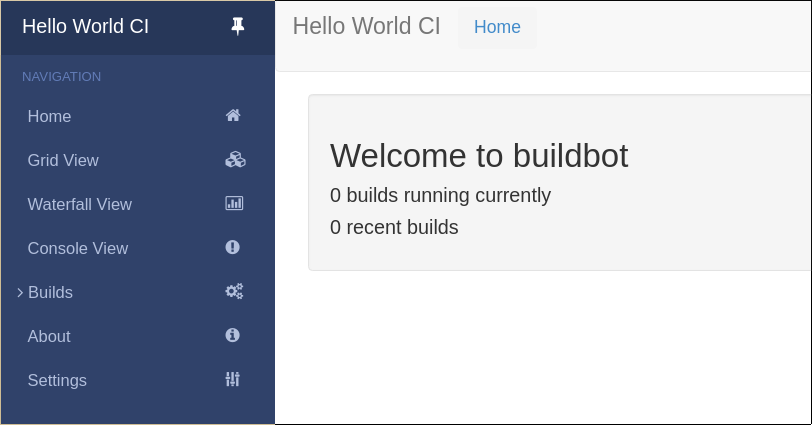
Click on “Builds” at the left to open the submenu and then Builders to see that the worker you just started (identified by the green bubble) has connected to the master:
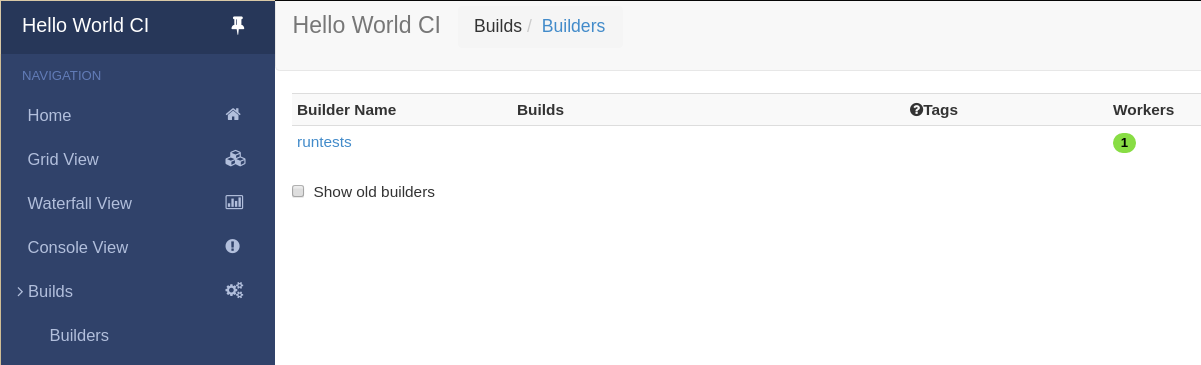
Your master is now quietly waiting for new commits to hello-world. This doesn’t happen very often though. In the next section, we’ll see how to manually start a build.
We just wanted to get you to dip your toes in the water. It’s easy to take your first steps, but this is about as far as we can go without touching the configuration.
You’ve got a taste now, but you’re probably curious for more. Let’s step it up a little in the second tutorial by changing the configuration and doing an actual build. Continue on to A Quick Tour.
1.2. A Quick Tour
1.2.1. Goal
This tutorial will expand on the First Run tutorial by taking a quick tour around some of the features of buildbot that are hinted at in the comments in the sample configuration. We will simply change parts of the default configuration and explain the activated features.
As a part of this tutorial, we will make buildbot do a few actual builds.
This section will teach you how to:
make simple configuration changes and activate them
deal with configuration errors
force builds
enable and control the IRC bot
add a ‘try’ scheduler
1.2.2. The First Build
On the Builders page, click on the runtests link. You’ll see a builder page, and a blue “force” button that will bring up the following dialog box:
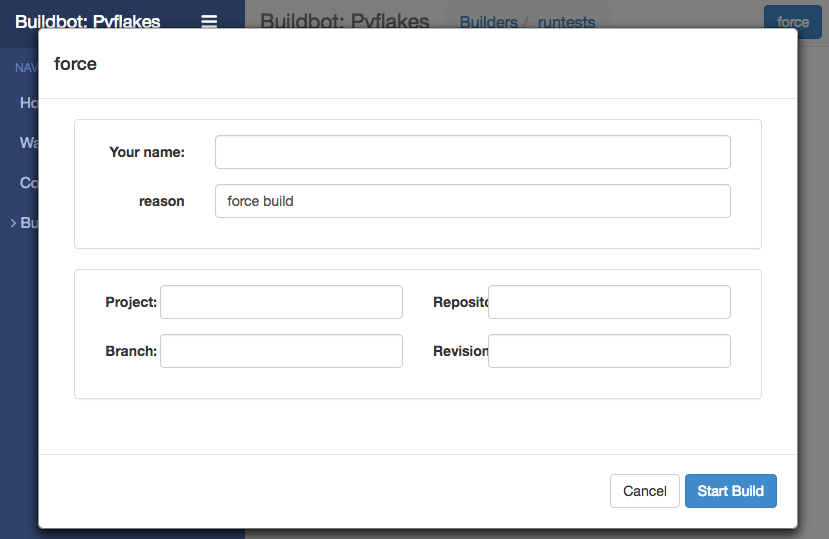
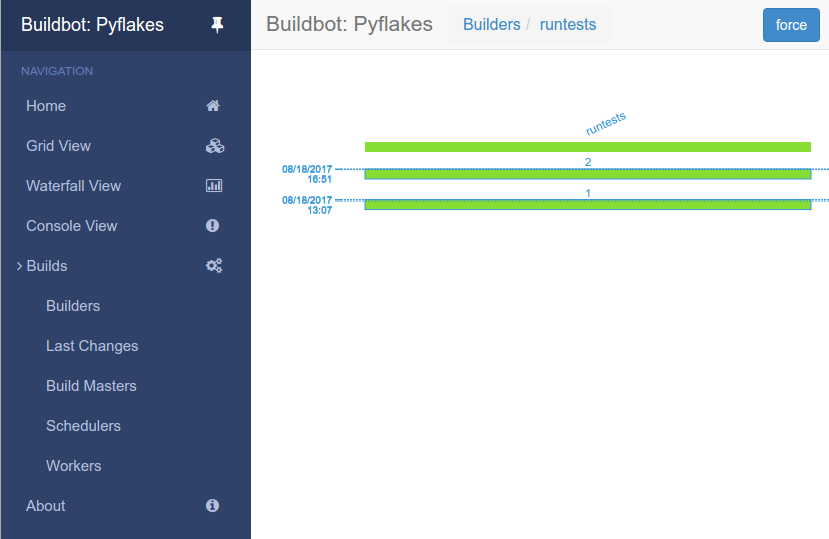
Click Start Build - there’s no need to fill in any of the fields in this case. Next, click on view in waterfall.
You will now see that a successful test run has happened:
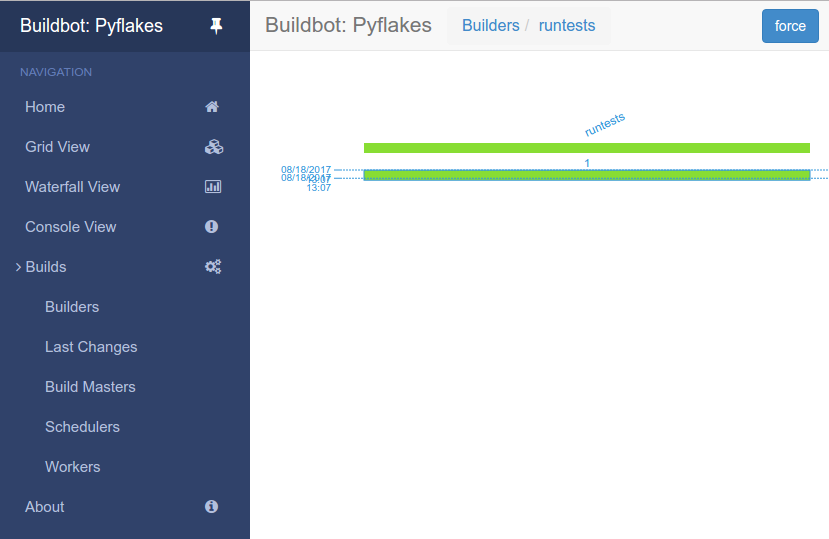
This simple process is essentially the whole purpose of the Buildbot project.
The information about what actions are executed for a certain build are defined in things called builders.
The information about when a certain builder should launch a build are defined in things called schedulers. In fact, the blue “force” button that was pushed in this example activated a scheduler too.
1.2.3. Setting Project Name and URL
Let’s start simple by looking at where you would customize the buildbot’s project name and URL.
We continue where we left off in the First Run tutorial.
Open a new terminal, go to the directory you created master in, activate the same virtualenv
instance you created before, and open the master configuration file with an editor (here
$EDITOR is your editor of choice like vim, gedit, or emacs):
cd ~/buildbot-test/master
source sandbox/bin/activate
$EDITOR master/master.cfg
Now, look for the section marked PROJECT IDENTITY which reads:
####### PROJECT IDENTITY
# the 'title' string will appear at the top of this buildbot installation's
# home pages (linked to the 'titleURL').
c['title'] = "Hello World CI"
c['titleURL'] = "https://buildbot.github.io/hello-world/"
If you want, you can change either of these links to anything you want so that you can see what happens when you change them.
After making a change, go to the terminal and type:
buildbot reconfig master
You will see a handful of lines of output from the master log, much like this:
2011-12-04 10:11:09-0600 [-] loading configuration from /path/to/buildbot/master.cfg
2011-12-04 10:11:09-0600 [-] configuration update started
2011-12-04 10:11:09-0600 [-] builder runtests is unchanged
2011-12-04 10:11:09-0600 [-] removing IStatusReceiver <...>
2011-12-04 10:11:09-0600 [-] (TCP Port 8010 Closed)
2011-12-04 10:11:09-0600 [-] Stopping factory <...>
2011-12-04 10:11:09-0600 [-] adding IStatusReceiver <...>
2011-12-04 10:11:09-0600 [-] RotateLogSite starting on 8010
2011-12-04 10:11:09-0600 [-] Starting factory <...>
2011-12-04 10:11:09-0600 [-] Setting up http.log rotating 10 files of 10000000 bytes each
2011-12-04 10:11:09-0600 [-] WebStatus using (/path/to/buildbot/public_html)
2011-12-04 10:11:09-0600 [-] removing 0 old schedulers, updating 0, and adding 0
2011-12-04 10:11:09-0600 [-] adding 1 new changesources, removing 1
2011-12-04 10:11:09-0600 [-] gitpoller: using workdir '/path/to/buildbot/gitpoller-workdir'
2011-12-04 10:11:09-0600 [-] GitPoller repository already exists
2011-12-04 10:11:09-0600 [-] configuration update complete
Reconfiguration appears to have completed successfully.
The important lines are the ones telling you that the new configuration is being loaded (at the top) and that the update is complete (at the bottom).
Now, if you go back to the waterfall page, you will see that the project’s name is whatever you may have changed it to, and when you click on the URL of the project name at the bottom of the page, it should take you to the link you put in the configuration.
1.2.4. Configuration Errors
It is very common to make a mistake when configuring buildbot, so you might as well see now what happens in that case and what you can do to fix the error.
Open up the config again and introduce a syntax error by removing the first single quote in the two lines you changed before, so they read:
c[title'] = "Hello World CI"
c[titleURL'] = "https://buildbot.github.io/hello-world/"
This creates a Python SyntaxError.
Now go ahead and reconfig the master:
buildbot reconfig master
This time, the output looks like:
2015-08-14 18:40:46+0000 [-] beginning configuration update
2015-08-14 18:40:46+0000 [-] Loading configuration from '/data/buildbot/master/master.cfg'
2015-08-14 18:40:46+0000 [-] error while parsing config file:
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/buildbot/master.py", line 265, in reconfig
d = self.doReconfig()
File "/usr/local/lib/python2.7/dist-packages/twisted/internet/defer.py", line 1274, in unwindGenerator
return _inlineCallbacks(None, gen, Deferred())
File "/usr/local/lib/python2.7/dist-packages/twisted/internet/defer.py", line 1128, in _inlineCallbacks
result = g.send(result)
File "/usr/local/lib/python2.7/dist-packages/buildbot/master.py", line 289, in doReconfig
self.configFileName)
--- <exception caught here> ---
File "/usr/local/lib/python2.7/dist-packages/buildbot/config.py", line 156, in loadConfig
exec f in localDict
exceptions.SyntaxError: EOL while scanning string literal (master.cfg, line 103)
2015-08-14 18:40:46+0000 [-] error while parsing config file: EOL while scanning string literal (master.cfg, line 103) (traceback in logfile)
2015-08-14 18:40:46+0000 [-] reconfig aborted without making any changes
Reconfiguration failed. Please inspect the master.cfg file for errors,
correct them, then try 'buildbot reconfig' again.
This time, it’s clear that there was a mistake in the configuration. Luckily, the Buildbot master will ignore the wrong configuration and keep running with the previous configuration.
The message is clear enough, so open the configuration again, fix the error, and reconfig the master.
1.2.5. Enabling the IRC Bot
Buildbot includes an IRC bot that you can tell to join a channel to control and report on the status of buildbot.
Note
Security Note
Please note that any user having access to your IRC channel, or can send a private message to the bot, will be able to create or stop builds bug #3377.
First, start an IRC client of your choice, connect to irc.freenode.net and join an empty channel.
In this example we will use #buildbot-test, so go join that channel.
(Note: please do not join the main buildbot channel!)
Edit master.cfg and look for the BUILDBOT SERVICES section.
At the end of that section add the lines:
c['services'].append(reporters.IRC(host="irc.freenode.net", nick="bbtest",
channels=["#buildbot-test"]))
The reconfigure the master and type:
grep -i irc master/twistd.log
The log output should contain a line like this:
2016-11-13 15:53:06+0100 [-] Starting factory <...>
2016-11-13 15:53:19+0100 [IrcStatusBot,client] <...>: I have joined #buildbot-test
You should see the bot now joining in your IRC client. In your IRC channel, type:
bbtest: commands
to get a list of the commands the bot supports.
Let’s tell the bot to notify on certain events. To learn on which EVENTS we can notify, type:
bbtest: help notify
Now, let’s set some event notifications:
<@lsblakk> bbtest: notify on started finished failure
< bbtest> The following events are being notified: ['started', 'failure', 'finished']
Now, go back to the web interface and force another build. Alternatively, ask the bot to force a build:
<@lsblakk> bbtest: force build --codebase= runtests
< bbtest> build #1 of runtests started
< bbtest> Hey! build runtests #1 is complete: Success [finished]
You can also see the new builds in the web interface.
The full documentation is available at IRC.
1.2.7. Adding a ‘try’ scheduler
Buildbot includes a way for developers to submit patches for testing without committing them to the source code control system. (This is really handy for projects that support several operating systems or architectures.)
To set this up, add the following lines to master.cfg:
from buildbot.scheduler import Try_Userpass
c['schedulers'] = []
c['schedulers'].append(Try_Userpass(
name='try',
builderNames=['runtests'],
port=5555,
userpass=[('sampleuser','samplepass')]))
Then you can submit changes using the try command.
Let’s try this out by making a one-line change to hello-world, say, to make it trace the tree by default:
git clone https://github.com/buildbot/hello-world.git hello-world-git
cd hello-world-git/hello
$EDITOR __init__.py
# change 'return "hello " + who' on line 6 to 'return "greets " + who'
Then run buildbot’s try command as follows:
cd ~/buildbot-test/master
source sandbox/bin/activate
buildbot try --connect=pb --master=127.0.0.1:5555 \
--username=sampleuser --passwd=samplepass --vc=git
This will do git diff for you and send the resulting patch to the server for build and test
against the latest sources from Git.
Now go back to the waterfall page, click on the runtests link, and scroll down. You should see that another build has been started with your change (and stdout for the tests should be chock-full of parse trees as a result). The “Reason” for the job will be listed as “‘try’ job”, and the blamelist will be empty.
To make yourself show up as the author of the change, use the --who=emailaddr option on
buildbot try to pass your email address.
To make a description of the change show up, use the --properties=comment="this is a comment"
option on buildbot try.
To use ssh instead of a private username/password database, see Try_Jobdir.
1.3. First Buildbot run with Docker
Note
Docker can be tricky to get working correctly if you haven’t used it before. If you’re having trouble, first determine whether it is a Buildbot issue or a Docker issue by running:
docker run ubuntu:20.04 apt-get update
If that fails, look for help with your Docker install. On the other hand, if that succeeds, then you may have better luck getting help from members of the Buildbot community.
Docker is a tool that makes building and deploying custom environments a breeze. It uses lightweight linux containers (LXC) and performs quickly, making it a great instrument for the testing community. The next section includes a Docker pre-flight check. If it takes more that 3 minutes to get the ‘Success’ message for you, try the Buildbot pip-based first run instead.
1.3.1. Current Docker dependencies
Linux system, with at least kernel 3.8 and AUFS support. For example, Standard Ubuntu, Debian and Arch systems.
Packages: lxc, iptables, ca-certificates, and bzip2 packages.
Local clock on time or slightly in the future for proper SSL communication.
This tutorial uses docker-compose to run a master, a worker, and a postgresql database server
1.3.2. Installation
Use the Docker installation instructions for your operating system.
Make sure you install docker-compose. As root or inside a virtualenv, run:
pip install docker-compose
Test docker is happy in your environment:
sudo docker run -i busybox /bin/echo Success
1.3.3. Building and running Buildbot
# clone the example repository
git clone --depth 1 https://github.com/buildbot/buildbot-docker-example-config
# Build the Buildbot container (it will take a few minutes to download packages)
cd buildbot-docker-example-config/simple
docker-compose up
You should now be able to go to http://localhost:8010 and see a web page similar to:
Click on “Builds” at the left to open the submenu and then Builders to see that the worker you just started has connected to the master:
1.3.4. Overview of the docker-compose configuration
This docker-compose configuration is made as a basis for what you would put in production
Separated containers for each component
A solid database backend with postgresql
A buildbot master that exposes its configuration to the docker host
A buildbot worker that can be cloned in order to add additional power
Containers are linked together so that the only port exposed to external is the web server
The default master container is based on Alpine linux for minimal footprint
The default worker container is based on more widely known Ubuntu distribution, as this is the container you want to customize.
Download the config from a tarball accessible via a web server
1.3.5. Playing with your Buildbot containers
If you’ve come this far, you have a Buildbot environment that you can freely experiment with.
In order to modify the configuration, you need to fork the project on github https://github.com/buildbot/buildbot-docker-example-config Then you can clone your own fork, and start the docker-compose again.
To modify your config, edit the master.cfg file, commit your changes, and push to your fork.
You can use the command buildbot check-config in order to make sure the config is valid before the push.
You will need to change docker-compose.yml the variable BUILDBOT_CONFIG_URL in order to point to your github fork.
The BUILDBOT_CONFIG_URL may point to a .tar.gz file accessible from HTTP.
Several git servers like github can generate that tarball automatically from the master branch of a git repository
If the BUILDBOT_CONFIG_URL does not end with .tar.gz, it is considered to be the URL to a master.cfg file accessible from HTTP.
1.3.6. Customize your Worker container
It is advised to customize you worker container in order to suit your project’s build dependencies and need. An example DockerFile is available which the buildbot community uses for its own CI purposes:
https://github.com/buildbot/metabbotcfg/blob/nine/docker/metaworker/Dockerfile
1.3.7. Multi-master
A multi-master environment can be setup using the multimaster/docker-compose.yml file in the example repository
# Build the Buildbot container (it will take a few minutes to download packages)
cd buildbot-docker-example-config/simple
docker-compose up -d
docker-compose scale buildbot=4
1.3.8. Going forward
You’ve got a taste now, but you’re probably curious for more. Let’s step it up a little in the second tutorial by changing the configuration and doing an actual build. Continue on to A Quick Tour.
1.4. Further Reading
See the following user-contributed tutorials for other highlights and ideas:
1.4.1. Buildbot in 5 minutes - a user-contributed tutorial
(Ok, maybe 10.)
Buildbot is really an excellent piece of software, however it can be a bit confusing for a newcomer (like me when I first started looking at it). Typically, at first sight, it looks like a bunch of complicated concepts that make no sense and whose relationships with each other are unclear. After some time and some reread, it all slowly starts to be more and more meaningful, until you finally say “oh!” and things start to make sense. Once you get there, you realize that the documentation is great, but only if you already know what it’s about.
This is what happened to me, at least. Here, I’m going to (try to) explain things in a way that would have helped me more as a newcomer. The approach I’m taking is more or less the reverse of that used by the documentation. That is, I’m going to start from the components that do the actual work (the builders) and go up the chain to the change sources. I hope purists will forgive this unorthodoxy. Here I’m trying to only clarify the concepts and not go into the details of each object or property; the documentation explains those quite well.
1.4.1.1. Installation
I won’t cover the installation; both Buildbot master and worker are available as packages for the major distributions, and in any case the instructions in the official documentation are fine. This document will refer to Buildbot 0.8.5 which was current at the time of writing, but hopefully the concepts are not too different in future versions. All the code shown is of course python code, and has to be included in the master.cfg configuration file.
We won’t cover basic things such as how to define the workers, project names, or other administrative information that is contained in that file; for that, again the official documentation is fine.
1.4.1.2. Builders: the workhorses
Since Buildbot is a tool whose goal is the automation of software builds, it makes sense to me to start from where we tell Buildbot how to build our software: the builder (or builders, since there can be more than one).
Simply put, a builder is an element that is in charge of performing some action or sequence of
actions, normally something related to building software (for example, checking out the source, or
make all), but it can also run arbitrary commands.
A builder is configured with a list of workers that it can use to carry out its task. The other
fundamental piece of information that a builder needs is, of course, the list of things it has to
do (which will normally run on the chosen worker). In Buildbot, this list of things is represented
as a BuildFactory object, which is essentially a sequence of steps, each one defining a certain
operation or command.
Enough talk, let’s see an example. For this example, we are going to assume that our super software
project can be built using a simple make all, and there is another target make packages
that creates rpm, deb and tgz packages of the binaries. In the real world things are usually more
complex (for example there may be a configure step, or multiple targets), but the concepts are
the same; it will just be a matter of adding more steps to a builder, or creating multiple
builders, although sometimes the resulting builders can be quite complex.
So to perform a manual build of our project, we would type the following on the command line (assuming we are at the root of the local copy of the repository):
$ make clean # clean remnants of previous builds
...
$ svn update
...
$ make all
...
$ make packages
...
# optional but included in the example: copy packages to some central machine
$ scp packages/*.rpm packages/*.deb packages/*.tgz someuser@somehost:/repository
...
Here we’re assuming the repository is SVN, but again the concepts are the same with git, mercurial or any other VCS.
Now, to automate this, we create a builder where each step is one of the commands we typed above. A step can be a shell command object, or a dedicated object that checks out the source code (there are various types for different repositories, see the docs for more info), or yet something else:
from buildbot.plugins import steps, util
# first, let's create the individual step objects
# step 1: make clean; this fails if the worker has no local copy, but
# is harmless and will only happen the first time
makeclean = steps.ShellCommand(name="make clean",
command=["make", "clean"],
description="make clean")
# step 2: svn update (here updates trunk, see the docs for more
# on how to update a branch, or make it more generic).
checkout = steps.SVN(baseURL='svn://myrepo/projects/coolproject/trunk',
mode="update",
username="foo",
password="bar",
haltOnFailure=True)
# step 3: make all
makeall = steps.ShellCommand(name="make all",
command=["make", "all"],
haltOnFailure=True,
description="make all")
# step 4: make packages
makepackages = steps.ShellCommand(name="make packages",
command=["make", "packages"],
haltOnFailure=True,
description="make packages")
# step 5: upload packages to central server. This needs passwordless ssh
# from the worker to the server (set it up in advance as part of the worker setup)
uploadpackages = steps.ShellCommand(
name="upload packages",
description="upload packages",
command="scp packages/*.rpm packages/*.deb packages/*.tgz someuser@somehost:/repository",
haltOnFailure=True)
# create the build factory and add the steps to it
f_simplebuild = util.BuildFactory()
f_simplebuild.addStep(makeclean)
f_simplebuild.addStep(checkout)
f_simplebuild.addStep(makeall)
f_simplebuild.addStep(makepackages)
f_simplebuild.addStep(uploadpackages)
# finally, declare the list of builders. In this case, we only have one builder
c['builders'] = [
util.BuilderConfig(name="simplebuild", workernames=['worker1', 'worker2', 'worker3'],
factory=f_simplebuild)
]
So our builder is called simplebuild and can run on either of worker1, worker2 or
worker3. If our repository has other branches besides trunk, we could create another one or
more builders to build them; in this example, only the checkout step would be different, in that it
would need to check out the specific branch. Depending on how exactly those branches have to be
built, the shell commands may be recycled, or new ones would have to be created if they are
different in the branch. You get the idea. The important thing is that all the builders be named
differently and all be added to the c['builders'] value (as can be seen above, it is a list of
BuilderConfig objects).
Of course the type and number of steps will vary depending on the goal; for example, to just check
that a commit doesn’t break the build, we could include just up to the make all step. Or we
could have a builder that performs a more thorough test by also doing make test or other
targets. You get the idea. Note that at each step except the very first we use
haltOnFailure=True because it would not make sense to execute a step if the previous one failed
(ok, it wouldn’t be needed for the last step, but it’s harmless and protects us if one day we add
another step after it).
1.4.1.3. Schedulers
Now this is all nice and dandy, but who tells the builder (or builders) to run, and when? This is the job of the scheduler which is a fancy name for an element that waits for some event to happen, and when it does, based on that information, decides whether and when to run a builder (and which one or ones). There can be more than one scheduler. I’m being purposely vague here because the possibilities are almost endless and highly dependent on the actual setup, build purposes, source repository layout and other elements.
So a scheduler needs to be configured with two main pieces of information: on one hand, which events to react to, and on the other hand, which builder or builders to trigger when those events are detected. (It’s more complex than that, but if you understand this, you can get the rest of the details from the docs).
A simple type of scheduler may be a periodic scheduler that runs a certain builder (or builders) when a configurable amount of time has passed. In our example, that’s how we would trigger a build every hour:
from buildbot.plugins import schedulers
# define the periodic scheduler
hourlyscheduler = schedulers.Periodic(name="hourly",
builderNames=["simplebuild"],
periodicBuildTimer=3600)
# define the available schedulers
c['schedulers'] = [hourlyscheduler]
That’s it. Every hour this hourly scheduler will run the simplebuild builder. If we have
more than one builder that we want to run every hour, we can just add them to the builderNames
list when defining the scheduler. Or since multiple schedulers are allowed, other schedulers can be
defined and added to c['schedulers'] in the same way.
Other types of schedulers exist; in particular, there are schedulers that can be more dynamic than the periodic one. The typical dynamic scheduler is one that learns about changes in a source repository (generally because some developer checks in some change) and triggers one or more builders in response to those changes. Let’s assume for now that the scheduler “magically” learns about changes in the repository (more about this later); here’s how we would define it:
from buildbot.plugins import schedulers
# define the dynamic scheduler
trunkchanged = schedulers.SingleBranchScheduler(name="trunkchanged",
change_filter=util.ChangeFilter(branch=None),
treeStableTimer=300,
builderNames=["simplebuild"])
# define the available schedulers
c['schedulers'] = [trunkchanged]
This scheduler receives changes happening to the repository, and among all of them, pays attention
to those happening in “trunk” (that’s what branch=None means). In other words, it filters the
changes to react only to those it’s interested in. When such changes are detected, and the tree has
been quiet for 5 minutes (300 seconds), it runs the simplebuild builder. The
treeStableTimer helps in those situations where commits tend to happen in bursts, which would
otherwise result in multiple build requests queuing up.
What if we want to act on two branches (say, trunk and 7.2)? First, we create two builders, one for each branch, and then we create two dynamic schedulers:
from buildbot.plugins import schedulers
# define the dynamic scheduler for trunk
trunkchanged = schedulers.SingleBranchScheduler(name="trunkchanged",
change_filter=util.ChangeFilter(branch=None),
treeStableTimer=300,
builderNames=["simplebuild-trunk"])
# define the dynamic scheduler for the 7.2 branch
branch72changed = schedulers.SingleBranchScheduler(
name="branch72changed",
change_filter=util.ChangeFilter(branch='branches/7.2'),
treeStableTimer=300,
builderNames=["simplebuild-72"])
# define the available schedulers
c['schedulers'] = [trunkchanged, branch72changed]
The syntax of the change filter is VCS-dependent (above is for SVN), but again, once the idea is
clear, the documentation has all the details. Another feature of the scheduler is that it can be
told which changes, within those it’s paying attention to, are important and which are not. For
example, there may be a documentation directory in the branch the scheduler is watching, but
changes under that directory should not trigger a build of the binary. This finer filtering is
implemented by means of the fileIsImportant argument to the scheduler (full details in the docs
and - alas - in the sources).
1.4.1.4. Change sources
Earlier, we said that a dynamic scheduler “magically” learns about changes; the final piece of the puzzle is change sources, which are precisely the elements in Buildbot whose task is to detect changes in a repository and communicate them to the schedulers. Note that periodic schedulers don’t need a change source since they only depend on elapsed time; dynamic schedulers, on the other hand, do need a change source.
A change source is generally configured with information about a source repository (which is where changes happen). A change source can watch changes at different levels in the hierarchy of the repository, so for example, it is possible to watch the whole repository or a subset of it, or just a single branch. This determines the extent of the information that is passed down to the schedulers.
There are many ways a change source can learn about changes; it can periodically poll the repository for changes, or the VCS can be configured (for example through hook scripts triggered by commits) to push changes into the change source. While these two methods are probably the most common, they are not the only possibilities. It is possible, for example, to have a change source detect changes by parsing an email sent to a mailing list when a commit happens. Yet other methods exist and the manual again has the details.
To complete our example, here’s a change source that polls a SVN repository every 2 minutes:
from buildbot.plugins import changes, util
svnpoller = changes.SVNPoller(repourl="svn://myrepo/projects/coolproject",
svnuser="foo",
svnpasswd="bar",
pollInterval=120,
split_file=util.svn.split_file_branches)
c['change_source'] = svnpoller
This poller watches the whole “coolproject” section of the repository, so it will detect changes in all the branches. We could have said:
repourl = "svn://myrepo/projects/coolproject/trunk"
or:
repourl = "svn://myrepo/projects/coolproject/branches/7.2"
to watch only a specific branch.
To watch another project, you need to create another change source, and you need to filter changes by project. For instance, when you add a change source watching project ‘superproject’ to the above example, you need to change the original scheduler from:
trunkchanged = schedulers.SingleBranchScheduler(
name="trunkchanged",
change_filter=filter.ChangeFilter(branch=None),
# ...
)
to e.g.:
trunkchanged = schedulers.SingleBranchScheduler(
name="trunkchanged",
change_filter=filter.ChangeFilter(project="coolproject", branch=None),
# ...
)
otherwise, coolproject will be built when there’s a change in superproject.
Since we’re watching more than one branch, we need a method to tell in which branch the change
occurred when we detect one. This is what the split_file argument does, it takes a callable
that Buildbot will call to do the job. The split_file_branches function, which comes with Buildbot,
is designed for exactly this purpose so that’s what the example above uses.
And of course this is all SVN-specific, but there are pollers for all the popular VCSs.
Note that if you have many projects, branches, and builders, it probably pays not to hardcode all the schedulers and builders in the configuration, but generate them dynamically starting from the list of all projects, branches, targets, etc, and using loops to generate all possible combinations (or only the needed ones, depending on the specific setup), as explained in the documentation chapter about Customization.
1.4.1.5. Reporters
Now that the basics are in place, let’s go back to the builders, which is where the real work happens. Reporters are simply the means Buildbot uses to inform the world about what’s happening, that is, how builders are doing. There are many reporters: a mail notifier, an IRC notifier, and others. They are described fairly well in the manual.
One thing I’ve found useful is the ability to pass a domain name as the lookup argument to a
mailNotifier, which allows you to take an unqualified username as it appears in the SVN change
and create a valid email address by appending the given domain name to it:
from buildbot.plugins import reporter
# if jsmith commits a change, an email for the build is sent to jsmith@example.org
notifier = reporter.MailNotifier(fromaddr="buildbot@example.org",
sendToInterestedUsers=True,
lookup="example.org")
c['reporters'].append(notifier)
The mail notifier can be customized at will by means of the messageFormatter argument, which is
a class that Buildbot calls to format the body of the email, and to which it makes available lots
of information about the build. For more details, look into the Reporters section of the
Buildbot manual.
1.4.1.6. Conclusion
Please note that this article has just scratched the surface; given the complexity of the task of build automation, the possibilities are almost endless. So there’s much much more to say about Buildbot. Hopefully this has been a gentle introduction before reading the official manual. Had I found an explanation as the one above when I was approaching Buildbot, I’d have had to read the manual just once, rather than multiple times. I hope this can help someone else.
(Thanks to Davide Brini for permission to include this tutorial, derived from one he originally posted at http://backreference.org .)
This is the Buildbot manual for Buildbot version 4.3.0.
2. Buildbot Manual
2.1. Introduction
Buildbot is a framework to automate the compile and test cycle that is used to validate code changes in most software projects.
Features:
run builds on a variety of worker platforms
arbitrary build process: handles projects using C, Python, whatever
minimal host requirements: Python and Twisted
workers can be behind a firewall if they can still do checkout
status delivery through web page, email, IRC, other protocols
flexible configuration by subclassing generic build process classes
debug tools to force a new build, submit fake
Changes, query worker statusreleased under the GPL
2.1.1. System Architecture
Buildbot consists of a single buildmaster and one or more workers that connect to the master. The buildmaster makes all decisions about what, when, and how to build. The workers only connect to master and execute whatever commands they are instructed to execute.
The usual flow of information is as follows:
the buildmaster fetches new code changes from version control systems
the buildmaster decides what builds (if any) to start
the builds are performed by executing commands on the workers (e.g.
git clone,make,make check).the workers send the results of the commands back to the buildmaster
buildmaster interprets the results of the commands and marks the builds as successful or failing
buildmaster sends success or failure reports to external services to e.g. inform the developers.

2.1.1.1. Worker Connections
The workers connect to the buildmaster over a TCP connection to a publicly-visible port. This allows workers to live behind a NAT or similar firewalls as long as they can get to buildmaster. After the connection is established, the connection is bidirectional: commands flow from the buildmaster to the worker and results flow from the worker to the buildmaster.
The buildmaster does not provide the workers with the source code itself, only with commands necessary to perform the source code checkout. As a result, the workers need to be able to reach the source code repositories that they are supposed to build.

2.1.1.2. Buildmaster Architecture
The following is rough overview of the data flow within the buildmaster.

The following provides a short overview of the core components of Buildbot master. For a more detailed description see the Concepts page.
The core components of Buildbot master are as follows:
- Builders
A builder is a user-configurable description of how to perform a build. It defines what steps a new build will have, what workers it may run on and a couple of other properties. A builder takes a build request which specifies the intention to create a build for specific versions of code and produces a build which is a concrete description of a build including a list of steps to perform, the worker this needs to be performed on and so on.
- Schedulers:
A scheduler is a user-configurable component that decides when to start a build. The decision could be based on time, on new code being committed or on similar events.
- Change Sources:
Change sources are user-configurable components that interact with external version control systems and retrieve new code. Internally new code is represented as Changes which roughly correspond to single commit or changeset. The design of Buildbot requires the workers to have their own copies of the source code, thus change sources is an optional component as long as there are no schedulers that create new builds based on new code commit events.
- Reporters
Reporters are user-configurable components that send information about started or completed builds to external sources. Buildbot provides its own web application to observe this data, so reporters are optional. However they can be used to provide up to date build status on platforms such as GitHub or sending emails.
2.2. Installation
2.2.1. Buildbot Components
Buildbot is shipped in two components: the buildmaster (called buildbot for legacy reasons)
and the worker. The worker component has far fewer requirements, and is more broadly compatible
than the buildmaster. You will need to carefully pick the environment in which to run your
buildmaster, but the worker should be able to run just about anywhere.
It is possible to install the buildmaster and worker on the same system, although for anything but the smallest installation this arrangement will not be very efficient.
2.2.2. Requirements
2.2.2.1. Common Requirements
At a bare minimum, you’ll need the following for both the buildmaster and a worker:
Python: https://www.python.org
Buildbot master works with Python-3.8+. Buildbot worker works with Python-3.7+.
Note
This should be a “normal” build of Python. Builds of Python with debugging enabled or other unusual build parameters are likely to cause incorrect behavior.
Twisted: http://twistedmatrix.com
Buildbot requires Twisted-17.9.0 or later on the master and the worker. In upcoming versions of Buildbot, a newer Twisted will also be required on the worker. As always, the most recent version is recommended.
Certifi: https://github.com/certifi/python-certifi
Certifi provides collection of Root Certificates for validating the trustworthiness of SSL certificates. Unfortunately it does not support any addition of own company certificates. At the moment you need to add your own .PEM content to cacert.pem manually.
Of course, your project’s build process will impose additional requirements on the workers. These hosts must have all the tools necessary to compile and test your project’s source code.
Note
If your internet connection is secured by a proxy server, please check your http_proxy and https_proxy environment variables.
Otherwise pip and other tools will fail to work.
Windows Support
Buildbot - both master and worker - runs well natively on Windows. The worker runs well on Cygwin, but because of problems with SQLite on Cygwin, the master does not.
Buildbot’s windows testing is limited to the most recent Twisted and Python versions. For best results, use the most recent available versions of these libraries on Windows.
Pywin32: http://sourceforge.net/projects/pywin32/
Twisted requires PyWin32 in order to spawn processes on Windows.
Build Tools for Visual Studio 2019 - Microsoft Visual C++ compiler
Twisted requires MSVC to compile some parts like tls during the installation, see https://twistedmatrix.com/trac/wiki/WindowsBuilds and https://wiki.python.org/moin/WindowsCompilers.
2.2.3. Installing the code
2.2.3.1. The Buildbot Packages
Buildbot comes in several parts: buildbot (the buildmaster), buildbot-worker (the worker),
buildbot-www, and several web plugins such as buildbot-waterfall-view.
The worker and buildmaster can be installed individually or together.
The base web (buildbot.www) and web plugins are required to run a master with a web interface
(the common configuration).
2.2.3.2. Installation From PyPI
The preferred way to install Buildbot is using pip.
For the master:
pip install buildbot
and for the worker:
pip install buildbot-worker
When using pip to install, instead of distribution specific package managers, e.g. via apt or
ports, it is simpler to choose exactly which version one wants to use.
It may however be easier to install via distribution specific package managers, but note that they
may provide an earlier version than what is available via pip.
If you plan to use TLS or SSL in master configuration (e.g. to fetch resources over HTTPS using
twisted.web.client), you need to install Buildbot with tls extras:
pip install buildbot[tls]
2.2.3.3. Installation From Tarballs
Use pip to install buildbot master or buildbot-worker using tarball.
Note
Support for installation using setup.py has been discontinued due to the deprecation of
support in the distutils and setuptools packages.
For more details, see Why you shouldn’t invoke setup.py directly.
If you have a tarball file named buildbot.tar.gz in your current directory, you can install it using:
pip install buildbot.tar.gz
Alternatively, you can provide a URL if the tarball is hosted online. Make sure to replace the URL with the actual URL of tarball you want to install.
pip install https://github.com/buildbot/buildbot/releases/download/v3.10.1/buildbot-3.10.1.tar.gz
Installation may need to be done as root.
This will put the bulk of the code in somewhere like /usr/lib/pythonx.y/site-packages/buildbot.
It will also install the buildbot command-line tool in /usr/bin/buildbot.
If the environment variable $NO_INSTALL_REQS is set to 1, then setup.py will not
try to install Buildbot’s requirements.
This is usually only useful when building a Buildbot package.
To test this, shift to a different directory (like /tmp), and run:
buildbot --version
# or
buildbot-worker --version
If it shows you the versions of Buildbot and Twisted, the install went ok.
If it says “no such command” or gets an ImportError when it tries to load the libraries, then
something went wrong. pydoc buildbot is another useful diagnostic tool.
Windows users will find these files in other places.
You will need to make sure that Python can find the libraries, and will probably find it convenient
to have buildbot in your PATH.
2.2.3.4. Installation in a Virtualenv
If you cannot or do not wish to install buildbot into a site-wide location like /usr or /usr/local, you can also install it into the account’s home directory or any other location using a tool like virtualenv.
2.2.3.5. Running Buildbot’s Tests (optional)
If you wish, you can run the buildbot unit test suite.
First, ensure that you have the mock Python module installed
from PyPI. You must not be using a Python wheels packaged version of Buildbot or have specified
the bdist_wheel command when building.
The test suite is not included with the PyPi packaged version.
This module is not required for ordinary Buildbot operation - only to run the tests.
Note that this is not the same as the Fedora mock package!
You can check if you have mock with:
python -mmock
Then, run the tests:
PYTHONPATH=. trial buildbot.test
# or
PYTHONPATH=. trial buildbot_worker.test
Nothing should fail, although a few might be skipped.
If any of the tests fail for reasons other than a missing mock, you should stop and investigate
the cause before continuing the installation process, as it will probably be easier to track down
the bug early.
In most cases, the problem is incorrectly installed Python modules or a badly configured PYTHONPATH.
This may be a good time to contact the Buildbot developers for help.
2.2.4. Buildmaster Setup
2.2.4.1. Creating a buildmaster
As you learned earlier (System Architecture), the buildmaster runs on a central host (usually one that is publicly visible, so everybody can check on the status of the project), and controls all aspects of the buildbot system
You will probably wish to create a separate user account for the buildmaster, perhaps named
buildmaster. Do not run the buildmaster as root!
You need to choose a directory for the buildmaster, called the basedir.
This directory will be owned by the buildmaster.
It will contain the configuration, database, and status information - including logfiles.
On a large buildmaster this directory will see a lot of activity, so it should be on a disk with
adequate space and speed.
Once you’ve picked a directory, use the buildbot create-master command to create the directory
and populate it with startup files:
buildbot create-master -r basedir
You will need to create a configuration file before starting the buildmaster.
Most of the rest of this manual is dedicated to explaining how to do this.
A sample configuration file is placed in the working directory, named master.cfg.sample,
which can be copied to master.cfg and edited to suit your purposes.
(Internal details: This command creates a file named buildbot.tac that contains all the
state necessary to create the buildmaster.
Twisted has a tool called twistd which can use this .tac file to create and launch a buildmaster
instance. Twistd takes care of logging and daemonization (running the program in the background).
/usr/bin/buildbot is a front end which runs twistd for you.)
Your master will need a database to store the various information about your builds, and its
configuration. By default, the sqlite3 backend will be used.
This needs no configuration, neither extra software.
All information will be stored in the file state.sqlite.
Buildbot however supports multiple backends.
See Using A Database Server for more options.
Buildmaster Options
This section lists options to the create-master command.
You can also type buildbot create-master --help for an up-to-the-moment summary.
- --force
This option will allow to re-use an existing directory.
- --no-logrotate
This disables internal worker log management mechanism. With this option worker does not override the default logfile name and its behaviour giving a possibility to control those with command-line options of twistd daemon.
- --relocatable
This creates a “relocatable”
buildbot.tac, which uses relative paths instead of absolute paths, so that the buildmaster directory can be moved about.
- --config
The name of the configuration file to use. This configuration file need not reside in the buildmaster directory.
- --log-size
This is the size in bytes when exceeded to rotate the Twisted log files. The default is 10MiB.
- --log-count
This is the number of log rotations to keep around. You can either specify a number or
Noneto keep alltwistd.logfiles around. The default is 10.
- --db
The database that the Buildmaster should use. Note that the same value must be added to the configuration file.
2.2.5. Worker Setup
2.2.5.1. Creating a worker
Typically, you will be adding a worker to an existing buildmaster, to provide additional architecture coverage. The Buildbot administrator will give you several pieces of information necessary to connect to the buildmaster. You should also be somewhat familiar with the project being tested so that you can troubleshoot build problems locally.
Buildbot exists to make sure that the project’s stated how to build it process actually works.
To this end, the worker should run in an environment just like that of your regular developers.
Typically the project’s build process is documented somewhere (README, INSTALL, etc),
in a document that should mention all library dependencies and contain a basic set of build instructions.
This document will be useful as you configure the host and account in which worker runs.
Here’s a good checklist for setting up a worker:
Set up the account
It is recommended (although not mandatory) to set up a separate user account for the worker. This account is frequently named
buildbotorworker. This serves to isolate your personal working environment from that of the worker’s, and helps to minimize the security threat posed by letting possibly-unknown contributors run arbitrary code on your system. The account should have a minimum of fancy init scripts.
Install the Buildbot code
Follow the instructions given earlier (Installing the code). If you use a separate worker account, and you didn’t install the Buildbot code to a shared location, then you will need to install it with
--home=~for each account that needs it.
Set up the host
Make sure the host can actually reach the buildmaster. Usually the buildmaster is running a status webserver on the same machine, so simply point your web browser at it and see if you can get there. Install whatever additional packages or libraries the project’s INSTALL document advises. (or not: if your worker is supposed to make sure that building without optional libraries still works, then don’t install those libraries.)
Again, these libraries don’t necessarily have to be installed to a site-wide shared location, but they must be available to your build process. Accomplishing this is usually very specific to the build process, so installing them to
/usror/usr/localis usually the best approach.
Test the build process
Follow the instructions in the
INSTALLdocument, in the worker’s account. Perform a full CVS (or whatever) checkout, configure, make, run tests, etc. Confirm that the build works without manual fussing. If it doesn’t work when you do it manually, it will be unlikely to work when Buildbot attempts to do it in an automated fashion.
Choose a base directory
This should be somewhere in the worker’s account, typically named after the project which is being tested. The worker will not touch any file outside of this directory. Something like
~/Buildbotor~/Workers/fooprojectis appropriate.
Get the buildmaster host/port, workername, and password
When the Buildbot admin configures the buildmaster to accept and use your worker, they will provide you with the following pieces of information:
your worker’s name
the password assigned to your worker
the hostname and port number of the buildmaster
Create the worker
Now run the ‘worker’ command as follows:
buildbot-worker create-worker BASEDIR MASTERHOST:PORT WORKERNAME PASSWORDThis will create the base directory and a collection of files inside, including the
buildbot.tacfile that contains all the information you passed to the buildbot-worker command.
Fill in the hostinfo files
When it first connects, the worker will send a few files up to the buildmaster which describe the host that it is running on. These files are presented on the web status display so that developers have more information to reproduce any test failures that are witnessed by the Buildbot. There are sample files in the
infosubdirectory of the Buildbot’s base directory. You should edit these to correctly describe you and your host.
BASEDIR/info/adminshould contain your name and email address. This is theworker admin address, and will be visible from the build status page (so you may wish to munge it a bit if address-harvesting spambots are a concern).
BASEDIR/info/hostshould be filled with a brief description of the host: OS, version, memory size, CPU speed, versions of relevant libraries installed, and finally the version of the Buildbot code which is running the worker.The optional
BASEDIR/info/access_urican specify a URI which will connect a user to the machine. Many systems acceptssh://hostnameURIs for this purpose.If you run many workers, you may want to create a single
~worker/infofile and share it among all the workers with symlinks.
Worker Options
There are a handful of options you might want to use when creating the worker with the
buildbot-worker create-worker <options> DIR <params> command.
You can type buildbot-worker create-worker --help for a summary.
To use these, just include them on the buildbot-worker create-worker command line, like this
buildbot-worker create-worker --umask=0o22 ~/worker buildmaster.example.org:42012 \
{myworkername} {mypasswd}
- --protocol
This is a string representing a protocol to be used when creating master-worker connection. The default option is Perspective Broker (
pb). Additionally, there is an experimental MessagePack-based protocol (msgpack_experimental_v7).
- --no-logrotate
This disables internal worker log management mechanism. With this option worker does not override the default logfile name and its behaviour giving a possibility to control those with command-line options of twistd daemon.
- --umask
This is a string (generally an octal representation of an integer) which will cause the worker process’
umaskvalue to be set shortly after initialization. Thetwistddaemonization utility forces the umask to 077 at startup (which means that all files created by the worker or its child processes will be unreadable by any user other than the worker account). If you want build products to be readable by other accounts, you can add--umask=0o22to tell the worker to fix the umask after twistd clobbers it. If you want build products to be writable by other accounts too, use--umask=0o000, but this is likely to be a security problem.
- --keepalive
This is a number that indicates how frequently
keepalivemessages should be sent from the worker to the buildmaster, expressed in seconds. The default (600) causes a message to be sent to the buildmaster at least once every 10 minutes. To set this to a lower value, use e.g.--keepalive=120.If the worker is behind a NAT box or stateful firewall, these messages may help to keep the connection alive: some NAT boxes tend to forget about a connection if it has not been used in a while. When this happens, the buildmaster will think that the worker has disappeared, and builds will time out. Meanwhile the worker will not realize that anything is wrong.
- --maxdelay
This is a number that indicates the maximum amount of time the worker will wait between connection attempts, expressed in seconds. The default (300) causes the worker to wait at most 5 minutes before trying to connect to the buildmaster again.
- --maxretries
This is a number that indicates the maximum number of times the worker will make connection attempts. After that amount, the worker process will stop. This option is useful for Latent Workers to avoid consuming resources in case of misconfiguration or master failure.
For VM based latent workers, the user is responsible for halting the system when the Buildbot worker has exited. This feature is heavily OS dependent, and cannot be managed by the Buildbot worker. For example, with systemd, one can add
ExecStopPost=shutdown nowto the Buildbot worker service unit configuration.
- --log-size
This is the size in bytes when exceeded to rotate the Twisted log files.
- --log-count
This is the number of log rotations to keep around. You can either specify a number or
Noneto keep alltwistd.logfiles around. The default is 10.
- --allow-shutdown
Can also be passed directly to the worker constructor in
buildbot.tac. If set, it allows the worker to initiate a graceful shutdown, meaning that it will ask the master to shut down the worker when the current build, if any, is complete.Setting allow_shutdown to
filewill cause the worker to watchshutdown.stampin basedir for updates to its mtime. When the mtime changes, the worker will request a graceful shutdown from the master. The file does not need to exist prior to starting the worker.Setting allow_shutdown to
signalwill set up a SIGHUP handler to start a graceful shutdown. When the signal is received, the worker will request a graceful shutdown from the master.The default value is
None, in which case this feature will be disabled.Both master and worker must be at least version 0.8.3 for this feature to work.
- --use-tls
Can also be passed directly to the Worker constructor in
buildbot.tac. If set, the generated connection string starts withtlsinstead of withtcp, allowing encrypted connection to the buildmaster. Make sure the worker trusts the buildmasters certificate. If you have an non-authoritative certificate (CA is self-signed) see option--connection-stringand also Worker-TLS-Config below.
- --delete-leftover-dirs
Can also be passed directly to the Worker constructor in
buildbot.tac. If set, unexpected directories in worker base directory will be removed. Otherwise, a warning will be displayed intwistd.logso that you can manually remove them.
- --connection-string
Can also be passed directly to the Worker constructor in
buildbot.tac. If set, the worker connection to master will be made using thisconnection_string. See Worker-TLS-Config below for more details. Note that this option will override required positional argumentmasterhost[:port]and also option--use-tls.
- --proxy-connection-string
Can also be passed directly to the Worker constructor in
buildbot.tac. If set, the worker connection will be tunneled through a HTTP proxy specified by the option value.
Other Worker Configuration
unicode_encodingThis represents the encoding that Buildbot should use when converting unicode commandline arguments into byte strings in order to pass to the operating system when spawning new processes.
The default value is what Python’s
sys.getfilesystemencodingreturns, which on Windows is ‘mbcs’, on macOS is ‘utf-8’, and on Unix depends on your locale settings.If you need a different encoding, this can be changed in your worker’s
buildbot.tacfile by adding aunicode_encodingargument to the Worker constructor.
s = Worker(buildmaster_host, port, workername, passwd, basedir,
keepalive, usepty, umask=umask, maxdelay=maxdelay,
unicode_encoding='utf-8', allow_shutdown='signal')
Worker TLS Configuration
tlsSee
--useTlsoption above as an alternative to setting theconneciton_stringmanually.connection_stringFor TLS connections to the master, the
connection_string-argument must be passed to the worker constructor.buildmaster_hostandportmust then beNone.connection_stringwill be used to create a client endpoint with clientFromString. An example ofconnection_stringis"TLS:buildbot-master.com:9989".See more about how to formulate the connection string in ConnectionStrings.
Example TLS connection string:
s = Worker(None, None, workername, passwd, basedir, keepalive, connection_string='TLS:buildbot-master.com:9989')
Make sure the worker trusts the certificate of the master. If you have a non-authoritative certificate (CA is self-signed), the trustRoots parameter can be used.
s = Worker(None, None, workername, passwd, basedir, keepalive, connection_string= 'TLS:buildbot-master.com:9989:trustRoots=/dir-with-ca-certs')
It must point to a directory with PEM-encoded certificates. For example:
$ cat /dir-with-ca-certs/ca.pem -----BEGIN CERTIFICATE----- MIIE9DCCA9ygAwIBAgIJALEqLrC/m1w3MA0GCSqGSIb3DQEBCwUAMIGsMQswCQYD VQQGEwJaWjELMAkGA1UECBMCUUExEDAOBgNVBAcTB05vd2hlcmUxETAPBgNVBAoT CEJ1aWxkYm90MRkwFwYDVQQLExBEZXZlbG9wbWVudCBUZWFtMRQwEgYDVQQDEwtC dWlsZGJvdCBDQTEQMA4GA1UEKRMHRWFzeVJTQTEoMCYGCSqGSIb3DQEJARYZYnVp bGRib3RAaW50ZWdyYXRpb24udGVzdDAeFw0xNjA5MDIxMjA5NTJaFw0yNjA4MzEx MjA5NTJaMIGsMQswCQYDVQQGEwJaWjELMAkGA1UECBMCUUExEDAOBgNVBAcTB05v d2hlcmUxETAPBgNVBAoTCEJ1aWxkYm90MRkwFwYDVQQLExBEZXZlbG9wbWVudCBU ZWFtMRQwEgYDVQQDEwtCdWlsZGJvdCBDQTEQMA4GA1UEKRMHRWFzeVJTQTEoMCYG CSqGSIb3DQEJARYZYnVpbGRib3RAaW50ZWdyYXRpb24udGVzdDCCASIwDQYJKoZI hvcNAQEBBQADggEPADCCAQoCggEBALJZcC9j4XYBi1fYT/fibY2FRWn6Qh74b1Pg I7iIde6Sf3DPdh/ogYvZAT+cIlkZdo4v326d0EkuYKcywDvho8UeET6sIYhuHPDW lRl1Ret6ylxpbEfxFNvMoEGNhYAP0C6QS2eWEP9LkV2lCuMQtWWzdedjk+efqBjR Gozaim0lr/5lx7bnVx0oRLAgbI5/9Ukbopansfr+Cp9CpFpbNPGZSmELzC3FPKXK 5tycj8WEqlywlha2/VRnCZfYefB3aAuQqQilLh+QHyhn6hzc26+n5B0l8QvrMkOX atKdznMLzJWGxS7UwmDKcsolcMAW+82BZ8nUCBPF3U5PkTLO540CAwEAAaOCARUw ggERMB0GA1UdDgQWBBT7A/I+MZ1sFFJ9jikYkn51Q3wJ+TCB4QYDVR0jBIHZMIHW gBT7A/I+MZ1sFFJ9jikYkn51Q3wJ+aGBsqSBrzCBrDELMAkGA1UEBhMCWloxCzAJ BgNVBAgTAlFBMRAwDgYDVQQHEwdOb3doZXJlMREwDwYDVQQKEwhCdWlsZGJvdDEZ MBcGA1UECxMQRGV2ZWxvcG1lbnQgVGVhbTEUMBIGA1UEAxMLQnVpbGRib3QgQ0Ex EDAOBgNVBCkTB0Vhc3lSU0ExKDAmBgkqhkiG9w0BCQEWGWJ1aWxkYm90QGludGVn cmF0aW9uLnRlc3SCCQCxKi6wv5tcNzAMBgNVHRMEBTADAQH/MA0GCSqGSIb3DQEB CwUAA4IBAQCJGJVMAmwZRK/mRqm9E0e3s4YGmYT2jwX5IX17XljEy+1cS4huuZW2 33CFpslkT1MN/r8IIZWilxT/lTujHyt4eERGjE1oRVKU8rlTH8WUjFzPIVu7nkte 09abqynAoec8aQukg79NRCY1l/E2/WzfnUt3yTgKPfZmzoiN0K+hH4gVlWtrizPA LaGwoslYYTA6jHNEeMm8OQLNf17OTmAa7EpeIgVpLRCieI9S3JIG4WYU8fVkeuiU cB439SdixU4cecVjNfFDpq6JM8N6+DQoYOSNRt9Dy0ioGyx5D4lWoIQ+BmXQENal gw+XLyejeNTNgLOxf9pbNYMJqxhkTkoE -----END CERTIFICATE-----
Using TCP in
connection_stringis the equivalent to using thebuildmaster_hostandportarguments.s = Worker(None, None, workername, passwd, basedir, keepalive connection_string='TCP:buildbot-master.com:9989')
is equivalent to
s = Worker('buildbot-master.com', 9989, workername, passwd, basedir, keepalive)
2.2.6. Next Steps
2.2.6.1. Launching the daemons
Both the buildmaster and the worker run as daemon programs. To launch them, pass the working directory to the buildbot and buildbot-worker commands, as appropriate:
# start a master
buildbot start [ BASEDIR ]
# start a worker
buildbot-worker start [ WORKER_BASEDIR ]
The BASEDIR is optional and can be omitted if the current directory contains the buildbot configuration (the buildbot.tac file).
buildbot start
This command will start the daemon and then return, so normally it will not produce any output.
To verify that the programs are indeed running, look for a pair of files named twistd.log
and twistd.pid that should be created in the working directory. twistd.pid contains
the process ID of the newly-spawned daemon.
When the worker connects to the buildmaster, new directories will start appearing in its base directory. The buildmaster tells the worker to create a directory for each Builder which will be using that worker. All build operations are performed within these directories: CVS checkouts, compiles, and tests.
Once you get everything running, you will want to arrange for the buildbot daemons to be started at
boot time. One way is to use cron, by putting them in a @reboot crontab entry [1]
@reboot buildbot start [ BASEDIR ]
When you run crontab to set this up, remember to do it as the buildmaster or worker account! If you add this to your crontab when running as your regular account (or worse yet, root), then the daemon will run as the wrong user, quite possibly as one with more authority than you intended to provide.
It is important to remember that the environment provided to cron jobs and init scripts can be
quite different than your normal runtime.
There may be fewer environment variables specified, and the PATH may be shorter than usual.
It is a good idea to test out this method of launching the worker by using a cron job with a time
in the near future, with the same command, and then check twistd.log to make sure the worker
actually started correctly.
Common problems here are for /usr/local or ~/bin to not be on your PATH,
or for PYTHONPATH to not be set correctly.
Sometimes HOME is messed up too. If using systemd to launch buildbot-worker,
it may be a good idea to specify a fixed PATH using the Environment directive
(see systemd unit file example).
Some distributions may include conveniences to make starting buildbot at boot time easy.
For instance, with the default buildbot package in Debian-based distributions, you may only need to
modify /etc/default/buildbot (see also /etc/init.d/buildbot, which reads the
configuration in /etc/default/buildbot).
Buildbot also comes with its own init scripts that provide support for controlling multi-worker and multi-master setups (mostly because they are based on the init script from the Debian package). With a little modification, these scripts can be used on both Debian and RHEL-based distributions. Thus, they may prove helpful to package maintainers who are working on buildbot (or to those who haven’t yet split buildbot into master and worker packages).
# install as /etc/default/buildbot-worker
# or /etc/sysconfig/buildbot-worker
worker/contrib/init-scripts/buildbot-worker.default
# install as /etc/default/buildmaster
# or /etc/sysconfig/buildmaster
master/contrib/init-scripts/buildmaster.default
# install as /etc/init.d/buildbot-worker
worker/contrib/init-scripts/buildbot-worker.init.sh
# install as /etc/init.d/buildmaster
master/contrib/init-scripts/buildmaster.init.sh
# ... and tell sysvinit about them
chkconfig buildmaster reset
# ... or
update-rc.d buildmaster defaults
2.2.6.2. Launching worker as Windows service
Security consideration
Setting up the buildbot worker as a Windows service requires Windows administrator rights. It is important to distinguish installation stage from service execution. It is strongly recommended run Buildbot worker with lowest required access rights. It is recommended run a service under machine local non-privileged account.
If you decide run Buildbot worker under domain account it is recommended to create dedicated strongly limited user account that will run Buildbot worker service.
Windows service setup
In this description, we assume that the buildbot worker account is the local domain account worker.
In case worker should run under domain user account please replace .\worker with <domain>\worker.
Please replace <worker.passwd> with given user password.
Please replace <worker.basedir> with the full/absolute directory
specification to the created worker (what is called BASEDIR in Creating a worker).
buildbot_worker_windows_service --user .\worker --password <worker.passwd> --startup auto install
powershell -command "& {&'New-Item' -path Registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\BuildBot\Parameters}"
powershell -command "& {&'set-ItemProperty' -path Registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\BuildBot\Parameters -Name directories -Value '<worker.basedir>'}"
The first command automatically adds user rights to run Buildbot as service.
Modify environment variables
This step is optional and may depend on your needs. At least we have found useful to have dedicated temp folder worker steps. It is much easier discover what temporary files your builds leaks/misbehaves.
As Administrator run
regeditOpen the key
Computer\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Buildbot.Create a new value of type
REG_MULTI_SZcalledEnvironment.Add entries like
TMP=c:\bbw\tmp
TEMP=c:\bbw\tmp
Check if Buildbot can start correctly configured as Windows service
As admin user run the command net start buildbot.
In case everything goes well, you should see following output
The BuildBot service is starting.
The BuildBot service was started successfully.
Troubleshooting
If anything goes wrong check
Twisted log on
C:\bbw\worker\twistd.logWindows system event log (
eventvwr.mscin command line,Show-EventLogin PowerShell).
2.2.6.3. Logfiles
While a buildbot daemon runs, it emits text to a logfile, named twistd.log.
A command like tail -f twistd.log is useful to watch the command output as it runs.
The buildmaster will announce any errors with its configuration file in the logfile, so it is a good idea to look at the log at startup time to check for any problems. Most buildmaster activities will cause lines to be added to the log.
2.2.6.4. Shutdown
To stop a buildmaster or worker manually, use:
buildbot stop [ BASEDIR ]
# or
buildbot-worker stop [ WORKER_BASEDIR ]
This simply looks for the twistd.pid file and kills whatever process is identified within.
At system shutdown, all processes are sent a SIGKILL.
The buildmaster and worker will respond to this by shutting down normally.
The buildmaster will respond to a SIGHUP by re-reading its config file.
Of course, this only works on Unix-like systems with signal support and not on Windows.
The following shortcut is available:
buildbot reconfig [ BASEDIR ]
When you update the Buildbot code to a new release, you will need to restart the buildmaster and/or worker before they can take advantage of the new code.
You can do a buildbot stop BASEDIR and buildbot start BASEDIR in succession, or you can use the restart shortcut, which does both steps for you:
buildbot restart [ BASEDIR ]
Workers can similarly be restarted with:
buildbot-worker restart [ BASEDIR ]
There are certain configuration changes that are not handled cleanly by buildbot reconfig.
If this occurs, buildbot restart is a more robust way to fully switch over to the new configuration.
buildbot restart may also be used to start a stopped Buildbot instance.
This behavior is useful when writing scripts that stop, start, and restart Buildbot.
A worker may also be gracefully shutdown from the web UI. This is useful to shutdown a worker without interrupting any current builds. The buildmaster will wait until the worker has finished all its current builds, and will then tell the worker to shutdown.
2.3. Concepts
This chapter defines some of the basic concepts that Buildbot uses. You’ll need to understand how Buildbot sees the world to configure it properly.
2.3.1. Source identification
The following concepts are used within Buildbot to describe source code that is being built:
- Repository
A repository is a location where files tracked by a version control system reside. Usually, it is identified by a URL or a location on a disk. It contains a subset of the history of a codebase.
- Codebase
A codebase is a collection of related files and their history tracked as a unit by version control systems. The files and their history are stored in one or more repositories. For example, the primary repository for the Buildbot codebase is at
https://github.com/buildbot/buildbot/. There are also more than a thousand forks of Buildbot. These repositories, while storing potentially very old versions of Buildbot code, still contain the same codebase.- Project
A project is a set of one or more codebases that together may be built and produce some end artifact. For example, an application may be comprised of two codebases - one for the code and one for the test data, the latter of which occupies a lot of space. Building and testing such an application requires acquiring code from both codebases.
- Revision:
A revision is an textual identifier used by most version control systems to uniquely specify a particular version of the source code in a particular codebase.
- Source stamp:
A source stamp is a collection of information needed to identify a particular version of code on a certain codebase. In most version control systems, source stamps only store a revision. On other version control systems, a branch is also required.
- Source stamp set:
A source stamp set is a set of source stamps to identify a particular version of code on a certain project. Like a project is a collection of codebases, a source stamp set is a collection of source stamps, one for each codebase within a project.
In order to build a project, Buildbot only needs to know a source stamp set corresponding to that project. This source stamp set has a source stamp for each codebase comprising the project. In turn, each source stamp has enough information to identify a particular version of the code within the codebase.

2.3.2. Change sources
Change sources are user-configurable components that interact with external version control systems and retrieve new code. Internally, new code is represented as Changes which roughly correspond to a single commit or changeset. The changes are sent to the schedulers which then decide whether new builds should be created for these new code changes.
The design of Buildbot requires the workers to have their own copies of the source code, thus change sources is an optional component as long as there are no schedulers that create new builds based on new code commit events.
2.3.3. Changes
A Change is an abstract way Buildbot uses to represent a single change to the source files, performed by a developer. In version control systems that support the notion of atomic check-ins, a change represents a changeset or commit.
Changes are used for the Change sources to communicate with Schedulers.
A Change comprises the following information:
the developer who is responsible for the change
the list of files that the change added, removed or modified
the message of the commit
the repository, the codebase and the project that the change corresponds to
the revision and the branch of the commit
2.3.4. Schedulers
A scheduler is a component that decides when to start a build. The decision could be based on time, on new code being committed or on similar events.
Schedulers are responsible for creating Build Requests which identify a request to start a build on a specific version of the source code.
Each Buildmaster has a set of scheduler objects, each of which gets a copy of every incoming
Change. The Schedulers are responsible for deciding when Builds should be run.
Some Buildbot installations might have a single scheduler, while others may have several, each for
a different purpose.
2.3.5. BuildRequests
A BuildRequest is a request to start a specific build.
A BuildRequest consists of the following information:
the name of the
Builder(see below) that will perform the build.the set of
SourceStamps (see above) that specify the version of the source tree to build and/or test.
Two build requests representing the same version of the source code and the same builder may be merged. The user may configure additional restrictions for determining mergeability of build requests.
2.3.6. Builders and Build Factories
A Builder is responsible for creating new builds from BuildRequests.
Creating a new build is essentially determining the following properties of the subsequent build:
The sequence of steps to run is performed by user-configurable BuildFactory that is
attached to each Builder by the user.
A Builder will attempt to create a Build from a BuildRequest as soon as
it is possible, that is, as soon as the associated worker becomes free. When a worker becomes free,
the build master will select the oldest BuildRequest that can run on that worker and
notify the corresponding Builder to maybe start a build out of it.
Each Builder by default runs completely independently. This means, that a worker that has
N builders attached to it, may potentially attempt to run N builds concurrently. This level of
concurrency may be controlled by various kinds of Interlocks.
At a low level, each builder has its own exclusive directory on the build master and one exclusive directory on each of the workers it is attached to. The directory on the master is used for keeping status information. The directories on the workers are used as a location where the actual checkout, compilation and testing steps happen.
For easier management in the Web UI related builders may be grouped into projects.
2.3.7. Builds
A Build represents a single compile or test run of a particular version of a source code.
A build is comprised of a series of steps. The steps may be arbitrary. For example, for compiled
software a build generally consists of the checkout, configure, make, and make check sequence. For
interpreted projects like Python modules, a build is generally a checkout followed by an invocation
of the bundled test suite.
Builds are created by instances of Builder (see above).
2.3.8. BuildSets
A BuildSet represents a set of potentially not yet created Builds that all
compile and/or test the same version of the source tree. It tracks whether this set of builds as a
whole succeeded or not. The information that is stored in a BuildSet is a set of
SourceStamps which define the version of the code to test and a set of Builders
which define what builds to create.
2.3.9. Workers
A Worker corresponds to an environment where builds are executed. A single physical
machine must run at least one Worker in order for Buildbot to be able to utilize it for
running builds. Multiple Workers may run on a single machine to provide different
environments that can reuse the same hardware by means of containers or virtual machines.
Each builder is associated with one or more Workers. For example, a builder which is used
to perform macOS builds (as opposed to Linux or Windows builds) should naturally be associated with
a Mac worker.
If multiple workers are available for any given builder, you will have some measure of redundancy:
in case one worker goes offline, the others can still keep the Builder working. In
addition, multiple workers will allow multiple simultaneous builds for the same Builder,
which might be useful if you have a lot of forced or try builds taking place.
Ideally, each Worker that is configured for a builder should be identical. Otherwise build
or test failures will be dependent on which worker the build is run and this will complicate
investigations of failures.
2.3.10. Users
Buildbot has a somewhat limited awareness of users. It assumes the world consists of a set of developers, each of whom can be described by a couple of simple attributes. These developers make changes to the source code, causing builds which may succeed or fail.
Users also may have different levels of authorization when issuing Buildbot commands, such as forcing a build from the web interface or from an IRC channel.
Each developer is primarily known through the source control system. Each Change object
that arrives is tagged with a who field that typically gives the account name (on the
repository machine) of the user responsible for that change. This string is displayed on the HTML
status pages and in each Build's blamelist.
To do more with the User than just refer to them, this username needs to be mapped into an address of some sort. The responsibility for this mapping is left up to the status module which needs the address. In the future, the responsibility for managing users will be transferred to User Objects.
The who fields in git Changes are used to create User Objects, which allows for more
control and flexibility in how Buildbot manages users.
2.3.10.1. User Objects
User Objects allow Buildbot to better manage users throughout its various interactions with users (see Change Sources and Changes and Reporters). The User Objects are stored in the Buildbot database and correlate the various attributes that a user might have: irc, Git, etc.
Changes
Incoming Changes all have a who attribute attached to them that specifies which developer is
responsible for that Change. When a Change is first rendered, the who attribute is parsed and
added to the database, if it doesn’t exist, or checked against an existing user. The who
attribute is formatted in different ways depending on the version control system that the Change
came from.
gitwhoattributes take the formFull Name <Email>.svnwhoattributes are of the formUsername.hgwhoattributes are free-form strings, but usually adhere to similar conventions asgitattributes (Full Name <Email>).cvswhoattributes are of the formUsername.darcswhoattributes contain anEmailand may also include aFull Namelikegitattributes.bzrwhoattributes are free-form strings likehg, and can include aUsername,Email, and/orFull Name.
Tools
For managing users manually, use the buildbot user command, which allows you to add, remove,
update, and show various attributes of users in the Buildbot database (see
Command-line Tool).
Uses
Correlating the various bits and pieces that Buildbot views as users also means that one attribute of a user can be translated into another. This provides a more complete view of users throughout Buildbot.
One such use is being able to find email addresses based on a set of Builds to notify users through
the MailNotifier. This process is explained more clearly in Email Addresses.
Another way to utilize User Objects is through UsersAuth for web authentication. To use
UsersAuth, you need to set a bb_username and bb_password via the buildbot user command
line tool to check against. The password will be encrypted before it gets stored in the database
along with other user attributes.
2.3.10.2. Doing Things With Users
Each change has a single user who is responsible for it. Most builds have a set of changes: the build generally represents the first time these changes have been built and tested by the Buildbot. The build has a blamelist that is the union of the users responsible for all of the build’s changes. If the build was created by a Try Schedulers this list will include the submitter of the try job if known.
The build provides a list of users who are interested in the build – the interested users. Usually this is equal to the blamelist, but may also be expanded, e.g., to include the current build sherrif or a module’s maintainer.
If desired, buildbot can notify the interested users until the problem is resolved.
2.3.10.3. Email Addresses
The MailNotifier is a status target which can send emails about the results of each
build. It accepts a static list of email addresses to which each message should be delivered, but
it can also be configured to send emails to a Build's Interested Users. To do this, it
needs a way to convert User names into email addresses.
For many VCSs, the User name is actually an account name on the system which hosts the repository.
As such, turning the name into an email address is simply a matter of appending
@repositoryhost.com. Some projects use other kinds of mappings (for example the preferred email
address may be at project.org, despite the repository host being named cvs.project.org),
and some VCSs have full separation between the concept of a user and that of an account on the
repository host (like Perforce). Some systems (like Git) put a full contact email address in every
change.
To convert these names to addresses, the MailNotifier uses an EmailLookup object.
This provides a getAddress method which accepts a name and (eventually) returns an address.
The default MailNotifier module provides an EmailLookup which simply appends a
static string, configurable when the notifier is created. To create more complex behaviors (perhaps
using an LDAP lookup, or using finger on a central host to determine a preferred address for
the developer), provide a different object as the lookup argument.
If an EmailLookup object isn’t given to the MailNotifier, the MailNotifier will try to find emails
through User Objects. If every user in the Build’s Interested Users list has an email in the
database for them, this will work the same as if an EmailLookup object was used. If a user whose
change led to a Build doesn’t have an email attribute, that user will not receive an email. If
extraRecipients is given, those users still get an email when the EmailLookup object is not
specified.
In the future, when the Problem mechanism has been set up, Buildbot will need to send emails to
arbitrary Users. It will do this by locating a MailNotifier-like object among all the
buildmaster’s status targets, and asking it to send messages to various Users. This means the
User-to-address mapping only has to be set up once, in your MailNotifier, and every email
message buildbot emits will take advantage of it.
2.3.10.4. IRC Nicknames
Like MailNotifier, the buildbot.reporters.irc.IRC class provides a status target
which can announce the results of each build. It also provides an interactive interface by
responding to online queries posted in the channel or sent as private messages.
In the future, buildbot can be configured to map User names to IRC nicknames, to watch for the
recent presence of these nicknames, and to deliver build status messages to the interested parties.
Like MailNotifier does for email addresses, the IRC object will have an
IRCLookup which is responsible for nicknames. The mapping can be set up statically, or it
can be updated by online users themselves (by claiming a username with some kind of buildbot: i
am user warner commands).
Once the mapping is established, buildbot can then ask the IRC object to send messages to
various users. It can report on the likelihood that the user saw the given message (based upon how
long the user has been inactive on the channel), which might prompt the Problem Hassler logic to
send them an email message instead.
These operations and authentication of commands issued by particular nicknames will be implemented in User Objects.
2.3.11. Build Properties
Each build has a set of Build Properties, which can be used by its build steps to modify their actions.
The properties are represented as a set of key-value pairs. Effectively, a single property is a variable that, once set, can be used by subsequent steps in a build to modify their behaviour. The value of a property can be a number, a string, a list or a dictionary. Lists and dictionaries can contain other lists or dictionaries. Thus, the value of a property could be any arbitrarily complex structure.
Properties work pretty much like variables, so they can be used to implement all manner of functionality.
The following are a couple of examples:
By default, the name of the worker that runs the build is set to the
workernameproperty. If there are multiple different workers and the actions of the build depend on the exact worker, some users may decide that it’s more convenient to vary the actions depending on theworkernameproperty instead of creating separate builders for each worker.In most cases, the build does not know the exact code revision that will be tested until it checks out the code. This information is only known after a source step runs. To give this information to the subsequent steps, the source step records the checked out revision into the
got_revisionproperty.
2.4. Secret Management
2.4.1. Requirements
Buildbot steps might need secrets to execute their actions. Secrets are used to execute commands or to create authenticated network connections. Secrets may be a SSH key, a password, or a file content like a wgetrc file or a public SSH key. To preserve confidentiality, the secret values must not be printed or logged in the twisted or step logs. Secrets must not be stored in the Buildbot configuration (master.cfg), as the source code is usually shared in SCM like git.
2.4.2. How to use Buildbot Secret Management
2.4.2.1. Secrets and providers
Buildbot implements several providers for secrets retrieval:
File system based: secrets are written in a file. This is a simple solution for example when secrets are managed by a config management system like Ansible Vault.
Third party backend based: secrets are stored by a specialized software. These solutions are usually more secure.
Secrets providers are configured if needed in the master configuration. Multiple providers can be configured at once. The secret manager is a Buildbot service. The secret manager returns the specific provider results related to the providers registered in the configuration.
2.4.2.2. How to use secrets in Buildbot
Secret can be used in Buildbot via the IRenderable mechanism.
Two IRenderable actually implement secrets.
Interpolate can be used if you need to mix secrets and other interpolation in the same argument.
Secret can be used if your secret is directly used as a component argument.
Secret
Secret is a simple renderable which directly renders a secret.
Secret("secretName")
As argument to steps
The following example shows a basic usage of secrets in Buildbot.
from buildbot.plugins import secrets, util
# First we declare that the secrets are stored in a directory of the filesystem
# each file contains one secret identified by the filename
c['secretsProviders'] = [secrets.SecretInAFile(dirname="/path/toSecretsFiles")]
# then in a buildfactory:
# use a secret on a shell command via Interpolate
f1.addStep(ShellCommand(
util.Interpolate("wget -u user -p '%(secret:userpassword)s' '%(prop:urltofetch)s'")))
# .. or non shell form:
f1.addStep(ShellCommand(["wget", "-u", "user", "-p",
util.Secret("userpassword"),
util.Interpolate("%(prop:urltofetch)s")]))
Secrets are also interpolated in the build like properties are. Their values will be used in a command line for example.
As argument to services
You can use secrets to configure services. All services arguments are not compatible with secrets. See their individual documentation for details.
# First we declare that the secrets are stored in a directory of the filesystem
# each file contains one secret identified by the filename
c['secretsProviders'] = [secrets.SecretInAFile(dirname="/path/toSecretsFiles")]
# then for a reporter:
c['services'] = [GitHubStatusPush(token=util.Secret("githubToken"))]
2.4.2.3. Secrets storages
SecretInAFile
c['secretsProviders'] = [secrets.SecretInAFile(dirname="/path/toSecretsFiles")]
In the passed directory, every file contains a secret identified by the filename.
e.g: a file user contains the text pa$$w0rd.
Arguments:
dirname(required) Absolute path to directory containing the files with a secret.
strip(optional) if
True(the default), trailing newlines are removed from the file contents.
HashiCorpVaultKvSecretProvider
c['secretsProviders'] = [
secrets.HashiCorpVaultKvSecretProvider(
authenticator=secrets.VaultAuthenticatorApprole(roleId="<role-guid>",
secretId="<secret-guid>"),
vault_server="http://localhost:8200",
secrets_mount="kv")
]
HashiCorpVaultKvSecretProvider allows to use HashiCorp Vault KV secret engine as secret provider. Other secret engines are not supported by this particular provider. For more information about Vault please visit: Vault: https://www.vaultproject.io/
In order to use this secret provider, optional dependency hvac needs to be installed (pip
install hvac).
It supports different authentication methods with ability to re-authenticate when authentication
token expires (not possible using HvacAuthenticatorToken).
Parameters accepted by HashiCorpVaultKvSecretProvider:
authenticator: required parameter, specifies Vault authentication method. Possible authenticators are:
VaultAuthenticatorToken(token): simplest authentication by directly providing the authentication token. This method cannot benefit from re-authentication mechanism and when token expires, secret provider will just stop working.
VaultAuthenticatorApprole(roleId, secretId): approle authentication using roleId and secretId. This is common method for automation tools fetching secrets from vault.
vault_server: required parameter, specifies URL of vault server.
secrets_mount: specifies mount point of KV secret engine in vault, default value is “secret”.
api_version: version of vault KV secret engine. Supported versions are 1 and 2, default value is 2.
path_delimiter: character used to separate path and key name in secret identifiers. Default value is “|”.
path_escape: escape character used in secret identifiers to allow escaping ofpath_delimitercharacter in path or key values. Default value is “".
The secret identifiers that need to be passed to, e.g. Interpolate, have format:
"path/to/secret:key". In case path or key name does contain colon character, it is possible to
escape it using “" or specify different separator character using path_delimiter parameter
when initializing secret provider.
Example use:
passwd = util.Secret('path/to/secret:password')
SecretInPass
c['secretsProviders'] = [secrets.SecretInPass(
gpgPassphrase="passphrase",
dirname="/path/to/password/store"
)]
Passwords can be stored in a unix password store, encrypted using GPG keys. Buildbot can query
secrets via the pass binary found in the PATH of each worker. While pass allows for
multiline entries, the secret must be on the first line of each entry. The only caveat is that all
passwords Buildbot needs to access have to be encrypted using the same GPG key.
For more information about pass, please visit pass: https://www.passwordstore.org/
Arguments:
gpgPassphrase(optional) Pass phrase to the GPG decryption key, if any
dirname(optional) Absolute path to the password store directory, defaults to ~/.password-store
2.4.2.4. How to populate secrets in a build
To populate secrets in files during a build, 2 steps are used to create and delete the files on the worker. The files will be automatically deleted at the end of the build.
f = BuildFactory()
with f.withSecrets(secrets_list):
f.addStep(step_definition)
or
f = BuildFactory()
f.addSteps([list_of_step_definitions], withSecrets=secrets_list)
In both cases the secrets_list is a list of (secret path, secret value) tuples.
secrets_list = [('/first/path', Interpolate('write something and %(secret:somethingmore)s')),
('/second/path', Interpolate('%(secret:othersecret)s'))]
The Interpolate class is used to render the value during the build execution.
2.4.2.5. How to configure a Vault instance
Vault being a very generic system, it can be complex to install for the first time. Here is a simple tutorial to install the minimal Vault to use with Buildbot.
Use Docker to install Vault
A Docker image is available to help users installing Vault. Without any arguments, the command launches a Docker Vault developer instance, easy to use and test the functions. The developer version is already initialized and unsealed. To launch a Vault server please refer to the VaultDocker documentation:
In a shell:
docker run vault
Starting the vault instance
Once the Docker image is created, launch a shell terminal on the Docker image:
docker exec -i -t ``docker_vault_image_name`` /bin/sh
Then, export the environment variable VAULT_ADDR needed to init Vault.
export VAULT_ADDR='vault.server.adress'
Writing secrets
By default the official docker instance of Vault is initialized with a mount path of ‘secret’, a KV v1 secret engine, and a second KV engine (v2) at ‘secret/data’. Currently, Buildbot is “hard wired” to expect KV v2 engines to reside within this “data” sub path. Provision is made to set a top level path via the “secretsmount” argument: defaults to “secret”. To add a new secret:
vault kv put secret/new_secret_key value=new_secret_value
2.5. Configuration
The following sections describe the configuration of the various Buildbot components. The information available here is sufficient to create basic build and test configurations, and does not assume great familiarity with Python.
In more advanced Buildbot configurations, Buildbot acts as a framework for a continuous-integration application. The next section, Customization, describes this approach, with frequent references into the development documentation.
2.5.1. Configuring Buildbot
Buildbot’s behavior is defined by the config file, which normally lives in the master.cfg file in the buildmaster’s base directory (but this can be changed with an option to the buildbot create-master command).
This file completely specifies which Builders are to be run, which workers they should use, how Changes should be tracked, and where the status information is to be sent.
The buildmaster’s buildbot.tac file names the base directory; everything else comes from the config file.
A sample config file was installed for you when you created the buildmaster, but you will need to edit it before your Buildbot will do anything useful.
This chapter gives an overview of the format of this file and the various sections in it. You will need to read the later chapters to understand how to fill in each section properly.
2.5.1.1. Config File Format
The config file is, fundamentally, just a piece of Python code which defines a dictionary named BuildmasterConfig, with a number of keys that are treated specially.
You don’t need to know Python to do the basic configuration, though; you can just copy the sample file’s syntax.
If you are comfortable writing Python code, however, you can use all the power of a full programming language to build more complicated configurations.
The BuildmasterConfig name is the only one which matters: all other names defined during the execution of the file are discarded.
When parsing the config file, the Buildmaster generally compares the old configuration with the new one and performs the minimum set of actions necessary to bring Buildbot up to date: Builders which are not changed are left untouched, and Builders which are modified get to keep their old event history.
The beginning of the master.cfg file typically starts with something like:
BuildmasterConfig = c = {}
Therefore a config key like change_source will usually appear in master.cfg as c['change_source'].
See Buildmaster Configuration Index for a full list of BuildMasterConfig keys.
Basic Python Syntax
The master configuration file is interpreted as Python, allowing the full flexibility of the language. For the configurations described in this section, a detailed knowledge of Python is not required, but the basic syntax is easily described.
Python comments start with a hash character #, tuples are defined with (parenthesis, pairs), and lists (arrays) are defined with [square, brackets].
Tuples and lists are mostly interchangeable.
Dictionaries (data structures which map keys to values) are defined with curly braces: {'key1': value1, 'key2': value2}.
Function calls (and object instantiations) can use named parameters, like steps.ShellCommand(command=["trial", "hello"]).
The config file starts with a series of import statements, which make various kinds of Steps and Status targets available for later use.
The main BuildmasterConfig dictionary is created, and then it is populated with a variety of keys, described section-by-section in the subsequent chapters.
2.5.1.2. Predefined Config File Symbols
The following symbols are automatically available for use in the configuration file.
basedirthe base directory for the buildmaster. This string has not been expanded, so it may start with a tilde. It needs to be expanded before use. The config file is located in:
os.path.expanduser(os.path.join(basedir, 'master.cfg'))
__file__the absolute path of the config file. The config file’s directory is located in
os.path.dirname(__file__).
2.5.1.3. Testing the Config File
To verify that the config file is well-formed and contains no deprecated or invalid elements, use the checkconfig command, passing it either a master directory or a config file.
% buildbot checkconfig master.cfg
Config file is good!
# or
% buildbot checkconfig /tmp/masterdir
Config file is good!
If the config file has deprecated features (perhaps because you’ve upgraded the buildmaster and need to update the config file to match), they will be announced by checkconfig. In this case, the config file will work, but you should really remove the deprecated items and use the recommended replacements instead:
% buildbot checkconfig master.cfg
/usr/lib/python2.4/site-packages/buildbot/master.py:559: DeprecationWarning: c['sources'] is
deprecated as of 0.7.6 and will be removed by 0.8.0 . Please use c['change_source'] instead.
Config file is good!
If you have errors in your configuration file, checkconfig will let you know:
% buildbot checkconfig master.cfg
Configuration Errors:
c['workers'] must be a list of Worker instances
no workers are configured
builder 'smoketest' uses unknown workers 'linux-002'
If the config file is simply broken, that will be caught too:
% buildbot checkconfig master.cfg
error while parsing config file:
Traceback (most recent call last):
File "/home/buildbot/master/bin/buildbot", line 4, in <module>
runner.run()
File "/home/buildbot/master/buildbot/scripts/runner.py", line 1358, in run
if not doCheckConfig(so):
File "/home/buildbot/master/buildbot/scripts/runner.py", line 1079, in doCheckConfig
return cl.load(quiet=quiet)
File "/home/buildbot/master/buildbot/scripts/checkconfig.py", line 29, in load
self.basedir, self.configFileName)
--- <exception caught here> ---
File "/home/buildbot/master/buildbot/config.py", line 147, in loadConfig
exec f in localDict
exceptions.SyntaxError: invalid syntax (master.cfg, line 52)
Configuration Errors:
error while parsing config file: invalid syntax (master.cfg, line 52) (traceback in logfile)
2.5.1.4. Loading the Config File
The config file is only read at specific points in time. It is first read when the buildmaster is launched.
Note
If the configuration is invalid, the master will display the errors in the console output, but will not exit.
Reloading the Config File (reconfig)
If you are on the system hosting the buildmaster, you can send a SIGHUP signal to it: the buildbot tool has a shortcut for this:
buildbot reconfig BASEDIR
This command will show you all of the lines from twistd.log that relate to the reconfiguration.
If there are any problems during the config-file reload, they will be displayed in the output.
When reloading the config file, the buildmaster will endeavor to change as little as possible about the running system.
For example, although old status targets may be shut down and new ones started up, any status targets that were not changed since the last time the config file was read will be left running and untouched.
Likewise any Builders which have not been changed will be left running.
If a Builder is modified (say, the build command is changed), this change will apply only for new Builds.
Any existing build that is currently running or was already queued will be allowed to finish using the old configuration.
Note that if any lock is renamed, old and new instances of the lock will be completely unrelated in the eyes of the buildmaster. This means that buildmaster will be able to start new builds that would otherwise have waited for the old lock to be released.
Warning
Buildbot’s reconfiguration system is fragile for a few difficult-to-fix reasons:
Any modules imported by the configuration file are not automatically reloaded. Python modules such as https://docs.python.org/3/library/importlib.html and importlib.reload() may help here, but reloading modules is fraught with subtleties and difficult-to-decipher failure cases.
During the reconfiguration, active internal objects are divorced from the service hierarchy, leading to tracebacks in the web interface and other components. These are ordinarily transient, but with HTTP connection caching (either by the browser or an intervening proxy) they can last for a long time.
If the new configuration file is invalid, it is possible for Buildbot’s internal state to be corrupted, leading to undefined results. When this occurs, it is best to restart the master.
For more advanced configurations, it is impossible for Buildbot to tell if the configuration for a
BuilderorSchedulerhas changed, and thus theBuilderorSchedulerwill always be reloaded. This occurs most commonly when a callable is passed as a configuration parameter.
The bbproto project (at https://github.com/dabrahams/bbproto) may help to construct large (multi-file) configurations which can be effectively reloaded and reconfigured.
2.5.2. Global Configuration
The keys in this section affect the operations of the buildmaster globally.
2.5.2.1. Database Specification
Buildbot requires a connection to a database to maintain certain state information, such as
tracking pending build requests. In the default configuration Buildbot uses a file-based SQLite
database, stored in the state.sqlite file of the master’s base directory.
Important
SQLite3 is perfectly suitable for small setups with a few users. However, it does not scale well with large numbers of builders, workers and users. If you expect your Buildbot to grow over time, it is strongly advised to use a real database server (e.g., MySQL or Postgres).
A SQLite3 database may be migrated to a real database server using buildbot copy-db script.
See the Using A Database Server section for more details.
Override this configuration with the db_url parameter.
Buildbot accepts a database configuration in a dictionary named db.
All keys are optional:
c['db'] = {
'db_url' : 'sqlite:///state.sqlite',
}
The db_url key indicates the database engine to use. The format of this parameter is completely
documented at http://www.sqlalchemy.org/docs/dialects/, but is generally of the form:
"driver://[username:password@]host:port/database[?args]"
This parameter can be specified directly in the configuration dictionary, as c['db_url'],
although this method is deprecated.
Buildbot also accepts a dictionary at c['db']['engine_kwargs'], this dictionary eventually ends
up being passed to SQLAlchemy’s create_engine function, see
https://docs.sqlalchemy.org/en/latest/core/engines.html#sqlalchemy.create_engine for details. As an
example, one may configure the amount of connections opened to PostgreSQL like so:
c['db'] = {
'db_url': "postgresql://username:password@hostname/dbname",
'engine_kwargs': {
'pool_size': 512,
'max_overflow': 0,
},
}
The following sections give additional information for particular database backends:
SQLite
For sqlite databases, since there is no host and port, relative paths are specified with
sqlite:/// and absolute paths with sqlite:////. For example:
c['db_url'] = "sqlite:///state.sqlite"
SQLite requires no special configuration.
MySQL
c['db_url'] = "mysql://username:password@example.com/database_name?max_idle=300"
The max_idle argument for MySQL connections is unique to Buildbot and should be set to
something less than the wait_timeout configured for your server. This controls the SQLAlchemy
pool_recycle parameter, which defaults to no timeout. Setting this parameter ensures that
connections are closed and re-opened after the configured amount of idle time. If you see errors
such as _mysql_exceptions.OperationalError: (2006, 'MySQL server has gone away'), this means
your max_idle setting is probably too high. show global variables like 'wait_timeout'; will
show what the currently configured wait_timeout is on your MySQL server.
Buildbot requires use_unique=True and charset=utf8, and will add them automatically, so
they do not need to be specified in db_url.
MySQL defaults to the MyISAM storage engine, but this can be overridden with the storage_engine
URL argument.
Postgres
c['db_url'] = "postgresql://username:password@hostname/dbname"
PosgreSQL requires no special configuration.
2.5.2.2. MQ Specification
Buildbot uses a message-queueing system to handle communication within the master. Messages are used to indicate events within the master, and components that are interested in those events arrange to receive them.
The message queueing implementation is configured as a dictionary in the mq option.
The type key describes the type of MQ implementation to be used.
Note that the implementation type cannot be changed in a reconfig.
The available implementation types are described in the following sections.
Simple
c['mq'] = {
'type' : 'simple',
'debug' : False,
}
This is the default MQ implementation. Similar to SQLite, it has no additional software dependencies, but does not support multi-master mode.
Note that this implementation also does not support message persistence across a restart of the master. For example, if a change is received, but the master shuts down before the schedulers can create build requests for it, then those schedulers will not be notified of the change when the master starts again.
The debug key, which defaults to False, can be used to enable logging of every message produced on this master.
Wamp
Note
At the moment, wamp is the only message queue implementation for multimaster. It has been
privileged as this is the only message queue that has very solid support for Twisted. Other
more common message queue systems like RabbitMQ (using the AMQP protocol) do not have a
convincing driver for twisted, and this would require to run on threads, which will add an
important performance overhead.
c['mq'] = {
'type' : 'wamp',
'router_url': 'ws://localhost:8080/ws',
'realm': 'realm1',
# valid are: none, critical, error, warn, info, debug, trace
'wamp_debug_level' : 'error'
}
This is a MQ implementation using the wamp protocol. This implementation uses Python Autobahn wamp client library, and is fully asynchronous (no use of threads). To use this implementation, you need a wamp router like Crossbar.
The implementation does not yet support wamp authentication. This MQ allows buildbot to run in multi-master mode.
Note that this implementation also does not support message persistence across a restart of the master. For example, if a change is received, but the master shuts down before the schedulers can create build requests for it, then those schedulers will not be notified of the change when the master starts again.
router_url(mandatory): points to your router websocket url.Buildbot is only supporting wamp over websocket, which is a sub-protocol of http. SSL is supported using
wss://instead ofws://.
realm (optional, defaults to buildbot): defines the wamp realm to use for your buildbot messages.
wamp_debug_level (optional, defaults to error): defines the log level of autobahn.
You must use a router with very reliable connection to the master. If for some reason, the wamp connection is lost, then the master will stop, and should be restarted via a process manager.
Crossbar
The default Crossbar setup will just work with Buildbot, provided you use the example mq
configuration below, and start Crossbar with:
# of course, you should work in a virtualenv...
pip install crossbar
crossbar init
crossbar start
.crossbar/config.json:
{
"version": 2,
"controller": {},
"workers": [
{
"type": "router",
"realms": [
{
"name": "test_realm",
"roles": [
{
"name": "anonymous",
"permissions": [
{
"uri": "",
"match": "prefix",
"allow": {
"call": true,
"register": true,
"publish": true,
"subscribe": true
},
"disclose": {
"caller": false,
"publisher": false
},
"cache": true
}
]
}
]
}
],
"transports": [
{
"type": "web",
"endpoint": {
"type": "tcp",
"port": 1245
},
"paths": {
"ws": {
"type": "websocket"
}
}
}
]
}
]
}
Buildbot can be configured to use Crossbar by the following:
c["mq"] = {
"type" : "wamp",
"router_url": "ws://localhost:1245/ws",
"realm": "test_realm",
"wamp_debug_level" : "warn"
}
Please refer to Crossbar documentation for more details.
2.5.2.3. Multi-master mode
See Multimaster for details on the multi-master mode in Buildbot Nine.
By default, Buildbot makes coherency checks that prevent typos in your master.cfg.
It makes sure schedulers are not referencing unknown builders, and enforces there is at least one builder.
In the case of an asymmetric multimaster, those coherency checks can be harmful and prevent you to implement what you want. For example, you might want to have one master dedicated to the UI, so that a big load generated by builds will not impact page load times.
To enable multi-master mode in this configuration, you will need to set the multiMaster
option so that buildbot doesn’t warn about missing schedulers or builders.
# Enable multiMaster mode; disables warnings about unknown builders and
# schedulers
c['multiMaster'] = True
c['db'] = {
'db_url' : 'mysql://...',
}
c['mq'] = { # Need to enable multimaster aware mq. Wamp is the only option for now.
'type' : 'wamp',
'router_url': 'ws://localhost:8080',
'realm': 'realm1',
# valid are: none, critical, error, warn, info, debug, trace
'wamp_debug_level' : 'error'
}
2.5.2.4. Site Definitions
Three basic settings describe the buildmaster in status reports:
c['title'] = "Buildbot"
c['titleURL'] = "http://buildbot.sourceforge.net/"
title is a short string that will appear at the top of this buildbot installation’s home
page (linked to the titleURL).
titleURL is a URL string.
HTML status displays will show title as a link to titleURL.
This URL is often used to provide a link from buildbot HTML pages to your project’s home page.
The buildbotURL string should point to the location where the buildbot’s internal web
server is visible.
When status notices are sent to users (e.g., by email or over IRC), buildbotURL will be
used to create a URL to the specific build or problem that they are being notified about.
2.5.2.5. Log Handling
c['logCompressionMethod'] = 'gz'
c['logMaxSize'] = 1024*1024 # 1M
c['logMaxTailSize'] = 32768
c['logEncoding'] = 'utf-8'
The logCompressionLimit enables compression of build logs on disk for logs that are
bigger than the given size, or disables that completely if set to False. The default value is
4096, which should be a reasonable default on most file systems. This setting has no impact on
status plugins, and merely affects the required disk space on the master for build logs.
The logCompressionMethod controls what type of compression is used for build logs. Valid
option are ‘raw’ (no compression), ‘gz’, ‘lz4’ (required lz4 package), ‘br’ (requires
buildbot[brotli] extra) or ‘zstd’ (requires buildbot[zstd] extra). The default is ‘zstd’ if the
buildbot[zstd] is installed, otherwise defaults to ‘gz’.
Please find below some stats extracted from 50x “trial Pyflakes” runs (results may differ according to log type).
compression |
raw log size |
compressed log size |
space saving |
compression speed |
|---|---|---|---|---|
bz2 |
2.981 MB |
0.603 MB |
79.77% |
3.433 MB/s |
gz |
2.981 MB |
0.568 MB |
80.95% |
6.604 MB/s |
lz4 |
2.981 MB |
0.844 MB |
71.68% |
77.668 MB/s |
The logMaxSize parameter sets an upper limit (in bytes) to how large logs from an
individual build step can be. The default value is None, meaning no upper limit to the log size.
Any output exceeding logMaxSize will be truncated, and a message to this effect will be
added to the log’s HEADER channel.
If logMaxSize is set, and the output from a step exceeds the maximum, the
logMaxTailSize parameter controls how much of the end of the build log will be kept. The
effect of setting this parameter is that the log will contain the first logMaxSize bytes
and the last logMaxTailSize bytes of output. Don’t set this value too high, as the tail
of the log is kept in memory.
The logEncoding parameter specifies the character encoding to use to decode bytestrings
provided as logs. It defaults to utf-8, which should work in most cases, but can be overridden
if necessary. In extreme cases, a callable can be specified for this parameter. It will be called
with byte strings, and should return the corresponding Unicode string.
This setting can be overridden for a single build step with the logEncoding step parameter. It
can also be overridden for a single log file by passing the logEncoding parameter to
addLog.
2.5.2.6. Data Lifetime
Horizons
Previously Buildbot implemented a global configuration for horizons. Now it is implemented as a
utility Builder, and shall be configured via the JanitorConfigurator.
Caches
c['caches'] = {
'Changes' : 100, # formerly c['changeCacheSize']
'Builds' : 500, # formerly c['buildCacheSize']
'chdicts' : 100,
'BuildRequests' : 10,
'SourceStamps' : 20,
'ssdicts' : 20,
'objectids' : 10,
'usdicts' : 100,
}
The caches configuration key contains the configuration for Buildbot’s in-memory caches.
These caches keep frequently-used objects in memory to avoid unnecessary trips to the database.
Caches are divided by object type, and each has a configurable maximum size.
The default size for each cache is 1, except where noted below. A value of 1 allows Buildbot to make a number of optimizations without consuming much memory. Larger, busier installations will likely want to increase these values.
The available caches are:
Changesthe number of change objects to cache in memory. This should be larger than the number of changes that typically arrive in the span of a few minutes, otherwise your schedulers will be reloading changes from the database every time they run. For distributed version control systems, like Git or Hg, several thousand changes may arrive at once, so setting this parameter to something like 10000 isn’t unreasonable.
This parameter is the same as the deprecated global parameter
changeCacheSize. Its default value is 10.BuildsThe
buildCacheSizeparameter gives the number of builds for each builder which are cached in memory. This number should be larger than the number of builds required for commonly-used status displays (the waterfall or grid views), so that those displays do not miss the cache on a refresh.This parameter is the same as the deprecated global parameter
buildCacheSize. Its default value is 15.chdictsThe number of rows from the
changestable to cache in memory. This value should be similar to the value forChanges.BuildRequestsThe number of BuildRequest objects kept in memory. This number should be higher than the typical number of outstanding build requests. If the master ordinarily finds jobs for BuildRequests immediately, you may set a lower value.
SourceStampsthe number of SourceStamp objects kept in memory. This number should generally be similar to the number
BuildRequesets.ssdictsThe number of rows from the
sourcestampstable to cache in memory. This value should be similar to the value forSourceStamps.objectidsThe number of object IDs - a means to correlate an object in the Buildbot configuration with an identity in the database–to cache. In this version, object IDs are not looked up often during runtime, so a relatively low value such as 10 is fine.
usdictsThe number of rows from the
userstable to cache in memory. Note that for a given user there will be a row for each attribute that user has.c[‘buildCacheSize’] = 15
2.5.2.7. Merging Build Requests
c['collapseRequests'] = True
This is a global default value for builders’ collapseRequests parameter, and controls the
merging of build requests.
This parameter can be overridden on a per-builder basis. See Collapsing Build Requests for the allowed values for this parameter.
2.5.2.8. Prioritizing Builders
def prioritizeBuilders(buildmaster, builders):
...
c['prioritizeBuilders'] = prioritizeBuilders
By default, buildbot will attempt to start builds on builders in order, beginning with the builder
with the oldest pending request. Customize this behavior with the prioritizeBuilders
configuration key, which takes a callable. See Builder Priority Functions for details on
this callable.
This parameter controls the order that the buildmaster can start builds, and is useful in situations where there is resource contention between builders, e.g., for a test database. It does not affect the order in which a builder processes the build requests in its queue. For that purpose, see Prioritizing Builds.
2.5.2.9. Prioritizing Workers
By default Buildbot will select worker for a build randomly from available workers. This can be
adjusted by select_next_worker function in global master configuration and additionally by
nextWorker per-builder configuration parameter. These two functions work exactly the same:
The function is passed three arguments, the Builder object which is assigning a new job,
a list of WorkerForBuilder objects and the BuildRequest.
The function should return one of the WorkerForBuilder objects, or None if none of the
available workers should be used. The function can optionally return a Deferred, which should fire
with the same results.
def select_next_worker(builder, workers, buildrequest):
...
c["select_next_worker"] = select_next_worker
2.5.2.10. Configuring worker protocols
The protocols key defines how buildmaster listens to connections from workers. The value of
the key is dictionary with keys being protocol names and values being per-protocol configuration.
The following protocols are supported:
pb- Perspective Broker protocol. This protocol supports not only connections from workers, but also remote Change Sources, status clients and debug tools. It supports the following configuration:port- specifies the listening port configuration. This may be a numeric port, or a connection string, as defined in the ConnectionStrings guide.
msgpack_experimental_v7- (experimental) MessagePack-based protocol. It supports the following configuration:port- specifies the listening port configuration. This may be a numeric port, or a connection string, as defined in the ConnectionStrings guide.
Note
Note, that the master host must be visible to all workers that would attempt to connect to it. The firewall (if any) must be configured to allow external connections. Additionally, the configured listen port must be larger than 1024 in most cases, as lower ports are usually restricted to root processes only.
The following is a minimal example of protocol configuration:
c['protocols'] = {"pb": {"port": 10000}}
The following example only allows connections from localhost. This might be useful in cases workers
are run on the same machine as master (e.g. in very small Buildbot installations). The workers would
need to be configured to contact the buildmaster at localhost:10000.
c['protocols'] = {"pb": {"port": "tcp:10000:interface=127.0.0.1"}}
The following example shows how to configure worker connections via TLS:
c['protocols'] = {"pb": {"port":
"ssl:9989:privateKey=master.key:certKey=master.crt"}}
Please note that IPv6 addresses with : must be escaped with as well as : in paths and in paths. Read more about the connection strings format in ConnectionStrings documentation.
See also Worker TLS Configuration
2.5.2.11. Defining Global Properties
The properties configuration key defines a dictionary of properties that will be
available to all builds started by the buildmaster:
c['properties'] = {
'Widget-version' : '1.2',
'release-stage' : 'alpha'
}
2.5.2.12. Manhole
Manhole is an interactive Python shell which allows full access to the Buildbot master instance. It is probably only useful for buildbot developers.
See documentation on Manhole implementations for available authentication and connection methods.
The manhole configuration key accepts a single instance of a Manhole class.
For example:
from buildbot import manhole
c['manhole'] = manhole.PasswordManhole("tcp:1234:interface=127.0.0.1",
"admin", "passwd",
ssh_hostkey_dir="data/ssh_host_keys")
2.5.2.13. Metrics Options
c['metrics'] = {
"log_interval": 10,
"periodic_interval": 10
}
metrics can be a dictionary that configures various aspects of the metrics subsystem.
If metrics is None, then metrics collection, logging and reporting will be disabled.
log_interval determines how often metrics should be logged to twistd.log.
It defaults to 60s.
If set to 0 or None, then logging of metrics will be disabled.
This value can be changed via a reconfig.
periodic_interval determines how often various non-event based metrics are collected, such as
memory usage, uncollectable garbage, reactor delay. This defaults to 10s. If set to 0 or None,
then periodic collection of this data is disabled. This value can also be changed via a reconfig.
Read more about metrics in the Metrics section in the developer documentation.
2.5.2.14. Statistics Service
The Statistics Service (stats service for short) supports the collection of arbitrary data from
within a running Buildbot instance and the export to a number of storage backends. Currently, only
InfluxDB is supported as a storage backend. Also, InfluxDB (or any other storage backend) is not
a mandatory dependency. Buildbot can run without it, although StatsService will be of no
use in such a case. At present, StatsService can keep track of build properties, build
times (start, end, duration) and arbitrary data produced inside Buildbot (more on this later).
Example usage:
captures = [stats.CaptureProperty('Builder1', 'tree-size-KiB'),
stats.CaptureBuildDuration('Builder2')]
c['services'] = []
c['services'].append(stats.StatsService(
storage_backends=[
stats.InfluxStorageService('localhost', 8086, 'root', 'root', 'test', captures)
], name="StatsService"))
The services configuration value should be initialized as a list and a StatsService instance should be appended to it as shown in the example above.
Statistics Service
- class buildbot.statistics.stats_service.StatsService
This is the main class for statistics services. It is initialized in the master configuration as shown in the example above. It takes two arguments:
storage_backendsA list of storage backends (see Storage Backends). In the example above,
stats.InfluxStorageServiceis an instance of a storage backend. Each storage backend is an instance of subclasses ofstatsStorageBase.nameThe name of this service.
yieldMetricsValue: This method can be used to send arbitrary data for storage. (See Using StatsService.yieldMetricsValue for more information.)
Capture Classes
- class buildbot.statistics.capture.CaptureProperty
Instance of this class declares which properties must be captured and sent to the Storage Backends. It takes the following arguments:
builder_nameThe name of builder in which the property is recorded.
property_nameThe name of property needed to be recorded as a statistic.
callback=None(Optional) A custom callback function for this class. This callback function should take in two arguments - build_properties (dict) and property_name (str) and return a string that will be sent for storage in the storage backends.
regex=FalseIf this is set to
True, then the property name can be a regular expression. All properties matching this regular expression will be sent for storage.
- class buildbot.statistics.capture.CapturePropertyAllBuilders
Instance of this class declares which properties must be captured on all builders and sent to the Storage Backends. It takes the following arguments:
property_nameThe name of property needed to be recorded as a statistic.
callback=None(Optional) A custom callback function for this class. This callback function should take in two arguments - build_properties (dict) and property_name (str) and return a string that will be sent for storage in the storage backends.
regex=FalseIf this is set to
True, then the property name can be a regular expression. All properties matching this regular expression will be sent for storage.
- class buildbot.statistics.capture.CaptureBuildStartTime
Instance of this class declares which builders’ start times are to be captured and sent to Storage Backends. It takes the following arguments:
builder_nameThe name of builder whose times are to be recorded.
callback=None(Optional) A custom callback function for this class. This callback function should take in a Python datetime object and return a string that will be sent for storage in the storage backends.
- class buildbot.statistics.capture.CaptureBuildStartTimeAllBuilders
Instance of this class declares start times of all builders to be captured and sent to Storage Backends. It takes the following arguments:
callback=None(Optional) A custom callback function for this class. This callback function should take in a Python datetime object and return a string that will be sent for storage in the storage backends.
- class buildbot.statistics.capture.CaptureBuildEndTime
Exactly like
CaptureBuildStartTimeexcept it declares the builders whose end time is to be recorded. The arguments are same asCaptureBuildStartTime.
- class buildbot.statistics.capture.CaptureBuildEndTimeAllBuilders
Exactly like
CaptureBuildStartTimeAllBuildersexcept it declares all builders’ end time to be recorded. The arguments are same asCaptureBuildStartTimeAllBuilders.
- class buildbot.statistics.capture.CaptureBuildDuration
Instance of this class declares the builders whose build durations are to be recorded. It takes the following arguments:
builder_nameThe name of builder whose times are to be recorded.
report_in='seconds'Can be one of three:
'seconds','minutes', or'hours'. This is the units in which the build time will be reported.callback=None(Optional) A custom callback function for this class. This callback function should take in two Python datetime objects - a
start_timeand anend_timeand return a string that will be sent for storage in the storage backends.
- class buildbot.statistics.capture.CaptureBuildDurationAllBuilders
Instance of this class declares build durations to be recorded for all builders. It takes the following arguments:
report_in='seconds'Can be one of three:
'seconds','minutes', or'hours'. This is the units in which the build time will be reported.callback=None(Optional) A custom callback function for this class. This callback function should take in two Python datetime objects - a
start_timeand anend_timeand return a string that will be sent for storage in the storage backends.
- class buildbot.statistics.capture.CaptureData
Instance of this capture class is for capturing arbitrary data that is not stored as build-data. Needs to be used in combination with
yieldMetricsValue(see Using StatsService.yieldMetricsValue). Takes the following arguments:data_nameThe name of data to be captured. Same as in
yieldMetricsValue.builder_nameThe name of builder whose times are to be recorded.
callback=NoneThe callback function for this class. This callback receives the data sent to
yieldMetricsValueaspost_data(see Using StatsService.yieldMetricsValue). It must return a string that is to be sent to the storage backends for storage.
- class buildbot.statistics.capture.CaptureDataAllBuilders
Instance of this capture class for capturing arbitrary data that is not stored as build-data on all builders. Needs to be used in combination with
yieldMetricsValue(see Using StatsService.yieldMetricsValue). Takes the following arguments:data_nameThe name of data to be captured. Same as in
yieldMetricsValue.callback=NoneThe callback function for this class. This callback receives the data sent to
yieldMetricsValueaspost_data(see Using StatsService.yieldMetricsValue). It must return a string that is to be sent to the storage backends for storage.
Using StatsService.yieldMetricsValue
Advanced users can modify BuildSteps to use StatsService.yieldMetricsValue which will send
arbitrary data for storage to the StatsService.
It takes the following arguments:
data_nameThe name of the data being sent or storage.
post_dataA dictionary of key value pair that is sent for storage. The keys will act as columns in a database and the value is stored under that column.
buildidThe integer build id of the current build. Obtainable in all
BuildSteps.
Along with using yieldMetricsValue, the user will also need to use the CaptureData capture
class. As an example, we can add the following to a build step:
yieldMetricsValue('test_data_name', {'some_data': 'some_value'}, buildid)
Then, we can add in the master configuration a capture class like this:
captures = [CaptureBuildData('test_data_name', 'Builder1')]
Pass this captures list to a storage backend (as shown in the example at the top of this
section) for capturing this data.
Storage Backends
Storage backends are responsible for storing any statistics data sent to them.
A storage backend will generally be some sort of a database-server running on a machine.
(Note: This machine may be different from the one running BuildMaster)
Currently, only InfluxDB is supported as a storage backend.
- class buildbot.statistics.storage_backends.influxdb_client.InfluxStorageService
This class is a Buildbot client to the InfluxDB storage backend. InfluxDB is a distributed, time series database that employs a key-value pair storage system.
It requires the following arguments:
urlThe URL where the service is running.
portThe port on which the service is listening.
userUsername of a InfluxDB user.
passwordPassword for
user.dbThe name of database to be used.
capturesA list of objects of Capture Classes. This tells which statistics are to be stored in this storage backend.
name=None(Optional) The name of this storage backend.
2.5.2.15. secretsProviders
See Secret Management for details on secret concepts.
Example usage:
c['secretsProviders'] = [ .. ]
secretsProviders is a list of secrets storage.
See Secret Management to configure a secret storage provider.
2.5.2.16. BuildbotNetUsageData
Since buildbot 0.9.0, buildbot has a simple feature which sends usage analysis info to buildbot.net. This is very important for buildbot developers to understand how the community is using the tools. This allows to better prioritize issues, and understand what plugins are actually being used. This will also be a tool to decide whether to keep support for very old tools. For example buildbot contains support for the venerable CVS, but we have no information whether it actually works beyond the unit tests. We rely on the community to test and report issues with the old features.
With BuildbotNetUsageData, we can know exactly what combination of plugins are working together, how much people are customizing plugins, what versions of the main dependencies people run.
We take your privacy very seriously.
BuildbotNetUsageData will never send information specific to your Code or Intellectual Property. No repository url, shell command values, host names, ip address or custom class names. If it does, then this is a bug, please report.
We still need to track unique number for installation. This is done via doing a sha1 hash of master’s hostname, installation path and fqdn. Using a secure hash means there is no way of knowing hostname, path and fqdn given the hash, but still there is a different hash for each master.
You can see exactly what is sent in the master’s twisted.log. Usage data is sent every time the master is started.
BuildbotNetUsageData can be configured with 4 values:
c['buildbotNetUsageData'] = Nonedisables the featurec['buildbotNetUsageData'] = 'basic'sends the basic information to buildbot including:versions of buildbot, python and twisted
platform information (CPU, OS, distribution, python flavor (i.e CPython vs PyPy))
mq and database type (mysql or sqlite?)
www plugins usage
Plugins usages: This counts the number of time each class of buildbot is used in your configuration. This counts workers, builders, steps, schedulers, change sources. If the plugin is subclassed, then it will be prefixed with a >
example of basic report (for the metabuildbot):
{ 'versions': { 'Python': '2.7.6', 'Twisted': '15.5.0', 'Buildbot': '0.9.0rc2-176-g5fa9dbf' }, 'platform': { 'machine': 'x86_64', 'python_implementation': 'CPython', 'version': '#140-Ubuntu SMP Mon Jul', 'processor': 'x86_64', 'distro:': ('Ubuntu', '14.04', 'trusty') }, 'db': 'sqlite', 'mq': 'simple', 'plugins': { 'buildbot.schedulers.forcesched.ForceScheduler': 2, 'buildbot.schedulers.triggerable.Triggerable': 1, 'buildbot.config.BuilderConfig': 4, 'buildbot.schedulers.basic.AnyBranchScheduler': 2, 'buildbot.steps.source.git.Git': 4, '>>buildbot.steps.trigger.Trigger': 2, '>>>buildbot.worker.base.Worker': 4, 'buildbot.reporters.irc.IRC': 1}, 'www_plugins': ['buildbot_travis', 'waterfall_view'] }
c['buildbotNetUsageData'] = 'full'sends the basic information plus additional information:configuration of each builders: how the steps are arranged together. for example:
{ 'builders': [ ['buildbot.steps.source.git.Git', '>>>buildbot.process.buildstep.BuildStep'], ['buildbot.steps.source.git.Git', '>>buildbot.steps.trigger.Trigger'], ['buildbot.steps.source.git.Git', '>>>buildbot.process.buildstep.BuildStep'], ['buildbot.steps.source.git.Git', '>>buildbot.steps.trigger.Trigger'] ] }
c['buildbotNetUsageData'] = myCustomFunctiondeclares a callback to use to specify exactlywhat to send.
This custom function takes the generated data from full report in the form of a dictionary, and returns a customized report as a jsonable dictionary. You can use this to filter any information you don’t want to disclose. You can also use a custom http_proxy environment variable in order to not send any data while developing your callback.
2.5.2.17. Users Options
from buildbot.plugins import util
c['user_managers'] = []
c['user_managers'].append(util.CommandlineUserManager(username="user",
passwd="userpw",
port=9990))
user_managers contains a list of ways to manually manage User Objects within Buildbot
(see User Objects). Currently implemented is a commandline tool buildbot user, described
at length in user. In the future, a web client will also be able to manage User
Objects and their attributes.
As shown above, to enable the buildbot user tool, you must initialize a CommandlineUserManager instance in your master.cfg. CommandlineUserManager instances require the following arguments:
usernameThis is the username that will be registered on the PB connection and need to be used when calling buildbot user.
passwdThis is the passwd that will be registered on the PB connection and need to be used when calling buildbot user.
portThe PB connection port must be different than c[‘protocols’][‘pb’][‘port’] and be specified when calling buildbot user
2.5.2.18. Input Validation
import re
c['validation'] = {
'branch' : re.compile(r'^[\w.+/~-]*$'),
'revision' : re.compile(r'^[ \w\.\-\/]*$'),
'property_name' : re.compile(r'^[\w\.\-\/\~:]*$'),
'property_value' : re.compile(r'^[\w\.\-\/\~:]*$'),
}
This option configures the validation applied to user inputs of various types. This validation is important since these values are often included in command-line arguments executed on workers. Allowing arbitrary input from untrusted users may raise security concerns.
The keys describe the type of input validated; the values are compiled regular expressions against which the input will be matched. The defaults for each type of input are those given in the example, above.
2.5.2.19. Revision Links
The revlink parameter is used to create links from revision IDs in the web status to a
web-view of your source control system. The parameter’s value must be a callable.
By default, Buildbot is configured to generate revlinks for a number of open source hosting platforms (https://github.com, https://sourceforge.net and https://bitbucket.org).
The callable takes the revision id and repository argument, and should return a URL to the revision. Note that the revision id may not always be in the form you expect, so code defensively. In particular, a revision of “??” may be supplied when no other information is available.
Note that SourceStamps that are not created from version-control changes (e.g., those
created by a Nightly or Periodic scheduler) may have an empty repository
string if the repository is not known to the scheduler.
Revision Link Helpers
Buildbot provides two helpers for generating revision links.
buildbot.revlinks.RevlinkMatcher takes a list of regular expressions and a replacement
text. The regular expressions should all have the same number of capture groups. The replacement
text should have sed-style references to that capture groups (i.e. ‘1’ for the first capture
group), and a single ‘%s’ reference for the revision ID. The repository given is tried against each
regular expression in turn. The results are then substituted into the replacement text, along with
the revision ID, to obtain the revision link.
from buildbot.plugins import util
c['revlink'] = util.RevlinkMatch([r'git://notmuchmail.org/git/(.*)'],
r'http://git.notmuchmail.org/git/\1/commit/%s')
buildbot.revlinks.RevlinkMultiplexer takes a list of revision link callables, and tries
each in turn, returning the first successful match.
2.5.2.20. Codebase Generator
all_repositories = {
r'https://hg/hg/mailsuite/mailclient': 'mailexe',
r'https://hg/hg/mailsuite/mapilib': 'mapilib',
r'https://hg/hg/mailsuite/imaplib': 'imaplib',
r'https://github.com/mailinc/mailsuite/mailclient': 'mailexe',
r'https://github.com/mailinc/mailsuite/mapilib': 'mapilib',
r'https://github.com/mailinc/mailsuite/imaplib': 'imaplib',
}
def codebaseGenerator(chdict):
return all_repositories[chdict['repository']]
c['codebaseGenerator'] = codebaseGenerator
For any incoming change, the codebase is set to ‘’. This codebase value is sufficient if all changes come from the same repository (or clones). If changes come from different repositories, extra processing will be needed to determine the codebase for the incoming change. This codebase will then be a logical name for the combination of repository and or branch etc.
The codebaseGenerator accepts a change dictionary as produced by the buildbot.db.changes.ChangesConnectorComponent, with a changeid equal to None.
2.5.3. Change Sources and Changes
A change source is the mechanism which is used by Buildbot to get information about new changes in a repository maintained by a Version Control System.
These change sources fall broadly into two categories: pollers which periodically check the repository for updates; and hooks, where the repository is configured to notify Buildbot whenever an update occurs.
A Change is an abstract way that Buildbot uses to represent changes in any of the Version
Control Systems it supports. It contains just enough information needed to acquire specific version
of the tree when needed. This usually happens as one of the first steps in a Build.
This concept does not map perfectly to every version control system. For example, for CVS, Buildbot must guess that version updates made to multiple files within a short time represent a single change.
Changes can be provided by a variety of ChangeSource types, although any given
project will typically have only a single ChangeSource active.
2.5.3.1. How Different VC Systems Specify Sources
For CVS, the static specifications are repository and module. In addition to those, each build
uses a timestamp (or omits the timestamp to mean the latest) and branch tag (which defaults to
HEAD). These parameters collectively specify a set of sources from which a build may be
performed.
Subversion combines the repository, module, and branch into a
single Subversion URL parameter. Within that scope, source checkouts can be specified by a
numeric revision number (a repository-wide monotonically-increasing marker, such that each
transaction that changes the repository is indexed by a different revision number), or a revision
timestamp. When branches are used, the repository and module form a static baseURL, while each
build has a revision number and a branch (which defaults to a statically-specified
defaultBranch). The baseURL and branch are simply concatenated together to derive the
repourl to use for the checkout.
Perforce is similar. The server is specified through a P4PORT
parameter. Module and branch are specified in a single depot path, and revisions are depot-wide.
When branches are used, the p4base and defaultBranch are concatenated together to produce
the depot path.
Bzr (which is a descendant of Arch/Bazaar, and is frequently referred to as “Bazaar”) has the same sort of repository-vs-workspace model as Arch, but the repository data can either be stored inside the working directory or kept elsewhere (either on the same machine or on an entirely different machine). For the purposes of Buildbot (which never commits changes), the repository is specified with a URL and a revision number.
The most common way to obtain read-only access to a bzr tree is via HTTP, simply by making the
repository visible through a web server like Apache. Bzr can also use FTP and SFTP servers, if the
worker process has sufficient privileges to access them. Higher performance can be obtained by
running a special Bazaar-specific server. None of these matter to the buildbot: the repository URL
just has to match the kind of server being used. The repoURL argument provides the location of
the repository.
Branches are expressed as subdirectories of the main central repository, which means that if
branches are being used, the BZR step is given a baseURL and defaultBranch instead of
getting the repoURL argument.
Darcs doesn’t really have the notion of a single master repository. Nor does
it really have branches. In Darcs, each working directory is also a repository, and there are
operations to push and pull patches from one of these repositories to another. For the
Buildbot’s purposes, all you need to do is specify the URL of a repository that you want to build
from. The worker will then pull the latest patches from that repository and build them. Multiple
branches are implemented by using multiple repositories (possibly living on the same server).
Builders which use Darcs therefore have a static repourl which specifies the location of the
repository. If branches are being used, the source Step is instead configured with a baseURL
and a defaultBranch, and the two strings are simply concatenated together to obtain the
repository’s URL. Each build then has a specific branch which replaces defaultBranch, or just
uses the default one. Instead of a revision number, each build can have a context, which is a
string that records all the patches that are present in a given tree (this is the output of darcs
changes --context, and is considerably less concise than, e.g. Subversion’s revision number, but
the patch-reordering flexibility of Darcs makes it impossible to provide a shorter useful
specification).
Mercurial follows a decentralized model, and each repository
can have several branches and tags. The source Step is configured with a static repourl which
specifies the location of the repository. Branches are configured with the defaultBranch
argument. The revision is the hash identifier returned by hg identify.
Git also follows a decentralized model, and each repository can have several
branches and tags. The source Step is configured with a static repourl which specifies the
location of the repository. In addition, an optional branch parameter can be specified to check
out code from a specific branch instead of the default master branch. The revision is specified
as a SHA1 hash as returned by e.g. git rev-parse. No attempt is made to ensure that the
specified revision is actually a subset of the specified branch.
Monotone is another that follows a decentralized model where each
repository can have several branches and tags. The source Step is configured with static
repourl and branch parameters, which specifies the location of the repository and the
branch to use. The revision is specified as a SHA1 hash as returned by e.g. mtn automate select
w:. No attempt is made to ensure that the specified revision is actually a subset of the
specified branch.
Comparison
Name |
Change |
Revision |
Branches |
|---|---|---|---|
CVS |
patch [1] |
timestamp |
unnamed |
Subversion |
revision |
integer |
directories |
Git |
commit |
sha1 hash |
named refs |
Mercurial |
changeset |
sha1 hash |
different repos or (permanently) named commits |
Darcs |
? |
none [2] |
different repos |
Bazaar |
? |
? |
? |
Perforce |
? |
? |
? |
BitKeeper |
changeset |
? |
different repos |
[1] note that CVS only tracks patches to individual files. Buildbot tries to recognize coordinated changes to multiple files by correlating change times.
[2] Darcs does not have a concise way of representing a particular revision of the source.
Tree Stability
Changes tend to arrive at a buildmaster in bursts. In many cases, these bursts of changes are meant to be taken together. For example, a developer may have pushed multiple commits to a DVCS that comprise the same new feature or bugfix. To avoid trying to build every change, Buildbot supports the notion of tree stability, by waiting for a burst of changes to finish before starting to schedule builds. This is implemented as a timer, with builds not scheduled until no changes have occurred for the duration of the timer.
2.5.3.2. Choosing a Change Source
There are a variety of ChangeSource classes available, some of which are meant to be used
in conjunction with other tools to deliver Change events from the VC repository to the
buildmaster.
As a quick guide, here is a list of VC systems and the ChangeSources that might be useful
with them. Note that some of these modules are in Buildbot’s master/contrib directory,
meaning that they have been offered by other users in hopes they may be useful, and might require
some additional work to make them functional.
CVS
CVSMaildirSource(watching mail sent by master/contrib/buildbot_cvs_mail.py script)PBChangeSource(listening for connections frombuildbot sendchangerun in a loginfo script)PBChangeSource(listening for connections from a long-running master/contrib/viewcvspoll.py polling process which examines the ViewCVS database directly)Change Hooksin WebStatus
SVN
PBChangeSource(listening for connections from master/contrib/svn_buildbot.py run in a postcommit script)PBChangeSource(listening for connections from a long-running master/contrib/svn_watcher.py or master/contrib/svnpoller.py polling processSVNCommitEmailMaildirSource(watching for email sent bycommit-email.pl)SVNPoller(polling the SVN repository)Change Hooksin WebStatus
Darcs
PBChangeSource(listening for connections from master/contrib/darcs_buildbot.py in a commit script)Change Hooksin WebStatus
Mercurial
Change Hooksin WebStatus (including master/contrib/hgbuildbot.py, configurable in achangegrouphook)BitBucket change hook (specifically designed for BitBucket notifications, but requiring a publicly-accessible WebStatus)
HgPoller(polling a remote Mercurial repository)BitbucketPullrequestPoller(polling Bitbucket for pull requests)Mail-parsing ChangeSources, though there are no ready-to-use recipes
Bzr (the newer Bazaar)
PBChangeSource(listening for connections from master/contrib/bzr_buildbot.py run in a post-change-branch-tip or commit hook)BzrPoller(polling the Bzr repository)Change Hooksin WebStatus
Git
PBChangeSource(listening for connections from master/contrib/git_buildbot.py run in the post-receive hook)PBChangeSource(listening for connections from master/contrib/github_buildbot.py, which listens for notifications from GitHub)Change Hooksin WebStatusGitHubchange hook (specifically designed for GitHub notifications, but requiring a publicly-accessible WebStatus)BitBucketchange hook (specifically designed for BitBucket notifications, but requiring a publicly-accessible WebStatus)GitPoller(polling a remote Git repository)GitHubPullrequestPoller(polling GitHub API for pull requests)BitbucketPullrequestPoller(polling Bitbucket for pull requests)
Repo/Gerrit
GerritChangeSourceconnects to Gerrit via SSH and optionally HTTP to get a live stream of changesGerritEventLogPollerconnects to Gerrit via HTTP with the help of the plugin events-log
Monotone
PBChangeSource(listening for connections frommonotone-buildbot.lua, which is available with Monotone)
All VC systems can be driven by a PBChangeSource and the buildbot sendchange tool
run from some form of commit script. If you write an email parsing function, they can also all be
driven by a suitable mail-parsing source. Additionally,
handlers for web-based notification (i.e. from GitHub) can be used with WebStatus’ change_hook
module. The interface is simple, so adding your own handlers (and sharing!) should be a breeze.
See Change Source Index for a full list of change sources.
2.5.3.3. Configuring Change Sources
The change_source configuration key holds all active change sources for the configuration.
Most configurations have a single ChangeSource, watching only a single tree, e.g.,
from buildbot.plugins import changes
c['change_source'] = changes.PBChangeSource()
For more advanced configurations, the parameter can be a list of change sources:
source1 = ...
source2 = ...
c['change_source'] = [
source1, source2
]
Repository and Project
ChangeSources will, in general, automatically provide the proper repository
attribute for any changes they produce. For systems which operate on URL-like specifiers, this is a
repository URL. Other ChangeSources adapt the concept as necessary.
Many ChangeSources allow you to specify a project, as well. This attribute is useful when
building from several distinct codebases in the same buildmaster: the project string can serve to
differentiate the different codebases. Schedulers can filter on project, so you can configure
different builders to run for each project.
2.5.3.4. Mail-parsing ChangeSources
Many projects publish information about changes to their source tree by sending an email message
out to a mailing list, frequently named PROJECT-commits or PROJECT-changes.
Each message usually contains a description of the change (who made the change, which files were
affected) and sometimes a copy of the diff. Humans can subscribe to this list to stay informed
about what’s happening to the source tree.
Buildbot can also subscribe to a -commits mailing list, and can trigger builds in response to Changes that it hears about. The buildmaster admin needs to arrange for these email messages to arrive in a place where the buildmaster can find them, and configure the buildmaster to parse the messages correctly. Once that is in place, the email parser will create Change objects and deliver them to the schedulers (see Schedulers) just like any other ChangeSource.
There are two components to setting up an email-based ChangeSource. The first is to route the email messages to the buildmaster, which is done by dropping them into a maildir. The second is to actually parse the messages, which is highly dependent upon the tool that was used to create them. Each VC system has a collection of favorite change-emailing tools with a slightly different format and its own parsing function. Buildbot has a separate ChangeSource variant for each of these parsing functions.
Once you’ve chosen a maildir location and a parsing function, create the change source and put it in change_source:
from buildbot.plugins import changes
c['change_source'] = changes.CVSMaildirSource("~/maildir-buildbot",
prefix="/trunk/")
Subscribing the Buildmaster
The recommended way to install Buildbot is to create a dedicated account for the buildmaster. If you do this, the account will probably have a distinct email address (perhaps buildmaster@example.org). Then just arrange for this account’s email to be delivered to a suitable maildir (described in the next section).
If Buildbot does not have its own account, extension addresses can be used to distinguish between
emails intended for the buildmaster and emails intended for the rest of the account. In most modern
MTAs, the e.g. foo@example.org account has control over every email address at example.org which
begins with “foo”, such that emails addressed to account-foo@example.org can be delivered to a
different destination than account-bar@example.org. qmail does this by using separate
.qmail files for the two destinations (.qmail-foo and .qmail-bar, with
.qmail controlling the base address and .qmail-default controlling all other
extensions). Other MTAs have similar mechanisms.
Thus you can assign an extension address like foo-buildmaster@example.org to the buildmaster and retain foo@example.org for your own use.
Using Maildirs
A maildir is a simple directory structure originally developed for qmail that allows safe atomic
update without locking. Create a base directory with three subdirectories: new,
tmp, and cur. When messages arrive, they are put into a uniquely-named file (using
pids, timestamps, and random numbers) in tmp. When the file is complete, it is atomically
renamed into new. Eventually the buildmaster notices the file in new, reads and
parses the contents, then moves it into cur. A cronjob can be used to delete files in
cur at leisure.
Maildirs are frequently created with the maildirmake tool, but a simple mkdir -p
~/MAILDIR/cur,new,tmp is pretty much equivalent.
Many modern MTAs can deliver directly to maildirs. The usual .forward or
.procmailrc syntax is to name the base directory with a trailing slash, so something like
~/MAILDIR/. qmail and postfix are maildir-capable MTAs, and procmail is a
maildir-capable MDA (Mail Delivery Agent).
Here is an example procmail config, located in ~/.procmailrc:
# .procmailrc
# routes incoming mail to appropriate mailboxes
PATH=/usr/bin:/usr/local/bin
MAILDIR=$HOME/Mail
LOGFILE=.procmail_log
SHELL=/bin/sh
:0
*
new
If procmail is not setup on a system wide basis, then the following one-line .forward file
will invoke it.
!/usr/bin/procmail
For MTAs which cannot put files into maildirs directly, the safecat tool can be executed from a
.forward file to accomplish the same thing.
The Buildmaster uses the linux DNotify facility to receive immediate notification when the
maildir’s new directory has changed. When this facility is not available, it polls the
directory for new messages, every 10 seconds by default.
Parsing Email Change Messages
The second component to setting up an email-based ChangeSource is to parse the actual notices.
This is highly dependent upon the VC system and commit script in use.
A couple of common tools used to create these change emails, along with the Buildbot tools to parse them, are:
- CVS
- Buildbot CVS MailNotifier
- SVN
- svnmailer
commit-email.pl
- Bzr
- Launchpad
- Mercurial
- NotifyExtension
- Git
The following sections describe the parsers available for each of these tools.
Most of these parsers accept a prefix= argument, which is used to limit the set of files that
the buildmaster pays attention to. This is most useful for systems like CVS and SVN which put
multiple projects in a single repository (or use repository names to indicate branches). Each
filename that appears in the email is tested against the prefix: if the filename does not start
with the prefix, the file is ignored. If the filename does start with the prefix, that prefix is
stripped from the filename before any further processing is done. Thus the prefix usually ends with
a slash.
CVSMaildirSource
- class buildbot.changes.mail.CVSMaildirSource
This parser works with the master/contrib/buildbot_cvs_mail.py script.
The script sends an email containing all the files submitted in one directory.
It is invoked by using the CVSROOT/loginfo facility.
The Buildbot’s CVSMaildirSource knows how to parse these messages and turn them into
Change objects. It takes the directory name of the maildir root. For example:
from buildbot.plugins import changes
c['change_source'] = changes.CVSMaildirSource("/home/buildbot/Mail")
Configuration of CVS and buildbot_cvs_mail.py
CVS must be configured to invoke the buildbot_cvs_mail.py script when files are checked in. This is done via the CVS loginfo configuration file.
To update this, first do:
cvs checkout CVSROOT
cd to the CVSROOT directory and edit the file loginfo, adding a line like:
SomeModule /cvsroot/CVSROOT/buildbot_cvs_mail.py --cvsroot :ext:example.com:/cvsroot -e buildbot -P SomeModule %@{sVv@}
Note
For cvs version 1.12.x, the --path %p option is required.
Version 1.11.x and 1.12.x report the directory path differently.
The above example you put the buildbot_cvs_mail.py
script under /cvsroot/CVSROOT. It can be anywhere. Run the script with --help to see all the
options. At the very least, the options -e (email) and -P (project) should be specified.
The line must end with %{sVv}. This is expanded to the files that were modified.
Additional entries can be added to support more modules.
See buildbot_cvs_mail.py --help for more information on the available options.
SVNCommitEmailMaildirSource
- class buildbot.changes.mail.SVNCommitEmailMaildirSource
SVNCommitEmailMaildirSource parses message sent out by the commit-email.pl
script, which is included in the Subversion distribution.
It does not currently handle branches: all of the Change objects that it creates will be associated with the default (i.e. trunk) branch.
from buildbot.plugins import changes
c['change_source'] = changes.SVNCommitEmailMaildirSource("~/maildir-buildbot")
BzrLaunchpadEmailMaildirSource
- class buildbot.changes.mail.BzrLaunchpadEmailMaildirSource
BzrLaunchpadEmailMaildirSource parses the mails that are sent to addresses that
subscribe to branch revision notifications for a bzr branch hosted on Launchpad.
The branch name defaults to lp:Launchpad path.
For example lp:~maria-captains/maria/5.1.
If only a single branch is used, the default branch name can be changed by setting defaultBranch.
For multiple branches, pass a dictionary as the value of the branchMap option to map specific
repository paths to specific branch names (see example below). The leading lp: prefix of the
path is optional.
The prefix option is not supported (it is silently ignored). Use the branchMap and
defaultBranch instead to assign changes to branches (and just do not subscribe the Buildbot to
branches that are not of interest).
The revision number is obtained from the email text. The bzr revision id is not available in the mails sent by Launchpad. However, it is possible to set the bzr append_revisions_only option for public shared repositories to avoid new pushes of merges changing the meaning of old revision numbers.
from buildbot.plugins import changes
bm = {
'lp:~maria-captains/maria/5.1': '5.1',
'lp:~maria-captains/maria/6.0': '6.0'
}
c['change_source'] = changes.BzrLaunchpadEmailMaildirSource("~/maildir-buildbot",
branchMap=bm)
2.5.3.5. PBChangeSource
- class buildbot.changes.pb.PBChangeSource
PBChangeSource actually listens on a TCP port for clients to connect and push change
notices into the Buildmaster. This is used by the built-in buildbot sendchange notification
tool, as well as several version-control hook scripts. This change is also useful for creating new
kinds of change sources that work on a push model instead of some kind of subscription scheme,
for example a script which is run out of an email .forward file. This ChangeSource always
runs on the same TCP port as the workers. It shares the same protocol, and in fact shares the same
space of “usernames”, so you cannot configure a PBChangeSource with the same name as a
worker.
If you have a publicly accessible worker port and are using PBChangeSource, you must
establish a secure username and password for the change source. If your sendchange credentials are
known (e.g., the defaults), then your buildmaster is susceptible to injection of arbitrary changes,
which (depending on the build factories) could lead to arbitrary code execution on workers.
The PBChangeSource is created with the following arguments.
portWhich port to listen on. If
None(which is the default), it shares the port used for worker connections.userThe user account that the client program must use to connect. Defaults to
changepasswdThe password for the connection - defaults to
changepw. Can be a Secret. Do not use this default on a publicly exposed port!prefixThe prefix to be found and stripped from filenames delivered over the connection, defaulting to
None. Any filenames which do not start with this prefix will be removed. If all the filenames in a given Change are removed, then that whole Change will be dropped. This string should probably end with a directory separator.This is useful for changes coming from version control systems that represent branches as parent directories within the repository (like SVN and Perforce). Use a prefix of
trunk/orproject/branches/foobranch/to only follow one branch and to get correct tree-relative filenames. Without a prefix, thePBChangeSourcewill probably deliver Changes with filenames liketrunk/foo.cinstead of justfoo.c. Of course this also depends upon the tool sending the Changes in (likebuildbot sendchange) and what filenames it is delivering: that tool may be filtering and stripping prefixes at the sending end.
For example:
from buildbot.plugins import changes
c['change_source'] = changes.PBChangeSource(port=9999, user='laura', passwd='fpga')
The following hooks are useful for sending changes to a PBChangeSource:
Bzr Hook
Bzr is also written in Python, and the Bzr hook depends on Twisted to send the changes.
To install, put master/contrib/bzr_buildbot.py in one of your plugins locations a bzr
plugins directory (e.g., ~/.bazaar/plugins). Then, in one of your bazaar conf files (e.g.,
~/.bazaar/locations.conf), set the location you want to connect with Buildbot with these
keys:
buildbot_onone of ‘commit’, ‘push, or ‘change’. Turns the plugin on to report changes via commit, changes via push, or any changes to the trunk. ‘change’ is recommended.
buildbot_server(required to send to a Buildbot master) the URL of the Buildbot master to which you will connect (as of this writing, the same server and port to which workers connect).
buildbot_port(optional, defaults to 9989) the port of the Buildbot master to which you will connect (as of this writing, the same server and port to which workers connect)
buildbot_pqm(optional, defaults to not pqm) Normally, the user that commits the revision is the user that is responsible for the change. When run in a pqm (Patch Queue Manager, see https://launchpad.net/pqm) environment, the user that commits is the Patch Queue Manager, and the user that committed the parent revision is responsible for the change. To turn on the pqm mode, set this value to any of (case-insensitive) “Yes”, “Y”, “True”, or “T”.
buildbot_dry_run(optional, defaults to not a dry run) Normally, the post-commit hook will attempt to communicate with the configured Buildbot server and port. If this parameter is included and any of (case-insensitive) “Yes”, “Y”, “True”, or “T”, then the hook will simply print what it would have sent, but not attempt to contact the Buildbot master.
buildbot_send_branch_name(optional, defaults to not sending the branch name) If your Buildbot’s bzr source build step uses a repourl, do not turn this on. If your buildbot’s bzr build step uses a baseURL, then you may set this value to any of (case-insensitive) “Yes”, “Y”, “True”, or “T” to have the Buildbot master append the branch name to the baseURL.
Note
The bzr smart server (as of version 2.2.2) doesn’t know how to resolve bzr:// urls into
absolute paths so any paths in locations.conf won’t match, hence no change notifications
will be sent to Buildbot. Setting configuration parameters globally or in-branch might still
work. When Buildbot no longer has a hardcoded password, it will be a configuration option here
as well.
Here’s a simple example that you might have in your ~/.bazaar/locations.conf.
[chroot-*:///var/local/myrepo/mybranch]
buildbot_on = change
buildbot_server = localhost
2.5.3.6. P4Source
The P4Source periodically polls a Perforce depot for changes.
It accepts the following arguments:
p4portThe Perforce server to connect to (as
host:port).p4userThe Perforce user.
p4passwdThe Perforce password.
p4baseThe base depot path to watch, without the trailing ‘/…’.
p4binAn optional string parameter. Specify the location of the perforce command line binary (p4). You only need to do this if the perforce binary is not in the path of the Buildbot user. Defaults to p4.
split_fileA function that maps a pathname, without the leading
p4base, to a (branch, filename) tuple. The default just returns(None, branchfile), which effectively disables branch support. You should supply a function which understands your repository structure.pollIntervalHow often to poll, in seconds. Defaults to 600 (10 minutes).
pollRandomDelayMinMinimum delay in seconds to wait before each poll, default is 0. This is useful in case you have a lot of pollers and you want to spread the polling load over a period of time. Setting it equal to the maximum delay will effectively delay all polls by a fixed amount of time. Must be less than or equal to the maximum delay.
pollRandomDelayMaxMaximum delay in seconds to wait before each poll, default is 0. This is useful in case you have a lot of pollers and you want to spread the polling load over a period of time. Must be less than the poll interval.
projectSet the name of the project to be used for the
P4Source. This will then be set in any changes generated by theP4Source, and can be used in a Change Filter for triggering particular builders.pollAtLaunchDetermines when the first poll occurs. True = immediately on launch, False = wait for one pollInterval (default).
histmaxThe maximum number of changes to inspect at a time. If more than this number occur since the last poll, older changes will be silently ignored.
encodingThe character encoding of
p4's output. This defaults to “utf8”, but if your commit messages are in another encoding, specify that here. For example, if you’re using Perforce on Windows, you may need to use “cp437” as the encoding if “utf8” generates errors in your master log.server_tzThe timezone of the Perforce server, using the usual timezone format (e.g:
"Europe/Stockholm") in case it’s not in UTC.use_ticketsSet to
Trueto use ticket-based authentication, instead of passwords (but you still need to specifyp4passwd).ticket_login_intervalHow often to get a new ticket, in seconds, when
use_ticketsis enabled. Defaults to 86400 (24 hours).revlinkA function that maps branch and revision to a valid url (e.g. p4web), stored along with the change. This function must be a callable which takes two arguments, the branch and the revision. Defaults to lambda branch, revision: (u’’)
resolvewhoA function that resolves the Perforce ‘user@workspace’ into a more verbose form, stored as the author of the change. Useful when usernames do not match email addresses and external, client-side lookup is required. This function must be a callable which takes one argument. Defaults to lambda who: (who)
Example #1
This configuration uses the P4PORT, P4USER, and P4PASSWD specified in
the buildmaster’s environment. It watches a project in which the branch name is simply the next
path component, and the file is all path components after.
from buildbot.plugins import changes
s = changes.P4Source(p4base='//depot/project/',
split_file=lambda branchfile: branchfile.split('/',1))
c['change_source'] = s
Example #2
Similar to the previous example but also resolves the branch and revision into a valid revlink.
from buildbot.plugins import changes
s = changes.P4Source(
p4base='//depot/project/',
split_file=lambda branchfile: branchfile.split('/',1))
revlink=lambda branch, revision: 'http://p4web:8080/@md=d&@/{}?ac=10'.format(revision)
c['change_source'] = s
2.5.3.7. SVNPoller
- class buildbot.changes.svnpoller.SVNPoller
The SVNPoller is a ChangeSource which periodically polls a Subversion repository for new revisions, by running the svn log command
in a subshell. It can watch a single branch or multiple branches.
SVNPoller accepts the following arguments:
repourlThe base URL path to watch, like
svn://svn.twistedmatrix.com/svn/Twisted/trunk, orhttp://divmod.org/svn/Divmo/, or evenfile:///home/svn/Repository/ProjectA/branches/1.5/. This must include the access scheme, the location of the repository (both the hostname for remote ones, and any additional directory names necessary to get to the repository), and the sub-path within the repository’s virtual filesystem for the project and branch of interest.The
SVNPollerwill only pay attention to files inside the subdirectory specified by the complete repourl.split_fileA function to convert pathnames into
(branch, relative_pathname)tuples. Use this to explain your repository’s branch-naming policy toSVNPoller. This function must accept a single string (the pathname relative to the repository) and return a two-entry tuple. Directory pathnames always end with a right slash to distinguish them from files, liketrunk/src/, orsrc/. There are a few utility functions inbuildbot.changes.svnpollerthat can be used as asplit_filefunction; see below for details.For directories, the relative pathname returned by
split_fileshould end with a right slash but an empty string is also accepted for the root, like("branches/1.5.x", "")being converted from"branches/1.5.x/".The default value always returns
(None, path), which indicates that all files are on the trunk.Subclasses of
SVNPollercan override thesplit_filemethod instead of using thesplit_file=argument.projectSet the name of the project to be used for the
SVNPoller. This will then be set in any changes generated by theSVNPoller, and can be used in a Change Filter for triggering particular builders.svnuserAn optional string parameter. If set, the option –user argument will be added to all svn commands. Use this if you have to authenticate to the svn server before you can do svn info or svn log commands. Can be a Secret.
svnpasswdLike
svnuser, this will cause a option –password argument to be passed to all svn commands. Can be a Secret.pollIntervalHow often to poll, in seconds. Defaults to 600 (checking once every 10 minutes). Lower this if you want the Buildbot to notice changes faster, raise it if you want to reduce the network and CPU load on your svn server. Please be considerate of public SVN repositories by using a large interval when polling them.
pollRandomDelayMinMinimum delay in seconds to wait before each poll, default is 0. This is useful in case you have a lot of pollers and you want to spread the polling load over a period of time. Setting it equal to the maximum delay will effectively delay all polls by a fixed amount of time. Must be less than or equal to the maximum delay.
pollRandomDelayMaxMaximum delay in seconds to wait before each poll, default is 0. This is useful in case you have a lot of pollers and you want to spread the polling load over a period of time. Must be less than the poll interval.
pollAtLaunchDetermines when the first poll occurs. True = immediately on launch, False = wait for one pollInterval (default).
histmaxThe maximum number of changes to inspect at a time. Every
pollIntervalseconds, theSVNPollerasks for the lasthistmaxchanges and looks through them for any revisions it does not already know about. If more thanhistmaxrevisions have been committed since the last poll, older changes will be silently ignored. Larger values ofhistmaxwill cause more time and memory to be consumed on each poll attempt.histmaxdefaults to 100.svnbinThis controls the svn executable to use. If subversion is installed in a weird place on your system (outside of the buildmaster’s
PATH), use this to tellSVNPollerwhere to find it. The default value of svn will almost always be sufficient.revlinktmplThis parameter is deprecated in favour of specifying a global revlink option. This parameter allows a link to be provided for each revision (for example, to websvn or viewvc). These links appear anywhere changes are shown, such as on build or change pages. The proper form for this parameter is an URL with the portion that will substitute for a revision number replaced by ‘’%s’’. For example,
'http://myserver/websvn/revision.php?rev=%s'could be used to cause revision links to be created to a websvn repository viewer.cachepathIf specified, this is a pathname of a cache file that
SVNPollerwill use to store its state between restarts of the master.extra_argsIf specified, the extra arguments will be added to the svn command args.
Several split file functions are available for common SVN repository layouts. For a poller that is
only monitoring trunk, the default split file function is available explicitly as
split_file_alwaystrunk:
from buildbot.plugins import changes, util
c['change_source'] = changes.SVNPoller(
repourl="svn://svn.twistedmatrix.com/svn/Twisted/trunk",
split_file=util.svn.split_file_alwaystrunk)
For repositories with the /trunk and /branches/BRANCH layout, split_file_branches
will do the job:
from buildbot.plugins import changes, util
c['change_source'] = changes.SVNPoller(
repourl="https://amanda.svn.sourceforge.net/svnroot/amanda/amanda",
split_file=util.svn.split_file_branches)
When using this splitter the poller will set the project attribute of any changes to the
project attribute of the poller.
For repositories with the PROJECT/trunk and PROJECT/branches/BRANCH layout,
split_file_projects_branches will do the job:
from buildbot.plugins import changes, util
c['change_source'] = changes.SVNPoller(
repourl="https://amanda.svn.sourceforge.net/svnroot/amanda/",
split_file=util.svn.split_file_projects_branches)
When using this splitter the poller will set the project attribute of any changes to the
project determined by the splitter.
The SVNPoller is highly adaptable to various Subversion layouts.
See Customizing SVNPoller for details and some common scenarios.
2.5.3.8. Bzr Poller
If you cannot insert a Bzr hook in the server, you can use the BzrPoller. To use it,
put master/contrib/bzr_buildbot.py somewhere that your Buildbot configuration can import it.
Even putting it in the same directory as the master.cfg should work. Install the poller in
the Buildbot configuration as with any other change source. Minimally, provide a URL that you want
to poll (bzr://, bzr+ssh://, or lp:), making sure the Buildbot user has necessary
privileges.
# put bzr_buildbot.py file to the same directory as master.cfg
from bzr_buildbot import BzrPoller
c['change_source'] = BzrPoller(
url='bzr://hostname/my_project',
poll_interval=300)
The BzrPoller parameters are:
urlThe URL to poll.
poll_intervalThe number of seconds to wait between polls. Defaults to 10 minutes.
branch_nameAny value to be used as the branch name. Defaults to None, or specify a string, or specify the constants from bzr_buildbot.py
SHORTorFULLto get the short branch name or full branch address.blame_merge_authorNormally, the user that commits the revision is the user that is responsible for the change. When run in a pqm (Patch Queue Manager, see https://launchpad.net/pqm) environment, the user that commits is the Patch Queue Manager, and the user that committed the merged, parent revision is responsible for the change. Set this value to
Trueif this is pointed against a PQM-managed branch.
2.5.3.9. GitPoller
If you cannot take advantage of post-receive hooks as provided by
master/contrib/git_buildbot.py for example, then you can use the GitPoller.
The GitPoller periodically fetches from a remote Git repository and processes any changes.
It requires its own working directory for operation.
The default should be adequate, but it can be overridden via the workdir property.
Note
There can only be a single GitPoller pointed at any given repository.
The GitPoller requires Git-1.7 and later.
It accepts the following arguments:
repourlThe git-url that describes the remote repository, e.g.
git@example.com:foobaz/myrepo.git(see the git fetch help for more info on git-url formats)branchesOne of the following:
a list of the branches to fetch. Non-existing branches are ignored.
Trueindicating that all branches should be fetcheda callable which takes a single argument. It should take a remote refspec (such as
'refs/heads/master'), and return a boolean indicating whether that branch should be fetched.
If not provided,
GitPollerwill useHEADto fetch the remote default branch.branchAccepts a single branch name to fetch. Exists for backwards compatibility with old configurations.
pollIntervalInterval in seconds between polls, default is 10 minutes
pollRandomDelayMinMinimum delay in seconds to wait before each poll, default is 0. This is useful in case you have a lot of pollers and you want to spread the polling load over a period of time. Setting it equal to the maximum delay will effectively delay all polls by a fixed amount of time. Must be less than or equal to the maximum delay.
pollRandomDelayMaxMaximum delay in seconds to wait before each poll, default is 0. This is useful in case you have a lot of pollers and you want to spread the polling load over a period of time. Must be less than the poll interval.
pollAtLaunchDetermines when the first poll occurs. True = immediately on launch, False = wait for one pollInterval (default).
buildPushesWithNoCommitsDetermines if a push on a new branch or update of an already known branch with already known commits should trigger a build. This is useful in case you have build steps depending on the name of the branch and you use topic branches for development. When you merge your topic branch into “master” (for instance), a new build will be triggered. (defaults to False).
gitbinPath to the Git binary, defaults to just
'git'categorySet the category to be used for the changes produced by the
GitPoller. This will then be set in any changes generated by theGitPoller, and can be used in a Change Filter for triggering particular builders.projectSet the name of the project to be used for the
GitPoller. This will then be set in any changes generated by theGitPoller, and can be used in a Change Filter for triggering particular builders.codebase(optional)Set the codebase that poller is tracking. If set,
GitPollerwill store more granular, per-commit data that can be viewed in the web UI.usetimestampsParse each revision’s commit timestamp (default is
True), or ignore it in favor of the current time, so that recently processed commits appear together in the waterfall page.encodingSet encoding will be used to parse author’s name and commit message. Default encoding is
'utf-8'. This will not be applied to file names since Git will translate non-ascii file names to unreadable escape sequences.workdirThe directory where the poller should keep its local repository. The default is
gitpoller_work. If this is a relative path, it will be interpreted relative to the master’s basedir. Multiple Git pollers can share the same directory.only_tagsDetermines if the GitPoller should poll for new tags in the git repository.
sshPrivateKey(optional)Specifies private SSH key for git to use. This may be either a Secret or just a string. This option requires Git-2.3 or later. The master must either have the host in the known hosts file or the host key must be specified via the sshHostKey option.
sshHostKey(optional)Specifies public host key to match when authenticating with SSH public key authentication. This may be either a Secret or just a string. sshPrivateKey must be specified in order to use this option. The host key must be in the form of <key type> <base64-encoded string>, e.g. ssh-rsa AAAAB3N<…>FAaQ==.
sshKnownHosts(optional)Specifies the contents of the SSH known_hosts file to match when authenticating with SSH public key authentication. This may be either a Secret or just a string. sshPrivateKey must be specified in order to use this option. sshHostKey must not be specified in order to use this option.
auth_credentials
(optional) An username/password tuple to use when running git for fetch operations. The worker’s git version needs to be at least 1.7.9.
git_credentials
(optional) See GitCredentialOptions. The worker’s git version needs to be at least 1.7.9.
A configuration for the Git poller might look like this:
from buildbot.plugins import changes
c['change_source'] = changes.GitPoller(repourl='git@example.com:foobaz/myrepo.git',
branches=['master', 'great_new_feature'])
2.5.3.10. HgPoller
The HgPoller periodically pulls a named branch from a remote Mercurial repository and
processes any changes. It requires its own working directory for operation, which must be specified
via the workdir property.
The HgPoller requires a working hg executable, and at least a read-only access to
the repository it polls (possibly through ssh keys or by tweaking the hgrc of the system user
Buildbot runs as).
The HgPoller will not transmit any change if there are several heads on the watched
named branch. This is similar (although not identical) to the Mercurial executable behaviour. This
exceptional condition is usually the result of a developer mistake, and usually does not last for
long. It is reported in logs. If fixed by a later merge, the buildmaster administrator does not
have anything to do: that merge will be transmitted, together with the intermediate ones.
The HgPoller accepts the following arguments:
nameThe name of the poller. This must be unique, and defaults to the
repourl.repourlThe url that describes the remote repository, e.g.
http://hg.example.com/projects/myrepo. Any url suitable forhg pullcan be specified.bookmarksA list of the bookmarks to monitor.
branchesA list of the branches to monitor; defaults to
['default'].branchThe desired branch to pull. Exists for backwards compatibility with old configurations.
workdirThe directory where the poller should keep its local repository. It is mandatory for now, although later releases may provide a meaningful default.
It also serves to identify the poller in the buildmaster internal database. Changing it may result in re-processing all changes so far.
Several
HgPollerinstances may share the sameworkdirfor mutualisation of the common history between two different branches, thus easing on local and remote system resources and bandwidth.If relative, the
workdirwill be interpreted from the master directory.pollIntervalInterval in seconds between polls, default is 10 minutes
pollRandomDelayMinMinimum delay in seconds to wait before each poll, default is 0. This is useful in case you have a lot of pollers and you want to spread the polling load over a period of time. Setting it equal to the maximum delay will effectively delay all polls by a fixed amount of time. Must be less than or equal to the maximum delay.
pollRandomDelayMaxMaximum delay in seconds to wait before each poll, default is 0. This is useful in case you have a lot of pollers and you want to spread the polling load over a period of time. Must be less than the poll interval.
pollAtLaunchDetermines when the first poll occurs. True = immediately on launch, False = wait for one pollInterval (default).
hgbinPath to the Mercurial binary, defaults to just
'hg'.categorySet the category to be used for the changes produced by the
HgPoller. This will then be set in any changes generated by theHgPoller, and can be used in a Change Filter for triggering particular builders.projectSet the name of the project to be used for the
HgPoller. This will then be set in any changes generated by theHgPoller, and can be used in a Change Filter for triggering particular builders.usetimestampsParse each revision’s commit timestamp (default is
True), or ignore it in favor of the current time, so that recently processed commits appear together in the waterfall page.encodingSet encoding will be used to parse author’s name and commit message. Default encoding is
'utf-8'.revlinkA function that maps branch and revision to a valid url (e.g. hgweb), stored along with the change. This function must be a callable which takes two arguments, the branch and the revision. Defaults to lambda branch, revision: (u’’)
A configuration for the Mercurial poller might look like this:
from buildbot.plugins import changes
c['change_source'] = changes.HgPoller(repourl='http://hg.example.org/projects/myrepo',
branch='great_new_feature',
workdir='hg-myrepo')
2.5.3.11. GitHubPullrequestPoller
- class buildbot.changes.github.GitHubPullrequestPoller
This GitHubPullrequestPoller periodically polls the GitHub API for new or updated pull
requests. The author, revision, revlink, branch and files fields in the recorded changes
are populated with information extracted from the pull request. This allows to filter for certain
changes in files and create a blamelist based on the authors in the GitHub pull request.
The GitHubPullrequestPoller accepts the following arguments:
ownerThe owner of the GitHub repository. This argument is required.
repoThe name of the GitHub repository. This argument is required.
branchesList of branches to accept as base branch (e.g. master). Defaults to None and accepts all branches as base.
pollIntervalPoll interval between polls in seconds. Default is 10 minutes.
pollAtLaunchWhether to poll on startup of the buildbot master. Default is False and first poll will occur pollInterval seconds after the master start.
categorySet the category to be used for the changes produced by the
GitHubPullrequestPoller. This will then be set in any changes generated by theGitHubPullrequestPoller, and can be used in a Change Filter for triggering particular builders.projectSet the name of the project to be used for the
GitHubPullrequestPoller. This will then be set in any changes generated by theGitHubPullrequestPoller, and can be used in a Change Filter for triggering particular builders. If unset, the default is to use the full name of the project as returned by the GitHub API.baseURLGitHub API endpoint. Default is
https://api.github.com.pullrequest_filterA callable which takes a dict which contains the decoded JSON object of the GitHub pull request as argument. All fields specified by the GitHub API are accessible. If the callable returns False the pull request is ignored. Default is True which does not filter any pull requests.
tokenA GitHub API token to execute all requests to the API authenticated. It is strongly recommended to use a API token since it increases GitHub API rate limits significantly.
repository_typeSet which type of repository link will be in the repository property. Possible values
https,svn,gitorsvn. This link can then be used in a Source Step to checkout the source.magic_linkSet to True if the changes should contain
refs/pulls/<PR #>/mergein the branch property and a link to the base repository in the repository property. These properties can be used by theGitHubsource to pull from the special branch in the base repository. Default is False.github_property_whitelistA list of
fnmatchexpressions which match against the flattened pull request information JSON prefixed withgithub. For examplegithub.numberrepresents the pull request number. Available entries can be looked up in the GitHub API Documentation or by examining the data returned for a pull request by the API.
2.5.3.12. BitbucketPullrequestPoller
- class buildbot.changes.bitbucket.BitbucketPullrequestPoller
This BitbucketPullrequestPoller periodically polls Bitbucket for new or updated pull
requests. It uses Bitbuckets powerful Pull Request REST API to gather the information needed.
The BitbucketPullrequestPoller accepts the following arguments:
ownerThe owner of the Bitbucket repository. All Bitbucket Urls are of the form
https://bitbucket.org/owner/slug/.slugThe name of the Bitbucket repository.
authAuthorization data tuple
(usename, password)(optional). If set, it will be used as authorization headers at Bitbucket API.branchA single branch or a list of branches which should be processed. If it is
None(the default) all pull requests are used.pollIntervalInterval in seconds between polls, default is 10 minutes.
pollAtLaunchDetermines when the first poll occurs.
True= immediately on launch,False= wait for onepollInterval(default).categorySet the category to be used by the
BitbucketPullrequestPoller. This will then be set in any changes generated by theBitbucketPullrequestPoller, and can be used in a Change Filter for triggering particular builders.projectSet the name of the project to be used by the
BitbucketPullrequestPoller. This will then be set in any changes generated by theBitbucketPullrequestPoller, and can be used in a Change Filter for triggering particular builders.pullrequest_filterA callable which takes one parameter, the decoded Python object of the pull request JSON. If it returns
False, the pull request is ignored. It can be used to define custom filters based on the content of the pull request. See the Bitbucket documentation for more information about the format of the response. By default, the filter always returnsTrue.usetimestampsParse each revision’s commit timestamp (default is
True), or ignore it in favor of the current time, so that recently processed commits appear together in the waterfall page.bitbucket_property_whitelistA list of
fnmatchexpressions which match against the flattened pull request information JSON prefixed withbitbucket. For examplebitbucket.idrepresents the pull request ID. Available entries can be looked up in the BitBucket API Documentation or by examining the data returned for a pull request by the API.encodingThis parameter is deprecated and has no effects. Author’s name and commit message are always parsed in
'utf-8'.
A minimal configuration for the Bitbucket pull request poller might look like this:
from buildbot.plugins import changes
c['change_source'] = changes.BitbucketPullrequestPoller(
owner='myname',
slug='myrepo',
)
Here is a more complex configuration using a pullrequest_filter.
The pull request is only processed if at least 3 people have already approved it:
def approve_filter(pr, threshold):
approves = 0
for participant in pr['participants']:
if participant['approved']:
approves = approves + 1
if approves < threshold:
return False
return True
from buildbot.plugins import changes
c['change_source'] = changes.BitbucketPullrequestPoller(
owner='myname',
slug='myrepo',
branch='mybranch',
project='myproject',
pullrequest_filter=lambda pr : approve_filter(pr,3),
pollInterval=600,
)
Warning
Anyone who can create pull requests for the Bitbucket repository can initiate a change, potentially causing the buildmaster to run arbitrary code.
2.5.3.13. GerritChangeSource
- class buildbot.changes.gerritchangesource.GerritChangeSource
The GerritChangeSource class connects to a Gerrit server by its SSH interface and uses
its event source mechanism, gerrit stream-events.
Optionally it may use the events-log plugin to retrieve any events that occur while Buildbot is not connected. If events-log mechanism is not used any events that occur while buildbot is not connected to Gerrit will be lost.
Note
The GerritChangeSource requires either the txrequest or the treq package for
using the HTTP API.
The GerritChangeSource accepts the following arguments:
gerritserverThe dns or ip that host the Gerrit ssh server
gerritportThe port of the Gerrit ssh server
usernameThe username to use to connect to Gerrit
identity_fileSsh identity file to for authentication (optional). Pay attention to the ssh passphrase
handled_eventsEvent to be handled (optional). By default processes patchset-created and ref-updated
get_filesPopulate the files attribute of emitted changes (default False). Buildbot will run an extra query command for each handled event to determine the changed files.
ssh_server_alive_interval_sSets the
ServerAliveIntervaloption of the ssh client (default 15). This causes client to emit periodic keepalive messages in case the connection is not otherwise active. If the server does not respond at leastssh_server_alive_count_maxtimes, a reconnection is forced. This helps to avoid stuck connections in case network link is severed without notification in the TCP layer. SpecifyingNonewill omit the option from the ssh client command line.ssh_server_alive_count_maxSets the
ServerAliveCountMaxoption of the ssh client (default 3). If the server does not respond at leastssh_server_alive_count_maxtimes, a reconnection is forced. This helps to avoid stuck connections in case network link is severed without notification in the TCP layer. SpecifyingNonewill omit the option from the ssh client command line.http_url(optional) HTTP URL to use when fetching events from the Gerrit internal database. This is used to fill in events that have occurred when Buildbot was not connected to the SSH API. If the URL of the events-log endpoint for your server is
https://example.com/a/plugins/events-log/events/then thehttp_urlishttps://example.com.http_auth(optional) authentication credentials for events-log plugin. If Gerrit is configured with
BasicAuth, then it shall be('login', 'password'). If Gerrit is configured withDigestAuth, then it shall berequests.auth.HTTPDigestAuth('login', 'password')from the requests module. However, note that usage ofrequests.auth.HTTPDigestAuthis incompatible withtreq.http_poll_interval(optional) frequency to poll the HTTP API when events are not being received through the SSH connection. The default is 30 seconds.
debugPrint Gerrit event in the log (default False). This allows to debug event content, but will eventually fill your logs with useless Gerrit event logs.
By default this class adds a change to the Buildbot system for each of the following events:
patchset-createdA change is proposed for review. Automatic checks like
checkpatch.plcan be automatically triggered. Beware of what kind of automatic task you trigger. At this point, no trusted human has reviewed the code, and a patch could be specially crafted by an attacker to compromise your workers.ref-updatedA change has been merged into the repository. Typically, this kind of event can lead to a complete rebuild of the project, and upload binaries to an incremental build results server.
But you can specify how to handle events:
Any event with change and patchSet will be processed by universal collector by default.
In case you’ve specified processing function for the given kind of events, all events of this kind will be processed only by this function, bypassing universal collector.
An example:
from buildbot.plugins import changes
class MyGerritChangeSource(changes.GerritChangeSource):
"""Custom GerritChangeSource
"""
def eventReceived_patchset_created(self, properties, event):
"""Handler events without properties
"""
properties = {}
self.addChangeFromEvent(properties, event)
This class will populate the property list of the triggered build with the info received from Gerrit server in JSON format.
Warning
If you selected GerritChangeSource, you must use Gerrit source step: the
branch property of the change will be target_branch/change_id and such a ref
cannot be resolved, so the Git source step would fail.
In case of patchset-created event, these properties will be:
event.change.branchBranch of the Change
event.change.idChange’s ID in the Gerrit system (the ChangeId: in commit comments)
event.change.numberChange’s number in Gerrit system
event.change.owner.emailChange’s owner email (owner is first uploader)
event.change.owner.nameChange’s owner name
event.change.projectProject of the Change
event.change.subjectChange’s subject
event.change.urlURL of the Change in the Gerrit’s web interface
event.patchSet.numberPatchset’s version number
event.patchSet.refPatchset’s Gerrit “virtual branch”
event.patchSet.revisionPatchset’s Git commit ID
event.patchSet.uploader.emailPatchset uploader’s email (owner is first uploader)
event.patchSet.uploader.namePatchset uploader’s name (owner is first uploader)
event.typeEvent type (
patchset-created)event.uploader.emailPatchset uploader’s email
event.uploader.namePatchset uploader’s name
In case of ref-updated event, these properties will be:
event.refUpdate.newRevNew Git commit ID (after merger)
event.refUpdate.oldRevPrevious Git commit ID (before merger)
event.refUpdate.projectProject that was updated
event.refUpdate.refNameBranch that was updated
event.submitter.emailSubmitter’s email (merger responsible)
event.submitter.nameSubmitter’s name (merger responsible)
event.typeEvent type (
ref-updated)event.submitter.emailSubmitter’s email (merger responsible)
event.submitter.nameSubmitter’s name (merger responsible)
A configuration for this source might look like:
from buildbot.plugins import changes
c['change_source'] = changes.GerritChangeSource(
"gerrit.example.com",
"gerrit_user",
handled_events=["patchset-created", "change-merged"])
See master/docs/examples/git_gerrit.cfg or master/docs/examples/repo_gerrit.cfg in
the Buildbot distribution for a full example setup of Git+Gerrit or Repo+Gerrit of
GerritChangeSource.
2.5.3.14. GerritEventLogPoller
- class buildbot.changes.gerritchangesource.GerritEventLogPoller
The GerritEventLogPoller class is similar to GerritChangeSource and
connects to the Gerrit server only by its HTTP interface and uses the events-log plugin.
Note
The GerritEventLogPoller requires either the txrequest or the treq package.
The GerritEventLogPoller accepts the following arguments:
baseURLThe HTTP url where to find Gerrit. If the URL of the events-log endpoint for your server is
https://example.com/a/plugins/events-log/events/then thebaseURLishttps://example.com/a. Ensure that/ais included.authA request’s authentication configuration. If Gerrit is configured with
BasicAuth, then it shall be('login', 'password'). If Gerrit is configured withDigestAuth, then it shall berequests.auth.HTTPDigestAuth('login', 'password')from the requests module. However, note that usage ofrequests.auth.HTTPDigestAuthis incompatible withtreq.handled_eventsEvent to be handled (optional). By default processes patchset-created and ref-updated.
pollIntervalInterval in seconds between polls (default is 30 sec).
pollAtLaunchDetermines when the first poll occurs. True = immediately on launch (default), False = wait for one pollInterval.
gitBaseURLThe git URL where Gerrit is accessible via git+ssh protocol.
get_filesPopulate the files attribute of emitted changes (default False). Buildbot will run an extra query command for each handled event to determine the changed files.
debugPrint Gerrit event in the log (default False). This allows to debug event content, but will eventually fill your logs with useless Gerrit event logs.
The same customization can be done as GerritChangeSource for handling special events.
2.5.3.15. GerritChangeFilter
- class buildbot.changes.gerritchangesource.GerritChangeFilter
GerritChangeFilter is a ready to use ChangeFilter you can pass to
AnyBranchScheduler in order to filter changes, to create pre-commit builders or
post-commit schedulers. It has the same api as Change Filter, except it has
additional eventtype set of filter (can as well be specified as value, list, regular expression,
or callable).
An example is following:
from buildbot.plugins import schedulers, util
# this scheduler will create builds when a patch is uploaded to gerrit
# but only if it is uploaded to the "main" branch
schedulers.AnyBranchScheduler(
name="main-precommit",
change_filter=util.GerritChangeFilter(branch="main", eventtype="patchset-created"),
treeStableTimer=15*60,
builderNames=["main-precommit"])
# this scheduler will create builds when a patch is merged in the "main" branch
# for post-commit tests
schedulers.AnyBranchScheduler(name="main-postcommit",
change_filter=util.GerritChangeFilter("main", "ref-updated"),
treeStableTimer=15*60,
builderNames=["main-postcommit"])
2.5.3.16. Change Hooks (HTTP Notifications)
Buildbot already provides a web frontend, and that frontend can easily be used to receive HTTP push notifications of commits from services like GitHub. See Change Hooks for more information.
2.5.4. Changes
- class buildbot.changes.changes.Change
A Change is an abstract way Buildbot uses to represent a single change to the source files
performed by a developer. In version control systems that support the notion of atomic check-ins, a
change represents a changeset or commit. Instances of Change have the following
attributes.
2.5.4.1. Who
Each Change has a who attribute, which specifies which developer is responsible
for the change. This is a string which comes from a namespace controlled by the VC repository.
Frequently this means it is a username on the host which runs the repository, but not all VC
systems require this. Each StatusNotifier will map the who attribute into
something appropriate for their particular means of communication: an email address, an IRC handle,
etc.
This who attribute is also parsed and stored into Buildbot’s database (see
User Objects). Currently, only who attributes in Changes from git repositories are
translated into user objects, but in the future all incoming Changes will have their who parsed
and stored.
2.5.4.2. Files
It also has a list of files, which are just the tree-relative filenames of any files that
were added, deleted, or modified for this Change. These filenames are checked by the
fileIsImportant function of a scheduler to decide whether it should trigger a new build or
not. For example, the scheduler could use the following function to only run a build if a C file
was checked in:
def has_C_files(change):
for name in change.files:
if name.endswith(".c"):
return True
return False
Certain BuildSteps can also use the list of changed files to run a more targeted series
of tests, e.g. the python_twisted.Trial step can run just the unit tests that provide coverage
for the modified .py files instead of running the full test suite.
2.5.4.4. Project
The project attribute of a change or source stamp describes the project to which it
corresponds, as a short human-readable string. This is useful in cases where multiple independent
projects are built on the same buildmaster. In such cases, it can be used to control which builds
are scheduled for a given commit, and to limit status displays to only one project.
2.5.4.5. Repository
This attribute specifies the repository in which this change occurred. In the case of DVCS’s, this information may be required to check out the committed source code. However, using the repository from a change has security risks: if Buildbot is configured to blindly trust this information, then it may easily be tricked into building arbitrary source code, potentially compromising the workers and the integrity of subsequent builds.
2.5.4.6. Codebase
This attribute specifies the codebase to which this change was made. As described in source
stamps section, multiple repositories may contain the same codebase. A change’s
codebase is usually determined by the codebaseGenerator configuration. By default the
codebase is ‘’; this value is used automatically for single-codebase configurations.
2.5.4.7. Revision
Each Change can have a revision attribute, which describes how to get a tree with a
specific state: a tree which includes this Change (and all that came before it) but none that come
after it. If this information is unavailable, the revision attribute will be None.
These revisions are provided by the ChangeSource.
Revisions are always strings.
- CVS
revisionis the seconds since the epoch as an integer.- SVN
revisionis the revision number- Darcs
revisionis a large string, the output of darcs changes --context- Mercurial
revisionis a short string (a hash ID), the output of hg identify- P4
revisionis the transaction number- Git
revisionis a short string (a SHA1 hash), the output of e.g. git rev-parse
2.5.4.8. Branches
The Change might also have a branch attribute.
This indicates that all of the Change’s files are in the same named branch.
The schedulers get to decide whether the branch should be built or not.
For VC systems like CVS, Git, Mercurial and Monotone the branch name is unrelated to the
filename. (That is, the branch name and the filename inhabit unrelated namespaces.) For SVN,
branches are expressed as subdirectories of the repository, so the file’s repourl is a
combination of some base URL, the branch name, and the filename within the branch. (In a sense, the
branch name and the filename inhabit the same namespace.) Darcs branches are subdirectories of a
base URL just like SVN.
- CVS
branch=’warner-newfeature’, files=[‘src/foo.c’]
- SVN
branch=’branches/warner-newfeature’, files=[‘src/foo.c’]
- Darcs
branch=’warner-newfeature’, files=[‘src/foo.c’]
- Mercurial
branch=’warner-newfeature’, files=[‘src/foo.c’]
- Git
branch=’warner-newfeature’, files=[‘src/foo.c’]
- Monotone
branch=’warner-newfeature’, files=[‘src/foo.c’]
2.5.4.9. Change Properties
A Change may have one or more properties attached to it, usually specified through the Force Build
form or sendchange. Properties are discussed in detail in the Build Properties
section.
2.5.5. Schedulers
Schedulers are responsible for initiating builds on builders.
Some schedulers listen for changes from ChangeSources and generate build sets in response to these changes. Others generate build sets without changes, based on other events in the buildmaster.
2.5.5.1. Configuring Schedulers
The schedulers configuration parameter gives a list of scheduler instances, each of which
causes builds to be started on a particular set of Builders.
The two basic scheduler classes you are likely to start with are SingleBranchScheduler
and Periodic, but you can write a customized subclass to implement more complicated
build scheduling.
Scheduler arguments should always be specified by name (as keyword arguments), to allow for future expansion:
sched = SingleBranchScheduler(name="quick", builderNames=['lin', 'win'])
There are several common arguments for schedulers, although not all are available with all schedulers.
name
Each Scheduler must have a unique name. This is used in status displays, and is also available in the build property
scheduler.
builderNames
This is the set of builders which this scheduler should trigger, specified as a list of names (strings). This can also be an
IRenderableobject which will render to a list of builder names (or a list ofIRenderablethat will render to builder names).Note
- When
builderNamesis rendered, these additionalPropertiesattributesare available:
masterA reference to the
BuildMasterobject that owns this scheduler. This can be used to access the data API.
sourcestampsThe list of sourcestamps that triggered the scheduler.
changesThe list of changes associated with the sourcestamps.
filesThe list of modified files associated with the changes.
Any property attached to the change(s) that triggered the scheduler will be combined and available when rendering builderNames.
Here is a simple example:
from buildbot.plugins import util, schedulers @util.renderer def builderNames(props): builders = set() for f in props.files: if f.endswith('.rst'): builders.add('check_docs') if f.endswith('.c'): builders.add('check_code') return list(builders) c['schedulers'] = [ schedulers.AnyBranchScheduler( name='all', builderNames=builderNames, ) ]And a more complex one:
import fnmatch from twisted.internet import defer from buildbot.plugins import util, schedulers @util.renderer @defer.inlineCallbacks def builderNames(props): # If "buildername_pattern" is defined with "buildbot sendchange", # check if the builder name matches it. pattern = props.getProperty('buildername_pattern') # If "builder_tags" is defined with "buildbot sendchange", # only schedule builders that have the specified tags. tags = props.getProperty('builder_tags') builders = [] for b in (yield props.master.data.get(('builders',))): if pattern and not fnmatch.fnmatchcase(b['name'], pattern): continue if tags and not set(tags.split()).issubset(set(b['tags'])): continue builders.append(b['name']) return builders c['schedulers'] = [ schedulers.AnyBranchScheduler( name='matrix', builderNames=builderNames, ) ]
properties (optional)
This is a dictionary specifying properties that will be transmitted to all builds started by this scheduler. The
ownerproperty may be of particular interest, as its content (string) will be added to the list of “interested users” (Doing Things With Users) for each triggered build.For example:
sched = Scheduler(..., properties = { 'owner': 'zorro@example.com' })
codebases (optional)
Specifies codebase definitions that are used when the scheduler processes data from more than one repository at the same time.
The
codebasesparameter is only used to fill in missing details about a codebase when scheduling a build. For example, when a change to codebaseAoccurs, a scheduler must invent a sourcestamp for codebaseB. Source steps that specify codebaseBas their codebase will use the invented timestamp.The parameter does not act as a filter on incoming changes – use a change filter for that purpose.
This parameter can be specified in two forms:
as a list of strings. This is the simplest form; use it if no special overrides are needed. In this form, just the names of the codebases are listed.
as a dictionary of dictionaries. In this form, the per-codebase overrides of repository, branch and revision can be specified.
Each codebase definition dictionary is a dictionary with any of the keys:
repository,branch,revision. The codebase definitions are combined in a dictionary keyed by the name of the codebase.codebases = {'codebase1': {'repository':'....', 'branch':'default', 'revision': None}, 'codebase2': {'repository':'....'} }
fileIsImportant (optional)
A callable which takes as argument a Change instance and returns
Trueif the change is worth building, andFalseif it is not. Unimportant Changes are accumulated until the build is triggered by an important change. The default value ofNonemeans that all Changes are important.
change_filter (optional)
The change filter that will determine which changes are recognized by this scheduler (see ChangeFilter). Note that this is different from
fileIsImportant; if the change filter filters out a change, the change is completely ignored by the scheduler. If a change is allowed by the change filter but is deemed unimportant, it will not cause builds to start but will be remembered and shown in status displays. The default value ofNonedoes not filter any changes at all.
onlyImportant (optional)
A boolean that, when
True, only adds important changes to the buildset as specified in thefileIsImportantcallable. This means that unimportant changes are ignored the same way achange_filterfilters changes. The default value isFalseand only applies whenfileIsImportantis given.
reason (optional)
A string that will be used as the reason for the triggered build. By default it lists the type and name of the scheduler triggering the build.
priority (optional)
Specifies the default priority for
BuildRequestscreated by this scheduler. It can either be an integer or a function (see Scheduler Priority Functions). By default it createsBuildRequestswith priority 0.
The remaining subsections represent a catalog of the available scheduler types.
All these schedulers are defined in modules under buildbot.schedulers, and their docstrings
are the best source of documentation on the arguments each one takes.
2.5.5.2. Scheduler Resiliency
In a multi-master configuration, schedulers with the same name can be configured on multiple masters. Only one instance of the scheduler will be active. If that instance becomes inactive, due to its master being shut down or failing, then another instance will become active after a short delay. This provides resiliency in scheduler configurations, so that schedulers are not a single point of failure in a Buildbot infrastructure.
The Data API and web UI display the master on which each scheduler is running.
There is currently no mechanism to control which master’s scheduler instance becomes active. The behavior is nondeterministic, based on the timing of polling by inactive schedulers. The failover is non-revertive.
2.5.5.3. Usage example
A quick scheduler might exist to give immediate feedback to developers, hoping to catch obvious problems in the code that can be detected quickly. These typically do not run the full test suite, nor do they run on a wide variety of platforms. They also usually do a VC update rather than performing a brand-new checkout each time.
A separate full scheduler might run more comprehensive tests, to catch more subtle problems.
It might be configured to run after the quick scheduler, to give developers time to commit fixes
to bugs caught by the quick scheduler before running the comprehensive tests.
This scheduler would also feed multiple Builders.
Many schedulers can be configured to wait a while after seeing a source-code change - this is the tree stable timer. The timer allows multiple commits to be “batched” together. This is particularly useful in distributed version control systems, where a developer may push a long sequence of changes all at once. To save resources, it’s often desirable only to test the most recent change.
Schedulers can also filter out the changes they are interested in, based on a number of criteria. For example, a scheduler that only builds documentation might skip any changes that do not affect the documentation. Schedulers can also filter on the branch to which a commit was made.
Periodic builds (those which are run every N seconds rather than after new Changes arrive) are
triggered by a special Periodic scheduler.
Each scheduler creates and submits BuildSet objects to the BuildMaster, which is
then responsible for making sure the individual BuildRequests are delivered to the target
Builders.
Scheduler instances are activated by placing them in the schedulers list in the
buildmaster config file. Each scheduler must have a unique name.
2.5.5.4. Scheduler Types
SingleBranchScheduler
This is the original and still most popular scheduler class.
It follows exactly one branch, and starts a configurable tree-stable-timer after each change on that
branch. When the timer expires, it starts a build on some set of Builders.
This scheduler accepts a fileIsImportant function which can be used to ignore some Changes
if they do not affect any important files.
If treeStableTimer is not set, then this scheduler starts a build for every Change that matches
its change_filter and satisfies fileIsImportant.
If treeStableTimer is set, then a build is triggered for each set of Changes that arrive in
intervals shorter than the configured time and match the filters.
Note
The behavior of this scheduler is undefined, if treeStableTimer is set, and changes from
multiple branches, repositories or codebases are accepted by the filter.
Note
The codebases argument will filter out codebases not specified there, but won’t filter
based on the branches specified there.
The arguments to this scheduler are:
name
builderNames
properties (optional)
codebases (optional)
fileIsImportant (optional)
change_filter (optional)
onlyImportant (optional)
reason (optional)
treeStableTimer
The scheduler will wait for this many seconds before starting the build. If new changes are made during this interval, the timer will be restarted. So the build will be started after this many seconds of inactivity following the last change.
If
treeStableTimerisNone, then a separate build is started immediately for each Change.
categories (deprecated; use change_filter)
A list of categories of changes that this scheduler will respond to. If this is specified, then any non-matching changes are ignored.
branch (deprecated; use change_filter)
The scheduler will pay attention to this branch, ignoring Changes that occur on other branches. Setting
branchequal to the special value ofNonemeans it should only pay attention to the default branch.Note
Noneis a keyword, not a string, so writeNoneand not"None".
Example:
from buildbot.plugins import schedulers, util
quick = schedulers.SingleBranchScheduler(
name="quick",
change_filter=util.ChangeFilter(branch='master'),
treeStableTimer=60,
builderNames=["quick-linux", "quick-netbsd"])
full = schedulers.SingleBranchScheduler(
name="full",
change_filter=util.ChangeFilter(branch='master'),
treeStableTimer=5*60,
builderNames=["full-linux", "full-netbsd", "full-OSX"])
c['schedulers'] = [quick, full]
In this example, the two quick builders are triggered 60 seconds after the tree has been changed. The full builders do not run quite that quickly (they wait 5 minutes), so that hopefully, if the quick builds fail due to a missing file or a simple typo, the developer can discover and fix the problem before the full builds are started. Both schedulers only pay attention to the default branch: any changes on other branches are ignored. Each scheduler triggers a different set of builders, referenced by name.
Note
The old names for this scheduler, buildbot.scheduler.Scheduler and
buildbot.schedulers.basic.Scheduler, are deprecated in favor of using buildbot.plugins:
from buildbot.plugins import schedulers
However if you must use a fully qualified name, it is buildbot.schedulers.basic.SingleBranchScheduler.
AnyBranchScheduler
This scheduler uses a tree-stable-timer like the default one, but uses a separate timer for each branch.
If treeStableTimer is not set, then this scheduler is indistinguishable from
SingleBranchScheduler.
If treeStableTimer is set, then a build is triggered for each set of Changes that arrive in
intervals shorter than the configured time and match the filters.
The arguments to this scheduler are:
name
builderNames
properties (optional)
codebases (optional)
fileIsImportant (optional)
change_filter (optional)
onlyImportant (optional)
reason (optional)
treeStableTimer
The scheduler will wait for this many seconds before starting a build. If new changes are made on the same branch during this interval, the timer will be restarted.
branches (deprecated; use change_filter)
Changes on branches not specified on this list will be ignored.
categories (deprecated; use change_filter)
A list of categories of changes that this scheduler will respond to. If this is specified, then any non-matching changes are ignored.
Dependent Scheduler
It is common to wind up with one kind of build which should only be performed if the same source code was successfully handled by some other kind of build first. An example might be a packaging step: you might only want to produce .deb or RPM packages from a tree that was known to compile successfully and pass all unit tests. You could put the packaging step in the same Build as the compile and testing steps, but there might be other reasons to not do this (in particular you might have several Builders worth of compiles/tests, but only wish to do the packaging once). Another example is if you want to skip the full builds after a failing quick build of the same source code. Or, if one Build creates a product (like a compiled library) that is used by some other Builder, you’d want to make sure the consuming Build is run after the producing one.
You can use dependencies to express this relationship to Buildbot. There is a special kind of
scheduler named Dependent that will watch an upstream scheduler for builds to
complete successfully (on all of its Builders). Each time that happens, the same source code (i.e.
the same SourceStamp) will be used to start a new set of builds, on a different set of
Builders. This downstream scheduler doesn’t pay attention to Changes at all. It only pays
attention to the upstream scheduler.
If the build fails on any of the Builders in the upstream set, the downstream builds will not fire.
Note that, for SourceStamps generated by a Dependent scheduler, the revision is
None, meaning HEAD. If any changes are committed between the time the upstream scheduler begins
its build and the time the dependent scheduler begins its build, then those changes will be
included in the downstream build. See the Triggerable scheduler for a more flexible
dependency mechanism that can avoid this problem.
The arguments to this scheduler are:
name
builderNames
properties (optional)
codebases (optional)
upstream
The upstream scheduler to watch. Note that this is an instance, not the name of the scheduler.
Example:
from buildbot.plugins import schedulers
tests = schedulers.SingleBranchScheduler(name="just-tests",
treeStableTimer=5*60,
builderNames=["full-linux",
"full-netbsd",
"full-OSX"])
package = schedulers.Dependent(name="build-package",
upstream=tests, # <- no quotes!
builderNames=["make-tarball", "make-deb",
"make-rpm"])
c['schedulers'] = [tests, package]
Periodic Scheduler
This simple scheduler just triggers a build every N seconds.
The arguments to this scheduler are:
name
builderNames
properties (optional)
codebases (optional)
fileIsImportant (optional)
change_filter (optional)
onlyImportant (optional)
reason (optional)
createAbsoluteSourceStamps (optional)
This option only has effect when using multiple codebases. When
True, it uses the last seen revision for each codebase that does not have a change. WhenFalse(the default), codebases without changes will use the revision from thecodebasesargument.
onlyIfChanged (optional)
If this is
True, then builds will be scheduled at the designated time only if the specified branch has seen an important change since the previous build. If there is no previous build or the previous build was made when this option wasFalsethen the build will be scheduled even if there are no new changes. By default this setting isFalse.
periodicBuildTimer
The time, in seconds, after which to start a build.
Example:
from buildbot.plugins import schedulers
nightly = schedulers.Periodic(name="daily",
builderNames=["full-solaris"],
periodicBuildTimer=24*60*60)
c['schedulers'] = [nightly]
The scheduler in this example just runs the full solaris build once per day. Note that this scheduler only lets you control the time between builds, not the absolute time-of-day of each Build, so this could easily wind up an evening or every afternoon scheduler depending upon when it was first activated.
Nightly Scheduler
This is highly configurable periodic build scheduler, which triggers a build at particular times of
day, week, month, or year. The configuration syntax is very similar to the well-known crontab
format, in which you provide values for minute, hour, day, and month (some of which can be
wildcards), and a build is triggered whenever the current time matches the given constraints. This
can run a build every night, every morning, every weekend, alternate Thursdays, on your boss’s
birthday, etc.
Pass some subset of minute, hour, dayOfMonth, month, and dayOfWeek; each may
be a single number or a list of valid values. The builds will be triggered whenever the current
time matches these values. Wildcards are represented by a ‘*’ string. All fields default to a
wildcard except ‘minute’, so with no fields, this defaults to a build every hour, on the hour. The
full list of parameters is:
name
builderNames
properties (optional)
codebases (optional)
fileIsImportant (optional)
change_filter (optional)
onlyImportant (optional)
reason (optional)
createAbsoluteSourceStamps (optional)
This option only has effect when using multiple codebases. When
True, it uses the last seen revision for each codebase that does not have a change. WhenFalse(the default), codebases without changes will use the revision from thecodebasesargument.
onlyIfChanged (optional)
If this is
True, then builds will not be scheduled at the designated time unless the change filter has accepted an important change since the previous build. The default value isFalse.
branch (optional)
(Deprecated; use
change_filterandcodebases.) The branch to build when the time comes, and the branch to filter for ifchange_filteris not specified. Remember that a value ofNonehere means the default branch, and will not match other branches!
minute (optional)
The minute of the hour on which to start the build. This defaults to 0, meaning an hourly build.
hour (optional)
The hour of the day on which to start the build, in 24-hour notation. This defaults to *, meaning every hour.
dayOfMonth (optional)
The day of the month to start a build. This defaults to
*, meaning every day. UseLto specify last day of the month. Last day option respects leap years.
month (optional)
The month in which to start the build, with January = 1. This defaults to
*, meaning every month. Month or month range / list as standard C abbreviated namejan-feb,jan,dec.
dayOfWeek (optional)
The day of the week to start a build, with Monday = 0. This defaults to
*, meaning every day of the week or nth weekday of month. Like first Monday of month1#1, last Monday of monthL1, Monday + Fridaymon,frior ranges Monday to Fridaymon-fri.
Forcing builds when there are no changes
Nightly scheduler supports scheduling builds even in there were no important changes and
onlyIfChanged was set to True. This is controlled by force_at_* parameters. The feature
is enabled if least one of them is set.
The time interval identified by force_at_minute, force_at_hour, force_at_day_of_month,
force_at_month and force_at_day_of_week must be subset of time interval identified by
minute, hour, dayOfMonth, month, dayOfWeek.
force_at_minute (optional)
The minute of the hour on which to start the build even if there were no important changes and
onlyIfChangedwas set toTrue. The default isNonemeaning this feature is disabled. If the feature is enabled by setting anotherforce_at_*parameter, then the default value is0meaning builds will run every hour.
force_at_hour (optional)
The hour of the day on which to start the build even if there were no important changes and
onlyIfChangedwas set toTrue. The default isNonemeaning this feature is disabled. If the feature is enabled by setting anotherforce_at_*parameter, then the default value is*meaning builds will run each hour.
force_at_day_of_month (optional)
The day of the month on which to start the build even if there were no important changes and
onlyIfChangedwas set toTrue. The default isNonemeaning this feature is disabled. If the feature is enabled by setting anotherforce_at_*parameter, then the default value is*meaning builds will run each day.
force_at_month (optional)
The month of the year on which to start the build even if there were no important changes and
onlyIfChangedwas set toTrue. The default isNonemeaning this feature is disabled. If the feature is enabled by setting anotherforce_at_*parameter, then the default value is*meaning builds will run each month.
force_at_day_of_week (optional)
The day of the week on which to start the build even if there were no important changes and
onlyIfChangedwas set toTrue. The default isNonemeaning this feature is disabled. If the feature is enabled by setting anotherforce_at_*parameter, then the default value is*meaning builds will run each day of the week.
Example
For example, the following master.cfg clause will cause a build to be started every night
at 3:00am:
from buildbot.plugins import schedulers, util
c['schedulers'].append(
schedulers.Nightly(name='nightly',
change_filter=util.ChangeFilter(branch='master'),
builderNames=['builder1', 'builder2'],
hour=3, minute=0))
This scheduler will perform a build each Monday morning at 6:23am and again at 8:23am, but only if someone has committed code in the interim:
c['schedulers'].append(
schedulers.Nightly(name='BeforeWork',
change_filter=util.ChangeFilter(branch='default'),
builderNames=['builder1'],
dayOfWeek=0, hour=[6,8], minute=23,
onlyIfChanged=True))
The following runs a build every two hours, using Python’s range function:
c.schedulers.append(
schedulers.Nightly(name='every2hours',
change_filter=util.ChangeFilter(branch=None), # default branch
builderNames=['builder1'],
hour=range(0, 24, 2)))
Finally, this example will run only on December 24th:
c['schedulers'].append(
schedulers.Nightly(name='SleighPreflightCheck',
change_filter=util.ChangeFilter(branch=None), # default branch
builderNames=['flying_circuits', 'radar'],
month=12,
dayOfMonth=24,
hour=12,
minute=0))
Try Schedulers
This scheduler allows developers to use the buildbot try command to trigger
builds of code they have not yet committed. See try for complete details.
Two implementations are available: Try_Jobdir and Try_Userpass. The former
monitors a job directory, specified by the jobdir parameter, while the latter listens for PB
connections on a specific port, and authenticates against userport.
The buildmaster must have a scheduler instance in the config file’s schedulers list to
receive try requests. This lets the administrator control who may initiate these trial builds,
which branches are eligible for trial builds, and which Builders should be used for them.
The scheduler has various means to accept build requests. All of them enforce more security than the usual buildmaster ports do. Any source code being built can be used to compromise the worker accounts, but in general that code must be checked out from the VC repository first, so only people with commit privileges can get control of the workers. The usual force-build control channels can waste worker time but do not allow arbitrary commands to be executed by people who don’t have those commit privileges. However, the source code patch that is provided with the trial build does not have to go through the VC system first, so it is important to make sure these builds cannot be abused by a non-committer to acquire as much control over the workers as a committer has. Ideally, only developers who have commit access to the VC repository would be able to start trial builds, but unfortunately, the buildmaster does not, in general, have access to the VC system’s user list.
As a result, the try scheduler requires a bit more configuration. There are currently two ways to set this up:
jobdir (ssh)
This approach creates a command queue directory, called the
jobdir, in the buildmaster’s working directory. The buildmaster admin sets the ownership and permissions of this directory to only grant write access to the desired set of developers, all of whom must have accounts on the machine. The buildbot try command creates a special file containing the source stamp information and drops it in the jobdir, just like a standard maildir. When the buildmaster notices the new file, it unpacks the information inside and starts the builds.The config file entries used by ‘buildbot try’ either specify a local queuedir (for which write and mv are used) or a remote one (using scp and ssh).
The advantage of this scheme is that it is quite secure, the disadvantage is that it requires fiddling outside the buildmaster config (to set the permissions on the jobdir correctly). If the buildmaster machine happens to also house the VC repository, then it can be fairly easy to keep the VC userlist in sync with the trial-build userlist. If they are on different machines, this will be much more of a hassle. It may also involve granting developer accounts on a machine that would not otherwise require them.
To implement this, the worker invokes
ssh -l username host buildbot tryserver ARGS, passing the patch contents over stdin. The arguments must include the inlet directory and the revision information.
user+password (PB)
In this approach, each developer gets a username/password pair, which are all listed in the buildmaster’s configuration file. When the developer runs buildbot try, their machine connects to the buildmaster via PB and authenticates themselves using that username and password, then sends a PB command to start the trial build.
The advantage of this scheme is that the entire configuration is performed inside the buildmaster’s config file. The disadvantages are that it is less secure (while the cred authentication system does not expose the password in plaintext over the wire, it does not offer most of the other security properties that SSH does). In addition, the buildmaster admin is responsible for maintaining the username/password list, adding and deleting entries as developers come and go.
For example, to set up the jobdir style of trial build, using a command queue directory of
MASTERDIR/jobdir (and assuming that all your project developers were members of the
developers unix group), you would first set up that directory:
mkdir -p MASTERDIR/jobdir MASTERDIR/jobdir/new MASTERDIR/jobdir/cur MASTERDIR/jobdir/tmp
chgrp developers MASTERDIR/jobdir MASTERDIR/jobdir/*
chmod g+rwx,o-rwx MASTERDIR/jobdir MASTERDIR/jobdir/*
and then use the following scheduler in the buildmaster’s config file:
from buildbot.plugins import schedulers
s = schedulers.Try_Jobdir(name="try1",
builderNames=["full-linux", "full-netbsd", "full-OSX"],
jobdir="jobdir")
c['schedulers'] = [s]
Note that you must create the jobdir before telling the buildmaster to use this configuration,
otherwise you will get an error. Also remember that the buildmaster must be able to read and write
to the jobdir as well. Be sure to watch the twistd.log file (Logfiles) as you start
using the jobdir, to make sure the buildmaster is happy with it.
Note
Patches in the jobdir are encoded using netstrings, which place an arbitrary upper limit on patch size of 99999 bytes. If your submitted try jobs are rejected with BadJobfile, try increasing this limit with a snippet like this in your master.cfg:
from twisted.protocols.basic import NetstringReceiver
NetstringReceiver.MAX_LENGTH = 1000000
To use the username/password form of authentication, create a Try_Userpass instance
instead. It takes the same builderNames argument as the Try_Jobdir form, but accepts
an additional port argument (to specify the TCP port to listen on) and a userpass list of
username/password pairs to accept. Remember to use good passwords for this: the security of the
worker accounts depends upon it:
from buildbot.plugins import schedulers
s = schedulers.Try_Userpass(name="try2",
builderNames=["full-linux", "full-netbsd", "full-OSX"],
port=8031,
userpass=[("alice","pw1"), ("bob", "pw2")])
c['schedulers'] = [s]
Like in most classes in Buildbot, the port argument takes a strports specification.
See twisted.application.strports for details.
Triggerable Scheduler
The Triggerable scheduler waits to be triggered by a Trigger step (see
Trigger) in another build. That step can optionally wait for the scheduler’s builds to
complete. This provides two advantages over Dependent schedulers. First, the same
scheduler can be triggered from multiple builds. Second, the ability to wait for
Triggerable’s builds to complete provides a form of “subroutine call”, where one or
more builds can “call” a scheduler to perform some work for them, perhaps on other workers. The
Triggerable scheduler supports multiple codebases. The scheduler filters out all
codebases from Trigger steps that are not configured in the scheduler.
The parameters are just the basics:
name
builderNames
properties (optional)
codebases (optional)
reason (optional)
This class is only useful in conjunction with the Trigger step.
Here is a fully-worked example:
from buildbot.plugins import schedulers, steps, util
checkin = schedulers.SingleBranchScheduler(name="checkin",
change_filter=util.ChangeFilter(branch=None),
treeStableTimer=5*60,
builderNames=["checkin"])
nightly = schedulers.Nightly(name='nightly',
change_filter=util.ChangeFilter(branch=None),
builderNames=['nightly'],
hour=3, minute=0)
mktarball = schedulers.Triggerable(name="mktarball", builderNames=["mktarball"])
build = schedulers.Triggerable(name="build-all-platforms",
builderNames=["build-all-platforms"])
test = schedulers.Triggerable(name="distributed-test",
builderNames=["distributed-test"])
package = schedulers.Triggerable(name="package-all-platforms",
builderNames=["package-all-platforms"])
c['schedulers'] = [mktarball, checkin, nightly, build, test, package]
# on checkin, make a tarball, build it, and test it
checkin_factory = util.BuildFactory()
checkin_factory.addStep(steps.Trigger(schedulerNames=['mktarball'],
waitForFinish=True))
checkin_factory.addStep(steps.Trigger(schedulerNames=['build-all-platforms'],
waitForFinish=True))
checkin_factory.addStep(steps.Trigger(schedulerNames=['distributed-test'],
waitForFinish=True))
# and every night, make a tarball, build it, and package it
nightly_factory = util.BuildFactory()
nightly_factory.addStep(steps.Trigger(schedulerNames=['mktarball'],
waitForFinish=True))
nightly_factory.addStep(steps.Trigger(schedulerNames=['build-all-platforms'],
waitForFinish=True))
nightly_factory.addStep(steps.Trigger(schedulerNames=['package-all-platforms'],
waitForFinish=True))
NightlyTriggerable Scheduler
- class buildbot.schedulers.timed.NightlyTriggerable
The NightlyTriggerable scheduler is a mix of the Nightly and
Triggerable schedulers. This scheduler triggers builds at a particular time of day,
week, or year, exactly as the Nightly scheduler. However, the source stamp set that is
used is provided by the last Trigger step that targeted this scheduler.
The following parameters are just the basics:
name
builderNames
properties (optional)
codebases (optional)
reason (optional)
minute (optional)
See
Nightly.
hour (optional)
See
Nightly.
dayOfMonth (optional)
See
Nightly.
month (optional)
See
Nightly.
dayOfWeek (optional)
See
Nightly.
This class is only useful in conjunction with the Trigger step.
Note that waitForFinish is ignored by Trigger steps targeting this scheduler.
Here is a fully-worked example:
from buildbot.plugins import schedulers, steps, util
checkin = schedulers.SingleBranchScheduler(name="checkin",
change_filter=util.ChangeFilter(branch=None),
treeStableTimer=5*60,
builderNames=["checkin"])
nightly = schedulers.NightlyTriggerable(name='nightly',
builderNames=['nightly'],
hour=3, minute=0)
c['schedulers'] = [checkin, nightly]
# on checkin, run tests
checkin_factory = util.BuildFactory([
steps.Test(),
steps.Trigger(schedulerNames=['nightly'])
])
# and every night, package the latest successful build
nightly_factory = util.BuildFactory([
steps.ShellCommand(command=['make', 'package'])
])
ForceScheduler Scheduler
The ForceScheduler scheduler is the to configure a “force build” form in the web UI.
For each configured ForceScheduler instance the builder page at
/#/builders/:builderid will show a button at the top right of the page.
If the button is clicked, a dialog will let you choose various parameters for requesting a new build.
The Buildbot framework allows to customize exactly how the build form looks, which builders have a force build form (it might not make sense to force build every builder), and who is allowed to force builds on which builders.
This is done configuring a ForceScheduler and adding it to the list of
schedulers.
The fields visible in the build form are configured by the arguments of ForceScheduler. There are
some pre-defined parameters, the rest are specified by properties parameter. All fields are
configured by a child class of BaseParameter. Use NestedParameter to provide logical groupings for
parameters.
The scheduler takes the following parameters:
name
See name scheduler argument. Force buttons are ordered by this property in the UI (so you can prefix by 01, 02, etc, in order to control precisely the order).
builderNames
List of builders where the force button should appear. See builderNames scheduler argument.
reason
A parameter allowing the user to specify the reason for the build. The default value is a string parameter with a default value “force build”.
reasonString
A string that will be used to create the build reason for the forced build. This string can contain the placeholders
%(owner)sand%(reason)s, which represents the value typed into the reason field.
username
A parameter specifying the username associated with the build (aka owner). The default value is a username parameter.
codebases
A list of strings or CodebaseParameter specifying the codebases that should be presented. The default is a single codebase with no name (i.e. codebases=[‘’]). The value of
Nonewill generate a default, butCodebaseParameter(codebase='', hide=True)will remove all codebases
properties
A list of parameters, one for each property. These can be arbitrary parameters, where the parameter’s name is taken as the property name, or
AnyPropertyParameter, which allows the web user to specify the property name. The default value is an empty list.
buttonName
The name of the “submit” button on the resulting force-build form. This defaults to the name of scheduler.
An example may be better than long explanation. What you need in your config file is something like:
from buildbot.plugins import schedulers, util
sch = schedulers.ForceScheduler(
name="force",
buttonName="pushMe!",
label="My nice Force form",
builderNames=["my-builder"],
codebases=[
util.CodebaseParameter(
"",
label="Main repository",
# will generate a combo box
branch=util.ChoiceStringParameter(
name="branch",
choices=["master", "hest"],
default="master"),
# will generate nothing in the form, but revision, repository,
# and project are needed by buildbot scheduling system so we
# need to pass a value ("")
revision=util.FixedParameter(name="revision", default=""),
repository=util.FixedParameter(name="repository", default=""),
project=util.FixedParameter(name="project", default=""),
),
],
# will generate a text input
reason=util.StringParameter(name="reason",
label="reason:",
required=True, size=80),
# in case you don't require authentication, this will display
# input for user to type their name
username=util.UserNameParameter(label="your name:",
size=80),
# A completely customized property list. The name of the
# property is the name of the parameter
properties=[
util.NestedParameter(name="options", label="Build Options",
layout="vertical", fields=[
util.StringParameter(name="pull_url",
label="optionally give a public Git pull url:",
default="", size=80),
util.BooleanParameter(name="force_build_clean",
label="force a make clean",
default=False)
])
])
This will result in the following UI:
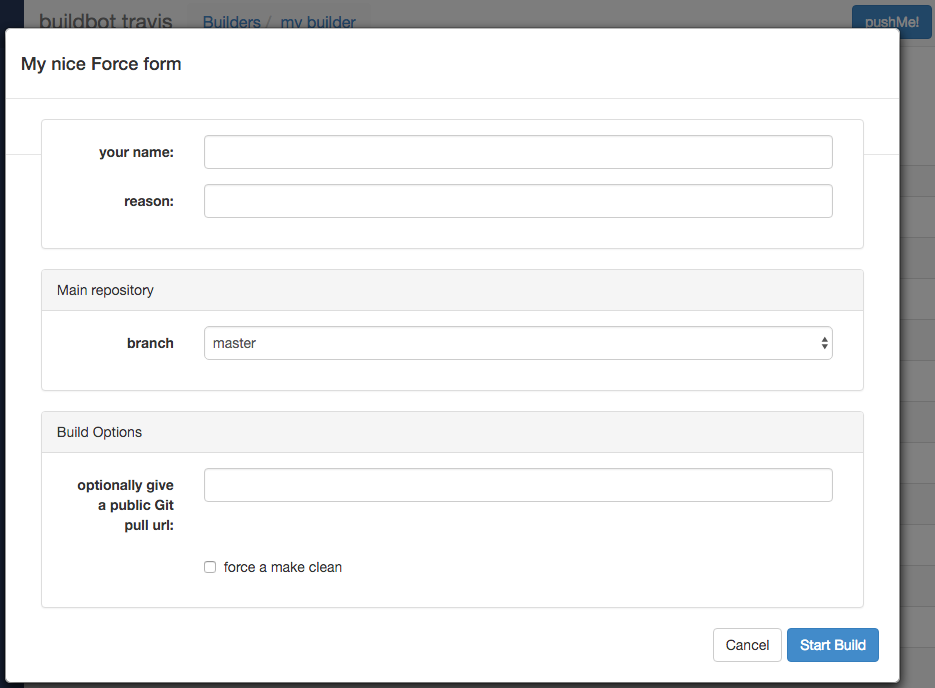
ForceScheduler Parameters
Most of the arguments to ForceScheduler are “parameters”. Several classes of parameters
are available, each describing a different kind of input from a force-build form.
All parameter types have a few common arguments:
name (required)
The name of the parameter. For properties, this will correspond to the name of the property that your parameter will set. The name is also used internally as the identifier for in the HTML form.
label (optional; default is same as name)
The label of the parameter. This is what is displayed to the user.
tablabel (optional; default is same as label)
The label of the tab if this parameter is included into a tab layout NestedParameter. This is what is displayed to the user.
default (optional; default: “”)
The default value for the parameter that is used if there is no user input.
required (optional; default: False)
If this is true, then an error will be shown to user if there is no input in this field
maxsize (optional; default: None)
The maximum size of a field (in bytes). Buildbot will ensure the field sent by the user is not too large.
tooltip (optional; default “”)
The tooltip of the parameter. This will show help text next to the field name, if set.
autopopulate (optional; default: None)
If not None,
autopopulateis a dictionary which describes how other parameters are updated if this one changes. This is useful for when you have lots of parameters, and defaults depends on e.g. the branch. This is implemented generically, and all parameters can update others. Beware of infinite loops!c['schedulers'].append(schedulers.ForceScheduler( name="custom", builderNames=["runtests"], buttonName="Start Custom Build", codebases = [util.CodebaseParameter( codebase='', project=None, branch=util.ChoiceStringParameter( name="branch", label="Branch", strict=False, choices=["master", "dev"], autopopulate={ 'master': { 'build_name': 'build for master branch', }, 'dev': { 'build_name': 'build for dev branch', } } ))], properties=[ util.StringParameter( name="build_name", label="Name of the Build release.", default="")])) # this parameter will be auto populated when user chooses branch
The parameter types are:
NestedParameter
NestedParameter(name="options", label="Build options", layout="vertical", fields=[...]),
This parameter type is a special parameter which contains other parameters. This can be used to group a set of parameters together, and define the layout of your form. You can recursively include NestedParameter into NestedParameter, to build very complex UIs.
It adds the following arguments:
layout (optional, default is “vertical”)
The layout defines how the fields are placed in the form.
The layouts implemented in the standard web application are:
simple: fields are displayed one by one without alignment.They take the horizontal space that they need.
vertical: all fields are displayed vertically, aligned in columns (as per thecolumnattribute of the NestedParameter)
tabs: each field gets its own tab.This can be used to declare complex build forms which won’t fit into one screen. The children fields are usually other NestedParameters with vertical layout.
columns (optional, accepted values are 1, 2, 3, 4)
The number of columns to use for a vertical layout. If omitted, it is set to 1 unless there are more than 3 visible child fields in which case it is set to 2.
FixedParameter
FixedParameter(name="branch", default="trunk"),
This parameter type will not be shown on the web form and always generates a property with its default value.
StringParameter
StringParameter(name="pull_url",
label="optionally give a public Git pull url:",
default="", size=80)
This parameter type will show a single-line text-entry box, and allow the user to enter an arbitrary string. It adds the following arguments:
regex (optional)
A string that will be compiled as a regex and used to validate the input of this parameter.
size (optional; default is 10)
The width of the input field (in characters).
TextParameter
TextParameter(name="comments",
label="comments to be displayed to the user of the built binary",
default="This is a development build", cols=60, rows=5)
This parameter type is similar to StringParameter, except that it is represented in the HTML form
as a textarea, allowing multi-line input. It adds the StringParameter arguments and the
following ones:
cols (optional; default is 80)
The number of columns the
textareawill have.
rows (optional; default is 20)
The number of rows the
textareawill have.
This class could be subclassed to have more customization, e.g.
developer could send a list of Git branches to pull from
developer could send a list of Gerrit changes to cherry-pick,
developer could send a shell script to amend the build.
Beware of security issues anyway.
IntParameter
IntParameter(name="debug_level",
label="debug level (1-10)", default=2)
This parameter type accepts an integer value using a text-entry box.
BooleanParameter
BooleanParameter(name="force_build_clean",
label="force a make clean", default=False)
This type represents a boolean value. It will be presented as a checkbox.
UserNameParameter
UserNameParameter(label="your name:", size=80)
This parameter type accepts a username. If authentication is active, it will use the authenticated user instead of displaying a text-entry box.
size (optional; default is 10)
The width of the input field (in characters).
need_email (optional; default is True)
If true, requires a full email address rather than arbitrary text.
ChoiceStringParameter
ChoiceStringParameter(name="branch",
choices=["main","devel"], default="main")
This parameter type lets the user choose between several choices (e.g. the list of branches you are
supporting, or the test campaign to run). If multiple is false, then its result is a string
with one of the choices. If multiple is true, then the result is a list of strings from the
choices.
Note that for some use cases, the choices need to be generated dynamically.
This can be done via subclassing and overriding the ‘getChoices’ member function.
An example of this is provided by the source for the InheritBuildParameter class.
Its arguments, in addition to the common options, are:
choices
The list of available choices.
strict (optional; default is True)
If true, verify that the user’s input is from the list.
multiple
If true, then the user may select multiple choices.
Example:
ChoiceStringParameter(name="forced_tests",
label="smoke test campaign to run",
default=default_tests,
multiple=True,
strict=True,
choices=["test_builder1", "test_builder2",
"test_builder3"])
# .. and later base the schedulers to trigger off this property:
# triggers the tests depending on the property forced_test
builder1.factory.addStep(Trigger(name="Trigger tests",
schedulerNames=Property("forced_tests")))
Example of scheduler allowing to choose which worker to run on:
worker_list = ["worker1", "worker2", "worker3"]
ChoiceStringParameter(name="worker",
label="worker to run the build on",
default="*",
multiple=False,
strict=True,
choices=worker_list)
# .. and in nextWorker, use this property:
def nextWorker(bldr, workers, buildrequest):
forced_worker = buildrequest.properties.getProperty("worker", "*")
if forced_worker == "*":
return random.choice(workers) if workers else None
for w in workers:
if w.worker.workername == forced_worker:
return w
return None # worker not yet available
c['builders'] = [
BuilderConfig(name='mybuild', factory=f, nextWorker=nextWorker,
workernames=worker_list),
]
CodebaseParameter
CodebaseParameter(codebase="myrepo")
This is a parameter group to specify a sourcestamp for a given codebase.
codebase
The name of the codebase.
branch (optional; default is StringParameter)
A parameter specifying the branch to build.
revision (optional; default is StringParameter)
A parameter specifying the revision to build.
repository (optional; default is StringParameter)
A parameter specifying the repository for the build.
project (optional; default is StringParameter)
A parameter specifying the project for the build.
patch (optional; default is None)
A
PatchParameterspecifying that the user can upload a patch for this codebase.
FileParameter
This parameter allows the user to upload a file to a build.
The user can either write some text to a text area, or select a file from the browser.
Note that the file is then stored inside a property, so a maxsize of 10 megabytes has been set.
You can still override that maxsize if you wish.
PatchParameter
This parameter allows the user to specify a patch to be applied at the source step.
The patch is stored within the sourcestamp, and associated to a codebase.
That is why PatchParameter must be set inside a CodebaseParameter.
PatchParameter is actually a NestedParameter composed of following fields:
FileParameter('body'),
IntParameter('level', default=1),
StringParameter('author', default=""),
StringParameter('comment', default=""),
StringParameter('subdir', default=".")
You can customize any of these fields by overwriting their field name e.g:
c['schedulers'] = [
schedulers.ForceScheduler(
name="force",
codebases=[util.CodebaseParameter("foo", patch=util.PatchParameter(
body=FileParameter('body', maxsize=10000)))], # override the maximum size
# of a patch to 10k instead of 10M
builderNames=["testy"])]
InheritBuildParameter
Note
InheritBuildParameter is not yet ported to data API, and cannot be used with buildbot nine yet (bug #3521).
This is a special parameter for inheriting force build properties from another build. The user is presented with a list of compatible builds from which to choose, and all forced-build parameters from the selected build are copied into the new build. The new parameter is:
compatible_builds
A function to find compatible builds in the build history. This function is given the master instance as first argument, and the current builder name as second argument, or None when forcing all builds.
Example:
@defer.inlineCallbacks
def get_compatible_builds(master, builder):
if builder is None: # this is the case for force_build_all
return ["cannot generate build list here"]
# find all successful builds in builder1 and builder2
builds = []
for builder in ["builder1", "builder2"]:
# get 40 last builds for the builder
build_dicts = yield master.data.get(('builders', builder, 'builds'),
order=['-buildid'], limit=40)
for build_dict in build_dicts:
if build_dict['results'] != SUCCESS:
continue
builds.append(builder + "/" + str(build_dict['number']))
return builds
# ...
sched = Scheduler(...,
properties=[
InheritBuildParameter(
name="inherit",
label="promote a build for merge",
compatible_builds=get_compatible_builds,
required = True),
])
WorkerChoiceParameter
Note
WorkerChoiceParameter is not yet ported to data API, and cannot be used with buildbot nine yet (bug #3521).
This parameter allows a scheduler to require that a build is assigned to the chosen worker. The
choice is assigned to the workername property for the build. The
enforceChosenWorker functor must be assigned to the canStartBuild
parameter for the Builder.
Example:
from buildbot.plugins import util
# schedulers:
ForceScheduler(
# ...
properties=[
WorkerChoiceParameter(),
]
)
# builders:
BuilderConfig(
# ...
canStartBuild=util.enforceChosenWorker,
)
AnyPropertyParameter
This parameter type can only be used in properties, and allows the user to specify both the
property name and value in the web form.
This Parameter is here to reimplement old Buildbot behavior, and should be avoided. Stricter parameter names and types should be preferred.
2.5.6. Workers
The workers configuration key specifies a list of known workers. In the common case, each
worker is defined by an instance of the buildbot.worker.Worker class. It represents a
standard, manually started machine that will try to connect to the Buildbot master as a worker.
Buildbot also supports “on-demand”, or latent, workers, which allow Buildbot to dynamically start
and stop worker instances.
2.5.6.1. Defining Workers
A Worker instance is created with a workername and a workerpassword. These are the
same two values that need to be provided to the worker administrator when they create the worker.
The workername must be unique, of course. The password exists to prevent evildoers from
interfering with Buildbot by inserting their own (broken) workers into the system and thus
displacing the real ones. Password may be a Secret.
Workers with an unrecognized workername or a non-matching password will be rejected when they
attempt to connect, and a message describing the problem will be written to the log file (see
Logfiles).
A configuration for two workers would look like:
from buildbot.plugins import worker
c['workers'] = [
worker.Worker('bot-solaris', 'solarispasswd'),
worker.Worker('bot-bsd', 'bsdpasswd'),
]
2.5.6.2. Worker Options
Properties
Worker objects can also be created with an optional properties argument, a dictionary
specifying properties that will be available to any builds performed on this worker. For example:
c['workers'] = [
worker.Worker('bot-solaris', 'solarispasswd',
properties={'os': 'solaris'}),
]
Worker properties have priority over other sources (Builder, Scheduler,
etc.). You may use the defaultProperties parameter that will only be added to
Build Properties if they are not already set by another source:
c['workers'] = [
worker.Worker('fast-bot', 'fast-passwd',
defaultProperties={'parallel_make': 10}),
]
Worker collects and exposes /etc/os-release fields for interpolation. These can be used to determine details about the running operating
system, such as distribution and version. See https://www.linux.org/docs/man5/os-release.html for
details on possible fields. Each field is imported with os_ prefix and in lower case.
os_id, os_id_like, os_version_id and os_version_codename are always set, but can be
null.
Limiting Concurrency
The Worker constructor can also take an optional max_builds parameter to limit the
number of builds that it will execute simultaneously:
c['workers'] = [
worker.Worker('bot-linux', 'linuxpassword',
max_builds=2),
]
Note
In Worker For Builders concept only one build from the same builder would run on the worker.
Master-Worker TCP Keepalive
By default, the buildmaster sends a simple, non-blocking message to each worker every hour. These keepalives ensure that traffic is flowing over the underlying TCP connection, allowing the system’s network stack to detect any problems before a build is started.
The interval can be modified by specifying the interval in seconds using the keepalive_interval
parameter of Worker (defaults to 3600):
c['workers'] = [
worker.Worker('bot-linux', 'linuxpasswd',
keepalive_interval=3600)
]
The interval can be set to None to disable this functionality altogether.
When Workers Go Missing
Sometimes, the workers go away. One very common reason for this is when the worker process is started once (manually) and left running, but then later the machine reboots and the process is not automatically restarted.
If you’d like to have the administrator of the worker (or other people) be notified by email when
the worker has been missing for too long, just add the notify_on_missing= argument to the
Worker definition. This value can be a single email address, or a list of addresses:
c['workers'] = [
worker.Worker('bot-solaris', 'solarispasswd',
notify_on_missing='bob@example.com')
]
By default, this will send an email when the worker has been disconnected for more than one hour.
Only one email per connection-loss event will be sent. To change the timeout, use
missing_timeout= and give it a number of seconds (the default is 3600).
You can have the buildmaster send an email to multiple recipients by providing a list of addresses instead of a single one:
c['workers'] = [
worker.Worker('bot-solaris', 'solarispasswd',
notify_on_missing=['bob@example.com', 'alice@example.org'],
missing_timeout=300) # notify after 5 minutes
]
The email sent this way will use a MailNotifier (see MailNotifier) status
target, if one is configured. This provides a way for you to control the from address of the
email, as well as the relayhost (aka smarthost) to use as an SMTP server. If no
MailNotifier is configured on this buildmaster, the worker-missing emails will be sent
using a default configuration.
Note that if you want to have a MailNotifier for worker-missing emails but not for regular
build emails, just create one with builders=[], as follows:
from buildbot.plugins import status, worker
m = status.MailNotifier(fromaddr='buildbot@localhost', builders=[],
relayhost='smtp.example.org')
c['reporters'].append(m)
c['workers'] = [
worker.Worker('bot-solaris', 'solarispasswd',
notify_on_missing='bob@example.com')
]
Workers States
There are some times when a worker misbehaves because of issues with its configuration. In those cases, you may want to pause the worker, or maybe completely shut it down.
There are three actions that you may take (in the worker’s web page Actions dialog):
Pause: If a worker is paused, it won’t accept new builds. The action of pausing a worker will not affect any ongoing build.
Graceful Shutdown: If a worker is in graceful shutdown mode, it won’t accept new builds, but will finish the current builds. When all of its build are finished, the buildbot-worker process will terminate.
Force Shutdown: If a worker is in force shutdown mode, it will terminate immediately, and the build it was currently doing will be put to retry state.
Those actions will put the worker in either of two states:
paused: the worker is paused if it is connected but doesn’t accept new builds.
graceful: the worker is graceful if it doesn’t accept new builds, and will shutdown when builds are finished.
A worker might not be able to accept a job for a period of time if buildbot detects a misbehavior. This is called the quarantine timer.
Quarantine timer is an exponential back-off mechanism for workers. This prevents a misbehaving
worker from eating the build queue by quickly finishing builds in EXCEPTION state. When
misbehavior is detected, the timer will pause the worker for 10 seconds, and then the time will
double with each misbehavior detection until the worker finishes a build.
The first case of misbehavior is for a latent worker to not start properly.
The second case of misbehavior is for a build to end with an EXCEPTION status.
Pausing and unpausing a worker will force it to leave quarantine immediately. The quarantine timeout will not be reset until the worker finishes a build.
Worker states are stored in the database, can be queried via REST API, and are visible in the UI’s workers page.
2.5.6.3. Local Workers
For smaller setups, you may want to just run the workers on the same machine as the master. To simplify the maintenance, you may even want to run them in the same process.
This is what LocalWorker is for.
Instead of configuring a worker.Worker, you have to configure a worker.LocalWorker.
As the worker is running on the same process, password is not necessary.
You can run as many local workers as your machine’s CPU and memory allows.
A configuration for two workers would look like:
from buildbot.plugins import worker
c['workers'] = [
worker.LocalWorker('bot1'),
worker.LocalWorker('bot2'),
]
In order to use local workers you need to have buildbot-worker package installed.
2.5.6.4. Latent Workers
The standard Buildbot model has workers started manually. The previous section described how to configure the master for this approach.
Another approach is to let the Buildbot master start workers when builds are ready, on-demand. Thanks to services such as Amazon Web Services’ Elastic Compute Cloud (“AWS EC2”), this is relatively easy to set up, and can be very useful for some situations.
The workers that are started on-demand are called “latent” workers. You can find the list of Supported Latent Workers below.
Common Options
The following options are available for all latent workers.
build_wait_timeoutThis option allows you to specify how long a latent worker should wait after a build for another build before it shuts down. It defaults to 10 minutes. If this is set to 0, then the worker will be shut down immediately. If it is less than 0, it will be shut down only when shutting down master.
check_instance_intervalThis option controls the interval that the health checks run during worker startup. The health checks speed up the detection of irrecoverably crashed worker (e.g. due to an issue with Docker image in the case of Docker workers). Without such checks build would continue waiting for the worker to connect until
missing_timeouttime elapses. The value of the option defaults to 10 seconds.
Supported Latent Workers
As of time of writing, Buildbot supports the following latent workers:
Amazon Web Services Elastic Compute Cloud (“AWS EC2”)
- class buildbot.worker.ec2.EC2LatentWorker
EC2 is a web service that allows you to start virtual machines in an Amazon data center. Please see their website for details, including costs. Using the AWS EC2 latent workers involves getting an EC2 account with AWS and setting up payment; customizing one or more EC2 machine images (“AMIs”) on your desired operating system(s) and publishing them (privately if needed); and configuring the buildbot master to know how to start your customized images for “substantiating” your latent workers.
This document will guide you through setup of a AWS EC2 latent worker:
Get an AWS EC2 Account
To start off, to use the AWS EC2 latent worker, you need to get an AWS developer account and sign up for EC2. Although Amazon often changes this process, these instructions should help you get started:
Go to http://aws.amazon.com/ and click to “Sign Up Now” for an AWS account.
Once you are logged into your account, you need to sign up for EC2. Instructions for how to do this have changed over time because Amazon changes their website, so the best advice is to hunt for it. After signing up for EC2, it may say it wants you to upload an x.509 cert. You will need this to create images (see below) but it is not technically necessary for the buildbot master configuration.
You must enter a valid credit card before you will be able to use EC2. Do that under ‘Payment Method’.
Make sure you’re signed up for EC2 by going to and verifying EC2 is listed.
Create an AMI
Now you need to create an AMI and configure the master. You may need to run through this cycle a few times to get it working, but these instructions should get you started.
Creating an AMI is out of the scope of this document. The EC2 Getting Started Guide is a good resource for this task. Here are a few additional hints.
When an instance of the image starts, it needs to automatically start a buildbot worker that connects to your master (to create a buildbot worker, Creating a worker; to make a daemon, Launching the daemons).
You may want to make an instance of the buildbot worker, configure it as a standard worker in the master (i.e., not as a latent worker), and test and debug it that way before you turn it into an AMI and convert to a latent worker in the master.
In order to avoid extra costs in case of master failure, you should configure the worker of the AMI with
maxretriesoption (see Worker Options) Also see example systemd unit file example
Configure the Master with an EC2LatentWorker
Now let’s assume you have an AMI that should work with the EC2LatentWorker.
It’s now time to set up your buildbot master configuration.
You will need some information from your AWS account: the Access Key Id and the Secret Access Key. If you’ve built the AMI yourself, you probably already are familiar with these values. If you have not, and someone has given you access to an AMI, these hints may help you find the necessary values:
While logged into your AWS account, find the “Access Identifiers” link (either on the left, or via .
On the page, you’ll see alphanumeric values for “Your Access Key Id:” and “Your Secret Access Key:”. Make a note of these. Later on, we’ll call the first one your
identifierand the second one yoursecret_identifier.
When creating an EC2LatentWorker in the buildbot master configuration, the first three arguments are required.
The name and password are the first two arguments, and work the same as with normal workers.
The next argument specifies the type of the EC2 virtual machine (available options as of this writing include m1.small, m1.large, m1.xlarge, c1.medium, and c1.xlarge; see the EC2 documentation for descriptions of these machines).
Here is the simplest example of configuring an EC2 latent worker. It specifies all necessary remaining values explicitly in the instantiation.
from buildbot.plugins import worker
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
ami='ami-12345',
identifier='publickey',
secret_identifier='privatekey'
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
)
]
The ami argument specifies the AMI that the master should start.
The identifier argument specifies the AWS Access Key Id, and the secret_identifier specifies the AWS Secret Access Key.
Both the AMI and the account information can be specified in alternate ways.
Note
Whoever has your identifier and secret_identifier values can request AWS work charged to your account, so these values need to be carefully protected.
Another way to specify these access keys is to put them in a separate file.
Buildbot supports the standard AWS credentials file.
You can then make the access privileges stricter for this separate file, and potentially let more people read your main configuration file.
If your master is running in EC2, you can also use IAM roles for EC2 to delegate permissions.
keypair_name and security_name allow you to specify different names for these AWS EC2 values.
You can make an .aws directory in the home folder of the user running the buildbot master.
In that directory, create a file called credentials.
The format of the file should be as follows, replacing identifier and secret_identifier with the credentials obtained before.
[default]
aws_access_key_id = identifier
aws_secret_access_key = secret_identifier
If you are using IAM roles, no config file is required. Then you can instantiate the worker as follows.
from buildbot.plugins import worker
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
ami='ami-12345',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
)
]
Previous examples used a particular AMI. If the Buildbot master will be deployed in a process-controlled environment, it may be convenient to specify the AMI more flexibly. Rather than specifying an individual AMI, specify one or two AMI filters.
In all cases, the AMI that sorts last by its location (the S3 bucket and manifest name) will be preferred.
One available filter is to specify the acceptable AMI owners, by AWS account number (the 12 digit number, usually rendered in AWS with hyphens like “1234-5678-9012”, should be entered as in integer).
from buildbot.plugins import worker
bot1 = worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
valid_ami_owners=[11111111111,
22222222222],
identifier='publickey',
secret_identifier='privatekey',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
)
The other available filter is to provide a regular expression string that will be matched against each AMI’s location (the S3 bucket and manifest name).
from buildbot.plugins import worker
bot1 = worker.EC2LatentWorker(
'bot1', 'sekrit', 'm1.large',
valid_ami_location_regex=r'buildbot\-.*/image.manifest.xml',
identifier='publickey',
secret_identifier='privatekey',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
)
The regular expression can specify a group, which will be preferred for the sorting. Only the first group is used; subsequent groups are ignored.
from buildbot.plugins import worker
bot1 = worker.EC2LatentWorker(
'bot1', 'sekrit', 'm1.large',
valid_ami_location_regex=r'buildbot\-.*\-(.*)/image.manifest.xml',
identifier='publickey',
secret_identifier='privatekey',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
)
If the group can be cast to an integer, it will be. This allows 10 to sort after 1, for instance.
from buildbot.plugins import worker
bot1 = worker.EC2LatentWorker(
'bot1', 'sekrit', 'm1.large',
valid_ami_location_regex=r'buildbot\-.*\-(\d+)/image.manifest.xml',
identifier='publickey',
secret_identifier='privatekey',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
)
In addition to using the password as a handshake between the master and the worker, you may want to use a firewall to assert that only machines from a specific IP can connect as workers.
This is possible with AWS EC2 by using the Elastic IP feature.
To configure, generate a Elastic IP in AWS, and then specify it in your configuration using the elastic_ip argument.
from buildbot.plugins import worker
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
'ami-12345',
identifier='publickey',
secret_identifier='privatekey',
elastic_ip='208.77.188.166',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
)
]
One other way to configure a worker is by settings AWS tags.
They can for example be used to have a more restrictive security IAM policy.
To get Buildbot to tag the latent worker specify the tag keys and values in your configuration using the tags argument.
from buildbot.plugins import worker
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
'ami-12345',
identifier='publickey',
secret_identifier='privatekey',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
tags={'SomeTag': 'foo'})
]
If the worker needs access to additional AWS resources, you can also enable your workers to access them via an EC2 instance profile. To use this capability, you must first create an instance profile separately in AWS. Then specify its name on EC2LatentWorker via instance_profile_name.
from buildbot.plugins import worker
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
ami='ami-12345',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
instance_profile_name='my_profile'
)
]
You may also supply your own boto3.Session object to allow for more flexible session options (ex. cross-account)
To use this capability, you must first create a boto3.Session object.
Then provide it to EC2LatentWorker via session argument.
import boto3
from buildbot.plugins import worker
session = boto3.session.Session()
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
ami='ami-12345',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
session=session
)
]
The EC2LatentWorker supports all other configuration from the standard Worker.
The missing_timeout and notify_on_missing specify how long to wait for an EC2 instance to attach before considering the attempt to have failed, and email addresses to alert, respectively.
missing_timeout defaults to 20 minutes.
Volumes
If you want to attach existing volumes to an ec2 latent worker, use the volumes attribute.
This mechanism can be valuable if you want to maintain state on a conceptual worker across multiple start/terminate sequences.
volumes expects a list of (volume_id, mount_point) tuples to attempt attaching when your instance has been created.
If you want to attach new ephemeral volumes, use the block_device_map attribute. This follows the AWS API syntax, essentially acting as a passthrough. The only distinction is that the volumes default to deleting on termination to avoid leaking volume resources when workers are terminated. See boto documentation for further details.
from buildbot.plugins import worker
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
ami='ami-12345',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
block_device_map= [
{
"DeviceName": "/dev/xvdb",
"Ebs" : {
"VolumeType": "io1",
"Iops": 1000,
"VolumeSize": 100
}
}
]
)
]
VPC Support
If you are managing workers within a VPC, your worker configuration must be modified from above. You must specify the id of the subnet where you want your worker placed. You must also specify security groups created within your VPC as opposed to classic EC2 security groups. This can be done by passing the ids of the vpc security groups. Note, when using a VPC, you can not specify classic EC2 security groups (as specified by security_name).
from buildbot.plugins import worker
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
ami='ami-12345',
keypair_name='latent_buildbot_worker',
subnet_id='subnet-12345',
security_group_ids=['sg-12345','sg-67890']
)
]
Spot instances
If you would prefer to use spot instances for running your builds, you can accomplish that by passing in a True value to the spot_instance parameter to the EC2LatentWorker constructor.
Additionally, you may want to specify max_spot_price and price_multiplier in order to limit your builds’ budget consumption.
from buildbot.plugins import worker
c['workers'] = [
worker.EC2LatentWorker('bot1', 'sekrit', 'm1.large',
'ami-12345', region='us-west-2',
identifier='publickey',
secret_identifier='privatekey',
elastic_ip='208.77.188.166',
keypair_name='latent_buildbot_worker',
security_name='latent_buildbot_worker',
placement='b', spot_instance=True,
max_spot_price=0.09,
price_multiplier=1.15,
product_description='Linux/UNIX')
]
This example would attempt to create a m1.large spot instance in the us-west-2b region costing no more than $0.09/hour.
The spot prices for ‘Linux/UNIX’ spot instances in that region over the last 24 hours will be averaged and multiplied by the price_multiplier parameter, then a spot request will be sent to Amazon with the above details.
If the multiple exceeds the max_spot_price, the bid price will be the max_spot_price.
Either max_spot_price or price_multiplier, but not both, may be None.
If price_multiplier is None, then no historical price information is retrieved; the bid price is simply the specified max_spot_price.
If the max_spot_price is None, then the multiple of the historical average spot prices is used as the bid price with no limit.
Libvirt
- class buildbot.worker.libvirt.LibVirtWorker
libvirt is a virtualization API for interacting with the virtualization capabilities of recent versions of Linux and other OSes. It is LGPL and comes with a stable C API, and Python bindings.
This means we now have an API which when tied to buildbot allows us to have workers that run under Xen, QEMU, KVM, LXC, OpenVZ, User Mode Linux, VirtualBox and VMWare.
The libvirt code in Buildbot was developed against libvirt 0.7.5 on Ubuntu Lucid. It is used with KVM to test Python code on VMs, but obviously isn’t limited to that. Each build is run on a new VM, images are temporary and thrown away after each build.
This document will guide you through setup of a libvirt latent worker:
Setting up libvirt
We won’t show you how to set up libvirt as it is quite different on each platform, but there are a few things you should keep in mind.
If you are using the system libvirt (libvirt and buildbot master are on same server), your buildbot master user will need to be in the libvirtd group.
If libvirt and buildbot master are on different servers, the user connecting to libvirt over ssh will need to be in the libvirtd group. Also need to setup authorization via ssh-keys (without password prompt).
If you are using KVM, your buildbot master user will need to be in the KVM group.
You need to think carefully about your virtual network first. Will NAT be enough? What IP will my VMs need to connect to for connecting to the master?
Configuring your base image
You need to create a base image for your builds that has everything needed to build your software. You need to configure the base image with a buildbot worker that is configured to connect to the master on boot.
Because this image may need updating a lot, we strongly suggest scripting its creation.
If you want to have multiple workers using the same base image it can be annoying to duplicate the image just to change the buildbot credentials. One option is to use libvirt’s DHCP server to allocate an identity to the worker: DHCP sets a hostname, and the worker takes its identity from that.
Doing all this is really beyond the scope of the manual, but there is a vmbuilder script and a network.xml file to create such a DHCP server in master/contrib/ (Contrib Scripts) that should get you started:
sudo apt-get install ubuntu-vm-builder
sudo contrib/libvirt/vmbuilder
Should create an ubuntu/ folder with a suitable image in it.
virsh net-define contrib/libvirt/network.xml
virsh net-start buildbot-network
Should set up a KVM compatible libvirt network for your buildbot VM’s to run on.
Configuring your Master
Warning
There is currently a buildbot bug that fails to use the base_image if provided.
This means that the worker always uses the hd_image and changes will persist between builds.
See the GitHub issue for details.
If you want to add a simple on demand VM to your setup, you only need the following.
We set the username to minion1, the password to sekrit.
The base image is called base_image and a copy of it will be made for the duration of the VM’s life.
That copy will be thrown away every time a build is complete.
from buildbot.plugins import worker, util
c['workers'] = [
worker.LibVirtWorker('minion1', 'sekrit',
uri="qemu:///session",
hd_image='/home/buildbot/images/minion1',
base_image='/home/buildbot/images/base_image')
]
You can use virt-manager to define minion1 with the correct hardware.
If you don’t, buildbot won’t be able to find a VM to start.
LibVirtWorker accepts the following arguments:
nameBoth a buildbot username and the name of the virtual machine.
passwordA password for the buildbot to login to the master with.
hd_imageThe path to a libvirt disk image, normally in qcow2 format when using KVM.
base_imageIf given a base image, buildbot will clone it every time it starts a VM. This means you always have a clean environment to do your build in.
uriThe URI of the connection to libvirt.
masterFQDN(optional, defaults to
socket.getfqdn()) Address of the master the worker should connect to. Use if you master machine does not have proper fqdn. This value is passed to the libvirt image via domain metadata.xmlIf a VM isn’t predefined in virt-manager, then you can instead provide XML like that used with
virsh define. The VM will be created automatically when needed, and destroyed when not needed any longer.
Note
The hd_image and base_image must be on same machine with buildbot master.
Connection to master
If xml configuration key is not provided, then Buildbot will set libvirt metadata for the domain.
It will contain the following XML element: <auth username="..." password="..." master="..."/>.
Here username, password and master are the name of the worker, password to use for connection and the FQDN of the master.
The libvirt metadata will be placed in the XML namespace buildbot=http://buildbot.net/.
Configuring Master to use libvirt on remote server
If you want to use libvirt on remote server configure remote libvirt server and buildbot server following way.
Define user to connect to remote machine using ssh. Configure connection of such user to remote libvirt server (see https://wiki.libvirt.org/page/SSHSetup) without password prompt.
Add user to libvirtd group on remote libvirt server
sudo usermod -G libvirtd -a <user>.
Configure remote libvirt server:
Create virtual machine for buildbot and configure it.
Change virtual machine image file to new name, which will be used as temporary image and deleted after virtual machine stops. Execute command
sudo virsh edit <VM name>. In xml file locatedevices/disk/sourceand change file path to new name. The file must not be exists, it will create via hook script.Add hook script to
/etc/libvirt/hooks/qemuto recreate VM image each start:
#!/usr/bin/python
# Script /etc/libvirt/hooks/qemu
# Don't forget to execute service libvirt-bin restart
# Also see https://www.libvirt.org/hooks.html
# This script make clean VM for each start using base image
import os
import subprocess
import sys
images_path = '/var/lib/libvirt/images/'
# build-vm - VM name in virsh list --all
# vm_base_image.qcow2 - base image file name, must exist in path /var/lib/libvirt/images/
# vm_temp_image.qcow2 - temporary image. Must not exist in path /var/lib/libvirt/images/, but
# defined in VM config file
domains = {
'build-vm' : ['vm_base_image.qcow2', 'vm_temp_image.qcow2'],
}
def delete_image_clone(vir_domain):
if vir_domain in domains:
domain = domains[vir_domain]
os.remove(images_path + domain[1])
def create_image_clone(vir_domain):
if vir_domain in domains:
domain = domains[vir_domain]
cmd = ['/usr/bin/qemu-img', 'create', '-b', images_path + domain[0],
'-f', 'qcow2', '-F', 'qcow2', images_path + domain[1]]
subprocess.call(cmd)
if __name__ == "__main__":
vir_domain, action = sys.argv[1:3]
if action in ["prepare"]:
create_image_clone(vir_domain)
if action in ["release"]:
delete_image_clone(vir_domain)
Configure buildbot server:
On buildbot server in virtual environment install libvirt-python package:
pip install libvirt-pythonCreate worker using remote ssh connection.
from buildbot.plugins import worker, util
c['workers'] = [
worker.LibVirtWorker(
'minion1', 'sekrit',
util.Connection("qemu+ssh://<user>@<ip address or DNS name>:<port>/session"),
'/home/buildbot/images/minion1')
]
OpenStack
- class buildbot.worker.openstack.OpenStackLatentWorker
OpenStack is a series of interconnected components that facilitates managing compute, storage, and network resources in a data center. It is available under the Apache License and has a REST interface along with a Python client.
This document will guide you through setup of an OpenStack latent worker:
Install dependencies
OpenStackLatentWorker requires python-novaclient to work, you can install it with pip install python-novaclient.
Get an Account in an OpenStack cloud
Setting up OpenStack is outside the domain of this document. There are four account details necessary for the Buildbot master to interact with your OpenStack cloud: username, password, a tenant name, and the auth URL to use.
Create an Image
OpenStack supports a large number of image formats. OpenStack maintains a short list of prebuilt images; if the desired image is not listed, The OpenStack Compute Administration Manual is a good resource for creating new images. You need to configure the image with a buildbot worker to connect to the master on boot.
Configure the Master with an OpenStackLatentWorker
With the configured image in hand, it is time to configure the buildbot master to create OpenStack instances of it. You will need the aforementioned account details. These are the same details set in either environment variables or passed as options to an OpenStack client.
OpenStackLatentWorker accepts the following arguments:
nameThe worker name.
passwordA password for the worker to login to the master with.
flavorA string containing the flavor name or UUID to use for the instance.
imageA string containing the image name or UUID to use for the instance.
os_username
os_password
os_tenant_name
os_user_domain
os_project_domain
os_auth_urlThe OpenStack authentication needed to create and delete instances. These are the same as the environment variables with uppercase names of the arguments.
os_auth_argsArguments passed directly to keystone. If this is specified, other authentication parameters (see above) are ignored. You can use
auth_typeto specify auth plugin to load. See OpenStack documentation <https://docs.openstack.org/python-keystoneclient/> for more information. Usually this should containauth_url,username,password,project_domain_nameanduser_domain_name.block_devicesA list of dictionaries. Each dictionary specifies a block device to set up during instance creation. The values support using properties from the build and will be rendered when the instance is started.
Supported keys
uuid(required): The image, snapshot, or volume UUID.
volume_size(optional): Size of the block device in GiB. If not specified, the minimum size in GiB to contain the source will be calculated and used.
device_name(optional): defaults to
vda. The name of the device in the instance; e.g. vda or xda.source_type(optional): defaults to
image. The origin of the block device. Valid values areimage,snapshot, orvolume.destination_type(optional): defaults to
volume. Destination of block device:volumeorlocal.delete_on_termination(optional): defaults to
True. Controls if the block device will be deleted when the instance terminates.boot_index(optional): defaults to
0. Integer used for boot order.
metaA dictionary of string key-value pairs to pass to the instance. These will be available under the
metadatakey from the metadata service.nova_args(optional) A dict that will be appended to the arguments when creating a VM. Buildbot uses the OpenStack Nova version 2 API by default (see client_version).
client_version(optional) A string containing the Nova client version to use. Defaults to
2. Supports using2.X, where X is a micro-version. Use1.1for the previous, deprecated, version. If using1.1, note that an older version of novaclient will be needed so it won’t switch to using2.region(optional) A string specifying region where to instantiate the worker.
Here is the simplest example of configuring an OpenStack latent worker.
from buildbot.plugins import worker
c['workers'] = [
worker.OpenStackLatentWorker('bot2', 'sekrit',
flavor=1, image='8ac9d4a4-5e03-48b0-acde-77a0345a9ab1',
os_username='user', os_password='password',
os_tenant_name='tenant',
os_auth_url='http://127.0.0.1:35357/v2.0')
]
The image argument also supports being given a callable.
The callable will be passed the list of available images and must return the image to use.
The invocation happens in a separate thread to prevent blocking the build master when interacting with OpenStack.
from buildbot.plugins import worker
def find_image(images):
# Sort oldest to newest.
def key_fn(x):
return x.created
candidate_images = sorted(images, key=key_fn)
# Return the oldest candidate image.
return candidate_images[0]
c['workers'] = [
worker.OpenStackLatentWorker('bot2', 'sekrit',
flavor=1, image=find_image,
os_username='user', os_password='password',
os_tenant_name='tenant',
os_auth_url='http://127.0.0.1:35357/v2.0')
]
The block_devices argument is minimally manipulated to provide some defaults and passed directly to novaclient.
The simplest example is an image that is converted to a volume and the instance boots from that volume.
When the instance is destroyed, the volume will be terminated as well.
from buildbot.plugins import worker
c['workers'] = [
worker.OpenStackLatentWorker('bot2', 'sekrit',
flavor=1, image='8ac9d4a4-5e03-48b0-acde-77a0345a9ab1',
os_username='user', os_password='password',
os_tenant_name='tenant',
os_auth_url='http://127.0.0.1:35357/v2.0',
block_devices=[
{'uuid': '3f0b8868-67e7-4a5b-b685-2824709bd486',
'volume_size': 10}])
]
The nova_args can be used to specify additional arguments for the novaclient.
For example network mappings, which is required if your OpenStack tenancy has more than one network, and default cannot be determined.
Please refer to your OpenStack manual whether it wants net-id or net-name.
Other useful parameters are availability_zone, security_groups and config_drive.
Refer to Python bindings to the OpenStack Nova API for more information.
It is found on section Servers, method create.
from buildbot.plugins import worker
c['workers'] = [
worker.OpenStackLatentWorker('bot2', 'sekrit',
flavor=1, image='8ac9d4a4-5e03-48b0-acde-77a0345a9ab1',
os_username='user', os_password='password',
os_tenant_name='tenant',
os_auth_url='http://127.0.0.1:35357/v2.0',
nova_args={
'nics': [
{'net-id':'uid-of-network'}
]})
]
OpenStackLatentWorker supports all other configuration from the standard Worker.
The missing_timeout and notify_on_missing specify how long to wait for an OpenStack instance to attach before considering the attempt to have failed and email addresses to alert, respectively.
missing_timeout defaults to 20 minutes.
Docker latent worker
- class buildbot.worker.docker.DockerLatentWorker
- class buildbot.plugins.worker.DockerLatentWorker
Docker is an open-source project that automates the deployment of applications inside software containers.
The DockerLatentWorker attempts to instantiate a fresh image for each build to assure consistency of the environment between builds.
Each image will be discarded once the worker finished processing the build queue (i.e. becomes idle).
See build_wait_timeout to change this behavior.
This document will guide you through the setup of such workers.
Docker Installation
An easy way to try Docker is through installation of dedicated Virtual machines. Two of them stands out:
Beside, it is always possible to install Docker next to the buildmaster. Beware that in this case, overall performance will depend on how many builds the computer where you have your buildmaster can handle as everything will happen on the same one.
Note
It is not necessary to install Docker in the same environment as your master as we will make use to the Docker API through docker-py. More in master setup.
CoreOS
CoreOS is targeted at building infrastructure and distributed systems.
In order to get the latent worker working with CoreOS, it is necessary to expose the docker socket outside of the Virtual Machine.
If you installed it via Vagrant, it is also necessary to uncomment the following line in your config.rb file:
$expose_docker_tcp=2375
The following command should allow you to confirm that your Docker socket is now available via the network:
docker -H tcp://127.0.0.1:2375 ps
boot2docker
boot2docker is one of the fastest ways to boot to Docker. As it is meant to be used from outside of the Virtual Machine, the socket is already exposed. Please follow the installation instructions on how to find the address of your socket.
Image Creation
Our build master will need the name of an image to perform its builds. Each time a new build will be requested, the same base image will be used again and again, actually discarding the result of the previous build. If you need some persistent storage between builds, you can use Volumes.
Each Docker image has a single purpose. Our worker image will be running a buildbot worker.
Docker uses Dockerfiles to describe the steps necessary to build an image.
The following example will build a minimal worker.
This example is voluntarily simplistic, and should probably not be used in production, see next paragraph.
1FROM debian:stable
2RUN apt-get update && apt-get install -y \
3 python-dev \
4 python-pip
5RUN pip install buildbot-worker
6RUN groupadd -r buildbot && useradd -r -g buildbot buildbot
7RUN mkdir /worker && chown buildbot:buildbot /worker
8# Install your build-dependencies here ...
9USER buildbot
10WORKDIR /worker
11RUN buildbot-worker create-worker . <master-hostname> <workername> <workerpassword>
12ENTRYPOINT ["/usr/local/bin/buildbot-worker"]
13CMD ["start", "--nodaemon"]
On line 11, the hostname for your master instance, as well as the worker name and password is setup. Don’t forget to replace those values with some valid ones for your project.
It is a good practice to set the ENTRYPOINT to the worker executable, and the CMD to ["start", "--nodaemon"].
This way, no parameter will be required when starting the image.
When your Dockerfile is ready, you can build your first image using the following command (replace myworkername with a relevant name for your case):
docker build -t myworkername - < Dockerfile
Reuse same image for different workers
Previous simple example hardcodes the worker name into the dockerfile, which will not work if you want to share your docker image between workers.
You can find in buildbot source code in master/contrib/docker one example configurations:
- pythonnode_worker
a worker with Python and node installed, which demonstrate how to reuse the base worker to create variations of build environments. It is based on the official
buildbot/buildbot-workerimage.
The master setups several environment variables before starting the workers:
BUILDMASTERThe address of the master the worker shall connect to
BUILDMASTER_PORTThe port of the master’s worker ‘pb’ protocol.
WORKERNAMEThe name the worker should use to connect to master
WORKERPASSThe password the worker should use to connect to master
Master Setup
We will rely on docker-py to connect our master with docker. Now is the time to install it in your master environment.
Before adding the worker to your master configuration, it is possible to validate the previous steps by starting the newly created image interactively. To do this, enter the following lines in a Python prompt where docker-py is installed:
>>> import docker
>>> docker_socket = 'tcp://localhost:2375'
>>> client = docker.client.DockerClient(base_url=docker_socket)
>>> worker_image = 'my_project_worker'
>>> container = client.containers.create_container(worker_image)
>>> client.containers.start(container['Id'])
>>> # Optionally examine the logs of the master
>>> client.containers.stop(container['Id'])
>>> client.containers.wait(container['Id'])
0
It is now time to add the new worker to the master configuration under workers.
The following example will add a Docker latent worker for docker running at the following address: tcp://localhost:2375, the worker name will be docker, its password: password, and the base image name will be my_project_worker:
from buildbot.plugins import worker
c['workers'] = [
worker.DockerLatentWorker('docker', 'password',
docker_host='tcp://localhost:2375',
image='my_project_worker')
]
password(mandatory) The worker password part of the Latent Workers API. If the password is
None, then it will be automatically generated from random number, and transmitted to the container via environment variable.
In addition to the arguments available for any Latent Workers, DockerLatentWorker will accept the following extra ones:
docker_host(renderable string, mandatory) This is the address the master will use to connect with a running Docker instance.
image(renderable string, mandatory) This is the name of the image that will be started by the build master. It should start a worker. This option can be a renderable, like Interpolate, so that it generates from the build request properties.
command(optional) This will override the command setup during image creation.
volumes(a renderable list of strings, optional) Allows to share directory between containers, or between a container and the host system. Refer to Docker documentation for more information about Volumes.
Each string within the
volumesarray specify a volume in the following format:volumename:bindname. The volume name has to be appended with:roif the volume should be mounted read-only.Note
This is the same format as when specifying volumes on the command line for docker’s own
-voption.dockerfile(renderable string, optional if
imageis given) This is the content of the Dockerfile that will be used to build the specified image if the image is not found by Docker. It should be a multiline string.Note
In case
imageanddockerfileare given, no attempt is made to compare the image with the content of the Dockerfile parameter if the image is found.version(optional, default to the highest version known by docker-py) This will indicates which API version must be used to communicate with Docker.
tls(optional) This allow to use TLS when connecting with the Docker socket. This should be a
docker.tls.TLSConfigobject. See docker-py’s own documentation for more details on how to initialise this object.followStartupLogs(optional, defaults to false) This transfers docker container’s log inside master logs during worker startup (before connection). This can be useful to debug worker startup. e.g network issues, etc.
masterFQDN(optional, defaults to socket.getfqdn()) Address of the master the worker should connect to. Use if you master machine does not have proper fqdn. This value is passed to the docker image via environment variable
BUILDMASTERmaster_protocol(optional, default to
pb) Protocol that the worker should use when connecting to master. Supported values arepbandmsgpack_experimental_v7.hostconfig(renderable dictionary, optional) Extra host configuration parameters passed as a dictionary used to create HostConfig object. See docker-py’s HostConfig documentation for all the supported options.
autopull(optional, defaults to false) Automatically pulls image if requested image is not on docker host.
alwaysPull(optional, defaults to false) Always pulls (update) image if autopull is set to true. Also affects the base image specified by FROM …. if using a dockerfile, autopull is not needed then.
target(renderable string, optional) Sets target build stage for multi-stage builds when using a dockerfile.
custom_context- (renderable boolean, optional)
Boolean indicating that the user wants to use custom build arguments for the docker environment. Defaults to False.
encoding- (renderable string, optional)
String indicating the compression format for the build context. defaults to ‘gzip’, but ‘bzip’ can be used as well.
buildargs- (renderable dictionary, optional if
custom_contextis True) Dictionary, passes information for the docker to build its environment. Eg. {‘DISTRO’:’ubuntu’, ‘RELEASE’:’11.11’}. Defaults to None.
- (renderable dictionary, optional if
hostname(renderable string, optional) This will set container’s hostname.
Marathon latent worker
Marathon Marathon is a production-grade container orchestration platform for Mesosphere’s Data-center Operating System (DC/OS) and Apache Mesos.
Buildbot supports using Marathon to host your latent workers.
- class buildbot.worker.marathon.MarathonLatentWorker
- class buildbot.plugins.worker.MarathonLatentWorker
The MarathonLatentWorker attempts to instantiate a fresh image for each build to assure consistency of the environment between builds.
Each image will be discarded once the worker finished processing the build queue (i.e. becomes idle).
See build_wait_timeout to change this behavior.
In addition to the arguments available for any Latent Workers, MarathonLatentWorker will accept the following extra ones:
marathon_url(mandatory) This is the URL to Marathon server. Its REST API will be used to start docker containers.
marathon_auth(optional) This is the optional
('userid', 'password')BasicAuthcredential. If txrequests is installed, this can be a requests authentication plugin.image(mandatory) This is the name of the image that will be started by the build master. It should start a worker. This option can be a renderable, like Interpolate, so that it generates from the build request properties. Images are by pulled from the default docker registry. MarathonLatentWorker does not support starting a worker built from a Dockerfile.
masterFQDN(optional, defaults to socket.getfqdn()) Address of the master the worker should connect to. Use if you master machine does not have proper fqdn. This value is passed to the docker image via environment variable
BUILDMASTERIf the value contains a colon (
:), then BUILDMASTER and BUILDMASTER_PORT environment variables will be passed, following scheme:masterFQDN="$BUILDMASTER:$BUILDMASTER_PORT"marathon_extra_config(optional, defaults to
{}`) Extra configuration to be passed to Marathon API. This implementation will setup the minimal configuration to run a worker (docker image,BRIDGEDnetwork) It will let the default for everything else, including memory size, volume mounting, etc. This configuration is voluntarily very raw so that it is easy to use new marathon features. This dictionary will be merged into the Buildbot generated config, and recursively override it. See Marathon API documentation to learn what to include in this config.
Kubernetes latent worker
Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.
Buildbot supports using Kubernetes to host your latent workers.
- class buildbot.worker.kubernetes.KubeLatentWorker
- class buildbot.plugins.worker.KubeLatentWorker
The KubeLatentWorker attempts to instantiate a fresh container for each build to assure consistency of the environment between builds
Each container will be discarded once the worker finished processing the build queue (i.e. becomes idle).
See build_wait_timeout to change this behavior.
In addition to the arguments available for any Latent Workers, KubeLatentWorker will accept the following extra ones:
image(optional, default to
buildbot/buildbot-worker) Docker image. Default to the official buildbot image.namespace(optional) This is the name of the namespace. Default to the current namespace
kube_config(mandatory) This is the object specifying how to connect to the kubernetes cluster. This object must be an instance of abstract class
KubeConfigLoaderBase, which have 3 implementations:KubeHardcodedConfigKubeCtlProxyConfigLoaderKubeInClusterConfigLoader
masterFQDN(optional, default to
None) Address of the master the worker should connect to. Put the service master service name if you want to place a load-balancer between the workers and the masters. The default behaviour is to compute address IP of the master. This option works out-of-the box inside kubernetes but don’t leverage the load-balancing through service. You can pass any callable, such asKubeLatentWorker.get_fqdnthat will setmasterFQDN=socket.getfqdn().master_protocol(optional, default to
pb) Protocol that the worker should use when connecting to master. Supported values arepbandmsgpack_experimental_v7.
For more customization, you can subclass KubeLatentWorker and override following methods.
All those methods can optionally return a deferred.
All those methods take props object which is a L{IProperties} allowing to get some parameters from the build properties
- createEnvironment(self, props)
This method compute the environment from your properties. Don’t forget to first call super().createEnvironment(props) to get the base properties necessary to connect to the master.
- getBuildContainerResources(self, props)
This method compute the pod resources part of the container spec (spec.containers[].resources). This is important to reserve some CPU and memory for your builds, and to trigger node auto-scaling if needed. You can also limit the CPU and memory for your container.
Example:
def getBuildContainerResources(self, props): return { "requests": { "cpu": "2500m", "memory": "4G", } }
- get_build_container_volume_mounts(self, props)
This method computes the volumeMounts part of the container spec.
Example:
def get_build_container_volume_mounts(self, props): return [ { "name": "mount-name", "mountPath": "/cache", } ]
- get_volumes(self, props)
This method computes the volumes part of the pod spec.
Example:
def get_volumes(self, props): return [ { "name": "mount-name", "hostPath": { "path": "/var/log/pods", } } ]
- get_node_selector(self, props)
This method computes the nodeSelector part of the pod spec.
Example:
def get_node_selector(self, props): return { "my-label": "my-label-value" }
- get_affinity(self, props)
This method computes the affinity part of the pod spec.
Example:
def get_affinity(self, props): return { "nodeAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": { "nodeSelectorTerms": [ "matchExpressions": [ { "key": "topology.kubernetes.io/zone", "operator": "In", "values": [ "antarctica-east1" ] } ] ] } } }
- getServicesContainers(self, props)
This method compute a list of containers spec to put alongside the worker container. This is useful for starting services around your build pod, like a database container. All containers within the same pod share the same localhost interface, so you can access the other containers TCP ports very easily.
Kubernetes config loaders
Kubernetes provides many options to connect to a cluster. It is especially more complicated as some cloud providers use specific methods to connect to their managed kubernetes. Config loaders objects can be shared between LatentWorker.
There are three options you may use to connect to your clusters.
When running both the master and slaves run on the same Kubernetes cluster, you should use the KubeInClusterConfigLoader.
If not, but having a configured kubectl tool available to the build master is an option for you, you should use KubeCtlProxyConfigLoader.
If neither of these options is convenient, use KubeHardcodedConfig.
- class buildbot.util.kubeclientservice.KubeCtlProxyConfigLoader
- class buildbot.plugins.util.KubeCtlProxyConfigLoader
KubeCtlProxyConfigLoader
With KubeCtlProxyConfigLoader, buildbot will user kubectl proxy to get access to the cluster.
This delegates the authentication to the kubectl golang binary, and thus avoid to implement a python version for every authentication scheme that kubernetes provides.
kubectl must be available in the PATH, and configured to be able to start pods.
While this method is very convenient and easy, it also opens an unauthenticated http access to your cluster via localhost.
You must ensure that this is properly secured, and your buildbot master machine is not on a shared multi-user server.
proxy_port(optional defaults to 8001) HTTP port to use.
namespace(optional defaults to
"default"default namespace to use if the latent worker do not provide one already.
- class buildbot.util.kubeclientservice.KubeHardcodedConfig
- class buildbot.plugins.util.KubeHardcodedConfig
KubeHardcodedConfig
With KubeHardcodedConfig, you just configure the necessary parameters to connect to the clusters.
master_url(mandatory) The http url of you kubernetes master. Only http and https protocols are supported
headers(optional) Additional headers to be passed to the HTTP request
basicAuth(optional) Basic authorization info to connect to the cluster, as a {‘user’: ‘username’, ‘password’: ‘psw’ } dict.
Unlike the headers argument, this argument supports secret providers, e.g:
basicAuth={'user': 'username', 'password': Secret('k8spassword')}
bearerToken(optional)
A bearer token to authenticate to the cluster, as a string. Unlike the headers argument, this argument supports secret providers, e.g:
bearerToken=Secret('k8s-token')
When using the Google Kubernetes Engine (GKE), a bearer token for the default service account can be had with:
gcloud container clusters get-credentials --region [YOURREGION] YOURCLUSTER kubectl describe sa kubectl describe secret [SECRET_ID]
Where SECRET_ID is displayed by the
describe sacommand line. The default service account does not have rights on the cluster (to create/delete pods), which is required by BuildBot’s integration. You may give it this right by making it a cluster admin withkubectl create clusterrolebinding service-account-admin \ --clusterrole=cluster-admin \ --serviceaccount default:default
cert(optional) Client certificate and key to use to authenticate. This only works if
txrequestsis installed:cert=('/path/to/certificate.crt', '/path/to/certificate.key')
verify(optional) Path to server certificate authenticate the server:
verify='/path/to/kube_server_certificate.crt'
When using the Google Kubernetes Engine (GKE), this certificate is available from the admin console, on the Cluster page. Verify that it is valid (i.e. no copy/paste errors) with
openssl verify PATH_TO_PEM.namespace(optional defaults to
"default"default namespace to use if the latent worker do not provide one already.
- class buildbot.util.kubeclientservice.KubeInClusterConfigLoader
- class buildbot.plugins.util.KubeInClusterConfigLoader
KubeInClusterConfigLoader
Use KubeInClusterConfigLoader, if your Buildbot master is itself located within the kubernetes cluster.
In this case, you would associated a service account to the Buildbot master pod, and KubeInClusterConfigLoader will get the credentials from that.
This config loader takes no arguments.
UpCloud
- class buildbot.worker.upcloud.UpcloudLatentWorker
UpCloud is a web service that allows you to start virtual machines in cloud. Please see their website for details, including costs.
This document will guide you through setup of a UpCloud latent worker:
Get an UpCloud Account
To start off, to use the UpCloud latent worker, you need to sign up on UpCloud.
Go to https://www.upcloud.com/ and create an account.
Once you are logged into your account, create a sub-account for buildbot to use. You need to tick the box enabling it for API usage. You should disable the box enabling web interface. You should not use your primary account for safety and security reasons.
Configure the Master with an UpcloudLatentWorker
Quick-start sample
from buildbot.plugins import worker
c['workers'].append(upcloud.UpcloudLatentWorker('upcloud-worker','pass',
image='Debian GNU/Linux 9.3 (Stretch)',
api_username="username",
api_password="password",
hostconfig = {
"user_data":"""
/usr/bin/apt-get update
/usr/bin/apt-get install -y buildbot-slave
/usr/bin/buildslave create-slave --umask=022 /buildslave buildbot.example.com upcloud-01 slavepass
/usr/bin/buildslave start /buildslave
"""}))
Complete example with default values
from buildbot.plugins import worker
c['workers'].append(upcloud.UpcloudLatentWorker('upcloud-worker','pass',
image='Debian GNU/Linux 9.3 (Stretch)',
api_username="username",
api_password="password",
hostconfig = {
"zone":"de-fra1",
"plan":"1xCPU-1GB",
"hostname":"hostname",
"ssh_keys":["ssh-rsa ...."],
"os_disk_size":10,
"core_number":1,
"memory_amount":512,
"user_data":""
}))
The image argument specifies the name of image in the image library.
UUID is not currently supported.
The api_username and api_password are for the sub-account you created on UpCloud.
hostconfigcan be used to set various aspects about the created host.zoneis a valid execution zone in UpCloud environment, check their API documentation <https://developers.upcloud.com/> for valid values.planis a valid pre-configured machine specification, or custom if you want to define your own. See their API documentation for valid valuesuser_datafield is used to specify startup script to run on the host.hostnamespecifies the hostname for the worker. Defaults to name of the worker.ssh_keysspecifies ssh key(s) to add for root account. Some images support only one SSH key. At the time of writing, only RSA keys are supported.os_disk_sizespecifies size of the system disk.core_numbercan be used to specify number of cores, when plan is custom.memory_amountcan be used to specify memory in megabytes, when plan is custom.user_datacan be used to specify either URL to script, or script to execute when machine is started.
Note that by default buildbot retains latent workers for 10 minutes, see build_wait_time on how to change this.
Dangers with Latent Workers
Any latent worker that interacts with a for-fee service, such as the
EC2LatentWorker, brings significant risks. As already identified, the
configuration will need access to account information that, if obtained by a criminal, can be used
to charge services to your account. Also, bugs in the Buildbot software may lead to unnecessary
charges. In particular, if the master neglects to shut down an instance for some reason, a virtual
machine may be running unnecessarily, charging against your account. Manual and/or automatic (e.g.
Nagios with a plugin using a library like boto) double-checking may be appropriate.
A comparatively trivial note is that currently if two instances try to attach to the same latent worker, it is likely that the system will become confused. This should not occur, unless, for instance, you configure a normal worker to connect with the authentication of a latent buildbot. If this situation does occurs, stop all attached instances and restart the master.
2.5.7. Builder Configuration
The builders configuration key is a list of objects holding the configuration of the Builders.
For more information on the Builders’ function in Buildbot, see the Concepts chapter.
The class definition for the builder configuration is in buildbot.config.
However, there is a simpler way to use it and it looks like this:
from buildbot.plugins import util
c['builders'] = [
util.BuilderConfig(name='quick', workernames=['bot1', 'bot2'], factory=f_quick),
util.BuilderConfig(name='thorough', workername='bot1', factory=f_thorough),
]
BuilderConfig takes the following keyword arguments:
nameThe name of the Builder, which is used in status reports.
workernameworkernamesThese arguments specify the worker or workers that will be used by this Builder. All worker names must appear in the
workersconfiguration parameter. Each worker can accommodate multiple builders. Theworkernamesparameter can be a list of names, whileworkernamecan specify only one worker.factoryThis is a
buildbot.process.factory.BuildFactoryinstance which controls how the build is performed by defining the steps in the build. Full details appear in their own section, Build Factories.
Other optional keys may be set on each BuilderConfig:
builddir(string, optional).
Specifies the name of a subdirectory of the master’s basedir in which everything related to this builder will be stored. This holds build status information. If not set, this parameter defaults to the builder name, with some characters escaped. Each builder must have a unique build directory.
workerbuilddir(string, optional).
Specifies the name of a subdirectory (under the worker’s configured base directory) in which everything related to this builder will be placed on the worker. This is where checkouts, compilations, and tests are run. If not set, defaults to
builddir. If a worker is connected to multiple builders that share the sameworkerbuilddir, make sure the worker is set to run one build at a time or ensure this is fine to run multiple builds from the same directory simultaneously.tags(list of strings, optional).
Identifies tags for the builder. A common use for this is to add new builders to your setup (for a new module or a new worker) that do not work correctly yet and allow you to integrate them with the active builders. You can tag these new builders with a
testtag, make your main status clients ignore them, and have only private status clients pick them up. As soon as they work, you can move them over to the active tag.project(string, optional).
If provided, the builder will be associated with the specific project.
nextWorker(function, optional).
If provided, this is a function that controls which worker will be assigned future jobs. The function is passed three arguments, the
Builderobject which is assigning a new job, a list ofWorkerForBuilderobjects and theBuildRequest. The function should return one of theWorkerForBuilderobjects, orNoneif none of the available workers should be used. As an example, for eachworkerin the list,worker.workerwill be aWorkerobject, andworker.worker.workernameis the worker’s name. The function can optionally return a Deferred, which should fire with the same results.To control worker selection globally for all builders, use
select_next_worker.nextBuild(function, optional).
If provided, this is a function that controls which build request will be handled next. The function is passed two arguments, the
Builderobject which is assigning a new job, and a list ofBuildRequestobjects of pending builds. The function should return one of theBuildRequestobjects, orNoneif none of the pending builds should be started. This function can optionally return a Deferred which should fire with the same results.canStartBuild(boolean, optional).
If provided, this is a function that can veto whether a particular worker should be used for a given build request. The function is passed three arguments: the
Builder, aWorker, and aBuildRequest. The function should returnTrueif the combination is acceptable, orFalseotherwise. This function can optionally return a Deferred which should fire with the same results.See canStartBuild Functions for a concrete example.
locks(list of instances of
buildbot.locks.WorkerLockorbuildbot.locks.MasterLock, optional).Specifies the locks that should be acquired before starting a
Buildfrom thisBuilder. Alternatively, this could be a renderable that returns this list depending on properties related to the build that is just about to be created. This lets you defer picking the locks to acquire until it is known whichWorkera build would get assigned to. The properties available to the renderable include all properties that are set to the build before its first step excluding the properties that come from the build itself and thebuilddirproperty that comes from worker. TheLockswill be released when the build is complete. Note that this is a list of actualLockinstances, not names. Also note that all Locks must have unique names. See Interlocks.env(dictionary of strings, optional).
A Builder may be given a dictionary of environment variables in this parameter. The variables are used in
ShellCommandsteps in builds created by this builder. The environment variables will override anything in the worker’s environment. Variables passed directly to aShellCommandwill override variables of the same name passed to the Builder.For example, if you have a pool of identical workers it is often easier to manage variables like
PATHfrom Buildbot rather than manually editing them in the workers’ environment.f = factory.BuildFactory f.addStep(ShellCommand( command=['bash', './configure'])) f.addStep(Compile()) c['builders'] = [ BuilderConfig(name='test', factory=f, workernames=['worker1', 'worker2', 'worker3', 'worker4'], env={'PATH': '/opt/local/bin:/opt/app/bin:/usr/local/bin:/usr/bin'}), ]
Unlike most builder configuration arguments, this argument can contain renderables.
collapseRequests(boolean, optional)
Specifies how build requests for this builder should be collapsed. See Collapsing Build Requests, below.
properties(dictionary of strings, optional)
A builder may be given a dictionary of Build Properties specific for this builder in this parameter. Those values can be used later on like other properties. Interpolate.
defaultProperties(dictionary of strings, optional)
Similar to the
propertiesparameter. ButdefaultPropertieswill only be added to Build Properties if they are not already set by another source.description(string, optional).
A builder may be given an arbitrary description, which will show up in the web status on the builder’s page.
description_format(string, optional)
The format of the
descriptionparameter. By default, it isNoneand corresponds to plain text format. Allowed values:None,markdown.do_build_if(function taking a
Buildand returning a bool, optional)Can be set a function, which if it returns False, the whole build will be skipped. This is useful in case one want the build to be displayed in the UI, without incurring worker preparation costs.
2.5.7.1. Collapsing Build Requests
When more than one build request is available for a builder, Buildbot can “collapse” the requests into a single build. This is desirable when build requests arrive more quickly than the available workers can satisfy them, but has the drawback that separate results for each build are not available.
Requests are only candidated for a merge if both requests have exactly the same codebases.
This behavior can be controlled globally, using the collapseRequests parameter, and on a per-Builder basis, using the collapseRequests argument to the Builder configuration.
If collapseRequests is given, it completely overrides the global configuration.
Possible values for both collapseRequests configurations are:
TrueRequests will be collapsed if their sourcestamp are compatible (see below for definition of compatible).
FalseRequests will never be collapsed.
callable(master, builder, req1, req2)Requests will be collapsed if the callable returns true. See Collapse Request Functions for detailed example.
Sourcestamps are compatible if all of the below conditions are met:
Their codebase, branch, project, and repository attributes match exactly
Neither source stamp has a patch (e.g., from a try scheduler)
Either both source stamps are associated with changes, or neither is associated with changes but they have matching revisions.
2.5.7.2. Prioritizing Builds
The BuilderConfig parameter nextBuild can be used to prioritize build requests within a builder.
Note that this is orthogonal to Prioritizing Builders, which controls the order in which builders are called on to start their builds.
The details of writing such a function are in Build Priority Functions.
Such a function can be provided to the BuilderConfig as follows:
def pickNextBuild(builder, requests):
...
c['builders'] = [
BuilderConfig(name='test', factory=f,
nextBuild=pickNextBuild,
workernames=['worker1', 'worker2', 'worker3', 'worker4']),
]
2.5.7.3. Virtual Builders
Dynamic Trigger is a method which allows to trigger the same builder, with different parameters. This method is used by frameworks which store the build config along side the source code like Buildbot_travis. The drawback of this method is that it is difficult to extract statistics for similar builds. The standard dashboards are not working well due to the fact that all the builds are on the same builder.
In order to overcome these drawbacks, Buildbot has the concept of virtual builder.
If a build has the property virtual_builder_name, it will automatically attach to that builder instead of the original builder.
That created virtual builder is not attached to any master and is only used for better sorting in the UI and better statistics.
The original builder and worker configuration is still used for all other build behaviors.
The virtual builder metadata is configured with the following properties:
virtual_builder_name: The name of the virtual builder.virtual_builder_description: The description of the virtual builder.virtual_builder_project: The project of the virtual builder.virtual_builder_tags: The tags for the virtual builder.
You can also use virtual builders with SingleBranchScheduler.
For example if you want to automatically build all branches in your project without having to manually create a new builder each time one is added:
c['schedulers'].append(schedulers.SingleBranchScheduler(
name='myproject-epics',
change_filter=util.ChangeFilter(branch_re='epics/.*'),
builderNames=['myproject-epics'],
properties={
'virtual_builder_name': util.Interpolate("myproject-%(ss::branch)s")
}
))
2.5.8. Projects
The projects configuration key is a list of objects holding the configuration of the Projects.
For more information on the Project function in Buildbot, see the Concepts chapter.
Project takes the following keyword arguments:
nameThe name of the Project. Builders are associated to the Project using this string as their
projectparameter.
The following arguments are optional:
slug(string, optional) A short string that is used to refer to the project in the URLs of the Buildbot web UI.
description(string, optional) A description of the project that appears in the Buildbot web UI.
description_format(string, optional)
The format of the
descriptionparameter. By default, it isNoneand corresponds to plain text format. Allowed values:None,markdown.
2.5.8.1. Example
The following is a demonstration of defining several Projects in the Buildbot configuration
from buildbot.plugins import util
c['projects'] = [
util.Project(name="example",
description="An application to build example widgets"),
util.Project(name="example-utils",
description="Utilities for the example project"),
]
2.5.9. Codebases
The codebases configuration key is a list of objects holding the configuration of Codebases.
For more information on the Codebase function in Buildbot, see the Concepts chapter.
Codebase takes the following keyword arguments:
nameThe name of the Codebase.
The name must be unique across all codebases that are part of the project.
If
nameis changed, then a new codebase is created with respect to historical data stored by Buildbot.projectThe name of the project that codebase is part of.
The following arguments are optional:
slug(string, optional) A short string that identifies the codebase.
Among other things, it may be used to refer to the codebase in the URLs of the Buildbot web UI.
By default
slugis equal toname.
2.5.9.1. Example
The following is a demonstration of defining several Projects in the Buildbot configuration
from buildbot.plugins import util
c['projects'] = [
util.Project(name="example",
description="An application to build example widgets"),
util.Project(name="example-utils",
description="Utilities for the example project"),
]
c['codebases'] = [
util.Codebase(name="main", project='example'),
util.Codebase(name="main", project='example-utils'),
]
2.5.10. Build Factories
Each Builder is equipped with a build factory, which defines the steps used to perform a particular type of build.
This factory is created in the configuration file, and attached to a Builder through the factory element of its dictionary.
The steps used by these builds are defined in the next section, Build Steps.
Note
Build factories are used with builders, and are not added directly to the buildmaster configuration dictionary.
2.5.10.1. Defining a Build Factory
A BuildFactory defines the steps that every build will follow.
Think of it as a glorified script.
For example, a build factory which consists of an SVN checkout followed by a make build would be configured as follows:
from buildbot.plugins import util, steps
f = util.BuildFactory()
f.addStep(steps.SVN(repourl="http://..", mode="incremental"))
f.addStep(steps.Compile(command=["make", "build"]))
This factory would then be attached to one builder (or several, if desired):
c['builders'].append(
BuilderConfig(name='quick', workernames=['bot1', 'bot2'], factory=f))
It is also possible to pass a list of steps into the BuildFactory when it is created.
Using addStep is usually simpler, but there are cases where it is more convenient to create the list of steps ahead of time, perhaps using some Python tricks to generate the steps.
from buildbot.plugins import steps, util
all_steps = [
steps.CVS(cvsroot=CVSROOT, cvsmodule="project", mode="update"),
steps.Compile(command=["make", "build"]),
]
f = util.BuildFactory(all_steps)
Finally, you can also add a sequence of steps all at once:
f.addSteps(all_steps)
Attributes
The following attributes can be set on a build factory after it is created, e.g.,
f = util.BuildFactory()
f.useProgress = False
useProgress(defaults to
True): ifTrue, the buildmaster keeps track of how long each step takes, so it can provide estimates of how long future builds will take. If builds are not expected to take a consistent amount of time (such as incremental builds in which a random set of files are recompiled or tested each time), this should be set toFalseto inhibit progress-tracking.workdir(defaults to ‘build’): workdir given to every build step created by this factory as default. The workdir can be overridden in a build step definition. The workdir can be renderable.
The attribute will be used for constructing the workdir (worker base + builder builddir + workdir).
2.5.10.2. Dynamic Build Factories
In some cases you may not know what commands to run until after you checkout the source tree. For those cases, you can dynamically add steps during a build from other steps.
The Build object provides 2 functions to do this:
addStepsAfterCurrentStep(self, step_factories)This adds the steps after the step that is currently executing.
addStepsAfterLastStep(self, step_factories)This adds the steps onto the end of the build.
Both functions only accept as an argument a list of steps to add to the build.
For example, let’s say you have a script checked in into your source tree called build.sh.
When this script is called with the argument --list-stages it outputs a newline separated list of stage names.
This can be used to generate at runtime a step for each stage in the build.
Each stage is then run in this example using ./build.sh --run-stage <stage name>.
from buildbot.plugins import util, steps
from buildbot.process import buildstep, logobserver
from twisted.internet import defer
class GenerateStagesCommand(buildstep.ShellMixin, steps.BuildStep):
def __init__(self, **kwargs):
kwargs = self.setupShellMixin(kwargs)
super().__init__(**kwargs)
self.observer = logobserver.BufferLogObserver()
self.addLogObserver('stdio', self.observer)
def extract_stages(self, stdout):
stages = []
for line in stdout.split('\n'):
stage = str(line.strip())
if stage:
stages.append(stage)
return stages
@defer.inlineCallbacks
def run(self):
# run './build.sh --list-stages' to generate the list of stages
cmd = yield self.makeRemoteShellCommand()
yield self.runCommand(cmd)
# if the command passes extract the list of stages
result = cmd.results()
if result == util.SUCCESS:
# create a ShellCommand for each stage and add them to the build
self.build.addStepsAfterCurrentStep([
steps.ShellCommand(name=stage, command=["./build.sh", "--run-stage", stage])
for stage in self.extract_stages(self.observer.getStdout())
])
return result
f = util.BuildFactory()
f.addStep(steps.Git(repourl=repourl))
f.addStep(GenerateStagesCommand(
name="Generate build stages",
command=["./build.sh", "--list-stages"],
haltOnFailure=True))
2.5.10.3. Predefined Build Factories
Buildbot includes a few predefined build factories that perform common build sequences. In practice, these are rarely used, as every site has slightly different requirements, but the source for these factories may provide examples for implementation of those requirements.
GNUAutoconf
- class buildbot.process.factory.GNUAutoconf
GNU Autoconf is a software portability tool, intended to make it possible to write programs in C (and other languages) which will run on a variety of UNIX-like systems. Most GNU software is built using autoconf. It is frequently used in combination with GNU automake. These tools both encourage a build process which usually looks like this:
% CONFIG_ENV=foo ./configure --with-flags
% make all
% make check
# make install
(except, of course, from Buildbot, which always skips the make install part).
The Buildbot’s buildbot.process.factory.GNUAutoconf factory is designed to build projects which use GNU autoconf and/or automake.
The configuration environment variables, the configure flags, and command lines used for the compile and test are all configurable, in general the default values will be suitable.
Example:
f = util.GNUAutoconf(source=source.SVN(repourl=URL, mode="copy"),
flags=["--disable-nls"])
Required Arguments:
sourceThis argument must be a step specification tuple that provides a BuildStep to generate the source tree.
Optional Arguments:
configureThe command used to configure the tree. Defaults to ./configure. Accepts either a string or a list of shell argv elements.
configureEnvThe environment used for the initial configuration step. This accepts a dictionary which will be merged into the worker’s normal environment. This is commonly used to provide things like
CFLAGS="-O2 -g"(to turn off debug symbols during the compile). Defaults to an empty dictionary.configureFlagsA list of flags to be appended to the argument list of the configure command. This is commonly used to enable or disable specific features of the autoconf-controlled package, like
["--without-x"]to disable windowing support. Defaults to an empty list.reconfuse autoreconf to generate the ./configure file, set to True to use a buildbot default autoreconf command, or define the command for the ShellCommand.
compilethis is a shell command or list of argv values which is used to actually compile the tree. It defaults to
make all. If set toNone, the compile step is skipped.testthis is a shell command or list of argv values which is used to run the tree’s self-tests. It defaults to
make check. If set to None, the test step is skipped.distcheckthis is a shell command or list of argv values which is used to run the packaging test. It defaults to
make distcheck. If set to None, the test step is skipped.
BasicBuildFactory
- class buildbot.process.factory.BasicBuildFactory
This is a subclass of GNUAutoconf which assumes the source is in CVS, and uses mode='full' and method='clobber' to always build from a clean working copy.
QuickBuildFactory
- class buildbot.process.factory.QuickBuildFactory
The QuickBuildFactory class is a subclass of GNUAutoconf which assumes the source is in CVS, and uses mode='incremental' to get incremental updates.
The difference between a full build and a quick build is that quick builds are generally done incrementally, starting with the tree where the previous build was performed.
That simply means that the source-checkout step should be given a mode='incremental' flag, to do the source update in-place.
In addition to that, this class sets the useProgress flag to False.
Incremental builds will (or at least the ought to) compile as few files as necessary, so they will take an unpredictable amount of time to run.
Therefore it would be misleading to claim to predict how long the build will take.
This class is probably not of use to new projects.
BasicSVN
- class buildbot.process.factory.BasicSVN
This class is similar to QuickBuildFactory, but uses SVN instead of CVS.
CPAN
- class buildbot.process.factory.CPAN
Most Perl modules available from the CPAN archive use the MakeMaker module to provide configuration, build, and test services.
The standard build routine for these modules looks like:
% perl Makefile.PL
% make
% make test
# make install
(except again Buildbot skips the install step)
Buildbot provides a CPAN factory to compile and test these projects.
Arguments:
source(required): A step specification tuple, like that used by
GNUAutoconf.perlA string which specifies the perl executable to use. Defaults to just perl.
Distutils
Deprecated since version 4.0.
- class buildbot.process.factory.Distutils
Most Python modules use the distutils package to provide configuration and build services.
The standard build process looks like:
% python ./setup.py build
% python ./setup.py install
Unfortunately, although Python provides a standard unit-test framework named unittest, to the best of my knowledge, distutils does not provide a standardized target to run such unit tests.
(Please let me know if I’m wrong, and I will update this factory.)
The Distutils factory provides support for running the build part of this process.
It accepts the same source= parameter as the other build factories.
Arguments:
source(required): A step specification tuple, like that used by
GNUAutoconf.pythonA string which specifies the python executable to use. Defaults to just python.
testProvides a shell command which runs unit tests. This accepts either a string or a list. The default value is
None, which disables the test step (since there is no common default command to run unit tests in distutils modules).
Trial
- class buildbot.process.factory.Trial
Twisted provides a unit test tool named trial which provides a few improvements over Python’s built-in unittest module.
Many Python projects which use Twisted for their networking or application services also use trial for their unit tests.
These modules are usually built and tested with something like the following:
% python ./setup.py build
% PYTHONPATH=build/lib.linux-i686-2.3 trial -v PROJECTNAME.test
% python ./setup.py install
Unfortunately, the build/lib directory into which the built/copied .py files are placed is actually architecture-dependent, and I do not yet know of a simple way to calculate its value.
For many projects it is sufficient to import their libraries in place from the tree’s base directory (PYTHONPATH=.).
In addition, the PROJECTNAME value where the test files are located is project-dependent: it is usually just the project’s top-level library directory, as common practice suggests the unit test files are put in the test sub-module.
This value cannot be guessed, the Trial class must be told where to find the test files.
The Trial class provides support for building and testing projects which use distutils and trial.
If the test module name is specified, trial will be invoked.
The library path used for testing can also be set.
One advantage of trial is that the Buildbot happens to know how to parse trial output, letting it identify which tests passed and which ones failed. The Buildbot can then provide fine-grained reports about how many tests have failed, when individual tests fail when they had been passing previously, etc.
Another feature of trial is that you can give it a series of source .py files, and it will search them for special test-case-name tags that indicate which test cases provide coverage for that file.
Trial can then run just the appropriate tests.
This is useful for quick builds, where you want to only run the test cases that cover the changed functionality.
Arguments:
testpathProvides a directory to add to
PYTHONPATHwhen running the unit tests, if tests are being run. Defaults to.to include the project files in-place. The generated build library is frequently architecture-dependent, but may simply bebuild/libfor pure-Python modules.pythonWhich Python executable to use. This list will form the start of the argv array that will launch trial. If you use this, you should set
trialto an explicit path (like/usr/bin/trialor./bin/trial). The parameter defaults toNone, which leaves it out entirely (runningtrial argsinstead ofpython ./bin/trial args). Likely values are['python'],['python2.2'], or['python', '-Wall'].trialProvides the name of the trial command. It is occasionally useful to use an alternate executable, such as trial2.2 which might run the tests under an older version of Python. Defaults to trial.
trialModeA list of arguments to pass to trial, specifically to set the reporting mode. This defaults to
['--reporter=bwverbose'], which only works for Twisted-2.1.0 and later.trialArgsA list of arguments to pass to trial, available to turn on any extra flags you like. Defaults to
[].testsProvides a module name or names which contain the unit tests for this project. Accepts a string, typically
PROJECTNAME.test, or a list of strings. Defaults toNone, indicating that no tests should be run. You must either set this ortestChanges.testChangesIf
True, ignore thetestsparameter and instead ask the Build for all the files that make up the Changes going into this build. Pass these filenames to trial and ask it to look for test-case-name tags, running just the tests necessary to cover the changes.recurseIf
True, tells Trial (with the--recurseargument) to look in all subdirectories for additional test cases.reactorwhich reactor to use, like ‘gtk’ or ‘java’. If not provided, the Twisted’s usual platform-dependent default is used.
randomlyIf
True, tells Trial (with the--random=0argument) to run the test cases in random order, which sometimes catches subtle inter-test dependency bugs. Defaults toFalse.
The step can also take any of the ShellCommand arguments, e.g., haltOnFailure.
Unless one of tests or testChanges are set, the step will generate an exception.
2.5.11. Build Sets
A BuildSet represents a set of Builds that all compile and/or test the same version of the source tree.
Usually, these builds are created by multiple Builders and will thus execute different steps.
The BuildSet is tracked as a single unit, which fails if any of the component Builds have failed, and therefore can succeed only if all of the component Builds have succeeded.
There are two kinds of status notification messages that can be emitted for a BuildSet: the firstFailure type (which fires as soon as we know the BuildSet will fail), and the Finished type (which fires once the BuildSet has completely finished, regardless of whether the overall set passed or failed).
A BuildSet is created with a set of one or more source stamp tuples of (branch, revision, changes, patch), some of which may be None, and a list of Builders on which it is to be run.
They are then given to the BuildMaster, which is responsible for creating a separate BuildRequest for each Builder.
There are a couple of different likely values for the SourceStamp:
(revision=None, changes=CHANGES, patch=None)This is a
SourceStampused when a series ofChanges have triggered a build. The VC step will attempt to check out a tree that contains CHANGES (and any changes that occurred before CHANGES, but not any that occurred after them.)(revision=None, changes=None, patch=None)This builds the most recent code on the default branch. This is the sort of
SourceStampthat would be used on aBuildthat was triggered by a user request, or aPeriodicscheduler. It is also possible to configure the VC Source Step to always check out the latest sources rather than paying attention to theChanges in theSourceStamp, which will result in the same behavior as this.(branch=BRANCH, revision=None, changes=None, patch=None)This builds the most recent code on the given BRANCH. Again, this is generally triggered by a user request or a
Periodicscheduler.(revision=REV, changes=None, patch=(LEVEL, DIFF, SUBDIR_ROOT))This checks out the tree at the given revision REV, then applies a patch (using
patch -pLEVEL <DIFF) from inside the relative directory SUBDIR_ROOT. Item SUBDIR_ROOT is optional and defaults to the builder working directory. Thetrycommand creates this kind ofSourceStamp. IfpatchisNone, the patching step is bypassed.
The buildmaster is responsible for turning the BuildSet into a set of BuildRequest objects and queueing them on the appropriate Builders.
2.5.12. Properties
Build properties are a generalized way to provide configuration information to build steps; see Build Properties for the conceptual overview of properties.
Some build properties come from external sources and are set before the build begins; others are set during the build and are available for later steps. The sources for properties are:
global configurationThese properties apply to all builds.
- schedulers
A scheduler can specify properties that become available to all builds it starts.
- changes
A change can have properties attached to it, supplying extra information gathered by the change source. This is most commonly used with the
sendchangecommand.- forced builds
The “Force Build” form allows users to specify properties
workersA worker can pass properties on to the builds it performs.
- builds
A build automatically sets a number of properties on itself.
buildersA builder can set properties on all the builds it runs.
- steps
The steps of a build can set properties that are available to subsequent steps. In particular, source steps set the got_revision property.
If the same property is supplied in multiple places, the final appearance takes precedence. For example, a property set in a builder configuration will override the one supplied by the scheduler.
Properties are stored internally in JSON format, so they are limited to basic types of data: numbers, strings, lists, and dictionaries.
2.5.12.1. Common Build Properties
The following build properties are set when the build is started, and are available to all steps.
got_revisionThis property is set when a
Sourcestep checks out the source tree, and provides the revision that was actually obtained from the VC system. In general this should be the same asrevision, except for non-absolute sourcestamps, wheregot_revisionindicates what revision was current when the checkout was performed. This can be used to rebuild the same source code later.Note
For some VC systems (Darcs in particular), the revision is a large string containing newlines, and is not suitable for interpolation into a filename.
For multi-codebase builds (where codebase is not the default ‘’), this property is a dictionary, keyed by codebase.
buildernameThis is a string that indicates which
Builderthe build was a part of. The combination of buildername and buildnumber uniquely identify a build.
builderidThis is a number that indicates which
Builderthe build was a part of.
buildnumberEach build gets a number, scoped to the
Builder(so the first build performed on any givenBuilderwill have a build number of 0). This integer property contains the build’s number.
workernameThis is a string which identifies which worker the build is running on.
schedulerIf the build was started from a scheduler, then this property will contain the name of that scheduler.
builddirThe absolute path of the base working directory on the worker of the current builder.
For single codebase builds, where the codebase is ‘’, the following Source Stamp Attributes
are also available as properties: branch, revision, repository, and project .
2.5.12.2. Source Stamp Attributes
branch
revision
repository
project
codebase
For details of these attributes see Concepts.
changes
This attribute is a list of dictionaries representing the changes that make up this sourcestamp.
2.5.12.3. Using Properties in Steps
For the most part, properties are used to alter the behavior of build steps during a build. This is
done by using renderables (objects implementing the
IRenderable interface) as step parameters. When the step is started,
each such object is rendered using the current values of the build properties, and the resultant
rendering is substituted as the actual value of the step parameter.
Buildbot offers several renderable object types covering common cases. It’s also possible to create custom renderables.
Note
Properties are defined while a build is in progress; their values are not available when the configuration file is parsed. This can sometimes confuse newcomers to Buildbot! In particular, the following is a common error:
if Property('release_train') == 'alpha':
f.addStep(...)
This does not work because the value of the property is not available when the if statement
is executed. However, Python will not detect this as an error - you will just never see the
step added to the factory.
You can use renderables in most step parameters. Please file bugs for any parameters which do not accept renderables.
Property
The simplest renderable is Property, which renders to the value of the property named by
its argument:
from buildbot.plugins import steps, util
f.addStep(steps.ShellCommand(command=['echo', 'buildername:',
util.Property('buildername')]))
You can specify a default value by passing a default keyword argument:
f.addStep(steps.ShellCommand(command=['echo', 'warnings:',
util.Property('warnings', default='none')]))
The default value is used when the property doesn’t exist, or when the value is something Python
regards as False. The defaultWhenFalse argument can be set to False to force Buildbot
to use the default argument only if the parameter is not set:
f.addStep(steps.ShellCommand(command=['echo', 'warnings:',
util.Property('warnings', default='none',
defaultWhenFalse=False)]))
The default value can be a renderable itself, e.g.,
command=util.Property('command', default=util.Property('default-command'))
Interpolate
Property can only be used to replace an entire argument: in the example above, it replaces
an argument to echo. Often, properties need to be interpolated into strings, instead. The tool
for that job is Interpolate.
The more common pattern is to use Python dictionary-style string interpolation by using the
%(prop:<propname>)s syntax. In this form, the property name goes in the parentheses, as above.
A common mistake is to omit the trailing “s”, leading to a rather obscure error from Python
(“ValueError: unsupported format character”).
from buildbot.plugins import steps, util
f.addStep(steps.ShellCommand(
command=['make',
util.Interpolate('REVISION=%(prop:got_revision)s'),
'dist']))
This example will result in a make command with an argument like REVISION=12098.
The syntax of dictionary-style interpolation is a selector, followed by a colon, followed by a selector specific key, optionally followed by a colon and a string indicating how to interpret the value produced by the key.
The following selectors are supported.
propThe key is the name of a property.
srcThe key is a codebase and source stamp attribute, separated by a colon. Note, the syntax is
%(src:<codebase>:<ssattr>)s, which differs from other selectors.kwThe key refers to a keyword argument passed to
Interpolate. Those keyword arguments may be ordinary values or renderables.secretThe key refers to a secret provided by a provider declared in
secretsProviders.workerThe key refers to an info item provided by
workers.
The following ways of interpreting the value are available.
-replacementIf the key exists, substitute its value; otherwise, substitute
replacement.replacementmay be empty (default),%(prop:propname:-)s.~replacementLike
-replacement, but only substitutes the value of the key if it is something Python regards asTrue. Python considersNone, 0, empty lists, and the empty string to be false, so such values will be replaced byreplacement.+replacementIf the key exists, substitute
replacement; otherwise, substitute an empty string.
?|sub_if_exists|sub_if_missing
#?|sub_if_true|sub_if_falseTernary substitution, depending on either the key being present (with
?, similar to+) or beingTrue(with#?, like~). Notice that there is a pipe immediately following the question mark and between the two substitution alternatives. The character that follows the question mark is used as the delimiter between the two alternatives. In the above examples, it is a pipe, but any character other than(can be used.
Note
Although these are similar to shell substitutions, no other substitutions are currently supported.
Example:
from buildbot.plugins import steps, util
f.addStep(steps.ShellCommand(
command=[
'save-build-artifacts-script.sh',
util.Interpolate('-r %(prop:repository)s'),
util.Interpolate('-b %(src::branch)s'),
util.Interpolate('-d %(kw:data)s', data="some extra needed data")
]))
Note
We use %(src::branch)s in most examples, because codebase is empty by default.
Example:
from buildbot.plugins import steps, util
f.addStep(steps.ShellCommand(
command=[
'make',
util.Interpolate('REVISION=%(prop:got_revision:-%(src::revision:-unknown)s)s'),
'dist'
]))
In addition, Interpolate supports using positional string interpolation. Here, %s is used
as a placeholder, and the substitutions (which may be renderables) are given as subsequent
arguments:
f.addStep(steps.ShellCommand(
command=[
'echo',
util.Interpolate('%d warnings and %d errors',
util.Property('warnings'),
util.Property('errors'))
]))
Note
Like Python, you can use either positional interpolation or dictionary-style interpolation,
but not both. Thus you cannot use a string like Interpolate("foo-%(src::revision)s-%s",
"branch").
Renderer
While Interpolate can handle many simple cases, and even some common conditionals, more complex
cases are best handled with Python code. The renderer decorator creates a renderable object
whose rendering is obtained by calling the decorated function when the step to which it’s passed
begins. The function receives an IProperties object, which it can use
to examine the values of any and all properties. For example:
from buildbot.plugins import steps, util
@util.renderer
def makeCommand(props):
command = ['make']
cpus = props.getProperty('CPUs')
if cpus:
command.extend(['-j', str(cpus+1)])
else:
command.extend(['-j', '2'])
command.extend([util.Interpolate('%(prop:MAKETARGET)s')])
return command
f.addStep(steps.ShellCommand(command=makeCommand))
You can think of renderer as saying “call this function when the step starts”.
Note
Since 0.9.3, renderer can itself return IRenderable objects or
containers containing IRenderable.
Optionally, extra arguments may be passed to the rendered function at any time by calling
withArgs on the renderable object. The withArgs method accepts *args and **kwargs
arguments which are stored in a new renderable object which is returned. The original renderable
object is not modified. Multiple withArgs calls may be chained. The passed *args and
**kwargs parameters are rendered and the results are passed to the rendered function at the
time it is itself rendered. For example:
from buildbot.plugins import steps, util
@util.renderer
def makeCommand(props, target):
command = ['make']
cpus = props.getProperty('CPUs')
if cpus:
command.extend(['-j', str(cpus+1)])
else:
command.extend(['-j', '2'])
command.extend([target])
return command
f.addStep(steps.ShellCommand(command=makeCommand.withArgs('mytarget')))
Note
The rendering of the renderable object may happen at unexpected times, so it is best to ensure that the passed extra arguments are not changed.
Note
Config errors with Renderables may not always be caught via checkconfig.
Transform
Transform is an alternative to renderer. While renderer is useful for creating new
renderables, Transform is easier to use when you want to transform or combine the renderings of
preexisting renderables.
Transform takes a function and any number of positional and keyword arguments. The function
must either be a callable object or a renderable producing one. When rendered, a Transform
first replaces all of its arguments that are renderables with their renderings, then calls the
function, passing it the positional and keyword arguments, and returns the result as its own
rendering.
For example, suppose my_path is a path on the worker, and you want to get it relative to the
build directory. You can do it like this:
import os.path
from buildbot.plugins import util
my_path_rel = util.Transform(os.path.relpath, my_path, start=util.Property('builddir'))
This works whether my_path is an ordinary string or a renderable.
my_path_rel will be a renderable in either case, however.
FlattenList
If a nested list should be flattened for some renderables, FlattenList can be used. For example:
from buildbot.plugins import steps, util
f.addStep(steps.ShellCommand(
command=[ 'make' ],
descriptionDone=util.FlattenList([ 'make ', [ 'done' ]])
))
descriptionDone will be set to [ 'make', 'done' ] when the ShellCommand executes.
This is useful when a list-returning property is used in renderables.
Note
ShellCommand automatically flattens nested lists in its command argument, so there is no
need to use FlattenList for it.
WithProperties
Warning
This class is deprecated. It is an older version of Interpolate. It exists for compatibility with older configs.
The simplest use of this class is with positional string interpolation.
Here, %s is used as a placeholder, and property names are given as subsequent arguments:
from buildbot.plugins import steps, util
f.addStep(steps.ShellCommand(
command=["tar", "czf",
util.WithProperties("build-%s-%s.tar.gz", "branch", "revision"),
"source"]))
If this BuildStep were used in a tree obtained from Git, it would create a tarball with a
name like build-master-a7d3a333db708e786edb34b6af646edd8d4d3ad9.tar.gz.
The more common pattern is to use Python dictionary-style string interpolation by using the
%(propname)s syntax. In this form, the property name goes in the parentheses, as above. A
common mistake is to omit the trailing “s”, leading to a rather obscure error from Python
(“ValueError: unsupported format character”).
from buildbot.plugins import steps, util
f.addStep(steps.ShellCommand(
command=['make',
util.WithProperties('REVISION=%(got_revision)s'),
'dist']))
This example will result in a make command with an argument like REVISION=12098.
The dictionary-style interpolation supports a number of more advanced syntaxes in the parentheses.
propname:-replacementIf
propnameexists, substitute its value; otherwise, substitutereplacement.replacementmay be empty (%(propname:-)s)propname:~replacementLike
propname:-replacement, but only substitutes the value of propertypropnameif it is something Python regards asTrue. Python considersNone, 0, empty lists, and the empty string to be false, so such values will be replaced byreplacement.propname:+replacementIf
propnameexists, substitutereplacement; otherwise, substitute an empty string.
Although these are similar to shell substitutions, no other substitutions are currently supported,
and replacement in the above cannot contain more substitutions.
Note: like Python, you can use either positional interpolation or dictionary-style interpolation,
not both. Thus you cannot use a string like WithProperties("foo-%(revision)s-%s", "branch").
Custom Renderables
If the options described above are not sufficient, more complex substitutions can be achieved by writing custom renderables.
The IRenderable interface is simple - objects must provide a
getRenderingFor method. The method should take one argument - an
IProperties provider - and should return the rendered value or a
deferred firing with one. You can pass instances of the class anywhere other renderables are
accepted. For example:
import time
from buildbot.interfaces import IRenderable
from zope.interface import implementer
@implementer(IRenderable)
class DetermineFoo(object):
def getRenderingFor(self, props):
if props.hasProperty('bar'):
return props['bar']
elif props.hasProperty('baz'):
return props['baz']
return 'qux'
ShellCommand(command=['echo', DetermineFoo()])
or, more practically,
from buildbot.interfaces import IRenderable
from zope.interface import implementer
from buildbot.plugins import util
@implementer(IRenderable)
class Now(object):
def getRenderingFor(self, props):
return time.clock()
ShellCommand(command=['make', util.Interpolate('TIME=%(kw:now)s', now=Now())])
This is equivalent to:
from buildbot.plugins import util
@util.renderer
def now(props):
return time.clock()
ShellCommand(command=['make', util.Interpolate('TIME=%(kw:now)s', now=now)])
Note that a custom renderable must be instantiated (and its constructor can take whatever arguments
you like), whereas a function decorated with renderer can be used directly.
URL for build
Its common to need to use the URL for the build in a step. For this, you can use a special custom renderer as following:
from buildbot.plugins import *
ShellCommand(command=['make', util.Interpolate('BUILDURL=%(kw:url)s', url=util.URLForBuild)])
Renderable Comparison
Its common to need to make basic comparison or calculation with properties. The Property
and Interpolate objects contain necessary operator overloads to make this possible.
from buildbot.plugins import *
ShellCommand(command=['make'], doStepIf=Interpolate("worker:os_id") == 'ubuntu')
In previous code, the value of the comparison can only be computed at runtime, so the result of the comparison is actually a renderable which will be computed at the start of the step.
from buildbot.plugins import *
ShellCommand(command=['make'], doStepIf=Interpolate("worker:os_id").in_(['debian', 'ubuntu']))
‘in’ operator cannot be overloaded, so we add a simple in_ method to Property and
Interpolate.
Currently supported operators are in_, ==, !=, <, <=, >, >=, +,
-, *, /, //, %.
2.5.13. Build Steps
2.5.13.1. Parameters Common to all Steps
All BuildSteps accept some common parameters.
Some of these control how their individual status affects the overall build.
Others are used to specify which Locks (see Interlocks) should be acquired before allowing the step to run.
Note that it is not possible to change the configuration of the BuildStep by adjusting its attributes after construction.
Use set_step_arg(name, value) function for that.
Arguments common to all BuildStep subclasses:
nameThe name used to describe the step on the status display. Since 0.9.8, this argument might be renderable.
haltOnFailureIf
True, aFAILUREof this build step will cause the build to halt immediately. Any steps withalwaysRun=Truewill still be run. Generally speaking,haltOnFailureimpliesflunkOnFailure(the default for mostBuildSteps). In some cases, particularly with a series of tests, it makes sense tohaltOnFailureif something fails early on but notflunkOnFailure. This can be achieved withhaltOnFailure=True,flunkOnFailure=False.
flunkOnWarningsWhen
True, aWARNINGSorFAILUREof this build step will mark the overall build asFAILURE. The remaining steps will still be executed.
flunkOnFailureWhen
True, aFAILUREof this build step will mark the overall build as aFAILURE. The remaining steps will still be executed.
warnOnWarningsWhen
True, aWARNINGSorFAILUREof this build step will mark the overall build as havingWARNINGS. The remaining steps will still be executed.
warnOnFailureWhen
True, aFAILUREof this build step will mark the overall build as havingWARNINGS. The remaining steps will still be executed.
alwaysRunIf
True, this build step will always be run, even if a previous buildstep withhaltOnFailure=Truehas failed.
descriptionThis will be used to describe the command (on the Waterfall display) while the command is still running. It should be a single imperfect-tense verb, like compiling or testing. The preferred form is a single, short string, but for historical reasons a list of strings is also acceptable.
descriptionDoneThis will be used to describe the command once it has finished. A simple noun like compile or tests should be used. Like
description, this may either be a string or a list of short strings.If neither
descriptionnordescriptionDoneare set, the actual command arguments will be used to construct the description. This may be a bit too wide to fit comfortably on the Waterfall display.All subclasses of
BuildStepwill contain the description attributes. Consequently, you could add aShellCommandstep like so:from buildbot.plugins import steps f.addStep(steps.ShellCommand(command=["make", "test"], description="testing", descriptionDone="tests"))
descriptionSuffixThis is an optional suffix appended to the end of the description (ie, after
descriptionanddescriptionDone). This can be used to distinguish between build steps that would display the same descriptions in the waterfall. This parameter may be a string, a list of short strings orNone.For example, a builder might use the
Compilestep to build two different codebases. ThedescriptionSuffixcould be set to projectFoo and projectBar, respectively for each step, which will result in the full descriptions compiling projectFoo and compiling projectBar to be shown in the waterfall.
doStepIfA step can be configured to only run under certain conditions. To do this, set the step’s
doStepIfto a boolean value, or to a function that returns a boolean value or Deferred. If the value or function result is false, then the step will returnSKIPPEDwithout doing anything. Otherwise, the step will be executed normally. If you setdoStepIfto a function, that function should accept one parameter, which will be theBuildStepobject itself.
hideStepIfA step can be optionally hidden from the waterfall and build details web pages. To do this, set the step’s
hideStepIfto a boolean value, or a function that takes two parameters (the results and theBuildStep) and returns a boolean value. Steps are always shown while they execute; however, after the step has finished, this parameter is evaluated (if it’s a function), and if the value is true, the step is hidden. For example, in order to hide the step if the step has been skipped:factory.addStep(Foo(..., hideStepIf=lambda results, s: results==SKIPPED))
locksA list of
Locks(instances ofbuildbot.locks.WorkerLockorbuildbot.locks.MasterLock) that should be acquired before starting thisBuildStep. Alternatively, this could be a renderable that returns this list during build execution. This lets you defer picking the locks to acquire until the build step is about to start running. TheLockswill be released when the step is complete. Note that this is a list of actualLockinstances, not names. Also note that all Locks must have unique names. See Interlocks.
logEncodingThe character encoding to use to decode logs produced during the execution of this step. This overrides the default
logEncoding; see Log Handling.
updateBuildSummaryPolicyThe policy to use to propagate the step summary to the build summary. If False, the build summary will never include the step summary. If True, the build summary will always include the step summary. If set to a list (e.g.
[FAILURE, EXCEPTION]), the step summary will be propagated if the step results id is present in that list. If not set or None, the default is computed according to other BuildStep parameters using following algorithm:self.updateBuildSummaryPolicy = [EXCEPTION, RETRY, CANCELLED] if self.flunkOnFailure or self.haltOnFailure or self.warnOnFailure: self.updateBuildSummaryPolicy.append(FAILURE) if self.warnOnWarnings or self.flunkOnWarnings: self.updateBuildSummaryPolicy.append(WARNINGS)
Note that in a custom step, if
BuildStep.getResultSummaryis overridden and sets thebuildsummary,updateBuildSummaryPolicyis ignored and thebuildsummary will be used regardless.
2.5.13.2. Common Parameters of source checkout operations
All source checkout steps accept some common parameters to control how they get the sources and where they should be placed. The remaining per-VC-system parameters are mostly to specify where exactly the sources are coming from.
mode
method
These two parameters specify the means by which the source is checked out.
modespecifies the type of checkout andmethodtells about the way to implement it.from buildbot.plugins import steps factory = BuildFactory() factory.addStep(steps.Mercurial(repourl='path/to/repo', mode='full', method='fresh'))The
modeparameter a string describing the kind of VC operation that is desired (defaults toincremental). The options are:
incrementalUpdate the source to the desired revision, but do not remove any other files generated by previous builds. This allows compilers to take advantage of object files from previous builds. This mode is exactly same as the old
updatemode.fullUpdate the source, but delete remnants of previous builds. Build steps that follow will need to regenerate all object files.
Methods are specific to the VC system in question, as they may take advantage of special behaviors in that VC system that can make checkouts more efficient or reliable.
workdirLike all Steps, this indicates the directory where the build will take place. Source Steps are special in that they perform some operations outside of the workdir (like creating the workdir itself).
alwaysUseLatestIf True, bypass the usual behavior of checking out the revision in the source stamp, and always update to the latest revision in the repository instead. If the specific VC system supports branches and a specific branch is specified in the step parameters via
branchordefaultBranch, then the latest revision on that branch is checked out.retryIf set, this specifies a tuple of
(delay, repeats)which means that when a full VC checkout fails, it should be retried up torepeatstimes, waitingdelayseconds between the attempts. If you don’t provide this, it defaults toNone, which means VC operations should not be retried. This is provided to make life easier for workers which are stuck behind poor network connections.repositoryThe name of this parameter might vary depending on the Source step you are running. The concept explained here is common to all steps and applies to
repourlas well as forbaseURL(when applicable).A common idiom is to pass
Property('repository', 'url://default/repo/path')as repository. This grabs the repository from the source stamp of the build. This can be a security issue, if you allow force builds from the web, or have theWebStatuschange hooks enabled; as the worker will download code from an arbitrary repository.codebaseThis specifies which codebase the source step should use to select the right source stamp. The default codebase value is
''. The codebase must correspond to a codebase assigned by thecodebaseGenerator. If there is no codebaseGenerator defined in the master, then codebase doesn’t need to be set; the default value will match all changes.timeoutSpecifies the timeout for worker-side operations, in seconds. If your repositories are particularly large, then you may need to increase this value from the default of 1200 (20 minutes).
logEnvironIf this option is true (the default), then the step’s logfile will describe the environment variables on the worker. In situations where the environment is not relevant and is long, it may be easier to set
logEnviron=False.envA dictionary of environment strings which will be added to the child command’s environment. The usual property interpolations can be used in environment variable names and values - see Properties.
2.5.13.3. Bzr
- class buildbot.steps.source.bzr.Bzr
bzr is a descendant of Arch/Baz, and is frequently referred to as simply Bazaar. The repository-vs-workspace model is similar to Darcs, but it uses a strictly linear sequence of revisions (one history per branch) like Arch. Branches are put in subdirectories. This makes it look very much like Mercurial.
from buildbot.plugins import steps
factory.addStep(steps.Bzr(mode='incremental',
repourl='lp:~knielsen/maria/tmp-buildbot-test'))
The step takes the following arguments:
repourl(required unless
baseURLis provided): the URL at which the Bzr source repository is available.baseURL(required unless
repourlis provided): the base repository URL, to which a branch name will be appended. It should probably end in a slash.defaultBranch(allowed if and only if
baseURLis provided): this specifies the name of the branch to use when a Build does not provide one of its own. This will be appended tobaseURLto create the string that will be passed to thebzr checkoutcommand. IfalwaysUseLatestisTruethen the branch and revision information that comes with the Build is ignored and branch specified in this parameter is used.
mode
method
No method is needed for incremental mode. For full mode,
methodcan take the values shown below. If no value is given, it defaults tofresh.
clobberThis specifies to remove the
workdirand make a full checkout.freshThis method first runs
bzr clean-treeto remove all the unversioned files thenupdatethe repo. This remove all unversioned files including those in .bzrignore.cleanThis is same as fresh except that it doesn’t remove the files mentioned in
.bzrginorei.e, by runningbzr clean-tree --ignore.copyA local bzr repository is maintained and the repo is copied to
builddirectory for each build. Before each build the local bzr repo is updated then copied tobuildfor next steps.
2.5.13.4. CVS
- class buildbot.steps.source.cvs.CVS
The CVS build step performs a CVS checkout or update.
from buildbot.plugins import steps
factory.addStep(steps.CVS(mode='incremental',
cvsroot=':pserver:me@cvs.example.net:/cvsroot/myproj',
cvsmodule='buildbot'))
This step takes the following arguments:
cvsroot(required): specify the CVSROOT value, which points to a CVS repository, probably on a remote machine. For example, if Buildbot was hosted in CVS then the CVSROOT value you would use to get a copy of the Buildbot source code might be
:pserver:anonymous@cvs.example.net:/cvsroot/buildbot.cvsmodule(required): specify the cvs
module, which is generally a subdirectory of theCVSROOT. The cvsmodule for the Buildbot source code isbuildbot.brancha string which will be used in a
-rargument. This is most useful for specifying a branch to work on. Defaults toHEAD. IfalwaysUseLatestisTruethen the branch and revision information that comes with the Build is ignored and branch specified in this parameter is used.global_optionsa list of flags to be put before the argument
checkoutin the CVS command.extra_optionsa list of flags to be put after the
checkoutin the CVS command.
mode
method
No method is needed for incremental mode. For full mode,
methodcan take the values shown below. If no value is given, it defaults tofresh.
clobberThis specifies to remove the
workdirand make a full checkout.freshThis method first runs
cvsdisardin the build directory, then updates it. This requirescvsdiscardwhich is a part of the cvsutil package.cleanThis method is the same as
method='fresh', but it runscvsdiscard --ignoreinstead ofcvsdiscard.copyThis maintains a
sourcedirectory for source, which it updates copies to the build directory. This allows Buildbot to start with a fresh directory, without downloading the entire repository on every build.
loginPassword to use while performing login to the remote CVS server. Default is
Nonemeaning that no login needs to be performed.
2.5.13.5. Darcs
- class buildbot.steps.source.darcs.Darcs
The Darcs build step performs a Darcs checkout or update.
from buildbot.plugins import steps
factory.addStep(steps.Darcs(repourl='http://path/to/repo',
mode='full', method='clobber', retry=(10, 1)))
Darcs step takes the following arguments:
repourl(required): The URL at which the Darcs source repository is available.
mode
(optional): defaults to
'incremental'. Specifies whether to clean the build tree or not.
incrementalThe source is update, but any built files are left untouched.
fullThe build tree is clean of any built files. The exact method for doing this is controlled by the
methodargument.
method(optional): defaults to
copywhen mode isfull. Darcs’ incremental mode does not require a method. The full mode has two methods defined:clobberIt removes the working directory for each build then makes full checkout.
copyThis first checkout source into source directory then copy the
sourcedirectory tobuilddirectory then performs the build operation in the copied directory. This way we make fresh builds with very less bandwidth to download source. The behavior of source checkout follows exactly same as incremental. It performs all the incremental checkout behavior insourcedirectory.
2.5.13.6. Gerrit
- class buildbot.steps.source.gerrit.Gerrit
Gerrit step is exactly like the Git step, except that it integrates with GerritChangeSource, and will automatically checkout the additional changes.
Gerrit integration can be also triggered using forced build with property named gerrit_change with values in format change_number/patchset_number.
This property will be translated into a branch name.
This feature allows integrators to build with several pending interdependent changes, which at the moment cannot be described properly in Gerrit, and can only be described by humans.
2.5.13.7. GitHub
- class buildbot.steps.source.github.GitHub
GitHub step is exactly like the Git step, except that it will ignore the revision sent by the GitHub change hook, and rather take the branch if the branch ends with /merge.
This allows to test github pull requests merged directly into the mainline.
GitHub indeed provides refs/origin/pull/NNN/merge on top of refs/origin/pull/NNN/head which is a magic ref that always creates a merge commit to the latest version of the mainline (i.e., the target branch for the pull request).
The revision in the GitHub event points to /head, and it’s important for the GitHub reporter as this is the revision that will be tagged with a CI status when the build is finished.
If you want to use Trigger to create sub tests and want to have the GitHub reporter still update the original revision, make sure you set updateSourceStamp=False in the Trigger configuration.
2.5.13.8. GitLab
- class buildbot.steps.source.gitlab.GitLab
GitLab step is exactly like the Git step, except that it uses the source repo and branch sent by the GitLab change hook when processing merge requests.
When configuring builders, you can use a ChangeFilter with category = "push"
to select normal commits, and category = "merge_request" to select merge requests.
See master/docs/examples/gitlab.cfg in the Buildbot distribution
for a tutorial example of integrating Buildbot with GitLab.
Note
Your build worker will need access to the source project of the changeset, or it won’t be able to check out the source. This means authenticating the build worker via ssh credentials in the usual way, then granting it access [via a GitLab deploy key or GitLab project membership](https://docs.gitlab.com/ee/ssh/). This needs to be done not only for the main git repo, but also for each fork that wants to be able to submit merge requests against the main repo.
2.5.13.9. Git
- class buildbot.steps.source.git.Git
The Git build step clones or updates a Git repository and checks out the specified branch or revision.
Note
Buildbot supports Git version 1.2.0 or later.
from buildbot.plugins import steps
factory.addStep(steps.Git(repourl='git://path/to/repo', mode='full',
method='clobber', submodules=True))
The Git step takes the following arguments:
repourl(required)The URL of the upstream Git repository.
port(optional, default:22)The SSH port of the Git server.
branch(optional, default:HEAD)This specifies the name of the branch or the tag to use when a Build does not provide one of its own. If this parameter is not specified, and the Build does not provide a branch, the default branch of the remote repository will be used. If
alwaysUseLatestisTruethen the branch and revision information that comes with the Build is ignored and the branch specified in this parameter is used.submodules(optional, default:False)When initializing/updating a Git repository, this tells Buildbot whether to handle Git submodules. If
remoteSubmodulesisTrue, then this tells Buildbot to use remote submodules: Git Remote Submodulestags(optional, default:False)Download tags in addition to the requested revision when updating repository.
shallow(optional)Instructs Git to attempt shallow clones (
--depth 1). The depth defaults to 1 and can be changed by passing an integer instead ofTrue. This option can be used only in incremental builds, or full builds with clobber method.reference(optional)Use the specified string as a path to a reference repository on the local machine. Git will try to grab objects from this path first instead of the main repository, if they exist.
origin(optional)By default, any clone will use the name “origin” as the remote repository (eg, “origin/master”). This renderable option allows that to be configured to an alternate name.
filters(optional, type:list)For each string in the passed in list, adds a
--filter <filter>argument to git clone. This allows for adding filters like--filter "tree:0"to speed up the clone step. This requires git version 2.27 or higher.progress(optional)Passes the (
--progress) flag to (git fetch). This solves issues of long fetches being killed due to lack of output, but requires Git 1.7.2 or later. Its value is True on Git 1.7.2 or later.retryFetch(optional, default:False)If true, if the
git fetchfails, then Buildbot retries to fetch again instead of failing the entire source checkout.clobberOnFailure(optional, default:False)If a fetch or full clone fails, we can retry to checkout the source by removing everything and cloning the repository. If the retry fails, it fails the source checkout step.
mode(optional, default:'incremental')Specifies whether to clean the build tree or not.
incrementalThe source is update, but any built files are left untouched.
fullThe build tree is clean of any built files. The exact method for doing this is controlled by the
methodargument.
method(optional, default:freshwhen mode isfull)Git’s incremental mode does not require a method. The full mode has four methods defined:
clobberIt removes the build directory entirely then makes full clone from repo. This can be slow as it need to clone whole repository. To make faster clones enable the
shallowoption. If the shallow option is enabled and the build request has unknown revision value, then this step fails.freshThis removes all other files except those tracked by Git. First it does git clean -d -f -f -x, then fetch/checkout to a specified revision (if any). This option is equal to update mode with
ignore_ignores=Truein old steps.cleanAll the files which are tracked by Git, as well as listed ignore files, are not deleted. All other remaining files will be deleted before the fetch/checkout. This is equivalent to git clean -d -f -f then fetch. This is equivalent to
ignore_ignores=Falsein old steps.copyThis first checks out source into source directory, then copies the
sourcedirectory tobuilddirectory, and then performs the build operation in the copied directory. This way, we make fresh builds with very little bandwidth to download source. The behavior of source checkout follows exactly the same as incremental. It performs all the incremental checkout behavior insourcedirectory.
getDescription(optional)After checkout, invoke a git describe on the revision and save the result in a property; the property’s name is either
commit-descriptionorcommit-description-foo, depending on whether thecodebaseargument was also provided. The argument should either be aboolordict, and will change how git describe is called:getDescription=False: disables this feature explicitlygetDescription=Trueor empty{}: runs git describe with no argsgetDescription={...}: a dict with keys named the same as the Git option. Each key’s value can beFalseorNoneto explicitly skip that argument.For the following keys, a value of
Trueappends the same-named Git argument:all: –allalways: –alwayscontains: –containsdebug: –debuglong: –long`exact-match: –exact-matchfirst-parent: –first-parenttags: –tagsdirty: –dirty
For the following keys, an integer or string value (depending on what Git expects) will set the argument’s parameter appropriately. Examples show the key-value pair:
match=foo: –match fooexclude=foo: –exclude fooabbrev=7: –abbrev=7candidates=7: –candidates=7dirty=foo: –dirty=foo
config(optional)A dict of Git configuration settings to pass to the remote Git commands.
sshPrivateKey(optional)The private key to use when running Git for fetch operations. The ssh utility must be in the system path in order to use this option. On Windows, only Git distribution that embeds MINGW has been tested (as of July 2017, the official distribution is MINGW-based). The worker must either have the host in the known hosts file or the host key must be specified via the sshHostKey option.
sshHostKey(optional)Specifies public host key to match when authenticating with SSH public key authentication. This may be either a Secret or just a string. sshPrivateKey must be specified in order to use this option. The host key must be in the form of <key type> <base64-encoded string>, e.g. ssh-rsa AAAAB3N<…>FAaQ==.
sshKnownHosts(optional)Specifies the contents of the SSH known_hosts file to match when authenticating with SSH public key authentication. This may be either a Secret or just a string. sshPrivateKey must be specified in order to use this option. sshHostKey must not be specified in order to use this option.
auth_credentials
(optional) An username/password tuple to use when running git for fetch operations. The worker’s git version needs to be at least 1.7.9.
git_credentials
(optional) See GitCredentialOptions. The worker’s git version needs to be at least 1.7.9.
2.5.13.10. Mercurial
- class buildbot.steps.source.mercurial.Mercurial
The Mercurial build step performs a Mercurial (aka hg) checkout or update.
Branches are available in two modes: dirname, where the name of the branch is a suffix of the name of the repository, or inrepo, which uses Hg’s named-branches support.
Make sure this setting matches your changehook, if you have that installed.
from buildbot.plugins import steps
factory.addStep(steps.Mercurial(repourl='path/to/repo', mode='full',
method='fresh', branchType='inrepo'))
The Mercurial step takes the following arguments:
repourlwhere the Mercurial source repository is available.
defaultBranchthis specifies the name of the branch to use when a Build does not provide one of its own. This will be appended to
repourlto create the string that will be passed to thehg clonecommand. IfalwaysUseLatestisTruethen the branch and revision information that comes with the Build is ignored and branch specified in this parameter is used.branchTypeeither ‘dirname’ (default) or ‘inrepo’ depending on whether the branch name should be appended to the
repourlor the branch is a Mercurial named branch and can be found within therepourl.clobberOnBranchChangeboolean, defaults to
True. If set and using inrepos branches, clobber the tree at each branch change. Otherwise, just update to the branch.
mode
method
Mercurial’s incremental mode does not require a method. The full mode has three methods defined:
clobberIt removes the build directory entirely then makes full clone from repo. This can be slow as it need to clone whole repository
freshThis remove all other files except those tracked by VCS. First it does hg purge --all then pull/update
cleanAll the files which are tracked by Mercurial and listed ignore files are not deleted. Remaining all other files will be deleted before pull/update. This is equivalent to hg purge then pull/update.
2.5.13.11. Monotone
- class buildbot.steps.source.mtn.Monotone
The Monotone build step performs a Monotone checkout or update.
from buildbot.plugins import steps
factory.addStep(steps.Monotone(repourl='http://path/to/repo',
mode='full', method='clobber',
branch='some.branch.name', retry=(10, 1)))
Monotone step takes the following arguments:
repourlthe URL at which the Monotone source repository is available.
branchthis specifies the name of the branch to use when a Build does not provide one of its own. If
alwaysUseLatestisTruethen the branch and revision information that comes with the Build is ignored and branch specified in this parameter is used.progressthis is a boolean that has a pull from the repository use
--ticker=dotinstead of the default--ticker=none.
mode
(optional): defaults to
'incremental'. Specifies whether to clean the build tree or not. In any case, the worker first pulls from the given remote repository to synchronize (or possibly initialize) its local database. The mode and method only affect how the build tree is checked-out or updated from the local database.
incrementalThe source is update, but any built files are left untouched.
fullThe build tree is clean of any built files. The exact method for doing this is controlled by the
methodargument. Even in this mode, the revisions already pulled remain in the database and a fresh pull is rarely needed.
method
(optional): defaults to
copywhen mode isfull. Monotone’s incremental mode does not require a method. The full mode has four methods defined:
clobberIt removes the build directory entirely then makes fresh checkout from the database.
cleanThis remove all other files except those tracked and ignored by Monotone. It will remove all the files that appear in mtn ls unknown. Then it will pull from remote and update the working directory.
freshThis remove all other files except those tracked by Monotone. It will remove all the files that appear in mtn ls ignored and mtn ls unknows. Then pull and update similar to
cleancopyThis first checkout source into source directory then copy the
sourcedirectory tobuilddirectory then performs the build operation in the copied directory. This way we make fresh builds with very less bandwidth to download source. The behavior of source checkout follows exactly same as incremental. It performs all the incremental checkout behavior insourcedirectory.
2.5.13.12. P4
- class buildbot.steps.source.p4.P4
The P4 build step creates a Perforce client specification and performs an update.
from buildbot.plugins import steps, util
factory.addStep(steps.P4(
p4port=p4port,
p4client=util.WithProperties('%(P4USER)s-%(workername)s-%(buildername)s'),
p4user=p4user,
p4base='//depot',
p4viewspec=p4viewspec,
mode='incremental'))
You can specify the client spec in two different ways.
You can use the p4base, p4branch, and (optionally) p4extra_views to build up the viewspec, or you can utilize the p4viewspec to specify the whole viewspec as a set of tuples.
Using p4viewspec will allow you to add lines such as:
//depot/branch/mybranch/... //<p4client>/...
-//depot/branch/mybranch/notthisdir/... //<p4client>/notthisdir/...
If you specify p4viewspec and any of p4base, p4branch, and/or p4extra_views you will receive a configuration error exception.
p4baseA view into the Perforce depot without branch name or trailing
/.... Typically//depot/proj.p4branch(optional): A single string, which is appended to the p4base as follows
<p4base>/<p4branch>/...to form the first line in the viewspecp4extra_views(optional): a list of
(depotpath, clientpath)tuples containing extra views to be mapped into the client specification. Both will have/...appended automatically. The client name and source directory will be prepended to the client path.p4viewspecThis will override any p4branch, p4base, and/or p4extra_views specified. The viewspec will be an array of tuples as follows:
[('//depot/main/','')]
It yields a viewspec with just:
//depot/main/... //<p4client>/...
p4viewspec_suffix(optional): The
p4viewspeclets you customize the client spec for a builder but, as the previous example shows, it automatically adds...at the end of each line. If you need to also specify file-level remappings, you can set thep4viewspec_suffixtoNoneso that nothing is added to your viewspec:[('//depot/main/...', '...'), ('-//depot/main/config.xml', 'config.xml'), ('//depot/main/config.vancouver.xml', 'config.xml')]
It yields a viewspec with:
//depot/main/... //<p4client>/... -//depot/main/config.xml //<p4client/main/config.xml //depot/main/config.vancouver.xml //<p4client>/main/config.xml
Note how, with
p4viewspec_suffixset toNone, you need to manually add...where you need it.p4client_spec_options(optional): By default, clients are created with the
allwrite rmdiroptions. This string lets you change that.p4port(optional): the
host:portstring describing how to get to the P4 Depot (repository), used as the option -p argument for all p4 commands.p4user(optional): the Perforce user, used as the option -u argument to all p4 commands.
p4passwd(optional): the Perforce password, used as the option -p argument to all p4 commands.
p4client(optional): The name of the client to use. In
mode='full'andmode='incremental', it’s particularly important that a unique name is used for each checkout directory to avoid incorrect synchronization. For this reason, Python percent substitution will be performed on this value to replace%(prop:workername)swith the worker name and%(prop:buildername)swith the builder name. The default isbuildbot_%(prop:workername)s_%(prop:buildername)s.p4line_end(optional): The type of line ending handling P4 should use. This is added directly to the client spec’s
LineEndproperty. The default islocal.p4client_type(optional): The type of client to create. A client type can be set to create a client better suited to CI use. Learn more about client type in the P4 documentation The default is
None.p4extra_args(optional): Extra arguments to be added to the P4 command-line for the
synccommand. So for instance if you want to sync only to populate a Perforce proxy (without actually syncing files to disk), you can do:P4(p4extra_args=['-Zproxyload'], ...)
use_ticketsSet to
Trueto use ticket-based authentication, instead of passwords (but you still need to specifyp4passwd).streamSet to
Trueto use a stream-associated workspace, in which casep4baseandp4branchare used to determine the stream path.
2.5.13.13. Repo
- class buildbot.steps.source.repo.Repo
The Repo build step performs a Repo init and sync.
The Repo step takes the following arguments:
manifestURL(required): the URL at which the Repo’s manifests source repository is available.
manifestBranch(optional, defaults to
master): the manifest repository branch on which repo will take its manifest. Corresponds to the-bargument to the repo init command.manifestFile(optional, defaults to
default.xml): the manifest filename. Corresponds to the-margument to the repo init command.tarball(optional, defaults to
None): the repo tarball used for fast bootstrap. If not present the tarball will be created automatically after first sync. It is a copy of the.repodirectory which contains all the Git objects. This feature helps to minimize network usage on very big projects with lots of workers.The suffix of the tarball determines if the tarball is compressed and which compressor is chosen. Supported suffixes are
bz2,gz,lzma,lzop, andpigz.jobs(optional, defaults to
None): Number of projects to fetch simultaneously while syncing. Passed to repo sync subcommand with “-j”.syncAllBranches(optional, defaults to
False): renderable boolean to control whetherreposyncs all branches. I.e.repo sync -cdepth(optional, defaults to 0): Depth argument passed to repo init. Specifies the amount of git history to store. A depth of 1 is useful for shallow clones. This can save considerable disk space on very large projects.
submodules(optional, defaults to
False): sync any submodules associated with the manifest repo. Corresponds to the--submodulesargument to the repo init command.updateTarballAge(optional, defaults to “one week”): renderable to control the policy of updating of the tarball given properties. Returns: max age of tarball in seconds, or
None, if we want to skip tarball update. The default value should be good trade off on size of the tarball, and update frequency compared to cost of tarball creationrepoDownloads(optional, defaults to None): list of
repo downloadcommands to perform at the end of the Repo step each string in the list will be prefixedrepo download, and run as is. This means you can include parameter in the string. For example:["-c project 1234/4"]will cherry-pick patchset 4 of patch 1234 in projectproject["-f project 1234/4"]will enforce fast-forward on patchset 4 of patch 1234 in projectproject
- class buildbot.steps.source.repo.RepoDownloadsFromProperties
util.repo.DownloadsFromProperties can be used as a renderable of the repoDownload parameter it will look in passed properties for string with following possible format:
repo download project change_number/patchset_numberproject change_number/patchset_numberproject/change_number/patchset_number
All of these properties will be translated into a repo download. This feature allows integrators to build with several pending interdependent changes, which at the moment cannot be described properly in Gerrit, and can only be described by humans.
- class buildbot.steps.source.repo.RepoDownloadsFromChangeSource
util.repo.DownloadsFromChangeSource can be used as a renderable of the repoDownload parameter
This rendereable integrates with GerritChangeSource, and will automatically use the repo download command of repo to download the additional changes introduced by a pending changeset.
Note
You can use the two above Rendereable in conjunction by using the class buildbot.process.properties.FlattenList
For example:
from buildbot.plugins import steps, util
factory.addStep(steps.Repo(manifestURL='git://gerrit.example.org/manifest.git',
repoDownloads=util.FlattenList([
util.RepoDownloadsFromChangeSource(),
util.RepoDownloadsFromProperties("repo_downloads")
])))
2.5.13.14. SVN
- class buildbot.steps.source.svn.SVN
The SVN build step performs a Subversion checkout or update.
There are two basic ways of setting up the checkout step, depending upon whether you are using multiple branches or not.
The SVN step should be created with the repourl argument:
repourl(required): this specifies the
URLargument that will be given to the svn checkout command. It dictates both where the repository is located and which sub-tree should be extracted. One way to specify the branch is to useInterpolate. For example, if you wanted to check out the trunk repository, you could userepourl=Interpolate("http://svn.example.com/repos/%(src::branch)s"). Alternatively, if you are using a remote Subversion repository which is accessible through HTTP at a URL ofhttp://svn.example.com/repos, and you wanted to check out thetrunk/calcsub-tree, you would directly userepourl="http://svn.example.com/repos/trunk/calc"as an argument to yourSVNstep.
If you are building from multiple branches, then you should create the SVN step with the repourl and provide branch information with Interpolate:
from buildbot.plugins import steps, util
factory.addStep(
steps.SVN(mode='incremental',
repourl=util.Interpolate(
'svn://svn.example.org/svn/%(src::branch)s/myproject')))
Alternatively, the repourl argument can be used to create the SVN step without Interpolate:
from buildbot.plugins import steps
factory.addStep(steps.SVN(mode='full',
repourl='svn://svn.example.org/svn/myproject/trunk'))
username(optional): if specified, this will be passed to the
svnbinary with a--usernameoption.password(optional): if specified, this will be passed to the
svnbinary with a--passwordoption.extra_args(optional): if specified, an array of strings that will be passed as extra arguments to the
svnbinary.keep_on_purge(optional): specific files or directories to keep between purges, like some build outputs that can be reused between builds.
depth(optional): Specify depth argument to achieve sparse checkout. Only available if worker has Subversion 1.5 or higher.
If set to
emptyupdates will not pull in any files or subdirectories not already present. If set tofiles, updates will pull in any files not already present, but not directories. If set toimmediates, updates will pull in any files or subdirectories not already present, the new subdirectories will have depth: empty. If set toinfinity, updates will pull in any files or subdirectories not already present; the new subdirectories will have depth-infinity. Infinity is equivalent to SVN default update behavior, without specifying any depth argument.preferLastChangedRev(optional): By default, the
got_revisionproperty is set to the repository’s global revision (“Revision” in the svn info output). Set this parameter toTrueto have it set to the “Last Changed Rev” instead.
mode
method
SVN’s incremental mode does not require a method. The full mode has five methods defined:
clobberIt removes the working directory for each build then makes full checkout.
freshThis always always purges local changes before updating. This deletes unversioned files and reverts everything that would appear in a svn status --no-ignore. This is equivalent to the old update mode with
always_purge.cleanThis is same as fresh except that it deletes all unversioned files generated by svn status.
copyThis first checkout source into source directory then copy the
sourcedirectory tobuilddirectory then performs the build operation in the copied directory. This way we make fresh builds with very less bandwidth to download source. The behavior of source checkout follows exactly same as incremental. It performs all the incremental checkout behavior insourcedirectory.exportSimilar to
method='copy', except usingsvn exportto create build directory so that there are no.svndirectories in the build directory.
If you are using branches, you must also make sure your ChangeSource will report the correct branch names.
2.5.13.15. GitCommit
- class buildbot.steps.source.git.GitCommit
The GitCommit build step adds files and commits modifications in your local Git repository.
The GitCommit step takes the following arguments:
workdir(required) The path to the local repository to push commits from.
messages(required) List of message that will be created with the commit. Correspond to the
-mflag of thegit commitcommand.paths(required) List of path that will be added to the commit.
logEnviron(optional) If this option is true (the default), then the step’s logfile will describe the environment variables on the worker. In situations where the environment is not relevant and is long, it may be easier to set
logEnviron=False.env(optional) A dictionary of environment strings which will be added to the child command’s environment. The usual property interpolations can be used in environment variable names and values - see Properties.
timeout(optional) Specifies the timeout for worker-side operations, in seconds. If your repositories are particularly large, then you may need to increase this value from its default of 1200 (20 minutes).
config(optional) A dict of git configuration settings to pass to the remote git commands.
no_verify(optional) Specifies whether
--no-verifyoption should be supplied to git. The default isFalse.emptyCommits(optional) One of the values
disallow(default),create-empty-commit, andignore. Decides the behavior when there is nothing to be committed. The valuedisallowwill make the buildstep fail. The valuecreate-empty-commitwill create an empty commit. The valueignorewill create no commit.
2.5.13.16. GitTag
- class buildbot.steps.source.git.GitTag
The GitTag build step creates a tag in your local Git repository.
The GitTag step takes the following arguments:
workdir(required) The path to the local repository to push commits from.
tagName(required) The name of the tag.
annotated(optional) If
True, create an annotated tag.messages(optional) List of message that will be created with the annotated tag. Must be set only if annotated parameter is
True. Correspond to the-mflag of thegit tagcommand.force(optional) If
True, forces overwrite of tags on the local repository. Corresponds to the--forceflag of thegit tagcommand.logEnviron(optional) If this option is true (the default), then the step’s logfile will describe the environment variables on the worker. In situations where the environment is not relevant and is long, it may be easier to set
logEnviron=False.env(optional) A dictionary of environment strings which will be added to the child command’s environment. The usual property interpolations can be used in environment variable names and values - see Properties.
timeout(optional) Specifies the timeout for worker-side operations, in seconds. If your repositories are particularly large, then you may need to increase this value from its default of 1200 (20 minutes).
config(optional) A dict of git configuration settings to pass to the remote git commands.
2.5.13.17. GitPush
- class buildbot.steps.source.git.GitPush
The GitPush build step pushes new commits to a Git repository.
The GitPush step takes the following arguments:
workdir(required) The path to the local repository to push commits from.
repourl(required) The URL of the upstream Git repository.
branch(required) The branch to push. The branch should already exist on the local repository.
force(optional) If
True, forces overwrite of refs on the remote repository. Corresponds to the--forceflag of thegit pushcommand.logEnviron(optional) If this option is true (the default), then the step’s logfile will describe the environment variables on the worker. In situations where the environment is not relevant and is long, it may be easier to set
logEnviron=False.env(optional) A dictionary of environment strings which will be added to the child command’s environment. The usual property interpolations can be used in environment variable names and values - see Properties.
timeout(optional) Specifies the timeout for worker-side operations, in seconds. If your repositories are particularly large, then you may need to increase this value from its default of 1200 (20 minutes).
config
(optional) A dict of git configuration settings to pass to the remote git commands.
sshPrivateKey
(optional) The private key to use when running git for fetch operations. The ssh utility must be in the system path in order to use this option. On Windows only git distribution that embeds MINGW has been tested (as of July 2017 the official distribution is MINGW-based). The worker must either have the host in the known hosts file or the host key must be specified via the
sshHostKeyoption.
sshHostKey
(optional) Specifies public host key to match when authenticating with SSH public key authentication. This may be either a Secret or just a string.
sshPrivateKeymust be specified in order to use this option. The host key must be in the form of<key type> <base64-encoded string>, e.g.ssh-rsa AAAAB3N<...>FAaQ==.
sshKnownHosts(optional)Specifies the contents of the SSH known_hosts file to match when authenticating with SSH public key authentication. This may be either a Secret or just a string. sshPrivateKey must be specified in order to use this option. sshHostKey must not be specified in order to use this option.
auth_credentials
(optional) An username/password tuple to use when running git for push operations. The worker’s git version needs to be at least 1.7.9.
git_credentials
(optional) See GitCredentialOptions. The worker’s git version needs to be at least 1.7.9.
2.5.13.18. GitDiffInfo
The GitDiffInfo step gathers information about differences between the current revision and the last common ancestor of this revision and another commit or branch.
This information is useful for various reporters to be able to identify new warnings that appear in newly modified code.
The diff information is stored as a custom json as transient build data via setBuildData function.
Currently only git repositories are supported.
The class inherits the arguments accepted by ShellMixin except command.
Additionally, it accepts the following arguments:
compareToRef(Optional, string, defaults to
master) The commit or branch identifying the revision to get the last common ancestor to. In most cases, this will be the target branch of a pull or merge request.dataName(Optional, string, defaults to
diffinfo-master) The name of the build data to save the diff json to.
Build data specification
This section documents the format of the data produced by the GitDiffInfo step and put into build data.
Any future steps performing the same operation on different version control systems should produce data in the same format.
Likewise, all consumers should expect the input data to be in the format as documented here.
Conceptually, the diffinfo data is a list of file changes, each of which itself contain a list of diff hunks within that file.
This data is stored as a JSON document.
The root element is a list of objects, each of which represent a file where changes have been detected. Each of these file objects has the following keys:
source_file- a string representing path to the source file. This does not include any prefixes such asa/. When there is no source file, e.g. when a new file is created,/dev/nullis used.target_file- a string representing path to the target file. This does not include any prefixes such asb/. When there is no target file, e.g. when a file has been deleted,/dev/nullis used.is_binary- a boolean specifying whether this is a binary file or not. Changes in binary files are not interpreted as hunks.is_rename- a boolean specifying whether this file has been renamedhunks- a list of objects (described below) specifying individual changes within the file.
Each of the hunk objects has the following keys:
ss- an integer specifying the start line of the diff hunk in the source filesl- an integer specifying the length of the hunk in the source file as a number of linests- an integer specifying the start line of the diff hunk in the target filetl- an integer specifying the length of the hunk in the target file as a number lines
Example of produced build data
The following shows build data that is produced for a deleted file, a changed file and a new file.
[
{
"source_file": "file1",
"target_file": "/dev/null",
"is_binary": false,
"is_rename": false,
"hunks": [
{
"ss": 1,
"sl": 3,
"ts": 0,
"tl": 0
}
]
},
{
"source_file": "file2",
"target_file": "file2",
"is_binary": false,
"is_rename": false,
"hunks": [
{
"ss": 4,
"sl": 0,
"ts": 5,
"tl": 3
},
{
"ss": 15,
"sl": 0,
"ts": 19,
"tl": 3
}
]
},
{
"source_file": "/dev/null",
"target_file": "file3",
"is_binary": false,
"is_rename": false,
"hunks": [
{
"ss": 0,
"sl": 0,
"ts": 1,
"tl": 3
}
]
}
]
2.5.13.19. ShellCommand
Most interesting steps involve executing a process of some sort on the worker.
The ShellCommand class handles this activity.
Several subclasses of ShellCommand are provided as starting points for common build steps.
Using ShellCommands
- class buildbot.steps.shell.ShellCommand
This is a useful base class for just about everything you might want to do during a build (except for the initial source checkout).
It runs a single command in a child shell on the worker.
All stdout/stderr is recorded into a LogFile.
The step usually finishes with a status of FAILURE if the command’s exit code is non-zero, otherwise it has a status of SUCCESS.
The preferred way to specify the command is with a list of argv strings, since this allows for spaces in filenames and avoids doing any fragile shell-escaping.
You can also specify the command with a single string, in which case the string is given to /bin/sh -c COMMAND for parsing.
On Windows, commands are run via cmd.exe /c which works well.
However, if you’re running a batch file, the error level does not get propagated correctly unless you add ‘call’ before your batch file’s name: cmd=['call', 'myfile.bat', ...].
ShellCommand includes all sub-processes created by the command in JobObject. This ensures
that all child processes are managed together with the parent process. When the main command is
terminated, all sub-processes are also terminated automatically, preventing any orphaned processes.
This enhancement aligns the behavior of Windows systems with POSIX systems, where similar process
management has been in place.
The ShellCommand arguments are:
commandA list of strings (preferred) or single string (discouraged) which specifies the command to be run. A list of strings is preferred because it can be used directly as an argv array. Using a single string (with embedded spaces) requires the worker to pass the string to /bin/sh for interpretation, which raises all sorts of difficult questions about how to escape or interpret shell metacharacters.
If
commandcontains nested lists (for example, from a properties substitution), then that list will be flattened before it is executed.workdirAll
ShellCommands are run by default in theworkdir, which defaults to thebuildsubdirectory of the worker builder’s base directory. The absolute path of the workdir will thus be the worker’s basedir (set as an option tobuildbot-worker create-worker, Creating a worker), plus the builder’s basedir (set in the builder’sbuilddirkey inmaster.cfg), plus the workdir itself (a class-level attribute of the BuildFactory, defaults tobuild).For example:
from buildbot.plugins import steps f.addStep(steps.ShellCommand(command=["make", "test"], workdir="build/tests"))
envA dictionary of environment strings which will be added to the child command’s environment. For example, to run tests with a different i18n language setting, you might use:
from buildbot.plugins import steps f.addStep(steps.ShellCommand(command=["make", "test"], env={'LANG': 'fr_FR'}))
These variable settings will override any existing ones in the worker’s environment or the environment specified in the
Builder. The exception isPYTHONPATH, which is merged with (actually prepended to) any existingPYTHONPATHsetting. The following example will prepend/home/buildbot/lib/pythonto any existingPYTHONPATH:from buildbot.plugins import steps f.addStep(steps.ShellCommand( command=["make", "test"], env={'PYTHONPATH': "/home/buildbot/lib/python"}))
To avoid the need of concatenating paths together in the master config file, if the value is a list, it will be joined together using the right platform dependent separator.
Those variables support expansion so that if you just want to prepend
/home/buildbot/binto thePATHenvironment variable, you can do it by putting the value${PATH}at the end of the value like in the example below. Variables that don’t exist on the worker will be replaced by"".from buildbot.plugins import steps f.addStep(steps.ShellCommand( command=["make", "test"], env={'PATH': ["/home/buildbot/bin", "${PATH}"]}))
Note that environment values must be strings (or lists that are turned into strings). In particular, numeric properties such as
buildnumbermust be substituted using Interpolate.want_stdoutIf
False, stdout from the child process is discarded rather than being sent to the buildmaster for inclusion in the step’sLogFile.want_stderrLike
want_stdoutbut forstderr. Note that commands that run through a PTY do not have separatestdout/stderrstreams, and both are merged intostdout.usePTYIf
True, this command will be run in apty(defaults toFalse). This option is not available on Windows.In general, you do not want to use a pseudo-terminal. This is only useful for running commands that require a terminal - for example, testing a command-line application that will only accept passwords read from a terminal. Using a pseudo-terminal brings lots of compatibility problems, and prevents Buildbot from distinguishing the standard error (red) and standard output (black) streams.
In previous versions, the advantage of using a pseudo-terminal was that
grandchildprocesses were more likely to be cleaned up if the build was interrupted or it timed out. This occurred because using a pseudo-terminal incidentally puts the command into its own process group.As of Buildbot-0.8.4, all commands are placed in process groups, and thus grandchild processes will be cleaned up properly.
logfilesSometimes commands will log interesting data to a local file, rather than emitting everything to stdout or stderr. For example, Twisted’s trial command (which runs unit tests) only presents summary information to stdout, and puts the rest into a file named
_trial_temp/test.log. It is often useful to watch these files as the command runs, rather than using /bin/cat to dump their contents afterwards.The
logfiles=argument allows you to collect data from these secondary logfiles in near-real-time, as the step is running. It accepts a dictionary which maps from a local Log name (which is how the log data is presented in the build results) to either a remote filename (interpreted relative to the build’s working directory), or a dictionary of options. Each named file will be polled on a regular basis (every couple of seconds) as the build runs, and any new text will be sent over to the buildmaster.If you provide a dictionary of options instead of a string, you must specify the
filenamekey. You can optionally provide afollowkey which is a boolean controlling whether a logfile is followed or concatenated in its entirety. Following is appropriate for logfiles to which the build step will append, where the pre-existing contents are not interesting. The default value forfollowisFalse, which gives the same behavior as just providing a string filename.from buildbot.plugins import steps f.addStep(steps.ShellCommand( command=["make", "test"], logfiles={"triallog": "_trial_temp/test.log"}))
The above example will add a log named ‘triallog’ on the master, based on
_trial_temp/test.logon the worker.from buildbot.plugins import steps f.addStep(steps.ShellCommand(command=["make", "test"], logfiles={ "triallog": { "filename": "_trial_temp/test.log", "follow": True } }))
lazylogfilesIf set to
True, logfiles will be tracked lazily, meaning that they will only be added when and if something is written to them. This can be used to suppress the display of empty or missing log files. The default isFalse.timeoutIf the command fails to produce any output for this many seconds, it is assumed to be locked up and will be killed. This defaults to 1200 seconds. Pass
Noneto disable.maxTimeIf the command takes longer than this many seconds, it will be killed. This is disabled by default.
max_linesIf the command outputs more lines than this maximum lines, it will be killed. This is disabled by default.
logEnvironIf
True(the default), then the step’s logfile will describe the environment variables on the worker. In situations where the environment is not relevant and is long, it may be easier to set it toFalse.interruptSignalThis is the signal (specified by name) that should be sent to the process when the command needs to be interrupted (either by the buildmaster, a timeout, etc.). By default, this is “KILL” (9). Specify “TERM” (15) to give the process a chance to cleanup. This functionality requires a version 0.8.6 worker or newer.
sigtermTimeIf set, when interrupting, try to kill the command with SIGTERM and wait for sigtermTime seconds before firing
interuptSignal. If None,interruptSignalwill be fired immediately upon interrupt.initialStdinIf the command expects input on stdin, the input can be supplied as a string with this parameter. This value should not be excessively large, as it is handled as a single string throughout Buildbot – for example, do not pass the contents of a tarball with this parameter.
decodeRCThis is a dictionary that decodes exit codes into results value. For example,
{0:SUCCESS,1:FAILURE,2:WARNINGS}will treat the exit code2asWARNINGS. The default ({0:SUCCESS}) is to treat just 0 as successful. Any exit code not present in the dictionary will be treated asFAILURE.
2.5.13.20. Shell Sequence
Some steps have a specific purpose, but require multiple shell commands to implement them.
For example, a build is often configure; make; make install.
We have two ways to handle that:
Create one shell command with all these. To put the logs of each commands in separate logfiles, we need to re-write the script as
configure 1> configure_log; ...and to add theseconfigure_logfiles aslogfilesargument of the buildstep. This has the drawback of complicating the shell script, and making it harder to maintain as the logfile name is put in different places.Create three
ShellCommandinstances, but this loads the build UI unnecessarily.
ShellSequence is a class that executes not one but a sequence of shell commands during a build.
It takes as argument a renderable, or list of commands which are ShellArg objects.
Each such object represents a shell invocation.
The single ShellSequence argument aside from the common parameters is:
from buildbot.plugins import steps, util
f.addStep(steps.ShellSequence(
commands=[
util.ShellArg(command=['configure']),
util.ShellArg(command=['make'], logname='make'),
util.ShellArg(command=['make', 'check_warning'], logname='warning',
warnOnFailure=True),
util.ShellArg(command=['make', 'install'], logname='make install')
]))
All these commands share the same configuration of environment, workdir and pty usage that can be set up the same way as in ShellCommand.
- class buildbot.steps.shellsequence.ShellArg(self, command=None, logname=None, haltOnFailure=False, flunkOnWarnings=False, flunkOnFailure=False, warnOnWarnings=False, warnOnFailure=False)
- Parameters:
command – (see the
ShellCommandcommandargument),logname – optional log name, used as the stdio log of the command
The
haltOnFailure,flunkOnWarnings,flunkOnFailure,warnOnWarnings,warnOnFailureparameters drive the execution of the sequence, the same way steps are scheduled in the build. They have the same default values as for buildsteps - see Parameters Common to all Steps.Any of the arguments to this class can be renderable.
Note that if
lognamename does not start with the prefixstdio, that prefix will be set likestdio <logname>. If nolognameis supplied, the output of the command will not be collected.
The two ShellSequence methods below tune the behavior of how the list of shell commands are executed, and can be overridden in subclasses.
- class buildbot.steps.shellsequence.ShellSequence
- shouldRunTheCommand(oneCmd)
- Parameters:
oneCmd – a string or a list of strings, as rendered from a
ShellArginstance’scommandargument.
Determine whether the command
oneCmdshould be executed. IfshouldRunTheCommandreturnsFalse, the result of the command will be recorded as SKIPPED. The default method skips all empty strings and empty lists.
- getFinalState()
Return the status text of the step in the end. The default value is to set the text describing the execution of the last shell command.
- runShellSequence(commands):
- Parameters:
commands – list of shell args
This method actually runs the shell sequence. The default
runmethod callsrunShellSequence, but subclasses can overriderunto perform other operations, if desired.
2.5.13.21. Compile
This is meant to handle compiling or building a project written in C.
The default command is make all.
When the compilation is finished, the log file is scanned for GCC warning messages, a summary log is created with any problems that were seen, and the step is marked as WARNINGS if any were discovered.
Through the WarningCountingShellCommand superclass, the number of warnings is stored in a Build Property named warnings-count, which is accumulated over all Compile steps (so if two warnings are found in one step, and three are found in another step, the overall build will have a warnings-count property of 5).
Each step can be optionally given a maximum number of warnings via the maxWarnCount parameter.
If this limit is exceeded, the step will be marked as a failure.
The default regular expression used to detect a warning is '.*warning[: ].*' , which is fairly liberal and may cause false-positives.
To use a different regexp, provide a warningPattern= argument, or use a subclass which sets the warningPattern attribute:
from buildbot.plugins import steps
f.addStep(steps.Compile(command=["make", "test"],
warningPattern="^Warning: "))
The warningPattern= can also be a pre-compiled Python regexp object: this makes it possible to add flags like re.I (to use case-insensitive matching).
If warningPattern is set to None then warning counting is disabled.
Note that the compiled warningPattern will have its match method called, which is subtly different from a search.
Your regular expression must match the from the beginning of the line.
This means that to look for the word “warning” in the middle of a line, you will need to prepend '.*' to your regular expression.
The suppressionFile= argument can be specified as the (relative) path of a file inside the workdir defining warnings to be suppressed from the warning counting and log file.
The file will be uploaded to the master from the worker before compiling, and any warning matched by a line in the suppression file will be ignored.
This is useful to accept certain warnings (e.g. in some special module of the source tree or in cases where the compiler is being particularly stupid), yet still be able to easily detect and fix the introduction of new warnings.
The file must contain one line per pattern of warnings to ignore.
Empty lines and lines beginning with # are ignored.
Other lines must consist of a regexp matching the file name, followed by a colon (:), followed by a regexp matching the text of the warning.
Optionally this may be followed by another colon and a line number range.
For example:
# Sample warning suppression file
mi_packrec.c : .*result of 32-bit shift implicitly converted to 64 bits.* : 560-600
DictTabInfo.cpp : .*invalid access to non-static.*
kernel_types.h : .*only defines private constructors and has no friends.* : 51
If no line number range is specified, the pattern matches the whole file; if only one number is given it matches only on that line.
The suppressionList= argument can be specified as a list of four-tuples as addition or instead of suppressionFile=.
The tuple should be [ FILE-RE, WARNING-RE, START, END ].
If FILE-RE is None, then the suppression applies to any file.
START and END can be specified as in suppression file, or None.
The default warningPattern regexp only matches the warning text, so line numbers and file names are ignored.
To enable line number and file name matching, provide a different regexp and provide a function (callable) as the argument of warningExtractor=.
The function is called with three arguments: the BuildStep object, the line in the log file with the warning, and the SRE_Match object of the regexp search for warningPattern.
It should return a tuple (filename, linenumber, warning_test).
For example:
f.addStep(Compile(command=["make"],
warningPattern="^(.\*?):([0-9]+): [Ww]arning: (.\*)$",
warningExtractor=Compile.warnExtractFromRegexpGroups,
suppressionFile="support-files/compiler_warnings.supp"))
(Compile.warnExtractFromRegexpGroups is a pre-defined function that returns the filename, linenumber, and text from groups (1,2,3) of the regexp match).
In projects with source files in multiple directories, it is possible to get full path names for file names matched in the suppression file, as long as the build command outputs the names of directories as they are entered into and left again.
For this, specify regexps for the arguments directoryEnterPattern= and directoryLeavePattern=.
The directoryEnterPattern= regexp should return the name of the directory entered into in the first matched group.
The defaults, which are suitable for GNU Make, are these:
directoryEnterPattern="make.*: Entering directory [\"`'](.*)['`\"]"
directoryLeavePattern="make.*: Leaving directory"
(TODO: this step needs to be extended to look for GCC error messages as well, and collect them into a separate logfile, along with the source code filenames involved).
2.5.13.22. Configure
- class buildbot.steps.shell.Configure
This is intended to handle the ./configure step from autoconf-style projects, or the perl Makefile.PL step from perl MakeMaker.pm-style modules.
The default command is ./configure but you can change this by providing a command= parameter.
The arguments are identical to ShellCommand.
from buildbot.plugins import steps
f.addStep(steps.Configure())
2.5.13.23. CMake
- class buildbot.steps.cmake.CMake
This is intended to handle the cmake step for projects that use CMake-based build systems.
Note
Links below point to the latest CMake documentation. Make sure that you check the documentation for the CMake you use.
In addition to the parameters ShellCommand supports, this step accepts the following parameters:
pathEither a path to a source directory to (re-)generate a build system for it in the current working directory. Or an existing build directory to re-generate its build system.
generatorA build system generator. See cmake-generators(7) for available options.
definitionsA dictionary that contains parameters that will be converted to
-D{name}={value}when passed to CMake. A renderable which renders to a dictionary can also be provided, see Properties. Refer to cmake(1) for more information.optionsA list or a tuple that contains options that will be passed to CMake as is. A renderable which renders to a tuple or list can also be provided, see Properties. Refer to cmake(1) for more information.
cmakePath to the CMake binary. Default is cmake
from buildbot.plugins import steps
...
factory.addStep(
steps.CMake(
generator='Ninja',
definitions={
'CMAKE_BUILD_TYPE': Property('BUILD_TYPE')
},
options=[
'-Wno-dev'
]
)
)
...
2.5.13.24. Visual C++
These steps are meant to handle compilation using Microsoft compilers.
VC++ 6-141 (aka Visual Studio 2003-2015 and VCExpress9) are supported via calling devenv.
Msbuild as well as Windows Driver Kit 8 are supported via the MsBuild4, MsBuild12, MsBuild14 and MsBuild141 steps.
These steps will take care of setting up a clean compilation environment, parsing the generated output in real time, and delivering as detailed as possible information about the compilation executed.
All of the classes are in buildbot.steps.vstudio.
The available classes are:
VC6VC7VC8VC9VC10VC11VC12VC14VC141VS2003VS2005VS2008VS2010VS2012VS2013VS2015VS2017VS2019VS2022VCExpress9MsBuild4MsBuild12MsBuild14MsBuild141MsBuild15MsBuild16MsBuild17
The available constructor arguments are
modeThe mode default to
rebuild, which means that first all the remaining object files will be cleaned by the compiler. The alternate values arebuild, where only the updated files will be recompiled, andclean, where the current build files are removed and no compilation occurs.projectfileThis is a mandatory argument which specifies the project file to be used during the compilation.
configThis argument defaults to
releasean gives to the compiler the configuration to use.installdirThis is the place where the compiler is installed. The default value is compiler specific and is the default place where the compiler is installed.
useenvThis boolean parameter, defaulting to
Falseinstruct the compiler to use its own settings or the one defined through the environment variablesPATH,INCLUDE, andLIB. If any of theINCLUDEorLIBparameter is defined, this parameter automatically switches toTrue.PATHThis is a list of path to be added to the
PATHenvironment variable. The default value is the one defined in the compiler options.INCLUDEThis is a list of path where the compiler will first look for include files. Then comes the default paths defined in the compiler options.
LIBThis is a list of path where the compiler will first look for libraries. Then comes the default path defined in the compiler options.
archThat one is only available with the class VS2005 (VC8). It gives the target architecture of the built artifact. It defaults to
x86and does not apply toMsBuild4orMsBuild12. Please seeplatformbelow.projectThis gives the specific project to build from within a workspace. It defaults to building all projects. This is useful for building cmake generate projects.
platformThis is a mandatory argument for
MsBuild4andMsBuild12specifying the target platform such as ‘Win32’, ‘x64’ or ‘Vista Debug’. The last one is an example of driver targets that appear once Windows Driver Kit 8 is installed.definesThat one is only available with the MsBuild family of classes. It allows to define pre-processor constants used by the compiler.
Here is an example on how to drive compilation with Visual Studio 2013:
from buildbot.plugins import steps
f.addStep(
steps.VS2013(projectfile="project.sln", config="release",
arch="x64", mode="build",
INCLUDE=[r'C:\3rd-party\libmagic\include'],
LIB=[r'C:\3rd-party\libmagic\lib-x64']))
Here is a similar example using “MsBuild12”:
from buildbot.plugins import steps
# Build one project in Release mode for Win32
f.addStep(
steps.MsBuild12(projectfile="trunk.sln", config="Release", platform="Win32",
workdir="trunk",
project="tools\\protoc"))
# Build the entire solution in Debug mode for x64
f.addStep(
steps.MsBuild12(projectfile="trunk.sln", config='Debug', platform='x64',
workdir="trunk"))
2.5.13.25. Cppcheck
This step runs cppcheck, analyse its output, and set the outcome in Properties.
from buildbot.plugins import steps
f.addStep(steps.Cppcheck(enable=['all'], inconclusive=True))
This class adds the following arguments:
binary(Optional, defaults to
cppcheck) Use this if you need to give the full path to the cppcheck binary or if your binary is called differently.source(Optional, defaults to
['.']) This is the list of paths for the sources to be checked by this step.enable(Optional) Use this to give a list of the message classes that should be in cppcheck report. See the cppcheck man page for more information.
inconclusive(Optional) Set this to
Trueif you want cppcheck to also report inconclusive results. See the cppcheck man page for more information.extra_args(Optional) This is the list of extra arguments to be given to the cppcheck command.
All other arguments are identical to ShellCommand.
2.5.13.26. Robocopy
- class buildbot.steps.mswin.Robocopy
This step runs robocopy on Windows.
Robocopy is available in versions of Windows starting with Windows Vista and Windows Server 2008. For previous versions of Windows, it’s available as part of the Windows Server 2003 Resource Kit Tools.
from buildbot.plugins import steps, util
f.addStep(
steps.Robocopy(
name='deploy_binaries',
description='Deploying binaries...',
descriptionDone='Deployed binaries.',
source=util.Interpolate('Build\\Bin\\%(prop:configuration)s'),
destination=util.Interpolate('%(prop:deploy_dir)\\Bin\\%(prop:configuration)s'),
mirror=True
)
)
Available constructor arguments are:
sourceThe path to the source directory (mandatory).
destinationThe path to the destination directory (mandatory).
filesAn array of file names or patterns to copy.
recursiveCopy files and directories recursively (
/Eparameter).mirrorMirror the source directory in the destination directory, including removing files that don’t exist anymore (
/MIRparameter).moveDelete the source directory after the copy is complete (
/MOVEparameter).exclude_filesAn array of file names or patterns to exclude from the copy (
/XFparameter).exclude_dirsAn array of directory names or patterns to exclude from the copy (
/XDparameter).custom_optsAn array of custom parameters to pass directly to the
robocopycommand.verboseWhether to output verbose information (
/V /TS /FPparameters).
Note that parameters /TEE /NP will always be appended to the command to signify, respectively, to output logging to the console, use Unicode logging, and not print any percentage progress information for each file.
2.5.13.27. Test
from buildbot.plugins import steps
f.addStep(steps.Test())
This is meant to handle unit tests.
The default command is make test, and the warnOnFailure flag is set.
The other arguments are identical to ShellCommand.
2.5.13.28. TreeSize
from buildbot.plugins import steps
f.addStep(steps.TreeSize())
This is a simple command that uses the du tool to measure the size of the code tree.
It puts the size (as a count of 1024-byte blocks, aka ‘KiB’ or ‘kibibytes’) on the step’s status text, and sets a build property named tree-size-KiB with the same value.
All arguments are identical to ShellCommand.
2.5.13.29. PerlModuleTest
from buildbot.plugins import steps
f.addStep(steps.PerlModuleTest())
This is a simple command that knows how to run tests of perl modules.
It parses the output to determine the number of tests passed and failed and total number executed, saving the results for later query.
The command is prove --lib lib -r t, although this can be overridden with the command argument.
All other arguments are identical to those for ShellCommand.
2.5.13.30. SubunitShellCommand
- class buildbot.steps.subunit.SubunitShellCommand
This buildstep is similar to ShellCommand, except that it runs the log content through a subunit filter to extract test and failure counts.
from buildbot.plugins import steps
f.addStep(steps.SubunitShellCommand(command="make test"))
This runs make test and filters it through subunit.
The ‘tests’ and ‘test failed’ progress metrics will now accumulate test data from the test run.
If failureOnNoTests is True, this step will fail if no test is run.
By default failureOnNoTests is False.
2.5.13.31. HLint
The HLint step runs Twisted Lore, a lint-like checker over a set of .xhtml files.
Any deviations from recommended style is flagged and put in the output log.
The step looks at the list of changes in the build to determine which files to check - it does not check all files.
It specifically excludes any .xhtml files in the top-level sandbox/ directory.
The step takes a single, optional, parameter: python.
This specifies the Python executable to use to run Lore.
from buildbot.plugins import steps
f.addStep(steps.HLint())
2.5.13.32. MaxQ
MaxQ (http://maxq.tigris.org/) is a web testing tool that allows you to record HTTP sessions and play them back.
The MaxQ step runs this framework.
from buildbot.plugins import steps
f.addStep(steps.MaxQ(testdir='tests/'))
The single argument, testdir, specifies where the tests should be run.
This directory will be passed to the run_maxq.py command, and the results analyzed.
2.5.13.33. Trigger
- class buildbot.steps.trigger.Trigger
The counterpart to the Triggerable scheduler is the Trigger build step:
from buildbot.plugins import steps
f.addStep(steps.Trigger(schedulerNames=['build-prep'],
waitForFinish=True,
updateSourceStamp=True,
set_properties={ 'quick' : False }))
The SourceStamps to use for the triggered build are controlled by the arguments updateSourceStamp, alwaysUseLatest, and sourceStamps.
Hyperlinks are added to the build detail web pages for each triggered build.
schedulerNamesLists the
Triggerableschedulers that should be triggered when this step is executed.Note
It is possible, but not advisable, to create a cycle where a build continually triggers itself, because the schedulers are specified by name.
unimportantSchedulerNamesWhen
waitForFinishisTrue, all schedulers in this list will not cause the trigger step to fail. unimportantSchedulerNames must be a subset of schedulerNames. IfwaitForFinishisFalse, unimportantSchedulerNames will simply be ignored.waitForFinishIf
True, the step will not finish until all of the builds from the triggered schedulers have finished.If
False(the default) or not given, then the buildstep succeeds immediately after triggering the schedulers.updateSourceStampIf
True(the default), then the step updates the source stamps given to theTriggerableschedulers to includegot_revision(the revision actually used in this build) asrevision(the revision to use in the triggered builds). This is useful to ensure that all of the builds use exactly the same source stamps, even if otherChanges have occurred while the build was running.If
False(and neither of the other arguments are specified), then the exact same SourceStamps are used.alwaysUseLatestIf
True, then no SourceStamps are given, corresponding to using the latest revisions of the repositories specified in the Source steps. This is useful if the triggered builds use to a different source repository.sourceStampsAccepts a list of dictionaries containing the keys
branch,revision,repository,project, and optionallypatch_level,patch_body,patch_subdir,patch_authorandpatch_commentand creates the corresponding SourceStamps. If only one sourceStamp has to be specified then the argumentsourceStampcan be used for a dictionary containing the keys mentioned above. The argumentsupdateSourceStamp,alwaysUseLatest, andsourceStampcan be specified using properties.set_propertiesAllows control of the properties that are passed to the triggered scheduler. The parameter takes a dictionary mapping property names to values. You may use Interpolate here to dynamically construct new property values. For the simple case of copying a property, this might look like:
set_properties={"my_prop1" : Property("my_prop1"), "my_prop2" : Property("my_prop2")}
where
Propertyis an instance ofbuildbot.process.properties.Property.Note
The
copy_propertiesparameter, given a list of properties to copy into the new build request, has been deprecated in favor of explicit use ofset_properties.
Dynamic Trigger
Sometimes it is desirable to select which scheduler to trigger, and which properties to set dynamically, at the time of the build.
For this purpose, the Trigger step supports a method that you can customize in order to override statically defined schedulernames, set_properties and optionally unimportant.
- getSchedulersAndProperties()
- Returns:
list of dictionaries containing the keys ‘sched_name’, ‘props_to_set’ and ‘unimportant’ optionally via deferred.
This method returns a list of dictionaries describing what scheduler to trigger, with which properties and if the scheduler is unimportant. The properties should already be rendered (ie, concrete value, not objects wrapped by
InterpolateorProperty). Since this function happens at build-time, the property values are available from the step and can be used to decide what schedulers or properties to use.With this method, you can also trigger the same scheduler multiple times with different set of properties. The sourcestamp configuration is however the same for each triggered build request.
2.5.13.34. BuildEPYDoc
- class buildbot.steps.python.BuildEPYDoc
epydoc is a tool for generating
API documentation for Python modules from their docstrings.
It reads all the .py files from your source tree, processes the docstrings therein, and creates a large tree of .html files (or a single .pdf file).
The BuildEPYDoc step will run epydoc to produce this API documentation, and will count the errors and warnings from its output.
You must supply the command line to be used.
The default is make epydocs, which assumes that your project has a Makefile with an epydocs target.
You might wish to use something like epydoc -o apiref source/PKGNAME instead.
You might also want to add option –pdf to generate a PDF file instead of a large tree of HTML files.
The API docs are generated in-place in the build tree (under the workdir, in the subdirectory controlled by the option -o argument).
To make them useful, you will probably have to copy them to somewhere they can be read.
For example if you have server with configured nginx web server, you can place generated docs to it’s public folder with command like rsync -ad apiref/ dev.example.com:~/usr/share/nginx/www/current-apiref/.
You might instead want to bundle them into a tarball and publish it in the same place where the generated install tarball is placed.
from buildbot.plugins import steps
f.addStep(steps.BuildEPYDoc(command=["epydoc", "-o", "apiref", "source/mypkg"]))
2.5.13.35. PyFlakes
- class buildbot.steps.python.PyFlakes
PyFlakes is a tool to perform basic static analysis of Python code to look for simple errors, like missing imports and references of undefined names. It is like a fast and simple form of the C lint program. Other tools (like pychecker) provide more detailed results but take longer to run.
The PyFlakes step will run pyflakes and count the various kinds of errors and warnings it detects.
You must supply the command line to be used.
The default is make pyflakes, which assumes you have a top-level Makefile with a pyflakes target.
You might want to use something like pyflakes . or pyflakes src.
from buildbot.plugins import steps
f.addStep(steps.PyFlakes(command=["pyflakes", "src"]))
2.5.13.36. Sphinx
- class buildbot.steps.python.Sphinx
Sphinx is the Python Documentation Generator. It uses RestructuredText as input format.
The Sphinx step will run sphinx-build or any other program specified in its sphinx argument and count the various warnings and error it detects.
from buildbot.plugins import steps
f.addStep(steps.Sphinx(sphinx_builddir="_build"))
This step takes the following arguments:
sphinx_builddir(required) Name of the directory where the documentation will be generated.
sphinx_sourcedir(optional, defaulting to
.), Name the directory where theconf.pyfile will be foundsphinx_builder(optional) Indicates the builder to use.
sphinx(optional, defaulting to sphinx-build) Indicates the executable to run.
tags(optional) List of
tagsto pass to sphinx-builddefines(optional) Dictionary of defines to overwrite values of the
conf.pyfile.strict_warnings(optional) Boolean, defaults to False. Treat all warnings as errors.
mode(optional) String, one of
fullorincremental(the default). If set tofull, indicates to Sphinx to rebuild everything without re-using the previous build results.
2.5.13.37. PyLint
Similarly, the PyLint step will run pylint and analyze the results.
You must supply the command line to be used. There is no default.
from buildbot.plugins import steps
f.addStep(steps.PyLint(command=["pylint", "src"]))
This step takes the following arguments:
store_results(Optional, defaults to
True) IfTrue, the test results will be stored in the test database.
2.5.13.38. Trial
- class buildbot.steps.python_twisted.Trial
This step runs a unit test suite using trial, a unittest-like testing framework that is a component of Twisted Python.
The Trial takes the following arguments:
python(string or list of strings, optional) Which python executable to use. Will form the start of the argv array that will launch
trial. If you use this, you should settrialto an explicit path (like /usr/bin/trial or ./bin/trial). Defaults toNone, which leaves it out entirely (running ‘trial args’ instead of python ./bin/trial args’). Likely values are'python',['python3.8'],['python', '-Wall'], etc.trial(string, optional) Which ‘trial’ executable to run Defaults to
'trial', which will cause$PATHto be searched and probably find/usr/bin/trial. If you setpython, this should be set to an explicit path (becausepython3.8 trialwill not work).trialMode(list of strings, optional) A list of arguments to pass to trial to set the reporting mode. This defaults to
['-to']which means ‘verbose colorless output’ to the trial that comes with Twisted-2.0.x and at least -2.1.0 . Newer versions of Twisted may come with a trial that prefers['--reporter=bwverbose'].trialArgs(list of strings, optional) A list of arguments to pass to trial. This can be used to turn on any extra flags you like. Defaults to
[].jobs(integer, optional) Defines the number of parallel jobs.
tests(list of strings, optional) Defines the test modules to run. For example,
['twisted.test.test_defer', 'twisted.test.test_process']If this is a string, it will be converted into a one-item list.testChanges(boolean, optional) Selects the tests according to the changes in the Build. If set, this will override the
testsparameter and asks the Build for all the files that make up the Changes going into this build. The filenames will be passed totrialasking to run just the tests necessary to cover the changes.recurse(boolean, optional) Selects the
--recurseoption of trial. This allows test cases to be found in deeper subdirectories of the modules listed intests. When usingtestChangesthis option is not necessary.reactor(boolean, optional) Selects the reactor to use within Trial. For example, options are
gtkorjava. If not provided, the Twisted’s usual platform-dependent default is used.randomly(boolean, optional) If
True, adds the--random=0argument, which instructs trial to run the unit tests in a random order each time. This occasionally catches problems that might be masked when one module always runs before another.**kwargs(dict, optional) The step inherits all arguments of
ShellMixinexceptcommand.
Trial creates and switches into a directory named _trial_temp/ before running the tests, and sends the twisted log (which includes all exceptions) to a file named test.log.
This file will be pulled up to the master where it can be seen as part of the status output.
from buildbot.plugins import steps
f.addStep(steps.Trial(tests='petmail.test'))
2.5.13.39. RemovePYCs
- class buildbot.steps.python_twisted.RemovePYCs
This is a simple built-in step that will remove .pyc files from the workdir.
This is useful in builds that update their source (and thus do not automatically delete .pyc files) but where some part of the build process is dynamically searching for Python modules.
Notably, trial has a bad habit of finding old test modules.
from buildbot.plugins import steps
f.addStep(steps.RemovePYCs())
2.5.13.40. HTTP Requests
Using the HTTPStep step, it is possible to perform HTTP requests in order to trigger another REST service about the progress of the build.
The parameters are the following:
url(mandatory) The URL where to send the request
methodThe HTTP method to use (out of
POST,GET,PUT,DELETE,HEADorOPTIONS), default toPOST.paramsDictionary of URL parameters to append to the URL.
dataThe body to attach the request. If a dictionary is provided, form-encoding will take place.
headersDictionary of headers to send.
hide_request_headersIterable of request headers to be hidden from the log. The header will be listed in the log but the value will be shown as
<HIDDEN>.hide_response_headersIterable of response headers to be hidden from the log. The header will be listed in the log but the value will be shown as
<HIDDEN>.other paramsAny other keywords supported by the
requestsapi can be passed to this step.Note
The entire Buildbot master process shares a single Requests
Sessionobject. This has the advantage of supporting connection re-use and other HTTP/1.1 features. However, it also means that any cookies or other state changed by one step will be visible to other steps, causing unexpected results. This behavior may change in future versions.
When the method is known in advance, class with the name of the method can also be used. In this case, it is not necessary to specify the method.
Example:
from buildbot.plugins import steps, util
f.addStep(steps.POST('http://myRESTService.example.com/builds',
data = {
'builder': util.Property('buildername'),
'buildnumber': util.Property('buildnumber'),
'workername': util.Property('workername'),
'revision': util.Property('got_revision')
}))
2.5.13.41. Worker Filesystem Steps
Here are some buildsteps for manipulating the worker’s filesystem.
FileExists
This step will assert that a given file exists, failing if it does not. The filename can be specified with a property.
from buildbot.plugins import steps
f.addStep(steps.FileExists(file='test_data'))
This step requires worker version 0.8.4 or later.
CopyDirectory
This command copies a directory on the worker.
from buildbot.plugins import steps
f.addStep(steps.CopyDirectory(src="build/data", dest="tmp/data"))
This step requires worker version 0.8.5 or later.
The CopyDirectory step takes the following arguments:
timeoutIf the copy command fails to produce any output for this many seconds, it is assumed to be locked up and will be killed. This defaults to 120 seconds. Pass
Noneto disable.maxTimeIf the command takes longer than this many seconds, it will be killed. This is disabled by default.
RemoveDirectory
This command recursively deletes a directory on the worker.
from buildbot.plugins import steps
f.addStep(steps.RemoveDirectory(dir="build/build"))
This step requires worker version 0.8.4 or later.
MakeDirectory
This command creates a directory on the worker.
from buildbot.plugins import steps
f.addStep(steps.MakeDirectory(dir="build/build"))
This step requires worker version 0.8.5 or later.
2.5.13.42. Transferring Files
- class buildbot.steps.transfer.FileUpload
- class buildbot.steps.transfer.FileDownload
Most of the work involved in a build will take place on the worker.
But occasionally it is useful to do some work on the buildmaster side.
The most basic way to involve the buildmaster is simply to move a file from the worker to the master, or vice versa.
There are a pair of steps named FileUpload and FileDownload to provide this functionality.
FileUpload moves a file up to the master, while FileDownload moves a file down from the master.
As an example, let’s assume that there is a step which produces an HTML file within the source tree that contains some sort of generated project documentation.
And let’s assume that we run nginx web server on the buildmaster host for serving static files.
We want to move this file to the buildmaster, into a /usr/share/nginx/www/ directory, so it can be visible to developers.
This file will wind up in the worker-side working directory under the name docs/reference.html.
We want to put it into the master-side /usr/share/nginx/www/ref.html, and add a link to the HTML status to the uploaded file.
from buildbot.plugins import steps
f.addStep(steps.ShellCommand(command=["make", "docs"]))
f.addStep(steps.FileUpload(workersrc="docs/reference.html",
masterdest="/usr/share/nginx/www/ref.html",
url="http://somesite/~buildbot/ref.html"))
The masterdest= argument will be passed to os.path.expanduser, so things like ~ will be expanded properly.
Non-absolute paths will be interpreted relative to the buildmaster’s base directory.
Likewise, the workersrc= argument will be expanded and interpreted relative to the builder’s working directory.
Note
The copied file will have the same permissions on the master as on the worker, look at the mode= parameter to set it differently.
To move a file from the master to the worker, use the FileDownload command.
For example, let’s assume that some step requires a configuration file that, for whatever reason, could not be recorded in the source code repository or generated on the worker side:
from buildbot.plugins import steps
f.addStep(steps.FileDownload(mastersrc="~/todays_build_config.txt",
workerdest="build_config.txt"))
f.addStep(steps.ShellCommand(command=["make", "config"]))
Like FileUpload, the mastersrc= argument is interpreted relative to the buildmaster’s base directory, and the workerdest= argument is relative to the builder’s working directory.
If the worker is running in ~worker, and the builder’s builddir is something like tests-i386, then the workdir is going to be ~worker/tests-i386/build, and a workerdest= of foo/bar.html will get put in ~worker/tests-i386/build/foo/bar.html.
Both of these commands will create any missing intervening directories.
Other Parameters
The maxsize= argument lets you set a maximum size for the file to be transferred.
This may help to avoid surprises: transferring a 100MB coredump when you were expecting to move a 10kB status file might take an awfully long time.
The blocksize= argument controls how the file is sent over the network: larger blocksizes are slightly more efficient but also consume more memory on each end, and there is a hard-coded limit of about 640kB.
The mode= argument allows you to control the access permissions of the target file, traditionally expressed as an octal integer.
The most common value is probably 0o755, which sets the x executable bit on the file (useful for shell scripts and the like).
The default value for mode= is None, which means the permission bits will default to whatever the umask of the writing process is.
The default umask tends to be fairly restrictive, but at least on the worker you can make it less restrictive with a --umask command-line option at creation time (Worker Options).
The keepstamp= argument is a boolean that, when True, forces the modified and accessed time of the destination file to match the times of the source file.
When False (the default), the modified and accessed times of the destination file are set to the current time on the buildmaster.
The url= argument allows you to specify an url that will be displayed in the HTML status.
The title of the url will be the name of the item transferred (directory for DirectoryUpload or file for FileUpload).
This allows the user to add a link to the uploaded item if that one is uploaded to an accessible place.
For FileUpload, the urlText= argument allows you to specify the url title that will be displayed in the web UI.
Transferring Directories
- class buildbot.steps.transfer.DirectoryUpload
To transfer complete directories from the worker to the master, there is a BuildStep named DirectoryUpload.
It works like FileUpload, just for directories.
However it does not support the maxsize, blocksize and mode arguments.
As an example, let’s assume an generated project documentation, which consists of many files (like the output of doxygen or epydoc).
And let’s assume that we run nginx web server on buildmaster host for serving static files.
We want to move the entire documentation to the buildmaster, into a /usr/share/nginx/www/docs directory, and add a link to the uploaded documentation on the HTML status page.
On the worker-side the directory can be found under docs:
from buildbot.plugins import steps
f.addStep(steps.ShellCommand(command=["make", "docs"]))
f.addStep(steps.DirectoryUpload(workersrc="docs",
masterdest="/usr/share/nginx/www/docs",
url="~buildbot/docs"))
The DirectoryUpload step will create all necessary directories and transfers empty directories, too.
The maxsize and blocksize parameters are the same as for FileUpload, although note that the size of the transferred data is implementation-dependent, and probably much larger than you expect due to the encoding used (currently tar).
The optional compress argument can be given as 'gz' or 'bz2' to compress the datastream.
For DirectoryUpload the urlText= argument allows you to specify the url title that will be displayed in the web UI.
Note
The permissions on the copied files will be the same on the master as originally on the worker, see option buildbot-worker create-worker --umask to change the default one.
Transferring Multiple Files At Once
- class buildbot.steps.transfer.MultipleFileUpload
In addition to the FileUpload and DirectoryUpload steps there is the MultipleFileUpload step for uploading a bunch of files (and directories) in a single BuildStep.
The step supports all arguments that are supported by FileUpload and DirectoryUpload, but instead of a the single workersrc parameter it takes a (plural) workersrcs parameter.
This parameter should either be a list, something that can be rendered as a list or a string which will be converted to a list.
Additionally it supports the glob parameter if this parameter is set to True all arguments in workersrcs will be parsed through glob and the results will be uploaded to masterdest.:
from buildbot.plugins import steps
f.addStep(steps.ShellCommand(command=["make", "test"]))
f.addStep(steps.ShellCommand(command=["make", "docs"]))
f.addStep(steps.MultipleFileUpload(workersrcs=["docs", "test-results.html"],
masterdest="/usr/share/nginx/www/",
url="~buildbot"))
The url= parameter, can be used to specify a link to be displayed in the HTML status of the step.
The way URLs are added to the step can be customized by extending the MultipleFileUpload class.
The allUploadsDone method is called after all files have been uploaded and sets the URL.
The uploadDone method is called once for each uploaded file and can be used to create file-specific links.
import os
from buildbot.plugins import steps
class CustomFileUpload(steps.MultipleFileUpload):
linkTypes = ('.html', '.txt')
def linkFile(self, basename):
name, ext = os.path.splitext(basename)
return ext in self.linkTypes
def uploadDone(self, result, source, masterdest):
if self.url:
basename = os.path.basename(source)
if self.linkFile(basename):
self.addURL(self.url + '/' + basename, basename)
def allUploadsDone(self, result, sources, masterdest):
if self.url:
notLinked = [src for src in sources if not self.linkFile(src)]
numFiles = len(notLinked)
if numFiles:
self.addURL(self.url, '... %d more' % numFiles)
For MultipleFileUpload the urlText= argument allows you to specify the url title that will be displayed in the web UI.
2.5.13.43. Transferring Strings
- class buildbot.steps.transfer.StringDownload
- class buildbot.steps.transfer.JSONStringDownload
- class buildbot.steps.transfer.JSONPropertiesDownload
Sometimes it is useful to transfer a calculated value from the master to the worker. Instead of having to create a temporary file and then use FileDownload, you can use one of the string download steps.
from buildbot.plugins import steps, util
f.addStep(steps.StringDownload(util.Interpolate("%(src::branch)s-%(prop:got_revision)s\n"),
workerdest="buildid.txt"))
StringDownload works just like FileDownload except it takes a single argument, s, representing the string to download instead of a mastersrc argument.
from buildbot.plugins import steps
buildinfo = {
'branch': Property('branch'),
'got_revision': Property('got_revision')
}
f.addStep(steps.JSONStringDownload(buildinfo, workerdest="buildinfo.json"))
JSONStringDownload is similar, except it takes an o argument, which must be JSON serializable, and transfers that as a JSON-encoded string to the worker.
from buildbot.plugins import steps
f.addStep(steps.JSONPropertiesDownload(workerdest="build-properties.json"))
JSONPropertiesDownload transfers a json-encoded string that represents a dictionary where properties maps to a dictionary of build property name to property value; and sourcestamp represents the build’s sourcestamp.
2.5.13.44. MasterShellCommand
- class buildbot.steps.master.MasterShellCommand
Occasionally, it is useful to execute some task on the master, for example to create a directory, deploy a build result, or trigger some other centralized processing.
This is possible, in a limited fashion, with the MasterShellCommand step.
This step operates similarly to a regular ShellCommand, but executes on the master, instead of the worker.
To be clear, the enclosing Build object must still have a worker object, just as for any other step – only, in this step, the worker does not do anything.
In the following example, the step renames a tarball based on the day of the week.
from buildbot.plugins import steps
f.addStep(steps.FileUpload(workersrc="widgetsoft.tar.gz",
masterdest="/var/buildoutputs/widgetsoft-new.tar.gz"))
f.addStep(steps.MasterShellCommand(
command="mv widgetsoft-new.tar.gz widgetsoft-`date +%a`.tar.gz",
workdir="/var/buildoutputs"))
Note
By default, this step passes a copy of the buildmaster’s environment variables to the subprocess.
To pass an explicit environment instead, add an env={..} argument.
Environment variables constructed using the env argument support expansion so that if you just want to prepend /home/buildbot/bin to the PATH environment variable, you can do it by putting the value ${PATH} at the end of the value like in the example below.
Variables that don’t exist on the master will be replaced by "".
from buildbot.plugins import steps
f.addStep(steps.MasterShellCommand(
command=["make", "www"],
env={'PATH': ["/home/buildbot/bin",
"${PATH}"]}))
Note that environment values must be strings (or lists that are turned into strings).
In particular, numeric properties such as buildnumber must be substituted using Interpolate.
workdir(optional) The directory from which the command will be run.
interruptSignal(optional) Signal to use to end the process if the step is interrupted.
runtime_timeout(optional) Timeout [s] after which the step is killed. Default is 3600 (1h).
2.5.13.45. LogRenderable
- class buildbot.steps.master.LogRenderable
This build step takes content which can be renderable and logs it in a pretty-printed format. It can be useful for debugging properties during a build.
2.5.13.46. Assert
- class buildbot.steps.master.Assert
This build step takes a Renderable or constant passed in as first argument. It will test if the expression evaluates to True and succeed the step or fail the step otherwise.
2.5.13.47. SetProperty
- class buildbot.steps.master.SetProperty
SetProperty takes two arguments of property and value where the value is to be assigned to the property key.
It is usually called with the value argument being specified as an Interpolate object which allows the value to be built from other property values:
from buildbot.plugins import steps, util
f.addStep(
steps.SetProperty(
property="SomeProperty",
value=util.Interpolate("sch=%(prop:scheduler)s, worker=%(prop:workername)s")
)
)
2.5.13.48. SetProperties
- class buildbot.steps.master.SetProperties
SetProperties takes a dictionary to be turned into build properties.
It is similar to SetProperty, and meant to be used with a Renderer function or a dictionary of Interpolate objects which allows the value to be built from other property values:
"""Example borrowed from Julia's master.cfg
https://github.com/staticfloat/julia-buildbot (MIT)"""
from buildbot.plugins import *
@util.renderer
def compute_artifact_filename(props):
# Get the output of the `make print-BINARYDIST_FILENAME` step
reported_filename = props.getProperty('artifact_filename')
# First, see if we got a BINARYDIST_FILENAME output
if reported_filename[:26] == "BINARYDIST_FILENAME=":
local_filename = util.Interpolate(reported_filename[26:].strip() +
"%(prop:os_pkg_ext)s")
else:
# If not, use non-sf/consistent_distnames naming
if is_mac(props):
template = \
"path/to/Julia-%(prop:version)s-%(prop:shortcommit)s.%(prop:os_pkg_ext)s"
elif is_winnt(props):
template = \
"julia-%(prop:version)s-%(prop:tar_arch)s.%(prop:os_pkg_ext)s"
else:
template = \
"julia-%(prop:shortcommit)s-Linux-%(prop:tar_arch)s.%(prop:os_pkg_ext)s"
local_filename = util.Interpolate(template)
# upload_filename always follows sf/consistent_distname rules
upload_filename = util.Interpolate(
"julia-%(prop:shortcommit)s-%(prop:os_name)s%(prop:bits)s.%(prop:os_pkg_ext)s")
return {
"local_filename": local_filename
"upload_filename": upload_filename
}
f1.addStep(steps.SetProperties(properties=compute_artifact_filename))
2.5.13.49. SetPropertyFromCommand
- class buildbot.steps.shell.SetPropertyFromCommand
This buildstep is similar to ShellCommand, except that it captures the output of the command into a property.
It is usually used like this:
from buildbot.plugins import steps
f.addStep(steps.SetPropertyFromCommand(command="uname -a", property="uname"))
This runs uname -a and captures its stdout, stripped of leading and trailing whitespace, in the property uname.
To avoid stripping, add strip=False.
The property argument can be specified as an Interpolate object, allowing the property name to be built from other property values.
Passing includeStdout=False (defaults to True) stops capture from stdout.
Passing includeStderr=True (defaults to False) allows capture from stderr.
The more advanced usage allows you to specify a function to extract properties from the command output.
Here you can use regular expressions, string interpolation, or whatever you would like.
In this form, extract_fn should be passed, and not Property.
The extract_fn function is called with three arguments: the exit status of the command, its standard output as a string, and its standard error as a string.
It should return a dictionary containing all new properties.
Note that passing in extract_fn will set includeStderr to True.
def glob2list(rc, stdout, stderr):
jpgs = [l.strip() for l in stdout.split('\n')]
return {'jpgs': jpgs}
f.addStep(SetPropertyFromCommand(command="ls -1 *.jpg", extract_fn=glob2list))
Note that any ordering relationship of the contents of stdout and stderr is lost. For example, given:
f.addStep(SetPropertyFromCommand(
command="echo output1; echo error >&2; echo output2",
extract_fn=my_extract))
Then my_extract will see stdout="output1\noutput2\n" and stderr="error\n".
Avoid using the extract_fn form of this step with commands that produce a great deal of output, as the output is buffered in memory until complete.
- class buildbot.steps.worker.SetPropertiesFromEnv
2.5.13.50. SetPropertiesFromEnv
Buildbot workers (later than version 0.8.3) provide their environment variables to the master on connect.
These can be copied into Buildbot properties with the SetPropertiesFromEnv step.
Pass a variable or list of variables in the variables parameter, then simply use the values as properties in a later step.
Note that on Windows, environment variables are case-insensitive, but Buildbot property names are case sensitive.
The property will have exactly the variable name you specify, even if the underlying environment variable is capitalized differently.
If, for example, you use variables=['Tmp'], the result will be a property named Tmp, even though the environment variable is displayed as TMP in the Windows GUI.
from buildbot.plugins import steps, util
f.addStep(steps.SetPropertiesFromEnv(variables=["SOME_JAVA_LIB_HOME", "JAVAC"]))
f.addStep(steps.Compile(commands=[util.Interpolate("%(prop:JAVAC)s"),
"-cp",
util.Interpolate("%(prop:SOME_JAVA_LIB_HOME)s")]))
Note that this step requires that the worker be at least version 0.8.3. For previous versions, no environment variables are available (the worker environment will appear to be empty).
2.5.13.51. RpmBuild
The RpmBuild step builds RPMs based on a spec file:
from buildbot.plugins import steps
f.addStep(steps.RpmBuild(specfile="proj.spec", dist='.el5'))
The step takes the following parameters
specfileThe
.specfile to build fromtopdirDefinition for
_topdir, defaulting to the workdir.builddirDefinition for
_builddir, defaulting to the workdir.rpmdirDefinition for
_rpmdir, defaulting to the workdir.sourcedirDefinition for
_sourcedir, defaulting to the workdir.srcrpmdirDefinition for
_srcrpmdir, defaulting to the workdir.distDistribution to build, used as the definition for
_dist.defineA dictionary of additional definitions to declare.
autoReleaseIf true, use the auto-release mechanics.
vcsRevisionIf true, use the version-control revision mechanics. This uses the
got_revisionproperty to determine the revision and define_revision. Note that this will not work with multi-codebase builds.
2.5.13.52. RpmLint
The RpmLint step checks for common problems in RPM packages or spec files:
from buildbot.plugins import steps
f.addStep(steps.RpmLint())
The step takes the following parameters
filelocThe file or directory to check. In case of a directory, it is recursively searched for RPMs and spec files to check.
configPath to a rpmlint config file. This is passed as the user configuration file if present.
2.5.13.53. MockBuildSRPM Step
The MockBuildSRPM step builds a SourceRPM based on a spec file and optionally a source directory:
Mock (http://fedoraproject.org/wiki/Projects/Mock) creates chroots and builds packages in them.
It populates the changeroot with a basic system and the packages listed as build requirement.
The type of chroot to build is specified with the root parameter.
To use mock your Buildbot user must be added to the mock group.
from buildbot.plugins import steps
f.addStep(steps.MockBuildSRPM(root='default', spec='mypkg.spec'))
The step takes the following parameters
rootUse chroot configuration defined in
/etc/mock/<root>.cfg.resultdirThe directory where the logfiles and the SourceRPM are written to.
specBuild the SourceRPM from this spec file.
sourcesPath to the directory containing the sources, defaulting to
..
Note
It is necessary to pass the resultdir parameter to let the master
watch for (and display) changes to build.log,
root.log, and state.log.
2.5.13.54. MockRebuild
The MockRebuild step rebuilds a SourceRPM package:
Mock (http://fedoraproject.org/wiki/Projects/Mock) creates chroots and builds packages in them.
It populates the changeroot with a basic system and the packages listed as build requirement.
The type of chroot to build is specified with the root parameter.
To use mock your Buildbot user must be added to the mock group.
from buildbot.plugins import steps
f.addStep(steps.MockRebuild(root='default', srpm='mypkg-1.0-1.src.rpm'))
The step takes the following parameters
rootUses chroot configuration defined in
/etc/mock/<root>.cfg.resultdirThe directory where the logfiles and the SourceRPM are written to.
srpmThe path to the SourceRPM to rebuild.
Note
It is necessary to pass the resultdir parameter to let the master
watch for (and display) changes to build.log,
root.log, and state.log.
2.5.13.55. DebPbuilder
The DebPbuilder step builds Debian packages within a chroot built by pbuilder.
It populates the chroot with a basic system and the packages listed as build requirements.
The type of the chroot to build is specified with the distribution, distribution and mirror parameter.
To use pbuilder, your Buildbot user must have the right to run pbuilder as root using sudo.
from buildbot.plugins import steps
f.addStep(steps.DebPbuilder())
The step takes the following parameters
architectureArchitecture to build chroot for.
distributionName, or nickname, of the distribution. Defaults to ‘stable’.
basetgzPath of the basetgz to use for building.
mirrorURL of the mirror used to download the packages from.
othermirrorList of additional
deb URL ...lines to add tosources.list.extrapackagesList if packages to install in addition to the base system.
keyringPath to a gpg keyring to verify the downloaded packages. This is necessary if you build for a foreign distribution.
componentsRepos to activate for chroot building.
2.5.13.56. DebCowbuilder
The DebCowbuilder step is a subclass of DebPbuilder, which use cowbuilder instead of pbuilder.
2.5.13.57. DebLintian
The DebLintian step checks a build .deb for bugs and policy violations.
The packages or changes file to test is specified in fileloc.
from buildbot.plugins import steps, util
f.addStep(steps.DebLintian(fileloc=util.Interpolate("%(prop:deb-changes)s")))
This class adds the following arguments:
fileloc(Optional, string) Location of the .deb or .changes files to test.
suppressTags(Optional, list of strings) List of tags to suppress.
All other arguments are identical to ShellCommand.
BuildSteps are usually specified in the buildmaster’s configuration file, in a list that given to a BuildFactory.
The BuildStep instances in this list are used as templates to construct new independent copies for each build (so that state can be kept on the BuildStep in one build without affecting a later build).
Each BuildFactory can be created with a list of steps, or the factory can be created empty and then steps added to it using the addStep method:
from buildbot.plugins import util, steps
f = util.BuildFactory()
f.addSteps([
steps.SVN(repourl="http://svn.example.org/Trunk/"),
steps.ShellCommand(command=["make", "all"]),
steps.ShellCommand(command=["make", "test"])
])
The basic behavior for a BuildStep is to:
run for a while, then stop
possibly invoke some RemoteCommands on the attached worker
possibly produce a set of log files
finish with a status described by one of four values defined in
buildbot.process.results:SUCCESS,WARNINGS,FAILURE,SKIPPEDprovide a list of short strings to describe the step
The rest of this section describes all the standard BuildStep objects available for use in a Build, and the parameters that can be used to control each.
A full list of build steps is available in the Build Step Index.
2.5.13.58. Build steps
The following build steps are available:
Source checkout steps - used to checkout the source code
Other source-related steps - used to perform non-checkout source operations
ShellCommand steps - used to perform various shell-based operations
Visual C++ (
VC<...>,VS<...>,VCExpress9,MsBuild<...)
Trigger - triggering other builds
Python build steps - used to perform Python-related build operations
Debian build steps - used to build
debpackagesDebPbuilder, DebCowBuilder
RPM build steps - used to build
rpmpackagesTransferring Files - used to perform file transfer operations
FileUpload
FileDownload
DirectoryUpload
MultipleFileUpload
StringDownload
JSONStringDownload
JSONPropertiesDownload
HTTP Requests - used to perform HTTP requests
HTTPStep
POST
GET
PUT
DELETE
HEAD
OPTIONS
Worker Filesystem Steps - used to perform filesystem operations on the worker
FileExists
CopyDirectory
RemoveDirectory
MakeDirectory
Master steps - used to perform operations on the build master
LogRenderable - used to log a renderable property for debugging
Assert - used to terminate build depending on condition
2.5.14. Interlocks
Until now, we assumed that a master can run builds at any worker whenever needed or desired. Some times, you want to enforce additional constraints on builds. For reasons like limited network bandwidth, old worker machines, or a self-willed data base server, you may want to limit the number of builds (or build steps) that can access a resource.
2.5.14.1. Access Modes
The mechanism used by Buildbot is known as the read/write lock [1]. It allows either many readers or a single writer but not a combination of readers and writers. The general lock has been modified and extended for use in Buildbot. Firstly, the general lock allows an infinite number of readers. In Buildbot, we often want to put an upper limit on the number of readers, for example allowing two out of five possible builds at the same time. To do this, the lock counts the number of active readers. Secondly, the terms read mode and write mode are confusing in the context of Buildbot. They have been replaced by counting mode (since the lock counts them) and exclusive mode. As a result of these changes, locks in Buildbot allow a number of builds (up to some fixed number) in counting mode, or they allow one build in exclusive mode.
Note
Access modes are specified when a lock is used. That is, it is possible to have a single lock that is used by several workers in counting mode, and several workers in exclusive mode. In fact, this is the strength of the modes: accessing a lock in exclusive mode will prevent all counting-mode accesses.
2.5.14.2. Count
Often, not all workers are equal. To address this situation, Buildbot allows to have a separate upper limit on the count for each worker. In this way, for example, you can have at most 3 concurrent builds at a fast worker, 2 at a slightly older worker, and 1 at all other workers. You can also specify the count during an access request. This specifies how many units an access consumes from the lock (in other words, as how many builds a build will count). This way, you can balance a shared resource that builders consume unevenly, for example, the amount of memory or the number of CPU cores.
2.5.14.3. Scope
The final thing you can specify when you introduce a new lock is its scope. Some constraints are global and must be enforced on all workers. Other constraints are local to each worker. A master lock is used for the global constraints. You can ensure for example that at most one build (of all builds running at all workers) accesses the database server. With a worker lock you can add a limit local to each worker. With such a lock, you can for example enforce an upper limit to the number of active builds at a worker, like above.
2.5.14.4. Examples
Time for a few examples. A master lock is defined below to protect a database, and a worker lock is created to limit the number of builds at each worker.
from buildbot.plugins import util
db_lock = util.MasterLock("database")
build_lock = util.WorkerLock("worker_builds",
maxCount=1,
maxCountForWorker={'fast': 3, 'new': 2})
db_lock is defined to be a master lock.
The database string is used for uniquely identifying the lock.
At the next line, a worker lock called build_lock is created with the name worker_builds.
Since the requirements of the worker lock are a bit more complicated, two optional arguments are also specified.
The maxCount parameter sets the default limit for builds in counting mode to 1.
For the worker called 'fast' however, we want to have at most three builds, and for the worker called 'new', the upper limit is two builds running at the same time.
The next step is accessing the locks in builds. Buildbot allows a lock to be used during an entire build (from beginning to end) or only during a single build step. In the latter case, the lock is claimed for use just before the step starts and released again when the step ends. To prevent deadlocks [2], it is not possible to claim or release locks at other times.
To use locks, you add them with a locks argument to a build or a step.
Each use of a lock is either in counting mode (that is, possibly shared with
other builds) or in exclusive mode, and this is indicated with the syntax
lock.access(mode, count), where mode is one of "counting" or
"exclusive".
The optional argument count is a non-negative integer (for counting
locks) or 1 (for exclusive locks). If unspecified, it defaults to 1. If 0, the
access always succeeds. This argument allows to use locks for balancing a
shared resource that is utilized unevenly.
A build or build step proceeds only when it has acquired all locks. If a build or step needs many locks, it may be starved [3] by other builds requiring fewer locks.
To illustrate the use of locks, here are a few examples.
from buildbot.plugins import util, steps
db_lock = util.MasterLock("database")
build_lock = util.WorkerLock("worker_builds",
maxCount=1,
maxCountForWorker={'fast': 3, 'new': 2})
f = util.BuildFactory()
f.addStep(steps.SVN(repourl="http://example.org/svn/Trunk"))
f.addStep(steps.ShellCommand(command="make all"))
f.addStep(steps.ShellCommand(command="make test",
locks=[db_lock.access('exclusive')]))
b1 = {'name': 'full1', 'workername': 'fast', 'builddir': 'f1', 'factory': f,
'locks': [build_lock.access('counting')] }
b2 = {'name': 'full2', 'workername': 'new', 'builddir': 'f2', 'factory': f,
'locks': [build_lock.access('counting')] }
b3 = {'name': 'full3', 'workername': 'old', 'builddir': 'f3', 'factory': f,
'locks': [build_lock.access('counting')] }
b4 = {'name': 'full4', 'workername': 'other', 'builddir': 'f4', 'factory': f,
'locks': [build_lock.access('counting')] }
c['builders'] = [b1, b2, b3, b4]
Here we have four workers fast, new, old, and other.
Each worker performs the same checkout, make, and test build step sequence.
We want to enforce that at most one test step is executed between all workers due to restrictions with the database server.
This is done by adding the locks= parameter to the third step.
It takes a list of locks with their access mode.
Alternatively, this can take a renderable that returns a list of locks with their access mode.
In this case, only the db_lock is needed.
The exclusive access mode is used to ensure there is at most one worker that executes the test step.
In addition to exclusive access to the database, we also want workers to stay responsive even under the load of a large number of builds being triggered.
For this purpose, the worker lock called build_lock is defined.
Since the restraint holds for entire builds, the lock is specified in the builder with 'locks': [build_lock.access('counting')].
Note that you will occasionally see lock.access(mode) written as LockAccess(lock, mode).
The two are equivalent, but the former is preferred.
2.5.15. Report Generators
2.5.15.1. BuildStatusGenerator
- class buildbot.reporters.BuildStatusGenerator
This report generator sends a message when a build completes. In case a reporter is used to provide a live status notification for both build start and completion, BuildStartEndStatusGenerator is a better option.
The following parameters are supported:
subject(string, optional).
Deprecated since Buildbot 3.5. Please use the
subjectargument of themessage_formatterpassed to the generator.A string to be used as the subject line of the message.
%(builder)swill be replaced with the name of the builder which provoked the message.%(result)swill be replaced with the name of the result of the build.%(title)sand%(projectName)swill be replaced with the title of the Buildbot instance.mode(list of strings or a string, optional). Defines the cases when a message should be sent. There are two strings which can be used as shortcuts instead of the full lists.
The possible shortcuts are:
allSend message for all cases. Equivalent to
('change', 'failing', 'passing', 'problem', 'warnings', 'exception').warningsEquivalent to
('warnings', 'failing').
If the argument is list of strings, it must be a combination of:
cancelledSend message about builds which were cancelled.
changeSend message about builds which change status.
failingSend message about builds which fail.
passingSend message about builds which succeed.
problemSend message about a build which failed when the previous build has passed.
warningsSend message about builds which generate warnings.
exceptionSend message about builds which generate exceptions.
Defaults to
('failing', 'passing', 'warnings').builders(list of strings, optional). A list of builder names to serve build status information for. Defaults to
None(all builds). Use either builders or tags, but not both.tags(list of strings, optional). A list of tag names to serve build status information for. Defaults to
None(all tags). Use either builders or tags, but not both.schedulers(list of strings, optional). A list of scheduler names to serve build status information for. Defaults to
None(all schedulers).branches(list of strings, optional). A list of branch names to serve build status information for. Defaults to
None(all branches).add_logs(boolean or a list of strings, optional). (deprecated, set the
want_logs_contentof the passedmessage_formatter). IfTrue, include all build logs as attachments to the messages. These can be quite large. This can also be set to a list of log names to send a subset of the logs. Defaults toFalse.add_patch(boolean, optional). If
True, include the patch content if a patch was present. Patches are usually used on aTryserver. Defaults toFalse.report_new(boolean, optional) Whether new builds will be reported in addition to finished builds. Defaults to
False.message_formatter(optional, instance of
reporters.MessageFormatter) This is an optional instance of thereporters.MessageFormatterclass that can be used to generate a custom message.
2.5.15.2. BuildStartEndStatusGenerator
- class buildbot.plugins.reporters.BuildStartEndStatusGenerator
This report generator that sends a message both when a build starts and finishes.
The following parameters are supported:
builders(list of strings, optional). A list of builder names to serve build status information for. Defaults to
None(all builds). Use either builders or tags, but not both.tags(list of strings, optional). A list of tag names to serve build status information for. Defaults to
None(all tags). Use either builders or tags, but not both.schedulers(list of strings, optional). A list of scheduler names to serve build status information for. Defaults to
None(all schedulers).branches(list of strings, optional). A list of branch names to serve build status information for. Defaults to
None(all branches).add_logs(boolean or a list of strings, optional). (deprecated, set the
want_logs_contentof the passedmessage_formatter). IfTrue, include all build logs as attachments to the messages. These can be quite large. This can also be set to a list of log names to send a subset of the logs. Defaults toFalse.add_patch(boolean, optional). If
True, include the patch content if a patch was present. Patches are usually used on aTryserver. Defaults toFalse.start_formatter(optional, instance of
reporters.MessageFormatterorreporters.MessageFormatterRenderable) This is an optional message formatter that can be used to generate a custom message at the start of the build.end_formatter(optional, instance of
reporters.MessageFormatterorreporters.MessageFormatterRenderable) This is an optional message formatter that can be used to generate a custom message at the end of the build.
2.5.15.3. BuildSetStatusGenerator
- class buildbot.reporters.BuildSetStatusGenerator
This report generator sends a message about builds in a buildset.
Message formatters are invoked for each matching build in the buildset. The collected messages are
then joined and sent as a single message. BuildStatusGenerator report generator
uses the same message generation logic, but a single, not multiple builds.
In case of multiple builds, the following algorithm is used to build the final message:
message body is merged from bodies provided by message formatters for the builds. If message bodies are lists or strings, then the result is simple concatenation. If the type is different or there is type mismatch, then mismatching messages are ignored.
message subject is taken from the first build for which message formatter a subject.
extra information is merged from the information dictionaries provided by message formatters. Note that extra information is specified as dictionary of dictionaries. Two root dictionaries are merged by merging child dictionaries. Values in merged child dictionaries that conflict (i.e. correspond to the same keys) are resolved by taking the value of the first build for which it is provided.
The following parameters are supported:
subject(string, optional).
Deprecated since Buildbot 3.5. Please use the
subjectargument of themessage_formatterpassed to the generator.A string to be used as the subject line of the message.
%(builder)swill be replaced with the name of the builder which provoked the message.%(result)swill be replaced with the name of the result of the build.%(title)sand%(projectName)swill be replaced with the title of the Buildbot instance.mode(list of strings or a string, optional). Defines the cases when a message should be sent. Only information about builds that matched the
modewill be included. There are two strings which can be used as shortcuts instead of the full lists.The possible shortcuts are:
allSend message for all cases. Equivalent to
('change', 'failing', 'passing', 'problem', 'warnings', 'exception').warningsEquivalent to
('warnings', 'failing').
If the argument is list of strings, it must be a combination of:
cancelledInclude builds which were cancelled.
changeInclude builds which change status.
failingInclude builds which fail.
passingInclude builds which succeed.
problemInclude a build which failed when the previous build has passed.
warningsInclude builds which generate warnings.
exceptionInclude builds which generate exceptions.
Defaults to
('failing', 'passing', 'warnings').builders(list of strings, optional). A list of builder names to serve build status information for. Defaults to
None(all builds). Use either builders or tags, but not both.tags(list of strings, optional). A list of tag names to serve build status information for. Defaults to
None(all tags). Use either builders or tags, but not both.schedulers(list of strings, optional). A list of scheduler names to serve build status information for. Defaults to
None(all schedulers).branches(list of strings, optional). A list of branch names to serve build status information for. Defaults to
None(all branches).add_logs(boolean or a list of strings, optional). (deprecated, set the
want_logs_contentof the passedmessage_formatter). IfTrue, include all build logs as attachments to the messages. These can be quite large. This can also be set to a list of log names to send a subset of the logs. Defaults toFalse.add_patch(boolean, optional). If
True, include the patch content if a patch was present. Patches are usually used on aTryserver. Defaults toFalse.message_formatter(optional, instance of
reporters.MessageFormatter) This is an optional instance of thereporters.MessageFormatterclass that can be used to generate a custom message.
2.5.15.4. BuildSetCombinedStatusGenerator
- class buildbot.reporters.BuildSetCombinedStatusGenerator
This report generator sends a message about a buildset.
Message formatter is invoked only once for all builds in the buildset.
It is very similar to BuildSetCombinedStatusGenerator but invokes message
formatters for each matching build in the buildset. The collected messages are then joined and sent
as a single message.
A buildset without any builds is useful as a means to report to code review system that a particular code version does not need to be tested. For example in cases when a pull request is updated with the only difference being commit message being changed.
The following parameters are supported:
message_formatter(instance of
reporters.MessageFormatter) This is an instance of thereporters.MessageFormatterclass that will be used to generate message for the buildset.
2.5.15.5. WorkerMissingGenerator
- class buildbot.reporters.WorkerMissingGenerator
This report generator sends a message when a worker goes missing.
The following parameters are supported:
workers(
"all"or a list of strings, optional). Identifies the workers for which to send a message."all"(the default) means that a message will be sent when any worker goes missing. The list version of the parameter specifies the names of the workers.message_formatter(optional, instance of
reporters.MessageFormatterMissingWorker) This is an optional instance of thereporters.MessageFormatterMissingWorkerclass that can be used to generate a custom message.
2.5.15.6. MessageFormatter
This formatter is used to format messages in BuildStatusGenerator and BuildSetStatusGenerator.
It formats a message using the Jinja2 templating language and picks the template either from a string.
The constructor of the class takes the following arguments:
template_typeThis indicates the type of the generated template. Use either ‘plain’ (the default) or ‘html’.
templateIf set, specifies the template used to generate the message body. If not set, a default template will be used. The default template is selected according to
template_typeso it may make sense to specify appropriatetemplate_typeeven if the default template is used.subjectIf set, specifies the template used to generate the message subject. In case of messages generated for multiple builds within a buildset (e.g. from within
BuildSetStatusGenerator), the subject of the first message will be used. Theis_buildsetkey of the context can be used to detect such case and adjust the message appropriately.ctxThis is an extension of the standard context that will be given to the templates. Use this to add content to the templates that is otherwise not available.
Alternatively, you can subclass MessageFormatter and override the
buildAdditionalContextin order to grab more context from the data API.- buildbot.reporters.message.buildAdditionalContext(master, ctx)
- Parameters:
master – the master object
ctx – the context dictionary to enhance
- Returns:
optionally deferred
default implementation will add
self.ctxinto the current template context
want_propertiesThis parameter (defaults to True) will extend the content of the given
buildobject with the Properties from the build.want_stepsThis parameter (defaults to False) will extend the content of the given
buildobject with information about the steps of the build. Use it only when necessary as this increases the overhead in terms of CPU and memory on the master.want_logsThis parameter (defaults to False) will extend the content of the steps of the given
buildobject with the log metadata of each steps from the build. This implieswantStepsto be True. Use it only when mandatory, as this greatly increases the overhead in terms of CPU and memory on the master.want_logs_contentThis parameter (defaults to
False) controls whether to include log content together with log metadata as controlled bywant_logs.Falsedisables log content inclusion.Trueenables log content inclusion for all logs. A list of strings specifies which logs to include. The logs can be included by name; or by step name and log name separated by dot character. If log name is specified, logs with that name will be included regardless of the step it is in. If both step and log names are specified, then logs with that name will be included only from the specific step.want_logs_contentbeing notFalseimplieswant_logs=Trueandwant_steps=True.Enabling want_logs_content dumps the full content of logs and may consume lots of memory and CPU depending on the log size.
extra_info_cbThis parameter (defaults to
None) can be used to customize extra information that is passed to reporters. If set, this argument must be a function that returns a dictionary of dictionaries either directly or via aDeferred. The interpretation of the return value depends on the exact reporter being used.
Context (build)
In the case the message formatter is used to create message for a build the context that is given to the template consists of the following data:
resultsThe results of the build as an integer. Equivalent to
build['results'].result_namesA collection that allows accessing a textual identifier of build result. The intended usage is
result_names[results].The following are possible values:
success,warnings,failure,skipped,exception,retry,cancelled.buildernameThe name of the builder. Equivalent to
build['builder']['name']modeThe mode argument that has been passed to the report generator.
workernameThe name of the worker. Equivalent to the
workernameproperty of the build or<unknown>if it’s not available.buildsetThe
buildsetdictionary from data API.buildThe
builddictionary from data API. Thepropertiesattribute is populated only ifwant_propertiesis set toTrue. It has the following extra properties:builderThe
builderdictionary from the data API that describes the builder of the build.buildrequestThe
buildrequestdictionary from the data API that describes the build request that the build was built for.buildsetThe
buildsetdictionary from the data API that describes the buildset that the build was built for.parentbuildThe
builddictionary from the data API that describes the parent build. This build is identified by theparent_buildidattribute of the buildset.parentbuilderThe
builderdictionary from the data API that describes the builder of the parent build.urlURL to the build in the Buildbot UI.
prev_buildThe
builddictionary from the data API that describes previous build, if any. This attribute is populated only ifwantPreviousBuildis set toTrue.stepsA list of
stepdictionaries from the data API that describe steps in the build, if any. This attribute is populated only ifwantStepsis set toTrue.Additionally, if
want_logsis set toTruethen the step dictionaries will containlogsattribute with a list oflogdictionaries from the data API that describe the logs of the step. The log dictionaries will additionally containurlkey with URL to the log in the web UI as the value.Additionally, if
want_logs_contentis set toTruethen the log dictionaries will containcontentskey with full contents of the log.
is_buildsetA boolean identifying whether the current message will form a larger message that describes multiple builds in a buildset. This mostly concerns generation of the subject as the message bodies will be merged.
projectsA string identifying the projects that the build was built for.
previous_resultsResults of the previous build, if available, otherwise
None.status_detectedString that describes the build in terms of current build results, previous build results and
mode.build_urlURL to the build in the Buildbot UI.
buildbot_titleThe title of the Buildbot instance as per
c['title']from themaster.cfgbuildbot_urlThe URL of the Buildbot instance as per
c['buildbotURL']from themaster.cfgblamelistThe list of users responsible for the build.
summaryA string that summarizes the build result.
sourcestampsA string identifying the source stamps for which the build was made.
Context (buildset)
In the case the message formatter is used to create message for an buildset itself (see
BuildSetCombinedStatusGenerator), the context that is given to the template consists of the
following data:
resultsThe results of the buildset as an integer. Equivalent to
build['results'].result_namesA collection that allows accessing a textual identifier of build result. The intended usage is
result_names[results].The following are possible values:
success,warnings,failure,skipped,exception,retry,cancelled.modeThe mode argument that has been passed to the report generator.
buildsetThe
buildsetdictionary from data API.buildsA list of
builddictionaries from data API. The builds are part of the buildset that is being formatted.is_buildsetAlways
True.projectsA string identifying the projects that the buildset was built for.
status_detectedString that describes the build in terms of current buildset results, previous build results and
mode.buildbot_titleThe title of the Buildbot instance as per
c['title']from themaster.cfgbuildbot_urlThe URL of the Buildbot instance as per
c['buildbotURL']from themaster.cfgblamelistThe list of users responsible for the buildset.
sourcestampsA string identifying the source stamps for which the buildset was made.
Examples
The following examples describe how to get some useful pieces of information from the various data objects:
- Name of the builder that generated this event
{{ buildername }}- Title of the BuildMaster
{{ projects }}- MailNotifier mode
{{ mode }}(a combination ofchange,failing,passing,problem,warnings,exception,all)- URL to build page
{{ build_url }}- URL to Buildbot main page
{{ buildbot_url }}- Status of the build as string.
This require extending the context of the Formatter via the
ctxparameter with:ctx={"statuses": util.Results}.{{ statuses[results] }}- Build text
{{ build['state_string'] }}- Mapping of property names to (values, source)
{{ build['properties'] }}- For instance the build reason (from a forced build)
{{ build['properties']['reason'][0] }}- Worker name
{{ workername }}- List of responsible users
{{ blamelist | join(', ') }}
2.5.15.7. MessageFormatterFunction
This formatter can be used to generate arbitrary messages bodies according to arbitrary calculations.
As opposed to MessageFormatterRenderable, more information is made available to this reporter. As opposed to MessageFormatterFunctionRaw, only the message body can be customized.
- class buildbot.reporters.message.MessageFormatterFunction(function, template_type, want_properties=True, want_steps=False, want_logs=False, want_logs_content=False)
- Parameters:
function (callable) –
A callable that will be called with a dictionary.
If the message formatter is used to format a build, the dictionary contains
buildkey with the build dictionary as received from the data API.If the message formatter is used to format a buildset (e.g. when used from
BuildSetCombinedStatusGenerator), the dictionary contains the following:buildsetkey with the buildset dictionary as received from the data API.buildskey with the builds dictionaries as received from the data API.
template_type (string) – either
plain,htmlorjsondepending on the output of the formatter. JSON output must not be encoded.want_properties (boolean) – include ‘properties’ in the build dictionary
want_steps (boolean) – include ‘steps’ in the build dictionary
wantLogs (boolean) – deprecated, use
want_logsandwant_logs_contentset to the same value.want_logs (boolean) – include ‘logs’ in the steps dictionaries. This implies want_steps=True. This includes only log metadata, for content use
want_logs_content.want_logs_content (boolean or list[str]) – include logs content in the logs dictionaries. False disables log content inclusion. True enables log content inclusion for all logs. A list of strings specifies which logs to include. The logs can be included by name; or by step name and log name separated by dot character. If log name is specified, logs with that name will be included regardless of the step it is in. If both step and log names are specified, then logs with that name will be included only from the specific step. want_logs_content being not False implies want_logs=True and want_steps=True. Enabling want_logs_content dumps the full content of logs and may consume lots of memory and CPU depending on the log size.
2.5.15.8. MessageFormatterFunctionRaw
This formatter can be used to generate arbitrary messages according to arbitrary calculations.
As opposed to MessageFormatterFunction, full message information can be customized.
The return value of the provided function must be a dictionary and is interpreted as follows:
body. Body of the message. Most reporters require this to be a string. If not provided,Noneis used.
type. Type of the message. Must be eitherplain,htmlorjson. If not provided,"plain"is used.
subject. Subject of the message. Must be a string. If not provided,Noneis used.
extra_info. Extra information of the message. Must be eitherNoneor a dictionary of dictionaries with string keys in both root and child dictionaries. If not provided,Noneis used.
- class buildbot.reporters.message.MessageFormatterFunctionRaw(function, want_properties=True, want_steps=False, want_logs=False, want_logs_content=False)
- Parameters:
function (callable) –
A callable that will be called with a two arguments.
master: An instance ofBuildMasterctx: dictionary that contains the same context dictionary as MessageFormatter.
want_properties (boolean) – include ‘properties’ in the build dictionary
want_steps (boolean) – include ‘steps’ in the build dictionary
want_logs (boolean) – include ‘logs’ in the steps dictionaries. This implies want_steps=True. This includes only log metadata, for content use
want_logs_content.want_logs_content (boolean or list[str]) – include logs content in the logs dictionaries. False disables log content inclusion. True enables log content inclusion for all logs. A list of strings specifies which logs to include. The logs can be included by name; or by step name and log name separated by dot character. If log name is specified, logs with that name will be included regardless of the step it is in. If both step and log names are specified, then logs with that name will be included only from the specific step. want_logs_content being not False implies want_logs=True and want_steps=True. Enabling want_logs_content dumps the full content of logs and may consume lots of memory and CPU depending on the log size.
2.5.15.9. MessageFormatterRenderable
This formatter is used to format messages in BuildStatusGenerator.
It renders any renderable using the properties of the build that was passed by the status generator.
This message formatter does not support formatting complete buildsets (
BuildSetCombinedStatusGenerator).
The constructor of the class takes the following arguments:
templateA renderable that is used to generate the body of the build report.
subjectA renderable that is used to generate the subject of the build report.
2.5.15.10. MessageFormatterMissingWorkers
This formatter is used to format messages in WorkerMissingGenerator.
It formats a message using the Jinja2 templating language and picks the template either from a string or from a file.
The constructor to that class takes the same arguments as MessageFormatter, minus want_logs,
want_logs_content, want_properties, want_steps.
templateThe content of the template used to generate the body of the mail as string.
template_typeThis indicates the type of the generated template. Use either ‘plain’ (the default) or ‘html’.
subjectThe content of the subject of the mail as string.
ctxThis is an extension of the standard context that will be given to the templates. Use this to add content to the templates that is otherwise not available.
Alternatively, you can subclass MessageFormatter and override the
buildAdditionalContextin order to grab more context from the data API.- buildbot.reporters.message.buildAdditionalContext(master, ctx)
- Parameters:
master – the master object
ctx – the context dictionary to enhance
- Returns:
optionally deferred
The default implementation will add
self.ctxinto the current template context
The default ctx for the missing worker email is made of:
buildbot_titleThe title of the Buildbot instance as per
c['title']from themaster.cfgbuildbot_urlThe URL of the Buildbot instance as per
c['buildbotURL']from themaster.cfgworkerThe worker object as defined in the REST api plus two attributes:
notifyList of emails to be notified for this worker.
last_connectionString describing the approximate time of last connection for this worker.
Report generators abstract the conditions of when a message is sent by a Reporter and the content of the message.
Multiple report generators can be registered to a reporter.
At this moment, only the following reporters support report generators:
Eventually, report generator support will be added to the rest of the reporters as well.
The following report generators are available:
The report generators may customize the reports using message formatters. The following message formatter classes are provided:
MessageFormatter (commonly used in
BuildStatusGenerator,BuildStartEndStatusGenerator,BuildSetCombinedStatusGeneratorandBuildSetStatusGenerator)MessageFormatterRenderable (commonly used in
BuildStatusGeneratorandBuildStartEndStatusGenerator)MessageFormatterFunction (commonly used in
BuildStatusGeneratorandBuildStartEndStatusGenerator)MessageFormatterFunctionRaw (commonly used in
BuildStatusGenerator,BuildStartEndStatusGenerator,BuildSetCombinedStatusGeneratorandBuildSetStatusGenerator)MessageFormatterMissingWorkers (commonly used in
WorkerMissingGenerator)
Message formatters produce the following information that is later used by the report generators:
Message type:
plain(text),htmlorjson.Message body: a string that describes the information about build or buildset. Other data types are supported too, but then the interpretation of data depends on actual reporter that is being used.
Message subject: an optional title of the message about build or buildset.
Extra information: optional dictionary of dictionaries with any extra information to give to the reporter. Interpretation of the data depends on the reporter that is being used.
2.5.16. Reporters
2.5.16.1. ReporterBase
- class buildbot.reporters.base.ReporterBase(generators)
ReporterBaseis a base class used to implement various reporters. It accepts a list of report generators which define what messages to issue on what events. If generators decide that an event needs a report, then thesendMessagefunction is called. ThesendMessagefunction should be implemented by deriving classes.- Parameters:
generators – (a list of report generator instances) A list of report generators to manage.
- sendMessage(self, reports)
Sends the reports via the mechanism implemented by the specific implementation of the reporter. The reporter is expected to interpret all reports, figure out the best mechanism for reporting and report the given information.
Note
The API provided by the sendMessage function is not yet stable and is subject to change.
- Parameters:
reports – A list of dictionaries, one for each generator that provided a report.
Frequently used report keys
Note
The list of report keys and their meanings are currently subject to change.
This documents frequently used keys within the dictionaries that are passed to the sendMessage function.
body: (string)The body of the report to be sent, usually sent as the body of e.g. email.
subject: (string orNone)The subject of the report to be sent or
Noneif nothing was supplied.
type: (string)The type of the body of the report. The following are currently supported:
plainandhtml.
builder_name: (string)The name of the builder corresponding to the build or buildset that the report describes.
results: (an instance of a result value frombuildbot.process.results)The current result of the build.
builds(a list of build dictionaries as reported by the data API)A list of builds that the report describes.
Many message formatters support
want_stepsargument. If it is set, then build will containstepskey with a list of step dictionaries as reported by the data API.Many message formatters support
want_logsargument. If it is set, then steps will containlogskey with a list of logs dictionaries as reported by the data API.The logs dictionaries contain the following keys in addition to what the data API provides:
stepname(string) The name of the step that produced the log.
url(string) The URL to the interactive page that displays the log contents
url_raw(string) The URL to the page that downloads the log contents as a file
url_raw_inline(string) The URL to the page that shows the log contents directly in thebrowser.
content(optional string) The content of the log. The content of the log is attached onlyif directed by
want_logs_contentargument of message formatters oradd_logsargument of report generators.
buildset(a buildset dictionary as reported by the data API)The buildset that is being described.
users(a list of strings)A list of users to send the report to.
patches(a list of patch dictionaries corresponding to sourcestamp’spatchvalues)A list of patches applied to the build or buildset that is being built.
logs(a list of dictionaries corresponding to logs as reported by the data API)A list of logs produced by the build(s) so far. The log dictionaries have the same enhancements that are described in the
buildsection above.
extra_info(a dictionary of dictionaries with string keys in both)A list of additional reporter-specific data to apply.
2.5.16.2. BitbucketServerCoreAPIStatusPush
from buildbot.plugins import reporters
ss = reporters.BitbucketServerCoreAPIStatusPush('https://bitbucketserver.example.com:8080/',
auth=('bitbucketserver_username',
'secret_password'))
c['services'].append(ss)
Or using Bitbucket personal access token
from buildbot.plugins import reporters
ss = reporters.BitbucketServerCoreAPIStatusPush('https://bitbucketserver.example.com:8080/',
token='MDM0MjM5NDc2MDxxxxxxxxxxxxxxxxxxxxx')
c['services'].append(ss)
BitbucketServerCoreAPIStatusPush publishes build status using
BitbucketServer Core REST API
into which it was integrated in
Bitbucket Server 7.4.
The build status is published to a specific commit SHA in specific repository in Bitbucket Server
with some additional information about reference name, build duration, parent relationship and also possibly test results.
- class BitbucketServerCoreAPIStatusPush(base_url, token=None, auth=None, name=None, statusSuffix=None, generators=None, key=None, parentName=None, buildNumber=None, ref=None, duration=None, testResults=None, verbose=False, debug=None, verify=None)
- Parameters:
base_url (string) – The base url of the Bitbucket Server host.
token (string) – Bitbucket personal access token (mutually exclusive with auth) (can be a Secret)
auth (tuple) – A tuple of Bitbucket Server username and password (mutually exclusive with token) (can be a Secret)
statusName (renderable string) – The name that is displayed for this status. If not defined it is constructed to look like “%(prop:buildername)s #%(prop:buildnumber)s”. Or if the plan has a parent plan the default is constructed to look like “<parent’s buildername> #<parent’s buildnumber> >> %(prop:buildername)s #%(prop:buildnumber)s”. If build status is generated by
BuildRequestGenerator“%(prop:buildername)s #(build request)” is used instead of “%(prop:buildername)s #%(prop:buildnumber)s”. Note: Parent information is not accessible as properties for user defined renderer.statusSuffix (renderable string) – Additional string that is appended to statusName. Empty by default. It is useful when the same plan is launched multiple times for a single parent plan instance. This way every instance of the child plan can have unique suffix and thus be more recognizable (than it would be just by the buildnumber).
generators (list of IReportGenerator instances) – A list of report generators that will be used to generate reports to be sent by this reporter. By default build statuses are generated by
BuildRequestGeneratorandBuildStartEndStatusGenerator.key (renderable string) – Passed to Bitbucket Server to differentiate between statuses. A static string can be passed or
Interpolatefor dynamic substitution. The default key is %(prop:buildername)s.parentName (renderable string) – Defaults to parent’s buildername if plan has a parent plan. Otherwise plan’s own buildername is used as default.
buildNumber (renderable string) – The default build number is %(prop:buildername)s.
ref (renderable string) – By default branch name from
SourceStampis used. If branch doesn’t start with string refs/ prefix refs/heads/ is added to it’s beginning.duration (renderable int) – Computed for finished builds. Otherwise None. (value in milliseconds)
testResults (renderable dict) – Test results can be reported via this parameter. Resulting dictionary must contain keys failed, skipped, successful. By default these keys are filled with values from build properties (tests_failed, tests_skipped, tests_successful) if at least one of the properties is found (missing values will default to 0). Otherwise None. Note: If you want to suppress the default behavior pass renderable that always interpolates to None.
verbose (boolean) – If True, logs a message for each successful status push.
verify (boolean) – Disable ssl verification for the case you use temporary self signed certificates.
debug (boolean) – Logs every requests and their response.
2.5.16.3. BitbucketServerPRCommentPush
from buildbot.plugins import reporters
ss = reporters.BitbucketServerPRCommentPush('https://bitbucket-server.example.com:8080/',
'bitbucket_server__username',
'secret_password')
c['services'].append(ss)
BitbucketServerPRCommentPush publishes a comment on a PR using Bitbucket Server REST API.
- class buildbot.reporters.bitbucketserver.BitbucketServerPRCommentPush(base_url, user, password, verbose=False, debug=None, verify=None, mode=('failing', 'passing', 'warnings'), tags=None, generators=None)
The following parameters are accepted by this reporter:
base_url(string) The base url of the Bitbucket server host.
user(string) The Bitbucket server user to post as. (can be a Secret)
password(string) The Bitbucket server user’s password. (can be a Secret)
generators(list) A list of instances of
IReportGeneratorwhich defines the conditions of when the messages will be sent and contents of them. See Report Generators for more information.verbose(boolean, defaults to
False) IfTrue, logs a message for each successful status push.debug(boolean, defaults to
False) IfTrue, logs every requests and their responseverify(boolean, defaults to
None) IfFalse, disables SSL verification for the case you use temporary self signed certificates. Default enables SSL verification.
Note
This reporter depends on the Bitbucket server hook to get the pull request url.
2.5.16.4. BitbucketServerStatusPush
from buildbot.plugins import reporters
ss = reporters.BitbucketServerStatusPush('https://bitbucketserver.example.com:8080/',
'bitbucketserver_username',
'secret_password')
c['services'].append(ss)
BitbucketServerStatusPush publishes build status using BitbucketServer Build Integration REST API.
The build status is published to a specific commit SHA in Bitbucket Server.
It tracks the last build for each builderName for each commit built.
Specifically, it follows the Updating build status for commits document.
It uses HTTP Basic AUTH. As a result, we recommend you use https in your base_url rather than http.
- class BitbucketServerStatusPush(base_url, user, password, key=None, statusName=None, generators=None, verbose=False)
- Parameters:
base_url (string) – The base url of the Bitbucket Server host, up to and optionally including the first / of the path.
user (string) – The Bitbucket Server user to post as. (can be a Secret)
password (string) – The Bitbucket Server user’s password. (can be a Secret)
key (renderable string) – Passed to Bitbucket Server to differentiate between statuses. A static string can be passed or
Interpolatefor dynamic substitution. The default key is %(prop:buildername)s.statusName (renderable string) – The name that is displayed for this status. The default name is nothing, so Bitbucket Server will use the
keyparameter.generators (list of IReportGenerator instances) – A list of report generators that will be used to generate reports to be sent by this reporter. Currently the reporter will consider only the report generated by the first generator.
verbose (boolean) – If True, logs a message for each successful status push.
verify (boolean) – Disable ssl verification for the case you use temporary self signed certificates
debug (boolean) – Logs every requests and their response
2.5.16.5. BitbucketStatusPush
from buildbot.plugins import reporters
c['services'].append(reporters.BitbucketStatusPush('oauth_key', 'oauth_secret'))
BitbucketStatusPush publishes build status using the Bitbucket Build Status API.
The build status is published to a specific commit SHA in Bitbucket.
By default, it tracks the last build for each builder and each commit built.
It uses OAuth 2.x to authenticate with Bitbucket. To enable this, you need to go to your Bitbucket Settings -> OAuth page. Click “Add consumer”. Give the new consumer a name, e.g. buildbot, and put in any URL as the callback (this is needed for Oauth 2.x, but it’s not used by this reporter), e.g. http://localhost:8010/callback. Give the consumer Repositories:Write access. After creating the consumer, you will then be able to see the OAuth key and secret.
- class buildbot.reporters.bitbucket.BitbucketStatusPush(oauth_key=None, oauth_secret=None, auth=None, base_url='https://api.bitbucket.org/2.0/repositories', oauth_url='https://bitbucket.org/site/oauth2/access_token', status_key=None, status_name=None, generators=None)
- Parameters:
oauth_key (string) – The OAuth consumer key, when using OAuth to authenticate (can be a Secret)
oauth_secret (string) – The OAuth consumer secret, when using OAuth to authenticate (can be a Secret)
auth (string) – The
username,passwordtuple if using App passwords to authenticate (can be a Secret)base_url (string) – Bitbucket’s Build Status API URL
oauth_url (string) – Bitbucket’s OAuth API URL
status_key (string) – Key that identifies a build status. Setting the key to a unique value per build allows to push multiple build statuses to a given commit. A static string can be passed or
Interpolatefor dynamic substitution. The default key is%(prop:buildername)sstatus_name (string) – Name of a build status. It shows up next to the status icon in Bitbucket. A static string can be passed or
Interpolatefor dynamic substitution. The default name is%(prop:buildername)sgenerators – A list of report generators that will be used to generate reports to be sent by this reporter. Currently the reporter will consider only the report generated by the first generator. The subject of the report will be used to set the description of the build status. The default subject is an empty string
verify (boolean) – Disable ssl verification for the case you use temporary self signed certificates
debug (boolean) – Logs every requests and their response
For example, the following reporter
from buildbot.plugins import reporters
reporters.BitbucketStatusPush(
'oauth_key', 'oauth_secret',
status_key=Interpolate("%(prop:buildername)s/%(prop:buildnumber)s"),
status_name=Interpolate("%(prop:buildername)s/%(prop:buildnumber)s"),
generators=[
reporters.BuildStartEndStatusGenerator(
start_formatter=reporters.MessageFormatter(subject="{{ status_detected }}"),
end_formatter=reporters.MessageFormatter(subject="{{ status_detected }}"))
])
c['services'].append(ss)
produces the build statuses below when a build stars and ends, respectively.

2.5.16.6. GerritStatusPush
GerritStatusPush sends review of the Change back to the Gerrit server, optionally also sending a message when a build is started.
GerritStatusPush can send a separate review for each build that completes, or a single review summarizing the results for all of the builds.
- class buildbot.reporters.status_gerrit.GerritStatusPush(server, username, reviewCB, startCB, port, reviewArg, startArg, summaryCB, summaryArg, identity_file, builders, notify...)
- Parameters:
server (string) – Gerrit SSH server’s address to use for push event notifications.
username (string) – Gerrit SSH server’s username.
identity_file – (optional) Gerrit SSH identity file.
port (int) – (optional) Gerrit SSH server’s port (default: 29418)
notify – (optional) Control who gets notified by Gerrit once the status is posted. The possible values for notify can be found in your version of the Gerrit documentation for the gerrit review command.
Note
By default, a single summary review is sent; that is, a default summaryCB is provided, but no reviewCB or startCB.
Note
If reviewCB or summaryCB do not return any labels, only a message will be pushed to the Gerrit server.
See also
master/docs/examples/git_gerrit.cfg and master/docs/examples/repo_gerrit.cfg in the Buildbot distribution provide a full example setup of Git+Gerrit or Repo+Gerrit of GerritStatusPush.
2.5.16.7. GerritVerifyStatusPush
- class buildbot.reporters.status_gerrit_verify_status.GerritVerifyStatusPush
GerritVerifyStatusPush sends a verify status to Gerrit using the verify-status Gerrit plugin.
It is an alternate method to GerritStatusPush, which uses the SSH API to send reviews.
The verify-status plugin allows several CI statuses to be sent for the same change, and display them separately in the Gerrit UI.
Most parameters are renderables.
- class buildbot.reporters.status_gerrit_verify_status.GerritVerifyStatusPush(baseURL, auth, verification_name=Interpolate('%(prop:buildername)s'), abstain=False, category=None, reporter=None, verbose=False, generators=None, **kwargs)
- Parameters:
baseURL (string) – Gerrit HTTP base URL
auth (string) – A requests authentication configuration. (can be a Secret). If Gerrit is configured with
BasicAuth, then it shall be('login', 'password'). If Gerrit is configured withDigestAuth, then it shall berequests.auth.HTTPDigestAuth('login', 'password')from the requests module.generators (list of IReportGenerator instances) – A list of report generators that will be used to generate reports to be sent by this reporter. Currently the reporter will consider only the report generated by the first generator.
verification_name (renderable string) – The name of the job displayed in the Gerrit UI
abstain (renderable boolean) – Whether this results should be counted as voting
category (renderable boolean) – Category of the build
reporter (renderable boolean) – The user that verified this build
verbose (boolean) – Whether to log every requests
verify (boolean) – Disable ssl verification for the case you use temporary self signed certificates
debug (boolean) – Logs every requests and their response
This reporter is integrated with GerritChangeSource, and will update changes detected by this change source.
This reporter can also send reports for changes triggered manually provided that there is a property in the build named gerrit_changes, containing the list of changes that were tested.
This property must be a list of dictionaries, containing change_id and revision_id keys, as defined in the revision endpoints of the Gerrit documentation.
2.5.16.8. GitHubCommentPush
from buildbot.plugins import reporters, util
context = Interpolate("bb/%(prop:buildername)s")
c['services'].append(reporters.GitHubCommentPush(token='githubAPIToken', context=context))
GitHubCommentPush publishes a comment on a GitHub PR using GitHub Review Comments API.
It requires a GitHub API token in order to operate. By default, the reporter will only comment at the end of a build unless a custom build report generator is supplied.
You can create a token from your own GitHub - Profile - Applications - Register new application or use an external tool to generate one.
- class buildbot.plugins.reporters.GitHubCommentPush(token, context=None, generators=None, baseURL=None, verbose=False)
- Parameters:
token (string) – Token used for authentication. (can be a Secret)
context (renderable string) – Passed to GitHub to differentiate between statuses. A static string can be passed or
Interpolatefor dynamic substitution. The default context isbuildbot/%(prop:buildername)s.generators (list of IReportGenerator instances) – A list of report generators that will be used to generate reports to be sent by this reporter. Currently the reporter will consider only the report generated by the first generator.
baseURL (string) – Specify the github API endpoint if you work with GitHub Enterprise
verbose (boolean) – If True, logs a message for each successful status push
Here’s a complete example of posting build results as a github comment:
@util.renderer
@defer.inlineCallbacks
def getresults(props):
all_logs=[]
master = props.master
steps = yield props.master.data.get(
('builders', props.getProperty('buildername'), 'builds',
props.getProperty('buildnumber'), 'steps'))
for step in steps:
if step['results'] == util.Results.index('failure'):
logs = yield master.data.get(("steps", step['stepid'], 'logs'))
for l in logs:
all_logs.append('Step : {0} Result : {1}'.format(
step['name'], util.Results[step['results']]))
all_logs.append('```')
l['stepname'] = step['name']
l['content'] = yield master.data.get(("logs", l['logid'], 'contents'))
step_logs = l['content']['content'].split('\n')
include = False
for i, sl in enumerate(step_logs):
all_logs.append(sl[1:])
all_logs.append('```')
return '\n'.join(all_logs)
generator = BuildStatusGenerator(message_formatter=MessageFormatterRenderable(getresults))
c['services'].append(GitHubCommentPush(token='githubAPIToken', generators=[generator]))
2.5.16.9. GitHubStatusPush
from buildbot.plugins import reporters, util
context = Interpolate("bb/%(prop:buildername)s")
c['services'].append(reporters.GitHubStatusPush(token='githubAPIToken', context=context))
GitHubStatusPush publishes a build status using the GitHub Status API.
It requires a GitHub API token in order to operate.
You can create a token from your own GitHub - Profile - Applications - Register new application or use an external tool to generate one.
- class buildbot.plugins.reporters.GitHubStatusPush(token, context=None, generators=None, baseURL=None, verbose=False)
- Parameters:
token (string) – Token used for authentication. (can be a Secret)
context (renderable string) – Passed to GitHub to differentiate between statuses. A static string can be passed or
Interpolatefor dynamic substitution. The default context isbuildbot/%(prop:buildername)s.generators (list of IReportGenerator instances) – A list of report generators that will be used to generate reports to be sent by this reporter. Currently the reporter will consider only the report generated by the first generator.
baseURL (string) – Specify the github api endpoint if you work with GitHub Enterprise
verbose (boolean) – If True, logs a message for each successful status push
2.5.16.10. GitLabStatusPush
from buildbot.plugins import reporters
gl = reporters.GitLabStatusPush('private-token', context='continuous-integration/buildbot',
baseURL='https://git.yourcompany.com')
c['services'].append(gl)
GitLabStatusPush publishes build status using GitLab Commit Status API.
The build status is published to a specific commit SHA in GitLab.
It uses private token auth, and the token owner is required to have at least developer access to each repository. As a result, we recommend you use https in your base_url rather than http.
- class buildbot.reporters.gitlab.GitLabStatusPush(token, context=None, baseURL=None, generators=None, verbose=False)
- Parameters:
token (string) – Private token of user permitted to update status for commits. (can be a Secret)
context (string) – Name of your build system, e.g. continuous-integration/buildbot
generators (list of IReportGenerator instances) – A list of report generators that will be used to generate reports to be sent by this reporter. Currently the reporter will consider only the report generated by the first generator.
baseURL (string) – The base url of the GitLab host, up to and optionally including the first / of the path. Do not include /api/
verbose (string) – Be more verbose
verify (boolean) – Disable ssl verification for the case you use temporary self signed certificates
debug (boolean) – Logs every requests and their response
2.5.16.11. HttpStatusPush
from buildbot.plugins import reporters
sp = reporters.HttpStatusPush(serverUrl="http://example.com/submit")
c['services'].append(sp)
HttpStatusPush sends HTTP POST requests to serverUrl.
The body of request contains json-encoded data of the build as returned by the data API.
It is useful to create a status front end outside of Buildbot for better scalability.
Note
The json data object sent is completely different from the one that was generated by 0.8.x buildbot. It is indeed generated using data api.
- class buildbot.reporters.HttpStatusPush(serverUrl, auth=None, headers=None, generators=None, debug=None, verify=None, cert=None, skip_encoding=False)
- Parameters:
serverUrl (string) – The url where to do the HTTP POST request
auth – The authentication method to use. Refer to the documentation of the requests library for more information.
headers (dict) – Pass custom headers to HTTP request.
generators (list of IReportGenerator instances) – A list of report generators that will be used to generate reports to be sent by this reporter. Currently the reporter will consider only the report generated by the first generator.
debug (boolean) – Logs every requests and their response
verify (boolean) – Disable ssl verification for the case you use temporary self signed certificates or path to a CA_BUNDLE file or directory. Refer to the documentation of the requests library for more information.
cert (string) – Path to client side certificate, as a single file (containing the private key and certificate) or a tuple of both files’ paths. Refer to the documentation of the requests library for more information.
skip_encoding (boolean) – Disables encoding of json data to bytes before pushing to server
Json object spec
The default json object sent is a build object augmented with some more data as follow.
{
"url": "http://yourbot/path/to/build",
"<build data api values>": "[...]",
"buildset": "<buildset data api values>",
"builder": "<builder data api values>",
"buildrequest": "<buildrequest data api values>"
}
If you want another format, don’t hesitate to use the format_fn parameter to customize the payload.
The build parameter given to that function is of type build, optionally enhanced with properties, steps, and logs information.
2.5.16.12. IRC Bot
- class buildbot.reporters.irc.IRC
The IRC reporter creates an IRC bot which will attach to certain channels and be
available for status queries. It can also be asked to announce builds as they occur, or be told to
shut up.
The IRC Bot in buildbot nine, is mostly a rewrite, and not all functionality has been ported yet. Patches are very welcome for restoring the full functionality.
from buildbot.plugins import reporters
irc = reporters.IRC("irc.example.org", "botnickname",
useColors=False,
channels=[{"channel": "#example1"},
{"channel": "#example2",
"password": "somesecretpassword"}],
password="mysecretnickservpassword",
authz={('force', 'stop'): "authorizednick"}
notify_events=[
'exception',
'problem',
'recovery',
'worker'
])
c['services'].append(irc)
The following parameters are accepted by this class:
host(mandatory) The IRC server address to connect to.
nick(mandatory) The name this bot will use on the IRC server.
channels(mandatory) This is a list of channels to join on the IRC server. Each channel can be a string (e.g.
#buildbot), or a dictionary{'channel': '#buildbot', 'password': 'secret'}if each channel requires a different password. A global password can be set with thepasswordparameter.pm_to_nicks(optional) This is a list of person to contact on the IRC server.
authz(optional) Authentication list for commands. It must be a dictionary with command names or tuples of command names as keys. There are two special command names:
''(empty string) meaning any harmless command and'!'for dangerous commands (currentlyforce,stop, andshutdown). The dictionary values are eitherTrueofFalse(which allows or deny commands for everybody) or a list of nicknames authorized to issue specified commands. By default, harmless commands are allowed for everybody and the dangerous ones are prohibited.A sample
authzparameter may look as follows:authz={ 'version': True, '': ['alice', 'bob'], ('force', 'stop'): ['alice'], }
Anybody will be able to run the
versioncommand, alice and bob will be allowed to run any safe command and alice will also have the right to force and stop builds.This parameter replaces older
allowForceandallowShutdown, which are deprecated as they were considered a security risk.Note
The authorization is purely nick-based, so it only makes sense if the specified nicks are registered to the IRC server.
port(optional, default to 6667) The port to connect to on the IRC server.
tags(optional) When set, this bot will only communicate about builders containing those tags. (tags functionality is not yet ported)
password(optional) The global password used to register the bot to the IRC server. If provided, it will be sent to Nickserv to claim the nickname: some IRC servers will not allow clients to send private messages until they have logged in with a password. Can be a Secret.
notify_events(optional) A list or set of events to be notified on the IRC channels. Available events to be notified are:
startedA build has started.
finishedA build has finished.
successA build finished successfully.
failureA build failed.
exceptionA build generated and exception.
cancelledA build was cancelled.
problemThe previous build result was success or warnings, but this one ended with failure or exception.
recoveryThis is the opposite of
problem: the previous build result was failure or exception and this one ended with success or warnings.worseA build state was worse than the previous one (so e.g. it ended with warnings and the previous one was successful).
betterA build state was better than the previous one.
workerA worker is missing. A notification is also send when the previously reported missing worker connects again.
This parameter can be changed during run-time by sending the notify command to the bot. Note
however, that at the buildbot restart or reconfig the notifications listed here will be turned on
for the specified channel and nicks. On the other hand, removing events from this parameters will
not automatically stop notifications for them (you need to turn them off for every channel with the
notify command).
noticeOnChannel(optional, disabled by default) Whether to send notices rather than messages when communicating with a channel.
showBlameList(optional, disabled by default) Whether or not to display the blame list for failed builds. (blame list functionality is not ported yet)
useRevisions(optional, disabled by default) Whether or not to display the revision leading to the build the messages are about. (useRevisions functionality is not ported yet)
useSSL(optional, disabled by default) Whether or not to use SSL when connecting to the IRC server. Note that this option requires PyOpenSSL.
lostDelay(optional) Delay to wait before reconnecting to the server when the connection has been lost.
failedDelay(optional) Delay to wait before reconnecting to the IRC server when the connection failed.
useColors(optional, enabled by default) The bot can add color to some of its messages. You might turn it off by setting this parameter to
False.
The following parameters are deprecated. You must not use them if you use the new authz parameter.
Note
Security Note
Please note that any user having access to your irc channel or can PM the bot will be able to
create or stop builds bug #3377. Use authz to give explicit list of nicks who are allowed
to do this.
allowForce(deprecated, disabled by default) This allow all users to force and stop builds via this bot.
allowShutdown(deprecated, disabled by default) This allow all users to shutdown the master.
To use the service, you address messages at the Buildbot, either normally (botnickname: status)
or with private messages (/msg botnickname status). The Buildbot will respond in kind.
If you issue a command that is currently not available, the Buildbot will respond with an error
message. If the noticeOnChannel=True option was used, error messages will be sent as channel
notices instead of messaging.
Some of the commands currently available:
list buildersEmit a list of all configured builders
status BUILDERAnnounce the status of a specific Builder: what it is doing right now.
status allAnnounce the status of all Builders
watch BUILDER
If the given
Builderis currently running, wait until theBuildis finished and then announce the results.
last BUILDERReturn the results of the last build to run on the given
Builder.
notify on|off|list EVENT
Report events relating to builds. If the command is issued as a private message, then the report will be sent back as a private message to the user who issued the command. Otherwise, the report will be sent to the channel. Available events to be notified are:
startedA build has started.
finishedA build has finished.
successA build finished successfully.
failureA build failed.
exceptionA build generated and exception.
cancelledA build was cancelled.
problemThe previous build result was success or warnings, but this one ended with failure or exception.
recoveryThis is the opposite of
problem: the previous build result was failure or exception and this one ended with success or warnings.
worseA build state was worse than the previous one (so e.g. it ended with warnings and the previous one was successful).
betterA build state was better than the previous one.
workerA worker is missing. A notification is also send when the previously reported missing worker connects again.
By default, this command can be executed by anybody. However, consider limiting it with
authz, as enabling notifications in huge number of channels or private chats can cause some problems with your buildbot efficiency.
help COMMANDDescribe a command. Use help commands to get a list of known commands.
sourceAnnounce the URL of the Buildbot’s home page.
versionAnnounce the version of this Buildbot.
Additionally, the config file may specify default notification options as shown in the example earlier.
If explicitly allowed in the authz config, some additional commands will be available:
join CHANNELJoin the given IRC channel
leave CHANNELLeave the given IRC channel
force build [--codebase=CODEBASE] [--branch=BRANCH] [--revision=REVISION] [--props=PROP1=VAL1,PROP2=VAL2...] BUILDER REASONTell the given
Builderto start a build of the latest code. The user requesting the build and REASON are recorded in theBuildstatus. The Buildbot will announce the build’s status when it finishes.The user can specify a branch and/or revision with the optional parameters--branch=BRANCHand--revision=REVISION. The user can also give a list of properties with--props=PROP1=VAL1,PROP2=VAL2...stop build BUILDER REASONTerminate any running build in the given
Builder. REASON will be added to the build status to explain why it was stopped. You might use this if you committed a bug, corrected it right away, and don’t want to wait for the first build (which is destined to fail) to complete before starting the second (hopefully fixed) build.shutdown ARGControl the shutdown process of the Buildbot master. Available arguments are:
checkCheck if the Buildbot master is running or shutting down
startStart clean shutdown
stopStop clean shutdown
nowShutdown immediately without waiting for the builders to finish
If the tags is set (see the tags option in Builder Configuration) changes related to only builders belonging to those tags of builders will be sent to the channel.
If the useRevisions option is set to True, the IRC bot will send status messages that replace the build number with a list of revisions that are contained in that build. So instead of seeing build #253 of …, you would see something like build containing revisions [a87b2c4]. Revisions that are stored as hashes are shortened to 7 characters in length, as multiple revisions can be contained in one build and may exceed the IRC message length limit.
Two additional arguments can be set to control how fast the IRC bot tries to reconnect when it
encounters connection issues. lostDelay is the number of seconds the bot will wait to reconnect
when the connection is lost, where as failedDelay is the number of seconds until the bot tries
to reconnect when the connection failed. lostDelay defaults to a random number between 1 and 5,
while failedDelay defaults to a random one between 45 and 60. Setting random defaults like this
means multiple IRC bots are less likely to deny each other by flooding the server.
2.5.16.13. MailNotifier
- class buildbot.reporters.mail.MailNotifier
Buildbot can send emails when builds finish. The most common use of this is to tell developers when their change has caused the build to fail. It is also quite common to send a message to a mailing list (usually named builds or similar) about every build.
The MailNotifier reporter is used to accomplish this.
You configure it by specifying who should receive mail, under what circumstances mail should be sent, and how to deliver the mail.
It can be configured to only send out mail for certain builders, and only send them when a build fails or when the builder transitions from success to failure.
It can also be configured to include various build logs in each message.
If a proper lookup function is configured, the message will be sent to the “interested users” list (Doing Things With Users), which includes all developers who made changes in the build.
By default, however, Buildbot does not know how to construct an email address based on the information from the version control system.
See the lookup argument, below, for more information.
You can add additional, statically-configured, recipients with the extraRecipients argument.
You can also add interested users by setting the owners build property to a list of users in the scheduler constructor (Configuring Schedulers).
Each MailNotifier sends mail to a single set of recipients.
To send different kinds of mail to different recipients, use multiple MailNotifiers.
TODO: or subclass MailNotifier and override getRecipients()
The following simple example will send an email upon the completion of each build, to just those developers whose Changes were included in the build.
The email contains a description of the Build, its results, and URLs where more information can be obtained.
from buildbot.plugins import reporters
mn = reporters.MailNotifier(fromaddr="buildbot@example.org",
lookup="example.org")
c['services'].append(mn)
To get a simple one-message-per-build (say, for a mailing list), use the following form instead.
This form does not send mail to individual developers (and thus does not need the lookup= argument, explained below); instead it only ever sends mail to the extra recipients named in the arguments:
mn = reporters.MailNotifier(fromaddr="buildbot@example.org",
sendToInterestedUsers=False,
extraRecipients=['listaddr@example.org'])
If your SMTP host requires authentication before it allows you to send emails, this can also be done by specifying smtpUser and smtpPassword:
mn = reporters.MailNotifier(fromaddr="myuser@example.com",
sendToInterestedUsers=False,
extraRecipients=["listaddr@example.org"],
relayhost="smtp.example.com", smtpPort=587,
smtpUser="myuser@example.com",
smtpPassword="mypassword")
Note
If for some reasons you are not able to send a notification with TLS enabled and specified user name and password, you might want to use master/contrib/check_smtp.py to see if it works at all.
If you want to require Transport Layer Security (TLS), then you can also set useTls:
mn = reporters.MailNotifier(fromaddr="myuser@example.com",
sendToInterestedUsers=False,
extraRecipients=["listaddr@example.org"],
useTls=True, relayhost="smtp.example.com",
smtpPort=587, smtpUser="myuser@example.com",
smtpPassword="mypassword")
Note
If you see twisted.mail.smtp.TLSRequiredError exceptions in the log while using TLS, this can be due either to the server not supporting TLS or a missing PyOpenSSL package on the BuildMaster system.
In some cases, it is desirable to have different information than what is provided in a standard MailNotifier message.
For this purpose, MailNotifier provides the argument messageFormatter (an instance of MessageFormatter), which allows for creating messages with unique content.
For example, if only short emails are desired (e.g., for delivery to phones):
from buildbot.plugins import reporters
generator = reporters.BuildStatusGenerator(
mode=('problem',),
message_formatter=reporters.MessageFormatter(template="STATUS: {{ summary }}"))
mn = reporters.MailNotifier(fromaddr="buildbot@example.org",
sendToInterestedUsers=False,
extraRecipients=['listaddr@example.org'],
generators=[generator])
Another example of a function delivering a customized HTML email is given below:
from buildbot.plugins import reporters
template=u'''\
<h4>Build status: {{ summary }}</h4>
<p> Worker used: {{ workername }}</p>
{% for step in build['steps'] %}
<p> {{ step['name'] }}: {{ step['results'] }}</p>
{% endfor %}
<p><b> -- Buildbot</b></p>
'''
generator = reporters.BuildStatusGenerator(
mode=('failing',),
message_formatter=reporters.MessageFormatter(
template=template, template_type='html',
want_properties=True, want_steps=True))
mn = reporters.MailNotifier(fromaddr="buildbot@example.org",
sendToInterestedUsers=False,
mode=('failing',),
extraRecipients=['listaddr@example.org'],
generators=[generator])
MailNotifier arguments
fromaddrThe email address to be used in the ‘From’ header.
sendToInterestedUsers(boolean). If
True(the default), send mail to all of the Interested Users. Interested Users are authors of changes and users from theownersbuild property. OverrideMailNotifiergetResponsibleUsersForBuildmethod to change that. IfFalse, only send mail to theextraRecipientslist.extraRecipients(list of strings). A list of email addresses to which messages should be sent (in addition to the InterestedUsers list, which includes any developers who made
Changes that went into this build). It is a good idea to create a small mailing list and deliver to that, then let subscribers come and go as they please.generators(list). A list of instances of
IReportGeneratorwhich defines the conditions of when the messages will be sent and contents of them. See Report Generators for more information.relayhost(string, deprecated). The host to which the outbound SMTP connection should be made. Defaults to ‘localhost’
smtpPort(int). The port that will be used on outbound SMTP connections. Defaults to 25.
useTls(boolean). When this argument is
True(default isFalse),MailNotifierrequires that STARTTLS encryption is used for the connection with therelayhost. Authentication is required for STARTTLS so the argumentssmtpUserandsmtpPasswordmust also be specified.useSmtps(boolean). When this argument is
True(default isFalse),MailNotifierconnects torelayhostover an encrypted SSL/TLS connection. This configuration is typically used over port 465.smtpUser(string). The user name to use when authenticating with the
relayhost. Can be a Secret.smtpPassword(string). The password that will be used when authenticating with the
relayhost. Can be a Secret.lookup(implementer of
IEmailLookup). Object which providesIEmailLookup, which is responsible for mapping User names (which come from the VC system) into valid email addresses.If the argument is not provided, the
MailNotifierwill attempt to build thesendToInterestedUsersfrom the authors of the Changes that led to the Build via User Objects. If the author of one of the Build’s Changes has an email address stored, it will added to the recipients list. With this method,ownersare still added to the recipients. Note that, in the current implementation of user objects, email addresses are not stored; as a result, unless you have specifically added email addresses to the user database, this functionality is unlikely to actually send any emails.Most of the time you can use a simple Domain instance. As a shortcut, you can pass as string: this will be treated as if you had provided
Domain(str). For example,lookup='example.com'will allow mail to be sent to all developers whose SVN usernames match theirexample.comaccount names. See master/buildbot/reporters/mail.py for more details.Regardless of the setting of
lookup,MailNotifierwill also send mail to addresses in theextraRecipientslist.extraHeaders(dictionary). A dictionary containing key/value pairs of extra headers to add to sent e-mails. Both the keys and the values may be an Interpolate instance.
watchedWorkersThis is a list of names of workers, which should be watched. In case a worker goes missing, a notification is sent. The value of
watchedWorkerscan also be set to all (default) orNone. You also need to specify an email address to which the notification is sent in the worker configuration.dumpMailsToLogIf set to
True, all completely formatted mails will be dumped to the log before being sent. This can be useful to debug problems with your mail provider. Be sure to only turn this on if you really need it, especially if you attach logs to emails. This can dump sensitive information to logs and make them very large.
2.5.16.14. PushjetNotifier
- class buildbot.reporters.pushover.PushjetNotifier
Pushjet is another instant notification service, similar to PushoverNotifier.
To use this reporter, you need to generate a Pushjet service and provide its secret.
The following parameters are accepted by this class:
generators(list) A list of instances of
IReportGeneratorwhich defines the conditions of when the messages will be sent and contents of them. See Report Generators for more information.secretThis is a secret token for your Pushjet service. See http://docs.pushjet.io/docs/creating-a-new-service to learn how to create a new Pushjet service and get its secret token. Can be a Secret.
levelsDictionary of Pushjet notification levels. The keys of the dictionary can be
change,failing,passing,warnings,exceptionand are equivalent to themodestrings. The values are integers between 0…5, specifying notification priority. In case a mode is missing from this dictionary, the default value set by Pushover is used.base_urlBase URL for custom Pushjet instances. Defaults to https://api.pushjet.io.
2.5.16.15. PushoverNotifier
- class buildbot.reporters.pushover.PushoverNotifier
Apart of sending mail, Buildbot can send Pushover notifications. It can be used by administrators to receive an instant message to an iPhone or an Android device if a build fails. The PushoverNotifier reporter is used to accomplish this. Its configuration is very similar to the mail notifications, however—due to the notification size constrains—the logs and patches cannot be attached.
To use this reporter, you need to generate an application on the Pushover website https://pushover.net/apps/ and provide your user key and the API token.
The following simple example will send a Pushover notification upon the completion of each build.
The notification contains a description of the Build, its results, and URLs where more information can be obtained. The user_key and api_token values should be replaced with proper ones obtained from the Pushover website for your application.
from buildbot.plugins import reporters
pn = reporters.PushoverNotifier(user_key="1234", api_token='abcd')
c['services'].append(pn)
The following parameters are accepted by this class:
generators(list) A list of instances of
IReportGeneratorwhich defines the conditions of when the messages will be sent and contents of them. See Report Generators for more information.user_keyThe user key from the Pushover website. It is used to identify the notification recipient. Can be a Secret.
api_tokenAPI token for a custom application from the Pushover website. Can be a Secret.
prioritiesDictionary of Pushover notification priorities. The keys of the dictionary can be
change,failing,passing,warnings,exceptionand are equivalent to themodestrings. The values are integers between -2…2, specifying notification priority. In case a mode is missing from this dictionary, the default value of 0 is used.otherParamsOther parameters send to Pushover API. Check https://pushover.net/api/ for their list.
2.5.16.16. Telegram Bot
Buildbot offers a bot, similar to the IRC for Telegram mobile and desktop messaging
app. The bot can notify users and groups about build events, respond to status queries, or force
and stop builds on request (if allowed to).
In order to use this reporter, you must first speak to BotFather and create a new telegram bot. A quick step-by-step procedure is as follows:
Start a chat with BotFather.
Type
/newbot.Enter a display name for your bot. It can be any string.
4. Enter a unique username for your bot. Usernames are 5-32 characters long and are case insensitive, but may only include Latin characters, numbers, and underscores. Your bot’s username must end in bot, e.g. MyBuildBot or MyBuildbotBot.
5. You will be presented with a token for your bot. Save it, as you will need it for
TelegramBot configuration.
Optionally, you may type
/setcommands, select the username of your new bot and paste the following text:commands - list available commands force - force a build getid - get user and chat ID hello - say hello help - give help for a command or one of it's arguments last - list last build status for a builder list - list configured builders or workers nay - forget the current command notify - notify me about build events shutdown - shutdown the buildbot master source - the source code for buildbot status - list status of a builder (or all builders) stop - stop a running build version - show buildbot version watch - announce the completion of an active build
If you do this, Telegram will provide hints about your bot commands.
If you want, you can set a custom picture and description for your bot.
After setting up the bot in Telegram, you should configure it in Buildbot.
from buildbot.plugins import reporters
telegram = reporters.TelegramBot(
bot_token='bot_token_given_by_botfather',
bot_username'username_set_in_botfather_bot',
chat_ids=[-1234567],
authz={('force', 'stop'): "authorizednick"}
notify_events=[
'exception',
'problem',
'recovery',
'worker'
],
usePolling=True)
c['services'].append(telegram)
The following parameters are accepted by this class:
bot_token(mandatory) Bot token given by BotFather.
bot_username(optional) This should be set to the bot unique username defined in BotFather. If this parameter is missing, it will be retrieved from the Telegram server. However, in case of the connection problems, configuration of the Buildbot will be interrupted. For this reason it is advised to set this parameter to the correct value.
chat_ids(optional) List of chats IDs to send notifications specified in the
notify_eventsparameter. For channels it should have form@channelusernameand for private chats and groups it should be a numeric ID. To get it, talk to your bot or add it to a Telegram group and issue/getidcommand.
Note
In order to receive notification from the bot, you need to talk to it first (and hit the
/start button) or add it to the group chat.
authz(optional) Authentication list for commands. It must be a dictionary with command names (without slashes) or tuples of command names as keys. There are two special command names:
''(empty string) meaning any harmless command and'!'for dangerous commands (currently/force,/stop, and/shutdown). The dictionary values are eitherTrueofFalse(which allows or deny commands for everybody) or a list of numeric IDs authorized to issue specified commands. By default, harmless commands are allowed for everybody and the dangerous ones are prohibited.A sample
authzparameter may look as follows:authz={ 'getid': True, '': [123456, 789012], ('force', 'stop'): [123456], }
Anybody will be able to run the
getidcommand, users with IDs 123456 and 789012 will be allowed to run any safe command and the user with ID 123456 will also have the right to force and stop builds.tags(optional) When set, this bot will only communicate about builders containing those tags. (tags functionality is not yet implemented)
notify_events(optional) A list or set of events to be notified on the Telegram chats. Telegram bot can listen to build ‘start’ and ‘finish’ events. It can also notify about missing workers and their return. This parameter can be changed during run-time by sending the
/notifycommand to the bot. Note however, that at the buildbot restart or reconfig the notifications listed here will be turned on for the specified chats. On the other hand, removing events from this parameters will not automatically stop notifications for them (you need to turn them off for every channel with the/notifycommand).showBlameList(optional, disabled by default) Whether or not to display the blame list for failed builds. (blame list functionality is not yet implemented)
useRevisions(optional, disabled by default) Whether or not to display the revision leading to the build the messages are about. (useRevisions functionality is not yet implemented)
useWebhook(optional, disabled by default) By default this bot receives messages from Telegram through polling. You can configure it to use a web-hook, which may be more efficient. However, this requires the web frontend of the Buildbot to be configured and accessible through HTTPS (not HTTP) on a public IP and port number 443, 80, 88, or 8443. Furthermore, the Buildbot configuration option
buildbotURLmust be correctly set. If you are using HTTP authentication, please ensure that the location buildbotURL/telegrambot_token (e.g.https://buildbot.example.com/telegram123456:secret) is accessible by everybody.certificate(optional) A content of your server SSL certificate. This is necessary if the access to the Buildbot web interface is through HTTPS protocol with self-signed certificate and
userWebhookis set toTrue.pollTimeout(optional) The time the bot should wait for Telegram to respond to polling using long polling.
retryDelay(optional) The delay the bot should wait before attempting to retry communication in case of no connection.
To use the service, you sent Telegram commands (messages starting with a slash) to the bot. In most cases you do not need to add any parameters; the bot will ask you about the details.
Some of the commands currently available:
/getidGet ID of the user and group. This is useful to find the numeric IDs, which should be put in
authzandchat_idsconfiguration parameters./listEmit a list of all configured builders, workers or recent changes.
/statusAnnounce the status of all builders.
/watchYou will be presented with a list of builders that are currently running. You can select any of them to be notified when the build finishes..
/lastReturn the results of the last builds on every builder.
/notifyReport events relating to builds. If the command is issued as a private message, then the report will be sent back as a private message to the user who issued the command. Otherwise, the report will be sent to the group chat. Available events to be notified are:
startedA build has started.
finishedA build has finished.
successA build finished successfully.
failureA build failed.
exceptionA build generated and exception.
cancelledA build was cancelled.
problemThe previous build result was success or warnings, but this one ended with failure or exception.
recoveryThis is the opposite of
problem: the previous build result was failure or exception and this one ended with success or warnings.worseA build state was worse than the previous one (so e.g. it ended with warnings and the previous one was successful).
betterA build state was better than the previous one.
workerA worker is missing. A notification is also send when the previously reported missing worker connects again.
By default this command can be executed by anybody. However, consider limiting it with
authz, as enabling notifications in huge number of chats (of any kind) can cause some problems with your buildbot efficiency./helpShow short help for the commands.
/commandsList all available commands. If you explicitly type
/commands botfather, the bot will respond with a list of commands with short descriptions, to be provided to BotFather./sourceAnnounce the URL of the Buildbot’s home page.
/versionAnnounce the version of this Buildbot.
If explicitly allowed in the authz config, some additional commands will be available:
/forceForce a build. The bot will read configuration from every configured
ForceSchedulerand present you with the build parameters you can change. If you set all the required parameters, you will be given an option to start the build./stopStop a build. If there are any active builds, you will be presented with options to stop them.
/shutdownControl the shutdown process of the Buildbot master. You will be presented with options to start a graceful shutdown, stop it or to shutdown immediately.
If you are in the middle of the conversation with the bot (e.g. it has just asked you a question),
you can always stop the current command with a command /nay.
If the tags is set (see the tags option in Builder Configuration) changes related to only builders belonging to those tags of builders will be sent to the channel.
If the useRevisions option is set to True, the IRC bot will send status messages that replace the build number with a list of revisions that are contained in that build. So instead of seeing build #253 of …, you would see something like build containing revisions a87b2c4. Revisions that are stored as hashes are shortened to 7 characters in length, as multiple revisions can be contained in one build and may result in too long messages.
2.5.16.17. ZulipStatusPush
from buildbot.plugins import reporters
zs = reporters.ZulipStatusPush(endpoint='your-organization@zulipchat.com',
token='private-token', stream='stream_to_post_in')
c['services'].append(zs)
ZulipStatusPush sends build status using The Zulip API.
The build status is sent to a user as a private message or in a stream in Zulip.
- class buildbot.reporters.zulip.ZulipStatusPush(endpoint, token, stream=None)
- Parameters:
endpoint (string) – URL of your Zulip server
token (string) – Private API token
stream (string) – The stream in which the build status is to be sent. Defaults to None
Note
A private message is sent if stream is set to None.
Json object spec
The json object sent contains the following build status values.
{
"event": "new/finished",
"buildid": "<buildid>",
"buildername": "<builder name>",
"url": "<URL to the build>",
"project": "name of the project",
"timestamp": "<timestamp at start/finish>"
}
The Buildmaster has a variety of ways to present build status to various users.
Each such delivery method is a Reporter Target object in the configuration’s services list.
To add reporter targets, you just append more objects to this list:
c['services'] = []
m = reporters.MailNotifier(fromaddr="buildbot@localhost",
extraRecipients=["builds@lists.example.com"],
sendToInterestedUsers=False)
c['services'].append(m)
c['services'].append(reporters.irc.IRC(host="irc.example.com", nick="bb",
channels=[{"channel": "#example1"},
{"channel": "#example2",
"password": "somesecretpassword"}]))
Most reporter objects take a tags= argument, which can contain a list of tag names.
In this case, the reporters will only show status for Builders that contain the named tags.
Note
Implementation Note
Each of these objects should be a service.BuildbotService which will be attached to the BuildMaster object when the configuration is processed.
The following reporters are available:
Most of the report generators derive from ReporterBase which implements basic reporter management functionality.
2.5.17. Web Server
Note
As of Buildbot 0.9.0, the built-in web server replaces the old WebStatus plugin.
Buildbot contains a built-in web server.
This server is configured with the www configuration key, which specifies a dictionary with the following keys:
portThe TCP port on which to serve requests. It might be an integer or any string accepted by serverFromString (ex: “tcp:8010:interface=127.0.0.1” to listen on another interface). Note that using twisted’s SSL endpoint is discouraged. Use a reverse proxy that offers proper SSL hardening instead (see Reverse Proxy Configuration). If this is
None(the default), then the master will not implement a web server.json_cache_secondsThe number of seconds into the future at which an HTTP API response should expire.
rest_minimum_versionThe minimum supported REST API version. Any versions less than this value will not be available. This can be used to ensure that no clients are depending on API versions that will soon be removed from Buildbot.
pluginsThis key gives a dictionary of additional UI plugins to load, along with configuration for those plugins. These plugins must be separately installed in the Python environment, e.g.,
pip install buildbot-waterfall-view. See UI plugins. For example:c['www'] = { 'plugins': {'waterfall_view': True} }
default_pageConfigure the default landing page of the web server, for example, to forward directly to another plugin. For example:
c['www']['default_page'] = 'console'
debugIf true, then debugging information will be output to the browser. This is best set to false (the default) on production systems, to avoid the possibility of information leakage.
allowed_originsThis gives a list of origins which are allowed to access the Buildbot API (including control via JSONRPC 2.0). It implements cross-origin request sharing (CORS), allowing pages at origins other than the Buildbot UI to use the API. Each origin is interpreted as filename match expression, with
?matching one character and*matching anything. Thus['*']will match all origins, and['https://*.buildbot.net']will match secure sites underbuildbot.net. The Buildbot UI will operate correctly without this parameter; it is only useful for allowing access from other web applications.authAuthentication module to use for the web server. See Authentication plugins.
avatar_methodsList of methods that can be used to get avatar pictures to use for the web server. By default, Buildbot uses Gravatar to get images associated with each users, if you want to disable this you can just specify empty list:
c['www'] = { 'avatar_methods': [] }
You could also use the GitHub user avatar if GitHub authentication is enabled:
c['www'] = { 'avatar_methods': [util.AvatarGitHub()] }
- class AvatarGitHub(github_api_endpoint=None, token=None, debug=False, verify=True)
- Parameters:
github_api_endpoint (string) – specify the github api endpoint if you work with GitHub Enterprise
token (string) – a GitHub API token to execute all requests to the API authenticated. It is strongly recommended to use a API token since it increases GitHub API rate limits significantly
client_id (string) – a GitHub OAuth client ID to use with client secret to execute all requests to the API authenticated in place of token
client_secret (string) – a GitHub OAuth client secret to use with client ID above
debug (boolean) – logs every requests and their response
verify (boolean) – disable ssl verification for the case you use temporary self signed certificates on a GitHub Enterprise installation
This class requires txrequests package to allow interaction with GitHub REST API.
For use of corporate pictures, you can use LdapUserInfo, which can also act as an avatar provider. See Authentication plugins.
logfileNameFilename used for HTTP access logs, relative to the master directory. If set to
Noneor the empty string, the content of the logs will land in the maintwisted.loglog file. (Defaults tohttp.log)logRotateLengthThe amount of bytes after which the
http.logfile will be rotated. (Defaults to the same value as for thetwisted.logfile, set inbuildbot.tac)maxRotatedFilesThe amount of log files that will be kept when rotating (Defaults to the same value as for the
twisted.logfile, set inbuildbot.tac)versionsCustom component versions that you’d like to display on the About page. Buildbot will automatically prepend the versions of Python, twisted and Buildbot itself to the list.
versionsshould be a list of tuples. For example:c['www'] = { # ... 'versions': [ ('master.cfg', '0.1'), ('OS', 'Ubuntu 14.04'), ] }
The first element of a tuple stands for the name of the component, the second stands for the corresponding version.
custom_templates_dirThis directory will be parsed for custom angularJS templates to replace the one of the original website templates. You can use this to slightly customize buildbot look for your project, but to add any logic, you will need to create a full-blown plugin. If the directory string is relative, it will be joined to the master’s basedir. Buildbot uses the jade file format natively (which has been renamed to ‘pug’ in the nodejs ecosystem), but you can also use HTML format if you prefer.
Either
*.jadefiles or*.htmlfiles can be used to override templates with the same name in the UI. On the regular nodejs UI build system, we use nodejs’s pug module to compile jade into html. For custom_templates, we use the pypugjs interpreter to parse the jade templates, before sending them to the UI.pip install pypugjsis required to use jade templates. You can also override plugin’s directives, but they have to be in another directory, corresponding to the plugin’s name in itspackage.json. For example:# replace the template whose source is in: # www/base/src/app/builders/build/build.tpl.jade build.jade # here we use a jade (aka pug) file # replace the template whose source is in # www/console_view/src/module/view/builders-header/console.tpl.jade console_view/console.html # here we use html format
Known differences between nodejs’s pug and pyjade:
quotes in attributes are not quoted (https://github.com/syrusakbary/pyjade/issues/132). This means you should use double quotes for attributes, e.g.:
tr(ng-repeat="br in buildrequests | orderBy:'-submitted_at'")pypugjs may have some differences but it is a maintained fork of pyjade. https://github.com/kakulukia/pypugjs
change_hook_dialectsSee Change Hooks.
cookie_expiration_time
This allows to define the timeout of the session cookie. Should be a datetime.timedelta. Default is one week.
import datetime c['www'] = { # ... 'cookie_expiration_time': datetime.timedelta(weeks=2) }
ui_default_config
Settings in the settings page are stored per browser. This configuration parameter allows to override the default settings for all your users. If a user already has changed a value from the default, this will have no effect to them. The settings page in the UI will tell you what to insert in your master.cfg to reproduce the configuration you have in your own browser. For example:
c['www']['ui_default_config'] = { 'Builders.buildFetchLimit': 500, 'Workers.showWorkerBuilders': True, }
ws_ping_interval
Send websocket pings every
ws_ping_intervalseconds. This is useful to avoid websocket timeouts when using reverse proxies or CDNs. If the value is 0 (the default), pings are disabled.
theme
Allows configuring certain properties of the web frontend, such as colors. The configuration value is a dictionary. The keys correspond to certain CSS variable names that are used throughout web frontend and made configurable. The values correspond to CSS values of these variables.
The keys and values are not sanitized, so using data derived from user-supplied information is a security risk.
The default is the following:
c["www"]["theme"] = { "bb-sidebar-background-color": "#30426a", "bb-sidebar-header-background-color": "#273759", "bb-sidebar-header-text-color": "#fff", "bb-sidebar-title-text-color": "#627cb7", "bb-sidebar-footer-background-color": "#273759", "bb-sidebar-button-text-color": "#b2bfdc", "bb-sidebar-button-hover-background-color": "#1b263d", "bb-sidebar-button-hover-text-color": "#fff", "bb-sidebar-button-current-background-color": "#273759", "bb-sidebar-button-current-text-color": "#b2bfdc", "bb-sidebar-stripe-hover-color": "#e99d1a", "bb-sidebar-stripe-current-color": "#8c5e10", }
Note
The buildbotURL configuration value gives the base URL that all masters will use to generate links.
The www configuration gives the settings for the webserver.
In simple cases, the buildbotURL contains the hostname and port of the master, e.g., http://master.example.com:8010/.
In more complex cases, with multiple masters, web proxies, or load balancers, the correspondence may be less obvious.
2.5.17.1. UI plugins
Waterfall View
Waterfall shows the whole Buildbot activity in a vertical time line. Builds are represented with boxes whose height vary according to their duration. Builds are sorted by builders in the horizontal axes, which allows you to see how builders are scheduled together.
pip install buildbot-waterfall-viewc['www'] = { 'plugins': {'waterfall_view': True} }
Note
Waterfall is the emblematic view of Buildbot Eight. It allowed to see the whole Buildbot activity very quickly. Waterfall however had big scalability issues, and larger installs had to disable the page in order to avoid tens of seconds master hang because of a big waterfall page rendering. The whole Buildbot Eight internal status API has been tailored in order to make Waterfall possible. This is not the case anymore with Buildbot Nine, which has a more generic and scalable Data API and REST API. This is the reason why Waterfall does not display the steps details anymore. However nothing is impossible. We could make a specific REST api available to generate all the data needed for waterfall on the server. Please step-in if you want to help improve the Waterfall view.
Console View
Console view shows the whole Buildbot activity arranged by changes as discovered by Change Sources and Changes vertically and builders horizontally.
If a builder has no build in the current time range, it will not be displayed.
If no change is available for a build, then it will generate a fake change according to the got_revision property.
Console view will also group the builders by tags. When there are several tags defined per builders, it will first group the builders by the tag that is defined for most builders. Then given those builders, it will group them again in another tag cluster. In order to keep the UI usable, you have to keep your tags short!
pip install buildbot-console-viewc['www'] = { 'plugins': {'console_view': True} }
Note
Nine’s Console View is the equivalent of Buildbot Eight’s Console and tgrid views. Unlike Waterfall, we think it is now feature equivalent and even better, with its live update capabilities. Please submit an issue if you think there is an issue displaying your data, with screen shots of what happen and suggestion on what to improve.
Grid View
Grid view shows the whole Buildbot activity arranged by builders vertically and changes horizontally. It is equivalent to Buildbot Eight’s grid view.
By default, changes on all branches are displayed but only one branch may be filtered by the user. Builders can also be filtered by tags. This feature is similar to the one in the builder list.
pip install buildbot-grid-viewc['www'] = { 'plugins': {'grid_view': True} }
Badges
Buildbot badges plugin produces an image in SVG or PNG format with information about the last build for the given builder name. PNG generation is based on the CAIRO SVG engine, it requires a bit more CPU to generate.
pip install buildbot-badgesc['www'] = { 'plugins': {'badges': {}} }
You can the access your builder’s badges using urls like http://<buildbotURL>/plugins/badges/<buildername>.svg.
The default templates are very much configurable via the following options:
{
"left_pad" : 5,
"left_text": "Build Status", # text on the left part of the image
"left_color": "#555", # color of the left part of the image
"right_pad" : 5,
"border_radius" : 5, # Border Radius on flat and plastic badges
# style of the template availables are "flat", "flat-square", "plastic"
"style": "plastic",
"template_name": "{style}.svg.j2", # name of the template
"font_face": "DejaVu Sans",
"font_size": 11,
"color_scheme": { # color to be used for right part of the image
"exception": "#007ec6", # blue
"failure": "#e05d44", # red
"retry": "#007ec6", # blue
"running": "#007ec6", # blue
"skipped": "a4a61d", # yellowgreen
"success": "#4c1", # brightgreen
"unknown": "#9f9f9f", # lightgrey
"warnings": "#dfb317" # yellow
}
}
Those options can be configured either using the plugin configuration:
c['www'] = {
'plugins': {'badges': {"left_color": "#222"}}
}
or via the URL arguments like http://<buildbotURL>/plugins/badges/<buildername>.svg?left_color=222.
Custom templates can also be specified in a template directory nearby the master.cfg.
The badgeio template
A badges template was developed to standardize upon a consistent “look and feel” across the usage of multiple CI/CD solutions, e.g.: use of Buildbot, Codecov.io, and Travis-CI. An example is shown below.

To ensure the correct “look and feel”, the following Buildbot configuration is needed:
c['www'] = {
'plugins': {
'badges': {
"left_pad": 0,
"right_pad": 0,
"border_radius": 3,
"style": "badgeio"
}
}
}
Note
It is highly recommended to use only with SVG.
2.5.17.2. Authentication plugins
By default, Buildbot does not require people to authenticate in order to access control features in the web UI. To secure Buildbot, you will need to configure an authentication plugin.
Note
To secure the Buildbot web interface, authorization rules must be provided via the ‘authz’ configuration. If you simply wish to lock down a Buildbot instance so that only read only access is permitted, you can restrict access to control endpoints to an unpopulated ‘admin’ role. For example:
c['www']['authz'] = util.Authz(allowRules=[util.AnyControlEndpointMatcher(role="admins")],
roleMatchers=[])
Note
As of Buildbot 0.9.4, user session is managed via a JWT token, using HS256 algorithm.
The session secret is stored in the database in the object_state table with name column being session_secret.
Please make sure appropriate access restriction is made to this database table.
Authentication plugins are implemented as classes, and passed as the auth parameter to www.
The available classes are described here:
- class buildbot.www.auth.NoAuth
This class is the default authentication plugin, which disables authentication.
- class buildbot.www.auth.UserPasswordAuth(users)
- Parameters:
users – list of
("user","password")tuples, or a dictionary of{"user": "password", ..}
Simple username/password authentication using a list of user/password tuples provided in the configuration file.
from buildbot.plugins import util c['www'] = { # ... 'auth': util.UserPasswordAuth({"homer": "doh!"}), }
- class buildbot.www.auth.CustomAuth
This authentication class means to be overridden with a custom
check_credentialsmethod that gets username and password as arguments and check if the user can login. You may use it e.g. to check the credentials against an external database or file.from buildbot.plugins import util class MyAuth(util.CustomAuth): def check_credentials(self, user, password): if user == 'snow' and password == 'white': return True else: return False from buildbot.plugins import util c['www']['auth'] = MyAuth()
- class buildbot.www.auth.HTPasswdAuth(passwdFile)
- Parameters:
passwdFile – An
.htpasswdfile to read
This class implements simple username/password authentication against a standard
.htpasswdfile.from buildbot.plugins import util c['www'] = { # ... 'auth': util.HTPasswdAuth("my_htpasswd"), }
- class buildbot.www.oauth2.GoogleAuth(clientId, clientSecret)
- Parameters:
clientId – The client ID of your buildbot application
clientSecret – The client secret of your buildbot application
ssl_verify (boolean) – If False disables SSL certificate verification
This class implements an authentication with Google single sign-on. You can look at the Google oauth2 documentation on how to register your Buildbot instance to the Google systems. The developer console will give you the two parameters you have to give to
GoogleAuth.Register your Buildbot instance with the
BUILDBOT_URL/auth/loginURL as the allowed redirect URI.Example:
from buildbot.plugins import util c['www'] = { # ... 'auth': util.GoogleAuth("clientid", "clientsecret"), }
In order to use this module, you need to install the Python
requestsmodule:pip install requests
- class buildbot.www.oauth2.GitHubAuth(clientId, clientSecret)
- param clientId:
The client ID of your buildbot application
- param clientSecret:
The client secret of your buildbot application
- param serverURL:
The server URL if this is a GitHub Enterprise server
- param apiVersion:
The GitHub API version to use. One of
3or4(V3/REST or V4/GraphQL). Defaults to 3.- param getTeamsMembership:
When
Truefetch all team memberships for each of the organizations the user belongs to. The teams will be included in the user’s groups asorg-name/team-name.- param debug:
When
Trueand usingapiVersion=4show some additional log calls with the GraphQL queries and responses for debugging purposes.- param boolean ssl_verify:
If False disables SSL certificate verification
This class implements an authentication with GitHub single sign-on. It functions almost identically to the
GoogleAuthclass.Register your Buildbot instance with the
BUILDBOT_URL/auth/loginurl as the allowed redirect URI.The user’s email-address (for e.g. authorization) is set to the “primary” address set by the user in GitHub. When using group-based authorization, the user’s groups are equal to the names of the GitHub organizations the user is a member of.
Example:
from buildbot.plugins import util c['www'] = { # ... 'auth': util.GitHubAuth("clientid", "clientsecret"), }
Example for Enterprise GitHub:
from buildbot.plugins import util c['www'] = { # ... 'auth': util.GitHubAuth("clientid", "clientsecret", "https://git.corp.mycompany.com"), }
An example on fetching team membership could be:
from buildbot.plugins import util c['www'] = { # ... 'auth': util.GitHubAuth("clientid", "clientsecret", apiVersion=4, getTeamsMembership=True), 'authz': util.Authz( allowRules=[ util.AnyControlEndpointMatcher(role="core-developers"), ], roleMatchers=[ util.RolesFromGroups(groupPrefix='buildbot/') ] ) }
If the
buildbotorganization had two teams, for example, ‘core-developers’ and ‘contributors’, with the above example, any user belonging to those teams would be granted the roles matching those team names.In order to use this module, you need to install the Python
requestsmodule:pip install requests
- class buildbot.www.oauth2.GitLabAuth(instanceUri, clientId, clientSecret)
- Parameters:
instanceUri – The URI of your GitLab instance
clientId – The client ID of your buildbot application
clientSecret – The client secret of your buildbot application
ssl_verify (boolean) – If False disables SSL certificate verification
This class implements an authentication with GitLab single sign-on. It functions almost identically to the
GoogleAuthclass.Register your Buildbot instance with the
BUILDBOT_URL/auth/loginURL as the allowed redirect URI.Example:
from buildbot.plugins import util c['www'] = { # ... 'auth': util.GitLabAuth("https://gitlab.com", "clientid", "clientsecret"), }
In order to use this module, you need to install the Python
requestsmodule:pip install requests
- class buildbot.www.oauth2.BitbucketAuth(clientId, clientSecret)
- Parameters:
clientId – The client ID of your buildbot application
clientSecret – The client secret of your buildbot application
ssl_verify (boolean) – If False disables SSL certificate verification
This class implements an authentication with Bitbucket single sign-on. It functions almost identically to the
GoogleAuthclass.Register your Buildbot instance with the
BUILDBOT_URL/auth/loginURL as the allowed redirect URI.Example:
from buildbot.plugins import util c['www'] = { # ... 'auth': util.BitbucketAuth("clientid", "clientsecret"), }
In order to use this module, you need to install the Python
requestsmodule:pip install requests
- class buildbot.www.auth.RemoteUserAuth
- Parameters:
header – header to use to get the username (defaults to
REMOTE_USER)headerRegex – regular expression to get the username from header value (defaults to
"(?P<username>[^ @]+)@(?P<realm>[^ @]+)"). Note that you need at least to specify a?P<username>regular expression named group.userInfoProvider – user info provider; see User Information
If the Buildbot UI is served through a reverse proxy that supports HTTP-based authentication (like apache or lighttpd), it’s possible to tell Buildbot to trust the web server and get the username from the request headers.
The administrator must make sure that it’s impossible to get access to Buildbot in any way other than through the frontend. Usually this means that Buildbot should listen for incoming connections only on localhost (or on some firewall-protected port). The reverse proxy must require HTTP authentication to access Buildbot pages (using any source for credentials, such as htpasswd, PAM, LDAP, Kerberos).
Example:
from buildbot.plugins import util c['www'] = { # ... 'auth': util.RemoteUserAuth(), }
A corresponding Apache configuration example:
<Location "/"> AuthType Kerberos AuthName "Buildbot login via Kerberos" KrbMethodNegotiate On KrbMethodK5Passwd On KrbAuthRealms <<YOUR CORP REALMS>> KrbVerifyKDC off KrbServiceName Any Krb5KeyTab /etc/krb5/krb5.keytab KrbSaveCredentials Off require valid-user Order allow,deny Satisfy Any #] SSO RewriteEngine On RewriteCond %{LA-U:REMOTE_USER} (.+)$ RewriteRule . - [E=RU:%1,NS] RequestHeader set REMOTE_USER %{RU}e </Location>The advantage of this sort of authentication is that it is uses a proven and fast implementation for authentication. The problem is that the only information that is passed to Buildbot is the username, and there is no way to pass any other information like user email, user groups, etc. That information can be very useful to the mailstatus plugin, or for authorization processes. See User Information for a mechanism to supply that information.
2.5.17.3. User Information
For authentication mechanisms which cannot provide complete information about a user, Buildbot needs another way to get user data. This is useful both for authentication (to fetch more data about the logged-in user) and for avatars (to fetch data about other users).
This extra information is provided, appropriately enough, by user info providers.
These can be passed to RemoteUserAuth and as an element of avatar_methods.
This can also be passed to oauth2 authentication plugins. In this case the username provided by oauth2 will be used, and all other information will be taken from ldap (Full Name, email, and groups):
Currently only one provider is available:
- class buildbot.ldapuserinfo.LdapUserInfo(uri, bindUser, bindPw, accountBase, accountPattern, groupBase=None, groupMemberPattern=None, groupName=None, accountFullName, accountEmail, avatarPattern=None, avatarData=None, accountExtraFields=None, tls=None)
- Parameters:
uri – uri of the ldap server
bindUser – username of the ldap account that is used to get the infos for other users (usually a “faceless” account)
bindPw – password of the
bindUseraccountBase – the base dn (distinguished name)of the user database
accountPattern – the pattern for searching in the account database. This must contain the
%(username)sstring, which is replaced by the searched usernameaccountFullName – the name of the field in account ldap database where the full user name is to be found.
accountEmail – the name of the field in account ldap database where the user email is to be found.
groupBase – the base dn of the groups database
groupMemberPattern – the pattern for searching in the group database. This must contain the
%(dn)sstring, which is replaced by the searched username’s dngroupName – the name of the field in groups ldap database where the group name is to be found.
avatarPattern – the pattern for searching avatars from emails in the account database. This must contain the
%(email)sstring, which is replaced by the searched emailavatarData – the name of the field in groups ldap database where the avatar picture is to be found. This field is supposed to contain the raw picture, format is automatically detected from jpeg, png or git.
accountExtraFields – extra fields to extracts for use with the authorization policies
tls – an instance of
ldap.Tlsthat specifies TLS settings.
If one of the three optional groups parameters is supplied, then all of them become mandatory. If none is supplied, the retrieved user info has an empty list of groups.
Example:
from buildbot.plugins import util
# this configuration works for MS Active Directory ldap implementation
# we use it for user info, and avatars
userInfoProvider = util.LdapUserInfo(
uri='ldap://ldap.mycompany.com:3268',
bindUser='ldap_user',
bindPw='p4$$wd',
accountBase='dc=corp,dc=mycompany,dc=com',
groupBase='dc=corp,dc=mycompany,dc=com',
accountPattern='(&(objectClass=person)(sAMAccountName=%(username)s))',
accountFullName='displayName',
accountEmail='mail',
groupMemberPattern='(&(objectClass=group)(member=%(dn)s))',
groupName='cn',
avatarPattern='(&(objectClass=person)(mail=%(email)s))',
avatarData='thumbnailPhoto',
)
c['www'] = {
"port": PORT,
"allowed_origins": ["*"],
"url": c['buildbotURL'],
"auth": util.RemoteUserAuth(userInfoProvider=userInfoProvider),
"avatar_methods": [
userInfoProvider,
util.AvatarGravatar()
]
}
Note
In order to use this module, you need to install the ldap3 module:
pip install ldap3
In the case of oauth2 authentications, you have to pass the userInfoProvider as keyword argument:
from buildbot.plugins import util
userInfoProvider = util.LdapUserInfo(...)
c['www'] = {
# ...
'auth': util.GoogleAuth("clientid", "clientsecret", userInfoProvider=userInfoProvider),
}
2.5.17.4. Reverse Proxy Configuration
It is usually better to put Buildbot behind a reverse proxy in production.
Provides automatic gzip compression
Provides SSL support with a widely used implementation
Provides support for http/2 or spdy for fast parallel REST api access from the browser
Reverse proxy however might be problematic for websocket, you have to configure it specifically to pass web socket requests. Here is an nginx configuration that is known to work (nginx 1.6.2):
server {
# Enable SSL and http2
listen 443 ssl http2 default_server;
server_name yourdomain.com;
root html;
index index.html index.htm;
ssl on;
ssl_certificate /etc/nginx/ssl/server.cer;
ssl_certificate_key /etc/nginx/ssl/server.key;
# put a one day session timeout for websockets to stay longer
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 1440m;
# please consult latest nginx documentation for current secure encryption settings
ssl_protocols ..
ssl_ciphers ..
ssl_prefer_server_ciphers on;
#
# force https
add_header Strict-Transport-Security "max-age=31536000; includeSubdomains;";
spdy_headers_comp 5;
proxy_set_header HOST $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-Host $host;
# you could use / if you use domain based proxy instead of path based proxy
location /buildbot/ {
proxy_pass http://127.0.0.1:5000/;
}
location /buildbot/sse/ {
# proxy buffering will prevent sse to work
proxy_buffering off;
proxy_pass http://127.0.0.1:5000/sse/;
}
# required for websocket
location /buildbot/ws {
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_pass http://127.0.0.1:5000/ws;
# raise the proxy timeout for the websocket
proxy_read_timeout 6000s;
}
}
To run with Apache2, you’ll need mod_proxy_wstunnel in addition to mod_proxy_http. Serving HTTPS (mod_ssl) is advised to prevent issues with enterprise proxies (see Server Sent Events), even if you don’t need the encryption itself.
Here is a configuration that is known to work (Apache 2.4.10 / Debian 8, Apache 2.4.25 / Debian 9, Apache 2.4.6 / CentOS 7), directly at the top of the domain.
If you want to add access control directives, just put them in a
<Location />.
<VirtualHost *:443>
ServerName buildbot.example
ServerAdmin webmaster@buildbot.example
# replace with actual port of your Buildbot master
ProxyPass /ws ws://127.0.0.1:8020/ws
ProxyPassReverse /ws ws://127.0.0.1:8020/ws
ProxyPass / http://127.0.0.1:8020/
ProxyPassReverse / http://127.0.0.1:8020/
SetEnvIf X-Url-Scheme https HTTPS=1
ProxyPreserveHost On
SSLEngine on
SSLCertificateFile /path/to/cert.pem
SSLCertificateKeyFile /path/to/cert.key
# check Apache2 documentation for current safe SSL settings
# This is actually the Debian 8 default at the time of this writing:
SSLProtocol all -SSLv3
</VirtualHost>
2.5.17.5. Authorization rules
The authorization framework in Buildbot is very generic and flexible. The drawback is that it is not very obvious for newcomers. The ‘simple’ example will however allow you to easily start by implementing an admins-have-all-rights setup.
Please carefully read the following documentation to understand how to setup authorization in Buildbot.
Authorization framework is tightly coupled to the REST API. Authorization framework only works for HTTP, not for other means of interaction like IRC or try scheduler. It allows or denies access to the REST APIs according to rules.

Roles is a label that you give to a user.
It is similar but different to the usual notion of group:
A user can have several roles, and a role can be given to several users.
Role is an application specific notion, while group is more organization specific notion.
Groups are given by the auth plugin, e.g
ldap,github, and are not always in the precise control of the buildbot admins.Roles can be dynamically assigned, according to the context. For example, there is the
ownerrole, which can be given to a user for a build that he is at the origin, so that he can stop or rebuild only builds of his own.
Endpoint matchers associate role requirements to REST API endpoints. The default policy is allow in case no matcher matches (see below why).
Role matchers associate authenticated users to roles.
Restricting Read Access
Please note that you can use this framework to deny read access to the REST API, but there is no access control in websocket or SSE APIs. Practically this means user will still see live updates from running builds in the UI, as those will come from websocket.
The only resources that are only available for read in REST API are the log data (a.k.a logchunks).
From a strict security point of view you cannot really use Buildbot Authz framework to securely deny read access to your bot. The access control is rather designed to restrict control APIs which are only accessible through REST API. In order to reduce attack surface, we recommend to place Buildbot behind an access controlled reverse proxy like OAuth2Proxy.
Authz Configuration
- class buildbot.www.authz.Authz(allowRules=[], roleMatcher=[], stringsMatcher=util.fnmatchStrMatcher)
- Parameters:
allowRules – List of
EndpointMatcherBaseprocessed in order for each endpoint grant request.roleMatcher – List of RoleMatchers
stringsMatcher – Selects algorithm used to make strings comparison (used to compare roles and builder names). Can be
util.fnmatchStrMatcherorutil.reStrMatcherfromfrom buildbot.plugins import util
Authzneeds to be configured inc['www']['authz']
Endpoint matchers
Endpoint matchers are responsible for creating rules to match REST endpoints, and requiring roles for them. Endpoint matchers are processed in the order they are configured. The first rule matching an endpoint will prevent further rules from being checked. To continue checking other rules when the result is deny, set defaultDeny=False. If no endpoint matcher matches, then access is granted.
One can implement the default deny policy by putting an AnyEndpointMatcher with nonexistent role in the end of the list.
Please note that this will deny all REST apis, and most of the UI do not implement proper access denied message in case of such error.
The following sequence is implemented by each EndpointMatcher class:
Check whether the requested endpoint is supported by this matcher
Get necessary info from data API and decide whether it matches
Look if the user has the required role
Several endpoints matchers are currently implemented. If you need a very complex setup, you may need to implement your own endpoint matchers. In this case, you can look at the source code for detailed examples on how to write endpoint matchers.
- class buildbot.www.authz.endpointmatchers.EndpointMatcherBase(role, defaultDeny=True)
- Parameters:
role – The role which grants access to this endpoint. List of roles is not supported, but a
fnmatchexpression can be provided to match several roles.defaultDeny – The role matcher algorithm will stop if this value is true and the endpoint matched.
This is the base endpoint matcher. Its arguments are inherited by all the other endpoint matchers.
- class buildbot.www.authz.endpointmatchers.AnyEndpointMatcher(role)
- Parameters:
role – The role which grants access to any endpoint.
AnyEndpointMatcher grants all rights to people with given role (usually “admins”).
- class buildbot.www.authz.endpointmatchers.AnyControlEndpointMatcher(role)
- Parameters:
role – The role which grants access to any control endpoint.
AnyControlEndpointMatcher grants control rights to people with given role (usually “admins”). This endpoint matcher matches current and future control endpoints. You need to add this in the end of your configuration to make sure it is future proof.
- class buildbot.www.authz.endpointmatchers.ForceBuildEndpointMatcher(builder, role)
- Parameters:
builder – Name of the builder.
role – The role needed to get access to such endpoints.
ForceBuildEndpointMatcher grants right to force builds.
- class buildbot.www.authz.endpointmatchers.StopBuildEndpointMatcher(builder, role)
- Parameters:
builder – Name of the builder.
role – The role needed to get access to such endpoints.
StopBuildEndpointMatcher grants rights to stop builds.
- class buildbot.www.authz.endpointmatchers.RebuildBuildEndpointMatcher(builder, role)
- Parameters:
builder – Name of the builder.
role – The role needed to get access to such endpoints.
RebuildBuildEndpointMatcher grants rights to rebuild builds.
- class buildbot.www.authz.endpointmatchers.EnableSchedulerEndpointMatcher(builder, role)
- Parameters:
builder – Name of the builder.
role – The role needed to get access to such endpoints.
EnableSchedulerEndpointMatcher grants rights to enable and disable schedulers via the UI.
Role matchers
Role matchers are responsible for creating rules to match people and grant them roles. You can grant roles from groups information provided by the Auth plugins, or if you prefer directly to people’s email.
- class buildbot.www.authz.roles.RolesFromGroups(groupPrefix)
- Parameters:
groupPrefix – Prefix to remove from each group
RolesFromGroups grants roles from the groups of the user. If a user has group
buildbot-admin, and groupPrefix isbuildbot-, then user will be granted the role ‘admin’ex:
roleMatchers=[ util.RolesFromGroups(groupPrefix="buildbot-") ]
- class buildbot.www.authz.roles.RolesFromEmails(roledict)
- Parameters:
roledict – Dictionary with key=role, and value=list of email strings
RolesFromEmails grants roles to users according to the hardcoded emails.
ex:
roleMatchers=[ util.RolesFromEmails(admins=["my@email.com"]) ]
- class buildbot.www.authz.roles.RolesFromDomain(roledict)
- Parameters:
roledict – Dictionary with key=role, and value=list of domain strings
RolesFromDomain grants roles to users according to their email domains. If a user tried to login with email
foo@gmail.com, then the user will be granted the role ‘admins’.ex:
roleMatchers=[ util.RolesFromDomain(admins=["gmail.com"]) ]
- class buildbot.www.authz.roles.RolesFromOwner(roledict)
- Parameters:
roledict – Dictionary with key=role, and value=list of email strings
RolesFromOwner grants a given role when property owner matches the email of the user
ex:
roleMatchers=[ RolesFromOwner(role="owner") ]
- class buildbot.www.authz.roles.RolesFromUsername(roles, usernames)
- Parameters:
roles – Roles to assign when the username matches.
usernames – List of usernames that have the roles.
RolesFromUsername grants the given roles when the
usernameproperty is within the list of usernames.ex:
roleMatchers=[ RolesFromUsername(roles=["admins"], usernames=["root"]), RolesFromUsername(roles=["developers", "integrators"], usernames=["Alice", "Bob"]) ]
Example Configs
Simple config which allows admin people to control everything, but allow anonymous to look at build results:
from buildbot.plugins import *
authz = util.Authz(
allowRules=[
util.AnyControlEndpointMatcher(role="admins"),
],
roleMatchers=[
util.RolesFromEmails(admins=["my@email.com"])
]
)
auth=util.UserPasswordAuth({'my@email.com': 'mypass'})
c['www']['auth'] = auth
c['www']['authz'] = authz
More complex config with separation per branch:
from buildbot.plugins import *
authz = util.Authz(
stringsMatcher=util.fnmatchStrMatcher, # simple matcher with '*' glob character
# stringsMatcher = util.reStrMatcher, # if you prefer regular expressions
allowRules=[
# admins can do anything,
# defaultDeny=False: if user does not have the admin role, we continue parsing rules
util.AnyEndpointMatcher(role="admins", defaultDeny=False),
util.StopBuildEndpointMatcher(role="owner"),
# *-try groups can start "try" builds
util.ForceBuildEndpointMatcher(builder="try", role="*-try"),
# *-mergers groups can start "merge" builds
util.ForceBuildEndpointMatcher(builder="merge", role="*-mergers"),
# *-releasers groups can start "release" builds
util.ForceBuildEndpointMatcher(builder="release", role="*-releasers"),
# if future Buildbot implement new control, we are safe with this last rule
util.AnyControlEndpointMatcher(role="admins")
],
roleMatchers=[
RolesFromGroups(groupPrefix="buildbot-"),
RolesFromEmails(admins=["homer@springfieldplant.com"],
reaper-try=["007@mi6.uk"]),
# role owner is granted when property owner matches the email of the user
RolesFromOwner(role="owner")
]
)
c['www']['authz'] = authz
Using GitHub authentication and allowing access to control endpoints for users in the “Buildbot” organization:
from buildbot.plugins import *
authz = util.Authz(
allowRules=[
util.AnyControlEndpointMatcher(role="BuildBot")
],
roleMatchers=[
util.RolesFromGroups()
]
)
auth=util.GitHubAuth('CLIENT_ID', 'CLIENT_SECRET')
c['www']['auth'] = auth
c['www']['authz'] = authz
2.5.18. Change Hooks
The /change_hook URL is a magic URL which will accept HTTP requests and translate them into
changes for Buildbot. Implementations (such as a trivial json-based endpoint and a GitHub
implementation) can be found in master/buildbot/www/hooks. The format of the URL is
/change_hook/DIALECT where DIALECT is a package within the hooks directory.
change_hook is disabled by default and each DIALECT has to be enabled separately, for security
reasons.
An example www configuration line which enables change_hook and two DIALECTS:
c['www'] = {
"change_hook_dialects": {
'base': True,
'somehook': {
'option1': True,
'option2':False
},
},
}
Within the www config dictionary arguments, the change_hook key enables/disables the
module, and change_hook_dialects whitelists DIALECTs where the keys are the module names and
the values are optional arguments which will be passed to the hooks.
The master/contrib/post_build_request.py script allows for the submission of an arbitrary
change request. Run post_build_request.py --help for more information. The base
dialect must be enabled for this to work.
2.5.18.1. Change Hooks Auth
By default, the change hook URL is not protected. Some hooks implement their own authentication method. Others require the generic method to be secured.
To protect URL against unauthorized access, you may use change_hook_auth option.
Note
This method uses HTTP BasicAuth. It implies the use of SSL via Reverse Proxy Configuration
in order to be fully secured.
from twisted.cred import strcred
c['www'] = {
...,
"change_hook_auth": [strcred.makeChecker("file:changehook.passwd")],
}
Create a file changehook.passwd with content:
user:password
change_hook_auth should be a list of ICredentialsChecker. See the details of
available options in Twisted documentation.
Note
In the case of the "file:changehook.passwd" description in makeChecker, Buildbot
checkconfig might give you a warning “not a valid file: changehook.passwd”. To resolve
this, you need specify the full path to the file, f"file:{os.path.join(basedir,
'changehook.passwd')}".
2.5.18.2. Mercurial hook
The Mercurial hook uses the base dialect:
c['www'] = {
...,
"change_hook_dialects": {'base': True},
}
Once this is configured on your buildmaster add the following hook on your server-side Mercurial
repository’s hgrc:
[hooks]
changegroup.buildbot = python:/path/to/hgbuildbot.py:hook
You’ll find master/contrib/hgbuildbot.py, and its inline documentation, in the buildbot-contrib repository.
2.5.18.3. GitHub hook
Note
There is a standalone HTTP server available for receiving GitHub notifications as well: master/contrib/github_buildbot.py. This script may be useful in cases where you cannot expose the WebStatus for public consumption. Alternatively, you can setup a reverse proxy Reverse Proxy Configuration.
The GitHub hook has the following parameters:
secret(default None)Secret token to use to validate payloads.
strict(default False)If the hook must be strict regarding valid payloads. If the value is False (default), the signature will only be checked if a secret is specified and a signature was supplied with the payload. If the value is True, a secret must be provided, and payloads without signature will be ignored.
codebase(default None)The codebase value to include with created changes. If the value is a function (or any other callable), it will be called with the GitHub event payload as argument and the function must return the codebase value to use for the event.
github_property_whitelist(default [])A list of
fnmatchexpressions which match against the flattened pull request information JSON prefixed withgithub. For examplegithub.numberrepresents the pull request number. Available entries can be looked up in the GitHub API Documentation or by examining the data returned for a pull request by the API.class(default None)A class to be used for processing incoming payloads. If the value is None (default), the default class –
buildbot.www.hooks.github.GitHubEventHandler– will be used. The default class handles ping, push and pull_request events only. If you’d like to handle other events (see Event Types & Payloads for more information), you’d need to subclassGitHubEventHandlerand add handler methods for the corresponding events. For example, if you’d like to handle blah events, your code should look something like this:from buildbot.www.hooks.github import GitHubEventHandler class MyBlahHandler(GitHubEventHandler): def handle_blah(self, payload): # Do some magic here return [], 'git'
skips(default[r'\[ *skip *ci *\]', r'\[ *ci *skip *\]'])A list of regex pattern makes buildbot ignore the push event. For instance, if user push 3 commits and the commit message of branch head contains a key string
[ci skip], buildbot will ignore this push event.If you want to disable the skip checking, please set it to
[].github_api_endpoint(defaulthttps://api.github.com)If you have a self-host GitHub Enterprise installation, please set this URL properly.
tokenIf your GitHub or GitHub Enterprise instance does not allow anonymous communication, youneed to provide an access token. Instructions can be found here. This attribute is rendered using the
IRenderableinterface, the only property available isfull_name, of the format{owner}/{full_name}.pullrequest_ref(defaultmerge)Remote ref to test if a pull request is sent to the endpoint. See the GitHub developer manual for possible values for pull requests. (e.g.
head)
The simplest way to use GitHub hook is as follows:
c['www'] = {
"change_hook_dialects": {'github': {}},
}
Having added this line, you should add a webhook for your GitHub project (see Creating Webhooks page at GitHub). The parameters are:
- Payload URL
This URL should point to
/change_hook/githubrelative to the root of the web status. For example, if the base URL ishttp://builds.example.com/buildbot, then point GitHub tohttp://builds.example.com/buildbot/change_hook/github. To specify a project associated to the repository, append?project=nameto the URL.- Content Type
Specify
application/x-www-form-urlencodedorapplication/json.- Secret
Any value. If you provide a non-empty value (recommended), make sure that your hook is configured to use it:
c['www'] = { ..., "change_hook_dialects": { 'github': { 'secret': 'MY-SECRET', }, }, }
- Which events would you like to trigger this webhook?
Click –
Let me select individual events, then selectPushandPull request– other kind of events are not currently supported.
And then press the Add Webhook button.
Github hook creates 3 kinds of changes, distinguishable by their category field:
None: This change is a push to a branch.Use
util.ChangeFilter(category=None, repository="http://github.com/<org>/<project>")
'tag': This change is a push to a tag.Use
util.ChangeFilter(category='tag', repository="http://github.com/<org>/<project>")
'pull': This change is from a pull-request creation or update.Use
util.ChangeFilter(category='pull', repository="http://github.com/<org>/<project>"). In this case, theGitHubstep must be used instead of the standardGitin order to be able to pull GitHub’s magic refs. With this method, theGitHubstep will always checkout the branch merged with latest master. This allows to test the result of the merge instead of just the source branch. Note that you can use theGitHubfor all categories of event.
Warning
Pull requests against every branch will trigger the webhook; the base branch name will be in the
basename property of the build.
Warning
The incoming HTTP requests for this hook are not authenticated by default. Anyone who can access the web server can “fake” a request from GitHub, potentially causing the buildmaster to run arbitrary code.
To protect URL against unauthorized access you should use Change Hooks Auth option.
Then change the Payload URL of your GitHub webhook to
https://user:password@builds.example.com/bbot/change_hook/github.
2.5.18.4. BitBucket hook
The BitBucket hook is as simple as the GitHub one and takes no options.
c['www'] = {
...,
"change_hook_dialects": {'bitbucket': True},
}
When this is set up, you should add a POST service pointing to /change_hook/bitbucket
relative to the root of the web status. For example, if the grid URL is
http://builds.example.com/bbot/grid, then point BitBucket to
http://builds.example.com/change_hook/bitbucket. To specify a project associated to the
repository, append ?project=name to the URL.
Note that there is a standalone HTTP server available for receiving BitBucket notifications, as well: master/contrib/bitbucket_buildbot.py. This script may be useful in cases where you cannot expose the WebStatus for public consumption.
Warning
As in the previous case, the incoming HTTP requests for this hook are not authenticated by default. Anyone who can access the web status can “fake” a request from BitBucket, potentially causing the buildmaster to run arbitrary code.
To protect URL against unauthorized access you should use Change Hooks Auth option. Then,
create a BitBucket service hook (see
https://confluence.atlassian.com/display/BITBUCKET/POST+Service+Management) with a WebHook URL like
https://user:password@builds.example.com/bbot/change_hook/bitbucket.
Note that as before, not using change_hook_auth can expose you to security risks.
2.5.18.5. Bitbucket Cloud hook
c['www'] = {
...,
"change_hook_dialects": {'bitbucketcloud': {}},
}
When this is set up, you should add a webhook pointing to /change_hook/bitbucketcloud relative
to the root of the web status.
According to the type of the event, the change category is set to push, pull-created,
pull-rejected, pull-updated, pull-fulfilled or ref-deleted.
The Bitbucket Cloud hook may have the following optional parameters:
codebase(default None)The codebase value to include with changes or a callable object that will be passed the payload in order to get it.
bitbucket_property_whitelist(default [])A list of
fnmatchexpressions which match against the flattened pull request information JSON prefixed withbitbucket. For examplebitbucket.idrepresents the pull request ID. Available entries can be looked up in the BitBucket API Documentation or by examining the data returned for a pull request by the API.
Warning
The incoming HTTP requests for this hook are not authenticated by default. Anyone who can access the web server can “fake” a request from Bitbucket Cloud, potentially causing the buildmaster to run arbitrary code.
2.5.18.6. Bitbucket Server hook
c['www'] = {
...,
"change_hook_dialects": {'bitbucketserver': {}},
}
When this is set up, you should add a webhook pointing to /change_hook/bitbucketserver relative
to the root of the web status.
According to the type of the event, the change category is set to push, pull-created,
pull-rejected, pull-updated, pull-fulfilled or ref-deleted.
The Bitbucket Server hook may have the following optional parameters:
codebase(default None)The codebase value to include with changes or a callable object that will be passed the payload in order to get it.
bitbucket_property_whitelist(default [])A list of
fnmatchexpressions which match against the flattened pull request information JSON prefixed withbitbucket. For examplebitbucket.idrepresents the pull request ID. Available entries can be looked up in the BitBucket API Documentation or by examining the data returned for a pull request by the API.
Warning
The incoming HTTP requests for this hook are not authenticated by default. Anyone who can access the web server can “fake” a request from Bitbucket Server, potentially causing the buildmaster to run arbitrary code.
Note
This hook requires the bitbucket-webhooks plugin (see https://marketplace.atlassian.com/plugins/nl.topicus.bitbucket.bitbucket-webhooks/server/overview).
2.5.18.7. Poller hook
The poller hook allows you to use GET or POST requests to trigger polling. One advantage of this is your buildbot instance can poll at launch (using the pollAtLaunch flag) to get changes that happened while it was down, but then you can still use a commit hook to get fast notification of new changes.
Suppose you have a poller configured like this:
c['change_source'] = SVNPoller(
repourl="https://amanda.svn.sourceforge.net/svnroot/amanda/amanda",
split_file=split_file_branches,
pollInterval=24*60*60,
pollAtLaunch=True,
)
And you configure your WebStatus to enable this hook:
c['www'] = {
...,
"change_hook_dialects": {'poller': True},
}
Then you will be able to trigger a poll of the SVN repository by poking the /change_hook/poller
URL from a commit hook like this:
curl -s -F poller=https://amanda.svn.sourceforge.net/svnroot/amanda/amanda \
http://yourbuildbot/change_hook/poller
If no poller argument is provided then the hook will trigger polling of all polling change sources.
You can restrict which pollers the webhook has access to using the allowed option:
c['www'] = {
...,
'change_hook_dialects': {
'poller': {
'allowed': ['https://amanda.svn.sourceforge.net/svnroot/amanda/amanda']
}
}
}
2.5.18.8. GitLab hook
c['www'] = {
...,
"change_hook_dialects": {
'gitlab' : {
'secret': '...',
},
},
}
The GitLab hook has the following parameters:
secret(default None)Secret token to use to validate payloads.
When this is set up, you should add a POST service pointing to /change_hook/gitlab relative
to the root of the web status. For example, if the grid URL is
http://builds.example.com/bbot/grid, then point GitLab to
http://builds.example.com/change_hook/gitlab. The project and/or codebase can also be passed in
the URL by appending ?project=name or ?codebase=foo to the URL. These parameters will be
passed along to the scheduler.
Note
To handle merge requests from forks properly, it’s easiest to use a GitLab source step rather than a Git source step.
Note
Your Git or GitLab step must be configured with a git@ repourl, not a https: one, else the change from the webhook will not trigger a build.
Warning
As in the previous case, the incoming HTTP requests for this hook are not authenticated by default. Anyone who can access the web status can “fake” a request from your GitLab server, potentially causing the buildmaster to run arbitrary code.
Warning
When applicable, you need to permit access to internal/local networks.
See https://docs.gitlab.com/ee/security/webhooks.html for details.
To protect URL against unauthorized access you should either
set secret token in the configuration above, then set it in the GitLab service hook declaration, or
use the Change Hooks Auth option. Then, create a GitLab service hook (see
https://your.gitlab.server/help/web_hooks) with a WebHook URL likehttps://user:password@builds.example.com/bbot/change_hook/gitlab.
Note that as before, not using change_hook_auth can expose you to security risks.
2.5.18.9. Gitorious Hook
The Gitorious hook is as simple as GitHub one and it also takes no options.
c['www'] = {
...,
"change_hook_dialects": {'gitorious': True},
}
When this is set up, you should add a POST service pointing to /change_hook/gitorious
relative to the root of the web status. For example, if the grid URL is
http://builds.example.com/bbot/grid, then point Gitorious to
http://builds.example.com/change_hook/gitorious.
Warning
As in the previous case, the incoming HTTP requests for this hook are not authenticated by default. Anyone who can access the web status can “fake” a request from your Gitorious server, potentially causing the buildmaster to run arbitrary code.
To protect URL against unauthorized access you should use Change Hooks Auth option. Then,
create a Gitorious web hook with a WebHook URL like
https://user:password@builds.example.com/bbot/change_hook/gitorious.
Note that as before, not using change_hook_auth can expose you to security risks.
Note
Web hooks are only available for local Gitorious installations, since this feature is not offered as part of Gitorious.org yet.
2.5.18.10. Custom Hooks
Custom hooks are supported via the Plugin Infrastructure in Buildbot mechanism. You can subclass any of the available
hook handler classes available in buildbot.www.hooks and register it in the plugin system
via a custom python module. For convenience, you can also use the generic option custom_class,
e.g.:
from buildbot.plugins import webhooks
class CustomBase(webhooks.base):
def getChanges(self, request):
args = request.args
chdict = {
"revision": args.get(b'revision'),
"repository": args.get(b'repository'),
"project": args.get(b'project'),
"codebase": args.get(b'codebase')
}
return ([chdict], None)
c['www'] = {
...,
"change_hook_dialects": {
'base' : {
'custom_class': CustomBase,
},
},
}
2.5.19. Custom Services
2.5.19.1. FailingBuildsetCanceller
- class buildbot.plugins.util.FailingBuildsetCanceller
The purpose of this service is to cancel builds once one build on a buildset fails.
This is useful for reducing use of resources in cases when there is no need to gather information from all builds of a buildset once one of them fails.
The service may be configured to track a subset of builds.
This is controlled by the filters parameter.
The decision on whether to cancel a build is done once a build fails.
The following parameters are supported by the FailingBuildsetCanceller:
name(required, a string) The name of the service. All services must have different names in Buildbot. For most use cases value like
buildset_cancellerwill work fine.filters(required, a list of three-element tuples) The source stamp filters that specify which builds the build canceller should track. The first element of each tuple must be a list of builder names that the filter would apply to. The second element of each tuple must be a list of builder names that will have the builders cancelled once a build fails. Alternatively, the value
Noneas the second element of the tuple specifies that all builds should be cancelled. The third element of each tuple must be an instance ofbuildbot.util.SourceStampFilter.
2.5.19.2. OldBuildCanceller
- class buildbot.plugins.util.OldBuildCanceller
The purpose of this service is to cancel builds on branches as soon as a superseding build request is created from a new commit on the branch.
This allows to reduce resource usage in projects that use Buildbot to run tests on pull request branches. For example, if a developer pushes new commits to the branch, notices and fixes a problem quickly and then pushes again, the builds that have been started on the older commit will be cancelled immediately instead of waiting for builds to finish.
The service may be configured to track a subset of builds.
This is controlled by the filters parameter.
The decision on whether to track a build is done on build startup.
Configuration changes are ignored for builds that have already started.
Certain version control systems have multiple branch names that map to a single logical branch which makes OldBuildCanceller unable to cancel builds even in the presence of new commits.
The handling of such scenarios is controlled by branch_key.
The following parameters are supported by the OldBuildCanceller:
name(required, a string) The name of the service. All services must have different names in Buildbot. For most use cases value like
build_cancellerwill work fine.filters(required, a list of two-element tuples) The source stamp filters that specify which builds the build canceller should track. The first element of each tuple must be a list of builder names that the filter would apply to. The second element of each tuple must be an instance of
buildbot.util.SourceStampFilter.branch_key(optional, a function that receives source stamp or change dictionary and returns a string) Allows customizing the branch that is used to track builds and decide whether to cancel them. The function receives a dictionary with at least the following keys:
project,codebase,repository,branchand must return a string.- The default implementation implements custom handling for the following Version control systems:
Gerrit: branches that identify changes (use format
refs/changes/*/*/*) have the change iteration number removed.
Pass
lambda ss: ss['branch']to always use branch property directly.Note that
OldBuildCancellerwill only cancel builds with the sameproject,codebase,repositorytuple as incoming change, so these do not need to be taken into account by this function.
Custom services are stateful components of Buildbot that can be added to the services key of the Buildbot config dictionary.
The following is the services that are meant to be used without advanced knowledge of Buildbot.
More complex services are described in the developer section of the Buildbot manual. They are meant to be used by advanced users of Buildbot.
2.5.20. DbConfig
DbConfig is a utility for master.cfg to get easy-to-use key-value storage in the Buildbot database.
DbConfig can get and store any json-able object to the db for use by other masters or separate UI plugins to edit them.
The design is intentionally simplistic, as the focus is on ease of use rather than efficiency.
A separate db connection is created each time get() or set() is called.
Example:
from buildbot.plugins import util, worker
c = BuildmasterConfig = {}
c['db_url'] = 'mysql://username:password@mysqlserver/buildbot'
dbConfig = util.DbConfig(BuildmasterConfig, basedir)
workers = dbConfig.get("workers")
c['workers'] = [
worker.Worker(worker['name'], worker['passwd'],
properties=worker.get('properties')),
for worker in workers
]
- class DbConfig
- __init__(BuildmasterConfig, basedir)
- Parameters:
BuildmasterConfig – the
BuildmasterConfig, wheredb_urlis already configuredbasedir –
basedirglobal variable of themaster.cfgrun environment. SQLite urls are relative to this dir
- get(name, default=MarkerClass)
- Parameters:
name – the name of the config variable to retrieve
default – in case the config variable has not been set yet, default is returned if defined, else
KeyErroris raised
- set(name, value)
- Parameters:
name – the name of the config variable to be set
value – the value of the config variable to be set
2.5.21. Configurators
For advanced users or plugin writers, the configurators key is available and holds a list of buildbot.interfaces.IConfigurator.
The configurators will run after the master.cfg has been processed, and will modify the config dictionary.
Configurator implementers should make sure that they are interoperable with each other, which means carefully modifying the config to avoid overriding a setting already made by the user or another configurator.
Configurators are run (thus prioritized) in the order of the configurators list.
2.5.21.1. JanitorConfigurator
JanitorConfigurator creates a builder and Nightly scheduler which will regularly remove old information.
At the moment, it only supports cleaning of logs, but it will contain more features as we implement them.
from buildbot.plugins import util
from datetime import timedelta
# configure a janitor which will delete all logs older than one month,
# and will run on sundays at noon
c['configurators'] = [util.JanitorConfigurator(
logHorizon=timedelta(weeks=4),
hour=12,
dayOfWeek=6
)]
Parameters for JanitorConfigurator are:
logHorizonA
timedeltaobject describing the minimum time for which the log data should be maintained.hour,dayOfWeek, …Arguments given to the
Nightlyscheduler which is backing theJanitorConfigurator. Determines when the cleanup will be done. With this, you can configure it daily, weekly or even hourly if you wish. You probably want to schedule it when Buildbot is less loaded.
2.5.22. Manhole
Manhole is an interactive Python shell that gives full access to the Buildbot master instance. It is probably only useful for Buildbot developers.
Using Manhole requires the cryptography and pyasn1 python packages to be installed.
These are not part of the normal Buildbot dependencies.
There are several implementations of Manhole available, which differ by the authentication mechanisms and the security of the connection.
Note
Manhole exposes full access to the buildmaster’s account (including the ability to modify and delete files). It’s recommended not to expose the manhole to the Internet and to use a strong password.
- class buildbot.plugins.util.AuthorizedKeysManhole(port, keyfile, ssh_hostkey_dir)
A manhole implementation that accepts encrypted ssh connections and authenticates by ssh keys. The prospective client must have an ssh private key that matches one of the public keys in manhole’s authorized keys file.
- Parameters:
port (string or int) – The port to listen on. This is a strports specification string, like
tcp:12345ortcp:12345:interface=127.0.0.1. Bare integers are treated as a simple tcp port.keyfile (string) – The path to the file containing public parts of the authorized SSH keys. The path is interpreted relative to the buildmaster’s basedir. The file should contain one public SSH key per line. This is the exact same format as used by sshd in
~/.ssh/authorized_keys.ssh_hostkey_dir (string) – The path to the directory which contains ssh host keys for this server.
- class buildbot.plugins.util.PasswordManhole(port, username, password, ssh_hostkey_dir)
A manhole implementation that accepts encrypted ssh connections and authenticates by username and password.
- Parameters:
port (string or int) – The port to listen on. This is a strports specification string, like
tcp:12345ortcp:12345:interface=127.0.0.1. Bare integers are treated as a simple tcp port.username (string) – The username to authenticate.
password (string) – The password of the user to authenticate.
ssh_hostkey_dir (string) – The path to the directory which contains ssh host keys for this server.
- class buildbot.plugins.util.TelnetManhole(port, username, password)
A manhole implementation that accepts unencrypted telnet connections and authenticates by username and password.
Note
This connection method is not secure and should not be used anywhere where the port is exposed to the Internet.
- Parameters:
port (string or int) – The port to listen on. This is a strports specification string, like
tcp:12345ortcp:12345:interface=127.0.0.1. Bare integers are treated as a simple tcp port.username (string) – The username to authenticate.
password (string) – The password of the user to authenticate.
2.5.22.1. Using manhole
The interactive Python shell can be entered by simply connecting to the host in question. For instance, in the case of ssh password-based manhole, the configuration may look like this:
from buildbot import manhole
c['manhole'] = manhole.PasswordManhole("tcp:1234:interface=127.0.0.1",
"admin", "passwd",
ssh_hostkey_dir="data/ssh_host_keys")
The above ssh_hostkey_dir declares a path relative to the buildmaster’s basedir to look for ssh keys. To create an ssh key, navigate to the buildmaster’s basedir and run:
mkdir -p data/ssh_host_keys
ckeygen3 -t rsa -f "data/ssh_host_keys/ssh_host_rsa_key"
Restart Buildbot and then try to connect to the running buildmaster like this:
ssh -p1234 admin@127.0.0.1
# enter passwd at prompt
After connection has been established, objects can be explored in more depth using dir(x) or the helper function show(x). For example:
>>> master.workers.workers
{'example-worker': <Worker 'example-worker', current builders: runtests>}
>>> show(master)
data attributes of <buildbot.master.BuildMaster instance at 0x7f7a4ab7df38>
basedir : '/home/dustin/code/buildbot/t/buildbot/'...
botmaster : <type 'instance'>
buildCacheSize : None
buildHorizon : None
buildbotURL : http://localhost:8010/
changeCacheSize : None
change_svc : <type 'instance'>
configFileName : master.cfg
db : <class 'buildbot.db.connector.DBConnector'>
db_url : sqlite:///state.sqlite
...
>>> show(master.botmaster.builders['win32'])
data attributes of <Builder ''builder'' at 48963528>
The buildmaster’s SSH server will use a different host key than the normal sshd running on a typical unix host.
This will cause the ssh client to complain about a host key mismatch, because it does not realize there are two separate servers running on the same host.
To avoid this, use a clause like the following in your .ssh/config file:
Host remotehost-buildbot
HostName remotehost
HostKeyAlias remotehost-buildbot
Port 1234
# use 'user' if you use PasswordManhole and your name is not 'admin'.
# if you use AuthorizedKeysManhole, this probably doesn't matter.
User admin
2.5.23. Multimaster
Warning
Buildbot Multimaster is considered experimental. There are still some companies using it in production. Don’t hesitate to use the mailing lists to share your experience.

Buildbot supports interconnection of several masters. This has to be done through a multi-master enabled message queue backend. As of now the only one supported is wamp and crossbar.io. see wamp
There are then several strategy for introducing multimaster in your buildbot infra. A simple way to say it is by adding the concept of symmetrics and asymmetrics multimaster (like there is SMP and AMP for multi core CPUs)
Symmetric multimaster is when each master share the exact same configuration. They run the same builders, same schedulers, same everything, the only difference is that workers are connected evenly between the masters (by any means (e.g. DNS load balancing, etc)) Symmetric multimaster is good to use to scale buildbot horizontally.
Asymmetric multimaster is when each master have different configuration. Each master may have a specific responsibility (e.g schedulers, set of builder, UI). This was more how you did in 0.8, also because of its own technical limitations. A nice feature of asymmetric multimaster is that you can have the UI only handled by some masters.
Separating the UI from the controlling will greatly help in the performance of the UI, because badly written BuildSteps?? can stall the reactor for several seconds.
The fanciest configuration would probably be a symmetric configuration for everything but the UI. You would scale the number of UI master according to your number of UI users, and scale the number of engine masters to the number of workers.
Depending on your workload and size of master host, it is probably a good idea to start thinking of multimaster starting from a hundred workers connected.
Multimaster can also be used for high availability, and seamless upgrade of configuration code. Complex configuration indeed requires sometimes to restart the master to reload custom steps or code, or just to upgrade the upstream buildbot version.
In this case, you will implement following procedure:
Start new master(s) with new code and configuration.
Send a graceful shutdown to the old master(s).
New master(s) will start taking the new jobs, while old master(s) will just finish managing the running builds.
As an old master is finishing the running builds, it will drop the connections from the workers, who will then reconnect automatically, and by the mean of load balancer will get connected to a new master to run new jobs.
As buildbot nine has been designed to allow such procedure, it has not been implemented in production yet as we know. There is probably a new REST API needed in order to gracefully shutdown a master, and the details of gracefully dropping the connection to the workers to be sorted out.
2.5.24. Multiple-Codebase Builds
What if an end-product is composed of code from several codebases? Changes may arrive from different repositories within the tree-stable-timer period. Buildbot will not only use the source-trees that contain changes but also needs the remaining source-trees to build the complete product.
For this reason, a Scheduler can be configured to base a build on a set of several source-trees that can (partly) be overridden by the information from incoming Changes.
As described in Source-Stamps, the source for each codebase is identified by a source stamp, containing its repository, branch and revision. A full build set will specify a source stamp set describing the source to use for each codebase.
Configuring all of this takes a coordinated approach. A complete multiple repository configuration consists of:
a codebase generator
Every relevant change arriving from a VC must contain a codebase. This is done by a
codebaseGeneratorthat is defined in the configuration. Most generators examine the repository of a change to determine its codebase, using project-specific rules.
some schedulers
Each
schedulerhas to be configured with a set of all requiredcodebasesto build a product. These codebases indicate the set of required source-trees. In order for the scheduler to be able to produce a complete set for each build, the configuration can give a default repository, branch, and revision for each codebase. When a scheduler must generate a source stamp for a codebase that has received no changes, it applies these default values.
multiple source steps - one for each codebase
A Builder’s build factory must include a source step for each codebase. Each of the source steps has a
codebaseattribute which is used to select an appropriate source stamp from the source stamp set for a build. This information comes from the arrived changes or from the scheduler’s configured default values.Note
Each source step has to have its own
workdirset in order for the checkout to be done for each codebase in its own directory.Note
Ensure you specify the codebase within your source step’s Interpolate() calls (e.g.
http://.../svn/%(src:codebase:branch)s). See Interpolate for details.
Warning
Defining a codebaseGenerator that returns non-empty (not '') codebases will change the behavior of all the schedulers.
2.5.25. Miscellaneous Configuration
2.5.25.1. SourceStampFilter
- class buildbot.util.SourceStampFilter
This class is used to filter source stamps.
It is conceptually very similar to ChangeFilter except that it operates on source stamps.
It accepts a set of conditions.
A source stamp is considered accepted if all conditions are satisfied.
The conditions are specified via the constructor arguments.
The following parameters are supported by the SourceStampFilter:
project_eq,codebase_eq,repository_eq,branch_eq(optional, a string or a list of strings) The corresponding property of the source stamp must match exactly to at least one string from the value supplied by the argument.
branchusesutil.NotABranchas its default value which indicates that no checking should be done, because the branch may actually haveNonevalue to be checked.project_not_eq,codebase_not_eq,repository_not_eq,branch_not_eq(optional, a string or a list of strings) The corresponding property of the source stamp must not match exactly to any string from the value supplied by the argument.
project_re,codebase_re,repository_re,branch_re(optional, a string or a list of strings or regex pattern objects) The corresponding property of the source stamp must match to at least one regex from the value supplied by the argument. Any strings passed via this parameter are converted to a regex via
re.compile.project_not_re,codebase_not_re,repository_not_re,branch_not_re(optional, a string or a list of strings or regex pattern objects) The corresponding property of the source stamp must not match to any regex from the value supplied by the argument. Any strings passed via this parameter are converted to a regex via
re.compile.filter_fn(optional, a callable accepting a dictionary and returning a boolean) The given function will be passed the source stamp. It is expected to return
Trueif the source stamp is matched,Falseotherwise. In case of a match, all other conditions will still be evaluated.
2.5.25.2. ChangeFilter
- class buildbot.util.ChangeFilter
This class is used to filter changes.
It is conceptually very similar to SourceStampFilter except that it operates on changes.
The class accepts a set of conditions.
A change is considered acepted if all conditions are satisfied.
The conditions are specified via the constructor arguments.
The following parameters are supported by the ChangeFilter:
project,repository,branch,category,codebase(optional, a string or a list of strings) The corresponding attribute of the change must match exactly to at least one string from the value supplied by the argument.
branchusesutil.NotABranchas its default value which indicates that no checking should be done, because the branch may actually haveNonevalue to be checked.project_not_eq,repository_not_eq,branch_not_eq,category_not_eq,codebase_not_eq(optional, a string or a list of strings) The corresponding attribute of the change must not match exactly to any of the strings from the value supplied by the argument.
branchusesutil.NotABranchas its default value which indicates that no checking should be done, because the branch may actually haveNonevalue to be checked.project_re,repository_re,branch_re,category_re,codebase_re(optional, a string or a list of strings or regex pattern objects) The corresponding attribute of the change must match to at least one regex from the value supplied by the argument. Any strings passed via this parameter are converted to a regex via
re.compile.project_not_re,repository_not_re,branch_not_re,category_not_re,codebase_not_re(optional, a string or a list of strings or regex pattern objects) The corresponding attribute of the change must not match to at least any regex from the value supplied by the argument. Any strings passed via this parameter are converted to a regex via
re.compile.property_eq(optional, a dictionary containing string keys and values each of which with a string or a list of strings) The property of the change with corresponding name must match exactly to at least one string from the value supplied by the argument.
property_not_eq(optional, a string or a list of strings) The property of the change with corresponding name must not be present or not match exactly to at least one string from the value supplied by the argument.
property_re(optional, a string or a list of strings or regex pattern objects) The property of the change with corresponding name must match to at least one regex from the value supplied by the argument. Any strings passed via this parameter are converted to a regex via
re.compile.property_not_re(optional, a string or a list of strings or regex pattern objects) The property of the change with corresponding name must not be present or not match to at least one regex from the value supplied by the argument. Any strings passed via this parameter are converted to a regex via
re.compile.project_fn,repository_fn,branch_fn,category_fn,codebase_fn(optional, a callable accepting a string and returning a boolean) The given function will be passed the value from the change that corresponds to the parameter name. It is expected to return
Trueif the change is matched,Falseotherwise. In case of a match, all other conditions will still be evaluated.filter_fn(optional, a callable accepting a
Changeobject and returning a boolean) The given function will be passed the change. It is expected to returnTrueif the change is matched,Falseotherwise. In case of a match, all other conditions will still be evaluated.
Secrets in conditions
ChangeFilter does not support renderables. Accordingly, secrets cannot be used to
construct the conditions that will later be used to filter changes.
This does not reduce security of the system because in order for secret values to be useful for filtering, they will need to be present in the changes themselves. The change information is stored in the database and frequently appears in the logs.
Best practice is to make sure secret values are not encoded in changes such as in repository URLs. Most of the source steps support passing authentication information separately from repository URL.
If encoding secrets is unavoidable, then changes should be filtered using regex (e.g. via
repository_re argument) or custom callback functions (e.g. via repository_fn or
filter_fn arguments).
Examples
ChangeFilter can be setup like this:
from buildbot.plugins import util
my_filter = util.ChangeFilter(project_re="^baseproduct/.*", branch="devel")
and then assigned to a scheduler with the change_filter parameter:
sch = SomeSchedulerClass(..., change_filter=my_filter)
buildbot.www.hooks.github.GitHubEventHandler has a special github_distinct property that can be used to specify whether or not non-distinct changes should be considered.
For example, if a commit is pushed to a branch that is not being watched and then later pushed to a watched branch, by default, this will be recorded as two separate changes.
In order to record a change only the first time the commit appears, you can use a custom ChangeFilter like this:
ChangeFilter(filter_fn=lambda c: c.properties.getProperty('github_distinct'))
For anything more complicated, a Python function can be defined to recognize the wanted strings:
def my_branch_fn(branch):
return branch in branches_to_build and branch not in branches_to_ignore
my_filter = util.ChangeFilter(branch_fn=my_branch_fn)
2.5.25.3. GitCredentialOptions
- class buildbot.util.GitCredentialOptions
The following parameters are supported by the GitCredentialOptions:
credentials(optional, a list of strings) Each element of the list must be in the git-credential input format and will be passed as input to
git credential approve.use_http_path(optional, a boolean) If provided, will set the credential.useHttpPath configuration to it’s value for commands that require credentials.
Examples
from buildbot.plugins import util
factory.addStep(steps.Git(
repourl='https://example.com/hello-world.git', mode='incremental',
git_credentials=util.GitCredentialOptions(
credentials=[
(
"url=https://example.com/hello-world.git\n"
"username=username\n"
"password=token\n"
),
],
),
))
This section outlines miscellaneous functionality that is useful for configuration but does not fit any other section.
2.5.26. Testing Utilities
2.5.26.1. Worker command expectations
TestBuildStepMixin is used to test steps and accepts command expectations to its
expect_commands method. These command expectations are instances of classes listed in this
page.
In all cases the arguments used to construct the expectation is what is expected to receive from the step under test. The methods called on the command are used to build a list of effects that the step will observe.
- class buildbot.test.steps.Expect
This class is the base class of all command expectation classes. It must not be instantiated by the user. It provides methods that are common to all command expectations.
- exit(code)
- Parameters:
code (int) – Exit code
Specifies command exit code sent to the step. In most cases
0signify success, other values signify failure.
- stdout(output)
- Parameters:
output – stdout output to send to the step. Must be an instance of
bytesorstr.
Specifies
stdoutstream in thestdiolog that is sent by the command to the step.
- stderr(output)
- Parameters:
output – stderr output to send to the step. Must be an instance of
bytesorstr.
Specifies
stderrstream in thestdiolog that is sent by the command to the step.
- log(name, **streams)
- Parameters:
name (str) – The name of the log.
streams (kwargs) – The log streams of the log streams. The most common are
stdoutandstderr. The values must be instances ofbytesorstr.
Specifies logs sent by the command to the step.
For
stdiolog andstdoutstream use thestdout()function.For
stdiolog andstderrstream use thestderr()function.
- error(error)
- Parameters:
error – An instance of an exception to throw when running the command.
Throws an exception when running the command. This is often used to simulate broken connection by throwing in an instance of
twisted.internet.error.ConnectionLost.
ExpectShell
- class buildbot.test.steps.ExpectShell(Expect)
This class represents a
shellcommand sent to the worker.Usually the stdout log produced by the command is specified by the
.stdoutmethod, the stderr log is specified by the.stderrmethod and the exit code is specified by the.exitmethod.ExpectShell(workdir='myworkdir', command=["my-test-command", "arg1", "arg2"]) .stdout(b'my sample output') .exit(0)
- __init__(workdir, command, env=None, want_stdout=1, want_stderr=1, initial_stdin=None, timeout=20 * 60, max_time=None, sigterm_time=None, logfiles=None, use_pty=None, log_environ=True, interrupt_signal=None)
Initializes the expectation.
ExpectStat
- class buildbot.test.steps.ExpectStat(Expect)
This class represents a
statcommand sent to the worker.Tests usually indicate the existence of the file by calling the
.exitmethod.- __init__(file, workdir=None, log_environ=None)
Initializes the expectation.
- stat(mode, inode=99, dev=99, nlink=1, uid=0, gid=0, size=99, atime=0, mtime=0, ctime=0)
Specifies
os.statresult that is sent back to the step.In most cases it’s more convenient to use
stat_fileorstat_dir.
- stat_file(mode=0, size=99, atime=0, mtime=0, ctime=0)
- Parameters:
mode (int) – Additional mode bits to set
Specifies
os.statresult of a regular file.
- stat_dir(mode=0, size=99, atime=0, mtime=0, ctime=0)
- Parameters:
mode (int) – Additional mode bits to set
Specifies
os.statresult of a directory.
ExpectUploadFile
- class buildbot.test.steps.ExpectUploadFile(Expect)
This class represents a
uploadFilecommand sent to the worker.- __init__(blocksize=None, maxsize=None, workersrc=None, workdir=None, writer=None, keepstamp=None, slavesrc=None, interrupted=False)
Initializes the expectation.
- upload_string(string, error=None)
- Parameters:
string (str) – The data of the file to sent to the step.
error (object) – An optional instance of an exception to raise to simulate failure to transfer data.
Specifies the data to send to the step.
ExpectDownloadFile
- class buildbot.test.steps.ExpectDownloadFile(Expect)
This class represents a
downloadFilecommand sent to the worker. Tests usually check what the step attempts to send to the worker by calling.download_stringand checking what data the supplied callable receives.- __init__(blocksize=None, maxsize=None, workerdest=None, workdir=None, reader=None, mode=None, interrupted=False, slavesrc=None, slavedest=None)
Initializes the expectation.
- download_string(dest_callable, size=1000)
- Parameters:
dest_callable (callable) – A callable to call with the data that is being sent from the step.
size (int) – The size of the data to read
Specifies the callable to store the data that the step wants the worker to download.
ExpectMkdir
ExpectRmdir
ExpectCpdir
ExpectRmfile
ExpectGlob
- class buildbot.test.steps.ExpectGlob(Expect)
This class represents a
mkdircommand sent to the worker.- __init__(path=None, log_environ=None)
Initializes the expectation.
- files(files=None)
- Parameters:
files (list) – An optional list of returned files.
Specifies the list of files returned to the step.
ExpectListdir
2.5.26.2. TestReactorMixin
- class buildbot.test.reactor.TestReactorMixin
The class
TestReactorMixinis used to create a faketwisted.internet.reactorin tests. This allows to mock the flow of time in tests. The fake reactor becomes available asself.reactorin the test case that mixes inTestReactorMixin.Call
self.reactor.advance(seconds)to advance the mocked time by the specified number of seconds.Call
self.reactor.pump(seconds_list)to advance the mocked time multiple times as if by callingadvance.For more information see the documentation of twisted.internet.task.Clock.
- setup_test_reactor(use_asyncio=False, auto_tear_down=True)
- Parameters:
use_asyncio (bool) – Whether to enable asyncio integration. This option has been deprecated and has no effect.
auto_tear_down (bool) – Whether to automatically tear down the test reactor. Setting it to
Falseis deprecated.
Call this function in the
setUp()of the test case to setup fake reactor.
- tear_down_test_reactor()
Call this function in the
tearDown()of the test case to tear down fake reactor. This function is deprecated. The function returns aDeferred.
2.5.26.3. TestBuildStepMixin
- class buildbot.test.steps.TestBuildStepMixin
The class
TestBuildStepMixinallows to test build steps. It mocks the connection to the worker. The commands sent to the worker can be verified and command results can be injected back into the step under test. Additionally, the step under test is modified to allow checking how the step runs and what results it produces.The following is an example of a basic step test:
class RemovePYCs(TestBuildStepMixin, TestReactorMixin, unittest.TestCase): @defer.inlineCallbacks def setUp(self): yield self.setup_test_reactor() yield self.setup_test_build_step() @defer.inlineCallbacks def test_run_ok(self): self.setup_step(python_twisted.RemovePYCs()) self.expect_commands( ExpectShell(workdir='wkdir', command=['find', '.', '-name', '\'*.pyc\'', '-exec', 'rm', '{}', ';']) .exit(0) ) self.expect_outcome(result=SUCCESS, state_string='remove .pycs') yield self.run_step()
Basic workflow is as follows:
The test case must derive from
TestReactorMixinand properly setup it.In
setUp()of test case callself.setup_test_build_step().- In unit test first optionally call
self.setup_build(...)function to setup information that will be available to the step during the test.
- In unit test first optionally call
In unit test call
self.setup_step(step)which will setup the step for testing.Call
self.expect_commands(commands)to specify commands that the step is expected to run and the results of these commands.Call various other
expect_*member functions to define other expectations.Call
self.run_step()to actually run the step.
All expectations are verified once the step has completed running.
- setup_test_build_step()
Call this function in the
setUp()method of the test case to setup step testing machinery.
- setup_build(worker_env=None, build_files=None)
- Parameters:
worker_env (dict) – An optional dictionary of environment variables on the mock worker.
build_files (list) – An optional list of source files that were changed in the build.
Sets up build and worker information that will be available to the tested step.
- setup_step(step, worker_env=None, build_files=None)
- Parameters:
step (BuildStep) – An instance of
BuildStepto test.worker_env (dict) – An optional dictionary of environment variables on the mock worker (deprecated).
build_files (list) – An optional list of source files that were changed in the build (deprecated).
- Returns:
An instance of prepared step (not the same as the
stepargument).
Prepares the given step for testing. This function may be invoked multiple times. The
stepargument is used as a step factory, just like in real Buildbot.
- step
(deprecated) The step under test. This attribute is available after
setup_step()is run.This function has been deprecated, use
get_nth_step(0)as a replacement
- get_nth_step(index)
- Parameters:
index (int) – The index of the step to retrieve
Retrieves the instance of a step that has been created by
setup_step().
- expect_commands(*commands)
- Parameters:
commands – A list of commands that are expected to be run (a subclass of
buildbot.test.steps.Expect).
Sets up an expectation of step sending the given commands to worker.
- expect_outcome(result, state_string=None)
- Parameters:
result – A result from buildbot.process.results.
state_string (str) – An optional status text.
Sets up an expectation of the step result. If there are multiple steps registered to the test, then there must be as many calls to
expect_outcomeas there are steps, in the same order.
- expect_property(property, value, source=None)
- Parameters:
property (str) – The name of the property
value (str) – The value of the property
source (str) – An optional source of the property
Sets up an expectation of a property set by the step. If there are multiple steps registered to the test, then this function tests the cumulative set of properties set on the build.
- expect_no_property(self, property)
- Parameters:
property (str) – The name of the property
Sets up an expectation of an absence of a property set by the step. If there are multiple steps registered to the test, then this function expects that no tests set the property.
- expect_log_file(self, logfile, contents, step_index=0)
- Parameters:
logfile (str) – The name of the log file
contents (str) – The contents of the log file
step_index (int) – The index of the step whose logs to investigate.
Sets up an expectation of a log file being produced by the step. Only the
stdoutassociated with the log file is checked. To check thestderrseeexpect_log_file_stderr()
- expect_log_file_stderr(self, logfile, contents, step_index=0)
- Parameters:
logfile (str) – The name of the log file
contents (str) – The contents of the log file
step_index (int) – The index of the step whose logs to investigate.
Sets up an expectation of a
stderroutput in log file being produced by the step.
- expect_build_data(name, value, source)
- Parameters:
name (str) – The name of the build data.
value (str) – The value of the build data.
source (str) – The source of the build data.
Sets up an expectation of build data produced by the step. If there are multiple steps registered to the test, then this function tests the cumulative set of build data added to the build.
- Parameters:
hidden (bool) – Whether the step should be hidden.
Sets up an expectation of step being hidden on completion.
- expect_exception(expection_class)
- Parameters:
expection_class – The type of the class to expect.
Sets up an expectation of an exception being raised during the runtime of the step. The expected result of the step is automatically set to
EXCEPTION.
- run_step()
Runs the steps and validates the expectations setup before this function.
This section outlives various utilities that are useful when testing configuration written for Buildbot.
Note
At this moment the APIs outlined here are experimental and subject to change.
TestBuildStepMixin - provides a framework for testing steps
TestReactorMixin - sets up test case with mock time
Command expectations:
ExpectShell - expects
shellcommandExpectStat - expects
statcommandExpectUploadFile - expects
uploadFilecommandExpectDownloadFile - expects
downloadFilecommandExpectMkdir - expects
mkdircommandExpectRmdir - expects
rmdircommandExpectCpdir - expects
cpdircommandExpectRmfile - expects
rmfilecommandExpectGlob - expects
globcommandExpectListdir - expects
listdircommand
2.6. Customization
For advanced users, Buildbot acts as a framework supporting a customized build application. For the most part, such configurations consist of subclasses set up for use in a regular Buildbot configuration file.
This chapter describes some of the more common idioms in advanced Buildbot configurations.
2.6.1. Programmatic Configuration Generation
Bearing in mind that master.cfg is a Python file, large configurations can be shortened
considerably by judicious use of Python loops. For example, the following will generate a builder
for each of a range of supported versions of Python:
pythons = ['python2.4', 'python2.5', 'python2.6', 'python2.7',
'python3.2', 'python3.3']
pytest_workers = ["worker%s" % n for n in range(10)]
for python in pythons:
f = util.BuildFactory()
f.addStep(steps.SVN(...))
f.addStep(steps.ShellCommand(command=[python, 'test.py']))
c['builders'].append(util.BuilderConfig(
name="test-%s" % python,
factory=f,
workernames=pytest_workers))
Next step would be the loading of pythons list from a .yaml/.ini file.
2.6.2. Collapse Request Functions
The logic Buildbot uses to decide which build request can be merged can be customized by providing
a Python function (a callable) instead of True or False described in
Collapsing Build Requests.
Arguments for the callable are:
masterpointer to the master object, which can be used to make additional data api calls via master.data.get
builderdictionary of type
builderreq1dictionary of type
buildrequestreq2dictionary of type
buildrequest
Warning
The number of invocations of the callable is proportional to the square of the request queue length, so a long-running callable may cause undesirable delays when the queue length grows.
It should return true if the requests can be merged, and False otherwise. For example:
@defer.inlineCallbacks
def collapseRequests(master, builder, req1, req2):
"any requests with the same branch can be merged"
# get the buildsets for each buildrequest
selfBuildset , otherBuildset = yield defer.gatherResults([
master.data.get(('buildsets', req1['buildsetid'])),
master.data.get(('buildsets', req2['buildsetid']))
])
selfSourcestamps = selfBuildset['sourcestamps']
otherSourcestamps = otherBuildset['sourcestamps']
if len(selfSourcestamps) != len(otherSourcestamps):
return False
for selfSourcestamp, otherSourcestamp in zip(selfSourcestamps, otherSourcestamps):
if selfSourcestamp['branch'] != otherSourcestamp['branch']:
return False
return True
c['collapseRequests'] = collapseRequests
In many cases, the details of the sourcestamp and buildrequest are important.
In the following example, only buildrequest with the same “reason” are merged; thus
developers forcing builds for different reasons will see distinct builds.
Note the use of the buildrequest.BuildRequest.canBeCollapsed method to access the source
stamp compatibility algorithm:
@defer.inlineCallbacks
def collapseRequests(master, builder, req1, req2):
canBeCollapsed = yield buildrequest.BuildRequest.canBeCollapsed(master, req1, req2)
if canBeCollapsed and req1.reason == req2.reason:
return True
else:
return False
c['collapseRequests'] = collapseRequests
Another common example is to prevent collapsing of requests coming from a Trigger step.
Trigger step can indeed be used in order to implement parallel testing of the same source.
Buildrequests will all have the same sourcestamp, but probably different properties, and shall not be collapsed.
Note
In most cases, just setting collapseRequests=False for triggered builders will do the trick.
In other cases, parent_buildid from buildset can be used:
@defer.inlineCallbacks
def collapseRequests(master, builder, req1, req2):
canBeCollapsed = yield buildrequest.BuildRequest.canBeCollapsed(master, req1, req2)
selfBuildset , otherBuildset = yield defer.gatherResults([
master.data.get(('buildsets', req1['buildsetid'])),
master.data.get(('buildsets', req2['buildsetid']))
])
if canBeCollapsed and selfBuildset['parent_buildid'] != None and \
otherBuildset['parent_buildid'] != None:
return True
else:
return False
c['collapseRequests'] = collapseRequests
If it’s necessary to perform some extended operation to determine whether two requests can be
merged, then the collapseRequests callable may return its result via Deferred.
Warning
Again, the number of invocations of the callable is proportional to the square of the request queue length, so a long-running callable may cause undesirable delays when the queue length grows.
For example:
@defer.inlineCallbacks
def collapseRequests(master, builder, req1, req2):
info1, info2 = yield defer.gatherResults([
getMergeInfo(req1),
getMergeInfo(req2),
])
return info1 == info2
c['collapseRequests'] = collapseRequests
2.6.3. Priorities
This section describes various priority functions that can be used to control the order in which builds are processed.
2.6.3.1. Builder Priority Functions
The prioritizeBuilders configuration key specifies a function which is called with two
arguments: a BuildMaster and a list of Builder objects. It should return a list
of the same Builder objects, in the desired order. It may also remove items from the list
if builds should not be started on those builders. If necessary, this function can return its
results via a Deferred (it is called with maybeDeferred).
A simple prioritizeBuilders implementation might look like this:
def prioritizeBuilders(buildmaster, builders):
"""Prioritize builders. 'finalRelease' builds have the highest
priority, so they should be built before running tests, or
creating builds."""
builderPriorities = {
"finalRelease": 0,
"test": 1,
"build": 2,
}
builders.sort(key=lambda b: builderPriorities.get(b.name, 0))
return builders
c['prioritizeBuilders'] = prioritizeBuilders
If the change frequency is higher than the turn-around of the builders, the following approach might be helpful:
from buildbot.util.async_sort import async_sort
from twisted.internet import defer
@defer.inlineCallbacks
def prioritizeBuilders(buildmaster, builders):
"""Prioritize builders. First, prioritize inactive builders.
Second, consider the last time a job was completed (no job is infinite past).
Third, consider the time the oldest request has been queued.
This provides a simple round-robin scheme that works with collapsed builds."""
def isBuilding(b):
return bool(b.building) or bool(b.old_building)
@defer.inlineCallbacks
def key(b):
newest_complete_time = yield b.getNewestCompleteTime()
if newest_complete_time is None:
newest_complete_time = datetime.datetime.min
oldest_request_time = yield b.getOldestRequestTime()
if oldest_request_time is None:
oldest_request_time = datetime.datetime.min
return (isBuilding(b), newest_complete_time, oldest_request_time)
yield async_sort(builders, key)
return builders
c['prioritizeBuilders'] = prioritizeBuilders
2.6.3.2. Build Priority Functions
When a builder has multiple pending build requests, it uses a nextBuild function to decide
which build it should start first. This function is given two parameters: the Builder, and
a list of BuildRequest objects representing pending build requests.
A simple function to prioritize release builds over other builds might look like this:
def nextBuild(bldr, requests):
for r in requests:
if r.source.branch == 'release':
return r
return requests[0]
If some non-immediate result must be calculated, the nextBuild function can also return a Deferred:
def nextBuild(bldr, requests):
d = get_request_priorities(requests)
def pick(priorities):
if requests:
return sorted(zip(priorities, requests))[0][1]
d.addCallback(pick)
return d
The nextBuild function is passed as parameter to BuilderConfig:
... BuilderConfig(..., nextBuild=nextBuild, ...) ...
2.6.3.3. Scheduler Priority Functions
When a Scheduler is creating a a new BuildRequest from a (list of)
Change (s),it is possible to set the BuildRequest priority. This can either be an
integer or a function, which receives a list of builder names and a dictionary of Change,
grouped by their codebase.
A simple implementation might look like this:
def scheduler_priority(builderNames, changesByCodebase):
priority = 0
for codebase, changes in changesByCodebase.items():
for chg in changes:
if chg["branch"].startswith("dev/"):
priority = max(priority, 0)
elif chg["branch"].startswith("bugfix/"):
priority = max(priority, 5)
elif chg["branch"] == "main":
priority = max(priority, 10)
return priority
The priority function/integer can be passed as a parameter to Scheduler:
... schedulers.SingleBranchScheduler(..., priority=scheduler_priority, ...) ...
2.6.4. canStartBuild Functions
Sometimes, you cannot know in advance what workers to assign to a BuilderConfig. For
example, you might need to check for the existence of a file on a worker before running a build on
it. It is possible to do that by setting the canStartBuild callback.
Here is an example that checks if there is a vm property set for the build request. If it is
set, it checks if a file named after it exists in the /opt/vm folder. If the file does not
exist on the given worker, refuse to run the build to force the master to select another worker.
@defer.inlineCallbacks
def canStartBuild(builder, wfb, request):
vm = request.properties.get('vm', builder.config.properties.get('vm'))
if vm:
args = {'file': os.path.join('/opt/vm', vm)}
cmd = RemoteCommand('stat', args, stdioLogName=None)
cmd.worker = wfb.worker
res = yield cmd.run(None, wfb.worker.conn, builder.name)
if res.rc != 0:
return False
return True
Here is a more complete example that checks if a worker is fit to start a build. If the load average is higher than the number of CPU cores or if there is less than 2GB of free memory, refuse to run the build on that worker. Also, put that worker in quarantine to make sure no other builds are scheduled on it for a while. Otherwise, let the build start on that worker.
class FakeBuild(object):
properties = Properties()
class FakeStep(object):
build = FakeBuild()
@defer.inlineCallbacks
def shell(command, worker, builder):
args = {
'command': command,
'logEnviron': False,
'workdir': worker.worker_basedir,
'want_stdout': False,
'want_stderr': False,
}
cmd = RemoteCommand('shell', args, stdioLogName=None)
cmd.worker = worker
yield cmd.run(FakeStep(), worker.conn, builder.name)
return cmd.rc
@defer.inlineCallbacks
def canStartBuild(builder, wfb, request):
# check that load is not too high
rc = yield shell(
'test "$(cut -d. -f1 /proc/loadavg)" -le "$(nproc)"',
wfb.worker, builder)
if rc != 0:
log.msg('loadavg is too high to take new builds',
system=repr(wfb.worker))
wfb.worker.putInQuarantine()
return False
# check there is enough free memory
sed_expr = r's/^MemAvailable:[[:space:]]+([0-9]+)[[:space:]]+kB$/\1/p'
rc = yield shell(
'test "$(sed -nre \'%s\' /proc/meminfo)" -gt 2000000' % sed_expr,
wfb.worker, builder)
if rc != 0:
log.msg('not enough free memory to take new builds',
system=repr(wfb.worker))
wfb.worker.putInQuarantine()
return False
# The build may now proceed.
#
# Prevent this worker from taking any other build while this one is
# starting for 2 min. This leaves time for the build to start consuming
# resources (disk, memory, cpu). When the quarantine is over, if the
# same worker is subject to start another build, the above checks will
# better reflect the actual state of the worker.
wfb.worker.quarantine_timeout = 120
wfb.worker.putInQuarantine()
# This does not take the worker out of quarantine, it only resets the
# timeout value to default.
wfb.worker.resetQuarantine()
return True
You can extend these examples using any remote command described in the Master-Worker API.
2.6.5. Customizing SVNPoller
Each source file that is tracked by a Subversion repository has a fully-qualified SVN URL in the
following form: (REPOURL)(PROJECT-plus-BRANCH)(FILEPATH). When you create the
SVNPoller, you give it a repourl value that includes all of the REPOURL
and possibly some portion of the PROJECT-plus-BRANCH string. The SVNPoller is
responsible for producing Changes that contain a branch name and a FILEPATH (which is
relative to the top of a checked-out tree). The details of how these strings are split up depend
upon how your repository names its branches.
2.6.5.1. PROJECT/BRANCHNAME/FILEPATH repositories
One common layout is to have all the various projects that share a repository get a single
top-level directory each, with branches, tags, and trunk subdirectories:
amanda/trunk
/branches/3_2
/3_3
/tags/3_2_1
/3_2_2
/3_3_0
To set up a SVNPoller that watches the Amanda trunk (and nothing else), we would use
the following, using the default split_file:
from buildbot.plugins import changes
c['change_source'] = changes.SVNPoller(
repourl="https://svn.amanda.sourceforge.net/svnroot/amanda/amanda/trunk")
In this case, every Change that our SVNPoller produces will have its branch attribute
set to None, to indicate that the Change is on the trunk. No other sub-projects or branches
will be tracked.
If we want our ChangeSource to follow multiple branches, we have to do two things. First we have to
change our repourl= argument to watch more than just amanda/trunk. We will set it to
amanda so that we’ll see both the trunk and all the branches. Second, we have to tell
SVNPoller how to split the (PROJECT-plus-BRANCH)(FILEPATH) strings it gets
from the repository out into (BRANCH) and (FILEPATH).
We do the latter by providing a split_file function. This function is responsible for splitting
something like branches/3_3/common-src/amanda.h into branch='branches/3_3' and
filepath='common-src/amanda.h'. The function is always given a string that names a file
relative to the subdirectory pointed to by the SVNPoller's repourl= argument. It
is expected to return a dictionary with at least the path key. The splitter may optionally set
branch, project and repository. For backwards compatibility it may return a tuple of
(branchname, path). It may also return None to indicate that the file is of no interest.
Note
The function should return branches/3_3 rather than just 3_3 because the SVN checkout
step, will append the branch name to the baseURL, which requires that we keep the
branches component in there. Other VC schemes use a different approach towards branches and
may not require this artifact.
If your repository uses this same {PROJECT}/{BRANCH}/{FILEPATH} naming scheme, the following
function will work:
def split_file_branches(path):
pieces = path.split('/')
if len(pieces) > 1 and pieces[0] == 'trunk':
return (None, '/'.join(pieces[1:]))
elif len(pieces) > 2 and pieces[0] == 'branches':
return ('/'.join(pieces[0:2]),
'/'.join(pieces[2:]))
else:
return None
In fact, this is the definition of the provided split_file_branches function.
So to have our Twisted-watching SVNPoller follow multiple branches, we would use this:
from buildbot.plugins import changes, util
c['change_source'] = changes.SVNPoller("svn://svn.twistedmatrix.com/svn/Twisted",
split_file=util.svn.split_file_branches)
Changes for all sorts of branches (with names like "branches/1.5.x", and None to indicate
the trunk) will be delivered to the Schedulers. Each Scheduler is then free to use or ignore each
branch as it sees fit.
If you have multiple projects in the same repository your split function can attach a project name to the Change to help the Scheduler filter out unwanted changes:
from buildbot.plugins import util
def split_file_projects_branches(path):
if not "/" in path:
return None
project, path = path.split("/", 1)
f = util.svn.split_file_branches(path)
if f:
info = {"project": project, "path": f[1]}
if f[0]:
info['branch'] = f[0]
return info
return f
Again, this is provided by default. To use it you would do this:
from buildbot.plugins import changes, util
c['change_source'] = changes.SVNPoller(
repourl="https://svn.amanda.sourceforge.net/svnroot/amanda/",
split_file=util.svn.split_file_projects_branches)
Note here that we are monitoring at the root of the repository, and that within that repository is
a amanda subdirectory which in turn has trunk and branches. It is that amanda
subdirectory whose name becomes the project field of the Change.
2.6.5.2. BRANCHNAME/PROJECT/FILEPATH repositories
Another common way to organize a Subversion repository is to put the branch name at the top, and the projects underneath. This is especially frequent when there are a number of related sub-projects that all get released in a group.
For example, Divmod.org hosts a project named Nevow as well as one named Quotient. In a
checked-out Nevow tree there is a directory named formless that contains a Python source file
named webform.py. This repository is accessible via webdav (and thus uses an http:
scheme) through the divmod.org hostname. There are many branches in this repository, and they use a
({BRANCHNAME})/({PROJECT}) naming policy.
The fully-qualified SVN URL for the trunk version of webform.py is
http://divmod.org/svn/Divmod/trunk/Nevow/formless/webform.py. The 1.5.x branch version of this
file would have a URL of http://divmod.org/svn/Divmod/branches/1.5.x/Nevow/formless/webform.py.
The whole Nevow trunk would be checked out with http://divmod.org/svn/Divmod/trunk/Nevow, while
the Quotient trunk would be checked out using http://divmod.org/svn/Divmod/trunk/Quotient.
Now suppose we want to have an SVNPoller that only cares about the Nevow trunk. This
case looks just like the PROJECT/BRANCH layout described earlier:
from buildbot.plugins import changes
c['change_source'] = changes.SVNPoller("http://divmod.org/svn/Divmod/trunk/Nevow")
But what happens when we want to track multiple Nevow branches? We have to point our repourl=
high enough to see all those branches, but we also don’t want to include Quotient changes (since
we’re only building Nevow). To accomplish this, we must rely upon the split_file function to
help us tell the difference between files that belong to Nevow and those that belong to Quotient,
as well as figuring out which branch each one is on.
from buildbot.plugins import changes
c['change_source'] = changes.SVNPoller("http://divmod.org/svn/Divmod",
split_file=my_file_splitter)
The my_file_splitter function will be called with repository-relative pathnames like:
trunk/Nevow/formless/webform.pyThis is a Nevow file, on the trunk. We want the Change that includes this to see a filename of
formless/webform.py, and a branch ofNonebranches/1.5.x/Nevow/formless/webform.pyThis is a Nevow file, on a branch. We want to get
branch='branches/1.5.x'andfilename='formless/webform.py'.trunk/Quotient/setup.pyThis is a Quotient file, so we want to ignore it by having
my_file_splitterreturnNone.branches/1.5.x/Quotient/setup.pyThis is also a Quotient file, which should be ignored.
The following definition for my_file_splitter will do the job:
def my_file_splitter(path):
pieces = path.split('/')
if pieces[0] == 'trunk':
branch = None
pieces.pop(0) # remove 'trunk'
elif pieces[0] == 'branches':
pieces.pop(0) # remove 'branches'
# grab branch name
branch = 'branches/' + pieces.pop(0)
else:
return None # something weird
projectname = pieces.pop(0)
if projectname != 'Nevow':
return None # wrong project
return {"branch": branch, "path": "/".join(pieces)}
If you later decide you want to get changes for Quotient as well you could replace the last 3 lines with simply:
return {"project": projectname, "branch": branch, "path": '/'.join(pieces)}
2.6.6. Writing Change Sources
For some version-control systems, making Buildbot aware of new changes can be a challenge. If the pre-supplied classes in Change Sources and Changes are not sufficient, then you will need to write your own.
There are three approaches, one of which is not even a change source. The first option is to write a change source that exposes some service to which the version control system can “push” changes. This can be more complicated, since it requires implementing a new service, but delivers changes to Buildbot immediately on commit.
The second option is often preferable to the first: implement a notification service in an external process (perhaps one that is started directly by the version control system, or by an email server) and delivers changes to Buildbot via PBChangeSource. This section does not describe this particular approach, since it requires no customization within the buildmaster process.
The third option is to write a change source which polls for changes - repeatedly connecting to an external service to check for new changes. This works well in many cases, but can produce a high load on the version control system if polling is too frequent, and can take too long to notice changes if the polling is not frequent enough.
2.6.6.1. Writing a Notification-based Change Source
A custom change source must implement buildbot.interfaces.IChangeSource.
The easiest way to do this is to subclass buildbot.changes.base.ChangeSource, implementing
the describe method to describe the instance. ChangeSource is a Twisted service,
so you will need to implement the startService and stopService methods to control
the means by which your change source receives notifications.
When the class does receive a change, it should call self.master.data.updates.addChange(..) to
submit it to the buildmaster. This method shares the same parameters as
master.db.changes.addChange, so consult the API documentation for that function for details on
the available arguments.
You will probably also want to set compare_attrs to the list of object attributes which
Buildbot will use to compare one change source to another when reconfiguring. During
reconfiguration, if the new change source is different from the old, then the old will be stopped
and the new started.
2.6.6.2. Writing a Change Poller
Polling is a very common means of seeking changes, so Buildbot supplies a utility parent class to
make it easier. A poller should subclass
buildbot.changes.base.ReconfigurablePollingChangeSource, which is a subclass of
ChangeSource. This subclass implements the Service methods,
and calls the poll method according to the pollInterval and pollAtLaunch options.
The poll method should return a Deferred to signal its completion.
Aside from the service methods, the other concerns in the previous section apply here, too.
2.6.7. Writing a New Latent Worker Implementation
Writing a new latent worker should only require subclassing
buildbot.worker.AbstractLatentWorker and implementing start_instance and
stop_instance at a minimum.
2.6.7.1. AbstractLatentWorker
- class buildbot.worker.AbstractLatentWorker
This class is the base class of all latent workers and implements some common functionality.
A custom worker should only need to override start_instance and stop_instance methods.
See buildbot.worker.ec2.EC2LatentWorker for an example.
Additionally, builds_may_be_incompatible and isCompatibleWithBuild members must be
overridden if some qualities of the new instances is determined dynamically according to the
properties of an incoming build. An example a build may require a certain Docker image or amount of
allocated memory. Overriding these members ensures that builds aren’t ran on incompatible workers
that have already been started.
- start_instance(self)
This method is responsible for starting instance that will try to connect with this master. A deferred should be returned.
Any problems should use an errback or exception. When the error is likely related to infrastructure problem and the worker should be paused in case it produces too many errors, then
LatentWorkerFailedToSubstantiateshould be thrown. When the error is related to the properties of the build request, such as renderable Docker image, thenLatentWorkerCannotSubstantiateshould be thrown.The callback value can be
None, or can be an iterable of short strings to include in the “substantiate success” status message, such as identifying the instance that started. Buildbot will ensure that a single worker will never have itsstart_instancecalled before any previous calls tostart_instanceorstop_instancefinish. Additionally, for eachstart_instancecall, exactly one corresponding call tostop_instancewill be done eventually.
- stop_instance(self, fast=False)
This method is responsible for shutting down instance. A deferred should be returned. If
fastisTruethen the function should call back as soon as it is safe to do so, as, for example, the master may be shutting down. The value returned by the callback is ignored. Buildbot will ensure that a single worker will never have itsstop_instancecalled before any previous calls tostop_instancefinish. During master shutdown any pending calls tostart_instanceorstop_instancewill be waited upon finish.
- builds_may_be_incompatible
Determines if new instances have qualities dependent on the build. If
True, the master will callisCompatibleWithBuildto determine whether new builds are compatible with the started instance. Unnecessarily settingbuilds_may_be_incompatibletoTruemay result in unnecessary overhead when processing the builds. By default, this isFalse.
- isCompatibleWithBuild(self, build_props)
This method determines whether a started instance is compatible with the build that is about to be started.
build_propsis the properties of the build that are known before the build has been started. A build may be incompatible with already started instance if, for example, it requests a different amount of memory or a different Docker image. A deferred should be returned, whose callback should returnTrueif build is compatible andFalseotherwise. The method may be called when the instance is not yet started and should indicate compatible build in that case. In the default implementation the callback returnsTrue.
- check_instance(self)
This method determines the health of an instance. The method is expected to return a tuple with two members:
is_goodandmessage. The first member identifies whether the instance is still valid. It should beFalseif the method determined that a serious error has occurred and worker will not connect to the master. In such case,messageshould identify any additional error message that should be displayed to Buildbot user.In case there is no additional messages,
messageshould be an empty string.Any exceptions raised from this method are interpreted as if the method returned
False.
2.6.8. Custom Build Classes
The standard BuildFactory object creates Build objects by default. These Builds
will each execute a collection of BuildSteps in a fixed sequence. Each step can affect
the results of the build, but in general there is little intelligence to tie the different steps
together.
By setting the factory’s buildClass attribute to a different class, you can instantiate a
different build class. This might be useful, for example, to create a build class that dynamically
determines which steps to run. The skeleton of such a project would look like:
class DynamicBuild(Build):
# override some methods
...
f = factory.BuildFactory()
f.buildClass = DynamicBuild
f.addStep(...)
2.6.9. Factory Workdir Functions
It is sometimes helpful to have a build’s workdir determined at runtime based on the parameters of
the build. To accomplish this, set the workdir attribute of the build factory to a
renderable.
There is deprecated support for setting workdir to a callable. That callable will be invoked
with the list of SourceStamp for the build, and should return the appropriate workdir.
Note that the value must be returned immediately - Deferreds are not supported.
This can be useful, for example, in scenarios with multiple repositories submitting changes to Buildbot. In this case you likely will want to have a dedicated workdir per repository, since otherwise a sourcing step with mode = “update” will fail as a workdir with a working copy of repository A can’t be “updated” for changes from a repository B. Here is an example how you can achieve workdir-per-repo:
def workdir(source_stamps):
return hashlib.md5(source_stamps[0].repository).hexdigest()[:8]
build_factory = factory.BuildFactory()
build_factory.workdir = workdir
build_factory.addStep(Git(mode="update"))
# ...
builders.append ({'name': 'mybuilder',
'workername': 'myworker',
'builddir': 'mybuilder',
'factory': build_factory})
The end result is a set of workdirs like
Repo1 => <worker-base>/mybuilder/a78890ba
Repo2 => <worker-base>/mybuilder/0823ba88
You could make the workdir function compute other paths, based on parts of the repo URL
in the sourcestamp, or lookup in a lookup table based on repo URL. As long as there is a permanent
1:1 mapping between repos and workdir, this will work.
2.6.10. Writing New BuildSteps
Warning
The API of writing custom build steps has changed significantly in Buildbot-0.9.0. See New-Style Build Steps in Buildbot 0.9.0 for details about what has changed since pre 0.9.0 releases. This section documents new-style steps.
While it is a good idea to keep your build process self-contained in the source code tree,
sometimes it is convenient to put more intelligence into your Buildbot configuration. One way to do
this is to write a custom BuildStep. Once written, this Step
can be used in the master.cfg file.
The best reason for writing a custom BuildStep is to better parse the results of the
command being run. For example, a BuildStep that knows about
JUnit could look at the logfiles to determine which tests had been run, how many passed and how
many failed, and then report more detailed information than a simple rc==0 -based good/bad
decision.
Buildbot has acquired a large fleet of build steps, and sports a number of knobs and hooks to make steps easier to write. This section may seem a bit overwhelming, but most custom steps will only need to apply one or two of the techniques outlined here.
For complete documentation of the build step interfaces, see BuildSteps.
2.6.10.1. Writing BuildStep Constructors
Build steps act as their own factories, so their constructors are a bit more complex than
necessary. The configuration file instantiates a BuildStep
object, but the step configuration must be re-used for multiple builds, so Buildbot needs some way
to create more steps.
Consider the use of a BuildStep in master.cfg:
f.addStep(MyStep(someopt="stuff", anotheropt=1))
This creates a single instance of class MyStep. However, Buildbot needs a new object each time
the step is executed. An instance of BuildStep remembers how
it was constructed, and can create copies of itself. When writing a new step class, then, keep in
mind that you cannot do anything “interesting” in the constructor – limit yourself to checking and
storing arguments.
It is customary to call the parent class’s constructor with all otherwise-unspecified keyword arguments.
Keep a **kwargs argument on the end of your options, and pass that up to the parent class’s constructor.
The whole thing looks like this:
class Frobnify(BuildStep):
def __init__(self,
frob_what="frobee",
frob_how_many=None,
frob_how=None,
**kwargs):
# check
if frob_how_many is None:
raise TypeError("Frobnify argument how_many is required")
# override a parent option
kwargs['parentOpt'] = 'xyz'
# call parent
super().__init__(**kwargs)
# set Frobnify attributes
self.frob_what = frob_what
self.frob_how_many = how_many
self.frob_how = frob_how
class FastFrobnify(Frobnify):
def __init__(self,
speed=5,
**kwargs):
super().__init__(**kwargs)
self.speed = speed
2.6.10.2. Step Execution Process
A step’s execution occurs in its run method. When
this method returns (more accurately, when the Deferred it returns fires), the step is complete.
The method’s result must be an integer, giving the result of the step. Any other output from the
step (logfiles, status strings, URLs, etc.) is the responsibility of the run method.
The ShellCommand class implements this run method, and in most cases steps
subclassing ShellCommand simply implement some of the subsidiary methods that its run
method calls.
2.6.10.3. Running Commands
To spawn a command in the worker, create a RemoteCommand
instance in your step’s run method and run it with
runCommand:
cmd = RemoteCommand(args)
d = self.runCommand(cmd)
The CommandMixin class offers a simple interface to several
common worker-side commands.
For the much more common task of running a shell command on the worker, use
ShellMixin. This class provides a method to handle the
myriad constructor arguments related to shell commands, as well as a method to create new
RemoteCommand instances. This mixin is the recommended
method of implementing custom shell-based steps. For simple steps that don’t involve much logic the
:bb:step:`ShellCommand is recommended.
A simple example of a step using the shell mixin is:
class RunCleanup(buildstep.ShellMixin, buildstep.BuildStep):
def __init__(self, cleanupScript='./cleanup.sh', **kwargs):
self.cleanupScript = cleanupScript
kwargs = self.setupShellMixin(kwargs, prohibitArgs=['command'])
super().__init__(**kwargs)
@defer.inlineCallbacks
def run(self):
cmd = yield self.makeRemoteShellCommand(
command=[self.cleanupScript])
yield self.runCommand(cmd)
if cmd.didFail():
cmd = yield self.makeRemoteShellCommand(
command=[self.cleanupScript, '--force'],
logEnviron=False)
yield self.runCommand(cmd)
return cmd.results()
@defer.inlineCallbacks
def run(self):
cmd = RemoteCommand(args)
log = yield self.addLog('output')
cmd.useLog(log, closeWhenFinished=True)
yield self.runCommand(cmd)
2.6.10.4. Updating Status Strings
Each step can summarize its current status in a very short string. For example, a compile step might display the file being compiled. This information can be helpful to users eager to see their build finish.
Similarly, a build has a set of short strings collected from its steps summarizing the overall
state of the build. Useful information here might include the number of tests run, but probably not
the results of a make clean step.
As a step runs, Buildbot calls its
getCurrentSummary method as necessary to get the
step’s current status. “As necessary” is determined by calls to
buildbot.process.buildstep.BuildStep.updateSummary. Your step should call this method
every time the status summary may have changed. Buildbot will take care of rate-limiting summary
updates.
When the step is complete, Buildbot calls its
getResultSummary method to get a final summary of
the step along with a summary for the build.
2.6.10.5. About Logfiles
Each BuildStep has a collection of log files. Each one has a short name, like stdio or
warnings. Each log file contains an arbitrary amount of text, usually the contents of some output
file generated during a build or test step, or a record of everything that was printed to
stdout/stderr during the execution of some command.
Each can contain multiple channels, generally limited to three basic ones: stdout, stderr, and
headers. For example, when a shell command runs, it writes a few lines to the headers channel to
indicate the exact argv strings being run, which directory the command is being executed in, and
the contents of the current environment variables. Then, as the command runs, it adds a lot of
stdout and stderr messages. When the command finishes, a final header line is
added with the exit code of the process.
Status display plugins can format these different channels in different ways. For example, the web page shows log files as text/html, with header lines in blue text, stdout in black, and stderr in red. A different URL is available which provides a text/plain format, in which stdout and stderr are collapsed together, and header lines are stripped completely. This latter option makes it easy to save the results to a file and run grep or whatever against the output.
2.6.10.6. Writing Log Files
Most commonly, logfiles come from commands run on the worker. Internally, these are configured by
supplying the RemoteCommand instance with log files via
the useLog method:
@defer.inlineCallbacks
def run(self):
...
log = yield self.addLog('stdio')
cmd.useLog(log, closeWhenFinished=True, 'stdio')
yield self.runCommand(cmd)
The name passed to useLog must match that
configured in the command. In this case, stdio is the default.
If the log file was already added by another part of the step, it can be retrieved with
getLog:
stdioLog = self.getLog('stdio')
Less frequently, some master-side processing produces a log file. If this log file is short and
easily stored in memory, this is as simple as a call to
addCompleteLog:
@defer.inlineCallbacks
def run(self):
...
summary = u'\n'.join('%s: %s' % (k, count)
for (k, count) in self.lint_results.items())
yield self.addCompleteLog('summary', summary)
Note that the log contents must be a unicode string.
Longer logfiles can be constructed line-by-line using the add methods of the log file:
@defer.inlineCallbacks
def run(self):
...
updates = yield self.addLog('updates')
while True:
...
yield updates.addStdout(some_update)
Again, note that the log input must be a unicode string.
Finally, addHTMLLog is similar to
addCompleteLog, but the resulting log will be tagged
as containing HTML. The web UI will display the contents of the log using the browser.
The logfiles= argument to ShellCommand and its subclasses creates new log files and
fills them in realtime by asking the worker to watch an actual file on disk. The worker will look
for additions in the target file and report them back to the BuildStep. These additions
will be added to the log file by calling addStdout.
All log files can be used as the source of a LogObserver
just like the normal stdio LogFile. In fact, it’s possible for one
LogObserver to observe a logfile created by another.
2.6.10.7. Reading Logfiles
For the most part, Buildbot tries to avoid loading the contents of a log file into memory as a single string. For large log files on a busy master, this behavior can quickly consume a great deal of memory.
Instead, steps should implement a LogObserver to examine log
files one chunk or line at a time.
For commands which only produce a small quantity of output,
RemoteCommand will collect the command’s stdout into its
stdout attribute if given the
collectStdout=True constructor argument.
2.6.10.8. Adding LogObservers
Most shell commands emit messages to stdout or stderr as they operate, especially if you ask them
nicely with a option –verbose flag of some sort. They may also write text to a log file while
they run. Your BuildStep can watch this output as it arrives, to keep track of how much
progress the command has made or to process log output for later summarization.
To accomplish this, you will need to attach a LogObserver to
the log. This observer is given all text as it is emitted from the command, and has the opportunity
to parse that output incrementally.
There are a number of pre-built LogObserver classes that you
can choose from (defined in buildbot.process.buildstep, and of course you can subclass them
to add further customization. The LogLineObserver class handles the grunt work of
buffering and scanning for end-of-line delimiters, allowing your parser to operate on complete
stdout/stderr lines.
For example, let’s take a look at the TrialTestCaseCounter, which is used by the
Trial step to count test cases as they are run. As Trial executes, it emits lines like
the following:
buildbot.test.test_config.ConfigTest.testDebugPassword ... [OK]
buildbot.test.test_config.ConfigTest.testEmpty ... [OK]
buildbot.test.test_config.ConfigTest.testIRC ... [FAIL]
buildbot.test.test_config.ConfigTest.testLocks ... [OK]
When the tests are finished, trial emits a long line of ====== and then some lines which summarize the tests that failed. We want to avoid parsing these trailing lines, because their format is less well-defined than the [OK] lines.
A simple version of the parser for this output looks like this. The full version is in master/buildbot/steps/python_twisted.py.
from buildbot.plugins import util
class TrialTestCaseCounter(util.LogLineObserver):
_line_re = re.compile(r'^([\w\.]+) \.\.\. \[([^\]]+)\]$')
numTests = 0
finished = False
def outLineReceived(self, line):
if self.finished:
return
if line.startswith("=" * 40):
self.finished = True
return
m = self._line_re.search(line.strip())
if m:
testname, result = m.groups()
self.numTests += 1
self.step.setProgress('tests', self.numTests)
This parser only pays attention to stdout, since that’s where trial writes the progress lines. It
has a mode flag named finished to ignore everything after the ==== marker, and a
scary-looking regular expression to match each line while hopefully ignoring other messages that
might get displayed as the test runs.
Each time it identifies that a test has been completed, it increments its counter and delivers the
new progress value to the step with self.step.setProgress. This helps Buildbot to determine the
ETA for the step.
To connect this parser into the Trial build step, Trial.__init__ ends with the following clause:
# this counter will feed Progress along the 'test cases' metric
counter = TrialTestCaseCounter()
self.addLogObserver('stdio', counter)
self.progressMetrics += ('tests',)
This creates a TrialTestCaseCounter and tells the step that the counter wants to watch the
stdio log. The observer is automatically given a reference to the step in its step
attribute.
2.6.10.9. Using Properties
In custom BuildSteps, you can get and set the build properties with the
getProperty and setProperty methods. Each takes a string for the name of the
property, and returns or accepts an arbitrary JSON-able (lists, dicts, strings, and numbers)
object. For example:
class MakeTarball(buildstep.ShellMixin, buildstep.BuildStep):
def __init__(self, **kwargs):
kwargs = self.setupShellMixin(kwargs)
super().__init__(**kwargs)
@defer.inlineCallbacks
def run(self):
if self.getProperty("os") == "win":
# windows-only command
cmd = yield self.makeRemoteShellCommand(commad=[ ... ])
else:
# equivalent for other systems
cmd = yield self.makeRemoteShellCommand(commad=[ ... ])
yield self.runCommand(cmd)
return cmd.results()
Remember that properties set in a step may not be available until the next step begins. In
particular, any Property or Interpolate instances for the current step are
interpolated before the step starts, so they cannot use the value of any properties determined in
that step.
2.6.10.10. Using Statistics
Statistics can be generated for each step, and then summarized across all steps in a build. For
example, a test step might set its warnings statistic to the number of warnings observed. The
build could then sum the warnings on all steps to get a total number of warnings.
Statistics are set and retrieved with the
setStatistic and
getStatistic methods. The
hasStatistic method determines whether a statistic
exists.
The Build method getSummaryStatistic can be used to
aggregate over all steps in a Build.
2.6.10.11. BuildStep URLs
Each BuildStep has a collection of links. Each has a name and a target URL. The web display displays clickable links for each link, making them a useful way to point to extra information about a step. For example, a step that uploads a build result to an external service might include a link to the uploaded file.
To set one of these links, the BuildStep should call the
addURL method with the name of the link and the
target URL. Multiple URLs can be set. For example:
@defer.inlineCallbacks
def run(self):
... # create and upload report to coverage server
url = 'http://coverage.example.com/reports/%s' % reportname
yield self.addURL('coverage', url)
This also works from log observers, which is helpful for instance if the build output points to an external page such as a detailed log file. The following example parses output of poudriere, a tool for building packages on the FreeBSD operating system.
Example output:
[00:00:00] Creating the reference jail... done
...
[00:00:01] Logs: /usr/local/poudriere/data/logs/bulk/103amd64-2018Q4/2018-10-03_05h47m30s
...
... build log without details (those are in the above logs directory) ...
Log observer implementation:
c = BuildmasterConfig = {}
c['titleURL'] = 'https://my-buildbot.example.com/'
# ...
class PoudriereLogLinkObserver(util.LogLineObserver):
_regex = re.compile(
r'Logs: /usr/local/poudriere/data/logs/bulk/([-_/0-9A-Za-z]+)$')
def __init__(self):
super().__init__()
self._finished = False
def outLineReceived(self, line):
# Short-circuit if URL already found
if self._finished:
return
m = self._regex.search(line.rstrip())
if m:
self._finished = True
# Let's assume local directory /usr/local/poudriere/data/logs/bulk
# is available as https://my-buildbot.example.com/poudriere/logs
poudriere_ui_url = c['titleURL'] + 'poudriere/logs/' + m.group(1)
# Add URLs for build overview page and for per-package log files
self.step.addURL('Poudriere build web interface', poudriere_ui_url)
self.step.addURL('Poudriere logs', poudriere_ui_url + '/logs/')
2.6.10.12. Discovering files
When implementing a BuildStep it may be necessary to know about files that are created
during the build. There are a few worker commands that can be used to find files on the worker and
test for the existence (and type) of files and directories.
The worker provides the following file-discovery related commands:
stat calls
os.statfor a file in the worker’s build directory. This can be used to check if a known file exists and whether it is a regular file, directory or symbolic link.listdir calls
os.listdirfor a directory on the worker. It can be used to obtain a list of files that are present in a directory on the worker.glob calls
glob.globon the worker, with a given shell-style pattern containing wildcards.
For example, we could use stat to check if a given path exists and contains *.pyc files. If the
path does not exist (or anything fails) we mark the step as failed; if the path exists but is not a
directory, we mark the step as having “warnings”.
from buildbot.plugins import steps, util
from buildbot.process import remotecommand
from buildbot.interfaces import WorkerSetupError
import stat
class MyBuildStep(steps.BuildStep):
def __init__(self, dirname, **kwargs):
super().__init__(**kwargs)
self.dirname = dirname
@defer.inlineCallbacks
def run(self):
# make sure the worker knows about stat
workerver = (self.workerVersion('stat'),
self.workerVersion('glob'))
if not all(workerver):
raise WorkerSetupError('need stat and glob')
cmd = remotecommand.RemoteCommand('stat', {'file': self.dirname})
yield self.runCommand(cmd)
if cmd.didFail():
self.description = ["File not found."]
return util.FAILURE
s = cmd.updates["stat"][-1]
if not stat.S_ISDIR(s[stat.ST_MODE]):
self.description = ["'tis not a directory"]
return util.WARNINGS
cmd = remotecommand.RemoteCommand('glob', {'path': self.dirname + '/*.pyc'})
yield self.runCommand(cmd)
if cmd.didFail():
self.description = ["Glob failed."]
return util.FAILURE
files = cmd.updates["files"][-1]
if len(files):
self.description = ["Found pycs"] + files
else:
self.description = ["No pycs found"]
return util.SUCCESS
For more information on the available commands, see Master-Worker API.
Todo
Step Progress BuildStepFailed
2.6.11. Writing Dashboards with Flask or Bottle
Buildbot UI is written in Javascript. This allows it to be reactive and real time, but comes at a price of a fair complexity.
There is a Buildbot plugin which allows to write a server side generated dashboard, and integrate it in the UI.
pip install buildbot_wsgi_dashboards flask
This plugin can use any WSGI compatible web framework, Flask is a very common one, Bottle is another popular option.
The application needs to implement a /index.html route, which will render the html code representing the dashboard.
The application framework runs in a thread outside of Twisted. No need to worry about Twisted and asynchronous code. You can use python-requests or any library from the python ecosystem to access other servers.
You could use HTTP in order to access Buildbot REST API, but you can also use the Data API, via the provided synchronous wrapper.
- buildbot_api.dataGet(path, filters=None, fields=None, order=None, limit=None, offset=None)
- Parameters:
path (tuple) – A tuple of path elements representing the API path to fetch. Numbers can be passed as strings or integers.
filters – result spec filters
fields – result spec fields
order – result spec order
limit – result spec limit
offset – result spec offset
- Raises:
- Returns:
a resource or list, or None
This is a blocking wrapper to master.data.get as described in Data API. The available paths are described in the REST API, as well as the nature of return values depending on the kind of data that is fetched. Path can be either the REST path e.g.
"builders/2/builds/4"or tuple e.g.("builders", 2, "builds", 4). The latter form being more convenient if some path parts are coming from variables. The Data API and REST API are functionally equivalent except:
Data API does not have HTTP connection overhead.
buildbot_api.dataGetis accessible via the WSGI application object passed towsgi_dashboardsplugin (as per the example).
That html code output of the server runs inside React application.
It will use the CSS of the React application (including the Bootstrap CSS base). You can use custom style-sheet with a standard
styletag within your html. Custom CSS will be shared with the whole Buildbot application once your dashboard is loaded. So you should make sure your custom CSS rules only apply to your dashboard (e.g. by having a specific class for your dashboard’s main div)It has full access to the application JS context.
The WSGI plugin can be registered as follows:
dashboardapp = Flask('test', root_path=os.path.dirname(__file__))
# this allows to work on the template without having to restart Buildbot
dashboardapp.config['TEMPLATES_AUTO_RELOAD'] = True
@dashboardapp.route("/index.html")
def main():
# This code fetches build data from the data api, and give it to the
builders = dashboardapp.buildbot_api.dataGet("/builders")
builds = dashboardapp.buildbot_api.dataGet("/builds", limit=20)
# properties are actually not used in the template example, but this is
# how you get more properties
for build in builds:
build['properties'] = dashboardapp.buildbot_api.dataGet(
("builds", build['buildid'], "properties")
)
graph_data = [
{'x': 1, 'y': 100},
{'x': 2, 'y': 200},
{'x': 3, 'y': 300},
{'x': 4, 'y': 0},
{'x': 5, 'y': 100},
]
# dashboard.html is a template inside the template directory
return render_template('dashboard.html', builders=builders, builds=builds,
graph_data=graph_data)
c['www']['plugins']['wsgi_dashboards'] = [
{
'name': 'dashboard',
'caption': 'Test Dashboard', # Text shown in the menu
'app': dashboardapp,
# Priority of the menu item in the menu (lower is higher in the menu)
'order': 5,
# An icon from https://react-icons.github.io/react-icons/icons/fa/
'icon': 'FaChartArea'
}
]
2.6.12. A Somewhat Whimsical Example (or “It’s now customized, how do I deploy it?”)
Let’s say that we’ve got some snazzy new unit-test framework called Framboozle. It’s the hottest thing since sliced bread. It slices, it dices, it runs unit tests like there’s no tomorrow. Plus if your unit tests fail, you can use its name for a Web 2.1 startup company, make millions of dollars, and hire engineers to fix the bugs for you, while you spend your afternoons lazily hang-gliding along a scenic pacific beach, blissfully unconcerned about the state of your tests. [1]
To run a Framboozle-enabled test suite, you just run the ‘framboozler’ command from the top of your source code tree. The ‘framboozler’ command emits a bunch of stuff to stdout, but the most interesting bit is that it emits the line “FNURRRGH!” every time it finishes running a test case You’d like to have a test-case counting LogObserver that watches for these lines and counts them, because counting them will help the buildbot more accurately calculate how long the build will take, and this will let you know exactly how long you can sneak out of the office for your hang-gliding lessons without anyone noticing that you’re gone.
This will involve writing a new BuildStep (probably named “Framboozle”) which inherits
from ShellCommand. The BuildStep class definition itself will look something
like this:
from buildbot.plugins import steps, util
class FNURRRGHCounter(util.LogLineObserver):
numTests = 0
def outLineReceived(self, line):
if "FNURRRGH!" in line:
self.numTests += 1
self.step.setProgress('tests', self.numTests)
class Framboozle(steps.ShellCommand):
command = ["framboozler"]
def __init__(self, **kwargs):
super().__init__(**kwargs) # always upcall!
counter = FNURRRGHCounter()
self.addLogObserver('stdio', counter)
self.progressMetrics += ('tests',)
So that’s the code that we want to wind up using. How do we actually deploy it?
You have a number of different options:
2.6.12.1. Inclusion in the master.cfg file
The simplest technique is to simply put the step class definitions in your master.cfg file,
somewhere before the BuildFactory definition where you actually use it in a clause like:
f = BuildFactory()
f.addStep(SVN(repourl="stuff"))
f.addStep(Framboozle())
Remember that master.cfg is secretly just a Python program with one job: populating the
BuildmasterConfig dictionary. And Python programs are allowed to define as many classes as
they like. So you can define classes and use them in the same file, just as long as the class is
defined before some other code tries to use it.
This is easy, and it keeps the point of definition very close to the point of use, and whoever replaces you after that unfortunate hang-gliding accident will appreciate being able to easily figure out what the heck this stupid “Framboozle” step is doing anyways. The downside is that every time you reload the config file, the Framboozle class will get redefined, which means that the buildmaster will think that you’ve reconfigured all the Builders that use it, even though nothing changed. Bleh.
2.6.12.2. Python file somewhere on the system
Instead, we can put this code in a separate file, and import it into the master.cfg file just like
we would the normal buildsteps like ShellCommand and SVN.
Create a directory named ~/lib/python, put the step class definitions in
~/lib/python/framboozle.py, and run your buildmaster using:
PYTHONPATH=~/lib/python buildbot start MASTERDIR
or use the Makefile.buildbot to control the way buildbot start works.
Or add something like this to something like your ~/.bashrc or ~/.bash_profile or ~/.cshrc:
export PYTHONPATH=~/lib/python
Once we’ve done this, our master.cfg can look like:
from framboozle import Framboozle
f = BuildFactory()
f.addStep(SVN(repourl="stuff"))
f.addStep(Framboozle())
or:
import framboozle
f = BuildFactory()
f.addStep(SVN(repourl="stuff"))
f.addStep(framboozle.Framboozle())
(check out the Python docs for details about how import and from A import B work).
What we’ve done here is to tell Python that every time it handles an “import” statement for some
named module, it should look in our ~/lib/python/ for that module before it looks anywhere
else. After our directories, it will try in a bunch of standard directories too (including the one
where buildbot is installed). By setting the PYTHONPATH environment variable, you can add
directories to the front of this search list.
Python knows that once it “import”s a file, it doesn’t need to re-import it again. This means that
reconfiguring the buildmaster (with buildbot reconfig, for example) won’t make it think the
Framboozle class has changed every time, so the Builders that use it will not be spuriously
restarted. On the other hand, you either have to start your buildmaster in a slightly weird way, or
you have to modify your environment to set the PYTHONPATH variable.
2.6.12.3. Install this code into a standard Python library directory
Find out what your Python’s standard include path is by asking it:
80:warner@luther% python
Python 2.4.4c0 (#2, Oct 2 2006, 00:57:46)
[GCC 4.1.2 20060928 (prerelease) (Debian 4.1.1-15)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> import pprint
>>> pprint.pprint(sys.path)
['',
'/usr/lib/python24.zip',
'/usr/lib/python2.4',
'/usr/lib/python2.4/plat-linux2',
'/usr/lib/python2.4/lib-tk',
'/usr/lib/python2.4/lib-dynload',
'/usr/local/lib/python2.4/site-packages',
'/usr/lib/python2.4/site-packages',
'/usr/lib/python2.4/site-packages/Numeric',
'/var/lib/python-support/python2.4',
'/usr/lib/site-python']
In this case, putting the code into /usr/local/lib/python2.4/site-packages/framboozle.py
would work just fine. We can use the same master.cfg import framboozle statement as in
Option 2. By putting it in a standard include directory (instead of the decidedly non-standard
~/lib/python), we don’t even have to set PYTHONPATH to anything special. The
downside is that you probably have to be root to write to one of those standard include
directories.
2.6.12.4. Distribute a Buildbot Plug-In
First of all, you must prepare a Python package (if you do not know what that is, please check How to package Buildbot plugins, where you can find a couple of pointers to tutorials).
When you have a package, you will have a special file called setup.py.
This file needs to be updated to include a pointer to your new step:
setup(
...
entry_points = {
...,
'buildbot.steps': [
'Framboozle = framboozle:Framboozle'
]
},
...
)
Where:
buildbot.stepsis the kind of plugin you offer (more information about possible kinds you can find in How to package Buildbot plugins)framboozle:Framboozleconsists of two parts:framboozleis the name of the Python module where to look forFramboozleclass, which implements the pluginFramboozleis the name of the plugin.This will allow users of your plugin to use it just like any other Buildbot plugins:
from buildbot.plugins import steps ... steps.Framboozle ...
Now you can upload it to PyPI where other people can download it from and use in their build systems. Once again, the information about how to prepare and upload a package to PyPI can be found in tutorials listed in How to package Buildbot plugins.
2.6.12.5. Submit the code for inclusion in the Buildbot distribution
Make a fork of buildbot on http://github.com/buildbot/buildbot or post a patch in a bug at http://trac.buildbot.net/. In either case, post a note about your patch to the mailing list, so others can provide feedback and, eventually, commit it.
When it’s committed to the master, the usage is the same as in the previous approach:
from buildbot.plugins import steps, util
...
f = util.BuildFactory()
f.addStep(steps.SVN(repourl="stuff"))
f.addStep(steps.Framboozle())
...
And then you don’t even have to install framboozle.py anywhere on your system, since it
will ship with Buildbot. You don’t have to be root, you don’t have to set PYTHONPATH. But
you do have to make a good case for Framboozle being worth going into the main distribution, you’ll
probably have to provide docs and some unit test cases, you’ll need to figure out what kind of beer
the author likes (IPA’s and Stouts for Dustin), and then you’ll have to wait until the next
release. But in some environments, all this is easier than getting root on your buildmaster box, so
the tradeoffs may actually be worth it.
2.6.12.6. Summary
Putting the code in master.cfg (1) makes it available to that buildmaster instance. Putting it in a file in a personal library directory (2) makes it available for any buildmasters you might be running. Putting it in a file in a system-wide shared library directory (3) makes it available for any buildmasters that anyone on that system might be running. Getting it into the buildbot’s upstream repository (4) makes it available for any buildmasters that anyone in the world might be running. It’s all a matter of how widely you want to deploy that new class.
2.7. Command-line Tool
This section describes command-line tools available after buildbot installation.
The two main command-line tools are buildbot and buildbot-worker. The former handles a Buildbot master and the former handles a Buildbot worker.
Every command-line tool has a list of global options and a set of commands which have their own options. One can run these tools in the following way:
buildbot [global options] command [command options]
buildbot-worker [global options] command [command options]
The buildbot command is used on the master, while buildbot-worker is used on the worker.
Global options are the same for both tools which perform the following actions:
- --help
Print general help about available commands and global options and exit. All subsequent arguments are ignored.
- --verbose
Set verbose output.
- --version
Print current buildbot version and exit. All subsequent arguments are ignored.
You can get help on any command by specifying --help as a command option:
buildbot command --help
You can also use manual pages for buildbot and buildbot-worker for quick reference on command-line options.
The remainder of this section describes each buildbot command. See Command Line Index for a full list.
2.7.1. buildbot
The buildbot command-line tool can be used to start or stop a buildmaster or buildbot, and to interact with a running buildmaster. Some of its subcommands are intended for buildmaster admins, while some are for developers who are editing the code that the buildbot is monitoring.
2.7.1.1. Administrator Tools
The following buildbot sub-commands are intended for buildmaster administrators:
create-master
buildbot create-master -r {BASEDIR}
This creates a new directory and populates it with files that allow it to be used as a buildmaster’s base directory.
You will usually want to use the option -r option to create a relocatable buildbot.tac.
This allows you to move the master directory without editing this file.
upgrade-master
buildbot upgrade-master {BASEDIR}
This upgrades a previously created buildmaster’s base directory for a new version of buildbot master source code. This will copy the web server static files, and potentially upgrade the db.
start
buildbot start [--nodaemon] {BASEDIR}
This starts a buildmaster which was already created in the given base directory.
The daemon is launched in the background, with events logged to a file named twistd.log.
The option –nodaemon option instructs Buildbot to skip daemonizing. The process will start in the foreground. It will only return to the command-line when it is stopped.
Additionally, the user can set the environment variable START_TIMEOUT to specify the amount of time the script waits for the master to start until it declares the operation as failure.
restart
buildbot restart [--nodaemon] {BASEDIR}
Restart the buildmaster.
This is equivalent to stop followed by start
The option –nodaemon option has the same meaning as for start.
stop
buildbot stop {BASEDIR}
This terminates the daemon (either buildmaster or worker) running in the given directory. The
--clean option shuts down the buildmaster cleanly. With --no-wait option buildbot stop
command will send buildmaster shutdown signal and will immediately exit, not waiting for complete
buildmaster shutdown.
sighup
buildbot sighup {BASEDIR}
This sends a SIGHUP to the buildmaster running in the given directory, which causes it to re-read
its master.cfg file.
checkconfig
buildbot checkconfig {BASEDIR|CONFIG_FILE}
This checks if the buildmaster configuration is well-formed and contains no deprecated or invalid
elements. If no arguments are used or the base directory is passed as the argument the config file
specified in buildbot.tac is checked. If the argument is the path to a config file then it
will be checked without using the buildbot.tac file.
cleanupdb
buildbot cleanupdb {BASEDIR|CONFIG_FILE} [-q]
This command is frontend for various database maintenance jobs:
optimiselogs: This optimization groups logs into bigger chunks to apply higher level of compression.
This script runs for as long as it takes to finish the job including the time needed to check master.cfg file.
copy-db
buildbot copy-db {DESTINATION_URL} {BASEDIR} [-q]
This command copies all buildbot data from source database configured in the buildbot configuration file to the destination database. The URL of the destination database is specified on the command line. The destination database may have different type from the source database.
The destination database must be empty. The script will initialize it in the same way as if a new Buildbot installation was created.
Source database must be already upgraded to the current Buildbot version by the
buildbot upgrade-master command.
2.7.1.2. Developer Tools
These tools are provided for use by the developers who are working on the code that the buildbot is monitoring.
try
This lets a developer to ask the question What would happen if I committed this patch right now?.
It runs the unit test suite (across multiple build platforms) on the developer’s current code,
allowing them to make sure they will not break the tree when they finally commit their changes.
The buildbot try command is meant to be run from within a developer’s local tree, and starts by
figuring out the base revision of that tree (what revision was current the last time the tree was
updated), and a patch that can be applied to that revision of the tree to make it match the
developer’s copy. This (revision, patch) pair is then sent to the buildmaster, which runs a
build with that SourceStamp. If you want, the tool will emit status messages as the builds
run, and will not terminate until the first failure has been detected (or the last success).
There is an alternate form which accepts a pre-made patch file (typically the output of a command like svn diff).
This --diff form does not require a local tree to run from.
See try –diff concerning the --diff command option.
For this command to work, several pieces must be in place: the Try_Jobdir or
:Try_Userpass, as well as some client-side configuration.
Locating the master
The try command needs to be told how to connect to the try scheduler, and must know
which of the authentication approaches described above is in use by the buildmaster. You specify
the approach by using --connect=ssh or --connect=pb (or try_connect = 'ssh' or
try_connect = 'pb' in .buildbot/options).
For the PB approach, the command must be given a option –master argument (in the form
HOST:PORT) that points to TCP port that you picked in the Try_Userpass
scheduler. It also takes a option –username and option –passwd pair of arguments that match
one of the entries in the buildmaster’s userpass list. These arguments can also be provided as
try_master, try_username, and try_password entries in the .buildbot/options
file.
For the SSH approach, the command must be given option –host and option –username, to get to
the buildmaster host. It must also be given option –jobdir, which points to the inlet directory
configured above. The jobdir can be relative to the user’s home directory, but most of the time you
will use an explicit path like ~buildbot/project/trydir. These arguments can be provided in
.buildbot/options as try_host, try_username, try_password, and try_jobdir.
If you need to use something different from the default ssh command for
connecting to the remote system, you can use –ssh command line option or
try_ssh in the configuration file.
The SSH approach also provides a option –buildbotbin argument to allow specification of the
buildbot binary to run on the buildmaster. This is useful in the case where buildbot is installed
in a virtualenv on the buildmaster host, or in other
circumstances where the buildbot command is not on the path of the user given by option
–username. The option –buildbotbin argument can be provided in .buildbot/options as
try_buildbotbin
The following command line arguments are deprecated, but retained for backward compatibility:
- --tryhost
is replaced by option –host
- --trydir
is replaced by option –jobdir
- --master
is replaced by option –masterstatus
Likewise, the following .buildbot/options file entries are deprecated, but retained for
backward compatibility:
try_diris replaced bytry_jobdir
masterstatusis replaced bytry_masterstatus
Waiting for results
If you provide the option –wait option (or try_wait = True in .buildbot/options),
the buildbot try command will wait until your changes have either been proven good or bad
before exiting. Unless you use the option –quiet option (or try_quiet=True), it will emit a
progress message every 60 seconds until the builds have completed.
The SSH connection method does not support waiting for results.
Choosing the Builders
A trial build is performed on multiple Builders at the same time, and the developer gets to choose
which Builders are used (limited to a set selected by the buildmaster admin with the
TryScheduler’s builderNames= argument). The set you choose will depend upon what your
goals are: if you are concerned about cross-platform compatibility, you should use multiple
Builders, one from each platform of interest. You might use just one builder if that platform has
libraries or other facilities that allow better test coverage than what you can accomplish on your
own machine, or faster test runs.
The set of Builders to use can be specified with multiple option –builder arguments on the
command line. It can also be specified with a single try_builders option in
.buildbot/options that uses a list of strings to specify all the Builder names:
try_builders = ["full-OSX", "full-win32", "full-linux"]
If you are using the PB approach, you can get the names of the builders that are configured for the
try scheduler using the get-builder-names argument:
buildbot try --get-builder-names --connect=pb --master=... --username=... --passwd=...
Specifying the VC system
The try command also needs to know how to take the developer’s current tree and extract
the (revision, patch) source-stamp pair. Each VC system uses a different process, so you start by
telling the try command which VC system you are using, with an argument like option
–vc=cvs or option –vc=git. This can also be provided as try_vc in
.buildbot/options.
The following names are recognized: bzr cvs darcs hg git mtn p4 svn
Finding the top of the tree
Some VC systems (notably CVS and SVN) track each directory more-or-less independently, which means
the try command needs to move up to the top of the project tree before it will be able
to construct a proper full-tree patch. To accomplish this, the try command will crawl up
through the parent directories until it finds a marker file. The default name for this marker file
is .buildbot-top, so when you are using CVS or SVN you should touch .buildbot-top from
the top of your tree before running buildbot try. Alternatively, you can use a filename
like ChangeLog or README, since many projects put one of these files in their
top-most directory (and nowhere else). To set this filename, use --topfile=ChangeLog, or set it
in the options file with try_topfile = 'ChangeLog'.
You can also manually set the top of the tree with --topdir=~/trees/mytree, or try_topdir =
'~/trees/mytree'. If you use try_topdir, in a .buildbot/options file, you will need a
separate options file for each tree you use, so it may be more convenient to use the
try_topfile approach instead.
Other VC systems which work on full projects instead of individual directories (Darcs, Mercurial, Git, Monotone) do not require try to know the top directory, so the option –try-topfile and option –try-topdir arguments will be ignored.
If the try command cannot find the top directory, it will abort with an error message.
The following command line arguments are deprecated, but retained for backward compatibility:
--try-topdiris replaced by option –topdir--try-topfileis replaced by option –topfile
Determining the branch name
Some VC systems record the branch information in a way that try can locate it. For the others,
if you are using something other than the default branch, you will have to tell the buildbot which
branch your tree is using. You can do this with either the option –branch argument, or a
try_branch entry in the .buildbot/options file.
Determining the revision and patch
Each VC system has a separate approach for determining the tree’s base revision and computing a patch.
- CVS
try pretends that the tree is up to date. It converts the current time into a option -D time specification, uses it as the base revision, and computes the diff between the upstream tree as of that point in time versus the current contents. This works, more or less, but requires that the local clock be in reasonably good sync with the repository.
- SVN
try does a svn status -u to find the latest repository revision number (emitted on the last line in the
Status against revision: NNmessage). It then performs ansvn diff -rNNto find out how your tree differs from the repository version, and sends the resulting patch to the buildmaster. If your tree is not up to date, this will result in thetrytree being created with the latest revision, then backwards patches applied to bring itbackto the version you actually checked out (plus your actual code changes), but this will still result in the correct tree being used for the build.- bzr
try does a
bzr revision-infoto find the base revision, then abzr diff -r$base..to obtain the patch.- Mercurial
hg parents --template '{node}\n'emits the full revision id (as opposed to the common 12-char truncated) which is a SHA1 hash of the current revision’s contents. This is used as the base revision.hg diffthen provides the patch relative to that revision. For try to work, your working directory must only have patches that are available from the same remotely-available repository that the build process’source.Mercurialwill use.- Perforce
try does a
p4 changes -m1 ...to determine the latest changelist and implicitly assumes that the local tree is synced to this revision. This is followed by ap4 diff -duto obtain the patch. A p4 patch differs slightly from a normal diff. It contains full depot paths and must be converted to paths relative to the branch top. To convert the following restriction is imposed. The p4base (seeP4Source) is assumed to be//depot- Darcs
try does a
darcs changes --contextto find the list of all patches back to and including the last tag that was made. This text file (plus the location of a repository that contains all these patches) is sufficient to re-create the tree. Therefore the contents of thiscontextfile are the revision stamp for a Darcs-controlled source tree. It then does adarcs diff -uto compute the patch relative to that revision.- Git
git branch -vlists all the branches available in the local repository along with the revision ID it points to and a short summary of the last commit. The line containing the currently checked out branch begins with “* “ (star and space) while all the others start with “ “ (two spaces). try scans for this line and extracts the branch name and revision from it. Then it generates a diff against the base revision.
Todo
I’m not sure if this actually works the way it’s intended since the extracted base revision might not actually exist in the upstream repository. Perhaps we need to add a –remote option to specify the remote tracking branch to generate a diff against.
- Monotone
mtn automate get_base_revision_id emits the full revision id which is a SHA1 hash of the current revision’s contents. This is used as the base revision. mtn diff then provides the patch relative to that revision. For try to work, your working directory must only have patches that are available from the same remotely-available repository that the build process’
source.Monotonewill use.
patch information
You can provide the option –who=dev to designate who is running the try build.
This will add the dev to the Reason field on the try build’s status web page.
You can also set try_who = dev in the .buildbot/options file.
Note that option –who=dev will not work on version 0.8.3 or earlier masters.
Similarly, option –comment=COMMENT will specify the comment for the patch, which is also
displayed in the patch information. The corresponding config-file option is try_comment.
Sending properties
You can set properties to send with your change using either the option –property=key=value option, which sets a single property, or the option –properties=key1=value1,key2=value2… option, which sets multiple comma-separated properties. Either of these can be specified multiple times. Note that the option –properties option uses commas to split on properties, so if your property value itself contains a comma, you’ll need to use the option –property option to set it.
try –diff
Sometimes you might have a patch from someone else that you want to submit to the buildbot. For example, a user may have created a patch to fix some specific bug and sent it to you by email. You’ve inspected the patch and suspect that it might do the job (and have at least confirmed that it doesn’t do anything evil). Now you want to test it out.
One approach would be to check out a new local tree, apply the patch, run your local tests, then
use buildbot try to run the tests on other platforms. An alternate approach is to use the
buildbot try --diff form to have the buildbot test the patch without using a local tree.
This form takes a option –diff argument which points to a file that contains the patch you want to apply. By default this patch will be applied to the TRUNK revision, but if you give the optional option –baserev argument, a tree of the given revision will be used as a starting point instead of TRUNK.
You can also use buildbot try --diff=- to read the patch from stdin.
Each patch has a patchlevel associated with it. This indicates the number of slashes (and
preceding pathnames) that should be stripped before applying the diff. This exactly corresponds to
the option -p or option –strip argument to the patch utility. By default buildbot
try --diff uses a patchlevel of 0, but you can override this with the option -p argument.
When you use option –diff, you do not need to use any of the other options that relate to a local tree, specifically option –vc, option –try-topfile, or option –try-topdir. These options will be ignored. Of course you must still specify how to get to the buildmaster (with option –connect, option –tryhost, etc).
2.7.1.3. Other Tools
These tools are generally used by buildmaster administrators.
sendchange
This command is used to tell the buildmaster about source changes. It is intended to be used from
within a commit script, installed on the VC server. It requires that you have a
PBChangeSource (PBChangeSource) running in the buildmaster (by being set in
c['change_source']).
buildbot sendchange --master {MASTERHOST}:{PORT} --auth {USER}:{PASS}
--who {USER} {FILENAMES..}
The option –auth option specifies the credentials to use to connect to the master, in the form
user:pass. If the password is omitted, then sendchange will prompt for it. If both are omitted,
the old default (username “change” and password “changepw”) will be used. Note that this password
is well-known, and should not be used on an internet-accessible port.
The option –master and option –username arguments can also be given in the options file (see
.buildbot config directory). There are other (optional) arguments which can influence the
Change that gets submitted:
- --branch
(or option
branch) This provides the (string) branch specifier. If omitted, it defaults toNone, indicating thedefault branch. All files included in this Change must be on the same branch.- --category
(or option
category) This provides the (string) category specifier. If omitted, it defaults toNone, indicatingno category. The category property can be used by schedulers to filter what changes they listen to.- --project
(or option
project) This provides the (string) project to which this change applies, and defaults to ‘’. The project can be used by schedulers to decide which builders should respond to a particular change.- --repository
(or option
repository) This provides the repository from which this change came, and defaults to''.- --revision
This provides a revision specifier, appropriate to the VC system in use.
- --revision_file
This provides a filename which will be opened and the contents used as the revision specifier. This is specifically for Darcs, which uses the output of
darcs changes --contextas a revision specifier. This context file can be a couple of kilobytes long, spanning a couple lines per patch, and would be a hassle to pass as a command-line argument.- --property
This parameter is used to set a property on the
Changegenerated bysendchange. Properties are specified as aname:valuepair, separated by a colon. You may specify many properties by passing this parameter multiple times.- --comments
This provides the change comments as a single argument. You may want to use option –logfile instead.
- --logfile
This instructs the tool to read the change comments from the given file. If you use
-as the filename, the tool will read the change comments from stdin.- --encoding
Specifies the character encoding for all other parameters, defaulting to
'utf8'.- --vc
Specifies which VC system the Change is coming from, one of:
cvs,svn,darcs,hg,bzr,git,mtn, orp4. Defaults toNone.
user
Note that in order to use this command, you need to configure a CommandlineUserManager instance in your master.cfg file, which is explained in Users Options.
This command allows you to manage users in buildbot’s database. No extra requirements are needed to use this command, aside from the Buildmaster running. For details on how Buildbot manages users, see Users.
- --master
The user command can be run virtually anywhere provided a location of the running buildmaster. The option –master argument is of the form
MASTERHOST:PORT.- --username
PB connection authentication that should match the arguments to CommandlineUserManager.
- --passwd
PB connection authentication that should match the arguments to CommandlineUserManager.
- --op
There are four supported values for the option –op argument:
add,update,remove, andget. Each are described in full in the following sections.- --bb_username
Used with the option –op=update option, this sets the user’s username for web authentication in the database. It requires option –bb_password to be set along with it.
- --bb_password
Also used with the option –op=update option, this sets the password portion of a user’s web authentication credentials into the database. The password is first encrypted prior to storage for security reasons.
- --ids
When working with users, you need to be able to refer to them by unique identifiers to find particular users in the database. The option –ids option lets you specify a comma separated list of these identifiers for use with the user command.
The option –ids option is used only when using option –op=remove or option –op=get.
- --info
Users are known in buildbot as a collection of attributes tied together by some unique identifier (see Users). These attributes are specified in the form
{TYPE}={VALUE}when using the option –info option. These{TYPE}={VALUE}pairs are specified in a comma separated list, so for example:--info=svn=jdoe,git='John Doe <joe@example.com>'
The option –info option can be specified multiple times in the user command, as each specified option will be interpreted as a new user. Note that option –info is only used with option –op=add or with option –op=update, and whenever you use option –op=update you need to specify the identifier of the user you want to update. This is done by prepending the option –info arguments with
{ID:}. If we were to update'jschmo'from the previous example, it would look like this:--info=jdoe:git='Joe Doe <joe@example.com>'
Note that option –master, option –username, option –passwd, and option –op are always required to issue the user command.
The option –master, option –username, and option –passwd options can be specified in the
option file with keywords user_master, user_username, and user_passwd, respectively. If
user_master is not specified, then option –master from the options file will be used
instead.
Below are examples of how each command should look. Whenever a user command is successful, results will be shown to whoever issued the command.
For option –op=add:
buildbot user --master={MASTERHOST} --op=add \
--username={USER} --passwd={USERPW} \
--info={TYPE}={VALUE},...
For option –op=update:
buildbot user --master={MASTERHOST} --op=update \
--username={USER} --passwd={USERPW} \
--info={ID}:{TYPE}={VALUE},...
For option –op=remove:
buildbot user --master={MASTERHOST} --op=remove \
--username={USER} --passwd={USERPW} \
--ids={ID1},{ID2},...
For option –op=get:
buildbot user --master={MASTERHOST} --op=get \
--username={USER} --passwd={USERPW} \
--ids={ID1},{ID2},...
A note on option –op=update: when updating the option –bb_username and option
–bb_password, the option –info doesn’t need to have additional {TYPE}={VALUE} pairs to
update and can just take the {ID} portion.
2.7.1.4. .buildbot config directory
Many of the buildbot tools must be told how to contact the buildmaster that they
interact with. This specification can be provided as a command-line argument, but most of the time
it will be easier to set them in an options file. The buildbot command will look for
a special directory named .buildbot, starting from the current directory (where the command
was run) and crawling upwards, eventually looking in the user’s home directory. It will look for a
file named options in this directory, and will evaluate it as a Python script, looking for
certain names to be set. You can just put simple name = 'value' pairs in this file to set the
options.
For a description of the names used in this file, please see the documentation for the individual buildbot sub-commands. The following is a brief sample of what this file’s contents could be.
# for status-reading tools
masterstatus = 'buildbot.example.org:12345'
# for 'sendchange' or the debug port
master = 'buildbot.example.org:18990'
Note carefully that the names in the options file usually do not match the command-line option name.
masterEquivalent to option –master for
sendchange. It is the location of thepb.PBChangeSourcefor`sendchange.usernameEquivalent to option –username for the
sendchangecommand.branchEquivalent to option –branch for the
sendchangecommand.categoryEquivalent to option –category for the
sendchangecommand.try_connectEquivalent to option –connect, this specifies how the
trycommand should deliver its request to the buildmaster. The currently accepted values aresshandpb.try_buildersEquivalent to option –builders, specifies which builders should be used for the
trybuild.try_vcEquivalent to option –vc for
try, this specifies the version control system being used.try_branchEquivalent to option –branch, this indicates that the current tree is on a non-trunk branch.
try_topdir
try_topfileUse
try_topdir, equivalent to option –try-topdir, to explicitly indicate the top of your working tree, ortry_topfile, equivalent to option –try-topfile to name a file that will only be found in that top-most directory.
try_host
try_username
try_dirWhen
try_connectisssh, the command will usetry_hostfor option –tryhost,try_usernamefor option –username, andtry_dirfor option –trydir. Apologies for the confusing presence and absence of ‘try’.
try_username
try_password
try_masterSimilarly, when
try_connectispb, the command will pay attention totry_usernamefor option –username,try_passwordfor option –passwd, andtry_masterfor option –master.
try_wait
masterstatustry_waitandmasterstatus(equivalent to option –wait andmaster, respectively) are used to ask thetrycommand to wait for the requested build to complete.
2.7.2. buildbot-worker
buildbot-worker command-line tool is used for worker management only and does not provide any additional functionality. One can create, start, stop and restart the worker.
2.7.2.1. create-worker
This creates a new directory and populates it with files that let it be used as a worker’s base directory.
You must provide several arguments, which are used to create the initial buildbot.tac file.
The option -r option is advisable here, just like for create-master.
buildbot-worker create-worker -r {BASEDIR} {MASTERHOST}:{PORT} {WORKERNAME} {PASSWORD}
The create-worker options are described in Worker Options.
2.7.2.2. start
This starts a worker which was already created in the given base directory.
The daemon is launched in the background, with events logged to a file named twistd.log.
buildbot-worker start [--nodaemon] BASEDIR
The option –nodaemon option instructs Buildbot to skip daemonizing. The process will start in the foreground. It will only return to the command-line when it is stopped.
2.7.2.3. restart
buildbot-worker restart [--nodaemon] BASEDIR
This restarts a worker which is already running.
It is equivalent to a stop followed by a start.
The option –nodaemon option has the same meaning as for start.
2.7.2.4. stop
This terminates the daemon worker running in the given directory.
buildbot stop BASEDIR
2.8. Resources
The Buildbot home page is http://buildbot.net/.
For configuration questions and general discussion, please use the buildbot-devel mailing list.
The subscription instructions and archives are available at https://lists.buildbot.net/pipermail/devel/
The #buildbot channel on Freenode’s IRC servers hosts development discussion, and often folks are available to answer questions there, as well.
2.9. Optimization
If you’re feeling your Buildbot is running a bit slow, here are some tricks that may help you, but use them at your own risk.
2.9.1. Properties load speedup
For example, if most of your build properties are strings, you can gain an approx. 30% speedup if you put this snippet of code inside your master.cfg file:
def speedup_json_loads():
import json, re
original_decode = json._default_decoder.decode
my_regexp = re.compile(r'^\[\"([^"]*)\",\s+\"([^"]*)\"\]$')
def decode_with_re(str, *args, **kw):
m = my_regexp.match(str)
try:
return list(m.groups())
except Exception:
return original_decode(str, *args, **kw)
json._default_decoder.decode = decode_with_re
speedup_json_loads()
It patches json decoder so that it would first try to extract a value from JSON that is a list of two strings (which is the case for a property being a string), and would fallback to general JSON decoder on any error.
2.10. Plugin Infrastructure in Buildbot
Added in version 0.8.11.
Plugin infrastructure in Buildbot allows easy use of components that are not part of the core. It also allows unified access to components that are included in the core.
The following snippet
from buildbot.plugins import kind
... kind.ComponentClass ...
allows to use a component of kind kind.
Available kinds are:
workerworkers, described in Workers
changeschange source, described in Change Sources and Changes
schedulersschedulers, described in Schedulers
stepsbuild steps, described in Build Steps
reportersreporters (or reporter targets), described in Reporters
utilutility classes. For example, BuilderConfig, Build Factories, ChangeFilter and Locks are accessible through
util.
Web interface plugins are not used directly: as described in web server configuration section, they are listed in the corresponding section of the web server configuration dictionary.
Note
If you are not very familiar with Python and you need to use different kinds of components, start your master.cfg file with:
from buildbot.plugins import *
As a result, all listed above components will be available for use.
This is what sample master.cfg file uses.
2.10.1. Finding Plugins
Buildbot maintains a list of plugins at https://github.com/buildbot/buildbot/wiki/PluginList.
2.10.2. Developing Plugins
Distribute a Buildbot Plug-In contains all necessary information for you to develop new plugins. Please edit https://github.com/buildbot/buildbot/wiki/PluginList to add a link to your plugin!
2.10.3. Plugins of note
Plugins were introduced in Buildbot-0.8.11, so as of this writing, only components that are bundled with Buildbot are available as plugins.
If you have an idea/need about extending Buildbot, head to How to package Buildbot plugins, create your own plugins and let the world know how Buildbot can be made even more useful.
2.11. Deployment
This page aims at describing the common pitfalls and best practices when deploying buildbot.
2.11.1. Using A Database Server
Buildbot uses the sqlite3 database backend by default.
Important
SQLite3 is perfectly suitable for small setups with a few users. However, it does not scale well with large numbers of builders, workers and users. If you expect your Buildbot to grow over time, it is strongly advised to use a real database server (e.g., MySQL or Postgres).
If you want to use a database server as the database backend for your Buildbot, use option
buildbot create-master –db to specify the connection string for
the database, and make sure that the same URL appears in the db_url of the db
parameter in your configuration file.
2.11.1.1. Server Setup Example
Installing and configuring a database server can be complex. Here is a minimalist example on how to install and configure a PostgreSQL server for your Buildbot on a recent Ubuntu system.
Note
To install PostgreSQL on Ubuntu, you need root access. There are other ways to do it without root access (e.g. docker, build from source, etc.) but outside the scope of this example.
First, let’s install the server with apt-get:
$ sudo apt-get update
<...>
$ sudo apt-get install postgresql
<...>
$ sudo systemctl status postgresql@10-main.service
● postgresql@10-main.service - PostgreSQL Cluster 10-main
Loaded: loaded (/lib/systemd/system/postgresql@.service; indirect; vendor preset: enabled)
Active: active (running) since Wed 2019-05-29 11:33:40 CEST; 3min 1s ago
Main PID: 24749 (postgres)
Tasks: 7 (limit: 4915)
CGroup: /system.slice/system-postgresql.slice/postgresql@10-main.service
├─24749 /usr/lib/postgresql/10/bin/postgres -D /var/lib/postgresql/10/main
| -c config_file=/etc/postgresql/10/main/postgresql.conf
├─24751 postgres: 10/main: checkpointer process
├─24752 postgres: 10/main: writer process
├─24753 postgres: 10/main: wal writer process
├─24754 postgres: 10/main: autovacuum launcher process
├─24755 postgres: 10/main: stats collector process
└─24756 postgres: 10/main: bgworker: logical replication launcher
May 29 11:33:38 ubuntu1804 systemd[1]: Starting PostgreSQL Cluster 10-main...
May 29 11:33:40 ubuntu1804 systemd[1]: Started PostgreSQL Cluster 10-main.
Once the server is installed, create a user and associated database for your Buildbot.
$ sudo su - postgres
postgres$ createuser -P buildbot
Enter password for new role: bu1ldb0t
Enter it again: bu1ldb0t
postgres$ createdb -O buildbot buildbot
postgres$ exit
After which, you can configure a proper SQLAlchemy URL:
c['db'] = {'db_url': 'postgresql://buildbot:bu1ldb0t@127.0.0.1/buildbot'}
And initialize the database tables with the following command:
$ buildbot upgrade-master
checking basedir
checking for running master
checking master.cfg
upgrading basedir
creating master.cfg.sample
upgrading database (postgresql://buildbot:xxxx@127.0.0.1/buildbot)
upgrade complete
2.11.1.2. Additional Requirements
Depending on the selected database, further Python packages will be required. Consult the SQLAlchemy dialect list for a full description. The most common choice for MySQL is mysqlclient. Any reasonably recent version should suffice.
The most common choice for Postgres is Psycopg. Any reasonably recent version should suffice.
2.11.2. Maintenance
The buildmaster can be configured to send out email notifications when a worker has been offline for a while. Be sure to configure the buildmaster with a contact email address for each worker so these notifications are sent to someone who can bring it back online.
If you find you can no longer provide a worker to the project, please let the project admins know, so they can put out a call for a replacement.
The Buildbot records status and logs output continually, each time a build is performed. The status
tends to be small, but the build logs can become quite large. Each build and log are recorded in a
separate file, arranged hierarchically under the buildmaster’s base directory. To prevent these
files from growing without bound, you should periodically delete old build logs. A simple cron job
to delete anything older than, say, two weeks should do the job. The only trick is to leave the
buildbot.tac and other support files alone, for which find’s -mindepth
argument helps skip everything in the top directory. You can use something like the following
(assuming builds are stored in ./builds/ directory):
@weekly cd BASEDIR && find . -mindepth 2 i-path './builds/*' \
-prune -o -type f -mtime +14 -exec rm {} \;
@weekly cd BASEDIR && find twistd.log* -mtime +14 -exec rm {} \;
Alternatively, you can configure a maximum number of old logs to be kept using the --log-count
command line option when running buildbot-worker create-worker or buildbot create-master.
2.11.3. Troubleshooting
Here are a few hints on diagnosing common problems.
2.11.3.1. Starting the worker
Cron jobs are typically run with a minimal shell (/bin/sh, not /bin/bash), and
tilde expansion is not always performed in such commands. You may want to use explicit paths,
because the PATH is usually quite short and doesn’t include anything set by your shell’s
startup scripts (.profile, .bashrc, etc). If you’ve installed buildbot (or other
Python libraries) to an unusual location, you may need to add a PYTHONPATH specification
(note that Python will do tilde-expansion on PYTHONPATH elements by itself). Sometimes it
is safer to fully-specify everything:
@reboot PYTHONPATH=~/lib/python /usr/local/bin/buildbot \
start /usr/home/buildbot/basedir
Take the time to get the @reboot job set up. Otherwise, things will work fine for a while, but
the first power outage or system reboot you have will stop the worker with nothing but the cries of
sorrowful developers to remind you that it has gone away.
2.11.3.2. Connecting to the buildmaster
If the worker cannot connect to the buildmaster, the reason should be described in the
twistd.log logfile. Some common problems are an incorrect master hostname or port number,
or a mistyped bot name or password. If the worker loses the connection to the master, it is
supposed to attempt to reconnect with an exponentially-increasing backoff. Each attempt (and the
time of the next attempt) will be logged. If you get impatient, just manually stop and re-start the
worker.
When the buildmaster is restarted, all workers will be disconnected, and will attempt to reconnect
as usual. The reconnect time will depend upon how long the buildmaster is offline (i.e. how far up
the exponential backoff curve the workers have travelled). Again,
buildbot-worker restart BASEDIR will speed up the process.
2.11.3.3. Logging to stdout
It can be useful to let buildbot output it’s log to stdout instead of a logfile.
For example when running via docker, supervisor or when buildbot is started with –no-daemon.
This can be accomplished by editing buildbot.tac. It’s already enabled in the docker buildbot.tac
Change the line: application.setComponent(ILogObserver, FileLogObserver(logfile).emit)
to: application.setComponent(ILogObserver, FileLogObserver(sys.stdout).emit)
2.11.3.4. Deleting old logs
Buildbot stores historical information in its database.
In a large installation, these can quickly consume disk space, yet developers never consult this historical information in many cases.
Read more on how to remove obsolete information in: JanitorConfigurator.
2.11.3.5. Debugging with the python debugger
Sometimes it’s necessary to see what is happening inside a program. To enable this, start buildbot with:
twistd --no_save -n -b --logfile=- -y buildbot.tac
This will load the debugger on every exception and breakpoints in the program. More information on the python debugger can be found here: https://docs.python.org/3/library/pdb.html
2.11.3.6. Contrib Scripts
While some features of Buildbot are included in the distribution, others are only available in master/contrib/ in the source directory. The latest versions of such scripts are available at master/contrib.
2.12. Upgrading
This section describes the process of upgrading the master and workers from old versions of Buildbot.
The users of the Buildbot project will be warned about backwards-incompatible changes by warnings produced by the code. Additionally, all backwards-incompatible changes will be done at a major version change (e.g. 1.x to 2.0). Minor version change (e.g. 2.3 to 2.4) will only introduce backwards-incompatible changes only if they affect small part of the users and are absolutely necessary. Direct upgrades between more than two major releases (e.g. 1.x to 3.x) are not supported.
The versions of the master and the workers do not need to match, so it’s possible to upgrade them separately.
Usually there are no actions needed to upgrade a worker except to install a new version of the code and restart it.
Usually the process of upgrading the master is as simple as running the following command:
buildbot upgrade-master basedir
This command will also scan the master.cfg file for incompatibilities (by loading it and printing any errors or deprecation warnings that occur).
It is safe to run this command multiple times.
Warning
The upgrade-master command may perform database schema modifications.
To avoid any data loss or corruption, it should not be interrupted.
As a safeguard, it ignores all signals except SIGKILL.
To upgrade between major releases the best approach is first to upgrade to the latest minor release on the same major release. Then, fix all deprecation warnings by upgrading the configuration code to the replacement APIs. Finally, upgrade to the next major release.
2.12.1. Upgrading to Buildbot 5.0 (not released)
Upgrading a Buildbot instance from 4.x to 5.0 may require some work to achieve.
The recommended upgrade procedure is as follows:
Upgrade to the last released BuildBot version in 4.x series.
Remove usage of the deprecated APIs. All usages of deprecated APIs threw a deprecation warning at the point of use. If the code does not emit deprecation warnings, it’s in a good shape in this regard. You may need to run the master on a real workload in order to force all deprecated code paths to be exercised.
Upgrade to the latest Buildbot 5.0.x release.
(Optional) Upgrade to newest Buildbot 5.x. The newest point release will contain bug fixes and functionality improvements.
2.12.2. Testing support
The build_files, worker_env and worker_version arguments of
TestBuildStepMixin.setup_step() have been removed. As a replacement, call
TestBuildStepMixin.setup_build() before setup_step.
2.12.3. Non-reconfigurable services
Raising NotImplementedError from reconfigServiceWithSibling or reconfigService service
functions has been deprecated. Use canReconfigWithSibling() that returns False as a
replacement.
2.12.4. HTTP service
The following methods of httpclientservice.HTTPClientService have been deprecated:
get
delete
post
put
updateHeaders
As a replacement, use httpclientservice.HTTPSession and call corresponding methods on it.
2.12.5. Build factories
BuildFactory workdir attribute no longer supports callables. As a replacement, use a
renderable instead.
2.12.6. Database connectors
The internal API presented by the database connectors has been changed to return data classes instead of Python dictionaries. To upgrade to the data classes simply access the data as class attributes, not dictionary keys.
The following functions have been affected:
BuildDataConnectorComponentgetBuildData,getBuildDataNoValue, andgetAllBuildDataNoValues.BuildsConnectorComponentgetBuild,getBuildByNumber,getPrevSuccessfulBuild,getBuildsForChange,getBuilds,_getRecentBuilds, and_getBuild.BuildRequestsConnectorComponentgetBuildRequest, andgetBuildRequests.BuildsetsConnectorComponentgetBuildset,getBuildsets, andgetRecentBuildsets.BuildersConnectorComponentgetBuilderandgetBuilders.ChangesConnectorComponentgetChange,getChangesForBuild,getChangeFromSSid.ChangeSourcesConnectorComponentgetChangeSource, andgetChangeSources.LogsConnectorComponentgetLog,getLogBySlug, andgetLogs.MastersConnectorComponentgetMaster, andgetMasters.ProjectsConnectorComponentget_project,get_projects.SchedulersConnectorComponentgetScheduler, andgetSchedulers.SourceStampsConnectorComponentgetSourceStamp,get_sourcestamps_for_buildset,getSourceStampsForBuild, andgetSourceStamps.StepsConnectorComponentgetStep, andgetSteps.TestResultsConnectorComponentgetTestResultandgetTestResults.TestResultSetsConnectorComponentgetTestResultSet, andgetTestResultSets.UsersConnectorComponentgetUser,getUserByUsername, andgetUsers.WorkersConnectorComponentgetWorker, andgetWorkers.
DataConnector.produceEvent() has been deprecated. The replacement is update methods from the
data API.
2.12.7. Schedulers
Old location of Dependent scheduler has been removed. Instead of
buildbot.schedulers.basic.Dependent use buildbot.plugins.schedulers.Dependent.
buildbot.schedulers.base.BaseScheduler has been deprecated. Replace uses of it with
buildbot.schedulers.base.ReconfigurableBaseScheduler.
2.12.8. Reporters
The add_logs argument of BuildStatusGenerator, BuildStartEndStatusGenerator and
BuildSetStatusGenerator has been removed. As a replacement, set want_logs_content of the
passed message formatter.
2.12.9. Data API
The multiline string type of ResourceType.eventPathPatterns and Enpoint.pathPatterns
attribute has been deprecated. Use list of strings type instead.
2.12.10. Upgrading to Buildbot 4.0
Upgrading a Buildbot instance from 3.x to 4.0 may require some work to achieve.
The recommended upgrade procedure is as follows:
Upgrade to the last released BuildBot version in 3.x series.
Remove usage of the deprecated APIs. All usages of deprecated APIs threw a deprecation warning at the point of use. If the code does not emit deprecation warnings, it’s in a good shape in this regard. You may need to run the master on a real workload in order to force all deprecated code paths to be exercised.
Upgrade to the latest Buildbot 4.0.x release.
(Optional) Upgrade to newest Buildbot 4.x. The newest point release will contain bug fixes and functionality improvements.
2.12.10.1. Web frontend
Buildbot 4.0 replaces the AngularJS-based web frontend with a new React-based one. In simple Buildbot installations there is nothing that needs to be done except to install compatible versions of any www plugins that are used. The following plugins are maintained as part of Buildbot and can be upgraded seamlessly by just installing new, compatible version:
buildbot-www(main web frontend)
buildbot-console-view
buildbot-grid-view
buildbot-waterfall-view
Custom plugins
If the Buildbot installation uses plugins that are developed outside Buildbot, these will need to be rewritten to use the new Buildbot plugin APIs that expect the plugin to be written in React. In such case the best approach is to rewrite any custom plugins into React while still using Buildbot 3.x and convert to 4.x once everything is ready.
More specifically, the recommended approach is as follows:
Upgrade to the last released BuildBot version in 3.x series.
Prepare the development environment
Install
buildbot-www-reactwith the same version.Install any Buildbot plugins that already have a version that is compatible with React. For example
buildbot-console-viewhas a React equivalentbuildbot-react-console-view.Add
'base_react': {}key-value pair to the www plugin dictionary. For example, in the default installation the configuration would look like this:c['www'] = {port: 8080, plugins={'base_react': {}}}.Other enabled plugins will need their keys in the dictionary changed. For example, the compatibility Buildbot plugins will have the following names:
console_viewasreact_console_view
grid_viewasreact_grid_view
waterfall_viewasreact_waterfall_viewRewrite any custom Buildbot plugins into React and new Buildbot plugin APIs in the development environment.
Replace the production setup with what was tested in the development environment section above.
Upgrade to Buildbot 4.x series
Buildbot plugins with the word
reactin the name are temporarily used for migration testing. After a successful migration to Buildbot 4.x, you should replace them with plugins without the wordreactin the plugin name.
Uninstall migration plugins
pip uninstall buildbot-www-react buildbot-react-console-view buildbot-react-grid-view buildbot-react-waterfall-view buildbot-react-wsgi-dashboardsInstall production plugins
pip install buildbot-www buildbot-console-view buildbot-grid-view buildbot-waterfall-view buildbot-react-wsgi-dashboardsUpdate the www plugin dictionary
Only update the ones you use in your installation.
Replace:
c['www'] = dict(port=8010, plugins=dict('base_react': {}, react_console_view={}, react_grid_view={}, react_waterfall_view={}, react_wsgi_dashboards={}))With:
c['www'] = dict(port=8010, plugins=dict(console_view={}, grid_view={}, waterfall_view={}, wsgi_dashboards={}))
2.12.10.2. GerritChangeSource and GerritEventLogPoller
Events between GerritChangeSource and GerritEventLogPoller are no longer deduplicated.
The equivalent is setting GerritChangeSource with both SSH and HTTP APIs. The http_url
should be set to baseURL of argument GerritEventLogPoller without the /a suffix included.
http_auth should be set to auth argument of GerritEventLogPoller.
2.12.10.3. Build status generators
The subject argument of BuildStatusGenerator and BuildSetStatusGenerator has been removed.
The equivalent is setting the subject argument of the message formatter.
2.12.10.4. Message formatters
The wantLogs argument to message formatters has been removed.
The equivalent is setting both want_logs and want_logs_content to the previous value of wantLogs.
The wantSteps and wantProperties arguments have been renamed to want_steps and want_properties respectively.
2.12.10.5. GerritStatusPush
The reviewCB, reviewArg, startCB, startArg, summaryCB, summaryArg,
builders , wantSteps, wantLogs arguments of GerritStatusPush have been deprecated.
The upgrade strategy is as follows:
reviewCB,reviewArg,startCB,startArg: UseBuildStartEndStatusGeneratorreport generator (generatorsargument). Depending onreviewCBcomplexity, use MessageFormatter or MessageFormatterFunctionRaw message formatters. To override default handling ofVerifiedandReviewedlabels, adjust extra information emitted by message formatter. E.g.{"labels": {"Verified": 1}}.
summaryCB,summaryArg: UseBuildSetStatusGeneratororBuildSetCombinedStatusGeneratorreport generator (generatorsargument). Depending onsummaryCBcomplexity, use MessageFormatter or MessageFormatterFunctionRaw message formatters. To override default handling ofVerifiedandReviewedlabels, adjust extra information emitted by message formatter. E.g.{"labels": {"Verified": 1}}.
builders- usebuildersargument of replacement report generator
wantSteps- usewant_stepsargument of replacement message formatter.
wantLogs- usewant_logsargument of replacement message formatter
2.12.10.6. buildbot.util.croniter
buildbot.util.croniter module has been removed.
The replacement is croniter package from PyPI.
Migration to croniter involves ensuring that the input times are passed as time-aware datetime objects.
The original buildbot.util.croniter code always assumed the input time is in the current timezone.
The croniter package assumes the input time is in UTC timezone.
2.12.10.7. Endpoint attributes
buildbot.data.base.Endpoint no longer provides isRaw and isCollection attributes.
The equivalent in Buildbot 4.x is setting the kind attribute to EndpointKind.RAW and EndpointKind.COLLECTION respectively.
2.12.10.8. Changes to BuildStep attributes
BuildBot no longer supports changing BuildStep attributes after a step is created during configuration.
Changing attributes of BuildStep instances that are not yet part of any build is most likely an error.
This is because such instances are only being used to configure a builder as a source to create real steps from.
In this scenario any attribute changes are ignored as far as build configuration is concerned.
For customizing BuildStep after an instance has already been created set_step_arg(name, value) function has been added.
2.12.11. Upgrading to Buildbot 3.0
Upgrading a Buildbot instance from 2.x to 3.0 may require some work to achieve.
The recommended upgrade procedure is as follows:
Upgrade to the last released BuildBot version in 2.x series.
Remove usage of the deprecated APIs. All usages of deprecated APIs threw a deprecation warning at the point of use. If the code does not emit deprecation warnings, it’s in a good shape in this regard. You may need to run the master on a real workload in order to force all deprecated code paths to be exercised.
Upgrade to the latest Buildbot 3.0.x release.
Fix all usages of deprecated APIs. In this case, the only deprecated APIs are temporary
*NewStylebuild step aliases.(Optional) Upgrade to newest Buildbot 3.x. The newest point release will contain bug fixes and functionality improvements.
2.12.11.1. Build steps
Buildbot 3.0 no longer supports old-style steps (steps which implement start method as opposed
to run method). This only affects users who use steps as base classes for their own steps. New
style steps provide a completely different set of functions that may be overridden. Direct
instantiation of step classes is not affected. Old and new style steps work exactly the same in
that case and users don’t need to do anything.
See New-Style Build Steps in Buildbot 0.9.0 for instructions of migration to new-style steps.
Migrating build steps that subclass one of the build steps provided by Buildbot is a little bit
more involved. The new and old-style step APIs cannot be provided by a single class. Therefore
Buildbot 2.9 introduces a number of new-style build steps that are direct equivalent of their
old-style counterparts. These build steps are named as <StepType>NewStyle where <StepType>
is the old-style step they provide compatibility interface for. Buildbot 3.0 removes old-style step
support and changes the <StepType> classes to be equivalent to <StepType>NewStyle
counterparts. Buildbot 3.2 removes the <StepType>NewStyle aliases.
If a custom step is a subclass of <StepType step which is provided by Buildbot, then the
migration process is as follows. The custom step should be changed to subclass the
<StepType>NewStyle equivalent and use the new-style APIs as specified in
New-Style Build Steps in Buildbot 0.9.0. This part of the migration must be done before the build master is
migrated to 3.0. The resulting custom step will work in Buildbot 2.9.x-3.1.x. After the build
master is migrated to 3.0, the custom step may be changed to subclass <StepType. This is a
simple renaming change, no other related changes are necessary. This part of the migration must be
done before the build master is migrated to 3.2.
The following build steps have their new-style equivalents since Buildbot 2.9:
The list of old-style steps that have new-style equivalents for gradual migration is as follows:
Configure(new-style equivalent isConfigureNewStyle)
Compile(new-style equivalent isCompileNewStyle)
HTTPStep(new-style equivalent isHTTPStepNewStyle)
GET,PUT,POST,DELETE,HEAD,OPTIONS(new-style equivalent isGETNewStyle,PUTNewStyle,POSTNewStyle,DELETENewStyle,HEADNewStyle,OPTIONSNewStyle)
MasterShellCommand(new-style equivalent isMasterShellCommandNewStyle)
ShellCommand(new-style equivalent isShellCommandNewStyle)
SetPropertyFromCommand(new-style equivalent isSetPropertyFromCommandNewStyle)
WarningCountingShellCommand(new-style equivalent isWarningCountingShellCommandNewStyle)
Test(new-style equivalent isTestNewStyle)
The migration path of all other steps is more involved as no compatibility steps are provided.
2.12.11.2. Reporters and report generators
Buildbot 2.9 introduced report generators as the preferred way of configuring the conditions of when a message is sent by a reporter and contents of the messages. The old parameters have been gradually deprecated in Buildbot 2.9 and Buildbot 2.10 and removed in Buildbot 3.0.
The following describes the procedure of upgrading reporters.
In general, one or more arguments to a reporter is going to be replaced by a list of one or more
report generators passed as a list to the generators parameter.
The description below will explain what to do with each parameter.
MailNotifier
The generators list will contain one or two report generators.
The first will be an instance of BuildStatusGenerator if the value of
buildSetSummary was True or BuildSetStatusGenerator if the value of
buildSetSummary was False. This will be referred to as status generator in the
description below.
The second generator is optional.
It included if the value of watchedWorkers is not None (the default is "all")
If included, it’s an instance of WorkerMissingGenerator.
This will be referred to as missing worker generator in the description below.
The following arguments have been removed:
subject. Replacement issubjectparameter of the status generator.mode. Replacement ismodeparameter of the status generator.builders. Replacement isbuildersparameter of the status generator.tags. Replacement istagsparameter of the status generator.schedulers. Replacement isschedulersparameter of the status generator.branches. Replacement isbranchesparameter of the status generator.addLogs. Replacement isadd_logsparameter of the status generator.addPatch. Replacement isadd_patchparameter of the status generator.buildSetSummary. Defines whether the status generator will be instance ofBuildStatusGenerator(value ofTrue, the default) orBuildSetStatusGenerator(value ofFalse).messageFormatter. Replacement ismessage_formatterparameter of the status generator.watchedWorkers. Replacement isworkersparameter of the missing worker generator. If the value wasNone, then there’s no missing worker generator and the value ofmessageFormatterMissingWorkeris ignored.messageFormatterMissingWorker. Replacement ismessage_formatterparameter of the missing worker generator.
PushjetNotifier, PushoverNotifier, BitbucketServerPRCommentPush
The generators list will contain one or two report generators.
The first will be an instance of BuildStatusGenerator if the value of
buildSetSummary was True or BuildSetStatusGenerator if the value of
buildSetSummary was False. This will be referred to as status generator in the
description below.
The second generator is optional.
It included if the value of watchedWorkers is not None (the default is None)
If included, it’s an instance of WorkerMissingGenerator.
This will be referred to as missing worker generator in the description below.
The following arguments have been removed:
subject. Replacement issubjectparameter of the status generator.mode. Replacement ismodeparameter of the status generator.builders. Replacement isbuildersparameter of the status generator.tags. Replacement istagsparameter of the status generator.schedulers. Replacement isschedulersparameter of the status generator.branches. Replacement isbranchesparameter of the status generator.buildSetSummary. Defines whether the status generator will be instance ofBuildStatusGenerator(value ofTrue, the default) orBuildSetStatusGenerator(value ofFalse).messageFormatter. Replacement ismessage_formatterparameter of the status generator. In the case ofPushjetNotifierandPushoverNotifier, the default message formatter isMessageFormatter(template_type='html', template=<default text>).watchedWorkers. Replacement isworkersparameter of the missing worker generator. If the value wasNone, then there’s no missing worker generator and the value ofmessageFormatterMissingWorkeris ignored.messageFormatterMissingWorker. Replacement ismessage_formatterparameter of the missing worker generator. In the case ofPushjetNotifierandPushoverNotifier, the default message formatter isMessageFormatterMissingWorker(template=<default text>).
BitbucketServerCoreAPIStatusPush, BitbucketServerStatusPush, GerritVerifyStatusPush, GitHubStatusPush, GitHubCommentPush, GitLabStatusPush
The generators list will contain one report generator of instance BuildStartEndStatusGenerator.
The following arguments have been removed:
builders. Replacement isbuildersparameter of the status generator.wantProperties. Replacement iswantPropertiesparameter of the message formatter passed to the status generator.wantSteps. Replacement iswantStepsparameter of the message formatter passed to the status generator.wantLogs. Replacement iswantLogsparameter of the message formatter passed to the status generator.wantPreviousBuild. There is no replacement, the value is computed automatically when information on previous build is needed.startDescription. Replacement is a message formatter of typeMessageFormatterRenderablepassed as thestart_formatterparameter to the status generator.endDescription. Replacement is a message formatter of typeMessageFormatterRenderablepassed as theend_formatterparameter to the status generator.
HttpStatusPush
The generators list will contain one report generator of instance
BuildStatusGenerator.
The following arguments have been removed:
builders. Replacement isbuildersparameter of the status generator.wantProperties. Replacement iswantPropertiesparameter of the message formatter passed to the status generator.wantSteps. Replacement iswantStepsparameter of the message formatter passed to the status generator.wantLogs. Replacement iswantLogsparameter of the message formatter passed to the status generator.wantPreviousBuild. There is no replacement, the value is computed automatically when information on previous build is needed.format_fn. Replacement is a message formatter of typeMessageFormatterFunctionpassed as themessage_formatterparameter to the status generator. TheMessageFormatterFunctionshould be passed a callable function as thefunctionparameter. Thisfunctionparameter has a different signature thanformat_fn.format_fnwas previously passed a build dictionary directly as the first argument.functionwill be passed a dictionary, which contains abuildkey which will contain the build dictionary as the value.
BitbucketStatusPush
The generators list will contain one report generator of instance
BuildStartEndStatusGenerator.
The following arguments have been removed:
builders. Replacement isbuildersparameter of the status generator.wantProperties,wantSteps,wantLogsandwantPreviousBuildwere previously accepted, but they do not affect the behavior of the reporter.
2.12.11.3. Template files in message formatters
Paths to template files that are passed to message formatters for rendering are no longer supported. Please read the templates in the configuration file and pass strings instead.
2.12.12. Upgrading to Buildbot 2.0
Upgrading a Buildbot instance from 1.x to 2.0 may require some work to achieve. The primary changes are removal of deprecated APIs and removal of Python 2.7 support.
The recommended upgrade procedure is as follows:
Upgrade to the last released BuildBot version in 1.x series.
Remove usage of the deprecated APIs. All usages of deprecated APIs threw a deprecation warning at the point of use. If the code does not emit deprecation warnings, it’s in a good shape in this regard.
Upgrade master to Python 3. Note that 1.x series has some bugs in Python 3 support, so any Python-related issues encountered in this step are relatively harmless as they will be fixed after upgrading to 2.0. You may need to run the master on a real workload in order to force all deprecated code paths to be exercised.
Upgrade to Buildbot 2.0.
(Optional) Upgrade to newest Buildbot 2.x. The newest point release will contain bug fixes and functionality improvements. Note that BuildBot 2.3.0 drops support for Internet Explorer 11 and some other old browsers.
2.12.13. Upgrading to Buildbot 1.0
Upgrading a Buildbot instance from 0.9.x to 1.0 does not require any changes in the master configuration. Despite the major version bump, Buildbot 1.0 does not have major difference with the 0.9 series. 1.0.0 is rather the mark of API stability.
2.12.14. Upgrading to Buildbot 0.9.0
Upgrading a Buildbot instance from 0.8.x to 0.9.x may require a number of changes to the master configuration. Those changes are summarized here. If you are starting fresh with 0.9.0 or later, you can safely skip this section.
First important note is that Buildbot does not support an upgrade of a 0.8.x instance to 0.9.x. Notably the build data and logs will not be accessible anymore if you upgraded, thus the database migration scripts have been dropped.
You should not pip upgrade -U buildbot, but rather start from a clean virtualenv aside from your old master.
You can keep your old master instance to serve the old build status.
Buildbot is now composed of several Python packages and Javascript UI, and the easiest way to install it is to run the following command within a virtualenv:
pip install 'buildbot[bundle]'
2.12.14.1. Config File Syntax
In preparation for compatibility with Python 3, Buildbot configuration files no longer allow the print statement:
print "foo"
To fix, simply enclose the print arguments in parentheses:
print("foo")
2.12.14.2. Plugins
Although plugin support was available in 0.8.12, its use is now highly recommended.
Instead of importing modules directly in master.cfg, import the plugin kind from buildbot.plugins:
from buildbot.plugins import steps
Then access the plugin itself as an attribute:
steps.SetProperty(..)
See Plugin Infrastructure in Buildbot for more information.
2.12.14.3. Web Status
The most prominent change is that the existing WebStatus class is now gone, replaced by the new www functionality.
Thus an html.WebStatus entry in c['status'] should be removed and replaced with configuration in c['www'].
For example, replace:
from buildbot.status import html
c['status'].append(html.WebStatus(http_port=8010, allowForce=True)
with:
c['www'] = {
"port": 8010,
"plugins": {
"waterfall_view": {},
"console_view": {}
}
}
See www for more information.
2.12.14.4. Status Classes
Where in 0.8.x most of the data about a build was available synchronously, it must now be fetched dynamically using the Data API.
All classes under the Python package buildbot.status should be considered deprecated.
Many have already been removed, and the remainder have limited functionality.
Any custom code which refers to these classes must be rewritten to use the Data API.
Avoid the temptation to reach into the Buildbot source code to find other useful-looking methods!
Common uses of the status API are:
getBuildin a custom renderable
MailNotifiermessage formatters (see below for upgrade hints)
doStepIffunctions on steps
Import paths for several classes under the buildbot.status package but which remain useful have changed.
Most of these are now available as plugins (see above), but for the remainder, consult the source code.
2.12.14.5. BuildRequest Merging
Buildbot 0.9.x has replaced the old concept of request merging (mergeRequests) with a more flexible request-collapsing mechanism.
See collapseRequests for more information.
2.12.14.6. Status Reporters
In fact, the whole c['status'] configuration parameter is gone.
Many of the status listeners used in the status hierarchy in 0.8.x have been replaced with “reporters” that are available as buildbot plugins. However, note that not all status listeners have yet been ported. See the release notes for details.
Including the "status" key in the configuration object will cause a configuration error.
All reporters should be included in c['services'] as described in Reporters.
The available reporters as of 0.9.0 are
GitHubStatusPush(replacesbuildbot.status.github.GitHubStatus)
See the reporter index for the full, current list.
A few notes on changes to the configuration of these reporters:
MailNotifierargumentmessageFormattershould now be abuildbot.reporters.message.MessageFormatter, due to the removal of the status classes (see above), such formatters must be re-implemented using the Data API.MailNotifierargumentpreviousBuildGetteris not supported anymoreMailNotifierno longer forces SSL 3.0 whenuseTlsis true.GerritStatusPushcallbacks slightly changed signature, and include a master reference instead of a status reference.GitHubStatusPushnow accepts acontextparameter to be passed to the GitHub Status API.buildbot.status.builder.Resultsand the constantsbuildbot.status.results.SUCCESSshould be imported from thebuildbot.process.resultsmodule instead.
2.12.14.7. Steps
Buildbot-0.8.9 introduced “new-style steps”, with an asynchronous run method.
In the remaining 0.8.x releases, use of new-style and old-style steps were supported side-by-side.
In 0.9.x, old-style steps are emulated using a collection of hacks to allow asynchronous calls to be called from synchronous code.
This emulation is imperfect, and you are strongly encouraged to rewrite any custom steps as New-Style Build Steps in Buildbot 0.9.0.
Note that new-style steps now “push” their status when it changes, so the describe method no longer exists.
2.12.14.8. Identifiers
Many strings in Buildbot must now be identifiers.
Identifiers are designed to fit easily and unambiguously into URLs, AMQP routes, and the like.
An “identifier” is a nonempty unicode string of limited length, containing only UTF-8 alphanumeric characters along with - (dash) and _ (underscore), and not beginning with a digit
Unfortunately, many existing names do not fit this pattern.
The following fields are identifiers:
worker name (50-character)
builder name (70-character)
step name (50-character)
2.12.14.9. Serving static files
Since version 0.9.0 Buildbot doesn’t use and doesn’t serve master’s public_html directory.
You need to use third-party HTTP server for serving static files.
2.12.14.10. Transition to “worker” terminology
Since version 0.9.0 of Buildbot “slave”-based terminology is deprecated in favor of “worker”-based terminology.
All identifiers, messages and documentation were updated to use “worker” instead of “slave”. Old API names are still available in Buildbot versions from 0.9.0 to 1.8.0, but deprecated. The support for old API names has been removed in Buildbot version 2.0.0. To upgrade pre-0.9.0 Buildbot installation a two-stage upgrade is recommended. First, upgrade to Buildbot version 1.8.0, then fix all deprecation warnings and finally upgrade to Buildbot version 2.x.y.
For details about changed API and how to control generated warnings see Transition to “worker” terminology in BuildBot 0.9.0.
2.12.14.11. Other Config Settings
The default master.cfg file contains some new changes, which you should look over:
c['protocols'] = {'pb': {'port': 9989}}(the default port used by the workers)Waterfall View: requires installation (
pip install buildbot-waterfall-view) and configuration (c['www'] = { ..., 'plugins': {'waterfall_view': {} }).
2.12.14.12. Build History
There is no support for importing build history from 0.8.x (where the history was stored on-disk in pickle files) into 0.9.x (where it is stored in the database).
2.12.14.13. Data LifeTime
Buildbot Nine data being implemented fully in an SQL database, the buildHorizon feature had to be reworked.
Instead of being number-of-things based, it is now time based.
This makes more sense from a user perspective but makes it harder to predict the database average size.
Please be careful to provision enough disk space for your database.
The old c['logHorizon'] way of configuring is not supported anymore.
See JanitorConfigurator to learn how to configure.
A new __Janitor builder will be created to help keep an eye on the cleanup activities.
2.12.14.14. Upgrading worker
Upgrading worker requires updating the buildbot.tac file to use the new APIs.
The easiest solution is to simply delete the worker directory and re-run buildbot-worker create-worker to get the stock buildbot.tac.
If the loss of the cached worker state is a problem, then the buildbot.tac can be updated manually:
Replace:
from buildslave.bot import BuildSlave
with:
from buildbot_worker.bot import Worker
Replace:
application = service.Application('buildslave')
with:
application = service.Application('buildbot-worker')
Replace:
s = BuildSlave(buildmaster_host, port, slavename, passwd, basedir, keepalive, usepty, umask=umask, maxdelay=maxdelay, numcpus=numcpus, allow_shutdown=allow_shutdown)
with:
s = Worker(buildmaster_host, port, slavename, passwd, basedir, keepalive, umask=umask, maxdelay=maxdelay, numcpus=numcpus, allow_shutdown=allow_shutdown)
2.12.14.15. More Information
For minor changes not mentioned here, consult the release notes for the versions over which you are upgrading.
Buildbot-0.9.0 represents several years’ work, and as such we may have missed potential migration issues.
2.12.15. New-Style Build Steps in Buildbot 0.9.0
In Buildbot-0.9.0, many operations performed by BuildStep subclasses return a Deferred. As a result, custom build steps which call these methods will need to be rewritten.
Buildbot-0.8.9 supports old-style steps natively, while new-style steps are emulated. Buildbot-0.9.0 supports new-style steps natively, while old-style steps are emulated. Buildbot-3.0 no longer supports old-style steps at all. All custom steps should be rewritten in the new style as soon as possible.
Buildbot distinguishes new-style from old-style steps by the presence of a run method.
If this method is present, then the step is a new-style step.
2.12.15.1. Summary of Changes
New-style steps have a
runmethod that is simpler to implement than the oldstartmethod.Many methods are now asynchronous (return Deferreds), as they perform operations on the database.
Logs are now implemented by a completely different class. This class supports the same log-writing methods (
addStderrand so on), although they are now asynchronous. However, it does not support log-reading methods such asgetText. It was never advisable to handle logs as enormous strings. New-style steps should, instead, use a LogObserver or (in Buildbot-0.9.0) fetch log lines bit by bit using the data API.buildbot.process.buildstep.LoggingBuildStepis deprecated and cannot be used in new-style steps. Mix inbuildbot.process.buildstep.ShellMixininstead.Step strings, derived by parameters like
description,descriptionDone, anddescriptionSuffix, are no longer treated as lists. For backward compatibility, the parameters may still be given as lists, but will be joined with spaces during execution (usingjoin_list).
2.12.15.2. Backward Compatibility
Some hacks are in place to support old-style steps. These hacks are only activated when an old-style step is detected. Support for old-style steps has been dropped in Buildbot-3.0.
The Deferreds from all asynchronous methods invoked during step execution are gathered internally. The step is not considered finished until all such Deferreds have fired, and is marked EXCEPTION if any fail. For logfiles, this is accomplished by means of a synchronous wrapper class.
Logfile data is available while the step is still in memory. This means that logs returned from
step.getLoghave the expected methodsgetText,readlinesand so on.ShellCommandsubclasses implicitly gather all stdio output in memory and provide it to thecreateSummarymethod.
2.12.15.3. Rewriting start
If your custom buildstep implements the start method, then rename that method to run and set it up to return a Deferred, either explicitly or via inlineCallbacks.
The value of the Deferred should be the result of the step (one of the codes in buildbot.process.results), or a Twisted failure instance to complete the step as EXCEPTION.
The new run method should not call self.finished or self.failed, instead signalling the same via Deferred.
For example, the following old-style start method :
def start(self): ## old style
cmd = remotecommand.RemoteCommand('stat', {'file': self.file })
d = self.runCommand(cmd)
d.addCallback(lambda res: self.convertResult(cmd))
d.addErrback(self.failed)
Becomes :
@defer.inlineCallbacks
def run(self): ## new style
cmd = remotecommand.RemoteCommand('stat', {'file': self.file })
yield self.runCommand(cmd)
return self.convertResult(cmd)
2.12.15.4. Newly Asynchronous Methods
The following methods now return a Deferred:
log.addStdoutlog.addStderrlog.addHeaderlog.finish(see “Log Objects”, below)
Any custom code in a new-style step that calls these methods must handle the resulting Deferred. In some cases, that means that the calling method’s signature will change. For example :
def summarize(self): ## old-style
for m in self.MESSAGES:
if counts[m]:
self.addCompleteLog(m, "".join(summaries[m]))
self.setProperty("count-%s" % m, counts[m], "counter")
Is a synchronous function, not returning a Deferred.
However, when converted to a new-style test, it must handle Deferreds from the methods it calls, so it must be asynchronous.
Syntactically, inlineCallbacks makes the change fairly simple:
@defer.inlineCallbacks
def summarize(self): ## new-style
for m in self.MESSAGES:
if counts[m]:
yield self.addCompleteLog(m, "".join(summaries[m]))
self.setProperty("count-%s" % m, counts[m], "counter")
However, this method’s callers must now handle the Deferred that it returns. All methods that can be overridden in custom steps can return a Deferred.
2.12.15.5. Properties
The API for properties is the same synchronous API as was available in old-style steps. Properties are handled synchronously during the build, and persisted to the database at completion of each step.
2.12.15.6. Log Objects
Old steps had two ways of interacting with logfiles, both of which have changed.
The first is writing to logs while a step is executing.
When using addCompleteLog or addHTMLLog, this is straightforward, except that in new-style steps these methods return a Deferred.
The second method is via buildbot.process.buildstep.BuildStep.addLog.
In new-style steps, the returned object (via Deferred) has the following methods to add log content:
All of these methods now return Deferreds. None of the old log-reading methods are available on this object:
hasContentsgetTextreadLinesgetTextWithHeadersgetChunks
If your step uses such methods, consider using a LogObserver instead, or using the Data API to get the required data.
The undocumented and unused subscribeConsumer method of logfiles has also been removed.
The subscribe method now takes a callable, rather than an instance, and does not support catchup.
This method was primarily used by LogObserver, the implementation of which has been modified accordingly.
Any other uses of the subscribe method should be refactored to use a LogObserver.
2.12.15.7. Status Strings
The self.step_status.setText and setText2 methods have been removed.
Similarly, the _describe and describe methods are not used in new-style steps.
In fact, steps no longer set their status directly.
Instead, steps call buildbot.process.buildstep.BuildStep.updateSummary whenever the status may have changed.
This method calls getCurrentSummary or getResultSummary as appropriate and update displays of the step’s status.
Steps override the latter two methods to provide appropriate summaries.
2.12.15.8. Statistics
Support for statistics has been moved to the BuildStep and Build objects.
Calls to self.step_status.setStatistic should be rewritten as self.setStatistic.
2.12.16. Transition to “worker” terminology in BuildBot 0.9.0
Since version 0.9.0 of Buildbot “slave”-based terminology is deprecated in favor of “worker”-based terminology.
API change is done in backward compatible way, so old “slave”-containing classes, functions and attributes are still available and can be used. Old API support will be removed in the future versions of Buildbot.
Rename of API introduced in beta versions of Buildbot 0.9.0 done without providing fallback. See release notes for the list of breaking changes of private interfaces. The fallbacks have been removed in Buildbot version 2.0.0.
2.12.16.1. Old names fallback settings
Use of obsolete names will raise Python warnings with category
buildbot.worker_transition.DeprecatedWorkerAPIWarning.
By default these warnings are printed in the application log.
This behaviour can be changed by setting appropriate Python warnings settings
via Python’s warnings module:
import warnings
from buildbot.worker_transition import DeprecatedWorkerAPIWarning
# Treat old-name usage as errors:
warnings.simplefilter("error", DeprecatedWorkerAPIWarning)
See Python’s warnings module documentation for complete list of
available actions, in particular warnings can be disabled using
"ignore" action.
It’s recommended to configure warnings inside buildbot.tac, before
using any other Buildbot classes.
2.12.16.2. Changed API
In general “Slave” and “Buildslave” parts in identifiers and messages were replaced with “Worker”; “SlaveBuilder” with “WorkerForBuilder”.
Below is the list of changed API (use of old names from this list will work). Note that some of these symbols are not included in Buildbot’s public API. Compatibility is provided as a convenience to those using the private symbols anyway.
buildbot.interfaces.IBuildSlavewas renamed toIWorkerbuildbot.interfaces.NoSlaveError(private) left as is, but deprecated (it shouldn’t be used at all)buildbot.interfaces.BuildSlaveTooOldErrorwas renamed toWorkerTooOldErrorbuildbot.interfaces.LatentBuildSlaveFailedToSubstantiate(private) was renamed toLatentWorkerFailedToSubstantiatebuildbot.interfaces.ILatentBuildSlavewas renamed toILatentWorkerbuildbot.interfaces.ISlaveStatus(will be removed in 0.9.x) was renamed toIWorkerStatusbuildbot.buildslavemodule with all contents was renamed tobuildbot.workerbuildbot.buildslave.AbstractBuildSlavewas renamed tobuildbot.worker.AbstractWorkerbuildbot.buildslave.AbstractBuildSlave.slavename(private) was renamed tobuildbot.worker.AbstractWorker.workernamebuildbot.buildslave.AbstractLatentBuildSlavewas renamed tobuildbot.worker.AbstractLatentWorkerbuildbot.buildslave.BuildSlavewas renamed tobuildbot.worker.Workerbuildbot.buildslave.ec2was renamed tobuildbot.worker.ec2buildbot.buildslave.ec2.EC2LatentBuildSlavewas renamed tobuildbot.worker.ec2.EC2LatentWorkerbuildbot.buildslave.libvirtwas renamed tobuildbot.worker.libvirtbuildbot.buildslave.libvirt.LibVirtSlavewas renamed tobuildbot.worker.libvirt.LibVirtWorkerbuildbot.buildslave.openstackwas renamed tobuildbot.worker.openstackbuildbot.buildslave.openstack.OpenStackLatentBuildSlavewas renamed tobuildbot.worker.openstack.OpenStackLatentWorkerbuildbot.config.MasterConfig.slaveswas renamed toworkersbuildbot.config.BuilderConfigconstructor keyword argumentslavenamewas renamed toworkernamebuildbot.config.BuilderConfigconstructor keyword argumentslavenameswas renamed toworkernamesbuildbot.config.BuilderConfigconstructor keyword argumentslavebuilddirwas renamed toworkerbuilddirbuildbot.config.BuilderConfigconstructor keyword argumentnextSlavewas renamed tonextWorkerbuildbot.config.BuilderConfig.slavenameswas renamed toworkernamesbuildbot.config.BuilderConfig.slavebuilddirwas renamed toworkerbuilddirbuildbot.config.BuilderConfig.nextSlavewas renamed tonextWorkerbuildbot.process.slavebuilderwas renamed tobuildbot.process.workerforbuilderbuildbot.process.slavebuilder.AbstractSlaveBuilderwas renamed tobuildbot.process.workerforbuilder.AbstractWorkerForBuilderbuildbot.process.slavebuilder.AbstractSlaveBuilder.slavewas renamed tobuildbot.process.workerforbuilder.AbstractWorkerForBuilder.workerbuildbot.process.slavebuilder.SlaveBuilderwas renamed tobuildbot.process.workerforbuilder.WorkerForBuilderbuildbot.process.slavebuilder.LatentSlaveBuilderwas renamed tobuildbot.process.workerforbuilder.LatentWorkerForBuilderbuildbot.process.build.Build.getSlaveNamewas renamed togetWorkerNamebuildbot.process.build.Build.slavenamewas renamed toworkernamebuildbot.process.builder.enforceChosenSlavewas renamed toenforceChosenWorkerbuildbot.process.builder.Builder.canStartWithSlavebuilderwas renamed tocanStartWithWorkerForBuilderbuildbot.process.builder.Builder.attaching_slaveswas renamed toattaching_workersbuildbot.process.builder.Builder.slaveswas renamed toworkersbuildbot.process.builder.Builder.addLatentSlavewas renamed toaddLatentWorkerbuildbot.process.builder.Builder.getAvailableSlaveswas renamed togetAvailableWorkersbuildbot.schedulers.forcesched.BuildslaveChoiceParameterwas renamed toWorkerChoiceParameterbuildbot.process.buildstep.BuildStep.buildslavewas renamed tobuildbot.process.buildstep.BuildStep.worker(also it was moved from class static attribute to instance attribute)buildbot.process.buildstep.BuildStep.setBuildSlavewas renamed tobuildbot.process.buildstep.BuildStep.setWorkerbuildbot.process.buildstep.BuildStep.slaveVersionwas renamed tobuildbot.process.buildstep.BuildStep.workerVersionbuildbot.process.buildstep.BuildStep.slaveVersionIsOlderThanwas renamed tobuildbot.process.buildstep.BuildStep.workerVersionIsOlderThanbuildbot.process.buildstep.BuildStep.checkSlaveHasCommandwas renamed tobuildbot.process.buildstep.BuildStep.checkWorkerHasCommandbuildbot.process.buildstep.BuildStep.getSlaveNamewas renamed tobuildbot.process.buildstep.BuildStep.getWorkerNamebuildbot.locks.SlaveLockwas renamed tobuildbot.locks.WorkerLockbuildbot.locks.SlaveLock.maxCountForSlavewas renamed tobuildbot.locks.WorkerLock.maxCountForWorkerbuildbot.locks.SlaveLockconstructor argumentmaxCountForSlavewas renamed tomaxCountForWorkerbuildbot.steps.slavewas renamed tobuildbot.steps.workerbuildbot.steps.slave.SlaveBuildStepwas renamed tobuildbot.steps.worker.WorkerBuildStepbuildbot.steps.slave.CompositeStepMixin.getFileContentFromSlavewas renamed tobuildbot.steps.worker.CompositeStepMixin.getFileContentFromWorkerbuildbot.steps.transfer.FileUpload.slavesrcwas renamedworkersrcbuildbot.steps.transfer.FileUploadconstructor argumentslavesrcwas renamed toworkersrcbuildbot.steps.transfer.DirectoryUpload.slavesrcwas renamed toworkersrcbuildbot.steps.transfer.DirectoryUploadconstructor argumentslavesrcwas renamed toworkersrcbuildbot.steps.transfer.MultipleFileUpload.slavesrcswas renamed toworkersrcsbuildbot.steps.transfer.MultipleFileUploadconstructor argumentslavesrcswas renamed toworkersrcsbuildbot.steps.transfer.FileDownload.slavedestwas renamed toworkerdestbuildbot.steps.transfer.FileDownloadconstructor argumentslavedestwas renamed toworkerdestbuildbot.steps.transfer.StringDownload.slavedestwas renamed toworkerdestbuildbot.steps.transfer.StringDownloadconstructor argumentslavedestwas renamed toworkerdestbuildbot.steps.transfer.JSONStringDownload.slavedestwas renamed toworkerdestbuildbot.steps.transfer.JSONStringDownloadconstructor argumentslavedestwas renamed toworkerdestbuildbot.steps.transfer.JSONPropertiesDownload.slavedestwas renamed toworkerdestbuildbot.steps.transfer.JSONPropertiesDownloadwas renamed to constructor argumentslavedestwas renamed toworkerdestbuildbot.process.remotecommand.RemoteCommand.buildslavewas renamed toworker
2.12.16.3. Plugins
buildbot.buildslave entry point was renamed to buildbot.worker, new
plugins should be updated accordingly.
Plugins that use old buildbot.buildslave entry point are still available
in the configuration file in the same way, as they were in versions prior
0.9.0:
from buildbot.plugins import buildslave # deprecated, use "worker" instead
w = buildslave.ThirdPartyWorker()
But also they available using new namespace inside configuration
file, so its recommended to use buildbot.plugins.worker
name even if plugin uses old entry points:
from buildbot.plugins import worker
# ThirdPartyWorker can be defined in using `buildbot.buildslave` entry
# point, this still will work.
w = worker.ThirdPartyWorker()
Other changes:
buildbot.plugins.util.BuildslaveChoiceParameteris deprecated in favor ofWorkerChoiceParameter.buildbot.plugins.util.enforceChosenSlaveis deprecated in favor ofenforceChosenWorker.buildbot.plugins.util.SlaveLockis deprecated in favor ofWorkerLock.
2.12.16.4. BuildmasterConfig changes
c['slaves']was replaced withc['workers']. Use ofc['slaves']will work, but is considered deprecated, and will be removed in the future versions of Buildbot.Configuration key
c['slavePortnum']is deprecated in favor ofc['protocols']['pb']['port'].
2.12.16.5. Docker latent worker changes
In addition to class being renamed, environment variables that are set inside
container SLAVENAME and SLAVEPASS were renamed to
WORKERNAME and WORKERPASS accordingly.
Old environment variable are still available, but are deprecated and will be
removed in the future.
2.12.16.6. EC2 latent worker changes
Use of default values of keypair_name and security_name
constructor arguments of buildbot.worker.ec2.EC2LatentWorker
is deprecated. Please specify them explicitly.
2.12.16.7. steps.slave.SetPropertiesFromEnv changes
In addition to buildbot.steps.slave module being renamed to
buildbot.steps.worker, default source value for
SetPropertiesFromEnv was changed from
"SlaveEnvironment" to "WorkerEnvironment".
2.12.16.8. Local worker changes
Working directory for local workers were changed from
master-basedir/slaves/name to master-basedir/workers/name.
2.12.16.9. Worker Manager changes
slave_config function argument was renamed to worker_config.
2.12.16.10. Properties
slavenameproperty is deprecated in favor ofworkernameproperty. Render of deprecated property will produce warning.buildbot.worker.AbstractWorker(previouslybuildbot.buildslave.AbstractBuildSlave)slavenameproperty source were changed fromBuildSlavetoWorker (deprecated)AbstractWorkernow setsworkernameproperty with sourceWorkerwhich should be used.
2.12.16.11. Metrics
buildbot.process.metrics.AttachedSlavesWatcherwas renamed tobuildbot.process.metrics.AttachedWorkersWatcher.buildbot.worker.manager.WorkerManager.name(previouslybuildbot.buildslave.manager.BuildslaveManager.name) metric measurement class name changed fromBuildslaveManagertoWorkerManagerbuildbot.worker.manager.WorkerManager.managed_services_name(previouslybuildbot.buildslave.manager.BuildslaveManager.managed_services_name`) metric measurement managed service name changed from ``buildslavestoworkers
Renamed events:
Old name |
New name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
2.12.16.12. Database
Schema changes:
Old name |
New name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
List of database-related changes in API (fallback for old API is provided):
buildbot.db.buildslaveswas renamed toworkersbuildbot.db.buildslaves.BuildslavesConnectorComponentwas renamed tobuildbot.db.workers.WorkersConnectorComponentbuildbot.db.buildslaves.BuildslavesConnectorComponent.getBuildslaves(rewritten in nine) was renamed tobuildbot.db.workers.WorkersConnectorComponent.getWorkersbuildbot.db.connector.DBConnector.buildslaveswas renamed tobuildbot.db.connector.DBConnector.workers
2.12.16.13. usePTY changes
usePTY default value has been changed from slave-config to None (use of
slave-config will still work, but discouraged).
2.12.16.14. buildbot-worker
buildbot-slave package has been renamed to buildbot-worker.
buildbot-worker has backward incompatible changes and requires buildmaster >= 0.9.0b8.
buildbot-slave from 0.8.x will work with both 0.8.x and 0.9.x versions of buildmaster, so there
is no need to upgrade currently deployed buildbot-slaves during switch from 0.8.x to 0.9.x.
master 0.8.x |
master 0.9.x |
|
|---|---|---|
buildbot-slave |
yes |
yes |
buildbot-worker |
no |
yes |
buildbot-worker doesn’t support worker-side specification of usePTY (with --usepty
command line switch of buildbot-worker create-worker), you need to specify this option on
master side.
getSlaveInfo remote command was renamed to getWorkerInfo in buildbot-worker.
3. Buildbot Development
This chapter is the official repository for the collected wisdom of the Buildbot hackers. It is intended both for developers writing patches that will be included in Buildbot itself and for advanced users who wish to customize Buildbot.
Note
Public API
Any API that is not documented in the official Buildbot documentation is considered internal and subject to change. If you would like it to be officially exposed, open a bug report on the Buildbot Github project.
3.1. Development Quick-start
Buildbot is a python based application. It tries very hard to follow the python best practices and make it easy to dive into the code.
In order to develop on Buildbot you need just a python environment and possibly some native packages in stripped-down setups. The most up to date list is in the docker file we use to manage our CI (MetaBBotDockerFile).
If you are completely new to python, it’s best to first follow the tutorials you get when you type “python virtualenv for dummies” in your favorite search engine.
3.1.1. Create a Buildbot Python Environment
Buildbot uses Twisted trial to run its test suite.
Windows users also need GNU make on their machines.
The easiest way is to install it via the choco package manager, choco install make.
But WSL or MSYS2 is an even better option because of the integrated bash.
Note that on Windows you need to create virtualenv manually.
Following is a quick shell session to put you on the right track, including running the test suite.
# the usual buildbot development bootstrap with git and virtualenv
git clone https://github.com/buildbot/buildbot
cd buildbot
# run a helper script which creates the virtualenv for development.
# Virtualenv allows to install python packages without affecting
# other parts of the system.
# This script does not support Windows: you should create the virtualenv and install
# requirements-ci.txt manually.
make virtualenv
# activate the virtualenv (you should now see (.venv) in your shell prompt)
. .venvpython3/bin/activate
# now run the test suite
trial buildbot
# using all CPU cores within the system helps to speed everything up
trial -j16 buildbot
# find all tests that talk about mail
trial -n --reporter=bwverbose buildbot | grep mail
# run only one test module
trial buildbot.test.unit.reporters.test_mail.TestMailNotifier
# you can also skip the virtualenv activation and
# run the test suite in one step with make
make trial
# you can pass options to make using TRIALOPTS
make trial TRIALOPTS='-j16 buildbot'
# or test with a specific Python version
make trial VENV_PY_VERSION=/usr/local/bin/python3
3.1.2. Create a JavaScript Frontend Environment
This section describes how to get set up quickly to hack on the JavaScript UI.
It does not assume familiarity with Python, although a Python installation is required, as well as virtualenv.
You will also need NodeJS, and yarn installed.
3.1.2.1. Prerequisites
Note
Buildbot UI requires at least node 14.18 or newer and yarn 1.x.
Install LTS release of Node.js.
http://nodejs.org/ is a good start for Windows and macOS.
For modern Linux distributions, you can often just install the distribution-provided packages if they are recent enough. Note, that on Debian-based distributions yarn is available as yarnpkg.
The below method has been tested on Debian Bookworm.
sudo apt install nodejs yarnpkg
In other cases, use https://deb.nodesource.com and https://classic.yarnpkg.com/lang/en/docs/install.
3.1.2.2. Hacking the Buildbot JavaScript
To effectively develop Buildbot JavaScript, you’ll need a running Buildmaster configured to operate out of the source directory.
As a prerequisite, follow Create a Buildbot Python Environment. With that, you should have created and enabled a virtualenv Python environment.
Next, you need to install the buildbot and buildbot-www python packages in --editable mode, which means their source directories will be directly used.
make frontend
This will fetch a number of Python dependencies from PyPI, the Python package repository, and also a number of Node.js dependencies that are used for building the web application.
Then the actual frontend code will be built with artifacts stored in the source directory, e.g. www/base/buildbot_www/static.
Finally, the built python packages will be installed to virtualenv environment as --editable packages.
This means that the webserver will load resources from www/base/buildbot_www/static.
Now you need to create a master instance. For more details, see the Buildbot First Run tutorial.
mkdir test-master
buildbot create-master test-master
mv test-master/master.cfg.sample test-master/master.cfg
buildbot start test-master
If all goes well, the master will start up and run in the background.
During make frontend, the www frontend was built using production mode, so everything is minified and hard to debug.
However, the frontend was installed as an editable python package, so all changes in the artifacts (e.g. www/base/buildbot_www/static) in the source directories will be observed in the browser.
Thus, we can manually rebuild the JavaScript resources using development settings, so they are not minified and easier to debug.
This can be done by running the following in e.g. www/base directory:
yarn run build-dev
The above rebuilds the resources only once. After each change you need to refresh the built resources.
The actual commands that are run are stored in the package.json file under the scripts key.
To avoid the need to type the above command after each change, you can use the following:
yarn run dev
This will watch files for changes and reload automatically.
To run unit tests, do the following:
yarn run test
To run unit tests within all frontend packages within Buildbot, do the following at the root of the project:
make frontend_tests
3.2. Submitting Pull Requests
As Buildbot is used by software developers, it tends to receive a significant number of patches. The most effective way to make sure your patch gets noticed and merged is to submit it via GitHub. This assumes some familiarity with git, but not too much. Note that GitHub has some great Git guides to get you started.
3.2.1. Guidelines
Pull requests should be based on the latest development code, not on the most recent release. That is, you should check out the master branch and develop on top of it.
Final pull requests should include code changes, relevant documentation changes, and relevant unit tests. Any patch longer than a few lines which does not have documentation or tests is unlikely to be merged as is. The developers will most likely ask to add documentation or tests.
Individual commits should, to the extent possible, be single-purpose. Please do not lump all of the changes you made to get Buildbot working the way you like into a single commit.
Pull requests must pass all tests that run against the GitHub pull requests. See Local testing cheat sheet for instructions of how to launch various tests locally.
Python code in Buildbot uses four-space indentations, with no tabs. Lines should be wrapped before the 100th column.
Pull requests must reliably pass all tests. Buildbot does not tolerate “flaky” tests. If you have trouble with tests that fail without any of your changes applied, get in touch with the developers for help.
Pull requests that add features or change existing behavior should include a brief description in the release notes. See the newsfragments directory and read the README.txt file therein.
Git commit messages form the “ChangeLog” for Buildbot, and as such should be as descriptive as possible.
Backward and forward compatibility is important to Buildbot. Try to minimize the effect of your patch on existing users.
3.2.1.1. Additional suggestions
The Buildbot developers are quite busy, and it can take a while to review a patch. While the following are not required, they will make things easier for you and the developers:
Make a distinct pull request, on a distinct branch in your repository, for each unrelated change. Some pull request may get merged immediately, while others will require revision, and this can get very confusing in a single branch.
Smaller, incremental commits are better than one large commit, as they can be considered on their own merits. It’s OK for a commit to add code that is unused (except for tests, of course) until a subsequent commit is applied.
If an individual change is complex or large, it makes sense to create an unpolished PR at first to gather feedback. When the Buildbot developers confirm that the presented pull request is the way to go, it can be polished as a second step.
Git history is the primary means by which Buildbot establishes authorship. Be careful to credit others for their work, if you include it in your code.
3.2.2. How to create a pull request
Note
See this github guide which offers a more generic description of this process.
Sign up for a free account at http://github.com, if you don’t already have one.
Go to http://github.com/buildbot/buildbot and click “fork”. This will create your own public copy of the latest Buildbot source.
Clone your forked repository on your local machine, so you can do your changes. GitHub will display a link titled “Your Clone URL”. Click this link to see instructions for cloning your URL. It’s something like:
git clone git@github.com:myusername/buildbot.git
cd buildbot
Locally, create a new branch based on the master branch:
git checkout -b myfixes origin/master
Hack mercilessly. If you’re a git aficionado, you can make a neat and pretty commit sequence; otherwise, just get it done. Don’t forget to add new test cases and any necessary documentation.
Test your changes. See Local testing cheat sheet for instructions of how to launch various tests locally.
Commit. For this step it’s best to use a GUI for Git. See this list of known Git GUIs. If you only want to use the shell, do the following:
git add $files_that_matter
git commit
When you’re confident that everything is as it should be, push your changes back to your repository on GitHub, effectively making them public.
git push origin myfixes
Now all that’s left is to let the Buildbot developers know that you have patches awaiting their attention. In your web browser, go to your repository (you may have to hit “reload”) and choose your new branch from the “all branches” menu.
Double-check that you’re on your branch, and not on a particular commit. The current URL should end in the name of your patch, not in a SHA1 hash.
Click “Pull Request”
Double-check that the base branch is “buildbot/buildbot@master”. If your repository is a fork of the buildbot/buildbot repository, this should already be the case.
Fill out the details and send away!
3.2.3. Local testing cheat sheet
This section details how to locally run the test suites that are run by Buildbot during each PR. Not all test suites have been documented so far, only these that fail most often. Before each of the commands detailed below, a virtualenv must be setup as described in Create a Buildbot Python Environment:
make virtualenv
. .venv/bin/activate
If you see weird test results after changing branches of the repository, remove the .venv directory and repeat the above again. Note that pip install -r <file>.txt only needs to be run once at the beginning of your testing session.
3.2.3.1. Master unit tests
Tests in this category run the Python unit tests for the master. These tests are represented by bb/trial/ test names in the Buildbot CI. To run locally, execute the following:
pip install -r requirements-ci.txt
trial -j8 buildbot # change -j parameter to fit the number of cores you have
3.2.3.2. Worker unit tests
Tests in this category run the Python unit tests for the worker. These tests are represented by bb/trial_worker/ test names in the Buildbot CI. To run locally, execute the following:
pip install -r requirements-ciworker.txt
trial buildbot_worker
3.2.3.3. Linter checks
Tests in this category run simple syntax and style checks on the Python code. These tests are represented by bb/pylint/ and bb/ruff/ test names in the Buildbot CI. To run locally, execute the following:
pip install -r requirements-ci.txt
make pylint
make ruff
If you see spell check errors, but your words are perfectly correct, then you may need to add these words to a whitelist at common/code_spelling_ignore_words.txt.
3.2.3.4. Documentation
This test builds the documentation. It is represented by bb/docs/ test names in the Buildbot CI. To run locally, execute the following:
pip install -r requirements-ci.txt
pip install -r requirements-cidocs.txt
make docs
If you see spell check errors, but your words are perfectly correct, then you may need to add these words to a whitelist at master/docs/spelling_wordlist.txt.
3.2.3.5. End-to-end tests
Tests in this category run the end-to-end tests by launching a full Buildbot instance, clicking on buttons on the web UI and testing the results. It is represented by bb/e2e/** test names in the Buildbot CI. The tests are sometimes unstable: if you didn’t change the front end code and see a failure then it’s most likely an instability. To run locally, install a Chrome-compatible browser and execute the following:
pip install -r requirements-ci.txt
make tarballs
./common/smokedist-react.sh whl
3.3. General Documents
This section gives some general information about Buildbot development.
3.3.1. Master Organization
Buildbot makes heavy use of Twisted Python’s support for services - software modules that can be started and stopped dynamically. Buildbot adds the ability to reconfigure such services, too - see Reconfiguration. Twisted arranges services into trees; the following section describes the service tree on a running master.
3.3.1.1. BuildMaster Object
The hierarchy begins with the master, a buildbot.master.BuildMaster
instance. Most other services contain a reference to this object in their
master attribute, and in general the appropriate way to access other
objects or services is to begin with self.master and navigate from there.
The master has a number of useful attributes:
master.metricsA
buildbot.process.metrics.MetricLogObserverinstance that handles tracking and reporting on master metrics.master.cachesA
buildbot.process.caches.CacheManagerinstance that provides access to object caches.master.pbmanagerA
buildbot.pbmanager.PBManagerinstance that handles incoming PB connections, potentially on multiple ports, and dispatching those connections to appropriate components based on the supplied username.master.workersA
buildbot.worker.manager.WorkerManagerinstance that provides wrappers around multiple master-worker protocols (e.g. PB) to unify calls for them from higher level code.master.change_svcA
buildbot.changes.manager.ChangeManagerinstance that manages the active change sources, as well as the stream of changes received from those sources. All active change sources are child services of this instance.master.botmasterA
buildbot.process.botmaster.BotMasterinstance that manages all of the workers and builders as child services.The botmaster acts as the parent service for a
buildbot.process.botmaster.BuildRequestDistributorinstance (atmaster.botmaster.brd), as well as all active workers (buildbot.worker.AbstractWorkerinstances) and builders (buildbot.process.builder.Builderinstances).master.scheduler_managerA
buildbot.schedulers.manager.SchedulerManagerinstance that manages the active schedulers. All active schedulers are child services of this instance.master.user_managerA
buildbot.process.users.manager.UserManagerManagerinstance that manages access to users. All active user managers are child services of this instance.master.dbA
buildbot.db.connector.DBConnectorinstance that manages access to the buildbot database. See Database for more information.master.debugA
buildbot.process.debug.DebugServicesinstance that manages debugging-related access – the manhole, in particular.master.masteridThis is the ID for this master, from the
masterstable. It is used in the database and messages to uniquely identify this master.
3.3.2. Buildbot Coding Style
3.3.2.1. Documentation
Buildbot strongly encourages developers to document the methods, behavior, and usage of classes
that users might interact with. However, this documentation should be in .rst files under
master/docs/developer, rather than in docstrings within the code. For private methods or where
code deserves some kind of explanatory preface, use comments instead of a docstring. While some
docstrings remain within the code, these should be migrated to documentation files and removed as
the code is modified.
Within the reStructuredText files, write each English sentence on its own line. While this does not affect the generated output, it makes git diffs between versions of the documentation easier to read, as they are not obscured by changes due to re-wrapping. This convention is not followed everywhere, but we are slowly migrating documentation from the old (wrapped) style as we update it.
3.3.2.2. Symbol Names
Buildbot follows PEP8 regarding the formatting of symbol names.
Due to historical reasons, most of the public API uses interCaps naming style To preserve backwards
compatibility, the public API should continue using interCaps naming style. That is, you should
spell public API methods and functions with the first character in lower-case, and the first letter
of subsequent words capitalized, e.g., compareToOther or getChangesGreaterThan. The public
API refers to the documented API that external developers can rely on. See section on the
definition of the public API in Buildbot Development.
Everything else should use the style recommended by PEP8.
In summary:
Symbol Type |
Format |
|---|---|
Methods and functions |
under_scores |
Method and function arguments |
under_scores |
Public API methods and functions |
interCaps |
Public API method and function arguments |
interCaps |
Classes |
InitialCaps |
Variables |
under_scores |
Constants |
ALL_CAPS |
3.3.2.3. Twisted Idioms
Programming with Twisted Python can be daunting. But sticking to a few well-defined patterns can help avoid surprises.
Prefer to Return Deferreds
If you’re writing a method that doesn’t currently block, but could conceivably block sometime in the future, return a Deferred and document that it does so. Just about anything might block - even getters and setters!
Helpful Twisted Classes
Twisted has some useful, but little-known classes. Brief descriptions follow, but you should consult the API documentation or source code for the full details.
twisted.internet.task.LoopingCallCalls an asynchronous function repeatedly at set intervals. Note that this will stop looping if the function fails. In general, you will want to wrap the function to capture and log errors.
twisted.application.internet.TimerServiceSimilar to
t.i.t.LoopingCall, but implemented as a service that will automatically start and stop the function calls when the service starts and stops. See the warning about failing functions fort.i.t.LoopingCall.
Sequences of Operations
Especially in Buildbot, we’re often faced with executing a sequence of operations, many of which may block.
In all cases where this occurs, there is a danger of pre-emption, so exercise the same caution you would if writing a threaded application.
For simple cases, you can use nested callback functions. For more complex cases, inlineCallbacks is appropriate. In all cases, please prefer maintainability and readability over performance.
Nested Callbacks
First, an admonition: do not create extra class methods that represent the continuations of the first:
def myMethod(self):
d = ...
d.addCallback(self._myMethod_2) # BAD!
def _myMethod_2(self, res): # BAD!
...
Invariably, this extra method gets separated from its parent as the code evolves, and the result is completely unreadable. Instead, include all of the code for a particular function or method within the same indented block, using nested functions:
def getRevInfo(revname):
# for demonstration only! see below for a better implementation with inlineCallbacks
results = {}
d = defer.succeed(None)
def rev_parse(_): # note use of '_' to quietly indicate an ignored parameter
return utils.getProcessOutput(git, [ 'rev-parse', revname ])
d.addCallback(rev_parse)
def parse_rev_parse(res):
results['rev'] = res.strip()
return utils.getProcessOutput(git, [ 'log', '-1', '--format=%s%n%b', results['rev'] ])
d.addCallback(parse_rev_parse)
def parse_log(res):
results['comments'] = res.strip()
d.addCallback(parse_log)
def set_results(_):
return results
d.addCallback(set_results)
return d
It is usually best to make the first operation occur within a callback, as the deferred machinery
will then handle any exceptions as a failure in the outer Deferred. As a shortcut,
d.addCallback can work as a decorator:
d = defer.succeed(None)
@d.addCallback
def rev_parse(_): # note use of '_' to quietly indicate an ignored parameter
return utils.getProcessOutput(git, [ 'rev-parse', revname ])
Note
d.addCallback is not really a decorator as it does not return a modified function. As a
result, in the previous code, rev_parse value is actually the Deferred. In general, the
inlineCallbacks method is preferred inside new code as it keeps the code easier to
read. As a general rule of thumb, when you need more than 2 callbacks in the same method, it’s
time to switch to inlineCallbacks. This would be for example the case for the
getRevInfo example. See this discussion <:pull:`2523>`_ with Twisted experts for
more information.
Be careful with local variables. For example, if parse_rev_parse, above,
merely assigned rev = res.strip(), then that variable would be local to
parse_rev_parse and not available in set_results. Mutable variables
(dicts and lists) at the outer function level are appropriate for this purpose.
Note
Do not try to build a loop in this style by chaining multiple
Deferreds! Unbounded chaining can result in stack overflows, at least on older
versions of Twisted. Use inlineCallbacks instead.
In most of the cases, if you need more than two callbacks in a method, it is more readable and maintainable to use inlineCallbacks.
inlineCallbacks
twisted.internet.defer.inlineCallbacks is a great help to writing code that makes a lot of
asynchronous calls, particularly if those calls are made in loop or conditionals. Refer to the
Twisted documentation for the details, but the style within Buildbot is as follows:
from twisted.internet import defer
@defer.inlineCallbacks
def mymethod(self, x, y):
xval = yield getSomething(x)
for z in (yield getZValues()):
y += z
if xval > 10:
return xval + y
self.someOtherMethod()
The key points to notice here:
Always import
deferas a module, not the names within it.Use the decorator form of
inlineCallbacks.In most cases, the result of a
yieldexpression should be assigned to a variable. It can be used in a larger expression, but remember that Python requires that you enclose the expression in its own set of parentheses.
The great advantage of inlineCallbacks is that it allows you to use all of the usual Pythonic control structures in their natural form.
In particular, it is easy to represent a loop or even nested loops in this style without losing any readability.
Note that code using deferredGenerator is no longer acceptable in Buildbot.
The previous getRevInfo example implementation should rather be written as:
@defer.inlineCallbacks
def getRevInfo(revname):
results = {}
res = yield utils.getProcessOutput(git, [ 'rev-parse', revname ])
results['rev'] = res.strip()
res = yield utils.getProcessOutput(git, [ 'log', '-1', '--format=%s%n%b',
results['rev'] ])
results['comments'] = res.strip()
return results
Locking
Remember that asynchronous programming does not free you from the need to worry about concurrency issues. In particular, if you are executing a sequence of operations, and each time you wait for a Deferred, other arbitrary actions can take place.
In general, you should try to perform actions atomically, but for the rare situations that require synchronization, the following might be useful:
twisted.internet.defer.DeferredLock
Joining Sequences
It’s often the case that you want to perform multiple operations in parallel and rejoin the results at the end. For this purpose, you may use a DeferredList:
def getRevInfo(revname):
results = {}
finished = dict(rev_parse=False, log=False)
rev_parse_d = utils.getProcessOutput(git, [ 'rev-parse', revname ])
def parse_rev_parse(res):
return res.strip()
rev_parse_d.addCallback(parse_rev_parse)
log_d = utils.getProcessOutput(git, [ 'log', '-1', '--format=%s%n%b', results['rev'] ])
def parse_log(res):
return res.strip()
log_d.addCallback(parse_log)
d = defer.DeferredList([rev_parse_d, log_d], consumeErrors=1, fireOnFirstErrback=1)
def handle_results(results):
return dict(rev=results[0][1], log=results[1][1])
d.addCallback(handle_results)
return d
Here, the deferred list will wait for both rev_parse_d and log_d to fire, or for one of
them to fail. You may attach callbacks and errbacks to a DeferredList just as you would with a
deferred.
Functions running outside of the main thread
It is very important in Twisted to be able to distinguish functions that runs in the main thread
and functions that don’t, as reactors and deferreds can only be used in the main thread. To make
this distinction clearer, every function meant to be run in a secondary thread must be prefixed
with thd_.
3.3.3. Buildbot’s Test Suite
Buildbot’s master tests are under buildbot.test and buildbot-worker package tests are under
buildbot_worker.test. Tests for the workers are similar to the master, although in some cases
helpful functionality on the master is not re-implemented on the worker.
3.3.3.1. Quick-Start
Buildbot uses Twisted trial to run its test suite. Following is a quick shell session to put you on the right track.
# the usual buildbot development bootstrap with git and virtualenv
git clone https://github.com/buildbot/buildbot
cd buildbot
# helper script which creates the virtualenv for development
make virtualenv
. .venvpython3/bin/activate
# now run the test suite
trial buildbot
# find all tests that talk about mail
trial -n --reporter=bwverbose buildbot | grep mail
# run only one test module
trial buildbot.test.unit.reporters.test_mail.TestMailNotifier
3.3.3.2. Suites
Tests are divided into a few suites:
Unit tests (
buildbot.test.unit) - these follow unit-testing practices and attempt to maximally isolate the system under test. Unit tests are the main mechanism of achieving test coverage, and all new code should be well-covered by corresponding unit tests.Interface tests are a special type of unit tests, and are found in the same directory and often the same file. In many cases, Buildbot has multiple implementations of the same interface – at least one “real” implementation and a fake implementation used in unit testing. The interface tests ensure that these implementations all meet the same standards. This ensures consistency between implementations, and also ensures that the unit tests are tested against realistic fakes.
Integration tests (
buildbot.test.integration) - these test combinations of multiple units. Of necessity, integration tests are incomplete - they cannot test every condition; difficult to maintain - they tend to be complex and touch a lot of code; and slow - they usually require considerable setup and execute a lot of code. As such, use of integration tests is limited to a few broad tests that act as a failsafe for the unit and interface tests.Regression tests (
buildbot.test.regressions) - these tests are used to prevent re-occurrence of historical bugs. In most cases, a regression is better tested by a test in the other suites, or is unlikely to recur, so this suite tends to be small.Fuzz tests (
buildbot.test.fuzz) - these tests run for a long time and apply randomization to try to reproduce rare or unusual failures. The Buildbot project does not currently have a framework to run fuzz tests regularly.
Unit Tests
Every code module should have corresponding unit tests. This is not currently true of Buildbot, due to a large body of legacy code, but is a goal of the project. All new code must meet this requirement.
Unit test modules follow the source file hierarchy (omitting the root buildbot directory) and
are named after the package or class they test (replacing . with _). For example,
test_timed_Periodic.py tests
the Periodic class in master/buildbot/schedulers/timed.py. Modules with only one
class, or a few trivial classes, can be tested in a single test module. For more complex
situations, prefer to use multiple test modules.
Unit tests using renderables require special handling. The following example shows how the same test would be written with the ‘param’ parameter as a plain argument and with the same parameter as a renderable:
def test_param(self):
f = self.ConcreteClass(param='val')
self.assertEqual(f.param, 'val')
When the parameter is renderable, you need to instantiate the class before you can test the renderables:
def setUp(self):
self.build = Properties(param='val')
@defer.inlineCallbacks
def test_param_renderable(self):
f = self.ConcreteClass(
param=Interpolate('%(kw:rendered_val)s',
rendered_val=Property('param')))
yield f.start_instance(self.build)
self.assertEqual(f.param, 'val')
Interface Tests
Interface tests exist to verify that multiple implementations of an interface meet the same requirements. Note that the name ‘interface’ should not be confused with the sparse use of Zope Interfaces in the Buildbot code – in this context, an interface is any boundary between testable units.
Ideally, all interfaces, both public and private, should be tested. Certainly, any public interfaces need interface tests.
Interface tests are most often found in files named for the “real” implementation, e.g., test_changes.py. When there is ambiguity, test modules should be named after the interface they are testing. Interface tests have the following form:
from buildbot.test.util import interfaces
from twistd.trial import unittest
class Tests(interfaces.InterfaceTests):
# define methods that must be overridden per implementation
def someSetupMethod(self):
raise NotImplementedError
# method signature tests
def test_signature_someMethod(self):
@self.assertArgSpecMatches(self.systemUnderTest.someMethod)
def someMethod(self, arg1, arg2):
pass
# tests that all implementations must pass
def test_something(self):
pass # ...
class RealTests(Tests):
# tests that only *real* implementations must pass
def test_something_else(self):
pass # ...
All of the test methods are defined here, segregated into tests that all implementations must pass,
and tests that the fake implementation is not expected to pass. The test_signature_someMethod
test above illustrates the buildbot.test.util.interfaces.assertArgSpecMatches decorator,
which can be used to compare the argument specification of a callable with a reference signature
conveniently written as a nested function. Wherever possible, prefer to add tests to the Tests
class, even if this means testing one method (e.g,. setFoo) in terms of another (e.g.,
getFoo).
The assertArgSpecMatches method can take multiple methods to test; it will check each one in turn.
At the bottom of the test module, a subclass is created for each implementation, implementing the setup methods that were stubbed out in the parent classes:
class TestFakeThing(unittest.TestCase, Tests):
def someSetupMethod(self):
pass # ...
class TestRealThing(unittest.TestCase, RealTests):
def someSetupMethod(self):
pass # ...
For implementations which require optional software, such as an AMQP server, this is the appropriate place to signal that tests should be skipped when their prerequisites are not available:
from twisted.trial import unittest
class TestRealThing(unittest.TestCase, RealTests):
def someSetupMethod(self):
try:
import foo
except ImportError:
raise unittest.SkipTest("foo not found")
Integration Tests
Integration test modules test several units at once, including their interactions. In general, they serve as a catch-all for failures and bugs that were not detected by the unit and interface tests. As such, they should not aim to be exhaustive, but merely representative.
Integration tests are very difficult to maintain if they reach into the
internals of any part of Buildbot. Where possible, try to use the same means
as a user would to set up, run, and check the results of an integration test.
That may mean writing a master.cfg to be parsed, and checking the
results by examining the database (or fake DB API) afterward.
Regression Tests
Regression tests are even more rare in Buildbot than integration tests. In many cases, a regression test is not necessary – either the test is better-suited as a unit or interface test, or the failure is so specific that a test will never fail again.
Regression tests tend to be closely tied to the code in which the error occurred. When that code is refactored, the regression test generally becomes obsolete, and is deleted.
Fuzz Tests
Fuzz tests generally run for a fixed amount of time, running randomized tests
against a system. They do not run at all during normal runs of the Buildbot
tests, unless BUILDBOT_FUZZ is defined. This is accomplished with something
like the following at the end of each test module:
if 'BUILDBOT_FUZZ' not in os.environ:
del LRUCacheFuzzer
3.3.3.3. Mixins
Buildbot provides a number of purpose-specific mixin classes in master/buildbot/util.
These generally define a set of utility functions as well as setUpXxx and tearDownXxx methods.
These methods should be called explicitly from your subclass’s setUp and tearDown methods.
Note that some of these methods return Deferreds, which should be handled properly by the caller.
3.3.3.4. Fakes
Buildbot provides a number of pre-defined fake implementations of internal interfaces, in master/buildbot/test/fake. These are designed to be used in unit tests to limit the scope of the test. For example, the fake DB API eliminates the need to create a real database when testing code that uses the DB API, and isolates bugs in the system under test from bugs in the real DB implementation.
The danger of using fakes is that the fake interface and the real interface can differ. The interface tests exist to solve this problem. All fakes should be fully tested in an integration test, so that the fakes pass the same tests as the “real” thing. It is particularly important that the method signatures be compared.
3.3.3.5. Type Validation
The master/buildbot/test/util/validation.py provides a set of classes and definitions for validating Buildbot data types. It supports four types of data:
DB API dictionaries, as returned from the
getXxxmethods,Data API dictionaries, as returned from
get,Data API messages, and
Simple data types.
These are validated from elsewhere in the codebase with calls to
verifyData(testcase, type, options, value),
verifyMessage(testcase, routingKey, message), and
verifyType(testcase, name, value, validator),
respectively.
The testcase argument is used to fail the test case if the validation does not succeed.
For DB dictionaries and data dictionaries, the type identifies the expected data type.
For messages, the type is determined from the first element of the routing key.
All messages sent with the fake MQ implementation are automatically validated using verifyMessage.
The verifyType method is used to validate simple types, e.g.,
validation.verifyType(self, 'param1', param1, validation.StringValidator())
In any case, if testcase is None, then the functions will raise an AssertionError on failure.
Validator Classes
A validator is an instance of the Validator class.
Its validate method is a generator function that takes a name and an object to validate.
It yields error messages describing any deviations of object from the designated data type.
The name argument is used to make such messages more helpful.
A number of validators are supplied for basic types. A few classes deserve special mention:
NoneOkwraps another validator, allowing the object to be None.
Anywill match any object without error.
IdentifierValidatorwill match identifiers; see identifier.
DictValidatortakes key names as keyword arguments, with the values giving validators for each key. TheoptionalNamesargument is a list of keys which may be omitted without error.
SourcedPropertiesValidatormatches dictionaries with (value, source) keys, the representation used for properties in the data API.
MessageValidatorvalidates messages. It checks that the routing key is a tuple of strings. The first tuple element gives the message type. The last tuple element is the event, and must be a member of theeventsset. ThemessageValidatorshould be aDictValidatorconfigured to check the message body. This validator’svalidatemethod is called with a tuple(routingKey, message).
Selectorallows different validators to be selected based on matching functions. Itsaddmethod takes a matching function, which should return a boolean, and a validator to use if the matching function returns true. If the matching function is None, it is used as a default. This class is used for message and data validation.
Defining Validators
DB validators are defined in the dbdict dictionary, e.g.,
dbdict['foodict'] = DictValidator(
id=IntValidator(),
name=StringValidator(),
...
)
Data validators are Selector validators, where the selector is the options passed to verifyData.
data['foo'] = Selector()
data['foo'].add(lambda opts : opt.get('fanciness') > 10,
DictValidator(
fooid=IntValidator(),
name=StringValidator(),
...
))
Similarly, message validators are Selector validators, where the selector is the routing key.
The underlying validator should be a MessageValidator.
message['foo'] = Selector()
message['foo'].add(lambda rk : rk[-1] == 'new',
MessageValidator(
events=['new', 'complete'],
messageValidator=DictValidator(
fooid=IntValidator(),
name=StringValidator(),
...
)))
3.3.3.6. Good Tests
Bad tests are worse than no tests at all. Since they waste developers’ time wondering “was that a spurious failure?” or “what the heck is this test trying to do?”, Buildbot needs good tests. So what makes a test good?
Independent of Time
Tests that depend on wall time will fail. As a bonus, they run very slowly. Do
not use reactor.callLater to wait “long enough” for something to happen.
For testing things that themselves depend on time, consider using
twisted.internet.tasks.Clock. This may mean passing a clock instance to
the code under test, and propagating that instance as necessary to ensure that
all of the code using callLater uses it. Refactoring code for
testability is difficult, but worthwhile.
For testing things that do not depend on time, but for which you cannot detect the “end” of an operation: add a way to detect the end of the operation!
Clean Code
Make your tests readable. This is no place to skimp on comments! Others will
attempt to learn about the expected behavior of your class by reading the
tests. As a side note, if you use a Deferred chain in your test, write
the callbacks as nested functions, rather than using methods with funny names:
def testSomething(self):
d = doThisFirst()
def andThisNext(res):
pass # ...
d.addCallback(andThisNext)
return d
This isolates the entire test into one indented block. It is OK to add methods for common functionality, but give them real names and explain in detail what they do.
Good Name
Test method names should follow the pattern test_METHOD_CONDITION
where METHOD is the method being tested, and CONDITION is the
condition under which it’s tested. Since we can’t always test a single
method, this is not a hard-and-fast rule.
Assert Only One Thing
Where practical, each test should have a single assertion. This may require a little bit of work to get several related pieces of information into a single Python object for comparison. The problem with multiple assertions is that, if the first assertion fails, the remainder are not tested. The test results then do not tell the entire story.
Prefer Fakes to Mocks
Mock objects are too “compliant”, and this often masks errors in the system under test. For example, a mis-spelled method name on a mock object will not raise an exception.
Where possible, use one of the pre-written fake objects (see Fakes) instead of a mock object. Fakes themselves should be well-tested using interface tests.
Where they are appropriate, Mock objects can be constructed easily using the aptly-named mock module, which is a requirement for Buildbot’s tests.
Small Tests
The shorter a test is, the better. Test as little code as possible in each test.
It is fine, and in fact encouraged, to write the code under test in such a way as to facilitate this. As an illustrative example, if you are testing a new Step subclass, but your tests require instantiating a BuildMaster, you’re probably doing something wrong!
This also applies to test modules. Several short, easily-digested test modules are preferred over a 1000-line monster.
Isolation
Each test should be maximally independent of other tests. Do not leave files laying around after your test has finished, and do not assume that some other test has run beforehand. It’s fine to use caching techniques to avoid repeated, lengthy setup times.
Be Correct
Tests should be as robust as possible, which at a basic level means using the available frameworks correctly. All Deferreds should have callbacks and be chained properly. Error conditions should be checked properly. Race conditions should not exist (see Independent of Time, above).
Be Helpful
Note that tests will pass most of the time, but the moment when they are most useful is when they fail.
When the test fails, it should produce output that is helpful to the person chasing it down. This is particularly important when the tests are run remotely, in which case the person chasing down the bug does not have access to the system on which the test fails. A test which fails sporadically with no more information than “AssertionFailed” is a prime candidate for deletion if the error isn’t obvious. Making the error obvious also includes adding comments describing the ways a test might fail.
Keeping State
Python does not allow assignment to anything but the innermost local scope or
the global scope with the global keyword. This presents a problem when
creating nested functions:
def test_localVariable(self):
cb_called = False
def cb():
cb_called = True
cb()
self.assertTrue(cb_called) # will fail!
The cb_called = True assigns to a different variable than
cb_called = False. In production code, it’s usually best to work around
such problems, but in tests this is often the clearest way to express the
behavior under test.
The solution is to change something in a common mutable object. While a simple
list can serve as such a mutable object, this leads to code that is hard to
read. Instead, use State:
from buildbot.test.state import State
def test_localVariable(self):
state = State(cb_called=False)
def cb():
state.cb_called = True
cb()
self.assertTrue(state.cb_called) # passes
This is almost as readable as the first example, but it actually works.
3.3.4. Configuration
Wherever possible, Buildbot components should access configuration information
as needed from the canonical source, master.config, which is an instance of
MasterConfig. For example, components should not keep a copy of
the buildbotURL locally, as this value may change throughout the lifetime
of the master.
Components which need to be notified of changes in the configuration should be
implemented as services, subclassing ReconfigurableServiceMixin, as
described in Reconfiguration.
- class buildbot.config.MasterConfig
The master object makes much of the configuration available from an object named
master.config. Configuration is stored as attributes of this object. Where possible, other Buildbot components should access this configuration directly and not cache the configuration values anywhere else. This avoids the need to ensure that update-from-configuration methods are called on a reconfig.Aside from validating the configuration, this class handles any backward-compatibility issues - renamed parameters, type changes, and so on - removing those concerns from other parts of Buildbot.
This class may be instantiated directly, creating an entirely default configuration, or via
FileLoader.loadConfig, which will load the configuration from a config file.The following attributes are available from this class, representing the current configuration. This includes a number of global parameters:
- buildbotURL
The URL of this buildmaster, for use in constructing WebStatus URLs; from
buildbotURL.
- logCompressionLimit
The current log compression limit, from
logCompressionLimit.
- logCompressionMethod
The current log compression method, from
logCompressionMethod.
- logMaxSize
The current log maximum size, from
logMaxSize.
- logMaxTailSize
The current log tail maximum size, from
logMaxTailSize.
- logEncoding
The encoding to expect when logs are provided as bytestrings, from
logEncoding.
- properties
A
Propertiesinstance containing global properties, fromproperties.
- collapseRequests
A callable, or True or False, describing how to collapse requests; from
collapseRequests.
- prioritizeBuilders
A callable, or None, used to prioritize builders; from
prioritizeBuilders.
- codebaseGenerator
A callable, or None, used to determine the codebase from an incoming
Change, fromcodebaseGenerator.
- multiMaster
If true, then this master is part of a cluster; based on
multiMaster.
The remaining attributes contain compound configuration structures, usually as dictionaries:
- validation
Validation regular expressions, a dictionary from
validation. It is safe to assume that all expected keys are present.
- db
Database specification, a dictionary with key
db_url. It is safe to assume that this key is present.
- caches
The cache configuration, from
cachesas well as the deprecatedbuildCacheSizeandchangeCacheSizeparameters.The keys
BuildsandCachesare always available; other keys should useconfig.caches.get(cachename, 1).
- schedulers
The dictionary of scheduler instances, by name, from
schedulers.
- builders
The list of
BuilderConfiginstances frombuilders. Builders specified as dictionaries in the configuration file are converted to instances.
- change_sources
The list of
IChangeSourceproviders fromchange_source.
- user_managers
The list of user managers providers from
user_managers.
- services
The list of additional plugin services.
- classmethod loadFromDict(config_dict, filename)
- Parameters:
config_dict (dict) – The dictionary containing the configuration to load
filename (string) – The filename to use when reporting errors
- Returns:
new
MasterConfiginstance
Load the configuration from the given dictionary.
Loading of the configuration file is generally triggered by the master, using the following class:
- class buildbot.config.FileLoader
- __init__(basedir, filename)
- Parameters:
basedir (string) – directory to which config is relative
filename (string) – the configuration file to load
The filename is treated as relative to basedir if it is not absolute.
- loadConfig(basedir, filename)
- Returns:
new
MasterConfiginstance
Load the configuration in the given file. Aside from syntax errors, this will also detect a number of semantic errors such as multiple schedulers with the same name.
- buildbot.config.loadConfigDict(basedir, filename)
- Parameters:
basedir (string) – directory to which config is relative
filename (string) – the configuration file to load
- Raises:
ConfigErrorsif any errors occur- Returns dict:
The
BuildmasterConfigdictionary.
Load the configuration dictionary in the given file.
The filename is treated as relative to basedir if it is not absolute.
3.3.4.1. Builder Configuration
- class buildbot.config.BuilderConfig([keyword args])
This class parameterizes configuration of builders; see Builder Configuration for its arguments. The constructor checks for errors, applies defaults, and sets the properties described here. Most are simply copied from the constructor argument of the same name.
Users may subclass this class to add defaults, for example.
- name
The builder’s name.
- factory
The builder’s factory.
- workernames
The builder’s worker names (a list, regardless of whether the names were specified with
workernameorworkernames).
- builddir
The builder’s builddir.
- workerbuilddir
The builder’s worker-side builddir.
- category
The builder’s category.
- nextWorker
The builder’s nextWorker callable.
- nextBuild
The builder’s nextBuild callable.
- canStartBuild
The builder’s canStartBuild callable.
- locks
The builder’s locks.
- env
The builder’s environment variables.
- properties
The builder’s properties, as a dictionary.
- collapseRequests
The builder’s collapseRequests callable.
- description
The builder’s description, displayed in the web status.
3.3.4.2. Error Handling
If any errors are encountered while loading the configuration, buildbot.config.error
should be called. This can occur both in the configuration-loading code, and in the constructors
of any objects that are instantiated in the configuration - change sources, workers, schedulers,
build steps, and so on.
- buildbot.config.error(error)
- Parameters:
error – error to report
- Raises:
ConfigErrorsif called at build-time
This function reports a configuration error. If a config file is being loaded, then the function merely records the error, and allows the rest of the configuration to be loaded. At any other time, it raises
ConfigErrors. This is done so that all config errors can be reported, rather than just the first one.
- exception buildbot.config.ConfigErrors([errors])
- Parameters:
errors (list) – errors to report
This exception represents errors in the configuration. It supports reporting multiple errors to the user simultaneously, e.g., when several consistency checks fail.
- errors
A list of detected errors, each given as a string.
- addError(msg)
- Parameters:
msg (string) – the message to add
Add another error message to the (presumably not-yet-raised) exception.
3.3.5. Configuration in AngularJS
The AngularJS frontend often needs access to the local master configuration. This is accomplished automatically by converting various pieces of the master configuration to a dictionary.
The IConfigured interface represents a way to convert any object
into a JSON-able dictionary.
- class buildbot.interfaces.IConfigured
Providers of this interface provide a method to get their configuration as a dictionary:
- getConfigDict()
- Returns:
object
Return the configuration of this object. Note that despite the name, the return value may not be a dictionary.
Any object can be “cast” to an
IConfiguredprovider. ThegetConfigDictmethod for basic Python objects simply returns the value.IConfigured(someObject).getConfigDict()
- class buildbot.util.ConfiguredMixin
This class is a basic implementation of
IConfigured. ItsgetConfigDictmethod simply returns the instance’snameattribute (all objects configured must have thenameattribute).- getConfigDict()
- Returns:
object
Return a config dictionary representing this object.
All of this is used by to serve /config.js to the JavaScript frontend.
3.3.5.1. Reconfiguration
When the buildmaster receives a signal to begin a reconfig, it re-reads the
configuration file, generating a new MasterConfig instance, and
then notifies all of its child services via the reconfig mechanism described
below. The master ensures that at most one reconfiguration is taking place at
any time.
See Master Organization for the structure of the Buildbot service tree.
To simplify initialization, a reconfiguration is performed immediately on
master startup. As a result, services only need to implement their
configuration handling once, and can use startService for initialization.
See below for instructions on implementing configuration of common types of components in Buildbot.
Note
Because Buildbot uses a pure-Python configuration file, it is not possible to support all forms of reconfiguration. In particular, when the configuration includes custom subclasses or modules, reconfiguration can turn up some surprising behaviors due to the dynamic nature of Python. The reconfig support in Buildbot is intended for “intermediate” uses of the software, where there are fewer surprises.
Reconfigurable Services
Instances which need to be notified of a change in configuration should be
implemented as Twisted services and mix in the
ReconfigurableServiceMixin class, overriding the
reconfigServiceWithBuildbotConfig method.
The services implementing ReconfigurableServiceMixin operate on whole master configuration.
In some cases they are effectively singletons that handle configuration identified by a specific
configuration key. Such singletons often manage non-singleton services as children and pass bits of
its own configuration when reconfiguring these children. BuildbotServiceManager is one internal
implementation of ReconfigurableServiceMixin which accepts a list of child service
configurations as its configuration and then intelligently reconfigures child services on changes.
Non-singleton ReconfigurableServiceMixin services are harder to write as they must manually
pick its configuration from whole master configuration. The parent service also needs explicit
support for this kind of setup to work correctly.
- class buildbot.config.ReconfigurableServiceMixin
- reconfigServiceWithBuildbotConfig(new_config)
- Parameters:
new_config (
MasterConfig) – new master configuration- Returns:
Deferred
This method notifies the service that it should make any changes necessary to adapt to the new configuration values given.
This method will be called automatically after a service is started.
It is generally too late at this point to roll back the reconfiguration, so if possible, any errors should be detected in the
MasterConfigimplementation. Errors are handled as best as possible and communicated back to the top level invocation, but such errors may leave the master in an inconsistent state.ConfigErrorsexceptions will be displayed appropriately to the user on startup.Subclasses should always call the parent class’s implementation. For
MultiServiceinstances, this will call any child services’reconfigServicemethods, as appropriate. This will be done sequentially, such that the Deferred from one service must fire before the next service is reconfigured.
- priority
Child services are reconfigured in order of decreasing priority. The default priority is 128, so a service that must be reconfigured before others should be given a higher priority.
Change Sources
When reconfiguring, there is no method by which Buildbot can determine that a
new ChangeSource represents the same source
as an existing ChangeSource, but with
different configuration parameters. As a result, the change source manager
compares the lists of existing and new change sources using equality, stops any
existing sources that are not in the new list, and starts any new change
sources that do not already exist.
ChangeSource inherits
ComparableMixin, so change sources are compared
based on the attributes described in their compare_attrs.
If a change source does not make reference to any global configuration
parameters, then there is no need to inherit
ReconfigurableServiceMixin, as a simple comparison and
startService and stopService will be sufficient.
If the change source does make reference to global values, e.g., as default
values for its parameters, then it must inherit
ReconfigurableServiceMixin to support the case where the global
values change.
Schedulers
Schedulers have names, so Buildbot can determine whether a scheduler has been added, removed, or
changed during a reconfig. Old schedulers will be stopped, new schedulers will be started, and both
new and existing schedulers will see a call to reconfigService,
if such a method exists. For backward compatibility, schedulers that do not support reconfiguration
will be stopped, and a new scheduler will be started when their configuration changes.
During a reconfiguration, if a new and old scheduler’s fully qualified class names differ, then the
old class will be stopped, and the new class will be started. This supports the case when a user
changes, for example, a Nightly scheduler to a Periodic scheduler without
changing the name.
Because Buildbot uses ReconfigurableBaseScheduler instances
directly in the configuration file, a reconfigured scheduler must extract its new configuration
information from another instance of itself.
Custom Subclasses
Custom subclasses are most often defined directly in the configuration file, or
in a Python module that is reloaded with reload every time the
configuration is loaded. Because of the dynamic nature of Python, this creates
a new object representing the subclass every time the configuration is loaded
– even if the class definition has not changed.
Note that if a scheduler’s class changes in a reconfig, but the scheduler’s name does not, it will still be treated as a reconfiguration of the existing scheduler. This means that implementation changes in custom scheduler subclasses will not be activated with a reconfig. This behavior avoids stopping and starting such schedulers on every reconfig, but can make development difficult.
One workaround for this is to change the name of the scheduler before each reconfig - this will cause the old scheduler to be stopped, and the new scheduler (with the new name and class) to be started.
Workers
Similar to schedulers, workers are specified by name, so new and old configurations are first
compared by name, and any workers to be added or removed are noted.
Workers for which the fully-qualified class name has changed are also added and removed.
All workers have their reconfigService method called.
This method takes care of the basic worker attributes, including changing the PB registration if
necessary. Any subclasses that add configuration parameters should override
reconfigService and update those parameters.
As with schedulers, because the AbstractWorker instance is given
directly in the configuration, a reconfigured worker instance must extract its new configuration
from another instance of itself.
User Managers
Since user managers are rarely used, and their purpose is unclear, they are always stopped and re-started on every reconfig. This may change in future versions.
Status Receivers
At every reconfig, all status listeners are stopped, and new versions are started.
3.3.6. Writing Schedulers
Buildbot schedulers are the process objects responsible for requesting builds.
Schedulers are free to decide when to request builds, and to define the parameters of the builds.
Many schedulers (e.g., SingleBranchScheduler) request builds in response to changes from change sources.
Others, such as Nightly, request builds at specific times.
Still others, like ForceScheduler, Try_Jobdir, or Triggerable, respond to external inputs.
Each scheduler has a unique name, and within a Buildbot cluster, can be active on at most one master. If a scheduler is configured on multiple masters, it will be inactive on all but one master. This provides a form of non-revertive failover for schedulers: if an active scheduler’s master fails, an inactive instance of that scheduler on another master will become active.
3.3.6.1. Implementing A Scheduler
A scheduler is a subclass of ReconfigurableBaseScheduler.
It is also a BuildbotService and has the lifecycle described in its documentation.
The first two arguments, name and builderNames, are positional.
The remaining arguments are keyword arguments, and the subclass’s checkConfig and
reconfigService should accept **kwargs to pass them to the parent class, along with the
positional arguments. Note that the name argument is handled internally and not passed
to checkConfig and reconfigService:
class MyScheduler(base.ReconfigurableBaseScheduler):
def checkService(self, builderNames, arg1=None, arg2=None, **kwargs):
super().checkService(name, **kwargs)
@defer.inlineCallbacks
def reconfigService(self, builderNames, arg1=None, arg2=None, **kwargs):
yield super().reconfigService(name, **kwargs)
self.arg1 = arg1
self.arg2 = arg2
Schedulers are Twisted services, so they can implement startService and stopService.
However, it is more common for scheduler subclasses to override startActivity and stopActivity instead.
See below.
3.3.6.2. Consuming Changes
A scheduler that needs to be notified of new changes should call startConsumingChanges when it becomes active.
Change consumption will automatically stop when the scheduler becomes inactive.
Once consumption has started, the gotChange method is invoked for each new change.
The scheduler is free to do whatever it likes in this method.
3.3.6.3. Adding Buildsets
To add a new buildset, subclasses should call one of the parent-class methods with the prefix addBuildsetFor.
These methods call addBuildset after applying behaviors common to all schedulers.
Any of these methods can be called at any time.
3.3.6.4. Handling Reconfiguration
When the configuration for a scheduler changes, Buildbot deactivates, stops and removes the old scheduler, then adds, starts, and maybe activates the new scheduler.
Buildbot determines whether a scheduler has changed by subclassing ComparableMixin.
See the documentation for class for an explanation of the compare_attrs attribute.
3.3.6.5. Becoming Active and Inactive
An inactive scheduler should not do anything that might interfere with an active scheduler of the same name.
Simple schedulers can consult the active attribute to determine whether the scheduler is active.
Most schedulers, however, will implement the activate method to begin any processing expected of an active scheduler.
That may involve calling startConsumingChanges,
beginning a LoopingCall, or subscribing to messages.
Any processing begun by the activate method, or by an active scheduler, should be stopped by the deactivate method.
The deactivate method’s Deferred should not fire until such processing has completely stopped.
Schedulers must up-call the parent class’s activate and deactivate methods!
3.3.6.6. Keeping State
The BaseScheduler class provides
getState and
setState methods to get and set
state values for the scheduler.
Active scheduler instances should use these functions to store persistent scheduler state, such that if they fail or become inactive, other instances can pick up where they left off.
A scheduler can cache its state locally, only calling getState when it first becomes active.
However, it is best to keep the state as up-to-date as possible, by calling setState any time the state changes.
This prevents loss of state from an unexpected master failure.
Note that the state-related methods do not use locks of any sort. It is up to the caller to ensure that no race conditions exist between getting and setting state. Generally, it is sufficient to rely on there being only one running instance of a scheduler, and cache state in memory.
3.3.7. Utilities
Several small utilities are available at the top-level buildbot.util package.
- buildbot.util.naturalSort(list)
- Parameters:
list – list of strings
- Returns:
sorted strings
This function sorts strings “naturally”, with embedded numbers sorted numerically. This ordering is good for objects which might have a numeric suffix, e.g.,
winworker1,winworker2
- buildbot.util.formatInterval(interval)
- Parameters:
interval – duration in seconds
- Returns:
human-readable (English) equivalent
This function will return a human-readable string describing a length of time, given a number of seconds.
- class buildbot.util.ComparableMixin
This mixin class adds comparability to a subclass. Use it like this:
class Widget(FactoryProduct, ComparableMixin): compare_attrs = ( 'radius', 'thickness' ) # ...
Any attributes not in
compare_attrswill not be considered when comparing objects. This is used to implement Buildbot’s reconfig logic, where a comparison between the new and existing objects is used to determine whether the new object should replace the existing object. If the comparison shows the objects to be equivalent, then the old object is left in place. If they differ, the old object is removed from the buildmaster, and the new object is added.For use in configuration objects (schedulers, changesources, etc.), include any attributes which are set in the constructor based on the user’s configuration. Be sure to also include the superclass’s list, e.g.:
class MyScheduler(base.BaseScheduler): compare_attrs = base.BaseScheduler.compare_attrs + ('arg1', 'arg2')
A point to note is that the compare_attrs list is cumulative; that is, when a subclass also has a compare_attrs and the parent class has a compare_attrs, the subclass’ compare_attrs also includes the parent class’ compare_attrs.
This class also implements the
buildbot.interfaces.IConfiguredinterface. The configuration is automatically generated, being the dict of allcompare_attrs.
- buildbot.util.safeTranslate(str)
- Parameters:
str – input string
- Returns:
safe version of the input
This function will filter out some inappropriate characters for filenames; it is suitable for adapting strings from the configuration for use as filenames. It is not suitable for use with strings from untrusted sources.
- buildbot.util.epoch2datetime(epoch)
- Parameters:
epoch – an epoch time (integer)
- Returns:
equivalent datetime object
Convert a UNIX epoch timestamp to a Python datetime object, in the UTC timezone. Note that timestamps specify UTC time (modulo leap seconds and a few other minor details). If the argument is None, returns None.
- buildbot.util.datetime2epoch(datetime)
- Parameters:
datetime – a datetime object
- Returns:
equivalent epoch time (integer)
Convert an arbitrary Python datetime object into a UNIX epoch timestamp. If the argument is None, returns None.
- buildbot.util.UTC
A
datetime.tzinfosubclass representing UTC time. A similar class has finally been added to Python in version 3.2, but the implementation is simple enough to include here. This is mostly used in tests to create timezone-aware datetime objects in UTC:dt = datetime.datetime(1978, 6, 15, 12, 31, 15, tzinfo=UTC)
- buildbot.util.diffSets(old, new)
- Parameters:
old (set or iterable) – old set
new (set or iterable) – new set
- Returns:
a (removed, added) tuple
This function compares two sets of objects, returning elements that were added and elements that were removed. This is largely a convenience function for reconfiguring services.
- buildbot.util.makeList(input)
- Parameters:
input – a thing
- Returns:
a list of zero or more things
This function is intended to support the many places in Buildbot where the user can specify either a string or a list of strings, but the implementation wishes to always consider lists. It converts any string to a single-element list,
Noneto an empty list, and any iterable to a list. Input lists are copied, avoiding aliasing issues.
- buildbot.util.now()
- Returns:
epoch time (integer)
Return the current time, using either
reactor.secondsortime.time().
- buildbot.util.flatten(list[, types])
- Parameters:
list – potentially nested list
types – An optional iterable of the types to flatten. By default, if unspecified, this flattens both lists and tuples
- Returns:
flat list
Flatten nested lists into a list containing no other lists. For example:
>>> flatten([ [ 1, 2 ], 3, [ [ 4 ], 5 ] ]) [ 1, 2, 3, 4, 5 ]
Both lists and tuples are looked at by default.
- buildbot.util.flattened_iterator(list[, types])
- Parameters:
list – potentially nested list
types – An optional iterable of the types to flatten. By default, if unspecified, this flattens both lists and tuples.
- Returns:
iterator over every element whose type isn’t in types
Returns a generator that doesn’t yield any lists/tuples. For example:
>>> for x in flattened_iterator([ [ 1, 2 ], 3, [ [ 4 ] ] ]): >>> print x 1 2 3 4 Use this for extremely large lists to keep memory-usage down and improve performance when you only need to iterate once.
- buildbot.util.none_or_str(obj)
- Parameters:
obj – input value
- Returns:
string or
None
If
objis not None, return its string representation.
- buildbot.util.bytes2unicode(bytestr, encoding='utf-8', errors='strict')
- Parameters:
bytestr – bytes
encoding – unicode encoding to pass to
str.encode, defaultutf-8.errors – error handler to pass to
str.encode, defaultstrict.
- Returns:
string as unicode
This function is intended to convert bytes to unicode for user convenience. If given a bytestring, it returns the string decoded using
encoding. If given a unicode string, it returns it directly.
- buildbot.util.string2boolean(str)
- Parameters:
str – string
- Raises:
KeyError –
- Returns:
boolean
This function converts a string to a boolean. It is intended to be liberal in what it accepts: case-insensitive “true”, “on”, “yes”, “1”, etc. It raises
KeyErrorif the value is not recognized.
- buildbot.util.toJson(obj)
- Parameters:
obj – object
- Returns:
UNIX epoch timestamp
This function is a helper for json.dump, that allows to convert non-json able objects to json. For now it supports converting datetime.datetime objects to unix timestamp.
- buildbot.util.NotABranch
This is a sentinel value used to indicate that no branch is specified. It is necessary since schedulers and change sources consider
Nonea valid name for a branch. This is generally used as a default value in a method signature, and then tested against withis:if branch is NotABranch: pass # ...
- buildbot.util.in_reactor(fn)
This decorator will cause the wrapped function to be run in the Twisted reactor, with the reactor stopped when the function completes. It returns the result of the wrapped function. If the wrapped function fails, its traceback will be printed, the reactor halted, and
Nonereturned.
- buildbot.util.asyncSleep(secs, reactor=None)
Yield a deferred that will fire with no result after
secsseconds. This is the asynchronous equivalent totime.sleep, and can be useful in tests. In case a custom reactor is used, thereactorparameter may be set. By default,twisted.internet.reactoris used.
- buildbot.util.stripUrlPassword(url)
- Parameters:
url – a URL
- Returns:
URL with any password component replaced with
xxxx
Sanitize a URL; use this before logging or displaying a DB URL.
- buildbot.util.join_list(maybe_list)
- Parameters:
maybe_list – list, tuple, byte string, or unicode
- Returns:
unicode string
If
maybe_listis a list or tuple, join it with spaces, casting any strings into unicode usingbytes2unicode. This is useful for configuration parameters that may be strings or lists of strings.
- class buildbot.util.Notifier
This is a helper for firing multiple deferreds with the same result.
- wait()
Return a deferred that will fire when when the notifier is notified.
- notify(value)
Fire all the outstanding deferreds with the given value.
- buildbot.util.giturlparse(url)
- Parameters:
url – a git url
- Returns:
a
GitUrlwith results of parsed url
This function is intended to help various components to parse git urls. It helps to find the
<owner>/<repo>of a git repository url coming from a change, in order to call urls.ownerandrepois a common scheme for identifying a git repository between various git hosting services, like GitHub, GitLab, BitBucket, etc. Each service has their own naming for similar things, but we choose to use the GitHub naming as a de-facto standard. To simplify implementation, the parser is accepting invalid urls, but it should always parse valid urls correctly. The unit tests intest_util_giturlparse.pyare the references on what the parser accepts. Please feel free to update the parser and the unit tests.Example use:
from buildbot.util import giturlparse repourl = giturlparse(sourcestamp['repository']) repoOwner = repourl.owner repoName = repourl.repo
- class buildbot.util.GitUrl
- proto
The protocol of the url
- user
The user of the url (as in
user@domain)
- domain
The domain part of the url
- port
The optional port of the url
- owner
The owner of the repository (in case of GitLab might be a nested group, i.e contain
/, e.grepo/subrepo/subsubrepo)
- repo
The name of the repository (in case of GitLab might be a nested group, i.e contain
/)
3.3.7.1. buildbot.util.lru
- class buildbot.util.lru.LRUCache(miss_fn, max_size=50)
- Parameters:
miss_fn – function to call, with key as parameter, for cache misses. The function should return the value associated with the key argument, or None if there is no value associated with the key.
max_size – maximum number of objects in the cache.
This is a simple least-recently-used cache. When the cache grows beyond the maximum size, the least-recently used items will be automatically removed from the cache.
This cache is designed to control memory usage by minimizing duplication of objects, while avoiding unnecessary re-fetching of the same rows from the database.
All values are also stored in a weak valued dictionary, even after they have expired from the cache. This allows values that are used elsewhere in Buildbot to “stick” in the cache in case they are needed by another component. Weak references cannot be used for some types, so these types are not compatible with this class. Note that dictionaries can be weakly referenced if they are an instance of a subclass of
dict.If the result of the
miss_fnisNone, then the value is not cached; this is intended to avoid caching negative results.This is based on Raymond Hettinger’s implementation, licensed under the PSF license, which is GPL-compatible.
- hits
cache hits so far
- refhits
cache misses found in the weak ref dictionary, so far
- misses
cache misses leading to re-fetches, so far
- max_size
maximum allowed size of the cache
- get(key, **miss_fn_kwargs)
- Parameters:
key – cache key
miss_fn_kwargs – keyword arguments to the
miss_fn
- Returns:
value via Deferred
Fetch a value from the cache by key, invoking
miss_fn(key, **miss_fn_kwargs)if the key is not in the cache.Any additional keyword arguments are passed to the
miss_fnas keyword arguments; these can supply additional information relating to the key. It is up to the caller to ensure that this information is functionally identical for each key value: if the key is already in the cache, themiss_fnwill not be invoked, even if the keyword arguments differ.
- put(key, value)
- Parameters:
key – key at which to place the value
value – value to place there
Add the given key and value into the cache. The purpose of this method is to insert a new value into the cache without invoking the miss_fn (e.g., to avoid unnecessary overhead).
- inv()
Check invariants on the cache. This is intended for debugging purposes.
- class buildbot.util.lru.AsyncLRUCache(miss_fn, max_size=50)
- Parameters:
miss_fn – This is the same as the miss_fn for class LRUCache, with the difference that this function must return a Deferred.
max_size – maximum number of objects in the cache.
This class has the same functional interface as LRUCache, but asynchronous locking is used to ensure that in the common case of multiple concurrent requests for the same key, only one fetch is performed.
3.3.7.2. buildbot.util.bbcollections
This package provides a few useful collection objects.
Note
This module used to be named collections, but without absolute imports (PEP 328), this
precluded using the standard library’s collections module.
- class buildbot.util.bbcollections.defaultdict
This is a clone of the Python
collections.defaultdictfor use in Python-2.4. In later versions, this is simply a reference to the built-indefaultdict, so Buildbot code can simply usebuildbot.util.collections.defaultdicteverywhere.
- class buildbot.util.bbcollections.KeyedSets
This is a collection of named sets. In principle, it contains an empty set for every name, and you can add things to sets, discard things from sets, and so on.
>>> ks = KeyedSets() >>> ks['tim'] # get a named set set([]) >>> ks.add('tim', 'friendly') # add an element to a set >>> ks.add('tim', 'dexterous') >>> ks['tim'] set(['friendly', 'dexterous']) >>> 'tim' in ks # membership testing True >>> 'ron' in ks False >>> ks.discard('tim', 'friendly')# discard set element >>> ks.pop('tim') # return set and reset to empty set(['dexterous']) >>> ks['tim'] set([])
This class is careful to conserve memory space - empty sets do not occupy any space.
3.3.7.3. buildbot.util.eventual
This function provides a simple way to say “please do this later”. For example
from buildbot.util.eventual import eventually
def do_what_I_say(what, where):
# ...
return d
eventually(do_what_I_say, "clean up", "your bedroom")
The package defines “later” as “next time the reactor has control”, so this is a good way to avoid long loops that block another activity in the reactor.
- buildbot.util.eventual.eventually(cb, *args, **kwargs)
- Parameters:
cb – callable to invoke later
args – args to pass to
cbkwargs – kwargs to pass to
cb
Invoke the callable
cbin a later reactor turn.Callables given to
eventuallyare guaranteed to be called in the same order as the calls toeventually– writingeventually(a); eventually(b)guarantees thatawill be called beforeb.Any exceptions that occur in the callable will be logged with
log.err(). If you really want to ignore them, provide a callable that catches those exceptions.This function returns None. If you care to know when the callable was run, be sure to provide a callable that notifies somebody.
- buildbot.util.eventual.fireEventually(value=None)
- Parameters:
value – value with which the Deferred should fire
- Returns:
Deferred
This function returns a Deferred which will fire in a later reactor turn, after the current call stack has been completed, and after all other Deferreds previously scheduled with
eventually. The returned Deferred will never fail.
- buildbot.util.eventual.flushEventualQueue()
- Returns:
Deferred
This returns a Deferred which fires when the eventual-send queue is finally empty. This is useful for tests and other circumstances where it is useful to know that “later” has arrived.
3.3.7.4. buildbot.util.debounce
It’s often necessary to perform some action in response to a particular type of event. For example, steps need to update their status after updates arrive from the worker. However, when many events arrive in quick succession, it’s more efficient to only perform the action once, after the last event has occurred.
The debounce.method(wait, until_idle=False) decorator is the tool for the job.
- buildbot.util.debounce.method(wait, until_idle=False, get_reactor)
- Parameters:
wait – time to wait before invoking, in seconds
until_idle – resets the timer on every call
get_reactor – A callable that takes the underlying instance and returns the reactor to use. Defaults to
instance.master.reactor.
Returns a decorator that debounces the underlying method. The underlying method must take no arguments (except
self).Calls are “debounced”, meaning that multiple calls to the decorated method will result in a single invocation.
When until_idle is True, the underlying method will be called after wait seconds have elapsed since the last time the decorated method have been called. In case of constant stream, it will never be called.
When until_idle is False, the underlying method will be called after wait seconds have elapsed since the first time the decorated method have been called. In case of constant stream, it will called about once every wait seconds (plus the time the method takes to execute)
The decorated method is an instance of
Debouncer, allowing it to be started and stopped. This is useful when the method is a part of a Buildbot service: callmethod.start()fromstartServiceandmethod.stop()fromstopService, handling its Deferred appropriately.
- class buildbot.util.debounce.Debouncer
- stop()
- Returns:
Deferred
Stop the debouncer. While the debouncer is stopped, calls to the decorated method will be ignored. If a call is pending when
stopis called, that call will occur immediately. When the Deferred thatstopreturns fires, the underlying method is not executing.
- start()
Start the debouncer. This reverses the effects of
stop. This method can be called on a started debouncer without issues.
3.3.7.5. buildbot.util.poll
Many Buildbot services perform some periodic, asynchronous operation. Change sources, for example, contact the repositories they monitor on a regular basis. The tricky bit is, the periodic operation must complete before the service stops.
The @poll.method decorator makes this behavior easy and reliable.
- buildbot.util.poll.method()
This decorator replaces the decorated method with a
Pollerinstance configured to call the decorated method periodically. The poller is initially stopped, so periodic calls will not begin until itsstartmethod is called. The start polling interval is specified when the poller is started. A random delay may optionally be supplied. This allows to avoid the situation of multiple services with the same interval are executing at exactly the same time.If the decorated method fails or raises an exception, the Poller logs the error and re-schedules the call for the next interval.
If a previous invocation of the method has not completed when the interval expires, then the next invocation is skipped and the interval timer starts again.
A common idiom is to call
startandstopfromstartServiceandstopService:class WatchThings(object): @poll.method def watch(self): d = self.beginCheckingSomething() return d def startService(self): self.watch.start(interval=self.pollingInterval, now=False) def stopService(self): return self.watch.stop()
- class buildbot.util.poll.Poller
- start(interval=N, now=False, random_delay_min=0, random_delay_max=0)
- Parameters:
interval – time, in seconds, between invocations
now – if true, call the decorated method immediately on startup.
random_delay_min – Minimum random delay to apply to the start time of the decorated method.
random_delay_min – Maximum random delay to apply to the start time of the decorated method.
Start the poller.
- stop()
- Returns:
Deferred
Stop the poller. The returned Deferred fires when the decorated method is complete.
- __call__()
Force a call to the decorated method now. If the decorated method is currently running, another call will begin as soon as it completes unless the poller is currently stopping.
3.3.7.6. buildbot.util.maildir
Several Buildbot components make use of maildirs to hand off messages between components. On the receiving end, there’s a need to watch a maildir for incoming messages and trigger some action when one arrives.
- class buildbot.util.maildir.MaildirService(basedir)
- param basedir:
(optional) base directory of the maildir
A
MaildirServiceinstance watches a maildir for new messages. It should be a child service of someMultiServiceinstance. When running, this class uses the linux dirwatcher API (if available) or polls for new files in the ‘new’ maildir subdirectory. When it discovers a new message, it invokes itsmessageReceivedmethod.To use this class, subclass it and implement a more interesting
messageReceivedfunction.- setBasedir(basedir)
- Parameters:
basedir – base directory of the maildir
If no
basediris provided to the constructor, this method must be used to set the basedir before the service starts.
- messageReceived(filename)
- Parameters:
filename – unqualified filename of the new message
This method is called with the short filename of the new message. The full name of the new file can be obtained with
os.path.join(maildir, 'new', filename). The method is un-implemented in theMaildirServiceclass, and must be implemented in subclasses.
- moveToCurDir(filename)
- Parameters:
filename – unqualified filename of the new message
- Returns:
open file object
Call this from
messageReceivedto start processing the message; this moves the message file to the ‘cur’ directory and returns an open file handle for it.
3.3.7.7. buildbot.util.misc
- buildbot.util.misc.deferredLocked(lock)
- Parameters:
lock – a
twisted.internet.defer.DeferredLockinstance or a string naming an instance attribute containing one
This is a decorator to wrap an event-driven method (one returning a
Deferred) in an acquire/release pair of a designatedDeferredLock. For simple functions with a static lock, this is as easy as:someLock = defer.DeferredLock() @util.deferredLocked(someLock) def someLockedFunction(): # .. return d
For class methods which must access a lock that is an instance attribute, the lock can be specified by a string, which will be dynamically resolved to the specific instance at runtime:
def __init__(self): self.someLock = defer.DeferredLock() @util.deferredLocked('someLock') def someLockedFunction(): # .. return d
- buildbot.util.misc.cancelAfter(seconds, deferred)
- Parameters:
seconds – timeout in seconds
deferred – deferred to cancel after timeout expires
- Returns:
the deferred passed to the function
Cancel the given deferred after the given time has elapsed, if it has not already been fired. When this occurs, the deferred’s errback will be fired with a
twisted.internet.defer.CancelledErrorfailure.
3.3.7.8. buildbot.util.netstrings
Similar to maildirs, netstrings are used occasionally in Buildbot to encode data for interchange. While Twisted supports a basic netstring receiver protocol, it does not have a simple way to apply that to a non-network situation.
- class buildbot.util.netstrings.NetstringParser
This class parses strings piece by piece, either collecting the accumulated strings or invoking a callback for each one.
- feed(data)
- Parameters:
data – a portion of netstring-formatted data
- Raises:
twisted.protocols.basic.NetstringParseError
Add arbitrarily-sized
datato the incoming-data buffer. Any complete netstrings will trigger a call to thestringReceivedmethod.Note that this method (like the Twisted class it is based on) cannot detect a trailing partial netstring at EOF - the data will be silently ignored.
- stringReceived(string):
- Parameters:
string – the decoded string
This method is called for each decoded string as soon as it is read completely. The default implementation appends the string to the
stringsattribute, but subclasses can do anything.
- strings
The strings decoded so far, if
stringReceivedis not overridden.
3.3.7.9. buildbot.util.sautils
This module contains a few utilities that are not included with SQLAlchemy.
- class buildbot.util.sautils.InsertFromSelect(table, select)
- Parameters:
table – table into which insert should be performed
select – select query from which data should be drawn
This class is taken directly from SQLAlchemy’s compiler.html, and allows a Pythonic representation of
INSERT INTO .. SELECT ..queries.
- buildbot.util.sautils.sa_version()
Return a 3-tuple representing the SQLAlchemy version. Note that older versions that did not have a
__version__attribute are represented by(0,0,0).
3.3.7.10. buildbot.util.pathmatch
- class buildbot.util.pathmatch.Matcher
This class implements the path-matching algorithm used by the data API.
Patterns are tuples of strings, with strings beginning with a colon (
:) denoting variables. A character can precede the colon to indicate the variable type:ispecifies an identifier (identifier).nspecifies a number (parseable byint).
A tuple of strings matches a pattern if the lengths are identical, every variable matches and has the correct type, and every non-variable pattern element matches exactly.
A matcher object takes patterns using dictionary-assignment syntax:
ep = ChangeEndpoint() matcher[('change', 'n:changeid')] = ep
and performs matching using the dictionary-lookup syntax:
changeEndpoint, kwargs = matcher[('change', '13')] # -> (ep, {'changeid': 13})
where the result is a tuple of the original assigned object (the
Changeinstance in this case) and the values of any variables in the path.- iterPatterns()
Returns an iterator which yields all patterns in the matcher as tuples of (pattern, endpoint).
3.3.7.11. buildbot.util.topicmatch
- class buildbot.util.topicmatch.TopicMatcher(topics)
- Parameters:
topics (list) – topics to match
This class implements the AMQP-defined syntax: routing keys are treated as dot-separated sequences of words and matched against topics. A star (
*) in the topic will match any single word, while an octothorpe (#) will match zero or more words.- matches(routingKey)
- Parameters:
routingKey (string) – routing key to examine
- Returns:
True if the routing key matches a topic
3.3.7.12. buildbot.util.subscription
The classes in the buildbot.util.subscription module are used for master-local
subscriptions. In the near future, all uses of this module will be replaced with message-queueing
implementations that allow subscriptions and subscribers to span multiple masters.
3.3.7.13. buildbot.util.croniter
(deprecated)
This module is a copy of https://github.com/taichino/croniter, and provides support for converting cron-like time specifications to actual times.
3.3.7.14. buildbot.util.state
The classes in the buildbot.util.state module are used for dealing with object state
stored in the database.
- class buildbot.util.state.StateMixin
This class provides helper methods for accessing the object state stored in the database.
- name
This must be set to the name to be used to identify this object in the database.
- master
This must point to the
BuildMasterobject.
- getState(name, default)
- Parameters:
name – name of the value to retrieve
default – (optional) value to return if name is not present
- Returns:
state value via a Deferred
- Raises:
KeyError – if name is not present and no default is given
TypeError – if JSON parsing fails
Get a named state value from the object’s state.
- setState(name, value)
- Parameters:
name – the name of the value to change
value – the value to set - must be a JSONable object
returns – Deferred
- Raises:
TypeError – if JSONification fails
Set a named state value in the object’s persistent state. Note that value must be json-able.
3.3.7.15. buildbot.util.identifiers
This module makes it easy to manipulate identifiers.
- buildbot.util.identifiers.isIdentifier(maxLength, object)
- Parameters:
maxLength – maximum length of the identifier
object – object to test for identifier-ness
- Returns:
boolean
Is object a identifier?
- buildbot.util.identifiers.forceIdentifier(maxLength, str)
- Parameters:
maxLength – maximum length of the identifier
str – string to coerce to an identifier
- Returns:
identifier of maximum length
maxLength
Coerce a string (assuming UTF-8 for bytestrings) into an identifier. This method will replace any invalid characters with
_and truncate to the given length.
- buildbot.util.identifiers.incrementIdentifier(maxLength, str)
- Parameters:
maxLength – maximum length of the identifier
str – identifier to increment
- Returns:
identifier of maximum length
maxLength- Raises:
ValueError if no suitable identifier can be constructed
“Increment” an identifier by adding a numeric suffix, while keeping the total length limited. This is useful when selecting a unique identifier for an object. Maximum-length identifiers like
_999999cannot be incremented and will raiseValueError.
3.3.7.16. buildbot.util.lineboundaries
- class buildbot.util.lineboundaries.LineBoundaryFinder
This class accepts a sequence of arbitrary strings and computes newline-terminated substrings. Input strings are accepted in append function, and newline-terminated substrings are returned.
The class buffers any partial lines until a subsequent newline is seen. It considers any of
\r,\n, and\r\nto be newlines. Because of the ambiguity of an append operation ending in the character\r(it may be a bare\ror half of\r\n), the last line of such an append operation will be buffered until the next append or flush.- append(text)
- Parameters:
text – text to append to the boundary finder
- Returns:
a newline-terminated substring or None
Add additional text to the boundary finder. If the addition of this text completes at least one line, as many complete lines as possible are selected as a result. If no lines are completed, the result will be
None.
- flush()
- Returns:
a newline-terminated substring or None
Flush any remaining partial line by adding a newline.
3.3.7.17. buildbot.util.service
This module implements some useful subclasses of Twisted services.
The first two classes are more robust implementations of two Twisted classes, and should be used universally in Buildbot code.
- class buildbot.util.service.AsyncMultiService
This class is similar to
twisted.application.service.MultiService, except that it handles Deferreds returned from child servicesstartServiceandstopServicemethods.Twisted’s service implementation does not support asynchronous
startServicemethods. The reasoning is that all services should start at process startup, with no need to coordinate between them. For Buildbot, this is not sufficient. The framework needs to know when startup has completed, so it can begin scheduling builds. This class implements the desired functionality, with a parent service’sstartServicereturning a Deferred which will only fire when all child servicesstartServicemethods have completed.This class also fixes a bug with Twisted’s implementation of
stopServicewhich ignores failures in thestopServiceprocess. WithAsyncMultiService, any errors in a child’sstopServicewill be propagated to the parent’sstopServicemethod.
- class buildbot.util.service.AsyncService
This class is similar to
twisted.application.service.Service, except that itssetServiceParentmethod will return a Deferred. That Deferred will fire after thestartServicemethod has completed, if the service was started because the new parent was already running.
Some services in buildbot must have only one “active” instance at any given time. In a single-master configuration, this requirement is trivial to maintain. In a multiple-master configuration, some arbitration is required to ensure that the service is always active on exactly one master in the cluster.
For example, a particular daily scheduler could be configured on multiple masters, but only one of them should actually trigger the required builds.
- class buildbot.util.service.ClusteredService
A base class for a service that must have only one “active” instance in a buildbot configuration.
Each instance of the service is started and stopped via the usual twisted
startServiceandstopServicemethods. This utility class hooks into those methods in order to run an arbitration strategy to pick the one instance that should actually be “active”.The arbitration strategy is implemented via a polling loop. When each service instance starts, it immediately offers to take over as the active instance (via
_claimService).If successful, the
activatemethod is called. Once active, the instance remains active until it is explicitly stopped (eg, viastopService) or otherwise fails. When this happens, thedeactivatemethod is invoked and the “active” status is given back to the cluster (via_unclaimService).If another instance is already active, this offer fails, and the instance will poll periodically to try again. The polling strategy helps guard against active instances that might silently disappear and leave the service without any active instance running.
Subclasses should use these methods to hook into this activation scheme:
- activate()
When a particular instance of the service is chosen to be the one “active” instance, this method is invoked. It is the corollary to twisted’s
startService.
- deactivate()
When the one “active” instance must be deactivated, this method is invoked. It is the corollary to twisted’s
stopService.
- isActive()
Returns whether this particular instance is the active one.
The arbitration strategy is implemented via the following required methods:
- _getServiceId()
The “service id” uniquely represents this service in the cluster. Each instance of this service must have this same id, which will be used in the arbitration to identify candidates for activation. This method may return a Deferred.
- _claimService()
An instance is attempting to become the one active instance in the cluster. This method must return True or False (optionally via a Deferred) to represent whether this instance’s offer to be the active one was accepted. If this returns True, the
activatemethod will be called for this instance.
- _unclaimService()
Surrender the “active” status back to the cluster and make it available for another instance. This will only be called on an instance that successfully claimed the service and has been activated and after its
deactivatehas been called. Therefore, in this method it is safe to reassign the “active” status to another instance. This method may return a Deferred.
This class implements a generic Service that needs to be instantiated only once according to its parameters. It is a common use case to need this for accessing remote services. Having a shared service allows to limit the number of simultaneous access to the same remote service. Thus, several completely independent Buildbot services can use that
SharedServiceto access the remote service, and automatically synchronize themselves to not overwhelm it.Constructor of the service.
Note that unlike
BuildbotService,SharedServiceis not reconfigurable and uses the classical constructor method.Reconfigurability would mean to add some kind of reference counting of the users, which will make the design much more complicated to use. This means that the SharedService will not be destroyed when there is no more users, it will be destroyed at the master’s stopService It is important that those
SharedServicelife cycles are properly handled. Twisted will indeed wait for any thread pool to finish at master stop, which will not happen if the thread pools are not properly closed.The lifecycle of the SharedService is the same as a service, it must implement startService and stopService in order to allocate and free its resources.
Class method. Takes same arguments as the constructor of the service. Get a unique name for that instance of a service. This returned name is the key inside the parent’s service dictionary that is used to decide if the instance has already been created before or if there is a need to create a new object. Default implementation will hash args and kwargs and use
<classname>_<hash>as the name.
- Parameters:
parentService – an
AsyncMultiServicewhere to lookup and register theSharedService(usually the root service, the master)- Returns:
instance of the service via Deferred
Class method. Takes same arguments as the constructor of the service (plus the parentService at the beginning of the list). Construct an instance of the service if needed, and place it at the beginning of the parentService service list. Placing it at the beginning will guarantee that the
SharedServicewill be stopped after the other services.
- class buildbot.util.service.BuildbotService
This class is the combinations of all Service classes implemented in buildbot. It is Async, MultiService, and Reconfigurable, and designed to be eventually the base class for all buildbot services. This class makes it easy to manage (re)configured services.
The design separates the check of the config and the actual configuration/start. A service sibling is a configured object that has the same name of a previously started service. The sibling configuration will be used to configure the running service.
Service lifecycle is as follow:
Buildbot master start
Buildbot is evaluating the configuration file. BuildbotServices are created, and checkConfig() are called by the generic constructor.
If everything is fine, all services are started. BuildbotServices startService() is called, and call reconfigService() for the first time.
User reconfigures buildbot.
Buildbot is evaluating the configuration file. BuildbotServices siblings are created, and checkConfig() are called by the generic constructor.
BuildbotServiceManager is figuring out added services, removed services, unchanged services
BuildbotServiceManager calls stopService() for services that disappeared from the configuration.
BuildbotServiceManager calls startService() like in buildbot start phase for services that appeared from the configuration.
BuildbotServiceManager calls reconfigService() for the second time for services that have their configuration changed.
- __init__(self, *args, **kwargs)
Constructor of the service. The constructor initializes the service, calls checkConfig() and stores the config arguments in private attributes.
This should not be overridden by subclasses, as they should rather override checkConfig.
- canReconfigWithSibling(self, sibling)
- This method is used to check if we are able to call
- :py:func:`reconfigServiceWithSibling` with the given sibling.
- If it returns `False`, we stop the old service and start a new one,
- instead of attempting a reconfig.
- checkConfig(self, *args, **kwargs)
Please override this method to check the parameters of your config. Please use
buildbot.config.errorfor error reporting. You can replace them*args, **kwargsby actual constructor like arguments with default args, and it have to match self.reconfigService This method is synchronous, and executed in the context of the master.cfg. Please don’t block, or use deferreds in this method. Remember that the object that runs checkConfig is not always the object that is actually started. The checked configuration can be passed to another sibling service. Any actual resource creation shall be handled in reconfigService() or startService()
- reconfigService(self, *args, **kwargs)
This method is called at buildbot startup, and buildbot reconfig. *args and **kwargs are the configuration arguments passed to the constructor in master.cfg. You can replace
them *args, **kwargsby actual constructor like arguments with default args, and it have to match self.checkConfigReturns a deferred that should fire when the service is ready. Builds are not started until all services are configured.
BuildbotServices must be aware that during reconfiguration, their methods can still be called by running builds. So they should atomically switch old configuration and new configuration, so that the service is always available.
If this method raises
NotImplementedError, it means the service is legacy, and do not support reconfiguration. TheBuildbotServiceManagerparent, will detect this, and swap old service with new service. This behaviour allow smooth transition of old code to new reconfigurable service lifecycle but shall not be used for new code.
- reconfigServiceWithSibling(self, sibling)
Internal method that finds the configuration bits in a sibling, an object with same class that is supposed to replace it from a new configuration. We want to reuse the service started at master startup and just reconfigure it. This method handles necessary steps to detect if the config has changed, and eventually call self.reconfigService()
- renderSecrets(self, *args)
Utility method which renders a list of parameters which can be interpolated as a secret. This is meant for services which have their secrets parameter configurable as positional arguments. If there are several argument, the secrets are interpolated in parallel, and a list of result is returned via deferred. If there is one argument, the result is directly returned.
Note
For keyword arguments, a simpler method is to use the
secretsclass variable, whose items will be automatically interpolated just before reconfiguration.def reconfigService(self, user, password, ...) user, password = yield self.renderSecrets(user, password)
def reconfigService(self, token, ...) token = yield self.renderSecrets(token)
secrets = ("user", "password") def reconfigService(self, user=None, password=None, ...): # nothing to do; user and password will be automatically interpolated
Advanced users can derive this class to make their own services that run inside buildbot, and follow the application lifecycle of buildbot master.
Such services are singletons accessible to nearly every object in Buildbot (buildsteps, status, changesources, etc) using self.master.namedServices[‘<nameOfYourService>’].
As such, they can be used to factorize access to external services, available e.g using a REST api. Having a single service will help with caching, and rate-limiting access of those APIs.
Here is an example on how you would integrate and configure a simple service in your master.cfg:
class MyShellCommand(ShellCommand): def getResultSummary(self): # access the service attribute service = self.master.namedServices['myService'] return dict(step="arg value: %d" % (service.arg1,)) class MyService(BuildbotService): name = "myService" def checkConfig(self, arg1): if not isinstance(arg1, int): config.error("arg1 must be an integer while it is %r" % (arg1,)) return if arg1 < 0: config.error("arg1 must be positive while it is %d" % (arg1,)) def reconfigService(self, arg1): self.arg1 = arg1 return defer.succeed(None) c['schedulers'] = [ ForceScheduler( name="force", builderNames=["testy"])] f = BuildFactory() f.addStep(MyShellCommand(command='echo hei')) c['builders'] = [ BuilderConfig(name="testy", workernames=["local1"], factory=f)] c['services'] = [ MyService(arg1=1) ]
3.3.7.18. buildbot.util.httpclientservice
- class buildbot.util.httpclientservice.HTTPClientService
This class implements a SharedService for doing http client access. The module automatically chooses from txrequests and treq and uses whichever is installed. It provides minimalistic API similar to the one from txrequests and treq. Having a SharedService for this allows to limits the number of simultaneous connection for the same host. While twisted application can managed thousands of connections at the same time, this is often not the case for the services buildbot controls. Both txrequests and treq use keep-alive connection polling. Lots of HTTP REST API will however force a connection close in the end of a transaction.
Note
The API described here is voluntary minimalistic, and reflects what is tested. As most of this module is implemented as a pass-through to the underlying libraries, other options can work but have not been tested to work in both backends. If there is a need for more functionality, please add new tests before using them.
- static getService(master, base_url, auth=None, headers=None, debug=None, verify=None)
- Parameters:
master – the instance of the master service (available in self.master for all the
BuildbotServiceinstances)base_url – The base http url of the service to access. e.g.
http://github.com/auth – Authentication information. If auth is a tuple then
BasicAuthwill be used. e.g('user', 'passwd')It can also be arequests.authauthentication plugin. In this case txrequests will be forced, and treq cannot be used.headers – The headers to pass to every requests for this url
debug – log every requests and every response.
verify – disable the SSL verification.
- Returns:
instance of :HTTPClientService
Get an instance of the SharedService. There is one instance per base_url and auth.
The constructor initialize the service, and store the config arguments in private attributes.
This should not be overridden by subclasses, as they should rather override checkConfig.
This function has been deprecated. Please use
HTTPSession.
- get(endpoint, params=None)
- Parameters:
endpoint – endpoint. It must either be a full URL (starts with
http://orhttps://) or relative to the base_url (starts with/)params – optional dictionary that will be encoded in the query part of the url (e.g.
?param1=foo)
- Returns:
implementation of :IHTTPResponse via deferred
Performs a HTTP
GET. This function has been deprecated. Please useHTTPSession.
- delete(endpoint, params=None)
- Parameters:
endpoint – endpoint. It must either be a full URL (starts with
http://orhttps://) or relative to the base_url (starts with/)params – optional dictionary that will be encoded in the query part of the url (e.g.
?param1=foo)
- Returns:
implementation of :IHTTPResponse via deferred
Performs a HTTP
DELETE. This function has been deprecated. Please useHTTPSession.
- post(endpoint, data=None, json=None, params=None)
- Parameters:
endpoint – endpoint. It must either be a full URL (starts with
http://orhttps://) or relative to the base_url (starts with/)data – optional dictionary that will be encoded in the body of the http requests as
application/x-www-form-urlencodedjson – optional dictionary that will be encoded in the body of the http requests as
application/jsonparams – optional dictionary that will be encoded in the query part of the url (e.g.
?param1=foo)
- Returns:
implementation of :IHTTPResponse via deferred
Performs a HTTP
POST. This function has been deprecated. Please useHTTPSession.Note
json and data cannot be used at the same time.
- put(endpoint, data=None, json=None, params=None)
- Parameters:
endpoint – endpoint. It must either be a full URL (starts with
http://orhttps://) or relative to the base_url (starts with/)data – optional dictionary that will be encoded in the body of the http requests as
application/x-www-form-urlencodedjson – optional dictionary that will be encoded in the body of the http requests as
application/jsonparams – optional dictionary that will be encoded in the query part of the url (e.g.
?param1=foo)
- Returns:
implementation of :IHTTPResponse via deferred
Performs a HTTP
PUT. This function has been deprecated. Please useHTTPSession.Note
json and data cannot be used at the same time.
- update_headers(headers)
- Parameters:
headers – dictionary of string key-value pairs containing headers to add to the session.
Adds or updates the session with the given headers. All subsequent HTTP requests will contain the additional headers specified in this call.
- class buildbot.util.httpclientservice.HTTPSession
A class that encapsulates certain parameters of connection to HTTP URLs and allows to perform connections to them.
Example usage in a service.
s = HTTPSession(self.master.httpservice, "https://api.github.com") r = await s.get("/repos/buildbot/buildbot/releases") print(r.json())
Usually
HTTPSessionis used by creating an instance of it in service constructor and reusing it throughout the life of the service.- __init__(http: HTTPClientService, base_url: str, auth=None, headers=None, debug=None, verify=None)
- Parameters:
http – the instance of HTTPClientService to use. It is available as
self.master.httpservicefor all theBuildbotServiceinstances.base_url – The base http url of the server to access. e.g.
http://github.com/auth – Authentication information. If auth is a tuple then
BasicAuthwill be used. e.g('user', 'passwd')It can also be arequests.authauthentication plugin. In this case txrequests will be forced, and treq cannot be used.headers – The headers to pass to every requests for this url
debug – log every requests and every response.
verify – disable the SSL verification.
Creates a
HTTPSessioninstance.
- get(endpoint, params=None)
- Parameters:
endpoint – endpoint. It must either be a full URL (starts with
http://orhttps://) or relative to the base_url (starts with/)params – optional dictionary that will be encoded in the query part of the url (e.g.
?param1=foo)
- Returns:
implementation of :IHTTPResponse via deferred
Performs a HTTP
GET
- delete(endpoint, params=None)
- Parameters:
endpoint – endpoint. It must either be a full URL (starts with
http://orhttps://) or relative to the base_url (starts with/)params – optional dictionary that will be encoded in the query part of the url (e.g.
?param1=foo)
- Returns:
implementation of :IHTTPResponse via deferred
Performs a HTTP
DELETE
- post(endpoint, data=None, json=None, params=None)
- Parameters:
endpoint – endpoint. It must either be a full URL (starts with
http://orhttps://) or relative to the base_url (starts with/)data – optional dictionary that will be encoded in the body of the http requests as
application/x-www-form-urlencodedjson – optional dictionary that will be encoded in the body of the http requests as
application/jsonparams – optional dictionary that will be encoded in the query part of the url (e.g.
?param1=foo)
- Returns:
implementation of :IHTTPResponse via deferred
Performs a HTTP
POSTNote
json and data cannot be used at the same time.
- put(endpoint, data=None, json=None, params=None)
- Parameters:
endpoint – endpoint. It must either be a full URL (starts with
http://orhttps://) or relative to the base_url (starts with/)data – optional dictionary that will be encoded in the body of the http requests as
application/x-www-form-urlencodedjson – optional dictionary that will be encoded in the body of the http requests as
application/jsonparams – optional dictionary that will be encoded in the query part of the url (e.g.
?param1=foo)
- Returns:
implementation of :IHTTPResponse via deferred
Performs a HTTP
PUTNote
json and data cannot be used at the same time.
- class buildbot.util.httpclientservice.IHTTPResponse
Note
IHTTPResponseis a subset of treqResponseAPI described here. The API it is voluntarily minimalistic and reflects what is tested and reliable to use with the three backends (including fake). The API is a subset of the treq API, which is itself a superset of twisted IResponse API. treq is thus implemented as passthrough.Notably:
There is no API to automatically decode content, as this is not implemented the same in both backends.
There is no API to stream content as the two libraries have very different way for doing it, and we do not see use-case where buildbot would need to transfer large content to the master.
- content()
- Returns:
raw (
bytes) content of the response via deferred
- json()
- Returns:
json decoded content of the response via deferred
- code
- Returns:
http status code of the request’s response (e.g 200)
- url
- Returns:
request’s url (e.g https://api.github.com/endpoint’)
3.3.7.19. buildbot.test.fake.httpclientservice
- class buildbot.test.fake.httpclientservice.HTTPClientService
This class implements a fake version of the
buildbot.util.httpclientservice.HTTPClientServicethat needs to be used for testing services which need http client access. It implements the same APIs asbuildbot.util.httpclientservice.HTTPClientService, plus one that should be used to register the expectations. It should be registered by the test case before the tested service actually requests an HTTPClientService instance, with the same parameters. It will then replace the original implementation automatically (no need to patch anything).- getService(cls, master, case, *args, **kwargs)
- Parameters:
master – the instance of a fake master service
case – a
twisted.python.unittest.TestCaseinstance
getServicereturns a fakeHTTPClientService, and should be used just like the regulargetService.It will make sure the original
HTTPClientServiceis not called, and assert that all expected http requests have been described in the test case.
- expect(self, method, ep, params=None, data=None, json=None, code=200, content=None, content_json=None, processing_delay_s=None)
- Parameters:
method – expected HTTP method
ep – expected endpoint
params – optional expected query parameters
data – optional expected non-json data (bytes)
json – optional expected json data (dictionary or list or string)
code – optional http code that will be received
content – optional content that will be received
content_json – optional content encoded in json that will be received
processing_delay_s – optional delay that the handling of the request will take
Records an expectation of HTTP requests that will happen during the test. The order of the requests is important. All the request expectation must be defined in the test.
For example:
from twisted.internet import defer from twisted.trial import unittest from buildbot.test.fake import httpclientservice as fakehttpclientservice from buildbot.util import httpclientservice from buildbot.util import service class MyTestedService(service.BuildbotService): name = 'myTestedService' @defer.inlineCallbacks def reconfigService(self, baseurl): self._http = yield httpclientservice.HTTPSession( self.master.httpservice, baseurl) @defer.inlineCallbacks def doGetRoot(self): res = yield self._http.get("/") # note that at this point, only the http response headers are received if res.code != 200: raise RuntimeError("%d: server did not succeed" % (res.code)) res_json = yield res.json() # res.json() returns a deferred to account for the time needed to fetch the # entire body return res_json class Test(unittest.TestCase): @defer.inlineCallbacks def setUp(self): baseurl = 'http://127.0.0.1:8080' self.parent = service.MasterService() self._http = \ yield fakehttpclientservice.HTTPClientService.getService(self.parent, self, baseurl)) self.tested = myTestedService(baseurl) yield self.tested.setServiceParent(self.parent) yield self.parent.startService() def test_root(self): self._http.expect("get", "/", content_json={'foo': 'bar'}) response = yield self.tested.doGetRoot() self.assertEqual(response, {'foo': 'bar'}) def test_root_error(self): self._http.expect("get", "/", content_json={'foo': 'bar'}, code=404) with self.assertRaises(RuntimeError) as e: yield self.tested.doGetRoot() self.assertIn('404: server did not succeed', str(e.exception))
3.3.7.20. buildbot.util.ssl
This module is a copy of twisted.internet.ssl except it won’t crash with
ImportError if pyopenssl is not installed. If you need to use
twisted.internet.ssl, please instead use buildbot.util.ssl, and call
ssl.ensureHasSSL in checkConfig to provide helpful message to the user, only
if they enabled SSL for your plugin.
- buildbot.util.ssl.ensureHasSSL(plugin_name)
- Parameters:
plugin_name – name of the plugin. Usually
self.__class__.__name__
Call this function to provide helpful config error to the user in case of
OpenSSLnot installed.
- buildbot.util.ssl.skipUnless(f)
- Parameters:
f – decorated test
Test decorator which will skip the test if
OpenSSLis not installed.
3.3.8. Build Result Codes
Buildbot represents the status of a step, build, or buildset using a set of
numeric constants. From Python, these constants are available in the module
buildbot.process.results, but the values also appear in the database and in
external tools, so the values are fixed.
- buildbot.process.results.SUCCESS
Value: 0; color: green; a successful run.
- buildbot.process.results.WARNINGS
Value: 1; color: orange; a successful run, with some warnings.
- buildbot.process.results.FAILURE
Value: 2; color: red; a failed run, due to problems in the build itself, as opposed to a Buildbot misconfiguration or bug.
- buildbot.process.results.SKIPPED
Value: 3; color: white; a run that was skipped – usually a step skipped by
doStepIf(see Parameters Common to all Steps)
- buildbot.process.results.EXCEPTION
Value: 4; color: purple; a run that failed due to a problem in Buildbot itself.
- buildbot.process.results.RETRY
Value: 5; color: purple; a run that should be retried, usually due to a worker disconnection.
- buildbot.process.results.CANCELLED
Value: 6; color: pink; a run that was cancelled by the user.
- buildbot.process.results.Results
A dictionary mapping result codes to their lowercase names.
- buildbot.process.results.worst_status(a, b)
This function takes two status values, and returns the “worst” status of the two. This is used to aggregate step statuses into build statuses, and build statuses into buildset statuses.
- buildbot.process.results.computeResultAndTermination(obj, result, previousResult)
- Parameters:
obj – an object with the attributes of
ResultComputingConfigMixinresult – the new result
previousResult – the previous aggregated result
Building on
worst_status, this function determines what the aggregated overall status is, as well as whether the attempt should be terminated, based on the configuration inobj.
- class buildbot.process.results.ResultComputingConfigMixin
This simple mixin is intended to help implement classes that will use
computeResultAndTermination. The class has, as class attributes, the result computing configuration parameters with default values:- haltOnFailure
- flunkOnWarnings
- flunkOnFailure
- warnOnWarnings
- warnOnFailure
The names of these attributes are available in the following attribute:
- resultConfig
3.3.9. WWW Server
3.3.9.1. History and Motivation
One of the goals of the ‘nine’ project is to rework Buildbot’s web services to use a more modern, consistent design and implement UI features in client-side JavaScript instead of server-side Python.
The rationale behind this is that a client side UI relieves pressure on the server while being more responsive for the user. The web server only concentrates on serving data via a REST interface wrapping the Data API. This removes a lot of sources of latency where, in previous versions, long synchronous calculations were made on the server to generate complex pages.
Another big advantage is live updates of status pages, without having to poll or reload. The new system uses Comet techniques in order to relay Data API events to connected clients.
Finally, making web services an integral part of Buildbot, rather than a status plugin, allows tighter integration with the rest of the application.
3.3.9.2. Design Overview
The www service exposes three pieces via HTTP:
A REST interface wrapping Data API;
HTTP-based messaging protocols wrapping the Messaging and Queues interface; and
Static resources implementing the client-side UI.
The REST interface is a very thin wrapper: URLs are translated directly into Data API paths, and results are returned directly, in JSON format. It is based on JSON API. Control calls are handled with a simplified form of JSONRPC 2.0.
The message interface is also a thin wrapper around Buildbot’s MQ mechanism. Clients can subscribe to messages, and receive copies of the messages, in JSON, as they are received by the buildmaster.
The client-side UI is an AngularJS application. Buildbot uses the Python setuptools entry-point mechanism to allow multiple packages to be combined into a single client-side experience. This allows frontend developers and users to build custom components for the web UI without hacking Buildbot itself.
Python development and AngularJS development are very different processes, requiring different environment requirements and skillsets. To maximize hackability, Buildbot separates the two cleanly. An experienced AngularJS hacker should be quite comfortable in the www/ directory, with a few exceptions described below. Similarly, an experienced Python hacker can simply download the pre-built web UI (from PyPI!) and never venture near the www/ directory.
URLs
The Buildbot web interface is rooted at its base URL, as configured by the user. It is entirely
possible for this base URL to contain path components, e.g.,
http://build.example.org/buildbot/, if hosted behind an HTTP proxy. To accomplish this, all
URLs are generated relative to the base URL.
Overall, the space under the base URL looks like this:
/– The HTML document that loads the UI/config– Returns implementation-defined master configuration used by the frontend UI. The same data may be embedded directly into the HTML document returned by the/URL./api/v{version}– The root of the REST APIs, each versioned numerically. Users should, in general, use the latest version./ws– The WebSocket endpoint to subscribe to messages from the mq system./sse– The server sent event endpoint where clients can subscribe to messages from the mq system.
3.3.9.3. REST API
Rest API is described in its own section.
3.3.9.4. Server-Side Session
The web server keeps a session state for each user, keyed on a session cookie.
This session is available from request.getSession(), and data is stored as attributes.
The following attributes may be available:
user_infoA dictionary maintained by the authentication subsystem. It may have the following information about the logged-in user:
usernameemailfull_namegroups(a list of group names)
As well as additional fields specific to the user info implementation.
The contents of the
user_infodictionary are made available to the UI asconfig.user.
3.3.9.5. Message API
Currently, messages are implemented with two protocols, WebSockets and server sent events.
WebSocket
WebSocket is a protocol for arbitrary messaging to and from a browser. As an HTTP extension, the protocol is not yet well supported by all HTTP proxy technologies. Although, it has been reported to work well used behind the https protocol. Only one WebSocket connection is needed per browser.
The client can connect using the url ws[s]://<BB_BASE_URL>/ws.
The protocol used is a simple in-house protocol based on json. The structure of a command from the client is as follows:
{ "cmd": "<command name>", '_id': <id of the command>, "arg1": arg1, "arg2": arg2 }
cmdis used to reference a command name_idis used to track the response, can be any unique number or string, generated by the client. It needs to be unique per websocket session.
Response is sent asynchronously, reusing _id to track which command is responded.
Success answer example would be:
{ "msg": "OK", "_id": 1, "code": 200 }
Error answer example would be:
{ "_id": 1, "code": 404, "error": "no such command 'poing'" }
The client can send several commands without waiting for a response.
Responses are not guaranteed to be sent in order.
Several commands are implemented:
ping{ "_id": 1, "cmd": "ping" }
The server will respond with a “pong” message:
{ "_id": 1, "msg": "pong", "code": 200 }
startConsumingStart consuming events that match
path.paths are described in the Messaging and Queues section. For size optimization reasons, paths are joined with “/”, and with the None wildcard replaced by “*”.{ "_id": 1, "cmd": "startConsuming", "path": "change/*/*" }
Success answer example will be:
{ "msg": "OK", "_id": 1, "code": 200 }
stopConsumingStop consuming events that were previously registered with
path.{ "_id": 1, "cmd": "stopConsuming", "path": "change/*/*" }
Success answer example will be:
{ "msg": "OK", "_id": 1, "code": 200 }
The client will receive events as websocket frames encoded in json with the following format:
{ "k": key, "m": message }
Server Sent Events
SSE is a simpler protocol than WebSockets and is more REST compliant. It uses the chunk-encoding HTTP feature to stream the events. SSE also does not work well behind an enterprise proxy, unless you use the https protocol.
The client can connect using following endpoints:
http[s]://<BB_BASE_URL>/sse/listen/<path>: Start listening to events on the http connection. Optionally, setup a first event filter on<path>. The first message send is a handshake, giving a uuid that can be used to add or remove event filters.http[s]://<BB_BASE_URL>/sse/add/<uuid>/<path>: Configure a sse session to add an event filterhttp[s]://<BB_BASE_URL>/sse/remove/<uuid>/<path>: Configure a sse session to remove an event filter
Note that if a load balancer is setup as a front end to buildbot web masters, the load balancer must be configured to always use the same master given a client IP address for /sse endpoint.
The client will receive events as sse events, encoded with the following format:
event: event
data: { "key": <key>, "message": <message> }
The first event received is a handshake, and is used to inform the client about the uuid to use for configuring additional event filters
event: handshake
data: <uuid>
3.3.10. Javascript Data Module
The Data module is a reusable AngularJS module used to access Buildbot’s data API from the browser. Its main purpose is to handle the 3 way binding.
2 way binding is the angular MVVM concept, which seamlessly synchronise the view and the model. Here, we introduce an additional way of synchronisation, which is from the server to the model.

We use the message queue and the websocket interfaces to maintain synchronisation between the server and the client.
The client application just needs to query the needed data using a highlevel API, and the data module uses the best approach to make the data always up to date.
Once the binding is set up by the controller, everything is automatically up to date.
3.3.10.1. Base Concepts
Collections
All the data you can get are Collections. Even a query to a single resource returns a collection. A collection is an Array subclass which has extra capabilities:
It listens to the event stream and is able to maintain itself up-to-date
It implements client side queries in order to guarantee up-to-date filtering, ordering and limiting queries.
It has a fast access to each item it contains via its id.
It has its own event handlers so that the client code can react when the Collection is changing
Wrappers
Each data type contained in a collection is wrapped in a javascript object. This allows to create some custom enhancements to the data model. For example, the Change wrapper decodes the author name and email from the “author” field.
Each wrapper class also has specific access methods, which allow to access more data from the REST hierarchy.

Installation
The Data module is available as a standalone AngularJS module.
Installation via yarn:
yarn add buildbot-data
Inject the bbData module to your application:
angular.module('myApp', ['bbData'])
Service API
- class DataService()
DataService is the service used for accessing the Buildbot data API. It has a modern interface for accessing data in such a way that the updating of the data via web socket is transparent.
- DataService.open()
- Returns:
a DataAccessor which handles 3 way data binding
Open a new accessor every time you need to update the data in a controller.
It registers on $destroy event on the scope, and thus automatically unsubscribes from updates when the data is not used anymore.
// open a new accessor every time you need updating data in a controller class DemoController { constructor($scope, dataService) { // automatically closes all the bindings when the $scope is destroyed const data = dataService.open().closeOnDestroy($scope); // request new data, it updates automatically this.builders = data.getBuilders({limit: 10, order: '-started_at'}); } }
- DataService.getXs([id][, query])
Xscan be the following:Builds,Builders,Buildrequests,Buildsets,Workers,Changes,Changesources,Forceschedulers,Masters,Schedulers,Sourcestamps.It’s highly advised to use these methods instead of the lower level
get('string').- Returns:
collection which will eventually contain all the requested data
The collections returned without using an accessor are not automatically updated. So use those methods only when you know the data are not changing.
// assign builds to $scope.builds and then load the steps when the builds are discovered // onNew is called at initial load $scope.builds = dataService.getBuilds({builderid: 1}); $scope.builds.onNew = build => build.loadSteps();
- DataService.get(endpoint[, id][, query])
- Returns:
a collection; when the promise is resolved, the collection contains all the requested data
// assign builds to $scope.builds once the Collection is filled const builderid = 1; $scope.builds = dataService.get(`builders/${builderid}/builds`, {limit: 1}); $scope.builds.onNew = build => build.loadSteps();
// assign builds to $scope.builds before the Collection is filled using the // getArray() method $scope.builds = dataService.get('builds', {builderid: 1});
- DataService.control(url, method[, params])
- Returns:
a promise; sends a JSON RPC2 POST request to the server
// open a new accessor every time you need to update the data in a controller dataService.control('forceschedulers/force', 'force') .then(response => $log.debug(response), reason => $log.error(reason));
- class DataAccessor()
DataAccessor object is returned by the
dataService.open()method.- DataAccessor.closeOnDestroy($scope)
Registers scope destruction as waterfall destruction for all collection accessed via this accessor.
- DataAccessor.close()
Destructs all collections previously accessed via this accessor. Destroying a collection means it will unsubscribe from any events necessary to maintain it up-to-date.
- DataAccessor.getXs([id][, query])
Same methods as in DataService, except here the data will be maintained up-to-date.
- Returns:
a collection which will eventually contain all the requested data
- class Collections()
- Collections.get(id)
This method does not do any network access, and thus only knows about data already fetched.
- Returns:
one element of the collection by id, or undefined, if this id is unknown to the collection.
- Collections.hasOwnProperty(id)
- Returns:
true if this id is known by this collection.
- Collections.close()
Forcefully unsubscribes this connection from auto-update. Normally, this is done automatically on scope destruction, but sometimes, when you got enough data, you want to save bandwidth and disconnect the collection.
- Collections.put(object)
Inserts one plain object to the collection. As an external API, this method is only useful for unit tests to simulate new data coming asynchronously.
- Collections.from(object_list)
Inserts several plain objects to the collection. This method is only useful for unit tests to simulate new data coming asynchronously.
- Collections.onNew = (object) ->()
Callback method which is called when a new object arrives in the collection. This can be called either when initial data is coming via REST API, or when data is coming via the event stream. The affected object is given in parameter. this context is the collection.
- Collections.onUpdate = (object) ->()
Callback method which is called when an object is modified. This is called when data is coming via the event stream. The affected object is given in parameter. this context is the collection.
- Collections.onChange = (collection) ->()
Callback method which is called when an object is modified. This is called when data is coming via the event stream. this context is the collection. The full collection is given in parameter (in case you override
thisvia fat arrow).
- Collections.$ready
Attribute similar to what
ngResourceprovides. True after first server interaction is completed, false before that. Knowing if the Collection has been resolved is useful in data-binding (for example to display a loading graphic).
- class Wrapper()
Wrapper objects are objects stored in the collection. These objects have specific methods, depending on their types.
- Wrapper.getXs([id][, query])
Same as
DataService.getXs, but with a relative endpoint.- Returns:
a collection; when the promise is resolved, the collection contains all the requested data
// assign builds to $scope.builds once the Collection is filled $scope.builds = dataService.getBuilds({builderid: 1}); $scope.builds.onNew = function(b) { b.complete_steps = b.getSteps({complete:true}); b.running_steps = b.getSteps({complete:false}); };
- Wrapper.loadXs([id][, query])
o.loadXs()is equivalent too.xs = o.getXs().- Returns:
a collection; the collection contains all the requested data, which is also assigned to
o.Xs
// get builder with id = 1 dataService.getBuilders(1).onNew = builder => { // load all builds in builder.builds builder.loadBuilds().onNew(build => { // load all buildsteps in build.steps build.loadSteps(); }); };
- Wrapper.control(method, params)
- Returns:
a promise; sends a JSON RPC2 POST request to the server
3.3.11. Base web application
3.3.11.1. JavaScript Application
The client side of the web UI is written in JavaScript and based on the React framework.
This is a Single Page Application. All
Buildbot pages are loaded from the same path, at the master’s base URL. The actual content of the
page is dictated by the fragment in the URL (the portion following the # character). Using the
fragment is a common JS technique to avoid reloading the whole page over HTTP when the user changes
the URI or clicks on a link.
React
The best place to learn about React is its own documentation.
React’s strong points are:
A component-based architecture that promotes reusability and maintainability
A virtual DOM for efficient updates and rendering
A rich ecosystem of tools and libraries
Strong community support and frequent updates
Built-in testing utilities and excellent support for unit testing
On top of React, we use nodeJS tools to ease development:
Vite build system, which provides fast builds and hot module replacement during development. In production mode, the build system minifies html, css and js, so that the final app is only 3 files to download (+img)
TypeScript for type-safe JavaScript development
JSX syntax for combining JavaScript and HTML
Bootstrap is a CSS library providing known good basis for our styles
React Icons is a comprehensive icon library with support for multiple icon sets
Additionally the following npm modules are loaded by Vite and are available to plugins:
For the exact versions of these dependencies, check www/base/package.json.
Extensibility
The Buildbot UI is designed for extensibility. The base application should be pretty minimal and only include very basic status pages. The base application cannot be disabled, so any page that’s not absolutely necessary should be put in plugins. You can also completely replace the default application by another application more suitable to your needs.
Some Web plugins are maintained inside Buildbot’s git repository, but this is not required in order for a plugin to work. Unofficial plugins are possible and encouraged.
Typical plugin source code layout is:
setup.pyStandard setup script. Most plugins should use the same boilerplate, which implements building the BuildBot plugin app as part of the package setup. Minimal adaptation is needed.
<pluginname>/__init__.pyThe python entrypoint. Must contain an “ep” variable of type buildbot.www.plugin.Application. Minimal adaptation is needed.
vite.config.tsConfiguration for Vite build system. Defines: - Entry point (typically src/index.ts) - Output directory (buildbot_<pluginname>/static) - External dependencies (React, MobX, etc.) Few changes are usually needed here. Please see Vite docs for details.
src/...Source code for the React application, typically organized as: - src/index.ts: Plugin entry point - src/views/: React components - src/utils/: Utility functions
package.jsonDeclares npm dependencies and development scripts.
tsconfig.jsonTypeScript configuration. Defines compiler options and includes/excludes.
MANIFEST.inNeeded by setup.py for sdist generation. You need to adapt this file to match the name of your plugin.
Plugins are packaged as python entry-points for the buildbot.www namespace.
The python part is defined in the buildbot.www.plugin module.
The entrypoint must contain a twisted.web Resource, that is populated in the web server in
/<pluginname>/.
The plugin may only add an http endpoint, or it could add a full JavaScript UI. This is controlled
by the ui argument of the Application endpoint object. If ui==True, then it will
automatically load /<pluginname>/scripts.js and /<pluginname>/styles.css into the
React application.
The plugin’s JavaScript entry point (typically src/index.ts) should use the buildbotSetupPlugin
function to register:
- Menu items (with icons from react-icons)
- Routes (using react-router-dom)
- Settings (configuration options)
- Any other UI extensions
Example registration:
buildbotSetupPlugin(reg => {
reg.registerMenuGroup({
name: 'pluginname',
caption: 'Plugin Name',
icon: <FaIcon/>,
order: 5,
route: '/pluginroute',
});
reg.registerRoute({
route: "/pluginroute",
group: "pluginname",
element: () => <PluginComponent/>,
});
});
The plugin writers may add more REST APIs to /<pluginname>/api. For that, a reference to the
master singleton is provided in master attribute of the Application entrypoint. The plugins are
not restricted to Twisted, and could even load a wsgi application using flask, django, or some
other framework.
Check out the official BuildBot www plugins for examples. The www/grid_view and www/badges are good examples of plugins with and without a JavaScript UI respectively.
Routing
React uses a router to match URLs and choose which page to display.
The router we use is react-router-dom.
Typically, a route registration will look like following example:
import { Route } from 'react-router-dom';
import { FaExclamationCircle } from 'react-icons/fa';
function MyComponent() {
return (
<Route path="/myname">
<div>
<h1>My Name Plugin</h1>
<FaExclamationCircle />
</div>
</Route>
);
}
Linking with Buildbot
A running buildmaster needs to be able to find the JavaScript source code it needs to serve the UI. This needs to work in a variety of contexts - Python development, JavaScript development, and end-user installations. To accomplish this, the www build process finishes by bundling all of the static data into a Python distribution tarball, along with a little bit of Python glue. The Python glue implements the interface described below, with some care taken to handle multiple contexts.
See Hacking the Buildbot JavaScript for a more extensive explanation and tutorial.
3.3.11.2. Testing Setup
buildbot_www uses Jest and React Testing Library to run the JavaScript test suite. These are the recommended testing tools for React applications. We don’t run the front-end testsuite inside the python ‘trial’ test suite, because testing python and JS is technically very different.
Jest needs Node.js to run the unit tests. Given our current experience, we did not see any bugs yet that would only happen on a particular browser. This is the reason why only Chrome is used for testing at the moment.
Debug with Jest
console.log is available via Jest. In order to debug the unit tests, you can use the
Chrome DevTools when running tests in watch mode. The React Developer Tools extension can also
be helpful for debugging component state and props.
Testing with real data
It is possible to run the frontend development server while proxying API requests to a real Buildbot instance. This allows front-end development with realistic data without needing a full local setup.
Vite’s development server includes built-in proxy support configured in www/base/vite.config.ts.
By default it proxies to https://buildbot.buildbot.net but you can modify this in the config file.
To start the development server:
cd www/base
yarn run start
3.3.12. Authentication
Buildbot’s HTTP authentication subsystem supports a rich set of information about users:
User credentials: Username and proof of ownership of that username.
User information: Additional information about the user, including
email address
full name
group membership
Avatar information: a small image to represent the user.
Buildbot’s authentication subsystem is designed to support several authentication modes:
- Simple username/password authentication.
The Buildbot UI prompts for a username and password and the backend verifies them.
- External authentication by an HTTP Proxy.
An HTTP proxy in front of Buildbot performs the authentication and passes the verified username to Buildbot in an HTTP Header.
- Authentication by a third-party website.
Buildbot sends the user to another site such as GitHub to authenticate and receives a trustworthy assertion of the user’s identity from that site.
3.3.12.1. Implementation
Authentication is implemented by an instance of AuthBase.
This instance is supplied directly by the user in the configuration file.
A reference to the instance is available at self.master.www.auth.
3.3.12.2. Username / Password Authentication
In this mode, the Buildbot UI displays a form allowing the user to specify a username and password.
When this form is submitted, the UI makes an AJAX call to /auth/login including HTTP Basic
Authentication headers. The master verifies the contents of the header and updates the server-side
session to indicate a successful login or to contain a failure message. Once the AJAX call is
complete, the UI reloads the page, re-fetching /config.js, which will include the username or
failure message from the session.
Subsequent access is authorized based on the information in the session; the authentication credentials are not sent again.
3.3.12.3. External Authentication
Buildbot’s web service can be run behind an HTTP proxy. Many such proxies can be configured to perform authentication on HTTP connections before forwarding the request to Buildbot. In these cases, the results of the authentication are passed to Buildbot in an HTTP header.
In this mode, authentication proceeds as follows:
The web browser connects to the proxy, requesting the Buildbot home page
The proxy negotiates authentication with the browser, as configured
Once the user is authenticated, the proxy forwards the request and the request goes to the Buildbot web service. The request includes a header, typically
Remote-User, containing the authenticated username.Buildbot reads the header and optionally connects to another service to fetch additional user information about the user.
Buildbot stores all of the collected information in the server-side session.
The UI fetches
/config.js, which includes the user information from the server-side session.
Note that in this mode, the HTTP proxy will send the header with every request, although it is only
interpreted during the fetch of /config.js.
Kerberos Example
Kerberos is an authentication system which allows passwordless authentication on corporate
networks. Users authenticate once on their desktop environment, and the OS, browser, webserver, and
corporate directory cooperate in a secure manner to share the authentication to a webserver. This
mechanism only takes care of the authentication problem, and no user information is shared other
than the username. The kerberos authentication is supported by an Apache front-end in
mod_kerberos.
3.3.12.4. Third-Party Authentication
Third-party authentication involves Buildbot redirecting a user’s browser to another site to establish the user’s identity. Once that is complete, that site redirects the user back to Buildbot, including a cryptographically signed assertion about the user’s identity.
The most common implementation of this sort of authentication is oAuth2. Many big internet service companies are providing oAuth2 services to identify their users. Most oAuth2 services provide authentication and user information in the same API.
The following process is used for third-party authentication:
The web browser connects to the Buildbot UI
A session cookie is created, but the user is not yet authenticated. The UI adds a widget entitled
Login via GitHub(or whatever third party is configured)When the user clicks on the widget, the UI fetches
/auth/login, which returns a bare URL ongithub.com. The UI loads that URL in the browser, with an effect similar to a redirect.GitHub authenticates the user, if necessary, and requests permission for Buildbot to access the user’s information.
On success, the GitHub web page redirects back to Buildbot’s
/auth/login?code=.., with an authentication code.Buildbot uses this code to request more information from GitHub, and stores the results in the server-side session. Finally, Buildbot returns a redirect response, sending the user’s browser to the root of the Buildbot UI. The UI code will fetch
/config.js, which contains the login data from the session.
3.3.12.5. Logout
A “logout” button is available in the simple and third-party modes. Such a button doesn’t make sense for external authentication, since the proxy will immediately re-authenticate the user.
This button fetches /auth/logout, which destroys the server-side session.
After this point, any stored authentication information is gone and the user is logged out.
3.3.12.6. Future Additions
Use the User table in db: This is a very similar to the UserPasswordAuth use cases (form + local db verification). Eventually, this method will require some work on the UI in order to populate the db, add a “register” button, verification email, etc. This has to be done in a ui plugin.
3.3.14. Master-Worker API
This section describes the master-worker interface. It covers the communication protocol of the “classic” remote Worker. Notice there are other types of workers which behave a bit differently, such as Local Worker and Latent Worker.
3.3.14.1. Connection
The interface is based on Twisted’s Perspective Broker, which operates over TCP connections.
The worker connects to the master, using the parameters supplied to buildbot-worker create-worker. It uses a reconnecting process with an exponential backoff, and will automatically reconnect on disconnection.
Once connected, the worker authenticates with the Twisted Cred (newcred) mechanism, using the username and password supplied to buildbot-worker create-worker.
The mind behind the worker is the worker bot instance (class buildbot_worker.pb.BotPb).
On the master side, the realm is implemented by buildbot.pbmanager.Dispatcher, which examines the username of incoming avatar requests.
There are special cases for change and debug, which are not discussed here.
For all other usernames, the botmaster is consulted, and if a worker with that name is configured, its buildbot.worker.Worker instance is returned as the perspective.
3.3.14.2. Workers
At this point, the master-side Worker object has a pointer to the remote
worker-side Bot object in its self.worker, and the worker-side Bot object has
a reference to the master-side Worker object in its self.perspective.
Bot methods
The worker-side Bot object has the following remote methods:
remote_getCommandsReturns a dictionary for all commands the worker recognizes: the key of the dictionary is the command name and the command version is the value.
remote_setBuilderListGiven a list of builders and their build directories, ensures that those builders, and only those builders, are running. This can be called after the initial connection is established, with a new list, to add or remove builders.
This method returns a dictionary of
WorkerForBuilderobjects - see below.remote_printAdds a message to the worker logfile.
remote_getWorkerInfoReturns a dictionary with the contents of the worker’s
info/directory (i.e. file name is used as key and file contents as the value). This dictionary also contains the following keys:environcopy of the workers environment
systemOS the worker is running (extracted from Python’s
os.name)basedirbase directory where the worker is running
numcpusnumber of CPUs on the worker, either as configured or as detected (since
buildbot-workerversion 0.9.0)versionworker’s version (same as the result of
remote_getVersioncall)worker_commandsworker supported commands (same as the result of
remote_getCommandscall)remote_getVersionReturns the worker’s version.
remote_shutdownShuts down the worker cleanly.
Worker methods
The master-side object has the following method:
perspective_keepaliveDoes nothing - used to keep traffic flowing over the TCP connection
3.3.14.3. Setup
After the initial connection and trading of a mind (buildbot_worker.pb.BotPb) for an avatar
(Worker), the master calls the Bot’s setBuilderList method to set
up the proper builders on the worker side. This method returns a
reference to each of the new worker-side WorkerForBuilderPb
objects, described below. Each of these is handed to the corresponding
master-side WorkerForBuilder object.
This immediately calls the remote setMaster method, and then the print method.
3.3.14.4. Pinging
To ping a remote Worker, the master calls its print method.
3.3.14.5. Building
When a build starts, the master calls the worker’s startBuild method.
Each BuildStep instance will subsequently call the startCommand method,
passing a reference to itself as the stepRef parameter. The
startCommand method returns immediately, and the end of the command is
signalled with a call to a method on the master-side BuildStep object.
3.3.14.6. Worker For Builders
Each worker has a set of builders which can run on it. These are represented by distinct classes on the master and worker, just like the Worker and Bot objects described above.
On the worker side, builders are represented as instances of the
buildbot_worker.pb.WorkerForBuilderPb class. On the master side, they are
represented by the buildbot.process.workerforbuilder.WorkerForBuilder class.
The identical names are a source of confusion. The following will refer to
these as the worker-side and master-side Worker For Builder classes. Each object
keeps a reference to its opposite in self.remote.
Worker-Side WorkerForBuilderPb Methods
remote_setMasterProvides a reference to the master-side Worker For Builder
remote_printAdds a message to the worker logfile; used to check round-trip connectivity
remote_startBuildIndicates that a build is about to start, and that any subsequent commands are part of that build
remote_startCommandInvokes a command on the worker side
remote_interruptCommandInterrupts the currently-running command
Master-side WorkerForBuilder Methods
The master side does not have any remotely-callable methods.
3.3.14.7. Commands
The actual work done by the worker is represented on the master side by a
buildbot.process.remotecommand.RemoteCommand instance.
The command instance keeps a reference to the worker-side
buildbot_worker.pb.WorkerForBuilderPb, and calls methods like
remote_startCommand to start new commands.
Once that method is called, the WorkerForBuilderPb instance
keeps a reference to the command, and calls the following methods on it:
Master-Side RemoteCommand Methods
remote_updateUpdate information about the running command. See below for the format.
remote_completeSignal that the command is complete, either successfully or with a Twisted failure.
3.3.14.8. Updates
Updates from the worker, sent via
remote_update, are a list of
individual update elements. Each update element is, in turn, a list of the
form [data, 0], where the 0 is present for historical reasons. The data is
a dictionary, with keys describing the contents. The updates are handled by
remote_update.
Updates with different keys can be combined into a single dictionary or delivered sequentially as list elements, at the worker’s option.
To summarize, an updates parameter to
remote_update might look like
this:
[
[ { 'header' : 'running command..' }, 0 ],
[ { 'stdout' : 'abcd', 'stderr' : 'local modifications' }, 0 ],
[ { 'log' : ( 'cmd.log', 'cmd invoked at 12:33 pm\n' ) }, 0 ],
[ { 'rc' : 0 }, 0 ],
]
Defined Commands
The following commands are defined on the workers.
shell
Runs a shell command on the worker. This command takes the following arguments:
command
The command to run. If this is a string, it will be passed to the system shell as a string. Otherwise, it must be a list, which will be executed directly.
workdir
The directory in which to run the command, relative to the builder dir.
env
A dictionary of environment variables to augment or replace the existing environment on the worker. In this dictionary,
PYTHONPATHis treated specially: it should be a list of path components, rather than a string, and will be prepended to the existing Python path.
initial_stdin
A string which will be written to the command’s standard input before it is closed.
want_stdout
If false, then no updates will be sent for stdout.
want_stderr
If false, then no updates will be sent for stderr.
usePTY
If true, the command should be run with a PTY (POSIX only). This defaults to False.
not_really
If true, skip execution and return an update with rc=0.
timeout
Maximum time without output before the command is killed.
maxTime
Maximum overall time from the start before the command is killed.
max_lines
Maximum overall produced lines by the command, then it is killed.
logfiles
A dictionary specifying logfiles other than stdio. Keys are the logfile names, and values give the workdir-relative filename of the logfile. Alternately, a value can be a dictionary; in this case, the dictionary must have a
filenamekey specifying the filename, and can also have the following keys:
followOnly follow the file from its current end-of-file, rather that starting from the beginning.
logEnviron
If false, the command’s environment will not be logged.
The shell command sends the following updates:
stdout
The data is a bytestring which represents a continuation of the stdout stream. Note that the bytestring boundaries are not necessarily aligned with newlines.
stderr
Similar to
stdout, but for the error stream.
header
Similar to
stdout, but containing data for a stream of Buildbot-specific metadata.
rc
The exit status of the command, where – in keeping with UNIX tradition – 0 indicates success and any nonzero value is considered a failure. No further updates should be sent after an
rc.
failure_reason
Value is a string and describes additional scenarios when a process failed. The value of the
failure_reasonkey can be one of the following:
timeoutif the command timed out due to time specified by themaxTimeparameter being exceeded.
timeout_without_outputif the command timed out due to time specified by thetimeoutparameter being exceeded.
max_lines_failureif the command is killed due to the number of lines specified by themax_linesparameter being exceeded.
log
This update contains data for a logfile other than stdio. The data associated with the update is a tuple of the log name and the data for that log. Note that non-stdio logs do not distinguish output, error, and header streams.
uploadFile
Upload a file from the worker to the master. The arguments are
workdir
Base directory for the filename, relative to the builder’s basedir.
workersrc
Name of the filename to read from, relative to the workdir.
writer
A remote reference to a writer object, described below.
maxsize
Maximum size, in bytes, of the file to write. The operation will fail if the file exceeds this size.
blocksize
The block size with which to transfer the file.
keepstamp
If true, preserve the file modified and accessed times.
The worker calls a few remote methods on the writer object. First, the
write method is called with a bytestring containing data, until all of the
data has been transmitted. Then, the worker calls the writer’s close,
followed (if keepstamp is true) by a call to upload(atime, mtime).
This command sends rc and stderr updates, as defined for the shell
command.
uploadDirectory
Similar to uploadFile, this command will upload an entire directory to the
master, in the form of a tarball. It takes the following arguments:
workdir
workersrc
writer
maxsize
blocksize
See
uploadFilefor these arguments.
compress
Compression algorithm to use – one of
None,'bz2', or'gz'.
The writer object is treated similarly to the uploadFile command, but after
the file is closed, the worker calls the master’s unpack method with no
arguments to extract the tarball.
This command sends rc and stderr updates, as defined for the shell
command.
downloadFile
This command will download a file from the master to the worker. It takes the following arguments:
workdir
Base directory for the destination filename, relative to the builder basedir.
workerdest
Filename to write to, relative to the workdir.
reader
A remote reference to a reader object, described below.
maxsize
Maximum size of the file.
blocksize
The block size with which to transfer the file.
mode
Access mode for the new file.
The reader object’s read(maxsize) method will be called with a maximum
size, which will return no more than that number of bytes as a bytestring. At
EOF, it will return an empty string. Once EOF is received, the worker will call
the remote close method.
This command sends rc and stderr updates, as defined for the shell
command.
mkdir
This command will create a directory on the worker. It will also create any intervening directories required. It takes the following argument:
dir
Directory to create.
The mkdir command produces the same updates as shell.
rmdir
This command will remove a directory or file on the worker. It takes the following arguments:
dir
Directory to remove.
timeout
maxTime
See
shellabove.
The rmdir command produces the same updates as shell.
cpdir
This command will copy a directory from one place to another place on the worker. It takes the following arguments:
fromdir
Source directory for the copy operation, relative to the builder’s basedir.
todir
Destination directory for the copy operation, relative to the builder’s basedir.
timeout
maxTime
See
shellabove.
The cpdir command produces the same updates as shell.
stat
This command returns status information about a file or directory. It takes a
single parameter, file, specifying the filename relative to the builder’s
basedir.
It produces two status updates:
stat
The return value from Python’s
os.stat.
rc
0 if the file is found, otherwise 1.
glob
This command finds all pathnames matching a specified pattern that uses shell-style wildcards.
It takes a single parameter, path, specifying the pattern to pass to Python’s
glob.glob function.
It produces two status updates:
files
The list of matching files returned from
glob.glob
rc
0 if the
glob.globdoes not raise exception, otherwise 1.
listdir
This command reads the directory and returns the list with directory contents. It
takes a single parameter, dir, specifying the directory relative to the builder’s basedir.
It produces two status updates:
files
The list of files in the directory returned from
os.listdir
rc
0 if the
os.listdirdoes not raise exception, otherwise 1.
rmfile
This command removes the file in the worker base directory.
It takes a single parameter, path, specifying the file path relative to the builder’s basedir.
It produces one status update:
rc
0 if the
os.removedoes not raise exception, otherwise the corresponding errno.
3.3.15. Master-Worker connection with MessagePack over WebSocket protocol
Note
This is experimental protocol.
Messages between master and worker are sent using WebSocket protocol in both directions. Data to be sent conceptually is a dictionary and is encoded using MessagePack. One such encoded dictionary corresponds to one WebSocket message.
Authentication happens during opening WebSocket handshake using standard HTTP Basic authentication. Worker credentials are sent in the value of the HTTP “Authorization” header. Master checks if the credentials match and if not - the connection is terminated.
A WebSocket message can be either a request or a response. Request message is sent when one side wants another one to perform an action. Once the action is performed, the other side sends the response message back. A response message is mandatory for every request message.
3.3.15.1. Message key-value pairs
This section describes a general structure of messages. It applies for both master and worker.
Request message
A request message must contain at least these keys: seq_number, op.
Additional key-value pairs may be supplied depending on the request type.
seq_numberValue is an integer.
seq_numbermust be unique for every request message coming from a particular side. The purpose ofseq_numbervalue is to link the request message with response message. Response message will carry the sameseq_numbervalue as in corresponding request message.opValue is a string. It must not be
response. Each side has a predefined set of commands that another side may invoke.opspecifies the command to be invoked by requesting side.
Response message
A response message must contain at least these keys: seq_number, op, result.
seq_numberValue is an integer. It represents a number which was specified in the corresponding request message.
opValue is a string, always a
response.resultValue is
Nonewhen success. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
3.3.15.2. Messages from master to worker
print
Request
This message requests worker to print a message to its log.
seq_numberDescribed in section on Request message structure.
opValue is a string
print.messageValue is a string. It represents the string to be printed in worker’s log.
Response
Worker prints a message from master to its log.
seq_numberDescribed in section on Response message structure.
opValue is a string
response.resultValue is
Noneif log was printed successfully. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
keep-alive
Request
Master sends this message to check if the connection is still working.
seq_numberDescribed in section on Request message structure.
opValue is a string
keepalive.
Response
Response indicates that connection is still working.
seq_numberDescribed in section on Response message structure.
opValue is a string
response.resultValue is
None.
get_worker_info
Request
This message requests worker to collect and send the information about itself back to the master.
Only op and seq_number values are sent, because worker does not need any additional
arguments for this action.
opValue is a string
get_worker_info.seq_numberDescribed in section on Request message structure.
Response
opValue is a string
response.seq_numberDescribed in section on Response message structure.
resultValue is a dictionary that contains data about worker. Otherwise – message of exception.
is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
Key-value pairs in result dictionary represent:
environValue is a dict. It represents environment variables of the worker.
systemValue is a string. It represents a name of the operating system dependent module imported.
basedirValue is a string. It represents a path to build directory.
numcpusValue is an integer. It represents a number of CPUs in the system. If CPUs number for the worker is not detected, number 1 is set.
versionValue is a string. It represents worker version.
worker_commandsValue is a dictionary. Keys of this dictionary represent the commands that worker is able to perform. Values represent the command version.
Additionally, files in Worker ‘basedir/info’ directory are read as key-value pairs. Key is a name of a file and value is the content of a file. As a convention, there are files named ‘admin’ and ‘host’:
adminValue is a string. It specifies information about administrator responsible for this worker.
hostValue is a string. It specifies the name of the host.
set_worker_settings
Request
Master sends this message to set worker settings. The settings must be sent from master before first command.
seq_numberDescribed in section on Request message structure.
opValue is a string
set_worker_settings.argsValue is a dictionary. It represents the settings needed for worker to format command output and buffer messages. The following settings are mandatory:
“buffer_size” - the maximum size of buffer in bytes to fill before sending an update message.
“buffer_timeout” - the maximum time in seconds that data can wait in buffer before update message is sent.
“newline_re” - the pattern in output string, which will be replaced with newline symbol.
“max_line_length” - the maximum size of command output line in bytes.
Response
seq_numberDescribed in section on Response message structure.
opValue is a string
response.resultValue is
Noneif success. Otherwise – message of exception.
start_command
Request
This message requests worker to start a specific command. Master does not have to wait for completion of previous commands before starting a new one, so many different commands may be running in worker simultaneously.
Each start command request message has a unique command_id value.
Worker may be sending request update messages to master which update master about status of
started command. When worker sends a request update message about command, the message takes a
command_id value from corresponding start command request message. Accordingly master can match
update messages to the commands they correspond to. When command execution in worker is completed,
worker sends a request complete message to master with the command_id value of the
completed command. It allows master to track which command exactly was completed.
opValue is a string
start_command.seq_numberDescribed in section Request message structure.
command_idValue is a string value that is unique per worker connection.
command_nameValue is a string. It represents a name of the command to be called.
argsValue is a dictionary. It represents arguments needed to run the command and any additional information about a command.
Arguments of all different commands are explained in section start_command request types.
Response
opValue is a string
response.seq_numberDescribed in section Response message structure.
resultValue is
Nonewhen success. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
interrupt_command
Request
This message requests worker to halt the specified command.
seq_numberDescribed in section Request message
opValue is a string
interrupt_command.command_idValue is a string which identifies the command to interrupt.
whyValue is a string. It represents the reason of interrupting command.
Response
During this command worker may also send back additional update messages to the master. Update messages are explained in section update.
opValue is a string
response.seq_numberDescribed in section Response message
resultValue is
Noneif success. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
shutdown
Request
This message requests worker to shutdown itself.
Action does not require arguments, so only op and seq_number values are sent.
seq_numberDescribed in section Request message
opThe value is a string
shutdown.
Response
Worker returns result: None without waiting for completion of shutdown.
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Noneif success. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
3.3.15.3. Messages from worker to master
update
From the start of a command till its completion, worker may be updating master about the processes
of commands it requested to start. These updates are sent in an update messages.
Request
seq_numberDescribed in section Request message.
opValue is a string
update.argsValue is a list of two-element lists. These two elements in sub-lists represent name-value pairs: first element is the name of update and second is its value. The names and values are further explained in section Contents of the value corresponding to args key in the dictionary of update request message.
command_idValue is a string which identifies command the update refers to.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Nonewhen master successfully acknowledges the update. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
update_upload_file_write
Request
opValue is a string
update_upload_file_write.argsContents of the chunk from the file that worker read.
command_idValue is a string which identifies command the update refers to.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Nonewhen master successfully acknowledges the update. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
update_upload_file_close
By this command worker states that no more data will be transferred.
Request
opValue is a string
update_upload_file_close.command_idValue is a string which identifies command the update refers to.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Nonewhen master successfully acknowledges the update. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
update_upload_file_utime
Request
opValue is a string
update_upload_file_utime.access_timeValue is a floating point number. It is a number of seconds that passed from the start of the Unix epoch (January 1, 1970, 00:00:00 (UTC)) and last access of path.
modified_timeValue is a floating point number. It is a number of seconds that passed from the start of the Unix epoch (January 1, 1970, 00:00:00 (UTC)) and last modification of path.
command_idValue is a string which identifies command the update refers to.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Nonewhen master successfully acknowledges the update. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
update_read_file
Request
opValue is a string
update_read_file.lengthMaximum number of bytes of data to read.
command_idValue is a string which identifies command the update refers to.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is data of length
lengththat master read from its file. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
update_read_file_close
By this command worker states that no more data will be transferred.
Request
opValue is a string
update_read_file_close.command_idValue is a string which identifies command the update refers to.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Nonewhen master successfully acknowledges the update. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
update_upload_directory_write
Request
opValue is a string
update_upload_directory_write.argsContents of the chunk from the directory that worker read.
command_idValue is a string which identifies command the update refers to.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Nonewhen master successfully acknowledges the update. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
update_upload_directory_unpack
By this command worker states that no more data will be transferred.
Request
opValue is a string
update_upload_directory_unpack.command_idValue is a string which identifies command the update refers to.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Nonewhen master successfully acknowledges the update. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
complete
Notifies master that the remote command has finished.
Request
seq_numberDescribed in section Request message
opValue is a string
complete.argsNoneif a command succeeded. A message of error as a string if command failed.command_idValue is a string which identifies command to complete.
Response
opValue is a string
response.seq_numberDescribed in section Response message.
resultValue is
Nonewhen master successfully acknowledges the completion. Otherwise – message of exception.is_exceptionThis key-value pair is optional. If request succeeded this key-value pair is absent. Otherwise, its value is a boolean
Trueand the message of exception is specified in the value ofresult.
3.3.15.4. start_command request types
Request causes worker to start performing an action. There are multiple types of the request each supporting a particular type of worker action. The basic structure of request is the same as explained in section Request message.
Values of command_name and args keys depend on the specific command within the request
message dictionary. command_name is a string which defines command type. args is a
dictionary which defines the arguments and other variables worker needs to perform the command
successfully. Worker starts a program specified in the key command_name and sends updates to
the master about ongoing command.
Command names and their arguments dictionary key-value pairs are explained below.
Command_name: shell
Runs a shell command on the worker.
workdirValue is a string.
workdiris an absolute path and overrides the builder directory. The resulting path represents the worker directory to run the command in.envValue is a dictionary and is optional. It contains key-value pairs that specify environment variables for the environment in which a new command is started.
If the value is of type list, its elements are concatenated to a single string using a platform specific path separator between the elements.
If this dictionary contains “PYTHONPATH” key, path separator and “$PYTHONPATH” is appended to that value.
Resulting environment dictionary sent to the command is created following these rules:
1) If
envhas value for specific key and it isNone, resulting dictionary does not have this key.2) If
envhas value for specific key and it is notNone, resulting dictionary contains this value with substitutions applied.Any matches of a pattern
${name}in this value, where name is any number of alphanumeric characters, are substituted with the value of the same key from worker environment.3) If a specific key from worker environment is not present in
env, resulting dictionary contains that key-value pair from worker environment.want_stdoutValue is a bool and is optional. If value is not specified, the default is
True. If value isTrue, worker sendsupdatelog messages to master from the processstdoutoutput.want_stderrValue is a bool and is optional. If value is not specified, the default is True. If value is
True, worker sendsupdatelog messages to the master from the processstderroutput.logfilesValue is a dictionary and is optional. If the value is not specified, the default is an empty dictionary.
This dictionary specifies logfiles other than stdio.
Keys are the logfile names.
Worker reads this logfile and sends the data with the
updatemessage, where logfile name as a key identifies data of different logfiles.Value is a dictionary. It contains the following keys:
filenameValue is a string. It represents the filename of the logfile, relative to worker directory where the command is run.
followValue is a boolean. If
True- only follow the file from its current end-of-file, rather than starting from the beginning. The default isFalse.
timeoutValue is an integer and is optional. If value is not specified, the default is
None. It represents, how many seconds a worker should wait before killing a process after it gives no output.maxTimeValue is an integer and is optional. If value is not specified, the default is
None. It represents, how many seconds a worker should wait before killing a process. Even if command is still running and giving the output,maxTimevariable sets the maximum time the command is allowed to be performing. IfmaxTimeis set toNone, command runs for as long as it needs unlesstimeoutspecifies otherwise.max_linesValue is an integer and is optional. If value is not specified, the default is
None. It represents, how many produced lines a worker should wait before killing a process. Ifmax_linesis set toNone, command runs for as long as it needs unlesstimeoutormaxTimespecifies otherwise.sigtermTimeValue is an integer and is optional. If value is not specified, the default is
None. It specifies how to abort the process. IfsigtermTimeis notNonewhen aborting the process, worker sends a signal SIGTERM. After sending this signal, worker waits forsigtermTimeseconds of time and if the process is still alive, sends the signal SIGKILL. IfsigtermTimeisNone, worker does not wait and sends signal SIGKILL to the process immediately.usePTYValue is a bool and is optional. If value is not specified, the default is
False.Trueto use a PTY,Falseto not use a PTY.logEnvironValue is a bool and is optional. If value is not specified, the default is
True. IfTrue, worker sends to master anupdatemessage with process environment key-value pairs at the beginning of a process.initial_stdinValue is a string or
None. If notNone, the value is sent to the process as an initial stdin after process is started. If value isNone, no initial stdin is sent.commandValue is a list of strings or a string. It represents the name of a program to be started and its arguments. If this is a string, it will be invoked via
/bin/shshell by calling it as/bin/sh -c <command>. Otherwise, it must be a list, which will be executed directly.If command succeeded, worker sends
rcvalue 0 as anupdatemessageargskey-value pair. It can also send many otherupdatemessages with keys such asheader,stdoutorstderrto inform about command execution. If command failed, it sendsrcvalue with the error number. If command timed out, it sendsfailure_reasonkey. The value of thefailure_reasonkey can be one of the following:timeoutif the command timed out due to time specified by themaxTimeparameter being exceeded.timeout_without_outputif the command timed out due to time specified by thetimeoutparameter being exceeded.max_lines_failureif the command is killed due to the number of lines specified by themax_linesparameter being exceeded.
The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: upload_file
Worker reads the contents of its file and sends them in chunks to write into the file on masters’s side.
pathValue is a string. It specifies the path of the worker file to read from.
maxsizeValue is an integer. Maximum number of bytes to transfer from the worker. The operation will fail if the file exceeds this size. Worker will send messages with data to master until it notices it exceeded
maxsize.blocksizeValue is an integer. Maximum size for each data block to be sent to master.
keepstampValue is a bool. It represents whether to preserve “file modified” and “accessed” times.
Trueis for preserving.Workers sends data to master with one or more
update_upload_file_writemessages. After reading the file is over, worker sendsupdate_upload_file_closemessage. IfkeepstampwasTrue, workers sendsupdate_upload_file_utimemessage. If command succeeded, worker sendsrcvalue 0 as anupdatemessageargskey-value pair. It can also sendupdatemessages with keyheaderorstderrto inform about command execution.If command failed, worker sends
update_upload_file_closemessage and theupdatemessage with dictionaryargskeyrcwith the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: upload_directory
Similar to upload_file.
This command will upload an entire directory to the master, in the form of a tarball.
pathValue is a string. It specifies the path of the worker directory to upload.
maxsizeValue is an integer. Maximum number of bytes to transfer from the worker. The operation will fail if the tarball file exceeds this size. Worker will send messages with data to master until it notices it exceeded
maxsize.blocksizeValue is an integer. Maximum size for each data block to be sent to master.
compressCompression algorithm to use – one of
None, ‘bz2’, or ‘gz’.Worker sends data to the master with one or more
update_upload_directory_writemessages. After reading the directory, worker sendsupdate_upload_directory_unpackwith no arguments to extract the tarball andrcvalue 0 as anupdatemessageargskey-value pair if the command succeeded.Otherwise, worker sends
updatemessage with dictionaryargskeyheaderwith information about the error that occurred and anotherupdatemessage with dictionaryargskeyrcwith the error number.
The basic structure of worker update message is explained in section
Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: download_file
Downloads a file from master to worker.
pathValue is a string. It specifies the path of the worker file to create.
maxsizeValue is an integer. Maximum number of bytes to transfer from the master. The operation will fail if the file exceeds this size. Worker will request data from master until it notices it exceeded
maxsize.blocksizeValue is an integer. It represents maximum size for each data block to be sent from master to worker.
modeValue is
Noneor an integer which represents an access mode for the new file.256 - owner has read permission.
128 - owner has write permission.
64 - owner has execute permission.
32 - group has read permission.
16 - group has write permission.
8 - group has execute permission.
4 - others have read permission.
2 - others have write permission.
1 - others have execute permission.
If
None, file has default permissions.If command succeeded, worker will send
rcvalue 0 as anupdatemessageargskey-value pair.Otherwise, worker sends
updatemessage with dictionaryargskeyheaderwith information about the error that occurred and anotherupdatemessage with dictionaryargskeyrcwith the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: listdir
This command reads the directory and returns the list with directory contents.
pathValue is a string. It specifies the path of a directory to list.
If command succeeded, the list containing the names of the entries in the directory given by that path is sent via
updatemessage inargskeyfiles. Worker will also sendrcvalue 0 as anupdatemessageargskey-value pair. If command failed, worker sendsupdatemessage with dictionaryargskeyheaderwith information about the error that occurred and anotherupdatemessage with dictionaryargskeyrcwith the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: mkdir
This command will create a directory on the worker. It will also create any intervening directories required.
pathsValue is a list of strings. It specifies absolute paths of directories to create.
If command succeeded, worker will send
rcvalue 0 as anupdatemessageargskey-value pair.Otherwise, worker sends
updatemessage with dictionaryargskeyheaderwith information about the error that occurred and anotherupdatemessage with dictionaryargskeyrcwith the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name rmdir
This command will remove directories or files on the worker.
pathsValue is a list of strings. It specifies absolute paths of directories or files to remove.
logEnvironValue is a bool and is optional. If value is not specified, the default is
True. IfTrue, worker sends to master anupdatemessage with process environment key-value pairs at the beginning of a process.timeoutValue is an integer and is optional. If value is not specified, the default is 120s. It represents how many seconds a worker should wait before killing a process when it gives no output.
maxTimeValue is an integer and is optional. If value is not specified, the default is
None. It represents, how many seconds a worker should wait before killing a process. Even if command is still running and giving the output,maxTimevariable sets the maximum time the command is allowed to be performing. IfmaxTimeis set toNone, command runs for as long as it needs unlesstimeoutspecifies otherwise.If command succeeded, worker sends
rcvalue 0 as anupdatemessageargskey-value pair. It can also send manyupdatemessages with keyheader,stdoutorstderrto inform about command execution. If command failed, worker changes the permissions of a directory and tries the removal once again. If that does not help, worker sendsrcvalue with the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: cpdir
This command copies a directory from one place in the worker to another.
from_pathValue is a string. It specifies the absolute path to the source directory for the copy operation.
to_pathValue is a string. It specifies the absolute path to the destination directory for the copy operation.
logEnvironValue is a bool. If
True, worker sends to master anupdatemessage with process environment key-value pairs at the beginning of a process.timeoutValue is an integer. If value is not specified, the default is 120s. It represents, how many seconds a worker should wait before killing a process if it gives no output.
maxTimeValue is an integer and is optional. If value is not specified, the default is
None. It represents, how many seconds a worker should wait before killing a process. Even if command is still running and giving the output,maxTimevariable sets the maximum time the command is allowed to be performing. IfmaxTimeis set toNone, command runs for as long as it needs unlesstimeoutspecifies otherwise.If command succeeded, worker sends
rcvalue 0 as anupdatemessageargskey-value pair. It can also send manyupdatemessages with keyheader,stdoutor`stderr` to inform about command execution. If command failed, it sends ``rcvalue with the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: stat
This command returns status information about workers file or directory.
pathValue is a string. It specifies the path of a file or directory to get the status of.
If command succeeded, status information is sent to the master in an update message, where
args has a key stat with a value of a tuple of these 10 elements:
0 - File mode: file type and file mode bits (permissions) in Unix convention.
1 - Platform dependent, but if non-zero, uniquely identifies the file for a specific device.
2 - Unique ID of disc device where this file resides.
3 - Number of hard links.
4 - ID of the file owner.
5 - Group ID of the file owner.
6 - If the file is a regular file or a symbolic link, size of the file in bytes, otherwise unspecified.
Timestamps depend on the platform:
Unix time or the time of Windows creation, expressed in seconds.
7 - time of last access in seconds.
8 - time of last data modification in seconds.
9 - time of last status change in seconds.
If command succeeded, worker also sends
rcvalue 0 as anupdatemessageargskey-value pair.Otherwise, worker sends
updatemessage with dictionaryargskeyheaderwith information about the error that occurred and anotherupdatemessage with dictionaryargskeyrcwith the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: glob
Worker sends to the master a possibly-empty list of path names that match shell-style path specification.
pathValue is a string. It specifies a shell-style path pattern. Path pattern can contain shell-style wildcards and must represent an absolute path.
If command succeeded, the result is sent to the master in an
updatemessage, whereargshas a keyfilewith the value of that possibly-empty path list. This path list may contain broken symlinks as in the shell. It is not specified whether path list is sorted.Worker also sends
rcvalue 0 as anupdatemessageargskey-value pair.Otherwise, worker sends
updatemessage with dictionaryargskeyheaderwith information about the error that occurred and anotherupdatemessage with dictionaryargskeyrcwith the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
Command_name: rmfile
This command removes the specified file.
pathValue is a string. It specifies a path of a file to delete.
If command succeeded, worker sends
rcvalue 0 as anupdatemessageargskey-value pair.Otherwise, worker sends
updatemessage with dictionaryargskeyheaderwith information about the error that occurred and anotherupdatemessage with dictionaryargskeyrcwith the error number.The basic structure of worker
updatemessage is explained in section Contents of the value corresponding to args key in the dictionary of update request message.
3.3.15.5. Contents of the value corresponding to args key in the dictionary of update request message
The args key-value pair describes information that the request message sends to master. The
value is a list of lists. Each sub-list contains a name-value pair and represents a single update.
First element in a list represents the name of update (see below) and second element represents its
value. Commands may have their own update names so only common ones are described here.
stdoutValue is a standard output of a process as a string. Some of the commands that master requests worker to start, may initiate processes which output a result as a standard output and this result is saved in the value of
stdout. The value satisfies the requirements described in a section below.rcValue is an integer. It represents an exit code of a process. 0 if the process exit was successful. Any other number represents a failure.
failure_reason
Value is a string and describes additional scenarios when a process failed. The value of the
failure_reasonkey can be one of the following:
timeoutif the command timed out due to time specified by themaxTimeparameter being exceeded.
timeout_without_outputif the command timed out due to time specified by thetimeoutparameter being exceeded.
max_lines_failureif the command is killed due to the number of lines specified by themax_linesparameter being exceeded.
headerValue is a string of a header. It represents additional information about how the command worked. For example, information may include the command name and arguments, working directory and environment or various errors or warnings of a process or other information that may be useful for debugging. The value satisfies the requirements described in a section below.
filesValue is a list of strings.
1) If the
updatemessage was a response to master request messagestart_commandwith a key value paircommand_nameandglob, then strings in this list represent path names that matched pathname given by the master.2) If the
updatemessage was a response to master request messagestart_commandwith a key value paircommand_nameandlistdir, then strings in this list represent the names of the entries in the directory given by path, which master sent as an argument.stderrValue is a standard error of a process as a string. Some of the commands that master requests worker to start may initiate processes which can output a result as a standard error and this result is saved in the value of
stderr. The value satisfies the requirements described in a section below.logValue is a list where the first element represents the name of the log and the second element is a list, representing the contents of the file. The composition of this second element is described in the section below. This message is used to transfer the contents of the file that master requested worker to read. This file is identified by the name of the log. The same value is sent by master as the key of dictionary represented by
logfilekey withinargsdictionary ofStartCommandcommand.elapsedValue is an integer. It represents how much time has passed between the start of a command and the completion in seconds.
Requirements for content lists of stdout, stderr, header and log
The lists that represents the contents of the output or a file consist of three elements.
First element is a string with the content, which must be processed using the following algorithm:
- Each value may contain one or more lines (characters with a terminating
\ncharacter). Each line is not longer than internal
maxsizevalue on worker side. Longer lines are split into multiple lines where each except the last line contains exactlymaxsizecharacters and the last line may contain less.
- Each value may contain one or more lines (characters with a terminating
The lines are run through an internal worker cleanup regex.
Second element is a list of indexes, representing the positions of newline characters in the string of first tuple element.
Third element is a list of numbers, representing at what time each line was received as an output while processing the command.
The number of elements in both lists is always the same.
3.3.16. Claiming Build Requests
At Buildbot’s core, there exists a distributed job (build) scheduling engine. Future builds are represented by build requests, which are created by schedulers.
When a new build request is created, it is added to the buildrequests table and an appropriate message is sent.
3.3.16.1. Distributing
Each master distributes build requests among its builders by examining the list of available build requests and workers, and accounting for user configuration on build request priorities, worker priorities, and so on. This distribution process is re-run whenever an event occurs that may allow a new build to start.
Such events can be signalled to master with:
maybeStartBuildsForBuilderwhen a single builder is affected;maybeStartBuildsForWorkerwhen a single worker is affected; ormaybeStartBuildsForAllBuilderswhen all builders may be affected.
In particular, when a master receives a new buildrequests message, it performs the equivalent of
maybeStartBuildsForBuilder for the affected
builder.
3.3.16.2. Claiming
If circumstances are right for a master to begin a build, then it attempts to “claim” the build
request. In fact, if several build requests were merged, it attempts to claim them as a group,
using the claimBuildRequests DB
method. This method uses transactions and an insert into the buildrequest_claims table to
ensure that exactly one master succeeds in claiming any particular build request.
If the claim fails, then another master has claimed the affected build requests, and the attempt is abandoned.
If the claim succeeds, then the master sends a message indicating that it has claimed the request. This message can be used by other masters to abandon their attempts to claim this request, although this is not yet implemented.
If the build request is later abandoned (as can happen if, for example, the worker has disappeared), then master will send a message indicating that the request is again unclaimed; like a new buildrequests message, this message indicates that other masters should try to distribute it once again.
3.3.16.3. The One That Got Away
The claiming process is complex, and things can go wrong at just about any point. Through master failures or message/database race conditions, it’s quite possible for a build request to be “missed”, even when resources are available to process it.
To account for this possibility, masters periodically poll the buildrequests table for
unclaimed requests and try to distribute them. This resiliency avoids “lost” build requests, at the
small cost of a polling delay before the requests are scheduled.
3.3.17. String Encodings
Buildbot expects all strings used internally to be valid Unicode strings - not bytestrings.
Note that Buildbot rarely feeds strings back into external tools in such a way that those strings must match. For example, Buildbot does not attempt to access the filenames specified in a Change. So it is more important to store strings in a manner that will be most useful to a human reader (e.g., in logfiles, web status, etc.) than to store them in a lossless format.
3.3.17.1. Inputs
On input, strings should be decoded, if their encoding is known. Where
necessary, the assumed input encoding should be configurable. In some cases,
such as filenames, this encoding is not known or not well-defined (e.g., a
utf-8 encoded filename in a latin-1 directory). In these cases, the input
mechanisms should make a best effort at decoding, and use e.g., the
errors='replace' option to fail gracefully on un-decodable characters.
3.3.17.2. Outputs
At most points where Buildbot outputs a string, the target encoding is known.
For example, the web status can encode to utf-8. In cases where it is not
known, it should be configurable, with a safe fallback (e.g., ascii with
errors='replace'. For HTML/XML outputs, consider using
errors='xmlcharrefreplace' instead.
3.3.18. Metrics
New in Buildbot 0.8.4 is support for tracking various performance metrics inside the buildbot
master process. Currently, these are logged periodically according to the log_interval
configuration setting of the metrics configuration.
The metrics subsystem is implemented in buildbot.process.metrics. It makes use of twisted’s
logging system to pass metrics data from all over Buildbot’s code to a central
MetricsLogObserver object, which is available at BuildMaster.metrics or via
Status.getMetrics().
3.3.18.1. Metric Events
MetricEvent objects represent individual items to monitor.
There are three sub-classes implemented:
MetricCountEventRecords incremental increase or decrease of some value, or an absolute measure of some value.
from buildbot.process.metrics import MetricCountEvent # We got a new widget! MetricCountEvent.log('num_widgets', 1) # We have exactly 10 widgets MetricCountEvent.log('num_widgets', 10, absolute=True)
MetricTimeEventMeasures how long things take. By default the average of the last 10 times will be reported.
from buildbot.process.metrics import MetricTimeEvent # function took 0.001s MetricTimeEvent.log('time_function', 0.001)
MetricAlarmEventIndicates the health of various metrics.
from buildbot.process.metrics import MetricAlarmEvent, ALARM_OK # num_workers looks ok MetricAlarmEvent.log('num_workers', level=ALARM_OK)
3.3.18.2. Metric Handlers
MetricsHandler objects are responsible for collecting MetricEvents of a specific
type and keeping track of their values for future reporting. There are MetricsHandler
classes corresponding to each of the MetricEvent types.
3.3.18.3. Metric Watchers
Watcher objects can be added to MetricsHandlers to be called when metric events of a
certain type are received. Watchers are generally used to record alarm events in response to count
or time events.
3.3.18.4. Metric Helpers
countMethod(name)A function decorator that counts how many times the function is called.
from buildbot.process.metrics import countMethod @countMethod('foo_called') def foo(): return "foo!"
Timer(name)Timerobjects can be used to make timing events easier. WhenTimer.stop()is called, aMetricTimeEventis logged with the elapsed time sincetimer.start()was called.from buildbot.process.metrics import Timer def foo(): t = Timer('time_foo') t.start() try: for i in range(1000): calc(i) return "foo!" finally: t.stop()
Timerobjects also provide a pair of decorators,startTimer/stopTimerto decorate other functions.from buildbot.process.metrics import Timer t = Timer('time_thing') @t.startTimer def foo(): return "foo!" @t.stopTimer def bar(): return "bar!" foo() bar()
timeMethod(name)A function decorator that measures how long a function takes to execute. Note that many functions in Buildbot return deferreds, so may return before all the work they set up has completed. Using an explicit
Timeris better in this case.from buildbot.process.metrics import timeMethod @timeMethod('time_foo') def foo(): for i in range(1000): calc(i) return "foo!"
3.3.19. Secrets
A Secret is defined by a key associated with a value, returned from a provider.
Secrets returned by providers are stored in a SecretDetails object.
A SecretDetails object is initialized with a provider name, a key and a value.
Each parameter is an object property.
secret = SecretDetails("SourceProvider", "myKey", "myValue")
print(secret.source)
"SourceProvider"
print(secret.key)
"myKey"
print(secret.value)
"myValue"
3.3.20. Secrets manager
The secrets manager is a Buildbot service manager.
secretsService = self.master.namedServices['secrets']
secretDetailsList = secretsService.get(self.secrets)
The service executes a get method.
Depending on the kind of storage chosen and declared in the configuration, the manager gets the selected provider and returns a list of secretDetails.
3.3.21. Secrets providers
The secrets providers are implementing the specific getters, related to the storage chosen.
3.3.21.1. File provider
c['secretsProviders'] = [secrets.SecretInAFile(dirname="/path/toSecretsFiles")]
In the master configuration the provider is instantiated through a Buildbot service secret manager with the file directory path. File secrets provider reads the file named by the key wanted by Buildbot and returns the contained text value (removing trailing newlines if present). SecretInAFile provider allows Buildbot to read secrets in the secret directory.
3.3.21.2. Vault provider
c['secretsProviders'] = [secrets.HashiCorpVaultKvSecretProvider(authenticator=secrets.VaultAuthenticatorApprole(roleId="xxx", secretId="yyy"),
vault_server="http://localhost:8200")]
In the master configuration, the provider is instantiated through a Buildbot service secret manager with the Vault authenticator and the Vault server address. Vault secrets provider accesses the Vault backend asking the key wanted by Buildbot and returns the contained text value. SecretInVaultKv provider allows Buildbot to read secrets only in the Vault KV store, other secret engines are not supported by this provider. Currently v1 and v2 of the Key-Value secret engines are supported, v2 being the default version.
3.3.21.3. Interpolate secret
text = Interpolate("some text and %(secret:foo)s")
Secret keys are replaced in a string by the secret value using the class Interpolate and the keyword secret. The secret is searched across the providers defined in the master configuration.
3.3.21.4. Secret Obfuscation
text = Interpolate("some text and %(secret:foo)s")
# some text rendered
rendered = yield self.build.render(text)
cleantext = self.build.properties.cleanupTextFromSecrets(rendered)
Secrets don’t have to be visible to the normal user via logs and thus are transmitted directly to the workers.
Secrets are rendered and can arrive anywhere in the logs.
The function cleanupTextFromSecrets defined in the class Properties helps to replace the secret value by the key value.
print("the example value is:%s" % (cleantext))
>> the example value is: <foo>
The secret is rendered and is recorded in a dictionary, named _used_secrets, where the key is the secret value and the value the secret key.
Therefore anywhere logs are written having content with secrets, the secrets are replaced by the value from _used_secrets.
3.3.21.5. How to use a secret in a BuildbotService
Service configurations are loaded during a Buildbot start or modified during a Buildbot restart. Secrets are used like renderables in a service and are rendered during the configuration load.
class MyService(BuildbotService):
secrets = ['foo', 'other']
secrets is a list containing all the secret keys that can be used as class attributes.
When the service is loaded during the Buildbot reconfigService function, secrets are rendered and the values are updated.
Everywhere the variable with the secret name (foo or other in the example) is used, the class attribute value is replaced by the secret value.
This is similar to the “renderable” annotation, but will only work for BuildbotServices, and will only interpolate secrets.
Other renderables can still be held in the service as attributes and rendered dynamically at a later time.
class MyService(object): secrets = ['foo', 'other'] myService = MyService()
After a Buildbot reconfigService:
print("myService returns secret value:", myService.foo)) >> myService returns secret value bar
3.3.22. Statistics Service
The statistics service (or stats service) is implemented in buildbot.statistics.stats_service.
Please see stats-service for more information.
Here is a diagram demonstrating the workings of the stats service:
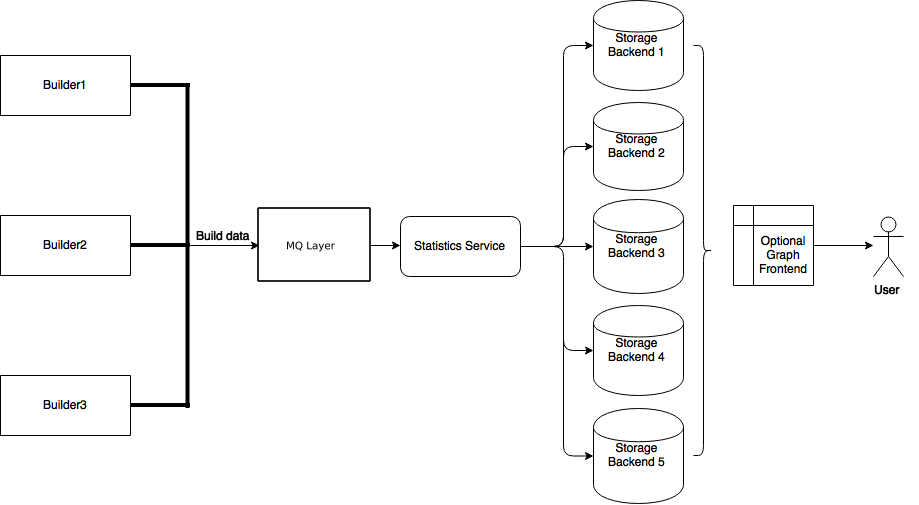
3.3.22.1. Stats Service
- class buildbot.statistics.stats_service.StatsService
An instance of this class functions as a
BuildbotService. The instance of the running service is initialized in the master configuration file (seestats-servicefor more information). The running service is accessible everywhere in Buildbot via theBuildMaster. The service is available atself.master.namedServices['<service-name>']. It takes the following initialization arguments:storage_backendsA list of storage backends. These are instance of subclasses of
StatsStorageBase.name(str) The name of this service. This name can be used to access the running instance of this service using
self.master.namedServices[name].
Please see
stats-servicefor examples.- checkConfig(self, storage_backends)
storage_backendsA list of storage backends.
This method is called automatically to verify that the list of storage backends contains instances of subclasses of
StatsStorageBase.
- reconfigService(self, storage_backends)
storage_backendsA list of storage backends.
This method is called automatically to reconfigure the running service.
- registerConsumers(self)
Internal method for this class called to register all consumers (methods from Capture classes) to the MQ layer.
- stopService(self)
Internal method for this class to stop the stats service and clean up.
- removeConsumers(self)
Internal method for this class to stop and remove consumers from the MQ layer.
- yieldMetricsValue(self, data_name, post_data, buildid)
data_name(str) The name of the data being sent for storage.
post_dataA dictionary of key-value pairs that is sent for storage.
buildidThe integer build id of the current build. Obtainable in all
BuildSteps.
This method should be called to post data that is not generated and stored as build-data in the database. This method generates the
stats-yield-dataevent to the mq layer which is then consumed inpostData.
3.3.22.2. Storage backends
Storage backends are responsible for storing any statistics/data sent to them. A storage backend will generally be some sort of a database-server running on a machine.
Note
This machine may be different from the one running BuildMaster.
Data is captured according to the master config file and then is sent to each of the storage backends provided by the master configuration (see stats-service).
Each storage backend has a Python client defined as part of buildbot.statistics.storage_backends to aid in posting data by StatsService.
Currently, only InfluxDB is supported as a storage backend.
- class buildbot.statistis.storage_backends.base.StatsStorageBase
An abstract class for all storage services. It cannot be directly initialized - it would raise a
TypeErrorotherwise.- thd_postStatsValue(self, post_data, series_name, context)
post_dataA dict of key-value pairs that is sent for storage. The keys of this dict can be thought of as columns in a database and the value is the data stored for that column.
series_name(str) The name of the time-series for this statistic.
context(Optional) Any other contextual information about the data. It is a dict of key-value pairs.
An abstract method that needs to be implemented by every child class of this class. Not doing so will result in a
TypeErrorwhen starting Buildbot.
- class buildbot.statistics.storage_backends.influxdb_client.InfluxStorageService
InfluxDB is a distributed time series database that employs a key-value pair storage system.
This class is a Buildbot client to the InfluxDB storage backend. It is available in the configuration as
statistics.InfluxStorageService. It takes the following initialization arguments:url(str) The URL where the service is running.
port(int) The port on which the service is listening.
user(str) Username of an InfluxDB user.
password(str) Password for
user.db(str) The name of database to be used.
capturesA list of instances of subclasses of
Capture. This tells which stats are to be stored in this storage backend.name=None(Optional) (str) The name of this storage backend.
- thd_postStatsValue(self, post_data, series_name, context={})
post_dataA dict of key-value pairs that is sent for storage. The keys of this dict can be thought of as columns in a database and the value is the data stored for that column.
series_name(str) The name of the time-series for this statistic.
context(Optional) Any other contextual information about the data. It is a dict of key-value pairs.
This method constructs a dictionary of data to be sent to InfluxDB in the proper format and then sends the data to the InfluxDB instance.
3.3.22.3. Capture Classes
Capture classes are used for declaring which data needs to captured and sent to storage backends for storage.
- class buildbot.statistics.capture.Capture
This is the abstract base class for all capture classes. Not to be used directly. It’s initialized with the following parameters:
- routingKey
(tuple) The routing key to be used by
StatsServiceto register consumers to the MQ layer for the subclass of this class.
- callback
The callback registered with the MQ layer for the consumer of a subclass of this class. Each subclass must provide a default callback for this purpose.
- _defaultContext(self, msg)
A method for providing default context to the storage backends.
- consume(self, routingKey, msg)
This is an abstract method - each subclass of this class should implement its own consume method. If not, then the subclass can’t be instantiated. The consume method, when called (from the mq layer), receives the following arguments:
- routingKey
The routing key which was registered to the MQ layer. Same as the
routingKeyprovided to instantiate this class.
- msg
The message that was sent by the producer.
- _store(self, post_data, series_name, context)
This is an abstract method of this class. It must be implemented by all subclasses of this class. It takes the following arguments:
- post_data
(dict) The key-value pair being sent to the storage backend.
- series_name
(str) The name of the series to which this data is stored.
- context
(dict) Any additional information pertaining to the data being sent.
- class buildbot.statistics.capture.CapturePropertyBase
This is a base class for both
CapturePropertyandCapturePropertyAllBuildersand abstracts away much of the common functionality between the two classes. It cannot be initialized directly as it contains an abstract method and raisesTypeErrorif tried. It is initialized with the following arguments:- property_name
(str) The name of property needed to be recorded as a statistic. This can be a regular expression if
regex=True(see below).
- callback=None
The callback function that is used by
CaptureProperty.consumerto post-process data before formatting it and sending it to the appropriate storage backends. A default callback is provided for this:
- regex=False
If this is set to
True, then the property name can be a regular expression. All properties matching this regular expression will be sent for storage.
- consume(self, routingKey, msg)
The consumer for all CaptureProperty classes described below. This method filters out the correct properties as per the configuration file and sends those properties for storage. The subclasses of this method do not need to implement this method as it takes care of all the functionality itself. See
Capturefor more information.
- _builder_name_matches(self, builder_info)
This is an abstract method and needs to be implemented by all subclasses of this class. This is a helper method to the
consumemethod mentioned above. It checks whether a builder is allowed to send properties to the storage backend according to the configuration file. It takes one argument:- builder_info
(dict) The dictionary returned by the data API containing the builder information.
- class buildbot.statistics.capture.CaptureProperty
The capture class for capturing build properties. It is available in the configuration as
statistics.CaptureProperty.It takes the following arguments:
- builder_name
(str) The name of builder in which the property is recorded.
- property_name
(str) The name of property needed to be recorded as a statistic.
- callback=None
The callback function that is used by
CaptureProperty.consumerto post-process data before formatting it and sending it to the appropriate storage backends. A default callback is provided for this (seeCapturePropertyBasefor more information).
- regex=False
If this is set to
True, then the property name can be a regular expression. All properties matching this regular expression will be sent for storage.
- _builder_name_matches(self, builder_info)
See
CapturePropertyBasefor more information on this method.
- class buildbot.statistics.capture.CapturePropertyAllBuilders
The capture class to use for capturing build properties on all builders. It is available in the configuration as
statistics.CapturePropertyAllBuilders.It takes the following arguments:
- property_name
(str) The name of property needed to be recorded as a statistic.
- callback=None
The callback function that is used by
CaptureProperty.consumerto post-process data before formatting it and sending it to the appropriate storage backends. A default callback is provided for this (seeCapturePropertyBasefor more information).
- regex=False
If this is set to
True, then the property name can be a regular expression. All properties matching this regular expression will be sent for storage.
- _builder_name_matches(self, builder_info)
See
CapturePropertyBasefor more information on this method.
- class buildbot.statistics.capture.CaptureBuildTimes
A base class for all Capture classes that deal with build times (start/end/duration). Not to be used directly. It’s initialized with:
- builder_name
(str) The name of builder whose times are to be recorded.
- callback
The callback function that is used by a subclass of this class to post-process data before formatting it and sending it to the appropriate storage backends. A default callback is provided for this. Each subclass must provide a default callback that is used in initialization of this class should the user not provide a callback.
- consume(self, routingKey, msg)
The consumer for all subclasses of this class. See
Capturefor more information.
- _retValParams(self, msg)
This is an abstract method which needs to be implemented by subclasses. This method needs to return a list of parameters that will be passed to the
callbackfunction. See individual buildCaptureBuild*classes for more information.
- _err_msg(self, build_data, builder_name)
A helper method that returns an error message for the
consumemethod.
- _builder_name_matches(self, builder_info)
This is an abstract method and needs to be implemented by all subclasses of this class. This is a helper method to the
consumemethod mentioned above. It checks whether a builder is allowed to send build times to the storage backend according to the configuration file. It takes one argument:- builder_info
(dict) The dictionary returned by the data API containing the builder information.
- class buildbot.statistics.capture.CaptureBuildStartTime
A capture class for capturing build start times. It takes the following arguments:
- builder_name
(str) The name of builder whose times are to be recorded.
- callback=None
The callback function for this class. See
CaptureBuildTimesfor more information.The default callback:
- _retValParams(self, msg)
Returns a list containing one Python datetime object (start time) from
msgdictionary.
- _builder_name_matches(self, builder_info)
See
CaptureBuildTimesfor more information on this method.
- class buildbot.statistics.capture.CaptureBuildStartTimeAllBuilders
A capture class for capturing build start times from all builders. It is a subclass of
CaptureBuildStartTime. It takes the following arguments:- callback=None
The callback function for this class. See
CaptureBuildTimesfor more information.The default callback:
See
CaptureBuildStartTime.__init__for the definition.
- _builder_name_matches(self, builder_info)
See
CaptureBuildTimesfor more information on this method.
- class buildbot.statistics.capture.CaptureBuildEndTime
A capture class for capturing build end times. Takes the following arguments:
- builder_name
(str) The name of builder whose times are to be recorded.
- callback=None
The callback function for this class. See
CaptureBuildTimesfor more information.The default callback:
- _retValParams(self, msg)
Returns a list containing two Python datetime object (start time and end time) from
msgdictionary.
- _builder_name_matches(self, builder_info)
See
CaptureBuildTimesfor more information on this method.
- class buildbot.statistics.capture.CaptureBuildEndTimeAllBuilders
A capture class for capturing build end times from all builders. It is a subclass of
CaptureBuildEndTime. It takes the following arguments:- callback=None
The callback function for this class. See
CaptureBuildTimesfor more information.The default callback:
See
CaptureBuildEndTime.__init__for the definition.
- _builder_name_matches(self, builder_info)
See
CaptureBuildTimesfor more information on this method.
- class buildbot.statistics.capture.CaptureBuildDuration
A capture class for capturing build duration. Takes the following arguments:
- builder_name
(str) The name of builder whose times are to be recorded.
- report_in='seconds'
Can be one of three:
'seconds','minutes', or'hours'. This is the units in which the build time will be reported.
- callback=None
The callback function for this class. See
CaptureBuildTimesfor more information.The default callback:
- default_callback(start_time, end_time)
It returns the duration of the build as per the
report_inargument. It receives the following arguments:
- _retValParams(self, msg)
Returns a list containing one Python datetime object (end time) from
msgdictionary.
- _builder_name_matches(self, builder_info)
See
CaptureBuildTimesfor more information on this method.
- class buildbot.statistics.capture.CaptureBuildDurationAllBuilders
A capture class for capturing build durations from all builders. It is a subclass of
CaptureBuildDuration. It takes the following arguments:- callback=None
The callback function for this class. See
CaptureBuildTimesfor more.The default callback:
See
CaptureBuildDuration.__init__for the definition.
- _builder_name_matches(self, builder_info)
See
CaptureBuildTimesfor more information on this method.
- class buildbot.statistics.capture.CaptureDataBase
This is a base class for both
CaptureDataandCaptureDataAllBuildersand abstracts away much of the common functionality between the two classes. Cannot be initialized directly as it contains an abstract method and raisesTypeErrorif tried. It is initialized with the following arguments:- data_name
(str) The name of data to be captured. Same as in
yieldMetricsValue.
- callback=None
The callback function for this class.
The default callback:
The default callback takes a value
xand return it without changing. As such,xitself acts as thepost_datasent to the storage backends.
- consume(self, routingKey, msg)
The consumer for this class. See
Capturefor more.
- _builder_name_matches(self, builder_info)
This is an abstract method and needs to be implemented by all subclasses of this class. This is a helper method to the
consumemethod mentioned above. It checks whether a builder is allowed to send properties to the storage backend according to the configuration file. It takes one argument:- builder_info
(dict) The dictionary returned by the data API containing the builder information.
- class buildbot.statistics.capture.CaptureData
A capture class for capturing arbitrary data that is not stored as build-data. See
yieldMetricsValuefor more. Takes the following arguments for initialization:- data_name
(str) The name of data to be captured. Same as in
yieldMetricsValue.
- builder_name
(str) The name of the builder on which the data is captured.
- callback=None
The callback function for this class.
The default callback:
See
CaptureDataBaseof definition.
- _builder_name_matches(self, builder_info)
See
CaptureDataBasefor more information on this method.
- class buildbot.statistics.capture.CaptureDataAllBuilders
A capture class to capture arbitrary data on all builders. See
yieldMetricsValuefor more. It takes the following arguments:- data_name
(str) The name of data to be captured. Same as in
yieldMetricsValue.
- callback=None
The callback function for this class.
- _builder_name_matches(self, builder_info)
See
CaptureDataBasefor more information on this method.
3.3.23. How to package Buildbot plugins
If you customized an existing component (see Customization) or created a new component that you believe might be useful for others, you have two options:
submit the change to the Buildbot main tree, however you need to adhere to certain requirements (see Buildbot Coding Style)
prepare a Python package that contains the functionality you created
Here we cover the second option.
3.3.23.1. Package the source
To begin with, you must package your changes. If you do not know what a Python package is, these two tutorials will get you going:
The former is more recent and, while it addresses everything that you need to know about Python packages, it’s still work in progress. The latter is a bit dated, though it was the most complete guide for quite some time available for Python developers looking to package their software.
You may also want to check the sample project, which exemplifies the best Python packaging practices.
3.3.23.2. Making the plugin package
Buildbot supports several kinds of pluggable components:
workerchangesschedulersstepsreportersutil
(these are described in Plugin Infrastructure in Buildbot), and
www
which is described in web server configuration.
Once you have your component packaged, it’s quite straightforward: you just need to add a few lines to the entry_points parameter of your call of setup function in setup.py file:
setup(
...
entry_points = {
...,
'buildbot.{kind}': [
'PluginName = PluginModule:PluginClass'
]
},
...
)
(You might have seen different ways to specify the value for entry_points, however they all do the same thing.
Full description of possible ways is available in setuptools documentation.)
After the setup.py file is updated, you can build and install it:
$ python setup.py build
$ sudo python setup.py install
(depending on your particular setup, you might not need to use sudo).
After that, the plugin should be available for Buildbot and you can use it in your master.cfg as:
from buildbot.plugins import {kind}
... {kind}.PluginName ...
3.3.23.3. Publish the package
This is the last step before the plugin becomes available to others.
Once again, there is a number of options available for you:
just put a link to your version control system
prepare a source tarball with the plugin (
python setup.py sdist)or publish it on PyPI
The last option is probably the best one since it will make your plugin available pretty much to all Python developers.
Once you have published the package, please send a link to buildbot-devel mailing list, so we can include a link to your plugin to Plugin Infrastructure in Buildbot.
3.4. REST API
The REST API is a public interface which can be used by external code to control Buildbot. Internally, the REST API is a thin wrapper around the data API’s “Getter” and “Control” sections. It is also designed, in keeping with REST principles, to be discoverable. As such, the details of the paths and resources are not documented here. Begin at the root URL, and see the Data API documentation for more information.
The precise specifications in RAML format are described in REST API Specification documentation.
3.4.1. Versions
The API described here is version 2. The ad-hoc API from Buildbot-0.8.x, version 1, is no longer supported [1].
The policy for incrementing the version is when there is an incompatible change added. Removing a field or endpoint is considered incompatible change. Adding a field or endpoint is not considered incompatible, and thus will only be described as a change in release notes. The policy is that we will avoid as much as possible incrementing the version.
3.4.2. Getting
To get data, issue a GET request to the appropriate path. For example, with a base URL of
http://build.example.org/buildbot, the list of masters for builder 9 is available at
http://build.example.org/buildbot/api/v2/builders/9/masters.
- resource type: collection
3.4.3. Collections
Results are formatted in keeping with the JSON API specification. The top level of every response is an object. Its keys are the plural names of the resource types, and the values are lists of objects, even for a single-resource request. For example:
{
"meta": {
"total": 2
},
"schedulers": [
{
"master": null,
"name": "smoketest",
"schedulerid": 1
},
{
"master": {
"active": true,
"last_active": 1369604067,
"link": "http://build.example.org/api/v2/master/1",
"masterid": 1,
"name": "master3:/BB/master"
},
"name": "goaheadtryme",
"schedulerid": 2
}
]
}
A response may optionally contain extra, related resources beyond those requested. The meta key
contains metadata about the response, including the total count of resources in a collection.
Several query parameters may be used to affect the results of a request. These parameters are applied in the order described (so, it is not possible to sort on a field that is not selected, for example).
3.4.3.1. Field Selection
If only certain fields of each resource are required, the field query parameter can be used to
select them. For example, the following will select just the names and id’s of all schedulers:
http://build.example.org/api/v2/scheduler?field=name&field=schedulerid
Field selection can be used for either detail (single-entity) or collection (multi-entity) requests. The remaining options only apply to collection requests.
3.4.3.2. Filtering
Collection responses may be filtered on any simple top-level field.
To select records with a specific value use the query parameter {field}={value}.
For example, http://build.example.org/api/v2/scheduler?name=smoketest selects the scheduler named “smoketest”.
Filters can use any of the operators listed below, with query parameters of the form {field}__{operator}={value}.
eqequality, with the same parameter appearing one or multiple times, is equality with one of the given values (so foo__eq=x&foo__eq=y would match resources where foo is x or y)
neinequality, or set exclusion
ltselect resources where the field’s value is less than
{value}leselect resources where the field’s value is less than or equal to
{value}gtselect resources where the field’s value is greater than
{value}geselect resources where the field’s value is greater than or equal to
{value}containsSelect resources where the field’s value contains
{value}. If the parameter is provided multiple times, results containing at least one of the values are returned (so foo__contains=x&foo__contains=y would match resources where foo contains x, y or both).
For example:
http://build.example.org/api/v2/builder?name__lt=cccchttp://build.example.org/api/v2/buildsets?complete__eq=false
Boolean values can be given as on/off, true/false, yes/no, or 1/0.
3.4.3.3. Sorting
Collection responses may be ordered with the order query parameter. This parameter takes a
field name to sort on, optionally prefixed with - to reverse the sort. The parameter can appear
multiple times, and will be sorted lexicographically with the fields arranged in the given order.
For example:
http://build.example.org/api/v2/buildrequests?order=builderid&order=buildrequestid
3.4.3.4. Pagination
Collection responses may be paginated with the offset and limit query parameters. The
offset is the 0-based index of the first result to include, after filtering and sorting. The limit
is the maximum number of results to return. Some resource types may impose a maximum on the limit
parameter; be sure to check the resulting links to determine whether further data is available. For
example:
http://build.example.org/api/v2/buildrequests?order=builderid&limit=10http://build.example.org/api/v2/buildrequests?order=builderid&offset=20&limit=10
3.4.4. Controlling
Data API control operations are handled by POST requests using a simplified form of JSONRPC 2.0. The JSONRPC “method” is mapped to the data API “action”, and the parameters are passed to that application.
The following parts of the protocol are not supported:
positional parameters
batch requests
Requests are sent as an HTTP POST, containing the request JSON in the body.
The content-type header must be application/json.
A simple example:
POST http://build.example.org/api/v2/scheduler/4
--> {"jsonrpc": "2.0", "method": "force",
"params": {"revision": "abcd", "branch": "dev"},
"id": 843}
<-- {"jsonrpc": "2.0", "result": {"buildsetid": 44}, "id": 843}
3.4.5. Authentication
Authentication to the REST API is performed in the same manner as authentication to the main web interface. Once credentials have been established, a cookie will be set, which must be sent to the Buildbot REST API with every request thereafter.
import requests
s = requests.Session()
s.get("https://<buildbot_url>/auth/login", auth=('user', 'passwd'))
builders = s.get("https://<buildbot_url>/api/v2/builders").json()
For those Buildbot instances using OAuth2 authentication providers, it is at the moment not possible to access the authenticated API .
3.5. REST API Specification
This section documents the available REST APIs according to the RAML specification.
3.5.1. builder
- resource type: builder
- Attributes:
builderid (integer) – the ID of this builder
description? (string) – The description for that builder
masterids[] (integer) – the ID of the masters this builder is running on
name (string) – builder name
tags[] (string) – list of tags for this builder
projectid? (string) – the ID of the project that this builder is associated with, if any
This resource type describes a builder.
3.5.1.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.builders.Builder
- updateBuilderList(masterid, builderNames)
- Parameters:
masterid (integer) – this master’s master ID
builderNames (list) – list of names of currently-configured builders (unicode strings)
- Returns:
Deferred
Record the given builders as the currently-configured set of builders on this master. Masters should call this every time the list of configured builders changes.
3.5.1.2. Endpoints
- path: /builders
This path selects all builders
GETreturns
- path: /builders/{builderid_or_buildername}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
This path selects a builder by builderid
GETreturns
- path: /masters/{masterid}/builders
- Path Keys:
masterid (number) – the id of the master
This path selects all builders of a given master
GETreturns
- path: /masters/{masterid}/builders/{builderid}
- Path Keys:
masterid (number) – the id of the master
builderid (number) – the id of the builder
This path selects one builder by id of a given master
GETreturns
- path: /projects/{projectid_or_projectname}/builders
- Path Keys:
projectid_or_projectname (number|identifier) – the ID or name of the project
This path selects all builders for a project
GETreturns
3.5.2. buildrequest
- resource type: buildrequest
- Attributes:
buildrequestid (integer) – the unique ID of this buildrequest
builderid (integer) – the id of the builder linked to this buildrequest
buildsetid (integer) – the id of the buildset that contains this buildrequest
claimed (boolean) – True if this buildrequest has been claimed. Note that this is a calculated field (from claimed_at != None). Ordering by this field is not optimized by the database layer.
claimed_at? (date) – time at which this build has last been claimed. None if this buildrequest has never been claimed or has been unclaimed
claimed_by_masterid? (integer) – the id of the master that claimed this buildrequest. None if this buildrequest has never been claimed or has been unclaimed
complete (boolean) – true if this buildrequest is complete
complete_at? (date) – time at which this buildrequest was completed, or None if it’s still running
priority (integer) – the priority of this buildrequest
properties? (sourcedproperties) – a dictionary of properties corresponding to buildrequest.
results? (integer) – the results of this buildrequest (see Build Result Codes), or None if not complete
submitted_at (date) – time at which this buildrequest was submitted
waited_for (boolean) – True if the entity that triggered this buildrequest is waiting for it to complete. Should be used by an (unimplemented so far) clean shutdown to only start br that are waited_for.
This resource type describes completed and in-progress buildrequests. Much of the contextual data for a buildrequest is associated with the buildset that contains this buildrequest.
3.5.2.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.buildrequests.BuildRequest
- claimBuildRequests(brids, claimed_at=None)
- Parameters:
brids (list(integer)) – list of buildrequest id to claim
claimed_at (datetime) – date and time when the buildrequest is claimed
- Returns:
(boolean) whether claim succeeded or not
Claim a list of buildrequests
- unclaimBuildRequests(brids)
- Parameters:
brids (list(integer)) – list of buildrequest id to unclaim
Unclaim a list of buildrequests
- completeBuildRequests(brids, results, complete_at=None)
- Parameters:
brids (list(integer)) – list of buildrequest id to complete
results (integer) – the results of the buildrequest (see Build Result Codes)
complete_at (datetime) – date and time when the buildrequest is completed
Complete a list of buildrequest with the
resultsstatus
3.5.2.2. Endpoints
- path: /builders/{builderid_or_buildername}/buildrequests
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
This path selects all buildrequests for a given builder (can return lots of data!)
GETreturns
- path: /buildrequests
GETreturns
- path: /buildrequests/{buildrequestid}
- Path Keys:
buildrequestid (number) – the id of the buildrequest
GETreturns
- POST with method: /buildrequests/{buildrequestid} (method=cancel)
- Body keys:
method (string) – must be
cancelreason (string) – The reason why the buildrequest was cancelled
- POST with method: /buildrequests/{buildrequestid} (method=set_priority)
- Body keys:
method (string) – must be
set_prioritypriority (int) – The new priority for the buildrequest
3.5.3. build
- resource type: build
- Attributes:
buildid (integer) – the unique ID of this build
number (integer) – the number of this build (sequential for a given builder)
builderid (integer) – id of the builder for this build
buildrequestid (integer) – build request for which this build was performed, or None if no such request exists
workerid (integer) – the worker this build ran on
masterid (integer) – the master this build ran on
started_at (date) – time at which this build started
complete (boolean) – true if this build is complete. Note that this is a calculated field (from complete_at != None). Ordering by this field is not optimized by the database layer.
complete_at? (date) – time at which this build was complete, or None if it’s still running
locks_duration_s (integer) – time spent acquiring locks so far, not including any running steps
properties? (sourcedproperties) – a dictionary of properties attached to build.
results? (integer) – the results of the build (see Build Result Codes), or None if not complete
state_string (string) – a string giving detail on the state of the build.
example
{ "builderid": 10, "buildid": 100, "buildrequestid": 13, "workerid": 20, "complete": false, "complete_at": null, "masterid": 824, "number": 1, "results": null, "started_at": 1451001600, "state_string": "created", "properties": {} }
This resource type describes completed and in-progress builds. Much of the contextual data for a build is associated with the build request, and through it the buildset.
Note
The properties field of a build is only filled out if the properties filterspec is set.
That means the property filter allows one to request properties through the Builds DATA API like so:
api/v2/builds?property=* (returns all properties)
api/v2/builds?property=propKey1&property=propKey2 (returns the properties that match the given keys)
api/v2/builds?property=propKey1&property=propKey2&limit=30 (filters combination)
Important
When combined with the field filter, for someone to get the build properties, they should ensure the properties field is set:
api/v2/builds?field=buildid&field=properties&property=workername&property=user
3.5.3.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.builds.Build
- newBuild(builderid, buildrequestid, workerid)
- Parameters:
builderid (integer) – id of the builder performing this build
buildrequestid (integer) – id of the build request being built
workerid (integer) – id of the worker on which this build is performed
- Returns:
(buildid, number) via Deferred
Create a new build resource and return its ID. The state strings for the new build will be set to ‘starting’.
- setBuildStateString(buildid, state_string)
- Parameters:
buildid (integer) – the build to modify
state_string (unicode) – new state string for this build
Replace the existing state strings for a build with a new list.
- finishBuild(buildid, results)
- Parameters:
buildid (integer) – the build to modify
results (integer) – the build’s results
Mark the build as finished at the current time, with the given results.
3.5.3.2. Endpoints
- path: /builders/{builderid_or_buildername}/builds
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
This path selects all builds for a builder (can return lots of data!)
GETreturnscollectionofbuild
- path: /builders/{builderid_or_buildername}/builds/{build_number}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
This path selects a specific build by builderid and buildnumber
GETreturnscollectionofbuild
- POST with method: /builders/{builderid_or_buildername}/builds/{build_number} (method=stop)
- Body keys:
method (string) – must be
stopreason (string) – The reason why the build was stopped
results (integer) – optionally results value override (default CANCELLED)
- POST with method: /builders/{builderid_or_buildername}/builds/{build_number} (method=rebuild)
- Body keys:
method (string) – must be
rebuild
- path: /buildrequests/{buildrequestid}/builds
- Path Keys:
buildrequestid (number) – the id of the buildrequest
GETreturnscollectionofbuild
- path: /builds
GETreturnscollectionofbuild
- path: /builds/{buildid}
- Path Keys:
buildid (number) – the id of the build
This path selects a build by id
GETreturnscollectionofbuild
- POST with method: /builds/{buildid} (method=stop)
- Body keys:
method (string) – must be
stopreason (string) – The reason why the build was stopped
- POST with method: /builds/{buildid} (method=rebuild)
- Body keys:
method (string) – must be
rebuild
- path: /builds/{buildid}/triggered_builds
- Path Keys:
buildid (number) – the id of the build
This selects all builds that have been triggered by this particular build
GETreturnscollectionofbuild
3.5.4. buildset
- resource type: buildset
- Attributes:
bsid (integer) – the ID of this buildset
complete (boolean) – true if all of the build requests in this buildset are complete
complete_at? (integer) – the time this buildset was completed, or None if not complete
external_idstring? (string) – an identifier that external applications can use to identify a submitted buildset; can be None
parent_buildid? (integer) – optional build id that is the parent for this buildset
parent_relationship? (string) – relationship identifier for the parent, this is a configured relationship between the parent build, and the childs buildsets
reason (string) – the reason this buildset was scheduled
rebuilt_buildid? (integer) – optional id of a build which was rebuilt or None if there was no rebuild. In case of repeated rebuilds, only initial build id is tracked
results? (integer) – the results of the buildset (see Build Result Codes), or None if not complete
sourcestamps[] (sourcestamp) – the sourcestamps for this buildset; each element is a valid
sourcestampentitysubmitted_at (integer) – the time this buildset was submitted
A buildset gathers build requests that were scheduled at the same time, and which share a source stamp, properties, and so on.
3.5.4.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.buildsets.Buildset
- addBuildset(scheduler=None, sourcestamps=[], reason='', properties={}, builderids=[], external_idstring=None, parent_buildid=None, parent_relationship=None)
- Parameters:
scheduler (string) – the name of the scheduler creating this buildset
sourcestamps (list) – sourcestamps for the new buildset; see below
reason (unicode) – the reason for this build
properties (dictionary with unicode keys and (source, property value) values) – properties to set on this buildset
builderids (list) – names of the builders for which build requests should be created
external_idstring (unicode) – arbitrary identifier to recognize this buildset later
parent_buildid (int) – optional build id that is the parent for this buildset
parent_relationship (unicode) – relationship identifier for the parent, this is a configured relationship between the parent build, and the childs buildsets
- Returns:
(buildset id, dictionary mapping builder ids to build request ids) via Deferred
Create a new buildset and corresponding buildrequests based on the given parameters. This is the low-level interface for scheduling builds.
Each sourcestamp in the list of sourcestamps can be given either as an integer, assumed to be a sourcestamp ID, or a dictionary of keyword arguments to be passed to
findSourceStampId.
- maybeBuildsetComplete(bsid)
- Parameters:
bsid (integer) – id of the buildset that may be complete
- Returns:
Deferred
This method should be called when a build request is finished. It checks the given buildset to see if all of its buildrequests are finished. If so, it updates the status of the buildset and sends the appropriate messages.
3.5.4.2. Endpoints
- path: /buildsets
This path selects all buildsets
GETreturns
- path: /buildsets/{bsid}
- Path Keys:
bsid (identifier) – the id of the buildset
This path selects a buildset by id
GETreturns
3.5.5. build_data
- resource type: build_data
- Attributes:
buildid (integer) – id of the build the build data is attached to
name (string) – the name of the build data
length (integer) – the number of bytes in the build data
source (string) – a string identifying the source of the data
example
{ "buildid": 31, "name": "stored_data_name", "length": 10, "source": "Step XYZ" }
This resource represents a key-value data pair associated to a build. A build can have any number of key-value pairs. The data is intended to be used for temporary purposes, until the build and all actions associated to it (such as reporters) are finished.
The value is a binary of potentially large size. There are two sets of APIs. One returns the properties of the key-value data pairs, such as key name and value length. Another returns the actual value as binary data.
3.5.5.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.build_data.BuildData
- setBuildData(buildid, name, value, source)
- Parameters:
buildid (integer) – build id to attach data to
name (unicode) – the name of the data
value (bytestr) – the value of the data as
bytessource (unicode) – a string identifying the source of the data
- Returns:
Deferred
Adds or replaces build data attached to the build.
3.5.5.2. Endpoints
- path: /builders/{builderid_or_buildername}/builds/{build_number}/data
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
This path selects all build data set for the build
GETreturns
- path: /builders/{builderid_or_buildername}/builds/{build_number}/data/{build_data_name}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
build_data_name (string) – the name of build data
This path selects a build data with specific name
GETreturns
- path: /builds/{buildid}/data
- Path Keys:
buildid (number) – the id of the build
This path selects all build data set for the build
GETreturns
- path: /builds/{buildid}/data/{build_data_name}
- Path Keys:
buildid (number) – the id of the build
build_data_name (string) – the name of build data
This path selects a build data with specific name
GETreturns
3.5.6. change
- resource type: change
- Attributes:
changeid (integer) – the ID of this change
author (string) – the author of the change in “name”, “name <email>” or just “email” (with @) format
branch? (string) – branch on which the change took place, or none for the “default branch”, whatever that might mean
category? (string) – user-defined category of this change, or none
codebase (string) – codebase in this repository
comments (string) – user comments for this change (aka commit)
files[] (string) – list of source-code filenames changed
parent_changeids[] (integer) – The ID of the parents. The data api allows for several parents, but the core Buildbot does not yet support it
project (string) – user-defined project to which this change corresponds
properties (sourcedproperties) – user-specified properties for this change, represented as an object mapping keys to tuple (value, source)
repository (string) – repository where this change occurred
revision? (string) – revision for this change, or none if unknown
revlink? (string) – link to a web view of this change
sourcestamp (sourcestamp) – the sourcestamp resource for this change
when_timestamp (integer) – time of the change
A change resource represents a change to the source code monitored by Buildbot.
3.5.6.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.changes.Change
- addChange(files=None, comments=None, author=None, revision=None, when_timestamp=None, branch=None, category=None, revlink='', properties={}, repository='', codebase=None, project='', src=None)
- Parameters:
files (list of unicode strings) – a list of filenames that were changed
comments (unicode) – user comments on the change
author (unicode) – the author of this change
revision (unicode) – the revision identifier for this change
when_timestamp (integer) – when this change occurred (seconds since the epoch), or the current time if None
branch (unicode) – the branch on which this change took place
category (unicode) – category for this change
revlink (string) – link to a web view of this revision
properties (dictionary with unicode keys and simple values (JSON-able).) – properties to set on this change. Note that the property source is not included in this dictionary.
repository (unicode) – the repository in which this change took place
project (unicode) – the project this change is a part of
src (unicode) – source of the change (vcs or other)
- Returns:
The ID of the new change, via Deferred
Add a new change to Buildbot. This method is the interface between change sources and the rest of Buildbot.
All parameters should be passed as keyword arguments.
All parameters labeled ‘unicode’ must be unicode strings and not bytestrings. Filenames in
files, and property names, must also be unicode strings. This is tested by the fake implementation.
3.5.6.2. Endpoints
- path: /builders/{builderid_or_buildername}/builds/{build_number}/changes
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
This path selects all changes tested by a build
GETreturnscollectionofchange
- path: /builds/{buildid}/changes
- Path Keys:
buildid (number) – the id of the build
This path selects all changes tested by a build
GETreturnscollectionofchange
- path: /changes
This path selects all changes.
On a reasonably loaded master, this can quickly return a very large result, taking minutes to process.
A specific query configuration is optimized which allows to get the recent changes: order:-changeid&limit=<n>
GETreturnscollectionofchange
- path: /changes/{changeid}
- Path Keys:
changeid (number) – the id of a change
This path selects one change by id
GETreturnscollectionofchange
- path: /sourcestamps/{ssid}/changes
- Path Keys:
ssid (number) – the id of the sourcestamp
This path selects all changes associated to one sourcestamp
GETreturnscollectionofchange
3.5.7. changesource
- resource type: changesource
- Attributes:
changesourceid (integer) – the ID of this changesource
master? (master) – the master on which this worker is running, or None if it is inactive
name (string) – name of this changesource
A changesource generates change objects, for example in response to an update in some repository. A particular changesource (by name) runs on at most one master at a time.
3.5.7.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.changesources.ChangeSource
- findChangeSourceId(name)
- Parameters:
name (string) – changesource name
- Returns:
changesource ID via Deferred
Get the ID for the given changesource name, inventing one if necessary.
- trySetChangeSourceMaster(changesourceid, masterid)
- Parameters:
changesourceid (integer) – changesource ID to try to claim
masterid (integer) – this master’s master ID
- Returns:
TrueorFalse, via Deferred
Try to claim the given scheduler for the given master and return
Trueif the scheduler is to be activated on that master.
3.5.7.2. Endpoints
- path: /changesources
This path selects all changesource
GETreturns
- path: /changesources/{changesourceid}
- Path Keys:
changesourceid (number) – the id of a changesource
This path selects one changesource given its id
GETreturns
- path: /masters/{masterid}/changesources
- Path Keys:
masterid (number) – the id of the master
This path selects all changesources for a given master
GETreturns
- path: /masters/{masterid}/changesources/{changesourceid}
- Path Keys:
masterid (number) – the id of the master
This path selects one changesource by id for a given master
GETreturns
3.5.8. codebase
- resource type: codebase
- Attributes:
codebaseid (integer) – the ID of this codebase
name (string) – the name of the codebase
slug (identifier) – the “slug”, suitable for use in a URL, of this codebase
projectid (integer) – the ID of the project codebase is associated to
Codebase represent an logical collection of source code and other resources.
3.5.8.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.codebases.Codebase
- update_codebase_info(*, codebaseid, projectid, slug)
- Parameters:
codebaseid (int) – the ID of the codebase to update
projectid (int) – the new project to associate the codebase to
slug (string) – the new slug to assign to codebase
- Returns:
None via Deferred.
Updates the information of an existing codebase.
3.5.9. codebase_branch
- resource type: codebase_branch
- Attributes:
codebaseid (integer) – the ID of the codebase that this commit is associated with
name (string) – the name of the branch
commitid? (int) – the ID of the current commit. This may be not set if there was an error accessing commit information, it was removed or due to similar reasons.
last_timestamp (int) – the time of the last branch change
A branch represents a certain named version of code in a codebase.
3.5.9.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.codebases.CodebaseBranch
- update_branch(*, codebaseid, name, commitid, last_timestamp)
- Parameters:
codebaseid (int) – the ID of the codebase to associate branch with
name (str) – the name of the branch
commitid (int) – optional ID of the commit pointed to by branch
last_timestamp (int) – the time of last change of the branch
- Returns:
None via Deferred.
Updates information of the branch
3.5.10. codebase_commit
- resource type: codebase_commit
- Attributes:
commitid (integer) – the ID of this commit
codebaseid (integer) – the ID of the codebase that this commit is associated with
author (string) – the author of the commit
committer? (string) – the committer of the commit
comments (string) – comment associated with the commit. Usually this is the commit message.
when_timestamp (integer) – time of the commit
revision (string) – the commit revision identifier in the underlying version control system
parent_commitid? (integer) – the ID of the parent commit. Commits form a chain from older to newer commits. Merging is not supported in this representation of the codebase.
A commit represents a certain version of code in a codebase.
3.5.10.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.codebases.CodebaseCommit
- add_commit(*, codebaseid, author, committer, files, comments, when_timestamp, revision, parent_commitid)
- Parameters:
codebaseid (int) – the ID of the codebase to associate commit with
author (str) – author associated with the commit
committer (str) – optional committer associated with the commit
files (list[str]) – optional list of file paths updated in the commit
comments (str) – any comments associated with the commit
when_timestamp (int) – the time when the commit happened
revision (str) – the ID of the commit in the version control system
parent_commitid (int) – optional ID of the parent commit
- Returns:
None via Deferred.
Creates a new commit.
3.5.11. forcescheduler
- resource type: forcescheduler
- Attributes:
all_fields[] (object)
builder_names[] (string) – names of the builders that this scheduler can trigger
button_name (string) – label of the button to use in the UI
label (string) – label of this scheduler to be displayed in the UI
name (identifier) – name of this scheduler
A forcescheduler initiates builds, via a formular in the web UI. At the moment, forceschedulers must be defined on all the masters where a web ui is configured. A particular forcescheduler runs on the master where the web request was sent.
Note
This datatype and associated endpoints will be deprecated when bug #2673 will be resolved.
3.5.11.1. Endpoints
- path: /builders/{builderid_or_buildername}/forceschedulers
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
This path selects all force-schedulers for a given builder
GETreturns
- path: /forceschedulers
This path selects all forceschedulers
GETreturns
- path: /forceschedulers/{schedulername}
- Path Keys:
schedulername (identifier) – the name of a scheduler
This path selects all changesource
GETreturns
- POST with method: /forceschedulers/{schedulername} (method=force)
- Body keys:
method (string) – must be
forceowner (string) – The user who wants to create the buildrequest
priority (integer) – The build request priority. Defaults to 0.
[] – content of the forcescheduler parameter is dependent on the configuration of the forcescheduler
3.5.12. identifier
- resource type: identifier
3.5.13. logchunk
- resource type: logchunk
- Attributes:
content (string) – content of the chunk
firstline (integer) – zero-based line number of the first line in this chunk
logid (integer) – the ID of log containing this chunk
A logchunk represents a contiguous sequence of lines in a logfile. Logs are not individually addressable in the data API; instead, they must be requested by line number range. In a strict REST sense, many logchunk resources will contain the same line.
The chunk contents is represented as a single unicode string. This string is the concatenation of each newline terminated-line.
Each log has a type, as identified by the “type” field of the corresponding log.
While all logs are sequences of unicode lines, the type gives additional information of interpreting the contents.
The defined types are:
t– text, a simple sequence of lines of text
s– stdio, like text but with each line tagged with a stream
h– HTML, represented as plain text
d– Deleted, logchunks for this log have been deleted by the Janitor
In the stream type, each line is prefixed by a character giving the stream type for that line.
The types are i for input, o for stdout, e for stderr, and h for header.
The first three correspond to normal UNIX standard streams, while the header stream contains metadata produced by Buildbot itself.
The offset and limit parameters can be used to select the desired lines.
These are specified as query parameters via the REST interface, or as arguments to the get method in Python.
The result will begin with line offset (so the resulting firstline will be equal to the given offset), and will contain up to limit lines.
Following example will get the first 100 lines of a log:
from buildbot.data import resultspec
first_100_lines = yield self.master.data.get(("logs", log['logid'], "contents"),
resultSpec=resultspec.ResultSpec(limit=100))
Following example will get the last 100 lines of a log:
from buildbot.data import resultspec
last_100_lines = yield self.master.data.get(("logs", log['logid'], "contents"),
resultSpec=resultspec.ResultSpec(offset=log['num_lines']-100))
Note
There is no event for a new chunk. Instead, the log resource is updated when new chunks are added, with the new number of lines. Consumers can then request those lines, if desired.
3.5.13.1. Update Methods
Log chunks are updated via log.
3.5.13.2. Endpoints
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_name}/logs/{log_slug}/contents
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_name (identifier) – the slug name of the step
log_slug (identifier) – the slug name of the log
GETreturns
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_number}/logs/{log_slug}/contents
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_number (number) – the number of the step
log_slug (identifier) – the slug name of the log
GETreturns
- path: /builds/{buildid}/steps/{step_number_or_name}/logs/{log_slug}/contents
- Path Keys:
buildid (number) – the id of the build
step_number_or_name (identifier|number) – the name or number of the step
log_slug (identifier) – the slug name of the log
GETreturns
- path: /logs/{logid}/contents
- Path Keys:
logid (number) – the id of the log
GETreturns
- path: /steps/{stepid}/logs/{log_slug}/contents
- Path Keys:
stepid (number) – the id of the step
log_slug (identifier) – the slug name of the log
GETreturns
3.5.14. log
- resource type: log
- Attributes:
complete (boolean) – true if this log is complete and will not generate additional logchunks
logid (integer) – the unique ID of this log
name (string) – the name of this log (e.g.,
err.html)num_lines (integer) – total number of line of this log
slug (identifier) – the “slug”, suitable for use in a URL, of this log (e.g.,
err_html)stepid (integer) – id of the step containing this log
type (identifier) – log type, identified by a single ASCII letter; see
logchunkfor details
example
{ "logid": 60, "name": "stdio", "slug": "stdio", "stepid": 50, "complete": false, "num_lines": 0, "type": "s" }
A log represents a stream of textual output from a step.
The actual output is encoded as a sequence of logchunk resources.
In-progress logs append logchunks as new data is added to the end, and event subscription allows a client to “follow” the log.
Each log has a “slug” which is unique within the step, and which can be used in paths.
The slug is generated by addLog based on the name, using forceIdentifier and incrementIdentifier to guarantee uniqueness.
Todo
- event: build.$buildid.step.$number.log.$logid.newlog
The log has just started. Logs are started when they are created, so this also indicates the creation of a new log.
- event: build.$buildid.step.$number.log.$logid.complete
The log is complete.
3.5.14.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.logs.Log
- addLog(stepid, name, type)
- Parameters:
stepid (integer) – stepid containing this log
name (string) – name for the log
- Raises:
KeyError – if a log by the given name already exists
- Returns:
logid via Deferred
Create a new log and return its ID. The name need not be unique. This method will generate a unique slug based on the name.
- appendLog(logid, content):
- Parameters:
logid (integer) – the log to which content should be appended
content (unicode) – the content to append
Append the given content to the given log. The content must end with a newline. All newlines in the content should be UNIX-style (
\n).
- finishLog(logid)
- Parameters:
logid (integer) – the log to finish
Mark the log as complete.
- compressLog(logid)
- Parameters:
logid (integer) – the log to compress
Compress the given log, after it is finished. This operation may take some time.
3.5.14.2. Endpoints
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_name}/logs
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_name (identifier) – the slug name of the step
This path selects all logs for the given step.
GETreturnscollectionoflog
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_name}/logs/{log_slug}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_name (identifier) – the slug name of the step
log_slug (identifier) – the slug name of the log
GETreturnscollectionoflog
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_number}/logs
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_number (number) – the number of the step
This path selects all log of a specific step
GETreturnscollectionoflog
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_number}/logs/{log_slug}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_number (number) – the number of the step
log_slug (identifier) – the slug name of the log
This path selects one log of a specific step
GETreturnscollectionoflog
- path: /builds/{buildid}/steps/{step_number_or_name}/logs
- Path Keys:
buildid (number) – the id of the build
step_number_or_name (identifier|number) – the name or number of the step
This path selects all logs of a step of a build
GETreturnscollectionoflog
- path: /builds/{buildid}/steps/{step_number_or_name}/logs/{log_slug}
- Path Keys:
buildid (number) – the id of the build
step_number_or_name (identifier|number) – the name or number of the step
log_slug (identifier) – the slug name of the log
This path selects one log of a a specific step
GETreturnscollectionoflog
- path: /logs/{logid}
- Path Keys:
logid (number) – the id of the log
This path selects one log
GETreturnscollectionoflog
- path: /steps/{stepid}/logs
- Path Keys:
stepid (number) – the id of the step
This path selects all logs for the given step
GETreturnscollectionoflog
- path: /steps/{stepid}/logs/{log_slug}
- Path Keys:
stepid (number) – the id of the step
log_slug (identifier) – the slug name of the log
GETreturnscollectionoflog
3.5.15. master
- resource type: master
- Attributes:
active (boolean) – true if the master is active
last_active (date) – time this master was last marked active
masterid (integer) – the ID of this master
name (string) – master name (in the form “hostname:basedir”)
This resource type describes buildmasters in the buildmaster cluster.
3.5.15.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.masters.Master
- masterActive(name, masterid)
- Parameters:
name (unicode) – the name of this master (generally
hostname:basedir)masterid (integer) – this master’s master ID
- Returns:
Deferred
Mark this master as still active. This method should be called at startup and at least once per minute. The master ID is acquired directly from the database early in the master startup process.
- expireMasters()
- Returns:
Deferred
Scan the database for masters that have not checked in for ten minutes. This method should be called about once per minute.
- masterStopped(name, masterid)
- Parameters:
name (unicode) – the name of this master
masterid (integer) – this master’s master ID
- Returns:
Deferred
Mark this master as inactive. Masters should call this method before completing an expected shutdown, and on startup. This method will take care of deactivating or removing configuration resources like builders and schedulers as well as marking lost builds and build requests for retry.
3.5.15.2. Endpoints
- path: /builders/{builderid_or_buildername}/masters
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
This path selects all masters supporting a given builder
GETreturnscollectionofmaster
- path: /builders/{builderid_or_buildername}/{masterid}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
masterid (number) – the id of the master
This path selects a master by id filtered by given builderid
GETreturnscollectionofmaster
- path: /masters
This path selects all masters
GETreturnscollectionofmaster
- path: /masters/{masterid}
- Path Keys:
masterid (number) – the id of the master
This path selects one master given its id
GETreturnscollectionofmaster
3.5.16. patch
- resource type: patch
- Attributes:
patchid (integer) – the unique ID of this patch
body (string) – patch body as a binary string
level (integer) – patch level - the number of directory names to strip from filenames in the patch
subdir (string) – subdirectory in which patch should be applied
author? (string) – patch author, or None
comment? (string) – patch comment, or None
This resource type describes a patch. Patches have unique IDs, but only appear embedded in sourcestamps, so those IDs are not especially useful.
3.5.16.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.patches.Patch
(no update methods)
3.5.17. project
- resource type: project
- Attributes:
projectid (integer) – the ID of this project
name (identifier) – project name
slug (identifier) – project slug
description? (string) – description of the project
This resource type describes a project.
3.5.17.1. Endpoints
- path: /projects
This path selects all projects
GETreturns
- path: /projects/{projectid_or_projectname}
- Path Keys:
projectid_or_projectname (number|identifier) – the ID or name of the project
This path selects a single project
GETreturns
3.5.18. rootlink
- resource type: rootlink
- Attributes:
name (string)
3.5.18.1. Endpoints
- path: /
GETreturns
3.5.19. scheduler
- resource type: scheduler
- Attributes:
master? (master) – the master on which this scheduler is running, or None if it is inactive
name (string) – name of this scheduler
schedulerid (integer) – the ID of this scheduler
A scheduler initiates builds, often in response to changes from change sources. A particular scheduler (by name) runs on at most one master at a time.
Note
This data type and associated endpoints is planned to be merged with forcescheduler data type when bug #2673 will be resolved.
3.5.19.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.schedulers.Scheduler
- findSchedulerId(name)
- Parameters:
name (string) – scheduler name
- Returns:
scheduler ID via Deferred
Get the ID for the given scheduler name, inventing one if necessary.
- trySetSchedulerMaster(schedulerid, masterid)
- Parameters:
schedulerid (integer) – scheduler ID to try to claim
masterid (integer) – this master’s master ID
- Returns:
TrueorFalse, via Deferred
Try to claim the given scheduler for the given master and return
Trueif the scheduler is to be activated on that master.
3.5.19.2. Endpoints
- path: /masters/{masterid}/schedulers
- Path Keys:
masterid (number) – the id of the master
This path selects all schedulers for a given master
GETreturns
- path: /masters/{masterid}/schedulers/{schedulerid}
- Path Keys:
masterid (number) – the id of the master
schedulerid (number) – the id of the scheduler
This path selects one scheduler by id for a given master
GETreturns
- path: /schedulers
This path selects all schedulers
GETreturns
- path: /schedulers/{schedulerid}
- Path Keys:
schedulerid (number) – the id of the scheduler
This path selects one scheduler by id
GETreturns
3.5.20. sourcedproperties
- resource type: sourcedproperties
- Attributes:
[] (object) –
Each key of this map is the name of a defined property. The value consists of a (value, source) tuple
1(OrderedDict([(‘type’, ‘string’), (‘description’, ‘source of the property’)]))2(OrderedDict([(‘type’, ‘integer | string | object | array | boolean’), (‘description’, ‘value of the property’)]))
User-specified properties for this change, represented as an object mapping keys to (value, source) tuples
Properties are present in several data resources, but have a separate endpoints, because they can represent a large dataset.
3.5.20.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.properties.Properties
- setBuildProperty(buildid, name, value, source)
- Parameters:
buildid (integer) – build ID
name (unicode) – name of the property to set
value (Any JSON-able type is accepted (lists, dicts, strings and numbers)) – value of the property
source (unicode) – source of the property to set
Set a build property. If no property with that name exists in that build, a new property will be created.
- setBuildProperties(buildid, props)
- Parameters:
buildid (integer) – build ID
props (IProperties) – name of the property to set
Synchronize build properties with the db. This sends only one event in the end of the sync, and only if properties changed. The event contains only the updated properties, for network efficiency reasons.
3.5.20.2. Endpoints
- path: /builders/{builderid_or_buildername}/builds/{build_number}/properties
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
This path selects all properties of a build
GETreturns
- path: /builds/{buildid}/properties
- Path Keys:
buildid (number) – the id of the build
This path selects all properties of a build
GETreturns
- path: /buildsets/{bsid}/properties
- Path Keys:
bsid (identifier) – the id of the buildset
This path selects all properties of a buildset. Buildset properties are part of the initial properties of a build.
GETreturns
3.5.21. sourcestamp
- resource type: sourcestamp
- Attributes:
ssid (integer) –
the ID of this sourcestamp
Note
For legacy reasons, the abbreviated name
ssidis used instead of canonicalsourcestampid. This might change in the future (bug #3509).branch? (string) – code branch, or none for the “default branch”, whatever that might mean
codebase (string) – revision for this sourcestamp, or none if unknown
created_at (date) – the timestamp when this sourcestamp was created
patch? (patch) – the patch for this sourcestamp, or none
project (string) – user-defined project to which this sourcestamp corresponds
repository (string) – repository where this sourcestamp occurred
revision? (string) – revision for this sourcestamp, or none if unknown
A sourcestamp represents a particular version of the source code. Absolute sourcestamps specify this completely, while relative sourcestamps (with revision = None) specify the latest source at the current time. Source stamps can also have patches; such stamps describe the underlying revision with the given patch applied.
Note that depending on the underlying version-control system, the same revision may describe different code in different branches (e.g., SVN) or may be independent of the branch (e.g., Git).
The created_at timestamp can be used to indicate the first time a sourcestamp was seen by Buildbot.
This provides a reasonable default ordering for sourcestamps when more reliable information is not available.
3.5.21.1. Endpoints
- path: /sourcestamps
This path selects all sourcestamps (can return lots of data!)
GETreturns
- path: /sourcestamps/{ssid}
- Path Keys:
ssid (number) – the id of the sourcestamp
This path selects one sourcestamp by id
GETreturns
3.5.22. spec
- resource type: spec
- Attributes:
path (string)
plural (string)
type (string)
type_spec (object)
3.5.22.1. Endpoints
- path: /application.spec
GETreturnscollectionofspec
3.5.23. step
- resource type: step
- Attributes:
stepid (integer) – the unique ID of this step
buildid (integer) – ID of the build containing this step
complete (boolean) – true if this step is complete
complete_at? (date) – time at which this step was complete, or None if it’s still running
hidden (boolean) – true if the step should not be displayed
name (identifier) – the step name, unique within the build
number (integer) – the number of this step (sequential within the build)
results? (integer) – the results of the step (see Build Result Codes), or None if not complete
started_at? (date) – time at which this step started, or None if it hasn’t started yet
locks_acquired_at? (date) – time at which this step acquired locks (if any), or None if the locks haven’t been acquired
state_string (string) – a string giving detail on the state of the build. The first is usually one word or phrase; the remainder are sized for one-line display
urls[] –
a list of URLs associated with this step
name(string)url(string)
This resource type describes a step in a build. Steps have unique IDs, but are most commonly accessed by name in the context of their containing builds.
3.5.23.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.steps.Step
- newStep(buildid, name)
- Parameters:
buildid (integer) – buildid containing this step
name (50-character identifier) – name for the step
- Returns:
(stepid, number, name) via Deferred
Create a new step and return its ID, number, and name. Note that the name may be different from the requested name if that name was already in use. The state strings for the new step will be set to ‘pending’.
- startStep(stepid, started_at=None, locks_acquired=False)
- Parameters:
stepid (integer) – the step to modify
started_at (integer) – optionally specify the startup time value. If not specified, then int(self.master.reactor.seconds()) will be used.
locks_acquired (boolean) – True if all locks are already acquired at the step startup. This effectively calls set_step_locks_acquired_at(stepid, locks_acquired_at=started_at)
Start the step.
- set_step_locks_acquired_at(stepid, locks_acquired_at=None)
- Parameters:
stepid (integer) – the step to modify
locks_acquired_at (integer) – optionally specify the timestamp value. If not specified, then int(self.master.reactor.seconds()) will be used.
Update step locks_acquired_at timestamp.
- setStepStateString(stepid, state_string)
- Parameters:
stepid (integer) – the step to modify
state_string (unicode) – new state strings for this step
Replace the existing state string for a step with a new list.
- addStepURL(stepid, name, url):
- Parameters:
stepid (integer) – the step to modify
name (string) – the url name
url (string) – the actual url
- Returns:
None via deferred
Add a new url to a step. The new url is added to the list of urls.
- finishStep(stepid, results, hidden)
- Parameters:
stepid (integer) – the step to modify
results (integer) – the step’s results
hidden (boolean) – true if the step should not be displayed
Mark the step as finished at the current time, with the given results.
3.5.23.2. Endpoints
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
This path selects all steps for the given build
GETreturnscollectionofstep
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_name}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_name (identifier) – the slug name of the step
This path selects a specific step for the given build
GETreturnscollectionofstep
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_number}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_number (number) – the number of the step
This path selects a specific step given its step number
GETreturnscollectionofstep
- path: /builds/{buildid}/steps
- Path Keys:
buildid (number) – the id of the build
This path selects all steps of a build
GETreturnscollectionofstep
- path: /builds/{buildid}/steps/{step_number_or_name}
- Path Keys:
buildid (number) – the id of the build
step_number_or_name (identifier|number) – the name or number of the step
This path selects one step of a build
GETreturnscollectionofstep
3.5.24. worker
- resource type: worker
- Attributes:
workerid (integer) – the ID of this worker
configured_on[] –
list of builders on masters this worker is configured on
builderid(integer)masterid(integer)
connected_to[] –
list of masters this worker is attached to
masterid(integer)
name (string) – the name of the worker
paused (bool) – the worker is paused if it is connected but doesn’t accept new builds
pause_reason? (string) – the reason for pausing the worker, if the worker is paused
graceful (bool) – the worker is graceful if it doesn’t accept new builds, and will shutdown when builds are finished
workerinfo (object) –
information about the worker
The worker information can be any JSON-able object. In practice, it contains the following keys, based on information provided by the worker:
admin(the admin information)host(the name of the host)access_uri(the access URI)version(the version on the worker)
A worker resource represents a worker to the source code monitored by Buildbot.
The contents of the connected_to and configured_on attributes are sensitive to the context of the request.
If a builder or master is specified in the path, then only the corresponding connections and configurations are included in the result.
3.5.24.1. Endpoints
- path: /builders/{builderid_or_buildername}/workers
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
This path selects all workers configured for a given builder
GETreturnscollectionofworker
- path: /builders/{builderid_or_buildername}/workers/{name}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
name (identifier) – the name of the worker
This path selects a worker by name filtered by given builderid
GETreturnscollectionofworker
- path: /builders/{builderid_or_buildername}/workers/{workerid}
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
workerid (number) – the id of the worker
This path selects a worker by id filtered by given builderid
GETreturnscollectionofworker
- POST with method: /builders/{builderid_or_buildername}/workers/{workerid} (method=stop)
- Body keys:
method (string) – must be
stopreason (string) – The reason why the worker was stopped
- POST with method: /builders/{builderid_or_buildername}/workers/{workerid} (method=kill)
- Body keys:
method (string) – must be
killreason (string) – The reason why the worker was stopped
- POST with method: /builders/{builderid_or_buildername}/workers/{workerid} (method=pause)
- Body keys:
method (string) – must be
pausereason (string) – The reason why the worker was paused
- POST with method: /builders/{builderid_or_buildername}/workers/{workerid} (method=unpause)
- Body keys:
method (string) – must be
unpausereason (string) – The reason why the worker was un-paused
- path: /masters/{masterid}/builders/{builderid}/workers
- Path Keys:
masterid (number) – the id of the master
builderid (number) – the id of the builder
This path selects all workers for a given builder and a given master
GETreturnscollectionofworker
- path: /masters/{masterid}/builders/{builderid}/workers/{name}
- Path Keys:
masterid (number) – the id of the master
builderid (number) – the id of the builder
name (identifier) – the name of the worker
This path selects one worker by name for a given builder and a given master
GETreturnscollectionofworker
- path: /masters/{masterid}/builders/{builderid}/workers/{workerid}
- Path Keys:
masterid (number) – the id of the master
builderid (number) – the id of the builder
workerid (number) – the id of the worker
This path selects one worker by name for a given builder and a given master
GETreturnscollectionofworker
- path: /masters/{masterid}/workers
- Path Keys:
masterid (number) – the id of the master
This path selects all workers for a given master
GETreturnscollectionofworker
- path: /masters/{masterid}/workers/{name}
- Path Keys:
masterid (number) – the id of the master
name (identifier) – the name of the worker
This path selects one worker by name for a given master
GETreturnscollectionofworker
- path: /masters/{masterid}/workers/{workerid}
- Path Keys:
masterid (number) – the id of the master
workerid (number) – the id of the worker
This path selects one worker by id for a given master
GETreturnscollectionofworker
- path: /workers
This path selects all workers
GETreturnscollectionofworker
- path: /workers/{name_or_id}
- Path Keys:
name_or_id (number|identifier) – the name or id of a worker
This path selects a worker by name or id
GETreturnscollectionofworker
3.5.25. test_result
- resource type: test_result
- Attributes:
test_resultid (integer) – the unique ID of this test result
builderid (integer) – id of the builder for this test result
test_result_setid (integer) – id of the test result set that the test result belongs to
test_name? (string) – the name of the test, if any
test_code_path? (string) – the code path associated to test, if any
line? (string) – the number of the line in the code path that produced this result, if any
duration_ns? (integer) – the number of nanoseconds it took to perform the test, if available
value (string) – the value of the test
example
{ "test_resultid": 1042, "builderid": 14, "test_result_setid": 412, "test_name": "test.perf.buildbot.api.123", "test_code_path": "master/buildbot/spec/types/test_result.raml", "duration_ns": 120410, "line": 123, "value": "31.1382" }
This resource represents a test result. Test results that are produced by a single test run are grouped by a relation to a test result set. Single test result set may represent thousands of test results.
3.5.25.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.test_result_sets.TestResult
- addTestResults(builderid, test_result_setid, result_values)
- Parameters:
builderid (integer) – The ID of the builder corresponding to the test result set
test_result_setid (integer) – The ID of the test result set for which to add results
result_values (integer) – A list of dictionaries that define the test results
Creates one or more new test results. This is a batch-based method as large number of test results are usually associated to a single test result set.
The dictionaries in
result_valuemay have the following keys:value(required): A string containing the value of the test resulttest_name(optional): A string containing the name of the testtest_code_path(optional): A string containing the path of the testline(optional): An integer containing the line within the source file corresponding to the testduration_ns(optional): An integer defining the duration of the test in nanoseconds
At least one of
test_nameandtest_code_pathmust be specified.The function returns nothing.
3.5.25.2. Endpoints
- path: /test_result_sets/{test_result_setid}/results
- Path Keys:
test_result_setid (number) – the id of the test result set
This path selects all test results for the given test result set
GETreturns
3.5.26. test_result_set
- resource type: test_result_set
- Attributes:
test_result_setid (integer) – the unique ID of this test result set
builderid (integer) – id of the builder for this test result set
buildid (integer) – id of the build for this test result set
stepid (integer) – id of the step for this test result set
description (string) – Free-form description of the source of the test data
category (string) –
The category of the test result set. This describes what data the test results contain.
Any value is allowed. The following standard categories are defined:
pass_fail: The test result set contains results that can indicate success or failure of specific test. The values of test results contain success or failure values.pass_only: The test result set contains results that can only indicate success of specific test. This is used in cases when failed tests are not reported.fail_only: The test result set contains results that can only indicate failure of specific test. This is used in tests when passed tests are not reported.code_issue: The test result set contains issues within the code reported by various tooling. This is effectively a subset offail_only.performance: The test result set contains performance results. The values of test results contain some kind of performance metric such as time per operation or the number of operations completed in a time period.binary_size: The test result set contains evaluation of binary size. The values of test results contain a binary size metric.memory_use: The test result set contains evaluation of dynamic memory use. The values of test results contain a memory use metric.
value_unit (string) –
Describes the unit of the values stored within the test results.
Any value is allowed. The following standard units are defined:
ps: Picosecondsns: Nanosecondsus: Microsecondsms: Millisecondss: Secondsboolean: A boolean value (0 or 1)B: BytesKB: Kilobytes (1000-based)KiB: Kibibytes (1024-based)MB: Megabytes (1000-based)MiB: Mebibytes (1024-based)GB: Gigabytes (1000-based)GiB: Gibibytes (1024-based)TB: Gigabytes (1000-based)TiB: Gibibytes (1024-based)message: Arbitrary string message
Note that the value of the test result is always stored as string.
tests_passed? (integer) – The number of passed tests in cases when the pass or fail criteria depends only on how that single test runs. For example, performance tests that track regressions across multiple tests do not have the number of passed tests defined.
tests_failed? (integer) – The number of failed tests in cases when the pass or fail criteria depends only on how that single test runs. For example, performance tests that track regressions across multiple tests do not have the number of failed tests defined.
complete (boolean) –
trueif all test results associated with test result set have been generated. Once set totruethis property will never be set back tofalse
example
{ "test_result_setid": 412, "builderid": 14, "buildid": 31, "stepid": 3, "description": "Performance test via BenchmarkDotNet", "category": "performance", "value_unit": "ms", "complete": true }
This resource represents a test result set. A test result set consists of a number of related test results. These test results need to be related in that they represent the same type of data and are produced by a single step. In reasonably tested codebases the number of test results in a test result set will approach several or even tens of thousands.
There may be a long delay between the creation of the test result set and full creation of the corresponding test results.
This is tracked by the complete property.
If it’s true, then the full set of test results have been committed to the database.
The test_result_unparsed_set object tracks test result sets that have not been parsed yet.
3.5.26.1. Update Methods
All update methods are available as attributes of master.data.updates.
- class buildbot.data.test_result_sets.TestResultSet
- addTestResultSet(builderid, buildid, stepid, description, category, value_unit)
- Parameters:
builderid (integer) – The ID of the builder for which the test result set is to be created
buildid (integer) – The ID of the build for which the test result set is to be created
stepid (integer) – The ID of the step for which the test result set is to be created
description – Description of the test result set
category – The category of the test result set
value_unit – Defines the unit of the values stored in the test results
Creates a new test result set. Returns the ID of the new test result set.
- completeTestResultSet(test_result_setid, tests_passed=None, tests_failed=None):
- Parameters:
test_result_setid (integer) – The ID of the test result set to complete
tests_passed (integer) – The number of passed tests, if known
tests_failed (integer) – The number of failed tests, if known
Marks a test result set as complete. The total number of passed and failed tests may be passed to have this information cached as part of a test result set so that expensive re-computations don’t need to be performed.
3.5.26.2. Endpoints
- path: /builders/{builderid_or_buildername}/test_result_sets
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
This selects all test result sets that have been created for a particular builder
GETreturns
- path: /builds/{buildid}/steps/{step_number_or_name}/test_result_sets
- Path Keys:
buildid (number) – the id of the build
step_number_or_name (identifier|number) – the name or number of the step
This selects all test result sets that have been created for a particular step
GETreturns
- path: /builds/{buildid}/test_result_sets
- Path Keys:
buildid (number) – the id of the build
This selects all test result sets that have been created for a particular build
GETreturns
- path: /steps/{stepid}/test_result_sets
- Path Keys:
stepid (number) – the id of the step
This selects all test result sets that have been created for a particular step
GETreturns
- path: /test_result_sets/{test_result_setid}
- Path Keys:
test_result_setid (number) – the id of the test result set
Selects a test result set by id
GETreturns
3.5.27. Raw endpoints
Raw endpoints allow to download content in their raw format (i.e. not within a json glue).
The content-disposition http header is set, so that the browser knows which file to store the content to.
- path: /builders/{builderid_or_buildername}/builds/{build_number}/data/{build_data_name}/value
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
build_data_name (string) – the name of build data
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_name}/logs/{log_slug}/raw
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_name (identifier) – the slug name of the step
log_slug (identifier) – the slug name of the log
This endpoint allows to get the raw logs for downloading into a file.
This endpoint does not provide paging capabilities.
For stream log types, the type line header characters are dropped.
‘text/plain’ is used as the mime type except for html logs, where ‘text/html’ is used.
The ‘slug’ is used as the filename for the resulting download. Some browsers are appending ".txt" or ".html" to this filename according to the mime-type.
- path: /builders/{builderid_or_buildername}/builds/{build_number}/steps/{step_number}/logs/{log_slug}/raw
- Path Keys:
builderid_or_buildername (number|string) – the ID or name of the builder
build_number (number) – the number of the build within the builder
step_number (number) – the number of the step
log_slug (identifier) – the slug name of the log
This path downloads the whole log
- path: /builds/{buildid}/data/{build_data_name}/value
- Path Keys:
buildid (number) – the id of the build
build_data_name (string) – the name of build data
- path: /builds/{buildid}/steps/{step_number_or_name}/logs/{log_slug}/raw
- Path Keys:
buildid (number) – the id of the build
step_number_or_name (identifier|number) – the name or number of the step
log_slug (identifier) – the slug name of the log
This path downloads the whole log
- path: /logs/{logid}/raw
- Path Keys:
logid (number) – the id of the log
This path downloads the whole log
- path: /steps/{stepid}/logs/{log_slug}/raw
- Path Keys:
stepid (number) – the id of the step
log_slug (identifier) – the slug name of the log
This path downloads the whole log
3.6. Data API
The data API is an interface against which various internal and external components can be written. It is a lower-level interface compared to the REST API that exposes more functionality. It combines access to stored state and messages, ensuring consistency between them. The callers can receive a dump of the current state plus changes to that state, without missing or duplicating messages.
3.6.1. Sections
The data API is divided into four sections:
getters - fetching data from the db API
subscriptions - subscribing to messages from the mq layer
control - allows state to be changed in specific ways by sending appropriate messages (e.g., stopping a build)
updates - direct updates to state appropriate messages.
The getters and subscriptions are exposed everywhere. Access to the control section must be authenticated at higher levels as the data layer does no authentication. The updates section is for use only by the process layer.
The interfaces for all sections, but the updates section, are intended to be language-agnostic. That is, they should be callable from JavaScript via HTTP, or via some other interface added to Buildbot after the fact.
3.6.1.1. Getters
The getters section can get either a single resource, or a list of resources. Getting a single resource requires a resource identifier (a tuple of strings) and a set of options to support automatic expansion of links to other resources (thus saving round-trips). Lists are requested with a partial resource identifier (a tuple of strings) and an optional set of filter options. In some cases, certain filters are implicit in the path, e.g., the list of buildsteps for a particular build.
3.6.1.2. Subscriptions
Message subscriptions can be made to anything that can be listed or gotten from the getters section, using the same resource identifiers. Options and explicit filters are not supported here. A message contains only the most basic information about a resource and a list of subscription results for every new resource of the desired type. Implicit filters are supported.
3.6.1.3. Control
The control section defines a set of actions that cause Buildbot to behave in a certain way, e.g., rebuilding a build or shutting down a worker. Actions correspond to a particular resource, although sometimes that resource is the root resource (an empty tuple).
3.6.1.4. Updates
The updates section defines a free-form set of methods that Buildbot’s process implementation calls to update data. Most update methods both modify state via the db API and send a message via the mq API. Some are simple wrappers for these APIs, while others contain more complex logic, e.g., building a source stamp set for a collection of changes. This section is the proper place to put common functionality, e.g., rebuilding builds or assembling buildsets.
3.6.2. Concrete Interfaces
3.6.2.1. Python Interface
Within the buildmaster process, the root of the data API is available at self.master.data,
which is a DataConnector instance.
- class buildbot.data.connector.DataConnector
This class implements the root of the data API. Within the buildmaster process, the data connector is available at
self.master.data. The first three sections are implemented through thegetandcontrolmethods, while the updates section is implemented using theupdatesattribute. Thepathargument to these methods should always be a tuple. Integer arguments can be presented as either integers or strings that can be parsed byint; all other arguments must be strings.- get(path, filters=None, fields=None, order=None, limit=None, offset=None)
- Parameters:
path (tuple) – A tuple of path elements representing the API path to fetch. Numbers can be passed as strings or integers
filters – result spec filters
fields – result spec fields
order – result spec order
limit – result spec limit
offset – result spec offset
- Raises:
- Returns:
a resource or list via Deferred, or None
This method implements the getters section. Depending on the path, it will return a single resource or a list of resources. If a single resource is not specified, it returns
None.The
filters,fields,order,limit, andoffsetare passed to theResultSpec, which will then be forwarded to the endpoint.The return value is composed of simple Python objects - lists, dicts, strings, numbers, and None.
For example, the following will query the buildrequests endpoint, filter for all non-completed buildrequests that were submitted after 1/5/2021, and return the buildrequest and buildset ids for the last 2 buildrequests in the collection:
from datetime import datetime from buildbot.data.resultspec import Filter submitted_at = datetime(2021, 5, 1).timestamp() buildrequests = yield self.master.data.get( ("buildrequests",), filters=[ Filter("submitted_at", "gt", [submitted_at]), Filter("complete", "eq", [False]), ], fields=["buildrequestid", "buildsetid"], order=("-buildrequestid",), limit=2 )
- getEndpoint(path)
- Parameters:
path (tuple) – A tuple of path elements representing the API path. Numbers can be passed as strings or integers.
- Raises:
- Returns:
tuple of endpoint and a dictionary of keyword arguments from the path
Get the endpoint responsible for the given path, along with any arguments extracted from the path. This can be used by callers that need access to information from the endpoint beyond that returned by
get.
- produceEvent(rtype, msg, event)
- Parameters:
rtype – the name identifying a resource type
msg – a dictionary describing the msg to send
event – the event to produce
This method implements the production of an event, for the rtype identified by its name string. Usually, this is the role of the data layer to produce the events inside the update methods. For the potential use cases where it would make sense to solely produce an event, and not update data, please use this API, rather than directly calling mq. It ensures the event is sent to all the routingkeys specified by eventPathPatterns.
- control(action, args, path)
- Parameters:
action – a short string naming the action to perform
args – dictionary containing arguments for the action
path (tuple) – A tuple of path elements representing the API path. Numbers can be passed as strings or integers.
- Raises:
- Returns:
a resource or list via Deferred, or None
This method implements the control section. Depending on the path, it may return a newly created resource.
For example, the following will cancel a buildrequest (and the associated build, if one has already started):
buildrequestid = 10 yield self.master.data.control( "cancel", {"reason": "User requested cancellation"}, ("buildrequests", buildrequestid), )
- allEndpoints()
- Returns:
list of endpoint specifications
This method returns the deprecated API spec. Please use REST API Specification instead.
- rtypes
This object has an attribute for each resource type, named after the singular form (e.g., self.master.data.builder). These attributes allow resource types to access one another for purposes of coordination. They are not intended for external access – all external access to the data API should be via the methods above or update methods.
Updates
The updates section is available at self.master.data.updates, and contains a number of ad-hoc
methods needed by the process modules.
Note
The update methods are implemented in resource type classes, but through some
initialization-time magic, all appear as attributes of self.master.data.updates.
The update methods are found in the resource type pages.
Exceptions
- exception buildbot.data.exceptions.DataException
This is a base class for all other Data API exceptions.
- exception buildbot.data.exceptions.InvalidPathError
The path argument was invalid or unknown.
- exception buildbot.data.exceptions.InvalidOptionError
A value in the
optionsargument was invalid or ill-formed.
- exception buildbot.data.exceptions.SchedulerAlreadyClaimedError
Identical to
SchedulerAlreadyClaimedError.
3.6.2.2. Web Interface
The HTTP interface is implemented by the buildbot.www package, as configured by the user.
Part of that configuration is a base URL, which is considered a prefix for all paths mentioned here.
See Base web application for more information.
3.6.3. Extending the Data API
The data API may be extended in various ways: adding new endpoints, new fields to resource types, new update methods, or entirely new resource types. In any case, you should only extend the API if you plan to submit the extensions to be merged into Buildbot itself. Private API extensions are strongly discouraged.
3.6.3.1. Adding Resource Types
You’ll need to use both plural and singular forms of the resource type; in this example, we’ll use ‘pub’ and ‘pubs’. You can also examine an existing file, like master/buildbot/data/changes.py, to see when to use which form.
In master/buildbot/data/pubs.py, create a subclass of ResourceType:
from buildbot.data import base
class Pub(base.ResourceType):
name = "pub"
endpoints = []
class EntityType(types.Entity):
pubid = types.Integer()
name = types.String()
num_taps = types.Integer()
closes_at = types.Integer()
entityType = EntityType(name)
- class buildbot.data.base.ResourceType
- name
- Type:
string
The singular, lower-cased name of the resource type. This becomes the first component in message routing keys.
- plural
- Type:
string
The plural, lower-cased name of the resource type. This becomes the key containing the data in REST responses.
- endpoints
- Type:
list
Subclasses should set this to a list of endpoint classes for this resource type.
- eventPathPatterns
- Type:
list of strings
This attribute should list the message routes where events should be sent, encoded as a REST like endpoint:
pub/:pubidIn the example above, a call to
produceEvent({'pubid': 10, 'name': 'Winchester'}, 'opened')would result in a message with routing key('pub', '10', 'opened').Several paths can be specified in order to be consistent with REST endpoints.
- entityType
-
The entity type describes the types of all of the fields in this particular resource type. See
buildbot.data.types.Entityand Adding Fields to Resource Types.
The parent class provides the following methods
- getEndpoints()
- Returns:
a list of
Endpointinstances
This method returns a list of the endpoint instances associated with the resource type.
The base method instantiates each class in the
endpointsattribute. Most subclasses can simply listEndpointsubclasses inendpoints.
- produceEvent(msg, event)
- Parameters:
msg (dict) – the message body
event (string) – the name of the event that has occurred
This is a convenience method to produce an event message for this resource type. It formats the routing key correctly and sends the message, thereby ensuring consistent routing-key structure.
Like all Buildbot source files, every resource type module must have corresponding tests. These should thoroughly exercise all update methods.
All resource types must be documented in the Buildbot documentation and linked from the bottom of this file (master/docs/developer/data.rst).
3.6.3.2. Adding Endpoints
Each resource path is implemented as an Endpoint instance.
In most cases, each instance is of a different class, but this is not required.
The data connector’s get and
control methods both take a path argument
that is used to look up the corresponding endpoint. The path matching is performed by
buildbot.util.pathmatch, and supports automatically extracting variable fields from the
path. See that module’s description for details.
- class buildbot.data.base.Endpoint
- pathPatterns
- Type:
list of strings
This attribute defines the path patterns which incoming paths must match to select this endpoint. Paths are specified as URIs, and can contain variables as parsed by
buildbot.util.pathmatch.Matcher. Each string in a list represents a path pattern.For example, the following specifies two paths with the second having a single variable:
pathPatterns = [ "/bugs", "/component/i:component_name/bugs", ]
- rootLinkName
- Type:
string
If set, then the first path pattern for this endpoint will be included as a link in the root of the API. This should be set for any endpoints that begin an explorable tree.
- kind
- Type:
number
Defines type of the endpoint. The following endpoint types are supported:
EndpointKind.SINGLE- returns single resourceEndpointKind.COLLECTION- returns a collection of resourcesEndpointKind.RAW- returns a raw resource.Raw resources are used to get the data not encoded in JSON via the REST API. The get() method from endpoint should return following data structure:
{ "raw": "raw data to be sent to the http client", "mime-type": "<mime-type>", "filename": "filename_to_be_used_in_content_disposition_attachement_header" }
EndpointKind.RAW_INLINE- returns a raw resource which is shown inline in HTTP client.The difference between
RAWresource is that content-disposition header is not set. The get() method from endpoint should return following data structure:{ "raw": "raw data to be sent to the http client", "mime-type": "<mime-type>" }
- get(options, resultSpec, kwargs)
- Parameters:
options (dict) – model-specific options
resultSpec – a
ResultSpecinstance describing the desired resultskwargs (dict) – fields extracted from the path
- Returns:
data via Deferred
Get data from the endpoint. This should return either a list of dictionaries (for list endpoints), a dictionary, or None (both for details endpoints). The endpoint is free to handle any part of the result spec. When doing so, it should remove the relevant configuration from the spec. See below.
Any result spec configuration that remains on return will be applied automatically.
- control(action, args, kwargs)
- Parameters:
action – a short string naming the action to perform
args – dictionary containing arguments for the action
kwargs – fields extracted from the path
Continuing the pub example, a simple endpoint would look like this:
class PubEndpoint(base.Endpoint):
pathPattern = ('pub', 'i:pubid')
def get(self, resultSpec, kwargs):
return self.master.db.pubs.getPub(kwargs['pubid'])
Endpoint implementations must have unit tests.
An endpoint’s path should be documented in the .rst file for its resource type.
The initial pass at implementing any endpoint should just ignore the resultSpec argument to
get. After that initial pass, the argument can be used to optimize certain types of queries.
For example, if the resource type has many resources, but most real-life queries use the result
spec to filter out all but a few resources from that group, then it makes sense for the endpoint to
examine the result spec and allow the underlying DB API to do that filtering.
When an endpoint handles parts of the result spec, it must remove those parts from the spec before
it returns. See the documentation for ResultSpec for methods
to do so.
Note that endpoints must be careful not to alter the order of the filtering applied for a result spec. For example, if an endpoint implements pagination, then it must also completely implement filtering and ordering, since those operations precede pagination in the result spec application.
3.6.3.3. Adding Messages
Message types are defined in master/buildbot/test/util/validation.py, via the message module-level value.
This is a dictionary of MessageValidator objects, one for each message type.
The message type is determined from the first atom of its routing key.
The events dictionary lists the possible last atoms of the routing key.
It should be identical to the attribute of the ResourceType with the same name.
3.6.3.4. Adding Update Methods
Update methods are for use by the Buildbot process code, and as such are generally designed to suit the needs of that code. They generally encapsulate logic common to multiple users (e.g., creating buildsets), and they finish by performing modifications in the database and sending a corresponding message. In general, Buildbot does not depend on timing of either the database or message broker, so the order in which these operations are initiated is not important.
Update methods are considered part of Buildbot’s user-visible interface, and as such, incompatible changes should be avoided wherever possible. Instead, either add a new method (and potentially re-implement existing methods in terms of the new method) or add new, optional parameters to an existing method. If an incompatible change is unavoidable, it should be described clearly in the release notes.
Update methods are implemented as methods of ResourceType
subclasses, decorated with @base.updateMethod:
- buildbot.data.base.updateMethod(f)
A decorator for
ResourceTypesubclass methods, indicating that the method should be copied tomaster.data.updates.
Returning to the pub example:
class PubResourceType(base.ResourceType):
# ...
@base.updateMethod
@defer.inlineCallbacks
def setPubTapList(self, pubid, beers):
pub = yield self.master.db.pubs.getPub(pubid)
# ...
self.produceMessage(pub, 'taps-updated')
Update methods should be documented in master/docs/developer/data.rst. They should be thoroughly tested with unit tests. They should have a fake implementation in master/buildbot/test/fake/fakedata.py. That fake implementation should be tested to match the real implementation in master/buildbot/test/unit/test_data_connector.py.
3.6.3.5. Adding Fields to Resource Types
The details of the fields of a resource type are rigorously enforced at several points in the
Buildbot tests. The enforcement is performed by the buildbot.data.types module.
The module provides a number of type classes for basic and compound types. Each resource type class
defines its entity type in its entityType class
attribute. Other resource types may refer to this class attribute if they embed an entity of that
type.
The types are used both for tests and by the REST interface to properly decode user-supplied query parameters.
Basic Types
- class buildbot.data.types.Integer
An integer.
myid = types.Integer()
- class buildbot.data.types.String
A string. Strings must always be Unicode.
name = types.String()
- class buildbot.data.types.Binary
A binary bytestring.
data = types.Binary()
- class buildbot.data.types.Boolean
A boolean value.
complete = types.Boolean()
- class buildbot.data.types.Identifier(length)
An identifier; see Identifier. The constructor argument specifies the maximum length.
ident = types.Identifier(25)
Compound Types
- class buildbot.data.types.NoneOk(nestedType)
Either the nested type, or None.
category = types.NoneOk(types.String())
- class buildbot.data.types.List(of)
An list of objects. The named constructor argument
ofspecifies the type of the list elements.tags = types.List(of=types.String())
- class buildbot.data.types.SourcedProperties
A data structure representing properties with their sources, in the form
{name: (value, source)}. The property name and source must be Unicode, and the value must be JSON-able.props = types.SourcedProperties()
Entity Type
- class buildbot.data.types.Entity(name)
A data resource is represented by a dictionary with well-known keys. To define those keys and their values, subclass the
Entityclass within your ResourceType class and include each field as an attribute:class MyStuff(base.ResourceType): name = "mystuff" # ... class EntityType(types.Entity): myid = types.Integer() name = types.String() data = types.Binary() complete = types.Boolean() ident = types.Identifier(25) category = types.NoneOk(types.String()) tags = types.List(of=types.String()) props = types.SourcedProperties()
Then instantiate the class with the resource type name. The second argument is used for GraphQl endpoints:
entityType = EntityType(name)
To embed another entity type, reference its entityType class attribute:
class EntityType(types.Entity): # ... master = masters.Master.entityType
3.6.4. Data Model
The data API enforces a strong and well-defined model on Buildbot’s data. This model is influenced by REST, in the sense that it defines resources, representations for resources, and identifiers for resources. For each resource type, the API specifies:
the attributes of the resource and their types (e.g., changes have a string specifying their project)
the format of links to other resources (e.g., buildsets to sourcestamp sets)
the paths relating to the resource type
the format of routing keys for messages relating to the resource type
the events that can occur on that resource (e.g., a buildrequest can be claimed)
options and filters for getting resources
Some resource type attributes only appear in certain formats, as noted in the documentation for the resource types. In general, messages do not include any optional attributes, nor links.
Paths are given here separated by slashes, with key names prefixed by : and described below.
Similarly, message routing keys given here are separated by dots, with key names prefixed by $.
The translation to tuples and other formats should be obvious.
All strings in the data model are unicode strings.
3.7. Database
Buildbot stores most of its state in a database. This section describes the database connector classes, which allow other parts of Buildbot to access the database. It also describes how to modify the database schema and the connector classes themselves.
3.7.1. Database Overview
All access to the Buildbot database is mediated by database connector classes. These classes provide a functional, asynchronous interface to other parts of Buildbot, and encapsulate the database-specific details in a single location in the codebase.
The connector API, defined below, is a stable API in Buildbot, and can be
called from any other component. Given a master master, the root of the
database connectors is available at master.db, so, for example, the state
connector’s getState method is master.db.state.getState.
All the connectors use SQLAlchemy Core to achieve (almost) database-independent operation. Note that the SQLAlchemy ORM is not used in Buildbot. Database queries are carried out in threads, and report their results back to the main thread via Twisted Deferreds.
3.7.2. Schema
Changes to the schema are accomplished through migration scripts, supported by Alembic.
The schema itself is considered an implementation detail, and may change significantly from version to version. Users should rely on the API (below), rather than performing queries against the database itself.
3.7.3. Identifier
Restrictions on many string fields in the database are referred to as the Identifier concept. An
“identifier” is a nonempty unicode string of limited length, containing only UTF-8 alphanumeric
characters along with - (dash) and _ (underscore), and not beginning with a digit. Wherever
an identifier is used, the documentation will give the maximum length in characters. The function
buildbot.util.identifiers.isIdentifier is useful to verify a well-formed identifier.
3.7.4. Writing Database Connector Methods
The information above is intended for developers working on the rest of Buildbot, and treating the database layer as an abstraction. The remainder of this section describes the internals of the database implementation, and is intended for developers modifying the schema or adding new methods to the database layer.
Warning
It’s difficult to change the database schema, especially after it has been released. Changing the database API is disruptive to users. Consider very carefully the future-proofing of any changes here!
3.7.4.1. The DB Connector and Components
- class buildbot.db.connector.DBConnector
The root of the database connectors,
master.db, is aDBConnectorinstance. Its main purpose is to hold a reference to each of the connector components, but it also handles timed cleanup tasks.If you are adding a new connector component, import its module and create an instance of it in this class’s constructor.
- run_db_task(deferred_task: defer.Deferred) None
For use when the deferred resulting from a DB operation is not awaited. If a function that will run DB operation is not awaited, a shutdown of the master could sever the connection to the database before the function completes. To avoid this issue, register the deferred to the connector so it can properly await it’s completion in such cases.
- class buildbot.db.base.DBConnectorComponent
This is the base class for connector components.
There should be no need to override the constructor defined by this base class.
- db
A reference to the
DBConnector, so that connector components can use e.g.,self.db.poolorself.db.model. In the unusual case that a connector component needs access to the master, the easiest path isself.db.master.
- checkLength(col, value)
For use by subclasses to check that ‘value’ will fit in ‘col’, where ‘col’ is a table column from the model. Ignore this check for database engines that either provide this error themselves (postgres) or that do not enforce maximum-length restrictions (sqlite).
- findSomethingId(self, tbl, whereclause, insert_values, _race_hook=None, autoCreate=True)
Find (using
whereclause) or add (usinginsert_values) a row totable, and return the resulting ID. IfautoCreate== False, we will not automatically insert the row.
- hashColumns(*args)
Hash the given values in a consistent manner: None is represented as xf5, an invalid unicode byte; strings are converted to utf8; and integers are represented by their decimal expansion. The values are then joined by ‘0’ and hashed with sha1.
- doBatch(batch, batch_n=500)
returns an Iterator that batches stuff in order to not push to many things in a single request. Especially sqlite has 999 limit that it can take in a request.
3.7.4.2. Direct Database Access
The connectors all use SQLAlchemy Core as a wrapper around database
client drivers. Unfortunately, SQLAlchemy is a synchronous library, so some
extra work is required to use it in an asynchronous context, like in Buildbot.
This is accomplished by deferring all database operations to threads, and
returning a Deferred. The Pool class takes care of
the details.
A connector method should look like this:
def myMethod(self, arg1, arg2):
def thd(conn):
q = ... # construct a query
for row in conn.execute(q):
... # do something with the results
return ... # return an interesting value
return self.db.pool.do(thd)
Picking that apart, the body of the method defines a function named thd
taking one argument, a Connection object. It then calls
self.db.pool.do, passing the thd function. This function is called in
a thread, and can make blocking calls to SQLAlchemy as desired. The do
method will return a Deferred that will fire with the return value of thd,
or with a failure representing any exception raised by thd.
The return value of thd must not be an SQLAlchemy object - in particular,
any ResultProxy
objects must be parsed into lists or other data structures before they are
returned.
Warning
As the name thd indicates, the function runs in a thread. It should
not interact with any other part of Buildbot, nor with any of the Twisted
components that expect to be accessed from the main thread – the reactor,
Deferreds, etc.
Queries can be constructed using any of the SQLAlchemy core methods, using
tables from Model, and executed with the connection
object, conn.
Note
SQLAlchemy requires the use of a syntax that is forbidden by pep8. If in where clauses you need to select rows where a value is NULL, you need to write (tbl.c.value == None). This form is forbidden by pep8 which requires the use of is None instead of == None. As sqlalchemy is using operator overloading to implement pythonic SQL statements, and the is operator is not overloadable, we need to keep the == operators. In order to solve this issue, Buildbot uses buildbot.db.NULL constant, which is None. So instead of writing tbl.c.value == None, please write tbl.c.value == NULL).
- class buildbot.db.pool.DBThreadPool
- do(callable, ...)
- Returns:
Deferred
Call
callablein a thread, with aConnectionobject as first argument. Returns a deferred that will fire with the results of the callable, or with a failure representing any exception raised during its execution.Any additional positional or keyword arguments are passed to
callable.
3.7.4.3. Database Schema
Database connector methods access the database through SQLAlchemy, which requires access to Python objects representing the database tables. That is handled through the model.
- class buildbot.db.model.Model
This class contains the canonical description of the Buildbot schema. It is represented in the form of SQLAlchemy
Tableinstances, as class variables. At runtime, the model is available atmaster.db.model. So, for example, thebuildrequeststable can be referred to asmaster.db.model.buildrequests, and columns are available in itscattribute.The source file, master/buildbot/db/model.py, contains comments describing each table; that information is not replicated in this documentation.
Note that the model is not used for new installations or upgrades of the Buildbot database. See Modifying the Database Schema for more information.
- metadata
The model object also has a
metadataattribute containing aMetaDatainstance. Connector methods should not need to access this object. The metadata is not bound to an engine.
The
Modelclass also defines some migration-related methods:- is_current()
- Returns:
boolean via Deferred
Returns true if the current database’s version is current.
- upgrade()
- Returns:
Deferred
Upgrades the database to the most recent schema version.
3.7.4.4. Caching
Connector component methods that get an object based on an ID are good
candidates for caching. The cached decorator
makes this automatic:
- buildbot.db.base.cached(cachename)
- Parameters:
cache_name – name of the cache to use
A decorator for “getter” functions that fetch an object from the database based on a single key. The wrapped method will only be called if the named cache does not contain the key.
The wrapped function must take one argument (the key); the wrapper will take a key plus an optional
no_cacheargument which, if true, will cause it to invoke the underlying method even if the key is in the cache.The resulting method will have a
cacheattribute which can be used to access the underlying cache.
In most cases, getter methods return a well-defined dictionary. Unfortunately,
Python does not handle weak references to bare dictionaries, so components must
instantiate a subclass of dict. The whole assembly looks something like
this:
class ThDict(dict):
pass
class ThingConnectorComponent(base.DBConnectorComponent):
@base.cached('thdicts')
def getThing(self, thid):
def thd(conn):
...
thdict = ThDict(thid=thid, attr=row.attr, ...)
return thdict
return self.db.pool.do(thd)
3.7.5. Modifying the Database Schema
Changes to the schema are accomplished through migration scripts, supported by Alembic.
The schema is tracked by a revision number, stored in the alembic_version table. It can be
anything, but by convention Buildbot uses revision numbers that are numbers incremented by one for
each revision. The master will refuse to run with an outdated database.
To make a change to the schema, first consider how to handle any existing data. When adding new columns, this may not be necessary, but table refactorings can be complex and require caution so as not to lose information.
Refer to the documentation of Alembic for details of how database migration scripts should be written.
The database schema itself is stored in master/buildbot/db/model.py which should be updated to represent the new schema. Buildbot’s automated tests perform a rudimentary comparison of an upgraded database with the model, but it is important to check the details - key length, nullability, and so on can sometimes be missed by the checks. If the schema and the upgrade scripts get out of sync, bizarre behavior can result.
Changes to database schema should be reflected in corresponding fake database table definitions in master/buildbot/test/fakedb
The upgrade scripts should have unit tests.
The classes in master/buildbot/test/util/migration.py make this straightforward.
Unit test scripts should be named e.g., test_db_migrate_versions_015_remove_bad_master_objectid.py.
The master/buildbot/test/integration/test_upgrade.py also tests upgrades, and will confirm that the
resulting database matches the model. If you encounter implicit indexes on MySQL, that do not
appear on SQLite or Postgres, add them to implied_indexes in
master/buidlbot/db/model.py.
3.7.6. Foreign key checking
PostgreSQL and SQlite db backends check the foreign keys consistency. bug #2248 needs to be fixed so that we can support foreign key checking for MySQL.
3.7.7. Database Compatibility Notes
Or: “If you thought any database worked right, think again”
Because Buildbot works over a wide range of databases, it is generally limited to database features present in all supported backends. This section highlights a few things to watch out for.
In general, Buildbot should be functional on all supported database backends. If use of a backend adds minor usage restrictions, or cannot implement some kinds of error checking, that is acceptable if the restrictions are well-documented in the manual.
The metabuildbot tests Buildbot against all supported databases, so most compatibility errors will be caught before a release.
3.7.7.1. Index Length in MySQL
MySQL only supports about 330-character indexes. The actual index length is 1000 bytes, but MySQL uses 3-byte encoding for UTF8 strings. This is a longstanding bug in MySQL - see “Specified key was too long; max key length is 1000 bytes” with utf8. While this makes sense for indexes used for record lookup, it limits the ability to use unique indexes to prevent duplicate rows.
InnoDB only supports indexes up to 255 unicode characters, which is why all indexed columns are limited to 255 characters in Buildbot.
3.7.7.2. Transactions in MySQL
Unfortunately, use of the MyISAM storage engine precludes real transactions in
MySQL. transaction.commit() and transaction.rollback() are essentially
no-ops: modifications to data in the database are visible to other users
immediately, and are not reverted in a rollback.
3.7.7.3. Referential Integrity in SQLite and MySQL
Neither MySQL nor SQLite enforce referential integrity based on foreign keys. Postgres does enforce it, however. If possible, test your changes on Postgres before committing, to check that tables are added and removed in the proper order.
3.7.7.4. Subqueries in MySQL
MySQL’s query planner is easily confused by subqueries. For example, a DELETE query specifying id’s that are IN a subquery will not work. The workaround is to run the subquery directly, and then execute a DELETE query for each returned id.
If this weakness has a significant performance impact, it would be acceptable to conditionalize use of the subquery on the database dialect.
3.7.7.5. Too Many Variables in SQLite
Sqlite has a limitation on the number of variables it can use.
This limitation is usually
SQLITE_LIMIT_VARIABLE_NUMBER=999.
There is currently no way with pysqlite to query the value of this limit.
The C-api sqlite_limit is just not bound to the python.
When you hit this problem, you will get error like the following:
sqlalchemy.exc.OperationalError: (OperationalError) too many SQL variables
u'DELETE FROM scheduler_changes WHERE scheduler_changes.changeid IN (?, ?, ?, ..., ?)
You can use the method doBatch in order to write batching code in a consistent manner.
3.7.8. Testing migrations with real databases
By default Buildbot test suite uses SQLite database for testing database
migrations.
To use other database set BUILDBOT_TEST_DB_URL environment variable to
value in SQLAlchemy database URL specification.
For example, to run tests with file-based SQLite database you can start tests in the following way:
BUILDBOT_TEST_DB_URL=sqlite:////tmp/test_db.sqlite trial buildbot.test
3.7.8.1. Run databases in Docker
Docker allows to easily install and configure different databases locally in containers.
To run tests with PostgreSQL:
# Install psycopg
pip install psycopg2
# Start container with PostgreSQL 9.5
# It will listen on port 15432 on localhost
sudo docker run --name bb-test-postgres -e POSTGRES_PASSWORD=password \
-p 127.0.0.1:15432:5432 -d postgres:9.5
# Start interesting tests
BUILDBOT_TEST_DB_URL=postgresql://postgres:password@localhost:15432/postgres \
trial buildbot.test
To run tests with MySQL:
# Install mysqlclient
pip install mysqlclient
# Start container with MySQL 5.5
# It will listen on port 13306 on localhost
sudo docker run --name bb-test-mysql -e MYSQL_ROOT_PASSWORD=password \
-p 127.0.0.1:13306:3306 -d mysql:5.5
# Start interesting tests
BUILDBOT_TEST_DB_URL=mysql+mysqldb://root:password@127.0.0.1:13306/mysql \
trial buildbot.test
3.8. Database connectors API
This section documents the available database connector classes.
3.8.1. Buildsets connector
- class buildbot.db.buildsets.BuildsetsConnectorComponent
This class handles getting buildsets into and out of the database. Buildsets combine multiple build requests that were triggered together.
An instance of this class is available at
master.db.buildsets.Buildsets are indexed by bsid and their contents are represented as
BuildSetModeldataclass with the following fields:bsidexternal_idstring(arbitrary string for mapping builds externally)reason(string; reason these builds were triggered)rebuilt_buildid(integer; id of a build which was rebuilt or None if there was no rebuild.In case of repeated rebuilds, only initial build id is tracked)
sourcestamps(list of sourcestamps for this buildset, by ID)submitted_at(datetime object; time this buildset was created)complete(boolean; true if all of the builds for this buildset are complete)complete_at(datetime object; time this buildset was completed)results(aggregate result of this buildset; see Build Result Codes)parent_buildid(optional build id that is the parent for this buildset)parent_relationship(relationship identifier for the parent)
- addBuildset(sourcestamps, reason, properties, builderids, rebuilt_buildid=None, external_idstring=None, parent_buildid=None, parent_relationship=None)
- Parameters:
sourcestamps (list) – sourcestamps for the new buildset; see below
reason (short unicode string) – reason for this buildset
properties (dictionary, where values are tuples of (value, source)) – properties for this buildset
builderids (list of int) – builderids specified by this buildset
external_idstring (unicode string) – external key to identify this buildset; defaults to None
submitted_at (datetime) – time this buildset was created; defaults to the current time
parent_buildid (int) – optional build id that is the parent for this buildset
parent_relationship (unicode) – relationship identifier for the parent. This is the configured relationship between the parent build and the child buildsets
rebuilt_buildid (int) – optional rebuilt build id
- Returns:
buildset ID and buildrequest IDs, via a Deferred
Add a new buildset to the database, along with build requests for each builder, returning the resulting bsid via a Deferred. Arguments should be specified by keyword.
Each sourcestamp in the list of sourcestamps can be given either as an integer, assumed to be a sourcestamp ID, or a dictionary of keyword arguments to be passed to
findSourceStampId.The return value is a tuple
(bsid, brids)wherebsidis the inserted buildset ID andbridsis a dictionary mapping builderids to build request IDs.
- completeBuildset(bsid, results[, complete_at=XX])
- Parameters:
bsid (integer) – buildset ID to complete
results (integer) – integer result code
complete_at (datetime) – time the buildset was completed
- Returns:
Deferred
- Raises:
KeyErrorif the buildset does not exist or is already complete
Complete a buildset, marking it with the given
resultsand setting itscompleted_atto the current time, if thecomplete_atargument is omitted.
- getBuildset(bsid)
- Parameters:
bsid – buildset ID
- Returns:
BuildSetModelorNone, via Deferred
Get a
BuildSetModelrepresenting the given buildset, orNoneif no such buildset exists.Note that buildsets are not cached, as the values in the database are not fixed.
- getBuildsets(complete=None, resultSpec=None)
- Parameters:
complete – if true, return only complete buildsets; if false, return only incomplete buildsets; if
Noneor omitted, return all buildsetsresultSpec – result spec containing filters sorting and paging requests from data/REST API. If possible, the db layer can optimize the SQL query using this information.
- Returns:
list of
BuildSetModel, via Deferred
Get a list of
BuildSetModelmatching the given criteria.
- getRecentBuildsets(count=None, branch=None, repository=None,
- complete=None):
- Parameters:
count (integer) – maximum number of buildsets to retrieve (required)
branch (string) – optional branch name. If specified, only buildsets affecting such branch will be returned
repository (string) – optional repository name. If specified, only buildsets affecting such repository will be returned
complete (Boolean) – if true, return only complete buildsets; if false, return only incomplete buildsets; if
Noneor omitted, return all buildsets
- Returns:
list of
BuildSetModel, via Deferred
Get “recent” buildsets, as defined by their
submitted_attimes.
- getBuildsetProperties(buildsetid)
- Parameters:
bsid – buildset ID
- Returns:
dictionary mapping property name to
value, source, via Deferred
Return the properties for a buildset, in the same format they were given to
addBuildset.Note that this method does not distinguish a nonexistent buildset from a buildset with no properties, and returns
{}in either case.
3.8.2. Buildrequests connector
- exception buildbot.db.buildrequests.AlreadyClaimedError
Raised when a build request is already claimed, usually by another master.
- exception buildbot.db.buildrequests.NotClaimedError
Raised when a build request is not claimed by this master.
- class buildbot.db.buildrequests.BuildRequestsConnectorComponent
This class handles the complex process of claiming and unclaiming build requests, based on a polling model: callers poll for unclaimed requests with
getBuildRequests, and then they attempt to claim the requests withclaimBuildRequests. The claim can fail if another master has claimed the request in the interim.An instance of this class is available at
master.db.buildrequests.Build requests are indexed by an ID referred to as a brid. The contents of a request are represented by a
BuildRequestModeldataclass with the following fields:buildrequestidbuildsetidbuilderidbuildernamepriorityclaimed(boolean, true if the request is claimed)claimed_at(datetime object, time this request was last claimed)claimed_by_masterid(integer, the id of the master that claimed this buildrequest)complete(boolean, true if the request is complete)complete_at(datetime object, time this request was completed)submitted_at(datetime object, time this request was completed)results(integer result code)waited_for(boolean)
- getBuildRequest(brid)
- Parameters:
brid – build request id to look up
- Returns:
BuildRequestModelorNone, via Deferred
Get a single BuildRequest, in the format described above. This method returns
Noneif there is no such buildrequest. Note that build requests are not cached, as the values in the database are not fixed.
- getBuildRequests(buildername=None, complete=None, claimed=None, bsid=None, branch=None, repository=None, resultSpec=None)
- Parameters:
buildername (string) – limit results to buildrequests for this builder
complete – if true, limit to completed buildrequests; if false, limit to incomplete buildrequests; if
None, do not limit based on completion.claimed – see below
bsid – see below
repository – the repository associated with the sourcestamps originating the requests
branch – the branch associated with the sourcestamps originating the requests
resultSpec – resultSpec containing filters sorting and paging request from data/REST API. If possible, the db layer can optimize the SQL query using this information.
- Returns:
list of
BuildRequestModel, via Deferred
Get a list of build requests matching the given characteristics.
Pass all parameters as keyword parameters to allow future expansion.
The
claimedparameter can beNone(the default) to ignore the claimed status of requests;Trueto return only claimed builds,Falseto return only unclaimed builds, or amaster IDto return only builds claimed by a particular master instance. A request is considered unclaimed if itsclaimed_atcolumn is either NULL or 0, and it is not complete. Ifbsidis specified, then only build requests for that buildset will be returned.A build is considered completed if its
completecolumn is 1; thecomplete_atcolumn is not consulted.
- claimBuildRequests(brids[, claimed_at=XX])
- Parameters:
brids (list) – ids of buildrequests to claim
claimed_at (datetime) – time at which the builds are claimed
- Returns:
Deferred
- Raises:
Try to “claim” the indicated build requests for this buildmaster instance. The resulting deferred will fire normally on success, or fail with
AlreadyClaimedErrorif any of the build requests are already claimed by another master instance. In this case, none of the claims will take effect.If
claimed_atis not given, then the current time will be used.Note
On database backends that do not enforce referential integrity (e.g., SQLite), this method will not prevent claims for nonexistent build requests. On database backends that do not support transactions (MySQL), this method will not properly roll back any partial claims made before an
AlreadyClaimedErroris generated.
- unclaimBuildRequests(brids)
- Parameters:
brids (list) – ids of buildrequests to unclaim
- Returns:
Deferred
Release this master’s claim on all of the given build requests. This will not unclaim requests that are claimed by another master, but will not fail in this case. The method does not check whether a request is completed.
- completeBuildRequests(brids, results[, complete_at=XX])
- Parameters:
brids (integer) – build request ids to complete
results (integer) – integer result code
complete_at (datetime) – time at which the buildset was completed
- Returns:
Deferred
- Raises:
Complete a set of build requests, all of which are owned by this master instance. This will fail with
NotClaimedErrorif the build request is already completed or does not exist. Ifcomplete_atis not given, the current time will be used.
3.8.3. Builders connector
- class buildbot.db.builders.BuildersConnectorComponent
This class handles the relationship between builder names and their IDs, as well as tracking which masters are configured for this builder.
Builders are represented by a
BuilderModeldataclass with the following fields:id– the ID of this buildername– the builder namedescription– the builder’s description (optional)description_format– the format of builder’s description (optional)description_html– the builder description rendered as html (optional, depends ondescription_format)projectid– the builder’s projecttags– the builder’s tagsmasterids– the IDs of the masters where this builder is configured (sorted by id)
- findBuilderId(name, autoCreate=True)
- Parameters:
name (string) – name of this builder
autoCreate (bool) – automatically create the builder if name not found
- Returns:
builder id via Deferred
Return the builder ID for the builder with this builder name. If such a builder is already in the database, this returns the ID. If not and
autoCreateis True, the builder is added to the database.
- addBuilderMaster(builderid=None, masterid=None)
- Parameters:
builderid (integer) – the builder
masterid (integer) – the master
- Returns:
Deferred
Add the given master to the list of masters on which the builder is configured. This will do nothing if the master and builder are already associated.
- removeBuilderMaster(builderid=None, masterid=None)
- Parameters:
builderid (integer) – the builder
masterid (integer) – the master
- Returns:
Deferred
Remove the given master from the list of masters on which the builder is configured.
- getBuilder(builderid)
- Parameters:
builderid (integer) – the builder to check in
- Returns:
BuilderModelor None via Deferred
Get the indicated builder.
- getBuilders(masterid=None, projectid=None, workerid=None)
- Parameters:
masterid (integer) – ID of the master to which the results should be limited
masterid – ID of the project to which the results should be limited
workerid (integer) – ID of the configured worker to which the results should be limited
- Returns:
list of
BuilderModelvia Deferred
Get all builders (in unspecified order). If
masteridis specified, then only builders configured on that master are returned. Ifprojectidis specified, then only builders for a particular project are returned. Ifworkeridis specified, then only builders for a particular configured worker are returned.
3.8.4. Builds connector
- class buildbot.db.builds.BuildsConnectorComponent
This class handles builds. One build record is created for each build performed by a master. This record contains information on the status of the build, as well as links to the resources used in the build: builder, master, worker, etc.
An instance of this class is available at
master.db.builds.Builds are indexed by buildid and their contents represented as
BuildModeldataclass, with the following fields:id(the build ID, globally unique)number(the build number, unique only within the builder)builderid(the ID of the builder that performed this build)buildrequestid(the ID of the build request that caused this build)workerid(the ID of the worker on which this build was performed)masterid(the ID of the master on which this build was performed)started_at(datetime at which this build began)complete_at(datetime at which this build finished, or None if it is ongoing)locks_duration_s(the amount of time spent acquiring locks so far, not including any running steps)state_string(short string describing the build’s state)results(results of this build; see Build Result Codes)
- getBuild(buildid)
- Parameters:
buildid (integer) – build id
- Returns:
BuildModelorNone, via Deferred
Get a single build, in the format described above. Returns
Noneif there is no such build.
- getBuildByNumber(builderid, number)
- Parameters:
builder (integer) – builder id
number (integer) – build number within that builder
- Returns:
BuildModelorNone, via Deferred
Get a single build, in the format described above, specified by builder and number, rather than build id. Returns
Noneif there is no such build.
- getPrevSuccessfulBuild(builderid, number, ssBuild)
- Parameters:
builderid (integer) – builder to get builds for
number (integer) – the current build number. Previous build will be taken from this number
ssBuild (list) – the list of sourcestamps for the current build number
- Returns:
BuildModelorNone, via Deferred
Returns the last successful build from the current build number with the same repository, branch, or codebase.
- getBuilds(builderid=None, buildrequestid=None, complete=None, resultSpec=None)
- Parameters:
builderid (integer) – builder to get builds for
buildrequestid (integer) – buildrequest to get builds for
complete (boolean) – if not None, filters results based on completeness
resultSpec – result spec containing filters sorting and paging requests from data/REST API. If possible, the db layer can optimize the SQL query using this information.
- Returns:
list of
BuildModel, via Deferred
Get a list of builds, in the format described above. Each of the parameters limits the resulting set of builds.
- addBuild(builderid, buildrequestid, workerid, masterid, state_string)
- Parameters:
builderid (integer) – builder to get builds for
buildrequestid (integer) – build request id
workerid (integer) – worker performing the build
masterid (integer) – master performing the build
state_string (unicode) – initial state of the build
- Returns:
tuple of build ID and build number, via Deferred
Add a new build to the db, recorded as having started at the current time. This will invent a new number for the build, unique within the context of the builder.
- setBuildStateString(buildid, state_string):
- Parameters:
buildid (integer) – build id
state_string (unicode) – updated state of the build
- Returns:
Deferred
Update the state strings for the given build.
- add_build_locks_duration(buildid, duration_s):
- Parameters:
buildid (integer) – build id
duration_s (integer) – time duration to add
- Returns:
Deferred
Adds the given duration to the
locks_duration_sfield of the build.
- finishBuild(buildid, results)
- Parameters:
buildid (integer) – build id
results (integer) – build result
- Returns:
Deferred
Mark the given build as finished, with
complete_atset to the current time.Note
This update is done unconditionally, even if the build is already finished.
- getBuildProperties(buildid, resultSpec=None)
- Parameters:
buildid – build ID
resultSpec – resultSpec
- Returns:
dictionary mapping property name to
value, source, via Deferred
Return the properties for a build, in the same format they were given to
addBuild. Optional filtering via resultSpec is available and optimized in the db layer.Note that this method does not distinguish a non-existent build from a build with no properties, and returns
{}in either case.
- setBuildProperty(buildid, name, value, source)
- Parameters:
buildid (integer) – build ID
name (string) – Name of the property to set
value – Value of the property
source (string) – Source of the Property to set
- Returns:
Deferred
Set a build property. If no property with that name existed in that build, a new property will be created.
3.8.5. Build data connector
- class buildbot.db.build_data.BuildDataConnectorComponent
This class handles build data. Build data is potentially large transient text data attached to the build that the steps can use for their operations. One of the use cases is to carry large amount of data from one step to another where storing that data on the worker is not feasible. This effectively forms a key-value store for each build. It is valid only until the build finishes and all reporters are done reporting the build result. After that the data may be removed from the database.
An instance of this class is available at
master.db.build_data.Builds are indexed by build_dataid and their contents represented as
BuildDataModeldataclass, with the following fields:id(the build data ID, globally unique)buildid(the ID of the build that the data is attached to)name(the name of the data)value(the value of the data. It must be an instance ofbytes. Can beNonewhen queried withgetBuildDataNoValue)source(an string identifying the source of this value)
- setBuildData(buildid, name, value, source)
- Parameters:
buildid (integer) – build id to attach data to
name (unicode) – the name of the data
value (bytestr) – the value of the data as
bytes.
- Parma unicode source:
the source of the data
- Returns:
Deferred
Adds or replaces build data attached to the build.
- getBuildData(buildid, name)
- Parameters:
buildid (integer) – build id retrieve data for
name (unicode) – the name of the data
- Returns:
BuildDataModelorNone, via Deferred
Get a single build data, in the format described above, specified by build and by name. Returns
Noneif build has no data with such name.
- getBuildDataNoValue(buildid, name)
- Parameters:
buildid (integer) – build id retrieve data for
name (unicode) – the name of the data
- Returns:
BuildDataModelorNone, via Deferred
Get a single build data, in the format described above, specified by build and by name. The
valuefield is omitted. ReturnsNoneif build has no data with such name.
- getAllBuildDataNoValues(buildid, name=None)
- Parameters:
buildid (integer) – build id retrieve data for
name (unicode) – the name of the data
- Returns:
a list of
BuildDataModel
Returns all data for a specific build. The values are not loaded. The returned values can be filtered by name
- deleteOldBuildData(older_than_timestamp)
- Parameters:
older_than_timestamp (integer) – the build data whose build’s
complete_atis older thanolder_than_timestampwill be deleted.- Returns:
Deferred
Delete old build data (helper for the
build_data_horizonpolicy). Old logs have their build data deleted from the database as they are only useful while build is running and shortly afterwards.
3.8.6. Steps connector
- class buildbot.db.steps.StepsConnectorComponent
This class handles the steps performed within the context of a build. Within a build, each step has a unique name and a unique 0-based number.
An instance of this class is available at
master.db.steps.Steps are indexed by stepid and are represented by a
StepModeldataclass with the following fields:id(the step ID, globally unique)number(the step number, unique only within the build)name(the step name, an 50-character identifier unique only within the build)buildid(the ID of the build containing this step)started_at(datetime at which this step began)locks_atquired_at(datetime at which this step acquired or None if the step has not yet acquired locks)complete_at(datetime at which this step finished, or None if it is ongoing)state_string(short string describing the step’s state)results(results of this step; see Build Result Codes)urls(list of URLs produced by this step. Each urls is stored as aUrlModeldataclass)hidden(true if the step should be hidden in status displays)
Urls are represented by a
UrlModeldataclass with the following fields:nameurl
- getStep(stepid=None, buildid=None, number=None, name=None)
- Parameters:
stepid (integer) – the step id to retrieve
buildid (integer) – the build from which to get the step
number (integer) – the step number
name (50-character identifier) – the step name
- Returns:
StepModelorNonevia Deferred
Get a single step. The step can be specified by:
stepidalonebuildidandnumber, the step number within that buildbuildidandname, the unique step name within that build
- getSteps(buildid)
- Parameters:
buildid (integer) – the build from which to get the step
- Returns:
list of
StepModel, sorted by number, via Deferred
Get all steps in the given build, ordered by number.
- addStep(self, buildid, name, state_string)
- Parameters:
buildid (integer) – the build to which to add the step
name (50-character identifier) – the step name
state_string (unicode) – the initial state of the step
- Returns:
tuple of step ID, step number, and step name, via Deferred
Add a new step to a build. The given name will be used if it is unique; otherwise, a unique numerical suffix will be appended.
- setStepStateString(stepid, state_string):
- Parameters:
stepid (integer) – step ID
state_string (unicode) – updated state of the step
- Returns:
Deferred
Update the state string for the given step.
- finishStep(stepid, results, hidden)
- Parameters:
stepid (integer) – step ID
results (integer) – step result
hidden (bool) – true if the step should be hidden
- Returns:
Deferred
Mark the given step as finished, with
complete_atset to the current time.Note
This update is done unconditionally, even if the steps are already finished.
- addURL(self, stepid, name, url)
- Parameters:
stepid (integer) – the stepid to add the url.
name (string) – the url name
url (string) – the actual url
- Returns:
None via deferred
Add a new url to a step. The new url is added to the list of urls.
3.8.7. Logs connector
- class buildbot.db.logs.LogsConnectorComponent
This class handles log data. Build steps can have zero or more logs. Logs are uniquely identified by name within a step.
Information about a log, apart from its contents, is represented as a
LogModeldataclass with the following fields:id(log ID, globally unique)stepid(step ID, indicating the containing step)namefree-form name of this logslug(50-identifier for the log, unique within the step)complete(true if the log is complete and will not receive more lines)num_lines(number of lines in the log)type(log type; see below)
Each log has a type that describes how to interpret its contents. See the
logchunkresource type for details.A log contains a sequence of newline-separated lines of unicode. Log line numbering is zero-based.
Each line must be less than 64k when encoded in UTF-8. Longer lines will be truncated, and a warning will be logged.
Lines are stored internally in “chunks”, and optionally compressed, but the implementation hides these details from callers.
- getLog(logid)
- Parameters:
logid (integer) – ID of the requested log
- Returns:
LogModelorNone, via Deferred
Get a log, identified by logid.
- getLogBySlug(stepid, slug)
- Parameters:
stepid (integer) – ID of the step containing this log
slug – slug of the logfile to retrieve
- Returns:
LogModelorNone, via Deferred
Get a log, identified by name within the given step.
- getLogs(stepid)
- Parameters:
stepid (integer) – ID of the step containing the desired logs
- Returns:
list of
LogModelvia Deferred
Get all logs within the given step.
- iter_log_lines(logid, first_line, last_line)
- Parameters:
logid (integer) – ID of the log
first_line – first line to return
last_line – last line to return
- Returns:
an AsyncGenerator of the chunks content (as str)
Get a subset of lines for a logfile.
yield lines (including line-ending).
- getLogLines(logid, first_line, last_line)
- Parameters:
logid (integer) – ID of the log
first_line – first line to return
last_line – last line to return
- Returns:
see below
Get a subset of lines for a logfile.
The return value, via Deferred, is a concatenation of newline-terminated strings. If the requested last line is beyond the end of the logfile, only existing lines will be included. If the log does not exist, or has no associated lines, this method returns an empty string.
- addLog(stepid, name, type)
- Parameters:
stepid (integer) – ID of the step containing this log
name (string) – name of the logfile
slug (50-character identifier) – slug (unique identifier) of the logfile
type (string) – log type (see above)
- Raises:
KeyError – if a log with the given slug already exists in the step
- Returns:
ID of the new log, via Deferred
Add a new log file to the given step.
- appendLog(logid, content)
- Parameters:
logid (integer) – ID of the requested log
content (string) – new content to be appended to the log
- Returns:
tuple of first and last line numbers in the new chunk, via Deferred
Append content to an existing log. The content must end with a newline. If the given log does not exist, the method will silently do nothing.
It is not safe to call this method more than once simultaneously for the same
logid.
- finishLog(logid)
- Parameters:
logid (integer) – ID of the log to mark complete
- Returns:
Deferred
Mark a log as complete.
Note that no checking for completeness is performed when appending to a log. It is up to the caller to avoid further calls to
appendLogafterfinishLog.
- compressLog(logid)
- Parameters:
logid (integer) – ID of the log to compress
- Returns:
Deferred
Compress the given log. This method performs internal optimizations on a log’s chunks to reduce the space used and make read operations more efficient. It should only be called for finished logs. This method may take some time to complete.
- deleteOldLogChunks(older_than_timestamp)
- Parameters:
older_than_timestamp (integer) – the logs whose step’s
started_atis older thanolder_than_timestampwill be deleted.- Returns:
Deferred
Delete old logchunks (helper for the
logHorizonpolicy). Old logs have their logchunks deleted from the database, but they keep theirnum_linesmetadata. They have their types changed to ‘d’, so that the UI can display something meaningful.
3.8.8. Changes connector
- class buildbot.db.changes.ChangesConnectorComponent
This class handles changes in the Buildbot database, including pulling information from the changes sub-tables.
An instance of this class is available at
master.db.changes.Changes are indexed by changeid, and are represented by a
ChangeModeldataclass, which has the following fields:changeid(the ID of this change)parent_changeids(list of ID; change’s parents)author(unicode; the author of the change)committer(unicode; the committer of the change)files(list of unicode; source-code filenames changed)comments(unicode; user comments)is_dir(deprecated)links(list of unicode; links for this change, e.g., to web views, review)revision(unicode string; revision for this change, orNoneif unknown)when_timestamp(datetime instance; time of the change)branch(unicode string; branch on which the change took place, orNonefor the “default branch”, whatever that might mean)category(unicode string; user-defined category of this change, orNone)revlink(unicode string; link to a web view of this change)properties(user-specified properties for this change, represented as a dictionary mapping keys to (value, source))repository(unicode string; repository where this change occurred)project(unicode string; user-defined project to which this change corresponds)
- getParentChangeIds(branch, repository, project, codebase)
- Parameters:
branch (unicode string) – the branch of the change
repository (unicode string) – the repository in which this change took place
project (unicode string) – the project this change is a part of
codebase (unicode string)
- Returns:
the last changeID that matches the branch, repository, project, or codebase
- addChange(author=None, committer=None, files=None, comments=None, is_dir=0, links=None, revision=None, when_timestamp=None, branch=None, category=None, revlink='', properties={}, repository='', project='', uid=None)
- Parameters:
author (unicode string) – the author of this change
committer (unicode string) – the committer of this change
files – a list of filenames that were changed
comments – user comments on the change
is_dir – deprecated
links (list of unicode strings) – a list of links related to this change, e.g., to web viewers or review pages
revision (unicode string) – the revision identifier for this change
when_timestamp (datetime instance or None) – when this change occurred, or the current time if None
branch (unicode string) – the branch on which this change took place
category (unicode string) – category for this change (arbitrary use by Buildbot users)
revlink (unicode string) – link to a web view of this revision
properties (dictionary) – properties to set on this change, where values are tuples of (value, source). At the moment, the source must be
'Change', although this may be relaxed in later versionsrepository (unicode string) – the repository in which this change took place
project (unicode string) – the project this change is a part of
uid (integer) – uid generated for the change author
- Returns:
new change’s ID via Deferred
Add a Change with the given attributes to the database, returning the changeid via a Deferred. All arguments should be given as keyword arguments.
The
projectandrepositoryarguments must be strings;Noneis not allowed.
- getChange(changeid, no_cache=False)
- Parameters:
changeid – the id of the change instance to fetch
no_cache (boolean) – bypass cache and always fetch from database
- Returns:
ChangeModelor None, via Deferred
Get a
ChangeModelfor the given changeid, orNoneif no such change exists.
- getChangeUids(changeid)
- Parameters:
changeid – the id of the change instance to fetch
- Returns:
list of uids via Deferred
Get the userids associated with the given changeid.
- getChanges(resultSpec=None)
- Parameters:
resultSpec – result spec containing filters sorting and paging requests from data/REST API. If possible, the db layer can optimize the SQL query using this information.
- Returns:
list of
ChangeModelvia Deferred
Get a list of the changes, represented as
ChangeModel, matching the given criteria. ifresultSpecis not provided, changes are sorted, and paged using generic data query options.
- getChangesCount()
- Returns:
list of dictionaries via Deferred
Get the number of changes that the query option would return if no paging option was set.
- getLatestChangeid()
- Returns:
changeid via Deferred
Get the most-recently-assigned changeid, or
Noneif there are no changes at all.
- getChangesForBuild(buildid)
- Parameters:
buildid – ID of the build
- Returns:
list of
ChangeModelvia Deferred
Get the “blame” list of changes for a build.
- getBuildsForChange(changeid)
- Parameters:
changeid – ID of the change
- Returns:
list of
ChangeModelvia Deferred
Get builds related to a change.
- getChangeFromSSid(sourcestampid)
- Parameters:
sourcestampid – ID of the sourcestampid
- Returns:
ChangeModelvia Deferred
Returns the
ChangeModelrelated to the sourcestamp ID.
3.8.9. Change sources connector
- exception buildbot.db.changesources.ChangeSourceAlreadyClaimedError
Raised when a changesource request is already claimed by another master.
- class buildbot.db.changesources.ChangeSourcesConnectorComponent
This class manages the state of the Buildbot changesources.
An instance of this class is available at
master.db.changesources.Changesources are identified by their changesourceid, which can be obtained from
findChangeSourceId.Changesources are represented as
ChangeSourceModeldataclass with the following fields:id- changesource’s IDname- changesource’s namemasterid- ID of the master currently running this changesource, or None if it is inactive
Note that this class is conservative in determining what changesources are inactive: a changesource linked to an inactive master is still considered active. This situation should never occur, however; links to a master should be deleted when it is marked inactive.
- findChangeSourceId(name)
- Parameters:
name – changesource name
- Returns:
changesource ID via Deferred
Return the changesource ID for the changesource with this name. If such a changesource is already in the database, this returns the ID. If not, the changesource is added to the database and its ID returned.
- setChangeSourceMaster(changesourceid, masterid)
- Parameters:
changesourceid – changesource to set the master for
masterid – new master for this changesource, or None
- Returns:
Deferred
Set, or unset if
masteridis None, the active master for this changesource. If no master is currently set, or the current master is not active, this method will complete without error. If the current master is active, this method will raiseChangeSourceAlreadyClaimedError.
- getChangeSource(changesourceid)
- Parameters:
changesourceid – changesource ID
- Returns:
ChangeSourceModelor None, via Deferred
Get the changesource dictionary for the given changesource.
- getChangeSources(active=None, masterid=None)
- Parameters:
active (boolean) – if specified, filter for active or inactive changesources
masterid (integer) – if specified, only return changesources attached associated with this master
- Returns:
list of
ChangeSourceModelin unspecified order
Get a list of changesources.
If
activeis given, changesources are filtered according to whether they are active (true) or inactive (false). An active changesource is one that is claimed by an active master.If
masteridis given, the list is restricted to schedulers associated with that master.
3.8.10. Schedulers connector
- exception buildbot.db.schedulers.SchedulerAlreadyClaimedError
Raised when a scheduler request is already claimed by another master.
- class buildbot.db.schedulers.SchedulersConnectorComponent
This class manages the state of the Buildbot schedulers. This state includes classifications of as-yet un-built changes.
An instance of this class is available at
master.db.schedulers.Schedulers are identified by their schedulerid, which can be obtained from
findSchedulerId.Schedulers are represented as
SchedulerModeldataclass with the following fields:id- scheduler’s IDname- scheduler’s nameenabled- scheduler’s statusmasterid- ID of the master currently running this scheduler, or None if it is inactive
Note that this class is conservative in determining what schedulers are inactive: a scheduler linked to an inactive master is still considered active. This situation should never occur, however; links to a master should be deleted when it is marked inactive.
- classifyChanges(objectid, classifications)
- Parameters:
schedulerid – ID of the scheduler classifying the changes
classifications (dictionary) – mapping of changeid to boolean, where the boolean is true if the change is important, and false if it is unimportant
- Returns:
Deferred
Record the given classifications. This method allows a scheduler to record which changes were important and which were not immediately, even if the build based on those changes will not occur for some time (e.g., a tree stable timer). Schedulers should be careful to flush classifications once they are no longer needed, using
flushChangeClassifications.
- flushChangeClassifications(objectid, less_than=None)
- Parameters:
schedulerid – ID of the scheduler owning the flushed changes
less_than – (optional) lowest changeid that should not be flushed
- Returns:
Deferred
Flush all scheduler_changes for the given scheduler, limiting to those with changeid less than
less_thanif the parameter is supplied.
- getChangeClassifications(objectid[, branch])
- Parameters:
schedulerid (integer) – ID of scheduler to look up changes for
branch (string or None (for default branch)) – (optional) limit to changes with this branch
- Returns:
dictionary via Deferred
Return the classifications made by this scheduler, in the form of a dictionary mapping changeid to a boolean, just as supplied to
classifyChanges.If
branchis specified, then only changes on that branch will be given. Note that specifyingbranch=Nonerequests changes for the default branch, and is not the same as omitting thebranchargument altogether.
- findSchedulerId(name)
- Parameters:
name – scheduler name
- Returns:
scheduler ID via Deferred
Return the scheduler ID for the scheduler with this name. If such a scheduler is already in the database, this returns the ID. If not, the scheduler is added to the database and its ID is returned.
- setSchedulerMaster(schedulerid, masterid)
- Parameters:
schedulerid – scheduler to set the master for
masterid – new master for this scheduler, or None
- Returns:
Deferred
Set, or unset if
masteridis None, the active master for this scheduler. If no master is currently set, or the current master is not active, this method will complete without error. If the current master is active, this method will raiseSchedulerAlreadyClaimedError.
- getScheduler(schedulerid)
- Parameters:
schedulerid – scheduler ID
- Returns:
SchedulerModelModelor None via Deferred
Get the
SchedulerModelModelfor the given scheduler.
- getSchedulers(active=None, masterid=None)
- Parameters:
active (boolean) – if specified, filter for active or inactive schedulers
masterid (integer) – if specified, only return schedulers attached associated with this master
- Returns:
list of
SchedulerModelModelin unspecified order
Get a list of schedulers.
If
activeis given, schedulers are filtered according to whether they are active (true) or inactive (false). An active scheduler is one that is claimed by an active master.If
masteridis given, the list is restricted to schedulers associated with that master.
3.8.11. Source stamps connector
- class buildbot.db.sourcestamps.SourceStampsConnectorComponent
This class manages source stamps, as stored in the database. A source stamp uniquely identifies a particular version of a single codebase. Source stamps are identified by their ID. It is safe to use sourcestamp ID equality as a proxy for source stamp equality. For example, all builds of a particular version of a codebase will share the same sourcestamp ID. This equality does not extend to patches: two sourcestamps generated with exactly the same patch will have different IDs.
Relative source stamps have a
revisionof None, meaning “whatever the latest is when this sourcestamp is interpreted”. While such source stamps may correspond to a wide array of revisions over the lifetime of a Buildbot installation, they will only ever have one ID.An instance of this class is available at
master.db.sourcestamps.Sourcestamps are represented by a
SourceStampModeldataclass with the following fields:ssidbranch(branch, orNonefor default branch)revision(revision, orNoneto indicate the latest revision, inwhich case this is a relative source stamp)
repository(repository containing the source; neverNone)created_at(timestamp when this stamp was first created)codebase(codebase this stamp is in; neverNone)project(project this source is for; neverNone)patch(aPatchModelorNone, see below)
PatchModelpatchid(ID of the patch)body(body of the patch, orNone)level(directory stripping level of the patch, orNone)subdir(subdirectory in which to apply the patch, orNone)author(author of the patch, orNone)comment(comment for the patch, orNone)
Note that the patch body is a bytestring, not a unicode string.
- findSourceStampId(branch=None, revision=Node, repository=None, project=None, patch_body=None, patch_level=None, patch_author=None, patch_comment=None, patch_subdir=None)
- Parameters:
branch (unicode string or None)
revision (unicode string or None)
repository (unicode string or None)
project (unicode string or None)
codebase (unicode string (required))
patch_body (bytes or unicode string or None) – patch body
patch_level (integer or None) – patch level
patch_author (unicode string or None) – patch author
patch_comment (unicode string or None) – patch comment
patch_subdir (unicode string or None) – patch subdir
- Returns:
ssid, via Deferred
Create a new SourceStamp instance with the given attributes, or find an existing one. In either case, return its ssid. The arguments all have the same meaning as in an
SourceStampModel.If a new SourceStamp is created, its
created_atis set to the current time.
- getSourceStamp(ssid)
- Parameters:
ssid – sourcestamp to get
no_cache (boolean) – bypass cache and always fetch from database
- Returns:
SourceStampModel, orNone, via Deferred
Get an
SourceStampModelrepresenting the given source stamp, orNoneif no such source stamp exists.
- getSourceStamps()
- Returns:
list of
SourceStampModel, via Deferred
Get all sourcestamps in the database. You probably don’t want to do this! This method will be extended to allow appropriate filtering.
- get_sourcestamps_for_buildset(buildsetid)
- Parameters:
buildsetid – buildset ID
- Returns:
list of
SourceStampModel, via Deferred
Get sourcestamps related to a buildset.
- getSourceStampsForBuild(buildid)
- Parameters:
buildid – build ID
- Returns:
list of
SourceStampModel, via Deferred
Get sourcestamps related to a build.
3.8.12. State connector
- class buildbot.db.state.StateConnectorComponent
This class handles maintaining arbitrary key-value state for Buildbot objects. Each object can store arbitrary key-value pairs, where the values are any JSON-encodable value. Each pair can be set and retrieved atomically.
Objects are identified by their (user-visible) name and their class. This allows, for example, a
nightly_smoketestobject of classNightlySchedulerto maintain its state even if it moves between masters, but avoids cross-contaminating state between different classes of objects with the same name.Note that “class” is not interpreted literally, and can be any string that will uniquely identify the class for the object; if classes are renamed, they can continue to use the old names.
An instance of this class is available at
master.db.state.Objects are identified by objectid.
- getObjectId(name, class_name)
- Parameters:
name – name of the object
class_name – object class name
- Returns:
the objectid, via a Deferred.
Get the object ID for this combination of name and class. This will add a row to the ‘objects’ table if none exists already.
- getState(objectid, name[, default])
- Parameters:
objectid – objectid on which the state should be checked
name – name of the value to retrieve
default – (optional) value to return if
nameis not present
- Returns:
state value via a Deferred
- Raises:
KeyError – if
nameis not present and no default is given- Raises:
TypeError if JSON parsing fails
Get the state value for key
namefor the object with idobjectid.
- setState(objectid, name, value)
- Parameters:
objectid – the objectid for which the state should be changed
name – the name of the value to change
value (JSON-able value) – the value to set
returns – value actually written via Deferred
- Raises:
TypeError if JSONification fails
Set the state value for
namefor the object with idobjectid, overwriting any existing value. In case of two racing writes, the first (as per db rule) one wins, the seconds returns the value from the first.
- atomicCreateState(objectid, name, thd_create_callback)
- Parameters:
objectid – the objectid for which the state should be created
name – the name of the value to create
thd_create_callback – the function to call from thread to create the value if non-existent. (returns JSON-able value)
returns – Deferred
- Raises:
TypeError if JSONification fails
Atomically creates the state value for
namefor the object with idobjectid. If there is an existing value, returns that instead. This implementation ensures the state is created only once for the whole cluster.
Those 3 methods have their threaded equivalent,
thdGetObjectId,thdGetState,thdSetStatethat is intended to run in synchronous code, (e.g master.cfg environment).
3.8.13. Users connector
- class buildbot.db.users.UsersConnectorComponent
This class handles Buildbot’s notion of users. Buildbot tracks the usual information about users – username and password, plus a display name.
The more complicated task is to recognize each user across multiple interfaces with Buildbot. For example, a user may be identified as ‘djmitche’ in Subversion, ‘dustin@v.igoro.us’ in Git, and ‘dustin’ on IRC. To support this functionality, each user has a set of attributes, keyed by type. The
findUserByAttrmethod uses these attributes to match users, adding a new user if no matching user is found.Users are identified canonically by uid, and are represented by a
UserModeldataclass with the following fields:uididentifier(display name for the user)bb_username(buildbot login username)bb_password(hashed login password)attributes(a dictionary of attributes, keyed by type)
- findUserByAttr(identifier, attr_type, attr_data)
- Parameters:
identifier – identifier to use for a new user
attr_type – attribute type to search for and/or add
attr_data – attribute data to add
- Returns:
userid via Deferred
Get an existing user, or add a new one, based on the given attribute.
This method is intended for use by other components of Buildbot to search for a user with the given attributes.
Note that
identifieris not used in the search for an existing user. It is only used when creating a new user. The identifier should be based deterministically on the attributes supplied, in some fashion that will seem natural to users.For future compatibility, always use keyword parameters to call this method.
- getUser(uid)
- Parameters:
uid – user id to look up
no_cache (boolean) – bypass cache and always fetch from database
- Returns:
UserModelorNonevia Deferred
Get a
UserModelfor the given user, orNoneif no matching user is found.
- getUserByUsername(username)
- Parameters:
username (string) – username portion of user credentials
- Returns:
UserModelor None via deferred
Looks up the user with the bb_username, returning a
UserModelorNoneif no matching user is found.
- getUsers()
- Returns:
list of
UserModelwithoutattributesvia Deferred
Get the entire list of users. User attributes are not included, so the
attributesfield of the resultingUserModelareNone.
- updateUser(uid=None, identifier=None, bb_username=None, bb_password=None, attr_type=None, attr_data=None)
- Parameters:
uid (int) – the user to change
identifier (string) – (optional) new identifier for this user
bb_username (string) – (optional) new buildbot username
bb_password (string) – (optional) new hashed buildbot password
attr_type (string) – (optional) attribute type to update
attr_data (string) – (optional) value for
attr_type
- Returns:
Deferred
Update information about the given user. Only the specified attributes are updated. If no user with the given uid exists, the method will return silently.
Note that
bb_passwordmust be given ifbb_usernameappears; similarly,attr_typerequiresattr_data.
- removeUser(uid)
- Parameters:
uid (int) – the user to remove
- Returns:
Deferred
Remove the user with the given uid from the database. This will remove the user from any associated tables as well.
- identifierToUid(identifier)
- Parameters:
identifier (string) – identifier to search for
- Returns:
uid or
None, via Deferred
Fetch a uid for the given identifier, if one exists.
3.8.14. Masters connector
- class buildbot.db.masters.MastersConnectorComponent
This class handles tracking the buildmasters in a multi-master configuration. Masters “check in” periodically. Other masters monitor the last activity times, and mark masters that have not recently checked in as inactive.
Masters are represented by a
MasterModeldataclass with the following fields:id– the ID of this mastername– the name of the master (generally of the formhostname:basedir)active– true if this master is runninglast_active– time that this master last checked in (a datetime object)
- findMasterId(name)
- Parameters:
name (unicode) – name of this master
- Returns:
master id via Deferred
Return the master ID for the master with this master name (generally
hostname:basedir). If such a master is already in the database, this returns the ID. If not, the master is added to the database, withactive=False, and its ID returned.
- setMasterState(masterid, active)
- Parameters:
masterid (integer) – the master to check in
active (boolean) – whether to mark this master as active or inactive
- Returns:
boolean via Deferred
Mark the given master as active or inactive, returning true if the state actually changed. If
activeis true, thelast_activetime is updated to the current time. Ifactiveis false, then any links to this master, such as schedulers, will be deleted.
- getMaster(masterid)
- Parameters:
masterid (integer) – the master to check in
- Returns:
MasterModelor None via Deferred
Get the indicated master.
- getMasters()
- Returns:
list of
MasterModelvia Deferred
Get a list of the masters, represented as
MasterModel; masters are sorted and paged using generic data query options
- setAllMastersActiveLongTimeAgo()
- Returns:
None via Deferred
This method is intended to be called by upgrade-master, and will effectively force housekeeping on all masters at next startup. This method is not intended to be called outside of housekeeping scripts.
3.8.15. Workers connector
- class buildbot.db.workers.WorkersConnectorComponent
This class handles Buildbot’s notion of workers. The worker information is returned as a
WorkerModeldataclass with the following fields:idname- the name of the workerworkerinfo- worker information as dictionarypaused- boolean indicating worker is paused and shall not take new buildspause_reason- string indicating the reason for working being pausedgraceful- boolean indicating worker will be shutdown as soon as build finishedconnected_to- a list of masters, by ID, to which this worker is currently connected. This list will typically contain only one master, but in unusual circumstances the same worker may appear to be connected to multiple masters simultaneouslyconfigured_on- a list of master-builder pairs, on which this worker is configured. Each pair is represented by aBuilderMasterModelwith fieldsbulideridandmasterid
The worker information can be any JSON-able object. See
workerfor more detail.- findWorkerId(name=name)
- Parameters:
name (50-character identifier) – worker name
- Returns:
worker ID via Deferred
Get the ID for a worker, adding a new worker to the database if necessary. The worker information for a new worker is initialized to an empty dictionary.
- getWorkers(masterid=None, builderid=None)
- Parameters:
masterid (integer) – limit to workers configured on this master
builderid (integer) – limit to workers configured on this builder
- Returns:
list of
WorkerModel, via Deferred
Get a list of workers. If either or both of the filtering parameters either specified, then the result is limited to workers configured to run on that master or builder. The
configured_onresults are limited by the filtering parameters as well. Theconnected_toresults are limited by themasteridparameter.
- getWorker(workerid=None, name=None, masterid=None, builderid=None)
- Parameters:
name (string) – the name of the worker to retrieve
workerid (integer) – the ID of the worker to retrieve
masterid (integer) – limit to workers configured on this master
builderid (integer) – limit to workers configured on this builder
- Returns:
WorkerModelor None, via Deferred
Looks up the worker with the given name or ID, returning
Noneif no matching worker is found. Themasteridandbuilderidarguments function as they do forgetWorkers.
- workerConnected(workerid, masterid, workerinfo)
- Parameters:
workerid (integer) – the ID of the worker
masterid (integer) – the ID of the master to which it connected
workerinfo (dict) – the new worker information dictionary
- Returns:
Deferred
Record the given worker as attached to the given master, and update its cached worker information. The supplied information completely replaces any existing information.
- workerDisconnected(workerid, masterid)
- Parameters:
workerid (integer) – the ID of the worker
masterid (integer) – the ID of the master to which it connected
- Returns:
Deferred
Record the given worker as no longer attached to the given master.
- workerConfigured(workerid, masterid, builderids)
- Parameters:
workerid (integer) – the ID of the worker
masterid (integer) – the ID of the master to which it configured
builderids (list of integer) – the ID of the builders to which it is configured
- Returns:
Deferred
Record the given worker as being configured on the given master and for given builders. This method will also remove any other builder that were configured previously for same (worker, master) combination.
- deconfigureAllWorkersForMaster(masterid)
- Parameters:
masterid (integer) – the ID of the master to which it configured
- Returns:
Deferred
Unregister all the workers configured to a master for given builders. This shall happen when master is disabled or before reconfiguration.
- set_worker_paused(workerid, paused, pause_reason=None)
- Parameters:
workerid (integer) – the ID of the worker whose state is being changed
paused (integer) – the paused state
pause_reason (string) – the reason for pausing the worker.
- Returns:
Deferred
Changes the
pausedstate of the worker (see definition of states above in worker dict description).
- set_worker_graceful(workerid, graceful)
- Parameters:
workerid (integer) – the ID of the worker whose state is being changed
graceful (integer) – the graceful state
- Returns:
Deferred
Changes the
gracefulstate of the worker (see definition of states above in worker dict description).
3.9. Messaging and Queues
Buildbot uses a message-queueing structure to handle asynchronous notifications in a distributed fashion. This avoids, for the most part, the need for each master to poll the database, allowing masters to react to events as they happen.
3.9.1. Overview
Buildbot is structured as a hybrid state- and event-based application, which will probably offend adherents of either pattern. In particular, the most current state is stored in the Database, while any changes to the state are announced in the form of a message. The content of the messages is sufficient to reconstruct the updated state, allowing external processes to represent “live” state without polling the database.
This split nature immediately brings to light the problem of synchronizing the two interfaces. Queueing systems can introduce queueing delays as messages propagate. Likewise, database systems may introduce a delay between committed modifications and the modified data appearing in queries; for example, with MySQL master/slave replication, there can be several seconds’ delay before a slave is updated.
Buildbot’s MQ connector simply relays messages, and makes no attempt to coordinate the timing of those messages with the corresponding database updates. It is up to higher layers to apply such coordination.
3.9.2. Connector API
All access to the queueing infrastructure is mediated by an MQ connector. The connector’s API is
defined below. The connector itself is always available as master.mq, where master is the
current BuildMaster instance.
The connector API is quite simple. It is loosely based on AMQP, although simplified because there is only one exchange (see Queue Schema).
All messages include a “routing key”, which is a tuple of 7-bit ascii strings describing the content of the message. By convention, the first element of the tuple gives the type of the data in the message. The last element of the tuple describes the event represented by the message. The remaining elements of the tuple describe attributes of the data in the message that may be useful for filtering; for example, buildsets may usefully be filtered on buildsetids. The topics and associated message types are described below in Message Schema.
Filters are also specified with tuples. For a filter to match a routing key, it must have the same length, and each element of the filter that is not None must match the corresponding routing key element exactly.
- class buildbot.mq.base.MQConnector
This is an abstract parent class for MQ connectors, and defines the interface. It should not be instantiated directly. It is a subclass of
buildbot.util.service.AsyncService, and subclasses can override service methods to start and stop the connector.- produce(routing_key, data)
- Parameters:
routing_key (tuple) – the routing key for this message
data – JSON-serializable body of the message
This method produces a new message and queues it for delivery to any associated consumers.
The routing key and data should match one of the formats given in Message Schema.
The method returns immediately; the caller will not receive any indication of a failure to transmit the message, although errors will be displayed in
twistd.log.
- startConsuming(callback, filter[, persistent_name=name])
- Parameters:
callback – callable to invoke for matching messages
filter (tuple) – filter for routing keys of interest
persistent_name – persistent name for this consumer
- Returns:
a
QueueRefinstance via Deferred
This method will begin consuming messages matching the filter, invoking
callbackfor each message. See above for the format of the filter.The callback will be invoked with two arguments: the message’s routing key and the message body, as a Python data structure. It may return a Deferred, but no special processing other than error handling will be applied to that Deferred. In particular, note that the callback may be invoked a second time before the Deferred from the first invocation fires.
A message is considered delivered as soon as the callback is invoked - there is no support for acknowledgements or re-queueing unhandled messages.
Note that the timing of messages is implementation-dependent. It is not guaranteed that messages sent before the
startConsumingmethod completes will be received. In fact, because the registration process may not be immediate, even messages sent after the method completes may not be received.If
persistent_nameis given, then the consumer is assumed to be persistent, and consumption can be resumed with the given name. Messages that arrive when no consumer is active are queued and will be delivered when a consumer becomes active.
- waitUntilEvent(filter, check_callback)
- Parameters:
filter (tuple) – filter for routing keys of interest
check_callback (function) – a callback which check if the event has already happened
- Returns:
a Deferred that fires when the event has been received and contains a (routing_key, value) tuple representing the event
This method is a helper which returns a deferred that fires when a certain event has occurred. This is useful for waiting the end of a build or disconnection of a worker. You shall make sure when using this method that this event will happen in the future, and take care of race conditions. For this reason, the caller must provide a check_callback that will check if the event has already occurred. The whole race-condition-free process is:
Register to event
Check if it has already happened
If not, wait for the event
Unregister from event
- class buildbot.mq.base.QueueRef
The
QueueRefreturned (via Deferred) fromstartConsumingcan be used to stop consuming messages when they are no longer needed. Users should be very careful to ensure that consumption is terminated in all cases.- stopConsuming()
Stop invoking the
callbackpassed tostartConsuming. This method can be called multiple times for the sameQueueRefinstance without harm.This method potentially returns a Deferred.
After the first call to this method has returned, the callback will not be invoked.
3.9.2.1. Implementations
Several concrete implementations of the MQ connector exist. The simplest is intended for cases where only one master exists, similar to the SQLite database support. The remainder use various existing queueing applications to support distributed communications.
Simple
Wamp
- class buildbot.mq.wamp.WampMQ
The
WampMQclass implements message-queueing using a wamp router. This class translates the semantics of the Buildbot MQ API to the semantics of the wamp messaging system. The message route is translated to a wamp topic by joining with dot and prefixing with the Buildbot namespace. Here is an example message that is sent via wamp:topic = "org.buildbot.mq.builds.1.new" data = { 'builderid': 10, 'buildid': 1, 'buildrequestid': 13, 'workerid': 20, 'complete': False, 'complete_at': None, 'masterid': 824, 'number': 1, 'results': None, 'started_at': 1, 'locks_acquired_at': 2, 'state_string': u'created' }
- class buildbot.wamp.connector.WampConnector
The
WampConnectorclass implements a Buildbot service for wamp. It is managed outside of the mq module as this protocol can also be reused as a worker protocol. The connector supports queueing of requests until the wamp connection is created but does not support disconnection and reconnection. Reconnection will be supported as part of a next release of AutobahnPython (https://github.com/crossbario/autobahn-python/issues/295). There is a chicken and egg problem at the Buildbot initialization phases, so the produce messages are actually not sent with deferred.
3.9.3. Queue Schema
Buildbot uses a particularly simple architecture: in AMQP terms, all messages are sent to a single topic exchange, and consumers define anonymous queues bound to that exchange.
In future versions of Buildbot, some components (e.g., schedulers) may use durable queues to ensure that messages are not lost when one or more masters are disconnected.
3.9.4. Message Schema
This section describes the general structure messages. The specific routing keys and content of each message are described in the relevant sub-sections of Data API.
3.9.4.1. Routing Keys
Routing keys are a sequence of strings, usually written with dot separators. Routing keys are
represented with variables when one or more of the words in the key are defined by the content of
the message. For example, buildset.$bsid describes routing keys such as buildset.1984,
where 1984 is the ID of the buildset described by the message body. Internally, keys are
represented as tuples of strings.
3.9.4.2. Body Format
Message bodies are encoded in JSON. The top level of each message is an object (a dictionary).
Most simple Python types - strings, numbers, lists, and dictionaries - are mapped directly to the corresponding JSON types. Timestamps are represented as seconds since the UNIX epoch in message bodies.
3.9.4.3. Cautions
Message ordering is generally maintained by the backend implementations, but this should not be depended on. That is, messages originating from the same master are usually delivered to consumers in the order they were produced. Thus, for example, a consumer can expect to see a build request claimed before it is completed. That said, consumers should be resilient to messages delivered out of order, at the very least by scheduling a “reload” from state stored in the database when messages arrive in an invalid order.
Unit tests should be used to ensure this resiliency.
Some related messages are sent at approximately the same time. Due to the non-blocking nature of
message delivery, consumers should not assume that subsequent messages in a sequence remain
queued. For example, upon receipt of a buildset.$bsid.new message, it is already too late to
try to subscribe to the associated build requests messages, as they may already have been consumed.
3.9.4.4. Schema Changes
Future versions of Buildbot may add keys to messages, or add new messages. Consumers should expect unknown keys and, if using wildcard topics, unknown messages.
3.10. Classes
The sections contained here document classes that can be used or subclassed.
Note
Some of this information duplicates information available in the source code itself. Consider this information authoritative, and the source code a demonstration of the current implementation which is subject to change.
3.10.1. Builds
The Build class represents a running build, with associated steps.
3.10.1.1. Build
- class buildbot.process.build.Build
- buildid
The ID of this build in the database.
- getSummaryStatistic(name, summary_fn, initial_value=None)
- Parameters:
name – statistic name to summarize
summary_fn – callable with two arguments that will combine two values
initial_value – first value to pass to
summary_fn
- Returns:
summarized result
This method summarizes the named step statistic over all steps in which it exists, using
combination_fnandinitial_valueto combine multiple results into a single result. This translates to a call to Python’sreduce:return reduce(summary_fn, step_stats_list, initial_value)
- getUrl()
- Returns:
URL as string
Returns url of the build in the UI. Build must be started. This is useful for custom steps.
- env
Initialized from
BuilderConfig’s env by deep copy. This attribute is mutable, steps can update it to change the environment of subsequent steps.
3.10.2. Workers
The Worker class represents a worker, which may or may not be connected to the master.
Instances of this class are created directly in the Buildbot configuration file.
3.10.2.1. Worker
3.10.3. BuildFactory
3.10.3.1. BuildFactory Implementation Note
The default BuildFactory, provided in the buildbot.process.factory module, contains
an internal list of BuildStep factories. A BuildStep factory is simply a callable that produces
a new BuildStep with the same arguments that were used during its construction. These BuildStep
factories are constructed when the config file is read, by asking the instances passed to
addStep for their factories.
When asked to create a Build, the BuildFactory puts a copy of the list of
BuildStep factories into the new Build object. When the Build is actually
started, these BuildStep factories are used to create the actual set of BuildSteps,
which are then executed one at a time. This serves to give each Build an independent copy of each
step.
Each step can affect the build process in the following ways:
If the step’s
haltOnFailureattribute isTrue, then a failure in the step (i.e. if it completes with a result ofFAILURE) will cause the whole build to be terminated immediately: no further steps will be executed, with the exception of steps withalwaysRunset toTrue.haltOnFailureis useful for setup steps upon which the rest of the build depends: if the Git checkout or ./configure process fails, there is no point in trying to compile or test the resulting tree.If the step’s
alwaysRunattribute isTrue, then it will always be run, regardless of if previous steps have failed. This is useful for cleanup steps that should always be run to return the build directory or worker into a good state.If the
flunkOnFailureorflunkOnWarningsflag is set, then a result ofFAILUREorWARNINGSwill mark the build as a whole asFAILED. However, the remaining steps will still be executed. This is appropriate for things like multiple testing steps: a failure in any one of them will indicate that the build has failed, however it is still useful to run them all to completion.Similarly, if the
warnOnFailureorwarnOnWarningsflag is set, then a result ofFAILUREorWARNINGSwill mark the build as havingWARNINGS, and the remaining steps will still be executed. This may be appropriate for certain kinds of optional build or test steps. For example, a failure experienced while building documentation files should be made visible with aWARNINGSresult but not be serious enough to warrant marking the whole build with aFAILURE.
In addition, each Step produces its own results, may create logfiles, etc.
However only the flags described above have any effect on the build as a whole.
The pre-defined BuildSteps like Git and Compile have reasonably
appropriate flags set on them already. For example, without a source tree there is no point in
continuing a build, so the Git class has the haltOnFailure flag set to True.
Look in buildbot/steps/*.py to see how the other Steps are marked.
Each Step is created with an additional workdir argument that indicates where its
actions should take place. This is specified as a subdirectory of the worker’s base directory, with
a default value of build. This is only implemented as a step argument (as opposed to simply
being a part of the base directory) because the Git/SVN steps need to perform their checkouts from
the parent directory.
3.10.4. Change Sources
3.10.4.1. ChangeSource
- class buildbot.changes.base.ChangeSource
This is the base class for change sources.
Subclasses should override the inherited
activateanddeactivatemethods if necessary to handle initialization and shutdown.Change sources which are active on every master should, instead, override
startServiceandstopService.
3.10.4.2. ReconfigurablePollingChangeSource
- class buildbot.changes.base.ReconfigurablePollingChangeSource
This is a subclass of
ChangeSourcewhich adds polling behavior. Its constructor accepts thepollIntervalandpollAtLauncharguments as documented for most built-in change sources.Subclasses should override the
pollmethod. This method may return a Deferred. Calls topollwill not overlap.
3.10.5. RemoteCommands
Most of the action in build steps consists of performing operations on the worker.
This is accomplished via RemoteCommand and its subclasses.
Each represents a single operation on the worker.
Most data is returned to a command via updates. These updates are described in detail in Updates.
3.10.5.1. RemoteCommand
- class buildbot.process.remotecommand.RemoteCommand(remote_command, args, collectStdout=False, ignore_updates=False, decodeRC=dict(0), stdioLogName='stdio')
- Parameters:
remote_command (string) – command to run on the worker
args (dictionary) – arguments to pass to the command
collectStdout – if True, collect the command’s stdout
ignore_updates – true to ignore remote updates
decodeRC – dictionary associating
rcvalues to buildstep results constants (e.g.SUCCESS,FAILURE,WARNINGS)stdioLogName – name of the log to which to write the command’s stdio
This class handles running commands, consisting of a command name and a dictionary of arguments. If true,
ignore_updateswill suppress any updates sent from the worker.This class handles updates for
stdout,stderr, andheaderby appending them to a stdio logfile named by thestdioLogNameparameter. Steps that run multiple commands and want to separate those commands’ stdio streams can use this parameter.It handles updates for
rcby recording the value in itsrcattribute.Most worker-side commands, even those which do not spawn a new process on the worker, generate logs and an
rc, requiring this class or one of its subclasses. See Updates for the updates that each command may send.- active
True if the command is currently running
- run(step, remote)
- Parameters:
step – the buildstep invoking this command
remote – a reference to the remote
WorkerForBuilderinstance
- Returns:
Deferred
Run the command. Call this method to initiate the command; the returned Deferred will fire when the command is complete. The Deferred fires with the
RemoteCommandinstance as its value.
- interrupt(why)
- Parameters:
why (Twisted Failure) – reason for interrupt
- Returns:
Deferred
This method attempts to stop the running command early. The Deferred it returns will fire when the interrupt request is received by the worker; this may be a long time before the command itself completes, at which time the Deferred returned from
runwill fire.
- results()
- Returns:
results constant
This method checks the
rcagainst the decodeRC dictionary, and returns a results constant.
- didFail()
- Returns:
bool
This method returns True if the results() function returns FAILURE.
The following methods are invoked from the worker. They should not be called directly.
- remote_update(updates)
- Parameters:
updates – new information from the worker
Handles updates from the worker on the running command. See Updates for the content of the updates. This class splits the updates out, and handles the
ignore_updatesoption, then callsremoteUpdateto process the update.
- remote_complete(failure=None)
- Parameters:
failure – the failure that caused the step to complete, or None for success
Called by the worker to indicate that the command is complete. Normal completion (even with a nonzero
rc) will finish with no failure; iffailureis set, then the step should finish with statusEXCEPTION.
These methods are hooks for subclasses to add functionality.
- remoteUpdate(update)
- Parameters:
update – the update to handle
Handle a single update. Subclasses must override this method.
- remoteComplete(failure)
- Parameters:
failure – the failure that caused the step to complete, or None for success
- Returns:
Deferred
Handle command completion, performing any necessary cleanup. Subclasses should override this method. If
failureis not None, it should be returned to ensure proper processing.
- logs
A dictionary of
Loginstances representing active logs. Do not modify this directly – useuseLoginstead.
- rc
Set to the return code of the command, after the command has completed. For compatibility with shell commands, 0 is taken to indicate success, while nonzero return codes indicate failure.
- stdout
If the
collectStdoutconstructor argument is true, then this attribute will contain all data from stdout, as a single string. This is helpful when running informational commands (e.g.,svnversion), but is not appropriate for commands that will produce a large amount of output, as that output is held in memory.
To set up logging, use
useLogoruseLogDelayedbefore starting the command:- useLog(log, closeWhenFinished=False, logfileName=None)
- Parameters:
Route log-related updates to the given logfile. Note that
stdiois not included by default, and must be added explicitly. ThelogfileNamemust match the name given by the worker in anylogupdates.
- useLogDelayed(logfileName, activateCallback, closeWhenFinished=False)
- Parameters:
logfileName – the name of the logfile, as given to the worker. This is
stdiofor standard streamsactivateCallback – callback for when the log is added; see below
closeWhenFinished – if true, call
finishwhen the command is finished
Similar to
useLog, but the logfile is only actually added when an update arrives for it. The callback,activateCallback, will be called with theRemoteCommandinstance when the first update for the log is delivered. It should return the desired log instance, optionally via a Deferred.
With that finished, run the command using the inherited
runmethod. During the run, you can inject data into the logfiles with any of these methods:- addStdout(data)
- Parameters:
data – data to add to the logfile
- Returns:
Deferred
Add stdout data to the
stdiolog.
- addStderr(data)
- Parameters:
data – data to add to the logfile
- Returns:
Deferred
Add stderr data to the
stdiolog.
- addHeader(data)
- Parameters:
data – data to add to the logfile
- Returns:
Deferred
Add header data to the
stdiolog.
- addToLog(logname, data)
- Parameters:
logname – the logfile to receive the data
data – data to add to the logfile
- Returns:
Deferred
Add data to a logfile other than
stdio.
- class buildbot.process.remotecommand.RemoteShellCommand(workdir, command, env=None, want_stdout=True, want_stderr=True, timeout=20 * 60, maxTime=None, max_lines=None, sigtermTime=None, logfiles={}, usePTY=None, logEnviron=True, collectStdio=False, collectStderr=False, interruptSignal=None, initialStdin=None, decodeRC=None, stdioLogName='stdio')
- Parameters:
workdir – directory in which the command should be executed, relative to the builder’s basedir
command (string or list) – shell command to run
want_stdout – If false, then no updates will be sent for stdout
want_stderr – If false, then no updates will be sent for stderr
timeout – Maximum time without output before the command is killed
maxTime – Maximum overall time from the start before the command is killed
max_lines – Maximum lines command can produce to stdout, then command is killed.
sigtermTime – Try to kill the command with SIGTERM and wait for sigtermTime seconds before firing
interruptSignalor SIGKILL if it’s not defined. If None, SIGTERM will not be firedenv – A dictionary of environment variables to augment or replace the existing environment on the worker
logfiles – Additional logfiles to request from the worker
usePTY – True to use a PTY, false to not use a PTY; the default value is False
logEnviron – If false, do not log the environment on the worker
collectStdout – If True, collect the command’s stdout
collectStderr – If True, collect the command’s stderr
interruptSignal – The signal to send to interrupt the command, e.g.
KILLorTERM. If None, SIGKILL is usedinitialStdin – The input to supply the command via stdin
decodeRC – dictionary associating
rcvalues to buildstep results constants (e.g.SUCCESS,FAILURE,WARNINGS)stdioLogName – name of the log to which to write the command’s stdio
Most of the constructor arguments are sent directly to the worker; see shell for the details of the formats. The
collectStdout,decodeRCandstdioLogNameparameters are as described for the parent class.If a shell command contains passwords, they can be hidden from log files by using Secret Management. This is the recommended procedure for new-style build steps. For legacy build steps passwords were hidden from the log file by passing them as tuples in command arguments. Eg.
['print', ('obfuscated', 'password', 'dummytext')]is logged as['print', 'dummytext'].This class is used by the
ShellCommandstep, and by steps that run multiple customized shell commands.
3.10.6. BuildSteps
There are a few parent classes that are used as base classes for real buildsteps. This section describes the base classes. The “leaf” classes are described in Build Steps.
See Writing New BuildSteps for a guide to implementing new steps.
3.10.6.1. BuildStep
- class buildbot.process.buildstep.BuildStep(name, description, descriptionDone, descriptionSuffix, locks, haltOnFailure, flunkOnWarnings, flunkOnFailure, warnOnWarnings, warnOnFailure, alwaysRun, progressMetrics, useProgress, doStepIf, hideStepIf)
All constructor arguments must be given as keyword arguments. Each constructor parameter is copied to the corresponding attribute.
All arguments passed to constructor of the
BuildStepsubclass being constructed are also copied to a separate internal storage. This is used to create new instances in the same way the original instance is created without any interference that the constructors themselves may have. The copying of arguments is done by overriding__new__.- name
The name of the step. Note that this value may change when the step is started, if the existing name was not unique.
- stepid
The ID of this step in the database. This attribute is not set until the step starts.
- description
The description of the step.
- descriptionDone
The description of the step after it has finished.
- descriptionSuffix
Any extra information to append to the description.
- locks
List of locks for this step; see Interlocks.
- progressMetrics
List of names of metrics that should be used to track the progress of this build and build ETA’s for users.
- useProgress
If true (the default), then ETAs will be calculated for this step using progress metrics. If the step is known to have unpredictable timing (e.g., an incremental build), then this should be set to false.
- doStepIf
A callable or bool to determine whether this step should be executed. See Parameters Common to all Steps for details.
- hideStepIf
A callable or bool to determine whether this step should be shown in the waterfall and build details pages. See Parameters Common to all Steps for details.
The following attributes affect the behavior of the containing build:
- haltOnFailure
If true, the build will halt on a failure of this step, and not execute subsequent steps (except those with
alwaysRun).
- flunkOnWarnings
If true, the build will be marked as a failure if this step ends with warnings.
- flunkOnFailure
If true, the build will be marked as a failure if this step fails.
- warnOnWarnings
If true, the build will be marked as warnings, or worse, if this step ends with warnings.
- warnOnFailure
If true, the build will be marked as warnings, or worse, if this step fails.
- alwaysRun
If true, the step will run even if a previous step halts the build with
haltOnFailure.
- logEncoding
The log encoding to use for logs produced in this step, or None to use the global default. See Log Handling.
- rendered
At the beginning of the step, the renderable attributes are rendered against the properties. There is a slight delay however when those are not yet rendered, which leads to weird and difficult to reproduce bugs. To address this problem, a
renderedattribute is available for methods that could be called early in the buildstep creation.
- results
This is the result (a code from
buildbot.process.results) of the step. This attribute only exists after the step is finished, and should only be used ingetResultSummary.
A few important pieces of information are not available when a step is constructed and are added later. These are set by the following methods; the order in which these methods are called is not defined.
- setBuild(build)
- Parameters:
build – the
Buildinstance controlling this step.
This method is called during setup to set the build instance controlling this worker. Subclasses can override this to get access to the build object as soon as it is available. The default implementation sets the
buildattribute.
- build
The build object controlling this step.
- setWorker(worker)
- Parameters:
worker – the
Workerinstance on which this step will run.
Similarly, this method is called with the worker that will run this step. The default implementation sets the
workerattribute.
- worker
The worker that will run this step.
- workdir
Directory where actions of the step will take place. The workdir is set by order of priority:
workdir of the step, if defined via constructor argument
workdir of the BuildFactory (itself defaults to ‘build’)
BuildFactory workdir can also be a function of a sourcestamp (see Factory Workdir Functions).
- setDefaultWorkdir(workdir)
- Parameters:
workdir – the default workdir, from the build
Note
This method is deprecated and should not be used anymore, as workdir is calculated automatically via a property.
- setupProgress()
This method is called during build setup to give the step a chance to set up progress tracking. It is only called if the build has
useProgressset. There is rarely any reason to override this method.
Execution of the step itself is governed by the following methods and attributes.
- run()
- Returns:
result via Deferred
Execute the step. When this method returns (or when the Deferred it returns fires), the step is complete. The method’s return value must be an integer, giving the result of the step – a constant from
buildbot.process.results. If the method raises an exception or its Deferred fires with failure, then the step will be completed with an EXCEPTION result. Any other output from the step (logfiles, status strings, URLs, etc.) is the responsibility of therunmethod.The function is not called if the step is skipped or otherwise not run.
Subclasses should override this method.
- interrupt(reason)
- Parameters:
reason (string or
Failure) – why the build was interrupted
This method is used from various control interfaces to stop a running step. The step should be brought to a halt as quickly as possible, by cancelling a remote command, killing a local process, etc.
The
reasonparameter can be a string or, when a worker is lost during step processing, aConnectionLostfailure.The parent method handles any pending lock operations, and should be called by implementations in subclasses.
- stopped
If false, then the step is running. If true, the step is not running, or has been interrupted.
- timed_out
If
True, then one or more remote commands of the step timed out.
A step can indicate its up-to-the-moment status using a short summary string. These methods allow step subclasses to produce such summaries.
- updateSummary()
Update the summary, calling
getCurrentSummaryorgetResultSummaryas appropriate. Build steps should call this method any time the summary may have changed. This method is debounced, so even calling it for every log line is acceptable.
- getCurrentSummary()
- Returns:
dictionary, optionally via Deferred
Returns a dictionary containing status information for a running step. The dictionary can have a
stepkey with a unicode value giving a summary for display with the step. This method is only called while the step is running.Build steps may override this method to provide a more interesting summary than the default
"running".
- getResultSummary()
- Returns:
dictionary, optionally via Deferred
Returns a dictionary containing status information for a completed step. The dictionary can have keys
stepandbuild, each with unicode values. Thestepkey gives a summary for display with the step, while thebuildkey gives a summary for display with the entire build. The latter should be used sparingly, and include only information that the user would find relevant for the entire build, such as a number of test failures. Either or both keys can be omitted.This method is only called when the step is finished. The step’s result is available in
self.resultsat that time.Build steps may override this method to provide a more interesting summary than the default, or to provide any build summary information.
- getBuildResultSummary()
- Returns:
dictionary, optionally via Deferred
Returns a dictionary containing status information for a completed step. This method calls
getResultSummary, and automatically computes abuildkey from thestepkey according to theupdateBuildSummaryPolicy.
- describe(done=False)
- Parameters:
done – If true, the step is finished.
- Returns:
list of strings
Describe the step succinctly. The return value should be a sequence of short strings suitable for display in a horizontally constrained space.
Note
Be careful not to assume that the step has been started in this method. In relatively rare circumstances, steps are described before they have started. Ideally, unit tests should be used to ensure that this method is resilient.
Note
This method is not called for new-style steps. Instead, override
getCurrentSummaryandgetResultSummary.
- addTestResultSets()
The steps may override this to add any test result sets for this step via
self.addTestResultSet(). This function is called just before the step execution is started. The function is not called if the step is skipped or otherwise not run.
- addTestResultSet(description, category, value_unit)
- Parameters:
description – Description of the test result set
category – Category of the test result set
value_unit – The value unit of the test result set
- Returns:
The ID of the created test result set via a Deferred.
Creates a new test result set to which test results can be associated.
There are standard values of the
categoryandvalue_unitparameters, see TODO.
- addTestResult(setid, value, test_name=None, test_code_path=None, line=None, duration_ns=None)
- Parameters:
setid – The ID of a test result set returned by
addTestResultSetvalue – The value of the result as a string
test_name – The name of the test
test_code_path – The path to the code file that resulted in this test result
line – The line within
test_code_pathfile that resulted in this test resultduration_ns – The duration of the test itself, in nanoseconds
Creates a test result. Either
test_nameortest_code_pathmust be specified. The function queues the test results and will submit them to the database when enough test results are added so that performance impact is minimized.
- finishTestResultSets()
The steps may override this to finish submission of any test results for the step.
Build steps have statistics, a simple key-value store of data which can later be aggregated over all steps in a build. Note that statistics are not preserved after a build is complete.
- setBuildData(self, name, value, source)
- Parameters:
name (unicode) – the name of the data
value (bytestr) – the value of the data as
bytessource (unicode) – the source of the data
- Returns:
Deferred
Builds can have transient data attached to them which allows steps to communicate to reporters and among themselves. The data is a byte string and its interpretation depends on the particular step or reporter.
- hasStatistic(stat)
- Parameters:
stat (string) – name of the statistic
- Returns:
True if the statistic exists on this step
- getStatistic(stat, default=None)
- Parameters:
stat (string) – name of the statistic
default – default value if the statistic does not exist
- Returns:
value of the statistic, or the default value
- getStatistics()
- Returns:
a dictionary of all statistics for this step
- setStatistic(stat, value)
- Parameters:
stat (string) – name of the statistic
value – value to assign to the statistic
- Returns:
value of the statistic
Build steps support progress metrics - values that increase roughly linearly during the execution of the step, and can thus be used to calculate an expected completion time for a running step. A metric may be a count of lines logged, tests executed, or files compiled. The build mechanics will take care of translating this progress information into an ETA for the user.
- setProgress(metric, value)
- Parameters:
metric (string) – the metric to update
value (integer) – the new value for the metric
Update a progress metric. This should be called by subclasses that can provide useful progress-tracking information.
The specified metric name must be included in
progressMetrics.
The following methods are provided as utilities to subclasses. These methods should only be invoked after the step has started.
- workerVersion(command, oldversion=None)
- Parameters:
command (string) – command to examine
oldversion – return value if the worker does not specify a version
- Returns:
string
Fetch the version of the named command, as specified on the worker. In practice, all commands on a worker have the same version, but passing
commandis still useful to ensure that the command is implemented on the worker. If the command is not implemented on the worker,workerVersionwill returnNone.Versions take the form
x.ywherexandyare integers, and are compared as expected for version numbers.Buildbot versions older than 0.5.0 did not support version queries; in this case,
workerVersionwill returnoldVersion. Since such ancient versions of Buildbot are no longer in use, this functionality is largely vestigial.
- workerVersionIsOlderThan(command, minversion)
- Parameters:
command (string) – command to examine
minversion – minimum version
- Returns:
boolean
This method returns true if
commandis not implemented on the worker, or if it is older thanminversion.
- checkWorkerHasCommand(command)
- Parameters:
command (string) – command to examine
This method raise
WorkerSetupErrorifcommandis not implemented on the worker
- getWorkerName()
- Returns:
string
Get the name of the worker assigned to this step.
Most steps exist to run commands. While the details of exactly how those commands are constructed are left to subclasses, the execution of those commands comes down to this method:
- runCommand(command)
- Parameters:
command –
RemoteCommandinstance- Returns:
Deferred
This method connects the given command to the step’s worker and runs it, returning the Deferred from
run.
The
BuildStepclass provides methods to add log data to the step. Subclasses provide a great deal of user-configurable functionality on top of these methods. These methods can be called while the step is running, but not before.- addLog(name, type='s', logEncoding=None)
- Parameters:
name – log name
type – log type; see
logchunklogEncoding – the log encoding, or None to use the step or global default (see Log Handling)
- Returns:
Loginstance via Deferred
Add a new logfile with the given name to the step, and return the log file instance.
- getLog(name)
- Parameters:
name – log name
- Raises:
KeyError – if there is no such log
KeyError – if no such log is defined
- Returns:
Loginstance
Return an existing logfile, previously added with
addLog. Note that this return value is synchronous, and only available afteraddLog’s deferred has fired.
- addCompleteLog(name, text)
- Parameters:
name – log name
text – content of the logfile
- Returns:
Deferred
This method adds a new log and sets
textas its content. This is often useful to add a short logfile describing activities performed on the master. The logfile is immediately closed, and no further data can be added.If the logfile’s content is a bytestring, it is decoded with the step’s log encoding or the global default log encoding. To add a logfile with a different character encoding, perform the decode operation directly and pass the resulting unicode string to this method.
- addHTMLLog(name, html)
- Parameters:
name – log name
html – content of the logfile
- Returns:
Deferred
Similar to
addCompleteLog, this adds a logfile containing pre-formatted HTML, allowing more expressiveness than the text format supported byaddCompleteLog.
- addLogObserver(logname, observer)
- Parameters:
logname – log name
observer – log observer instance
Add a log observer for the named log. The named log need not have been added already. The observer will be connected when the log is added.
See Adding LogObservers for more information on log observers.
- addLogWithFailure(why, logprefix='')
- Parameters:
why (Failure) – the failure to log
logprefix – prefix for the log name
- Returns:
Deferred
Add log files displaying the given failure, named
<logprefix>err.textand<logprefix>err.html.
- addLogWithException(why, logprefix='')
- Parameters:
why (Exception) – the exception to log
logprefix – prefix for the log name
- Returns:
Deferred
Similar to
addLogWithFailure, but for an Exception instead of a Failure.
Along with logs, build steps have an associated set of links that can be used to provide additional information for developers. Those links are added during the build with this method:
- addURL(name, url)
- Parameters:
name – URL name
url – the URL
Add a link to the given
url, with the givennameto displays of this step. This allows a step to provide links to data that is not available in the log files.
3.10.6.2. CommandMixin
The runCommand method can run a RemoteCommand instance, but it’s no help in building that object or interpreting the results afterward.
This mixin class adds some useful methods for running commands.
This class can only be used in new-style steps.
- class buildbot.process.buildstep.CommandMixin
Some remote commands are simple enough that they can boil down to a method call. Most of these take an
abandonOnFailureargument which, if true, will abandon the entire buildstep on command failure. This is accomplished by raisingBuildStepFailed.These methods all write to the
stdiolog (generally just for errors). They do not close the log when finished.- runRmdir(dir, abandonOnFailure=True)
- Parameters:
dir – directory to remove
abndonOnFailure – if true, abandon step on failure
- Returns:
Boolean via Deferred
Remove the given directory, using the
rmdircommand. Returns False on failure.
- runMkdir(dir, abandonOnFailure=True)
- Parameters:
dir – directory to create
abndonOnFailure – if true, abandon step on failure
- Returns:
Boolean via Deferred
Create the given directory and any parent directories, using the
mkdircommand. Returns False on failure.
- pathExists(path)
- Parameters:
path – path to test
- Returns:
Boolean via Deferred
Determine if the given path exists on the worker (in any form - file, directory, or otherwise). This uses the
statcommand.
- runGlob(path)
- Parameters:
path – path to test
- Returns:
list of filenames
Get the list of files matching the given path pattern on the worker. This uses Python’s
globmodule. If therunGlobmethod fails, it aborts the step.
- getFileContentFromWorker(path, abandonOnFailure=False)
- Parameters:
path – path of the file to download from worker
- Returns:
string via deferred (content of the file)
Get the content of a file on the worker.
3.10.6.3. ShellMixin
Most Buildbot steps run shell commands on the worker, and Buildbot has an impressive array of configuration parameters to control that execution.
The ShellMixin mixin provides the tools to make running shell commands easy and flexible.
This class can only be used in new-style steps.
- class buildbot.process.buildstep.ShellMixin
This mixin manages the following step configuration parameters, the contents of which are documented in the manual. Naturally, all of these are renderable.
- command
- workdir
- env
- want_stdout
- want_stderr
- usePTY
- logfiles
- lazylogfiles
- timeout
- maxTime
- max_lines
- logEnviron
- interruptSignal
- sigtermTime
- initialStdin
- decodeRC
- setupShellMixin(constructorArgs, prohibitArgs=[])
- Parameters:
constructorArgs (dict) – constructor keyword arguments
prohibitArgs (list) – list of recognized arguments to reject
- Returns:
keyword arguments destined for
BuildStep
This method is intended to be called from the shell constructor, and be passed any keyword arguments not otherwise used by the step. Any attributes set on the instance already (e.g., class-level attributes) are used as defaults. Attributes named in
prohibitArgsare rejected with a configuration error.The return value should be passed to the
BuildStepconstructor.
- makeRemoteShellCommand(collectStdout=False, collectStderr=False, **overrides)
- Parameters:
collectStdout – if true, the command’s stdout will be available in
cmd.stdouton completioncollectStderr – if true, the command’s stderr will be available in
cmd.stderron completionoverrides – overrides arguments that might have been passed to
setupShellMixin
- Returns:
RemoteShellCommandinstance via Deferred
This method constructs a
RemoteShellCommandinstance based on the instance attributes and any supplied overrides. It must be called while the step is running, as it examines the worker capabilities before creating the command. It takes care of just about everything:Creating log files and associating them with the command
Merging environment configuration
Selecting the appropriate workdir configuration
All that remains is to run the command with
runCommand.
The
ShellMixinclass implementsgetResultSummary, returning a summary of the command. If no command was specified or run, it falls back to the defaultgetResultSummarybased ondescriptionDone. Subclasses can override this method to return a more appropriate status.
3.10.6.4. Exceptions
- exception buildbot.process.buildstep.BuildStepFailed
This exception indicates that the buildstep has failed. It is useful as a way to skip all subsequent processing when a step goes wrong.
3.10.7. BaseScheduler
- class buildbot.schedulers.base.ReconfigurableBaseScheduler
This is the base class for all Buildbot schedulers. See Writing Schedulers for information on writing new schedulers.
- __init__(name, builderNames, properties={}, codebases={'': {}})
- Parameters:
name – (positional) the scheduler name
builderName – (positional) a list of builders, by name, for which this scheduler can queue builds
properties – a dictionary of properties to be added to queued builds
codebases – the codebase configuration for this scheduler (see user documentation)
Initializes a new scheduler.
The scheduler configuration parameters, and a few others, are available as attributes:
- name
This scheduler’s name.
- builderNames
- Type:
list
Builders for which this scheduler can queue builds.
- codebases
- Type:
dict
The codebase configuration for this scheduler.
- properties
- Type:
Properties instance
Properties that this scheduler will attach to queued builds. This attribute includes the
schedulerproperty.
- schedulerid
- Type:
integer
The ID of this scheduler in the
schedulerstable.
Subclasses can consume changes by implementing
gotChangeand callingstartConsumingChangesfromstartActivity.- startConsumingChanges(self, fileIsImportant=None, change_filter=None, onlyImportant=False)
- Parameters:
fileIsImportant (callable) – a callable provided by the user to distinguish important and unimportant changes
change_filter (
buildbot.changes.filter.ChangeFilterinstance) – a filter to determine which changes are even considered by this scheduler, orNoneto consider all changesonlyImportant (boolean) – If True, only important changes, as specified by fileIsImportant, will be added to the buildset
- Returns:
Deferred
Subclasses should call this method when becoming active in order to receive changes. The parent class will take care of filtering the changes (using
change_filter) and (iffileIsImportantis not None) classifying them.
- gotChange(change, important)
- Parameters:
change (buildbot.changes.changes.Change) – the new change
important (boolean) – true if the change is important
- Returns:
Deferred
This method is called when a change is received. Schedulers which consume changes should implement this method.
If the
fileIsImportantparameter tostartConsumingChangeswas None, then all changes are considered important. It is guaranteed that thecodebaseof the change is one of the scheduler’s codebase.Note
The
buildbot.changes.changes.Changeinstance will instead be a change resource in later versions.
The following methods are available for subclasses to queue new builds. Each creates a new buildset with a build request for each builder.
- addBuildsetForSourceStamps(self, sourcestamps=[], waited_for=False, reason='', external_idstring=None, properties=None, builderNames=None)
- Parameters:
sourcestamps (list) – a list of full sourcestamp dictionaries or sourcestamp IDs
waited_for (boolean) – if true, this buildset is being waited for (and thus should continue during a clean shutdown)
reason (string) – reason for the build set
external_idstring (string) – external identifier for the buildset
properties (
Propertiesinstance) – properties to include in the buildset, in addition to those in the scheduler configurationbuilderNames (list) – a list of builders for the buildset, or None to use the scheduler’s configured
builderNames
- Returns:
(buildset ID, buildrequest IDs) via Deferred
Add a buildset for the given source stamps. Each source stamp must be specified as a complete source stamp dictionary (with keys
revision,branch,project,repository, andcodebase), or an integersourcestampid.The return value is a tuple. The first tuple element is the ID of the new buildset. The second tuple element is a dictionary mapping builder name to buildrequest ID.
- addBuildsetForSourceStampsWithDefaults(reason, sourcestamps, waited_for=False, properties=None, builderNames=None)
- Parameters:
reason (string) – reason for the build set
sourcestamps (list) – partial list of source stamps to build
waited_for (boolean) – if true, this buildset is being waited for (and thus should continue during a clean shutdown)
properties (
Propertiesinstance) – properties to include in the buildset, in addition to those in the scheduler configurationbuilderNames (list) – a list of builders for the buildset, or None to use the scheduler’s configured
builderNames
- Returns:
(buildset ID, buildrequest IDs) via Deferred, as for
addBuildsetForSourceStamps
Create a buildset based on the supplied sourcestamps, with defaults applied from the scheduler’s configuration.
The
sourcestampsparameter is a list of source stamp dictionaries, giving the required parameters. Any unspecified values, including sourcestamps from unspecified codebases, will be filled in from the scheduler’s configuration. Ifsourcestampsis None, then only the defaults will be used. Ifsourcestampsincludes sourcestamps for codebases not configured on the scheduler, they will be included anyway, although this is probably a sign of an incorrect configuration.
- addBuildsetForChanges(waited_for=False, reason='', external_idstring=None, changeids=[], builderNames=None, properties=None)
- Parameters:
waited_for (boolean) – if true, this buildset is being waited for (and thus should continue during a clean shutdown)
reason (string) – reason for the build set
external_idstring (string) – external identifier for the buildset
changeids (list) – changes from which to construct the buildset
builderNames (list) – a list of builders for the buildset, or None to use the scheduler’s configured
builderNamesproperties (
Propertiesinstance) – properties to include in the buildset, in addition to those in the scheduler configuration
- Returns:
(buildset ID, buildrequest IDs) via Deferred, as for
addBuildsetForSourceStamps
Add a buildset for the given changes (
changeids). This will take sourcestamps from the latest of any changes with the same codebase, and will fill in sourcestamps for any codebases for which no changes are included.
The active state of the scheduler is tracked by the following attribute and methods.
- active
True if this scheduler is active
- activate()
- Returns:
Deferred
Subclasses should override this method to initiate any processing that occurs only on active schedulers. This is the method from which to call
startConsumingChanges, or to set up any timers or message subscriptions.
- deactivate()
- Returns:
Deferred
Subclasses should override this method to stop any ongoing processing, or wait for it to complete. The method’s returned Deferred should not fire until the processing is complete.
The state-manipulation methods are provided by
buildbot.util.state.StateMixin. Note that no locking of any sort is performed between these two functions. They should only be called by an active scheduler.- getState(name[, default])
- Parameters:
name – state key to fetch
default – default value if the key is not present
- Returns:
Deferred
This calls through to
buildbot.db.state.StateConnectorComponent.getState, using the scheduler’s objectid.
- setState(name, value)
- Parameters:
name – state key
value – value to set for the key
- Returns:
Deferred
This calls through to
buildbot.db.state.StateConnectorComponent.setState, using the scheduler’s objectid.
- class buildbot.schedulers.base.BaseScheduler
This class is legacy counterpart of
ReconfigurableBaseScheduler. It does not support reconfiguration.
3.10.8. ForceScheduler
The force scheduler has a symbiotic relationship with the web application, so it deserves some further description.
3.10.8.1. Parameters
The force scheduler comes with a set of parameter classes. This section contains information to help users or developers who are interested in adding new parameter types or hacking the existing types.
- class buildbot.schedulers.forceshed.BaseParameter(name, label, regex, **kwargs)
This is the base implementation for most parameters, it will check validity, ensure the arg is present if the
requiredattribute is set, and implement the default value. It will finally callupdateFromKwargsto process the string(s) from the HTTP POST.The
BaseParameterconstructor converts all keyword arguments into instance attributes, so it is generally not necessary for subclasses to implement a constructor.For custom parameters that set properties, one simple customization point is getFromKwargs:
- getFromKwargs(kwargs)
- Parameters:
kwargs – a dictionary of the posted values
Given the passed-in POST parameters, return the value of the property that should be set.
For more control over parameter parsing, including modifying sourcestamps or changeids, override the
updateFromKwargsfunction, which is the function thatForceSchedulerinvokes for processing:- updateFromKwargs(master, properties, changes, sourcestamps, collector, kwargs)
- Parameters:
master – the
BuildMasterinstanceproperties – a dictionary of properties
changes – a list of changeids that will be used to build the SourceStamp for the forced builds
sourcestamps – the SourceStamp dictionary that will be passed to the build; some parameters modify sourcestamps rather than properties
collector – a
buildbot.schedulers.forcesched.ValidationErrorCollectorobject, which is used by nestedParameter to collect errors from its childskwargs – a dictionary of the posted values
This method updates
properties,changes, and/orsourcestampsaccording to the request. The default implementation is good for many simple uses, but can be overridden for more complex purposes.When overriding this function, take all parameters by name (not by position), and include an
**unusedcatch-all to guard against future changes.
The remaining attributes and methods should be overridden by subclasses, although
BaseParameterprovides appropriate defaults.- name
The name of the parameter. This corresponds to the name of the property that your parameter will set. This name is also used internally as identifier for HTTP POST arguments.
- label
The label of the parameter, as displayed to the user. This value can contain raw HTML.
- fullName()
A fully-qualified name that uniquely identifies the parameter in the scheduler. This name is used internally as the identifier for HTTP POST arguments. It is a mix of name and the parent’s name (in the case of nested parameters). This field is not modifiable.
- type
A string identifying the type that the parameter conforms to. It is used by the angular application to find which angular directive to use for showing the form widget. The available values are visible in www/base/src/app/common/directives/forcefields/forcefields.directive.js.
Examples of how to create a custom parameter widgets are available in the Buildbot source code in directories:
- default
The default value to use if there is no user input. This is also used to fill in the form presented to the user.
- required
If true, an error will be shown to user if there is no input in this field.
- multiple
If true, this parameter represents a list of values (e.g. list of tests to run).
- regex
A string that will be compiled as a regex and used to validate the string value of this parameter. If None, then no validation will take place.
- parse_from_args(l)
Return the list of property values corresponding to the list of strings passed by the user. The default function will just call
parse_from_argon every argument.
- parse_from_arg(s)
Return the property value corresponding to the string passed by the user. The default function will simply return the input argument.
3.10.8.2. Nested Parameters
The NestedParameter class is a container for parameters. The original motivating
purpose for this feature is the multiple-codebase configuration, which needs to provide the user
with a form to control the branch (et al) for each codebase independently. Each branch parameter is
a string field with name ‘branch’ and these must be disambiguated.
In Buildbot nine, this concept has been extended to allow grouping different parameters into UI containers. Details of the available layouts is described in NestedParameter.
Each of the child parameters mixes in the parent’s name to create the fully qualified fullName.
This allows, for example, each of the ‘branch’ fields to have a unique name in the POST request.
The NestedParameter handles adding this extra bit to the name to each of the children. When the
kwarg dictionary is posted back, this class also converts the flat POST dictionary into a richer
structure that represents the nested structure.
For example, if the nested parameter has the name ‘foo’, and has children ‘bar1’ and ‘bar2’, then the POST will have entries like “foo.bar1” and “foo.bar2”. The nested parameter will translate this into a dictionary in the ‘kwargs’ structure, resulting in something like:
kwargs = {
# ...
'foo': {
'bar1': '...',
'bar2': '...'
}
}
Arbitrary nesting is allowed and results in a deeper dictionary structure.
Nesting can also be used for presentation purposes. If the name of the NestedParameter
is empty, the nest is “anonymous” and does not mangle the child names. However, in the HTML layout,
the nest will be presented as a logical group.
3.10.9. IRenderable
- class buildbot.interfaces.IRenderable
Providers of this class can be “rendered”, based on available properties, when a build is started.
- getRenderingFor(iprops)
- Parameters:
iprops – the
IPropertiesprovider supplying the properties of the build- Returns:
the interpretation of the given properties, optionally in a Deferred
3.10.10. IProperties
- class buildbot.interfaces.IProperties
Providers of this interface allow get and set access to a build’s properties.
- getProperty(propname, default=None)
Get a named property, returning the default value if the property is not found.
- hasProperty(propname)
Determine whether the named property exists.
- setProperty(propname, value, source, runtime=False)
Set a property’s value, also specifying the source for this value.
- getProperties()
Get a
buildbot.process.properties.Propertiesinstance. The interface of this class is not finalized; where possible, use the otherIPropertiesmethods.
3.10.11. IConfigurator
- class buildbot.interfaces.IConfigurator
A configurator is an object which configures several components of Buildbot in a coherent manner. This can be used to implement higher level configuration tools.
- configure(config_dict)
Alter the Buildbot
config_dict, as defined in master.cfg.Like master.cfg, this is run out of the main reactor thread, so this can block, but it can’t call most Buildbot facilities.
3.10.12. ResultSpecs
Result specifications are used by the Data API to describe the desired results of a get call.
They can be used to filter, sort and paginate the contents of collections, and to limit the fields returned for each item.
Python calls to get can pass a ResultSpec instance directly.
Requests to the HTTP REST API are converted into instances automatically.
Implementers of Data API endpoints can ignore result specifications entirely, except where efficiency suffers.
Any filters, sort keys, and so on still present after the endpoint returns its result are applied generically.
ResultSpec instances are mutable, so endpoints that do apply some of the specification can remove parts of the specification.
Result specifications are applied in the following order:
Field Selection (fields)
Filters
Order
Pagination (limit/offset)
Properties
Only fields & properties are applied to non-collection results. Endpoints processing a result specification should take care to replicate this behavior.
- class buildbot.data.resultspec.ResultSpec
A result specification has the following attributes, which should be treated as read-only:
- fields
A list of field names that should be included, or
Nonefor no sorting. if the field names all begin with-, then those fields will be omitted and all others included.
- order
A list of field names to sort on. if any field name begins with
-, then the ordering on that field will be in reverse.
- limit
The maximum number of collection items to return.
- offset
The 0-based index of the first collection item to return.
- properties
A list of
Propertyinstances to be applied. The result is a logical AND of all properties.All of the attributes can be supplied as constructor keyword arguments.
Endpoint implementations may call these methods to indicate that they have processed part of the result spec. A subsequent call to
applywill then not waste time re-applying that part.- popProperties()
If a property exists, return its values list and remove it from the result spec.
- popFilter(field, op)
If a filter exists for the given field and operator, return its values list and remove it from the result spec.
- popBooleanFilter(field)
If a filter exists for the field, remove it and return the expected value (True or False); otherwise return None. This method correctly handles odd cases like
field__ne=false.
- popStringFilter(field)
If one string filter exists for the field, remove it and return the expected value (as string); otherwise return None.
- popIntegerFilter(field)
If one integer filter exists for the field, remove it and return the expected value (as integer); otherwise return None. raises ValueError if the field is not convertible to integer.
- removePagination()
Remove the pagination attributes (
limitandoffset) from the result spec. And endpoint that calls this method should return aListResultinstance with its pagination attributes set appropriately.
- removeOrder()
Remove the order attribute.
- popField(field)
Remove a single field from the
fieldsattribute, returning True if it was present. Endpoints can use this in conditionals to avoid fetching particularly expensive fields from the DB API.
The following method is used internally to apply any remaining parts of a result spec that are not handled by the endpoint.
- apply(data)
Apply the result specification to the data, returning a transformed copy of the data. If the data is a collection, then the result will be a
ListResultinstance.
- class buildbot.data.resultspec.Filter(field, op, values)
- Parameters:
field (string) – the field to filter on
op (string) – the comparison operator (e.g., “eq” or “gt”)
values (list) – the values on the right side of the operator
A filter represents a limitation of the items from a collection that should be returned.
Many operators, such as “gt”, only accept one value. Others, such as “eq” or “ne”, can accept multiple values. In either case, the values must be passed as a list.
- class buildbot.data.resultspec.Property(values)
- Parameters:
values (list) – the values on the right side of the operator (
eq)
A property represents an item of a foreign table.
In either case, the values must be passed as a list.
3.10.13. Protocols
To exchange information over the network between master and worker, we need to use a protocol.
buildbot.worker.protocols.base provide interfaces to implement
wrappers around protocol specific calls, so other classes which use them do not need
to know about protocol calls or handle protocol specific exceptions.
- class buildbot.worker.protocols.base.Listener(master)
- Parameters:
master –
buildbot.master.BuildMasterinstance
Responsible for spawning Connection instances and updating registrations. Protocol-specific subclasses are instantiated with protocol-specific parameters by the buildmaster during startup.
- class buildbot.worker.protocols.base.Connection(master, worker)
Represents connection to single worker.
- proxies
Dictionary containing mapping between
Implclasses andProxyclass for this protocol. This may be overridden by a subclass to declare its proxy implementations.
- createArgsProxies(args)
- Returns:
shallow copy of args dictionary with proxies instead of impls
Helper method that will use
proxies, and replaceImplobjects by specificProxycounterpart.
- notifyOnDisconnect(cb)
- Parameters:
cb – callback
- Returns:
buildbot.util.subscriptions.Subscription
Register a callback to be called if a worker gets disconnected.
- loseConnection()
Close connection.
- remotePrint(message)
- Parameters:
message (string) – message for worker
- Returns:
Deferred
Print message to worker log file.
- remoteGetWorkerInfo()
- Returns:
Deferred
Get worker information, commands and version, put them in dictionary, and then return back.
- remoteSetBuilderList(builders)
- Parameters:
builders (List) – list with wanted builders
- Returns:
Deferred containing PB references XXX
Take a list with wanted builders, send them to the worker, and return the list with created builders.
- remoteStartCommand(remoteCommand, builderName, commandId, commandName, args)
- Parameters:
remoteCommand –
RemoteCommandImplinstancebuilderName (string) – self explanatory
commandId (string) – command number
commandName (string) – command which will be executed on worker
args (List) – arguments for that command
- Returns:
Deferred
Start command on the worker.
- remoteShutdown()
- Returns:
Deferred
Shutdown the worker, causing its process to halt permanently.
- remoteStartBuild(builderName)
- Parameters:
builderName – name of the builder for which the build is starting
- Returns:
Deferred
Start a build.
- remoteInterruptCommand(builderName, commandId, why)
- Parameters:
builderName (string) – self explanatory
commandId (string) – command number
why (string) – reason to interrupt
- Returns:
Deferred
Interrupt the command executed on builderName with given commandId on worker, and print reason “why” to worker logs.
The following classes describe the worker -> master part of the protocol.
In order to support old workers, we must make sure we do not change the current pb protocol.
This is why we implement a Impl vs Proxy method.
All the objects that are referenced from the workers for remote calls have an Impl and a Proxy base class in this module.
Impl classes are subclassed by Buildbot master, and implement the actual logic for the protocol API.
Proxy classes are implemented by the worker/master protocols, and implement the demux and de-serialization of protocol calls.
On worker sides, those proxy objects are replaced by a proxy object having a single method to call master side methods:
- class buildbot.worker.protocols.base.workerProxyObject
- callRemote(message, *args, **kw)
Calls the method
"remote_" + messageon master side
- class buildbot.worker.protocols.base.RemoteCommandImpl
Represents a RemoteCommand status controller.
- remote_update(updates)
- Parameters:
updates – dictionary of updates
Called when the workers have updates to the current remote command.
Possible keys for updates are:
stdout: Some logs where captured in remote command’s stdout. value:<data> as stringstderr: Some logs where captured in remote command’s stderr. value:<data> as stringheader: Remote command’s header text. value:<data> as stringlog: One of the watched logs has received some text. value:(<logname> as string, <data> as string)rc: Remote command exited with a return code. value:<rc> as integerelapsed: Remote command has taken <elapsed> time. value:<elapsed seconds> as floatstat: Sent by thestatcommand with the result of the os.stat, converted to a tuple. value:<stat> as tuplefiles: Sent by theglobcommand with the result of the glob.glob. value:<files> as list of stringgot_revision: Sent by the source commands with the revision checked out. value:<revision> as stringrepo_downloaded: sent by therepocommand with the list of patches downloaded by repo. value:<downloads> as list of string
- class buildbot.worker.protocols.base.FileWriterImpl
Class used to implement data transfer between worker and master.
3.10.14. WorkerManager
3.10.14.1. WorkerRegistration
- class buildbot.worker.manager.WorkerRegistration(master, worker)
Represents single worker registration.
- unregister()
Remove registration for worker.
- update(worker_config, global_config)
- Parameters:
worker_config (
Worker) – new Worker instanceglobal_config (
MasterConfig) – Buildbot config
Update the registration in case the port or password has changed.
Note
You should invoke this method after calling WorkerManager.register(worker).
3.10.14.2. WorkerManager
- class buildbot.worker.manager.WorkerManager(master)
Handle worker registrations for multiple protocols.
- register(worker)
- Parameters:
worker (
Worker) – new Worker instance- Returns:
Creates
WorkerRegistrationinstance.Note
You should invoke .update() on returned WorkerRegistration instance.
3.10.15. Logs
- class buildbot.process.log.Log
This class handles write-only access to log files from running build steps. It does not provide an interface for reading logs - such access should occur directly through the Data API.
Instances of this class can only be created by the
addLogmethod of a build step.- name
The name of the log.
Note that if you have a build step which outputs multiple logs, naming one of the logs
Summarywill cause the Web UI to sort the summary log first in the list, and expand it so that the contents are immediately visible.
- logid
The ID of the logfile.
- decoder
A callable used to decode bytestrings. See
logEncoding.
- subscribe(receiver)
- Parameters:
receiver (callable) – the function to call
Register
receiverto be called with line-delimited chunks of log data. The callable is invoked asreceiver(stream, chunk), where the stream is indicated by a single character, or None for logs without streams. The chunk is a single string containing an arbitrary number of log lines, and terminated with a newline. When the logfile is finished,receiverwill be invoked withNonefor both arguments.The callable cannot return a Deferred. If it must perform some asynchronous operation, it will need to handle its own Deferreds, and be aware that multiple overlapping calls may occur.
Note that no “rewinding” takes place: only log content added after the call to
subscribewill be supplied toreceiver.
- flush()
- Returns:
Deferred
Flush any pending data to database. All unfinished lines will be terminated with newline characters.
- finish()
- Returns:
Deferred
This method indicates that the logfile is finished. No further additions will be permitted.
In use, callers will receive a subclass with methods appropriate for the log type:
- class buildbot.process.log.TextLog
- addContent(text):
- Parameters:
text – log content
- Returns:
Deferred
Add the given data to the log. The data need not end on a newline boundary.
- class buildbot.process.log.HTMLLog
- addContent(text):
- Parameters:
text – log content
- Returns:
Deferred
Same as
TextLog.addContent.
- class buildbot.process.log.StreamLog
This class handles logs containing three interleaved streams: stdout, stderr, and header. The resulting log maintains data distinguishing these streams, so they can be filtered or displayed in different colors. This class is used to represent the stdio log in most steps.
- addStdout(text)
- Parameters:
text – log content
- Returns:
Deferred
Add content to the stdout stream. The data need not end on a newline boundary.
- addStderr(text)
- Parameters:
text – log content
- Returns:
Deferred
Add content to the stderr stream. The data need not end on a newline boundary.
- addHeader(text)
- Parameters:
text – log content
- Returns:
Deferred
Add content to the header stream. The data need not end on a newline boundary.
3.10.16. LogObservers
- class buildbot.process.logobserver.LogObserver
This is a base class for objects which receive logs from worker commands as they are produced. It does not provide an interface for reading logs - such access should occur directly through the Data API.
See Adding LogObservers for help creating and using a custom log observer.
The three methods that subclasses may override follow. None of these methods may return a Deferred. It is up to the callee to handle any asynchronous operations. Subclasses may also override the constructor, with no need to call
LogObserver’s constructor.- outReceived(data):
- Parameters:
data (unicode) – received data
This method is invoked when a “chunk” of data arrives in the log. The chunk contains one or more newline-terminated unicode lines. For stream logs (e.g.,
stdio), output to stderr generates a call toerrReceived, instead.
- errReceived(data):
- Parameters:
data (unicode) – received data
This method is similar to
outReceived, but is called for output to stderr.
- headerReceived(data):
- Parameters:
data (unicode) – received data
This method is similar to
outReceived, but is called for header output.
- finishReceived()
This method is invoked when the observed log is finished.
- class buildbot.process.logobserver.LogLineObserver
This subclass of
LogObservercalls its subclass methods once for each line, instead of once per chunk.- outLineReceived(line):
- Parameters:
line (unicode) – received line, without newline
Like
outReceived, this is called once for each line of output received. The argument does not contain the trailing newline character.
- errLineReceived(line):
- Parameters:
line (unicode) – received line, without newline
Similar to
outLineReceived, but for stderr.
- headerLineReceived(line):
- Parameters:
line (unicode) – received line, without newline
Similar to
outLineReceived, but for header output.
- finishReceived()
This method, inherited from
LogObserver, is invoked when the observed log is finished.
- class buildbot.process.logobserver.LineConsumerLogObserver
This subclass of
LogObservertakes a generator function and “sends” each line to that function. This allows consumers to be written as stateful Python functions, e.g.,def logConsumer(self): while True: stream, line = yield if stream == 'o' and line.startswith('W'): self.warnings.append(line[1:]) def __init__(self): ... self.warnings = [] self.addLogObserver('stdio', logobserver.LineConsumerLogObserver(self.logConsumer))
Each
yieldexpression evaluates to a tuple of (stream, line), where the stream is one of ‘o’, ‘e’, or ‘h’ for stdout, stderr, and header, respectively. As with any generator function, theyieldexpression will raise aGeneratorExitexception when the generator is complete. To do something after the log is finished, just catch this exception (but then re-raise it or return).def logConsumer(self): while True: try: stream, line = yield if stream == 'o' and line.startswith('W'): self.warnings.append(line[1:]) except GeneratorExit: self.warnings.sort() return
Warning
This use of generator functions is a simple Python idiom first described in PEP 342. It is unrelated to the generators used in
inlineCallbacks. In fact, consumers of this type are incompatible with asynchronous programming, as each line must be processed immediately.
- class buildbot.process.logobserver.BufferLogObserver(wantStdout=True, wantStderr=False)
- Parameters:
wantStdout (boolean) – true if stdout should be buffered
wantStderr (boolean) – true if stderr should be buffered
This subclass of
LogObserverbuffers stdout and/or stderr for analysis after the step is complete. This can cause excessive memory consumption if the output is large.- getStdout()
- Returns:
unicode string
Return the accumulated stdout.
- getStderr()
- Returns:
unicode string
Return the accumulated stderr.
3.10.17. Authentication
- class buildbot.www.auth.AuthBase
This class is the base class for all authentication methods. All authentications are not done at the same level, so several optional methods are available. This class implements a default implementation. The login session is stored via twisted’s
request.getSession(), and detailed used information is stored inrequest.getSession().user_info. The session information is then sent to the UI via theconfigconstant (in theuserattribute ofconfig).- userInfoProvider
Authentication modules are responsible for providing user information as detailed as possible. When there is a need to get additional information from another source, a userInfoProvider can optionally be specified.
- reconfigAuth(master, new_config)
- Parameters:
master – the reference to the master
new_config – the reference to the new configuration
Reconfigure the authentication module. In the base class, this simply sets
self.master.
- maybeAutoLogin(request)
- Parameters:
request – the request object
- Returns:
Deferred
This method is called when
/config.jsis fetched. If the authentication method supports automatic login, e.g., from a header provided by a frontend proxy, this method handles the login.If it succeeds, the method sets
request.getSession().user_info. If the login fails unexpectedly, it raisesresource.Error. The default implementation simply returns without settinguser_info.
- getLoginResource()
Return the resource representing
/auth/login.
- getLogout()
Return the resource representing
/auth/logout.
- updateUserInfo(request)
- Parameters:
request – the request object
Separate entrypoint for getting user information. This is a means to call self.userInfoProvider if provided.
- class buildbot.www.auth.UserInfoProviderBase
Class that can be used, to get more info for the user, like groups, from a separate database.
- getUserInfo(username)
- Returns:
the user info for the username used for login, via a Deferred
Returns a
dictwith following keys:email: email address of the userfull_name: Full name of the user, like “Homer Simpson”groups: groups the user belongs to, like [“duff fans”, “dads”]
- class buildbot.www.oauth2.OAuth2Auth
OAuth2Auth implements oauth2 two-factor authentication. With this method,
/auth/loginis called twice. The first time (without argument), it should return the URL the browser has to redirect to in order to perform oauth2 authentication and authorization. Then the oauth2 provider will redirect to/auth/login?code=???and the Buildbot web server will verify the code using the oauth2 provider.Typical login process is:
UI calls the
/auth/loginAPI and redirects the browser to the returned oauth2 provider URLoauth2 provider shows a web page with a form for the user to authenticate, and asks the user for permission for Buildbot to access their account
oauth2 provider redirects the browser to
/auth/login?code=???OAuth2Auth module verifies the code, and get the user’s additional information
Buildbot UI is reloaded, with the user authenticated
This implementation is using requests. Subclasses must override the following class attributes:
name: Name of the oauth pluginfaIcon: Font awesome class to use for login button logoresourceEndpoint: URI of the resource where the authentication token is usedauthUri: URI the browser is pointed to let the user enter credstokenUri: URI to verify the browser code and get auth tokenauthUriAdditionalParams: Additional parameters for the authUritokenUriAdditionalParams: Additional parameters for the tokenUri
- getUserInfoFromOAuthClient(self, c)
This method is called after a successful authentication to get additional information about the user from the oauth2 provider.
3.10.18. Avatars
Buildbot’s avatar support associates a small image with each user.
- class buildbot.www.avatar.AvatarBase
This class can be used to get the avatars for the users. It can be used for authenticated users, but also for the users referenced in changes.
- getUserAvatar(self, email, size, defaultAvatarUrl)
- Returns:
the user’s avatar, from the user’s email (via Deferred).
If the data is directly available, this function returns a tuple
(mime_type, picture_raw_data). If the data is available in another URL, this function can raiseresource.Redirect(avatar_url), and the web server will redirect to the avatar_url.
3.10.19. Web Server Classes
Most of the source in master/buildbot/www is self-explanatory. However, a few classes and methods deserve some special mention.
3.10.19.1. Resources
- class buildbot.www.resource.Redirect(url)
This is a subclass of Twisted Web’s
Error. If this is raised withinasyncRenderHelper, the user will be redirected to the given URL.
- class buildbot.www.resource.Resource
This class specializes the usual Twisted Web
Resourceclass.It adds support for resources getting notified when the master is reconfigured.
- needsReconfig
If True,
reconfigResourcewill be called on reconfig.
- reconfigResource(new_config)
- Parameters:
new_config – new
MasterConfiginstance- Returns:
Deferred if desired
Reconfigure this resource.
It’s surprisingly difficult to render a Twisted Web resource asynchronously. This next method makes it quite a bit easier.
- asyncRenderHelper(request, callable, writeError=None)
- Parameters:
request – the request instance
callable – the render function
writeError – optional callable for rendering errors
This method will call
callable, which can be async or a Deferred, with the givenrequest. The value returned from this callable will be converted to an HTTP response. Exceptions, includingErrorsubclasses, are handled properly. If the callable raisesRedirect, the response will be a suitable HTTP 302 redirect.Use this method as follows:
def render_GET(self, request): return self.asyncRenderHelper(request, self.renderThing)
4. Release Notes
4.1. Buildbot 4.2.1.dev490 ( 2025-05-12 )
4.1.1. Bug fixes
Fixed crash when WSGI dashboard uses non-existent icon. A default icon is now used instead (#7435).
4.1.2. Improved Documentation
Updated developer documentation to reflect React web UI stack.
4.2. Buildbot 4.3.0 ( 2025-05-12 )
4.2.1. Bug fixes
Improved handling of not found exceptions when stopping containers in Docker latent worker.
Fixed garbage output from ANSI escape code sequences in build step logs (bug #7852)
Fixed
AuthorizedKeysManholenot picking up the specifiedssh_host_keydirFixed deprecation warnings being incorrectly raised as errors
Fixed Git step failures when checking out commits containing LFS objects that require authentication
Fixed crashes when using callable categories with HgPoller
HttpStatusPushnow correctly exposes and passes through the skip_encoding parameterImplemented bold text style in build step logs (issue #7853)
- Websocket connections no longer allow unauthenticated users to connect when authorization is
enabled
4.2.2. Changes
Buildnow has a mutableenvattribute, which is deep copied from theBuilder’sBuilderConfig.env. This allows steps to modify their current build’s environment if needed.
4.2.3. Features
Added a
Build.do_buildfield andBuilderConfig.do_build_ifto allow skipping entire buildsAdded support for configuring the database engine via the
db.engine_kwargsconfiguration keyAdded support for tracking exact commits within codebases
HTTPSessionnow supports mTLS.HttpStatusPushnow supports mTLS endpoints by accepting client certificates via the cert parameter (as either a combined file or tuple)Added a
Log.flush()method to flush incomplete log lines without finishing the logAdded a runtime_timeout argument to MasterShellCommand issue #8377
Added a builds/<buildid>/triggered_builds Data API endpoint to retrieve builds triggered by a specific build
4.2.4. Misc
Added a
path_clsattribute (eitherPureWindowsPathorPurePosixPathdepending on worker OS). This will replacepath_moduleusage with better ergonomics and typing support.
4.2.5. Deprecations and Removals
BuildFactory workdir callable support has been deprecated. Use renderables instead.
Endpoint.pathPatterns as a multiline string has been deprecated. Use list of strings instead.
ResourceType.eventPathPatterns as a multiline string has been deprecated. Use list of strings instead.
DataConnector.produceEvent() has been deprecated. Use Data API update methods as replacement.
The
rootlinksData and REST API endpoint has been deprecatedBuildbot Master now requires Python 3.9 or newer. Python 3.8 is no longer supported.
Raising
NotImplementedErrorfromreconfigServiceWithSiblingorreconfigServicehas been deprecated. UsecanReconfigWithSibling()that returnsFalseas a replacement.buildbot.schedulers.base.BaseSchedulerhas been deprecated. Replace uses of it withReconfigurableBaseScheduler.Old location of
Dependentscheduler has been deprecated. Instead ofbuildbot.schedulers.basic.Dependentusebuildbot.plugins.schedulers.Dependent.
4.3. Buildbot 4.2.1 ( 2025-01-10 )
4.3.1. Bug fixes
Fixed regression introduced in Buildbot 4.2.0 that broke support for renderable Git step repourl parameter.
4.4. Buildbot 4.2.0 ( 2024-12-10 )
4.4.1. Bug fixes
Fixed an Access is denied error on Windows when calling AssignProcessToJobObject (issue #8162).
Improved new build prioritization when many builds arrive at similar time.
Fixed
copydbscript when SQLAlchemy 2.x is used.Fixed
copydbscript when there are rebuilt builds in the database.Fixed
SetPropertiesFromEnvnot treating environment variable names as case insensitive for Windows workersReliability of Gerrit change source has been improved on unstable connections.
Fixed bad default of Github webhooks not verifying HTTPS certificates in connections originating from Buildbot.
Fixed the timestamp comparison in janitor: it should cleanup builds ‘older than’ given timestamp - previously janitor would delete all build_data for builds ‘newer than’ the configured build data horizon.
Fixed compatibility with Twisted 24.11.0 due to
twisted.python.constantsmodule being moved.Fixed build status reporting to use state_string as fallback when
status_stringisNone. This makes IRC build failure messages more informative by showing the failure reason instead of just “failed”.Fix exception when worker loses connection to master while a command is running.
Fix certain combinations of ANSI reset escape sequences not displayed correctly (issue #8216).
Fixed wrong positioning of search box in Buildbot UI log viewer.
Improved ANSI escape sequence support in Buildbot UI log viewer: - Fixed support for formatting and color reset. - Fixed support for simultaneous background and foreground color (issue #8151).
Slightly reduced waterfall view loading times
4.4.2. Improved Documentation
Fixed Scheduler documentation to indicate that owner property is a string, not a list, and contains only one owner. This property was changed to singular and to string in Buildbot 1.0, but documentation was not updated.
4.4.3. Features
Use standard URL syntax for Git steps to enable the use of a dedicated SSH port.
Added
ignore-fk-error-rowsoption tocopy-dbscript. It allows ignoring all rows that fail foreign key constraint checks. This is useful in cases when migrating from a database engine that does not support foreign key constraints to one that does.Enhanced
debounce.methodto support calling target function only when the burst is finished.Added support for specifying the master protocol to
DockerLatentWorkerandKubeLatentWorker. These classes get newmaster_protocolargument. The worker docker image will receive the master protocol via BUILDMASTER_PROTOCOL environment variable.Master’s
cleanupdbcommand can now run database optimization on PostgreSQL and MySQL (only available on SQLite previously)Added a way to setup
TestReactorMixinwith explicit tear down function.Added a way to return all test result sets from getTestResultSets() and from data API via new /test_result_sets path.
4.4.4. Misc
Logs compression/decompression operation no longer occur in a Database connection thread. This change will improve overall master reactivity on instances receiving large logs from Steps.
Improve logs compression operation performance with zstd. Logs compression/decompression tasks now re-use
zstandard’sZstdCompressorandZstdDecompressorobjects, as advised in the documentation.BuildView’s ‘Changes’ tab (builders/:builderid/builds/:buildnumber) now only loads a limited number of changes, with the option to load more.
BuildView (builders/:builderid/builds/:buildnumber) now load ‘Changes’ and ‘Responsible Users’ on first access to the tab. This lower unnecessary queries on the master.
4.4.5. Deprecations and Removals
The following test tear down functions have been deprecated:
TestBuildStepMixin.tear_down_test_build_step()TestReactorMixin.tear_down_test_reactor()
The tear down is now run automatically. Any additional test tear down should be run using
twisted.trial.TestCase.addCleanupto better control tear down ordering.Worker.__init__no longer acceptsusePTYargument. It has been deprecated for a long time and no other values thanNonewere accepted.
4.5. Buildbot 4.1.0 ( 2024-10-13 )
4.5.1. Bug fixes
Fixed crash in
GerritEventLogPollerwhen invalid input is passed (issue #7612)Fixed
Buildsummary containing non obfuscatedSecretvalues present in a failedBuildStepsummary (issue #7833)Fixed data API query using buildername to correctly work with buildername containing spaces and unicode characters (issue #7752)
Fixed an error when master is reconfigured with new builders and a build finishing at this time, causing the build to never finish.
Fixed crash on master shutdown trying to insubstantiate build’s worker when no worker is assigned to the build (issue #7753)
Fixed confusing error messages in case of HTTP errors that occur when connecting to Gerrit server.
Fixed
GitPollermerge commit processing.GitPollernow correctly list merge commit files. (issue #7494)Fixed hang in
buildbot stop --cleanwhen a in progress build was waiting on a not yet started BuildRequest that it triggered.Improved error message in case of OAuth2 failures.
Fixed display of navigation links when the web frontend is displayed in narrow window (issue #7818)
Fixed inconsistent logs data in reports produced by report generators. In particular,
stepnamekey is consistently attached to logs regardless if they come with build steps or with the globallogskey.Fixed a regression where a
ChoiceStringParameterrequires a user selected value (no default value), but the force build form incorrectly displays the first choice as being selected which later causes validation error.Fixed logs
/rawand/raw_inlineendpoint requiring large memory on master (more than full log size) (issue #3011)Fixed sidebar group expander to use different icon for expanded groups.
Log queries in BuildView (
builders/:builderid/builds/:buildnumber) have been reduced when logs won’t be displayed to the user.REST API json responses now correctly provide the
Content-Lengthheader for non-HEAD requests.Buildbot is now compatible with SQLAlchemy v2.0+
4.5.2. Changes
Buildbot will now add a trailing ‘/’ to the
buildbotURLandtitleURLconfigured values if it does not have one.The internal API presented by the database connectors has been changed to return data classes instead of Python dictionaries. For backwards compatibility the classes also support being accessed as dictionaries. The following functions have been affected:
BuildDataConnectorComponentgetBuildData,getBuildDataNoValue, andgetAllBuildDataNoValuesnow return aBuildDataModelinstead of a dictionary.BuildsConnectorComponentgetBuild,getBuildByNumber,getPrevSuccessfulBuild,getBuildsForChange,getBuilds,_getRecentBuilds, and_getBuildnow return aBuildModelinstead of a dictionary.BuildRequestsConnectorComponentgetBuildRequest, andgetBuildRequestsnow return aBuildRequestModelinstead of a dictionary.BuildsetsConnectorComponentgetBuildset,getBuildsets, andgetRecentBuildsetsnow return aBuildSetModelinstead of a dictionary.BuildersConnectorComponentgetBuilderandgetBuildersnow return aBuilderModelinstead of a dictionary.ChangesConnectorComponentgetChange,getChangesForBuild,getChangeFromSSid, andgetChangesnow return aChangeModelinstead of a dictionary.ChangeSourcesConnectorComponentgetChangeSource, andgetChangeSourcesnow return aChangeSourceModelinstead of a dictionary.LogsConnectorComponentgetLog,getLogBySlug, andgetLogsnow return aLogModelinstead of a dictionary.MastersConnectorComponentgetMaster, andgetMastersnow return aMasterModelinstead of a dictionary.ProjectsConnectorComponentget_project,get_projects, andget_active_projectsnow return aProjectModelinstead of a dictionary.SchedulersConnectorComponentgetScheduler, andgetSchedulersnow return aSchedulerModelinstead of a dictionary.SourceStampsConnectorComponentgetSourceStamp,get_sourcestamps_for_buildset,getSourceStampsForBuild, andgetSourceStampsnow return aSourceStampModelinstead of a dictionary.StepsConnectorComponentgetStep, andgetStepsnow return aStepModelinstead of a dictionary.TestResultsConnectorComponentgetTestResult, andgetTestResultsnow return aTestResultModelinstead of a dictionary.TestResultSetsConnectorComponentgetTestResultSet, andgetTestResultSetsnow return aTestResultSetModelinstead of a dictionary.UsersConnectorComponentgetUser,getUserByUsername, andgetUsersnow return aUserModelinstead of a dictionary.WorkersConnectorComponentgetWorker, andgetWorkersnow return aWorkerModelinstead of a dictionary.
Gitstep no longer includes-t(tags) option when fetching by default. Explicitly enabling withtags=Trueis now required to achieve the same functionality.logCompressionMethodwill default tozstdif thebuildbot[zstd]extra set was installed (otherwise, it default togzipas before).Buildbot now requires
treqpackage to be installed.Buildbot worker will now run process in
JobObjecton Windows, so child processes can be killed if main process dies itself either intentionally or accidentally.Worker docker image now uses Debian 12.
Settings UI has been improved by reducing group header size and adding space between groups.
4.5.3. Features
copy-dbscript now reads/writes in parallel and in batches. This results in it being faster and having smaller memory footprintAdded possibility to set
START_TIMEOUTvia environment variable.Added data API
/workers/n:workerid/buildersallowing to query the Builders assigned to a workerThe
db_urlconfig value can now be a renderable, allowing usage of secrets from secrets providers. eg.util.Interpolate("postgresql+psycopg2://db_user:%(secret:db_password)s@db_host:db_port/db_name")Added
tooltipparameter to the forcescheduler, allowing passing help text to web frontend to explain the user what the parameters mean.GitandGitPushsteps andGitPollerchange source now support authentication with username/password. Credentials can be provided through theauth_credentialsand/orgit_credentialsparameters.GitstepgetDescriptionconfiguration now supports the first-parent and exclude arguments.Gitstep now honors the shallow option in fetching in addition to clone and submodules.Github change hooks how have access to
full_nameof the repository when rendering GitHub tokens.Implemented simpler way to perform HTTP requests via
httpclientservice.HTTPSession. It does not require a parent service.logCompressionMethodcan now be set tobr(using brotli, requires thebuildbot[brotli]extra) orzstd(using zstandard, requires thebuildbot[zstd]extra)Buildbot now compress REST API responses with the appropriate
accept-encodingheader is set. Available encodings are: gzip, brotli (requires thebuildbot[brotli]extra), and zstd (requires thebuildbot[zstd]extra)Added
max_linesparameter to the shell command, allowing processes to be terminated if they exceed a specified line count.The
want_logs_contentargument of message formatters now supports being passed a list of logs for which to load the content.Exposed log URLs as
url,url_raw,url_raw_inlinein the log dictionary generated by report generators.TestBuildStepMixinnow supports testing multiple steps added viasetup_step()in a single unit test.Worker base directory has been exposed as a normal build property called
basedir.Show build and step start and stop times when hovering on duration in build step table.
The following website URLs now support receiving
buildernameinstead ofbuilderidto select the builder:builders/:builderid,builders/:builderid/builds/:buildnumber, andbuilders/:builderid/builds/:buildnumber/steps/:stepnumber/logs/:logslug.Human readable time is now shown in addition to timestamp in various debug tabs in the web frontend.
ChoiceStringParametercan now have bothmultiple=Trueandstrict=Falseallowing to create values in the web UI.Buildrequests tables in various places in the web UI now have a button to load more items.
Added a way to configure sidebar menu group expand behavior in web frontend.
Web UI’s Worker view (
workers/{workerId}) now has aBuilderstab showing Builders configured on the workerBuilders view now paginates builders list. Page size can be configured with the setting ‘Builders page related settings > Number of builders to show per page’.
Workers view now paginates workers list. Page size can be configured with the setting ‘Workers page related settings > Number of workers to show per page’.
Workers view now includes a search box to filter on worker’s name.
4.5.4. Deprecations and Removals
Buildbot worker no longer supports Python 3.4, 3.5 and 3.6. Older version of Buildbot worker should be used in case it needs to run on these old versions of Python. Old versions of Buildbot worker are fully supported by Buildbot master.
buildbot.db.test_results.TestResultDictis deprecated in favor ofbuildbot.db.test_results.TestResultModel.buildbot.db.test_result_sets.TestResultSetDictis deprecated in favor ofbuildbot.db.test_result_sets.TestResultSetModel.buildbot.db.buildrequests.BrDictis deprecated in favor ofbuildbot.db.buildrequests.BuildRequestModel.buildbot.db.build_data.BuildDataDictis deprecated in favor ofbuildbot.db.build_data.BuildDataModel.buildbot.db.changes.ChDictis deprecated in favor ofbuildbot.db.changes.ChangeModel.buildbot.db.masters.MasterDictis deprecated in favor ofbuildbot.db.masters.MasterModel.buildbot.db.sourcestamps.SsDictis deprecated in favor ofbuildbot.db.sourcestamps.SourceStampModel.buildbot.db.users.UsDictis deprecated in favor ofbuildbot.db.users.UserModel.The following methods of
httpclientservice.HTTPClientServicehave been deprecated:get,delete,post,put,updateHeaders. Use corresponding methods fromHTTPSession.The
add_logsargument ofBuildStatusGenerator,BuildStartEndStatusGeneratorandBuildSetStatusGeneratorhas been removed. As a replacement, setwant_logs_contentof the passed message formatter.The
build_files,worker_envandworker_versionarguments ofTestBuildStepMixin.setup_step()have been deprecated. As a replacement, callTestBuildStepMixin.setup_build()beforesetup_step.The
stepattribute ofTestBuildStepMixinhas been deprecated. As a replacement, callTestBuildStepMixin.get_nth_step().Master running with Twisted >= 24.7.0 does not work with buildbot-worker 0.8. Use Twisted 24.3.0 on master if you need to communicate with buildbot-worker 0.8. This may be fixed in the future.
Buildbot master now requires Twisted 22.1.0 or newer.
4.6. Buildbot 4.0.4 ( 2024-10-12 )
4.6.1. Bug fixes
Fixed missing builder force scheduler route
/builders/:builderid/force/:scheduler.Fixed URL of WGSI dashboards to keep backward compatibility with the old non-React WSGI plugin.
Fixed display of long property values by wrapping them
Dropped no longer needed dependency on the
futurelibrary
4.7. Buildbot 4.0.3 ( 2024-09-27 )
4.7.1. Bug fixes
Fixed function signature for CustomAuth.check_credentials.
Fixed ReactUI authentication when Buildbot is hosted behind a reverse proxy not at url’s root. (issue #7814)
Made Tags column in Builders page take less space when there are no tags
Fixed cropped change author avatar image in web UI.
Fixed pluralization of build count in build summaries in the web UI.
The change details page no longer requires an additional mouse click to show the change details.
Fixed showing misleading “Loading” spinner when a change has no builds.
Fixed too small spacing in change header text in web UI.
Fixed showing erroneous zero changes count in the web UI when loading changes.
Cleaned up build and worker tabs in builders view in web UI.
Fixed links to external URLs in the about pages.
Fixed missing warnings on old browsers.
Builds in the home page are now sorted to show the latest one first.
Fixed loading of plugins settings (e.g. from master’s ui_default_config)
Improved visual separation between pending build count and build status in trigger build steps in web UI.
4.7.2. Changes
Buildbot has migrated to quay.io container registry for storing released container images. In order to migrate to the new registry container image name in FROM instruction in Dockerfiles needs to be adjusted to quay.io/buildbot/buildbot-master or quay.io/buildbot/buildbot-worker.
GitHubStatusPush will now render github tokens right before the request. This allow to update the token in the configuration file without restarting the server, which is useful for Github App installations where tokens are rotated every hour.
The list of supported browsers has been updated to Chrome >=80, Firefox >= 80, Edge >=80, Safari >= 14, Opera >=67.
4.7.3. Features
The text displayed in build links is now configurable and can use any build property. It was showing build number or branch and build number before.
Changes and builds tables in various places in the web UI now have a button to load more items.
4.8. Buildbot 4.0.2 ( 2024-08-01 )
4.8.1. Bug fixes
Fixed
GitPollerwhen repourl has the port specified (issue #7822)Fixed
ChoiceStringParameterfields withmultiplewould not store the selected valuesFixed unnecessary trimming of spaces in logs showed in the web UI (issue #7774)
Fixed favicon colors on build views in the web UI
Fixed the icon on the about page in the web UI
Fixed a regression where builds in waterfall view were no longer linking to the build page.
Fixed an issue that would cause non-ui www plugins to not be configured (such as buildbot-badges) (issue #7665)
4.8.2. Changes
Buildbot will now error when configured with multiple services of the same type are configured with the same name (issue #6987)
4.9. Buildbot 4.0.1 ( 2024-07-12 )
4.9.1. Bug fixes
Transfer build steps (
FileUpload,DirectoryUpload,MultipleFileUpload,FileDownload, andStringDownload) now correctly remove destination on failure, no longer leaving partial content (issue #2860)Fixed ReactUI when Buildbot is hosted behind a reverse proxy not at url’s root (issue #7260, issue #7746)
Fixed results color shown on builder’s header in waterfall view
Fixed cases where waterfall view could be squashed to a pixel high
Improved flexibility of
scaling_waterfallsetting to support floating-point values for more condensed view.Fixed broken theming in web frontend when not using it via
base_reactplugin name.Fixed
/builders/n:builderid/builds/n:build_number/propertiesendpoint returning results for wrong builds.Fixed useless logged
fatal Exception on DB: log with slug ... already exists in this steperrors.
4.10. Buildbot 4.0.0 ( 2024-06-24 )
4.10.1. Bug fixes
BitbucketServerCoreAPIStatusPushnow handles epoch time format in events as well as datetime.datetime.Fixed buildrequest cancel requests being ignored under certain infrequent conditions.
Fixed an issue in lock handling which caused step locks to be acquired in excess of their configured capacity under certain conditions (issue #5655, issue #5987).
OldBuildCancellerwill now cancel builds only if a superseding buildrequest is actually created. Previously it was enough to observe a superseding change even if it did not result in actually running builds.Fixed
OldBuildCancellercrashes when sourcestamp with no branch was ingested.Fixed
ChoiceStringParameterfields being not present in ForceBuild Form.Fixed initialization of default web setting values from config.
Fixed loading of user saved settings in React web frontend.
4.10.2. Changes
Added optional
locks_acquired_atargument tomaster.data.updates.set_step_locks_acquired_at().Master and Worker packages have stopped using the deprecated
distutilspackage and rely on setuptools. Worker installation now requires setuptools.Events between
GerritChangeSourceandGerritEventLogPollerare no longer deduplicated. UseGerritChangeSourcewith both SSH and HTTP API configured as a replacement.GitPollerno longer track themasterbranch when neitherbranchnorbranchesarguments are provided. It now track the remote’s default branch.Improved performance of
OpenstackWorkerstartup when there are large number of images on the server.buildbot.www.plugin.Applicationno longer accepts module name as the first parameter. It requires the name of package. In most cases where__name__was being passed,__package__is now required.Padding of the UI elements in the web UI has been reduced to increase density of presented data.
Buildbot now requires SQLAlchemy 1.4.0 or newer.
Old
importlib_resourcesis no longer used.
4.10.3. Features
Added
rebuilt_buildidkey-value pair to buildsets to be able to keep track on which build is being rebuild.Buildbot now tracks total time that has been spent waiting for locks in a build.
Added
projectidandprojectnameproperties to BuildThe
worker_preparationdummy step that tracks various build startup overhead has been split into two steps to track worker startup and locks wait times separately.Builds now have
builderidproperty.Build request cancellation has been exposed to the Data API.
Added optional
started_atandlocks_acquiredarguments tomaster.data.updates.startStep().buildbot.test.fake.httpclientservice.HTTPClientServicenow can simulate network and processing delays viaprocessing_delay_soption toexpect()method.Added ability to poll HTTP event API of Gerrit server to
GerritChangeSource. This has the following advantages compared to simply pointingGerritChangeSourceandGerritEventLogPollerat the same Gerrit server:All events are properly deduplicated
SSH connection is restarted in case of silent hangs of underlying SSH connection (this may happen even when ServerAliveInterval is used)
Added
select_next_workerglobal configuration key which sets defaultnextWorkercustomization hook on all builders.Added support for connecting Kubernetes workers to multiple Kubernetes clusters.
Raw logs downloaded from the web UI now include full identifying information in the filename.
Raw text logs downloaded from the web UI now include a small header with identifying information.
The Rebuild button on a Build’s view now redirect to the Buildrequest corresponding to the latest rebuild.
Add a “Workers” tab to the Builder view listing workers that are assigned to this builder (issue #7162)
Added check for correct argument types to
BuildStepandShellCommandbuild steps and all steps deriving fromShellMixin. This will avoid wrong arguments causing confusing errors in unrelated parts of the codebase.Implemented a check for step attempting to acquire the same lock as its build.
Implement support for customizing
affinityandnodeSelectorfields in Kubernetes pod spec for Kubernetes worker.The debug tab in build page now shows previous build that has been built on the same worker for the same builder. This helps debugging any build directory cleanup problems in custom Buildbot setups.
Add support for case insensitive search within the logs.
Add support for regex search within the logs.
4.10.4. Deprecations and Removals
buildbot.process.factory.Distutilsfactory has been deprecated.HashiCorpVaultSecretProviderhas been removed.GerritStatusPushno longer accepts deprecated arguments:reviewCB,startCB,reviewArg,startArg,summaryCB,summaryArg,builders,wantSteps,wantLogs.Deprecated module-level attributes have been deleted.
GerritStatusPushcallback functions now can only return dictionary type.AngularJS web frontend has been removed.
Deprecated
LineBoundaryFinder callbackargument has been removed.Removed Python 2.7 support on the worker. This does not affect compatibility of connecting workers running old versions of Buildbot to masters running new versions of Buildbot.
This release includes all changes up to Buildbot 3.11.5.
5. Older Release Notes
5.1. Buildbot 3.11.9 ( 2024-10-13 )
5.1.1. Bug fixes
Fixed missing builder force scheduler route
/builders/:builderid/force/:scheduler.Fixed URL of WGSI dashboards to keep backward compatibility with the old non-React WSGI plugin.
Fixed display of long property values by wrapping them
5.2. Buildbot 3.11.8 ( 2024-09-27 )
5.2.1. Bug fixes
Made Tags column in Builders page take less space when there are no tags.
Fixed cropped change author avatar image in web UI.
Correctly pluralize build count in build summaries in the web UI.
The change details page no longer requires an additional mouse click to show the change details.
Fixed showing misleading “Loading” spinner when a change has no builds.
Fixed too small spacing in change header text in web UI.
Fixed showing erroneous zero changes count in the web UI when loading changes.
Cleaned up build and worker tabs in builders view in web UI.
Improved visual separation between pending build count and build status in trigger build steps in web UI.
5.2.2. Changes
Buildbot has migrated to
quay.iocontainer registry for storing released container images. In order to migrate to the new registry container image name inFROMinstruction in Dockerfiles needs to be adjusted toquay.io/buildbot/buildbot-masterorquay.io/buildbot/buildbot-worker.The list of supported browsers has been updated to Chrome >=80, Firefox >= 80, Edge >=80, Safari >= 14, Opera >=67.
5.2.3. Features
Add a “Workers” tab to the Builder view listing workers that are assigned to this builder (issue #7162)
The text displayed in build links is now configurable and can use any build property. It was showing build number or branch and build number before.
Changes and builds tables in various places in the web UI now have a button to load more items.
5.3. Buildbot 3.11.7 ( 2024-08-01 )
5.3.1. Bug fixes
Fixed
GitPollerwhen repourl has the port specified (issue #7822)Fixed
ChoiceStringParameterfields withmultiplewould not store the selected valuesFixed unnecessary trimming of spaces in logs showed in the web UI (issue #7774)
Fixed favicon colors on build views in the web UI
Fixed the icon on the about page in the web UI
Fixed a regression where builds in waterfall view were no longer linking to the build page.
5.3.2. Changes
Buildbot will now error when configured with multiple services of the same type are configured with the same name (issue #6987)
5.4. Buildbot 3.11.6 ( 2024-07-12 )
5.4.1. Bug fixes
Transfer build steps (
FileUpload,DirectoryUpload,MultipleFileUpload,FileDownload, andStringDownload) now correctly remove destination on failure, no longer leaving partial content (issue #2860)Fixed ReactUI when Buildbot is hosted behind a reverse proxy not at url’s root (issue #7260, issue #7746)
Fixed results color shown on builder’s header in waterfall view
Fixed cases where waterfall view could be squashed to a pixel high
Improved flexibility of scaling_waterfall setting to support floating-point values for more condensed view.
5.5. Buildbot 3.11.5 ( 2024-06-24 )
5.5.1. Bug fixes
Fixed several occasional data update glitches in web frontend
Fixed display of newly added builds in Workers view in the web frontend.
5.6. Buildbot 3.11.4 ( 2024-06-20 )
5.6.1. Bug fixes
Fixed a regression where
GitPollerwould no longer register new changes (regression introduced in 3.11.3 in #7554)
5.7. Buildbot 3.11.3 ( 2024-05-19 )
5.7.1. Bug fixes
Fixed a bug that caused
GitPollerrunning with git configured withfetch.prune=trueparameter to fail.Fixed a bug that caused
GitPollerto miss changes when buildbot is reconfiguredReduced length of directory names produced by
GitPollerinternally. Long directory names could potentially breakGitPolleron filesystems with low path and name length limits.Removed credentials from
repourlused in the tracker branch name.
5.7.2. Deprecations and Removals
The
pollinterval(note the smalli) argument of various change sources has been deprecated with a warning in favor ofpollInterval.
5.7.3. Features
Added
MessageFormatterFunctionRawwhich allows complete customization of messages to be emitted. This feature has been available since 3.11.0 and only the announcement has been missed.
5.8. Buildbot 3.11.2 ( 2024-05-04 )
5.8.1. Bug fixes
Fixed an error in HgPoller when repository initialization fails (issue #7488)
Updated Makefile to handle Windows paths and Python.
Added a web configuration setting to select whether build completion or start times are displayed.
Added revision info column in the web frontend.
Fixed steps raw log download button.
Fixed a regression in React UI that prevented hosting Buildbot at a custom URL prefix. This allows to support multiple Buildbot instances on a single server.
5.8.2. Improved Documentation
Documented that
ChangeSourcedoes not support secrets (or any other renderables), best practice of not encoding secret values in changes and alternative solutions when secret values in changes are unavoidable.ChangeSourceaccidentally supported renderable arguments up until Buildbot 3.7, but this was not documented behavior.
5.9. Buildbot 3.11.1 ( 2024-02-24 )
5.9.1. Bug fixes
GitPollernow ensures the SSH Private Key it uses has a trailing newline.Migrated off python-future which prevented installing Buildbot on distributions that do not provide that package.
Fix sporadic navigation to builders page when new build is started (issue #7307).
5.10. Buildbot 3.11.0 ( 2024-01-25 )
5.10.1. Bug fixes
Declare Python 3.12 compatibility in generated packages of master and worker
5.10.2. Features
Added a new WSGI dashboards plugin for React frontend. It is backwards compatible with AngularJS one but may require changes in CSS styling of displayed web pages.
Implemented a report generator (
BuildSetCombinedStatusGenerator) that can access complete information about a buildset.Low level database API now has
get_sourcestamps_for_buildsetto get source stamps for a buildset. “/buildsets/:buildsetid/sourcestamps” endpoint has been added to access this from the Data API.Added buildset information to dictionaries returned by report generators.
Added a way to pass additional reporter-specific data to Reporters. Added
extra_info_cbargument toMessageFormatterfor this use case.Implemented support for report generators in
GerritStatusPush.
5.10.3. Deprecations and Removals
The
reviewCB,reviewArg,startCB,startArg,summaryCB,summaryArg,builders,wantSteps,wantLogsarguments ofGerritStatusPushhave been deprecated.
5.11. Buildbot 3.10.1 ( 2023-12-26 )
5.11.1. Bug fixes
Fixed support for Twisted 23.10 and Python 3.12.
Fixed Data API to have “parent_buildid” key-value pair in messages for rebuilt buildsets (:issue 7222).
Improved security of tarfile extraction to help avoid CVE-2007-4559. See more details in https://peps.python.org/pep-0706/. Buildbot uses filter=’data’ now. (issue #7294)
Fixed web frontend package build on certain Python versions (e.g. 3.9).
5.12. Buildbot 3.10.0 ( 2023-12-04 )
5.12.1. Bug fixes
buildbot.changes.bitbucket.BitbucketPullrequestPollerhas been updated to emit the change files.Fixed build status key sent to Bitbucket exceeding length limits (issue #7049).
Fixed a race condition resulting in
EXCEPTIONbuild results when build steps that are about to end are cancelled.Buildrequests are now selected by priority and then by buildrequestid (previously, Buildbot used the age as the secondary sort parameter). This preserves the property of choosing the oldest buildrequest, but makes it predictable which buildrequest will be selected, as there might be multiple buildrequests with the same age.
Fixed worker to fail a step
uploadDirectoryinstead of throwing an exception when directory is not available. (issue #5878)Added missing
parent_buildidandparent_relationshipkeys to the buildset completion event in the Data API.Improved handling of Docker containers that fail before worker attaches to master. In such case build will be restarted immediately instead of waiting for a timeout to expire.
Enhanced the accessibility of secret files by enabling group-readability. Previously, secret files were exclusively accessible to the owner. Now, accessibility has been expanded to allow group members access as well. This enhancement is particularly beneficial when utilizing Systemd’s LoadCredential feature, which configures secrets with group-readable (0o440) permissions.
MailNotifiernow works correctly when SSL packages are installed butuseTls=Falseand auth (smtpUser,smtpPassword) is not set. (issue #5609)P4 now reports the correct got_revision when syncing a changelist that only delete files
P4 step now use the rev-spec format //{p4client}/…@{revision} when syncing with a revision
Fixed incorrect propagation of option
--proxy-connection-stringinto buildbot.tac when creating new Worker.Fixed link to Builder in React Grid View.
Addressed a number of timing errors in
Nightlyscheduler by upgradingcronitercode.
5.12.2. Changes
Buildbot will render step properties and check if step should be skipped before acquiring locks. This allows to skip waiting for locks in case step is skipped.
The
isRawandisCollectionattributes of theEndpointtype have been deprecated.Endpointis used to extend the Buildbot API. Us a replacement use the newkindattribute.AbstractLatentWorker.check_instance()now accepts error message being supplied in case instance is not good. The previous API has been deprecated.The published Docker image for the worker now uses Debian 11 (Bullseye) as base image.
The published Docker image for the worker now runs Buildbot in virtualenv.
5.12.3. Improved Documentation
Describe an existing bug with Libvirt latent workers that does not use a copy of the image (:issue 7122).
5.12.4. Features
The new React-based web frontend is no longer experimental. To enable please see the documentation on upgrading to 4.0 for more information. The new web frontend includes the following improvements compared to legacy AngularJS web frontend:
Project support (initially released in Buildbot 3.9.0).
Steps now show the amount of time spent waiting for locks.
The log viewer now supports huge logs without problems.
The log viewer now includes a search box that downloads entire log on-demand without additional button click.
The log viewer now supports downloading log file both as a file and also showing it inline in the browser.
The colors of the website can be adjusted from Buildbot configuration via
www["theme"]key.Buildsteps and pending buildrequests have anchor links which allows linking directly to them from external web pages.
Workers can now be created to use
connection stringright out of the box when new option--connection-string=is used.Docker Latent workers will now show last logs in Buildbot UI when their startup fails.
Added
EndpointKind.RAW_INLINEdata API endpoint type which will show the response data inline in the browser instead of downloading as a file.Implemented a way to specify volumes for containers spawned by
KubeLatentWorker.Nightlyscheduler now supports forcing builds at specific times even ifonlyIfChangedparameter was true and there were no important changes.buildbot.steps.source.p4.P4can now take ap4client_typeargument to set the client type (More information on client type [here](https://www.perforce.com/manuals/p4sag/Content/P4SAG/performance.readonly.html))Added data and REST APIs to retrieve only projects with active builders.
Improved step result reporting to specify whether step failed due to a time out.
Added
tagsoption to theGitsource step to download tags when updating repository.Worker now sends
failure_reasonupdate when the command it was running timed out.
5.12.5. Deprecations and Removals
Legacy AngularJS web frontend will be removed in Buildbot 4.0. Fixes to React web frontend that are regressions from AngularJS web frontend will be backported to 3.x Buildbot series to make migration easier.
Buildbot Master now requires Python 3.8 or newer. Python 3.7 is no longer supported.
buildbot.util.cronitermodule has been deprecated in favor of using PyPIcroniterpackage.master.data.updates.setWorkerState()has been deprecated. Usemaster.data.updates.set_worker_paused()andmaster.data.updates.set_worker_graceful()as replacements.Buildbot now requires
dockerof version v4.0.0 or newer for Docker support.BuildStep instances are now more strict about when their attributes can be changed. Changing attributes of BuildStep instances that are not yet part of any build is most likely an error. This is because such instances are only being used to configure a builder as a source to create real steps from. In this scenario any attribute changes are ignored as far as build configuration is concerned.
Such changing of attributes has been deprecated and will become an error in the future release.
For customizing BuildStep after an instance has already been created set_step_arg(name, value) function has been added.
5.13. Buildbot 3.9.2 ( 2023-09-02 )
5.13.1. Bug fixes
Work around requirements parsing error for the Twisted dependency by pinning Twisted to 22.10 or older. This fixes buildbot crash on startup when newest Twisted is installed.
5.14. Buildbot 3.9.1 ( 2023-09-02 )
5.14.1. Bug fixes
Fixed handling of primary key columns on Postgres in the
copy-dbscript.Fixed a race condition in the
copy-dbscript which sometimes lead to no data being copied.Options for create-worker that are converted to numbers are now also checked to be valid Python literals. This will prevent creating invalid worker configurations, e.g.: when using option
--umask=022instead of--umask=0o022or--umask=18. (issue #7047)Fixed worker not connecting error when there are files in WORKER/info folder that can not be decoded. (issue #3585) (issue #4758) (issue #6932)
Fixed incorrect git command line parameters when using
Gitsource step withmode="incremental",shallow=True,submodules=True(regression since Buildbot 3.9.0) (issue #7054).
5.14.2. Improved Documentation
Clarified that
shallowoption for theGitsource step is also supported inincrementalmode.
5.15. Buildbot 3.9.0 ( 2023-08-16 )
5.15.1. Bug fixes
Fixed missed invocations of methods decorated with
util.debouncewhen debouncer was being stopped under certain conditions. This caused step and build state string updates to be sometimes missed.Improved stale connection handling in
GerritChangeSource.GerritChangeSourcewill instruct the ssh client to send periodic keepalive messages and will reconnect if the server does not reply for 45 seconds (default).GerritChangeSourcenow hasssh_server_alive_interval_sandssh_server_alive_count_maxoptions to control this behavior.Fixed unnecessary build started under the following conditions: there is an existing Nightly scheduler,
onlyIfChangedis set to true and there is version upgrade from v3.4.0 (issue #6793).Fixed performance of changes data API queries with custom filters.
Prevent possible event loss during reconfig of reporters (issue #6982).
Fixed exception thrown when worker copies directories in Solaris operating system (issue #6870).
Fixed excessive log messages due to JWT token decoding error (issue #6872).
Fixed excessive log messages when otherwise unsupported
/auth/loginendpoint is accessed when usingRemoteUserAuthauthentication plugin.
5.15.2. Features
Introduce a way to group builders by project. A new
projectslist is added to the configuration dictionary. Builders can be associated to the entries in that list by the newprojectargument.Grouping builders by project allows to significantly clean up the UI in larger Buildbot installations that contain hundreds or thousands of builders for a smaller number of unrelated codebases. This is currently implemented only in experimental React UI.
Added support specifying the project in
GitHubPullrequestPoller. Previously it was forced to be equal to GitHub’s repository full name.Reporter
BitbucketServerCoreAPIStatusPushnow supportsBuildRequestGeneratorand generates build status for build requests (by default).Buildbot now has
copy-dbscript migrate all data stored in the database from one database to another. This may be used to change database engine types. For example a sqlite database may be migrated to Postgres or MySQL when the load and data size grows.Added cron features like last day of month to
NightlyScheduler.Buildrequests can now have their priority changed, using the
/buildrequestsAPI.The force scheduler can now set a build request priority.
Added support for specifying builder descriptions in markdown which is later rendered to HTML for presentation in the web frontend.
Build requests are now sorted according to their buildrequest. Request time is now used as a secondary sort key.
Significantly improved performance of reporters or reporters with slower generators which is important on larger Buildbot installations.
Schedulers can now set a default priority for the buildrequests that it creates. It can either be an integer or a function.
Implement support for shallow submodule update using git.
GerritChangeSourcewill now log a small number of previous log lines coming fromsshprocess in case of connection failure.
5.15.3. Deprecations and Removals
Deprecated
projectNameandprojectURLconfiguration dictionary keys.
5.16. Buildbot 3.8.0 ( 2023-04-16 )
5.16.1. Bug fixes
Fixed compatibility issues with Python 3.11.
Fixed compatibility with Autobahn v22.4.1 and newer.
Fixed issue with overriding env when calling ShellMixin.makeRemoteShellCommand
Buildbot will now include the previous location of moved files when evaluating a Github commit. This fixes an issue where a commit that moves a file out of a folder, would not be shown in the web UI for a builder that is tracking that same folder.
Improved reliability of Buildbot log watching to follow log files even after rotation. This improves reliability of Buildbot start and restart scripts.
Fixed handling of occasional errors that happen when attempting to kill a master-side process that has already exited.
Fixed a race condition in PyLint step that may lead to step throwing exceptions.
Fixed compatibility with qemu 6.1 and newer when using LibVirtWorker with
cheap_copy=True(default).Fixed an issue with secrets provider stripping newline from ssh keys sent in git steps.
Fixed occasional errors that happen when killing processes on Windows. TASKKILL command may return code 255 when process has already exited.
Fixed deleting secrets from worker that contain ‘~’ in their destination path.
5.16.2. Changes
Buildbot now requires NodeJS 14.18 or newer to build the frontend.
The URLs emitted by the Buildbot APIs have been changed to include slash after the hash (
#) symbol to be compatible with what React web UI supports.
5.16.3. Improved Documentation
Replace statement “https is unsupported” with a more detailed disclaimer.
5.16.4. Features
Add a way to disable default
WarningCountingShellCommandparser.Added health check API that latent workers can use to specify that a particular worker will not connect and build should not wait for it and mark itself as failure immediately.
Implemented a way to customize TLS setting for
LdapUserInfo.
5.17. Buildbot 3.7.0 ( 2022-12-04 )
5.17.1. Bug fixes
Improved statistics capture to avoid negative build duration.
Improved reliability of “buildbot stop” (issue #3535).
Cancelled builds now have stop reason included into the state string.
Fixed
custom_classchange hook checks to allow hook without a plugin.Added treq response wrapper to fix issue with missing url attribute.
Fixed Buildbot Worker being unable to start on Python 2.7 due to issue in a new version of Automat dependency.
5.17.2. Features
- Expanded
ChangeFilterfiltering capabilities: New
<attribute>_not_eqparameters to require no match<attribute>_renow support multiple regexesNew
<attribute>_not_reparameters to require no match by regexNew
property_<match_type>parameters to perform filtering on change properties.
- Expanded
Exposed frontend configuration as implementation-defined JSON document that can be queried separately.
Added support for custom branch keys to
OldBuildCanceller. This is useful in Version Control Systems such as Gerrit that have multiple branch names for the same logical branch that should be tracked by the canceller.p4portargument of theP4step has been marked renderable.Added automatic generation of commands for Telegram bot without need to send them manually to BotFather.
5.17.3. Deprecations and Removals
This release includes an experimental web UI written using React framework. The existing web UI is written using AngularJS framework which is no longer maintained. The new web UI can be tested by installing
buildbot-www-reactpackage and'base_react': {}key-value to www plugins. Currently no web UI plugins are supported. The existing web UI will be deprecated on subsequent Buildbot released and eventually replaced with the React-based web UI on Buildbot 4.0.
5.18. Buildbot 3.6.1 ( 2022-09-22 )
5.18.1. Bug fixes
Fixed handling of last line in logs when Buildbot worker 3.5 and older connects to Buildbot master 3.6 (issue #6632).
Fixed worker
cpdircommand handling when using PB protocol (issue #6539)
5.19. Buildbot 3.6.0 ( 2022-08-25 )
5.19.1. Bug fixes
Fixed compatibility with Autobahn 22.4.x.
Fixed a circular import that causes errors in certain cases.
Fixed issue with
DockerLatentWorkeraccumulating connections with the docker server (issue #6538).Fixed documentation build for ReadTheDocs: Sphinx and Python have been updated to latest version.
Fixed build pending and canceled status reports to GitLab.
Fixed compatibility of hvac implementation with Vault 1.10.x (issue #6475).
Fixed a race condition in
PyLintstep that may lead to step throwing exceptions.Reporters now always wait for previous report to completing upload before sending another one. This works around a race condition in GitLab build reports ingestion pipeline (issue #6563).
Fixed “retry fetch” and “clobber on failure” git checkout options.
Improved Visual Studio installation path retrieval when using MSBuild and only ‘BuildTools’ are installed.
Fixed search for Visual Studio executables by inspecting both
C:\Program FilesandC:\Program Files (x86)directories.Fixed Visual Studio based steps causing an exception in
getResultSummarywhen being skipped.Fixed issue where workers would immediately retry login on authentication failure.
Fixed sending emails when using Twisted 21.2 or newer (issue #5943)
5.19.2. Features
Implemented support for App password authentication in
BitbucketStatusPushreporter.Cancelled build requests now generate build reports.
Implemented support for
--no-verifygit option to theGitCommitstep.HTTPClientServicenow accepts full URL in its methods. Previously only a relative URL was supported.Callback argument of class
LineBoundaryFinderis now optional and deprecated.Added
VS2019,VS2022,MsBuild15,MsBuild16,MsBuild17steps.Names of transfer related temporary files are now prefixed with
buildbot-transfer-.buildbot trynow accepts empty diffs and prints a warning instead of rejecting the diff.Implemented note event handling in GitLab www hook.
5.19.3. Deprecations and Removals
Removed support for Python 3.6 from master. Minimal python version for the master is now 3.7. The Python version requirements for the worker don’t change: 2.7 or 3.4 and newer.
buildbotpackage now requires Twisted versions >= 18.7.0
5.20. Buildbot 3.5.0 ( 2022-03-06 )
5.20.1. Bug fixes
Improved handling of “The container operating system does not match the host operating system” error on Docker on Windows to mark the build as erroneous so that it’s not retried.
Fixed rare
AlreadyCalledErrorexceptions in the logs when worker worker connection is lost at the same time it is delivering final outcome of a command.Fixed errors when accessing non-existing build via REST API when an endpoint matching rule with builder filter was present.
Fixed an error in
CMakepassing options and definitions on the cmake command line.Fixed an error when handling command management errors on the worker side (regression since v3.0.0).
Fixed updating build step summary with mock state changes for MockBuildSRPM and MockRebuild.
Fixed support for optional
builderparameter used in RebuildBuildEndpointMatcher (issue #6307).Fixed error that caused builds to become stuck in building state until next master restart if builds that were in the process of being interrupted lost connection to the worker.
Fixed Gerrit change sources to emit changes with proper branch name instead of one containing
refs/heads/as the prefix.Fixed handling of
build_wait_timeouton latent workers which previously could result in latent worker being shut down while a build is running in certain scenarios (issue #5988).Fixed problem on MySQL when using master names or builder tags that differ only by case.
Fixed timed schedulers not scheduling builds the first time they are enabled with
onlyIfChanged=Truewhen there are no important changes. In such case the state of the code is not known, so a build must be run to establish the baseline.Switched Bitbucket OAuth client from the deprecated ‘teams’ APIs to the new ‘workspaces’ APIs
Fixed errors when killing a process on a worker fails due to any reason (e.g. permission error or process being already exited) (issue #6140).
Fixed updates to page title in the web UI. Web UI now shows the configured buildbot title within the page title.
5.20.2. Improved Documentation
Fixed brackets in section 2.4.2.4 - How to populate secrets in a build (issue #6417).
5.20.3. Features
The use of Renderables when constructing payload For JSONStringDownload is now allowed.
Added
alwaysPullsupport when usingdockerfileparameter ofDockerLatentWorker.Base Debian image has been upgraded to Debian Bullseye for the Buildbot master.
Added rendering support to
docker_hostandhostconfigparameters ofDockerLatentWorker.MailNotifierreporter now sends HTML messages by default.MessageFormatterwill now use a default subject value if one is not specified.The default templates used in message formatters have been improved to supply more information. Separate default templates for html messages have been provided.
Added
buildbot_title,result_namesandis_buildsetkeys to the data passed toMessageFormatterinstances for message rendering.Added
targetsupport when usingdockerfileparameter ofDockerLatentWorker.Simplified
prioritizeBuildersdefault function to make an example easier to customize.Buildbot now exposes its internal framework for writing tests of custom build steps. Currently the API is experimental and subject to change.
Implemented detection of too long step and builder property names to produce errors at config time if possible.
5.20.4. Deprecations and Removals
Deprecated
subjectargument ofBuildStatusGeneratorandBuildSetStatusGeneratorstatus generators. Usesubjectargument of corresponding message formatters.
5.21. Buildbot 3.4.1 ( 2022-02-09 )
5.21.1. Bug fixes
Updated Bitbucket API URL for
BitbucketPullrequestPoller.Fixed a crash in
BitbucketPullrequestPoller(issue #4153)Fixed installation of master and worker as Windows service from wheel package (regression since 3.4.0) (issue #6294)
Fixed occasional exceptions when using Visual Studio steps (issue #5698).
Fixed rare “Did you maybe forget to yield the method” errors coming from the log subsystem.
5.22. Buildbot 3.4.0 ( 2021-10-15 )
5.22.1. Bug fixes
Database migrations are now handled using Alembic (1.6.0 or newer is required) (issue #5872).
AMI for latent worker is now set before making spot request to enable dynamically setting AMIs for instantiating workers.
Fixed
GitPollerfetch commands timing out on huge repositoriesFixed a bug that caused Gerrit review comments sometimes not to be reported.
Fixed a critical bug in the
MsBuild141step (regression since Buildbot v2.8.0) (issue #6262).Implemented renderable support in secrets list of
RemoveWorkerFileSecret.Fixed issues that prevented Buildbot from being used in Setuptools 58 and newer due to dependencies failing to build (issue #6222).
5.22.2. Improved Documentation
Fixed help text for
buildbot create-masterso it states that--dboption is passed verbatim tomaster.cfg.sampleinstead ofbuildbot.tac.Added documentation of properties available in the formatting context that is presented to message formatters.
5.22.3. Features
MsBuild steps now handle correctly rebuilding or cleaning a specific project. Previously it could only be done on the entire solution.
Implemented support for controlling
filteroption ofgit clone.Optimized build property filtering in the database instead of in Python code.
Implemented support of
SASL PLAINauthentication toIRCreporter.The
want_logs(previouslywantLogs) argument to message formatters will now implywantStepsif selected.Added information about log URLs to message formatter context.
Implemented a way to ask for only logs metadata (excluding content) in message formatters via
want_logsandwant_logs_contentarguments.Implemented support for specifying pre-processor defines sent to the compiler in the
MsBuildsteps.Introduced
HvacKvSecretProviderto allow working around flaws inHashiCorpVaultSecretProvider(issue #5903).Implemented support for proxying worker connection through a HTTP proxy.
5.22.4. Deprecations and Removals
The
wantLogsargument of message formatters has been deprecated. Please replace any uses with bothwant_logsandwant_logs_contentset to the same value.The
wantPropertiesandwantStepsarguments of message formatters have been renamed towant_propertiesandwant_stepsrespectively.Buildbot now requires SQLAlchemy 1.3.0 or newer.
5.23. Buildbot 3.3.0 ( 2021-07-31 )
5.23.1. Bug fixes
Fixed support of SQLAlchemy v1.4 (issue #5992).
Improved default build request collapsing functionality to take into account properties set by the scheduler and not collapse build requests if they differ (issue #4686).
Fixed a race condition that would result in attempts to complete unclaimed buildrequests (issue #3762).
Fixed a race condition in default buildrequest collapse function which resulted in two concurrently submitted build requests potentially being able to cancel each other (issue #4642).
The
comment-addedevent on Gerrit now produces the same branch as other events such aspatchset-created.GerritChangeSourceandGerritEventLogPollerwill now produce change events withbranchattribute that corresponds to the actual git branch on the repository.Fixed handling of
GitPollerstate to not grow without bounds and eventually exceed the database field size. (issue #6100)Old browser warning banner is no longer shown for browsers that could not be identified (issue #5237).
Fixed worker lock handling that caused max lock count to be ignored (issue #6132).
5.23.2. Features
Buildbot can now be configured (via
FailingBuildsetCanceller) to cancel unfinished builds when a build in a buildset fails.GitHubEventHandlercan now configure authentication token via Secrets management for GitHub instances that do not allow anonymous accessBuildbot can now be configured (via
OldBuildCanceller) to cancel unfinished builds when branches on which they are running receive new commits.Buildbot secret management can now be used to configure worker passwords.
Services can now be forced to reload their code via new
canReconfigWithSiblingAPI.
5.23.3. Deprecations and Removals
changes.base.PollingChangeSourcehas been fully deprecated as internal uses of it were migrated to replacement APIs.
5.24. Buildbot 3.2.0 ( 2021-06-17 )
5.24.1. Bug fixes
Fixed occasional
InvalidSpotInstanceRequestID.NotFounderrors when using spot instances on EC2. This could have lead to Buildbot launching zombie instances and not shutting them down.Improved
GitPollerbehavior during reconfiguration to exit at earliest possible opportunity and thus reduce the delay that runningGitPollerincurs for the reconfiguration.The docker container for the master now fully builds the www packages. Previously they were downloaded from pypi which resulted in downloading whatever version was newest at the time (issue #4998).
Implemented time out for master-side utility processes (e.g.
gitorhg) which could break the respective version control poller potentially indefinitely upon hanging.Fixed a regression in the
reconfigscript which would time out instead of printing error when configuration update was not successfully applied.Improved buildbot restart behavior to restore the worker paused state (issue #6074)
Fixed support for binary patch files in try client (issue #5933)
Improved handling of unsubscription errors in WAMP which will no longer crash the unsubscribing component and instead just log an error.
Fixed a crash when a worker is disconnected from a running build that uses worker information for some of its properties (issue #5745).
5.24.2. Improved Documentation
Added documentation about installation Buildbot worker as Windows service.
5.24.3. Features
DebPbuildernow supports the--othermirrorflag for including additional repositoriesImplemented support for setting docker container’s hostname
The libvirt latent worker will now wait for the VM to come online instead of disabling the worker during connection establishment process. The VM management connections are now pooled by URI.
Buildbot now sends metadata required to establish connection back to master to libvirt worker VMs.
LibVirtWorkerwill now setup libvirt metadata with details needed by the worker to connect back to master.The docker container for the master has been switched to Debian. Additionally, buildbot is installed into a virtualenv there to reduce chances of conflicts with Python packages installed via
dpkg.BitbucketStatusPush now has renderable build status key, name, and description.
Pausing a worker is a manual operation which the quarantine timer was overwriting. Worker paused state and quarantine state are now independent. (issue #5611)
Reduce buildbot_worker wheel package size by 40% by dropping tests from package.
5.24.4. Deprecations and Removals
The connection argument of the LibVirtWorker constructor has been deprecated along with the related Connection class. Use uri as replacement.
The
*NewStylebuild step aliases have been removed. Please use equivalent steps without theNewStylesuffix in the name.Try client no longer supports protocol used by Buildbot older than v0.9.
5.25. Buildbot 3.1.1 ( 2021-04-28 )
5.25.1. Bug fixes
Fix missing VERSION file in buildbot_worker wheel package (issue #5948, issue #4464).
Fixed error when attempting to specify
ws_ping_intervalconfiguration option (issue #5991).
5.26. Buildbot 3.1.0 ( 2021-04-05 )
5.26.1. Bug fixes
Fixed usage of invalid characters in temporary file names by git-related steps (issue #5949)
Fixed parsing of URLs of the form https://api.bitbucket.org/2.0/repositories/OWNER/REPONAME in BitbucketStatusPush. These URLs are in the sourcestamps returned by the Bitbucket Cloud hook.
Brought back the old (pre v2.9.0) behavior of the
FileDownloadstep to act more gracefully by returningFAILUREinstead of raising an exception when the file doesn’t exist on master. This makes use cases such asFileDownload(haltOnFailure=False)possible again.Fixed issue with
getNewestCompleteTimewhich was returning no completed builds, although it could.Fixed the
Gitsource step causing last active branch to point to wrong commits. This only affected the branch state in the local repository, the checked out code was correct.Improved cleanup of any containers left running by
OpenstackLatentWorker.Improved consistency of log messages produced by the reconfig script. Note that this output is not part of public API of Buildbot and may change at any time.
Improved error message when try client cannot create a build due to builder being not configured on master side.
Fixed exception when submitting builds via try jobdir client when the branch was not explicitly specified.
Fixed handling of secrets in nested folders by the vault provider.
5.26.2. Features
Implemented report generator for new build requests
Allow usage of Basic authentication to access GitHub API when looking for avatars
Added support for default Pylint message that was changed in v2.0.
Implemented support for configurable timeout in the reconfig script via new
progress_timeoutcommand-line parameter which determines how long it waits between subsequent progress updates in the logs before declaring a timeout.Implemented
GitDiffInfostep that would extract information about what code has been changed in a pull/merge request.Add support
--submoduleoption for therepo initcommand of the Repo source step.
5.26.3. Deprecations and Removals
MessageFormatterwill receive the actual builder name instead ofwhole buildsetwhen used fromBuildSetStatusGenerator.
5.27. Buildbot 3.0.3 ( 2021-04-05 )
5.27.1. Bug fixes
Fixed a race condition in log handling of
RpmLintandWarningCountingShellCommandsteps resulting in steps crashing occasionally.Fixed incorrect state string of a finished buildstep being sent via message queue (issue #5906).
Reduced flickering of build summary tooltip during mouseover of build numbers (issue #5930).
Fixed missing data in Owners and Worker columns in changes and workers pages (issue #5888, issue #5887).
Fixed excessive debug logging in
GerritEventLogPoller.Fixed regression in pending buildrequests UI where owner is not displayed anymore (issue #5940).
Re-added support for
lazylogfilesargument ofShellCommandthat was available in old style steps.
5.28. Buildbot 3.0.2 ( 2021-03-16 )
5.28.1. Bug fixes
Updated Buildbot requirements to specify sqlalchemy 1.4 and newer as not supported yet.
5.29. Buildbot 3.0.1 ( 2021-03-14 )
5.29.1. Bug fixes
Fixed special character handling in avatar email URLs.
Fixed errors when an email address matches GitHub commits but the user is unknown to it.
Added missing report generators to the Buildbot plugin database (issue #5892)
Fixed non-default mode support for
BuildSetStatusGenerator.
5.30. Buildbot 3.0.0 ( 2021-03-08 )
This release includes all changes up to Buildbot 2.10.2.
5.30.1. Bug fixes
Avatar caching is now working properly and size argument is now handled correctly.
Removed display of hidden steps in the build summary tooltip.
GitHubPullrequestPollernow supports secrets in itstokenargument (issue #4921)Plugin database will no longer issue warnings on load, but only when a particular entry is accessed.
SSH connections are now run with
-o BatchMode=yesto prevent interactive prompts which may tie up a step, reporter or change source until it times out.
5.30.2. Features
BitbucketPullrequestPoller,BitbucketCloudEventHandler,BitbucketServerEventHandlerwere enhanced to save PR entries matching provided masks as build properties.BitbucketPullrequestPollerhas been enhanced to optionally authorize Bitbucket API.Added pullrequesturl property to the following pollers and change hooks:
BitbucketPullrequestPoller,GitHubPullrequestPoller,GitHubEventHandler. This unifies all Bitbucket and GitHub pollers with the shared property interface.AvatarGitHub class has been enhanced to handle avatar based on email requests and take size argument into account
Added support for Fossil user objects for use by the buildbot-fossil plugin.
A new
www.ws_ping_intervalconfiguration option was added to avoid websocket timeouts when using reverse proxies and CDNs (issue #4078)
5.30.3. Deprecations and Removals
Removed deprecated
encodingargument toBitbucketPullrequestPoller.Removed deprecated support for constructing build steps from class and arguments in
BuildFactory.addStep().Removed support for deprecated
db_poll_intervalconfiguration setting.Removed support for deprecated
logHorizon,eventHorizonandbuildHorizonconfiguration settings.Removed support for deprecated
nextWorkerfunction signature that accepts two parameters instead of three.Removed deprecated
statusconfiguration setting.LoggingBuildStephas been removed.GET,PUT,POST,DELETE,HEAD,OPTIONSsteps now use new-style step implementation.MasterShellCommandstep now uses new-style step implementation.Configure,Compile,ShellCommand,SetPropertyFromCommand,WarningCountingShellCommand,Teststeps now use new-style step implementation.Removed support for old-style steps.
Python 3.5 is no longer supported for running Buildbot master.
The deprecated
HipChatStatusPushreporter has been removed.Removed support for the following deprecated parameters of
HttpStatusPushreporter:format_fn,builders,wantProperties,wantSteps,wantPreviousBuild,wantLogs,user,password.Removed support for the following deprecated parameters of
BitbucketStatusPushreporter:builders,wantProperties,wantSteps,wantPreviousBuild,wantLogs.Removed support for the following deprecated parameters of
BitbucketServerStatusPush,BitbucketServerCoreAPIStatusPush,GerritVerifyStatusPush,GitHubStatusPush,GitHubCommentPushandGitLabStatusPushreporters:startDescription,endDescription,builders,wantProperties,wantSteps,wantPreviousBuild,wantLogs.Removed support for the following deprecated parameters of
BitbucketServerPRCommentPush,MailNotifier,PushjetNotifierandPushoverNotifierreporters:subject,mode,builders,tags,schedulers,branches,buildSetSummary,messageFormatter,watchedWorkers,messageFormatterMissingWorker.Removed support for the following deprecated parameters of
MessageFormatterreport formatter:template_name.The deprecated
send()function that can be overridden by custom reporters has been removed.Removed deprecated support for
template_filename,template_dirandsubject_filenameconfiguration parameters of message formatters.The deprecated
buildbot.statusmodule has been removed.The deprecated
MTRstep has been removed. Contributors are welcome to step in, migrate this step to newer APIs and add a proper test suite to restore this step in Buildbot.Removed deprecated
buildbot.test.fake.httpclientservice.HttpClientService.getFakeService()function.Removed deprecated support for
block_device_mapargument of EC2LatentWorker being not a list.Removed support for deprecated builder categories which have been replaced by tags.
5.31. Buildbot 2.10.5 ( 2021-04-05 )
5.31.1. Bug fixes
Fixed a race condition in log handling of
RpmLintandWarningCountingShellCommandsteps resulting in steps crashing occasionally.Fixed incorrect state string of a finished buildstep being sent via message queue (issue #5906).
Reduced flickering of build summary tooltip during mouseover of build numbers (issue #5930).
Fixed missing data in Owners and Worker columns in changes and workers pages (issue #5888, issue #5887).
Fixed excessive debug logging in
GerritEventLogPoller.Fixed regression in pending buildrequests UI where owner is not displayed anymore (issue #5940).
Re-added support for
lazylogfilesargument ofShellCommandthat was available in old style steps.
5.32. Buildbot 2.10.4 ( 2021-03-16 )
5.32.1. Bug fixes
Updated Buildbot requirements to specify sqlalchemy 1.4 and newer as not supported yet.
5.33. Buildbot 2.10.3 ( 2021-03-14 )
5.33.1. Bug fixes
Fixed special character handling in avatar email URLs.
Added missing report generators to the Buildbot plugin database (issue #5892)
Fixed non-default mode support in
BuildSetStatusGenerator.
5.34. Buildbot 2.10.2 ( 2021-03-07 )
5.34.1. Bug fixes
Optimized builder reconfiguration when configuration does not change. This leads to up to 6 times faster reconfiguration in Buildbot instances with many builders.
Fixed build steps continuing running commands even if when they have been cancelled.
Worked around failure to build recent enough cryptography module in the docker image due to too old rust being available.
Fixed a regression in
GitHubEventHandlerin that it would require a GitHub token for public repositories (issue #5760).Fixed a regression in
GerritChangeSourcesince v2.6.0 that caused only the first event related to a Gerrit change to be reporter as a change to Buildbot (issue #5596). Now such deduplication will be applied only topatchset-createdandref-updatedevents.Reconfiguration reliability has been improved by not reconfiguring WAMP router if settings have not changed.
Fixed unauthorized login errors when latent worker with automatic password is reconfigured during substantiation.
Don’t deactivate master as seen by the data API before builds are stopped.
Fixed a race condition that may result in a crash when build request distributor stops when its activity loop is running.
Fixed a crash when a manual step interruption is happening during master shutdown which tries to stop builds itself.
Fixed a race condition that may result in a deadlock if master is stopped at the same time a build is started.
Improved
buildbot.util.poll.methodto react faster to a request to stop. New pending calls are no longer executed. Calls whose interval but not random delay has already expired are no longer executed.Fixed a crash when a trigger step is used in a build with patch body data passed via the try scheduler (issue #5165).
Fixed secret replacement for an empty string or whitespace which may have many matches and generally will not need to be redacted.
Fixed exceptions when using LdapUserInfo as avatar provider
Fixed exceptions when LDAP filter string contains characters that needs to be escaped.
5.35. Buildbot 2.10.1 ( 2021-01-29 )
5.35.1. Bug fixes
Fixed reference to
tuplematchin theReporterBaseclass (issue #5764).For build summary tooltip, truncate very long step names or build status strings, enable auto positioning of tooltip, and improve text alignment. Also, add build summary tooltip to masters page and builds tables.
Fixed crash when using renderable locks with latent workers that may have incompatible builds (issue #5757).
Improved REST API to use username or full name of a logged in user when email is empty.
Worked around a bug in Python’s urllib which caused Python clients not to accept basic authentication headers (issue #5743)
Fixed crash in
BuildStartEndStatusGeneratorwhen tags filter is setup (issue #5766).Added missing
MessageFormatterEmpty,MessageFormatterFunction,MessageFormatterMissingWorker, andMessageFormatterRenderabletobuildbot.reportersnamespace
5.35.2. Improved Documentation
Fix services config for IRC in tour.
5.35.3. Deprecations and Removals
Added deprecation messages to the following members of
buildbot.process.buildstepmodule that have been deprecated in Buildbot 0.8.9:RemoteCommandLoggedRemoteCommandRemoteShellCommandLogObserverLogLineObserverOutputProgressObserver
5.36. Buildbot 2.10.0 ( 2021-01-02 )
5.36.1. Highlights
This is the last release in 2.x series. Only 2.10.y bugfix releases will follow. Upgrading existing Buildbot instances to 3.x will require an upgrade to 2.10.y first and resolving all deprecation warnings. Please see the documentation on upgrading to 3.0 for more information.
Please submit bug reports for any issues found in new functionality that replaces deprecated functionality to be removed in Buildbot 3.0. These bugs will be fixed with extra priority in 2.10.y bugfix releases.
5.36.2. Bug fixes
Fixed a bug that caused builds running on latent workers to become unstoppable when an attempt was made to stop them while the latent worker was being substantiated (issue #5136).
Fixed a bug that caused the buildmaster to be unable to restart if a latent worker was previously reconfigured during its substantiation.
Fixed handling of very long lines in the logs during Buildbot startup (issue #5706).
Fixed a bug which prevented polling change sources derived from
ReconfigurablePollingChangeSourcefrom working correctly with /change_hook/poller (issue #5727)
5.36.3. Improved Documentation
Corrected the formatting for the code sample in the Docker Tutorial’s Multi-master section.
Improved the readability of the documentation by conserving horizontal space.
Improved the introduction and concepts parts of the documentation.
5.36.4. Features
Added build summary tooltip for build bubbles in grid and console views (issue #4733).
Added support for custom HTTP headers to
HttpStatusPushreporter (issue #5398).Implemented
MessageFormatterFunctionthat creates build report text or json by processing full build dictionary.Implemented
MessageFormatterRenderablethat creates build report text by rendering build properties onto a renderable.Implemented
BuildStartEndStatusGeneratorwhich ensures that a report is generated for either both build start and end events or neither of them.The
BitbucketServerCoreAPIStatusPush,BitbucketServerStatusPush,BitbucketStatusPush,GerritVerifyStatusPush,GitHubStatusPush,GitHubCommentPush,GitLabStatusPushandHttpStatusPushreporters now support report generators via thegeneratorsargument.Implemented support for remote submodules when cloning a Git repository.
5.36.5. Deprecations and Removals
The following arguments of
BitbucketServerCoreAPIStatusPush,BitbucketServerStatusPush,GerritVerifyStatusPush,GitHubStatusPush,GitHubCommentPushandGitLabStatusPushreporters have been deprecated in favor of the list of report generators provided via thegeneratorsargument:startDescription,endDescription,builders.The following arguments of
BitbucketStatusPushreporter have been deprecated in favor of the list of report generators provided via thegeneratorsargument:builders.The following arguments of
HttpStatusPushreporter have been deprecated in favor of the list of report generators provided via thegeneratorsargument:format_fn,builders,wantProperties,wantSteps,wantPreviousBuild,wantLogs.HipChatStatusPushhas been deprecated because the public version of hipchat has been shut down. This reporter will be removed in Buildbot 3.0 unless there is someone who will upgrade the reporter to the new internal APIs present in Buildbot 3.0.Support for passing paths to template files for rendering in message formatters has been deprecated.
Buildbot now requires at least the version 0.13 of sqlalchemy-migrate (issue #5669).
The
logfileargument ofShellArghas been deprecated (issue #3771).
5.37. Buildbot 2.9.4 ( 2020-12-26 )
5.37.1. Bug fixes
Fixed spam messages to stdout when renderable operators were being used.
Fixed handling of very long lines in the logs during Buildbot startup (issue #5706).
Fixed logging of error message to
twistd.login case of old git andprogressoption being enabled.
5.37.2. Deprecations and Removals
Removed setup of unused
webstatusfeature of autobahn.
5.38. Buildbot 2.9.3 ( 2020-12-15 )
5.38.1. Bug fixes
Fixed extraneous warnings due to deprecation of
buildbot.statusmodule even when it’s not used (issue #5693).The topbar zoom buttons are now cleared when leaving waterfall view.
The waterfall is now re-rendered upon change to masters.
5.39. Buildbot 2.9.2 ( 2020-12-08 )
5.39.1. Bug fixes
Fixed the profile menu wrapping because the avatar shows more often and hiding the profile name was not kept in sync.
Reverted too early deprecation of the
format_fn,builders,wantProperties,wantSteps,wantPreviousBuild,wantLogsarguments ofHttpStatusPush.Reverted accidental too early migration of
MasterShellCommandand HTTP steps to new style (issue #5674).
5.40. Buildbot 2.9.1 ( 2020-12-05 )
5.40.1. Bug fixes
Fixed
checkConfigfailures inGitHubStatusPushandGitLabStatusPush(issue #5664).Fixed incorrect deprecation notice for the
buildersargument ofGitLabStatusPush.
5.41. Buildbot 2.9.0 ( 2020-12-04 )
5.41.1. Bug fixes
Fixed a bug preventing the
timeout=Noneparameter of CopyDirectory step from having effect (issue #3032).Fixed a bug in
GitHubStatusPushthat would cause silent failures for builders that specified multiple codebases.Fixed display refresh of breadcrumb and topbar contextual action buttons (issue #5549)
Throwing an exception out of a log observer while processing logs will now correctly fail the step in the case of new style steps.
Fixed an issue where
git fetchwould break on tag changes by adding the-foption. This could previously be handled by manually specifyingclobberOnFailure, but as that is rather heavy handed and off by default, this new default functionality will keep Buildbot in sync with the repository it is fetching from.Fixed
GitHubStatusPushlogging an error when triggered by the NightlySchedulerFixed GitHub webhook event handler when no token has been set
Fixed
HashiCorpVaultSecretProviderreading secrets attributes, when they are not namedvalueFixed
HgPollermisuse ofhg heads -r <branch>tohg heads <branch>because-roption shows heads that may not be on the wanted branch.Fixed inconsistent REST api, buildid vs build_number, issue #3427
Fixed permission denied in
rmtree()usage inPrivateTemporaryDirectoryon WindowsFixed AssertionError when calling try client with
--dryrunoption (issue #5618).Fixed issue with known hosts not working when using git with a version less than 2.3.0
ForceSchedulernow gets Responsible Users from owner property (issue #3476)Added support for
refs/pull/###/headref for fetching the issue ID in the GitHub reporter instead of always expectingrefs/pull/###/merge.Fixed Github v4 API URL
Fixed
show_old_buildersto have expected effects in the waterfall view.Latent workers no longer reuse the started worker when it’s incompatible with the requested build.
Fixed handling of submission of non-decoded
byteslogs in new style steps.Removed usage of distutils.LooseVersion is favor of packaging.version
Updated
OpenstackLatentWorkerto use checkConfig/reconfigService structure.Fixed
OpenstackLatentWorkerto use correct method when listing images. UpdatedOpenstackLatentWorkerto support renderableflavor,nova_argsandmeta.Fixed support of renderables for p4base` and
p4brancharguments of the P4 step.Buildbot now uses pypugjs library instead of pyjade to render pug templates.
Step summary is now updated after the last point where the step status is changed. Previously exceptions in log finish methods would be ignored.
Transfer steps now return
CANCELLEDinstead ofSUCCESSwhen interrupted.Fixed bytes-related master crash when calling buildbot try (issue #4488)
The waterfall modal is now closed upon clicking build summary link
The worker will now report low level cause of errors during the command startup.
5.41.2. Improved Documentation
Added documentation of how to log to stdout instead of twistd.log.
Added documentation of how to use pdb in a buildbot application.
Fixed import path for plugins
Added documentation about vault secrets handling.
5.41.3. Features
Added UpCloud latent worker
UpCloudLatentWorkerThe init flag is now allowed to be set to false in the host config for
DockerLatentWorkerAdded ability for the browser to auto-complete force dialog form fields.
AvatarGitHub class has been implemented, which lets us display the user’s GitHub avatar.
New reporter has been implemented
BitbucketServerCoreAPIStatusPush. Reporting build status has been integrated into BitbucketServer Core REST API in Bitbucket Server 7.4. Old BitbucketServer Build REST API is still working, but does not provide the new and improved functionality.A per-build key-value store and related APIs have been created for transient and potentially large per-build data.
Buildbot worker docker image has been upgraded to
python3.Added the ability to copy build properties to the clipboard.
The
urlTextparameter to theDirectoryUploadstep is now renderable.Added the option to hide sensitive HTTP header values from the log in
HTTPStep.It is now possible to set
urlTexton a url linked to aMultipleFileUploadstep.Use
os_auth_argsto pass in authentication forOpenstackLatentWorker.DebPbuilder,DebCowbuilder,UbuPbuilderandUbuCowbuildernow support renderables for the step parameters.A new report generator API has been implemented to abstract generation of various reports that are then sent via the reporters. The
BitbucketServerPRCommentPush,MailNotifier,PushjetNotifierandPushoverNotifiersupport this new API via their newgeneratorsparameter.Added rules for Bitbucket to default revlink helpers.
Added counts of the statuses of the triggered builds to the summary of trigger steps
The worker preparation step now shows the worker name.
5.41.4. Deprecations and Removals
buildbot.test.fake.httpclientservice.HttpClientService.getFakeService()has been deprecated. UsegetServicemethod of the same class.The
MTRstep has been deprecated due to migration to new style steps and the build result APIs. The lack of proper unit tests made it too time-consuming to migrate this step along with other steps. Contributors are welcome to step in, migrate this step and add a proper test suite so that this situation never happens again.Many steps have been migrated to new style from old style.
This only affects users who use steps as base classes for their own steps. New style steps provide a completely different set of functions that may be overridden. Direct instantiation of step classes is not affected. Old and new style steps work exactly the same in that case and users don’t need to do anything.
The old-style steps have been deprecated since Buildbot v0.9.0 released in October 2016. The support for old-style steps will be removed entirely Buildbot v3.0.0 which will be released in near future. Users are advised to upgrade their custom steps to new-style steps as soon as possible.
A gradual migration path is provided for steps that are likely to be used as base classes. Users need to inherit from
<StepName>NewStyleclass and convert all overridden APIs to use new-style step APIs. The old-style<StepName>classes will be provided until Buildbot v3.0.0 release. In Buildbot v3.0.0<StepName>will refer to new-style steps and will be equivalent to<StepName>NewStyle.<StepName>NewStylealiases will be removed in Buildbot v3.2.0.The list of old-style steps that have new-style equivalents for gradual migration is as follows:
Configure(new-style equivalent isConfigureNewStyle)Compile(new-style equivalent isCompileNewStyle)HTTPStep(new-style equivalent isHTTPStepNewStyle)GET,PUT,POST,DELETE,HEAD,OPTIONS(new-style equivalent isGETNewStyle,PUTNewStyle,POSTNewStyle,DELETENewStyle,HEADNewStyle,OPTIONSNewStyle)MasterShellCommand(new-style equivalent isMasterShellCommandNewStyle)ShellCommand(new-style equivalent isShellCommandNewStyle)SetPropertyFromCommand(new-style equivalent isSetPropertyFromCommandNewStyle)WarningCountingShellCommand(new-style equivalent isWarningCountingShellCommandNewStyle)Test(new-style equivalent isTestNewStyle)
The list of old-style steps that have been converted to new style without a gradual migration path is as follows:
BuildEPYDocCopyDirectoryDebLintianDebPbuilderDirectoryUploadFileDownloadFileExistsFileUploadHLintJsonPropertiesDownloadJsonStringDownloadLogRenderableMakeDirectoryMaxQMockMockBuildSRPMMsBuild,MsBuild4,MsBuild12,MsBuild14,MsBuild141MultipleFileUploadPerlModuleTestPyFlakesPyLintRemoveDirectoryRemovePYCsRpmLintRpmBuildSetPropertiesFromEnvSphinxStringDownloadTreeSizeTrialVC6,VC7,VC8,VC9,VC10,VC11,VC12,VC14,VC141VS2003,VS2005,VS2008,VS2010`, ``VS2012,VS2013,VS2015,VS2017
Additionally, all source steps have been migrated to new style without a gradual migration path. Ability to be used as base classes was not documented and thus is considered unsupported. Please submit any custom steps to Buildbot for inclusion into the main tree to reduce maintenance burden. Additionally, bugs can be submitted to expose needed APIs publicly for which a migration path will be provided in the future.
The list of old-style source steps that have been converted to new style is as follows:
BzrCVSDarcsGerritGitGitCommitGitLabGitPushGitTagMonotoneMercurialP4RepoSourceSVN
The undocumented and broken RpmSpec step has been removed.
The usage of certain parameters have been deprecated in
BitbucketServerPRCommentPush,MailNotifier,PushjetNotifierandPushoverNotifierreporters. They have been replaced by thegeneratorsparameter. The support for the deprecated parameters will be removed in Buildbot v3.0. The list of deprecated parameters is as follows:modetagsbuildersbuildSetSummarymessageFormattersubjectaddLogsaddPatchschedulersbrancheswatchedWorkersmessageFormatterMissingWorker
The undocumented
NotifierBaseclass has been renamed toReporterBase.The undocumented
HttpStatusPushBaseclass has been deprecated. Please useReporterBasedirectly.The
sendmethod of the reporters based onHttpStatusPushBasehas been deprecated. This affects only users who implemented custom reporters that directly or indirectly deriveHttpStatusPushBase. Please usesendMessageas the replacement. The following reporters have been affected:HttpStatusPushBitbucketStatusPushBitbucketServerStatusPushBitbucketServerCoreAPIStatusPushGerritVerifyStatusPushGitHubStatusPushGitLabStatusPushHipChatStatusPushZulipStatusPush
BuildBot now requires SQLAlchemy 1.2.0 or newer.
Deprecation warnings have been added to the
buildbot.statusmodule. It has been deprecated in documentation since v0.9.0.buildbot.interfaces.WorkerTooOldErroris deprecated in favour ofbuildbot.interfaces.WorkerSetupErrorThe
worker_transitionmodule has been removed.The buildbot worker Docker image has been updated to Ubuntu 20.04.
5.42. Buildbot 2.8.4 ( 2020-08-29 )
5.42.1. Bug fixes
Fix 100% CPU on large installations when using the changes API (issue #5504)
Work around incomplete support for codebases in
GerritChangeSource(issue #5190). This avoids an internal assertion when the configuration file does not specify any codebases.Add missing VS2017 entry points.
5.43. Buildbot 2.8.3 ( 2020-08-22 )
5.43.1. Bug fixes
Fix Docker image building for the master which failed due to mismatching versions of Alpine (issue #5469).
5.44. Buildbot 2.8.2 ( 2020-06-14 )
5.44.1. Bug fixes
Fix crash in Buildbot Windows service startup code (issue #5344)
5.45. Buildbot 2.8.1 ( 2020-06-06 )
5.45.1. Bug fixes
Fix source distribution missing required buildbot.test.fakedb module for unit tests.
Fix crash in trigger step when renderables are used for scheduler names (issue #5312)
5.46. Buildbot 2.8.0 ( 2020-05-27 )
5.46.1. Bug fixes
Fix
GitHubEventHandlerto include files in Change that comes from a github PR (issue #5294)Updated the Docker container buildbot-master to Alpine 3.11 to fix segmentation faults caused by an old version of musl
Base64 encoding logs and attachments sent via email so emails conform to RFC 5322 2.1.1
Handling the case where the BitbucketStatusPush return code is not 200
When cancelling a buildrequest, the reason field is now correctly transmitted all the way to the cancelled step.
Fix Cache-control header to be compliant with RFC 7234 (issue #5220)
Fix
GerritEventLogPollerclass to be declared as entry_point (can be used in master.cfg file)Git poller: add –ignore-missing argument to git log call to avoid fatal: bad object errors
Log watcher looks for the “tail” utility in the right location on Haiku OS.
Add limit and filtering support for the changes data API as described in issue #5207
5.46.2. Improved Documentation
Make docs build with the latest sphinx and improve rendering of the example HTML file for custom dashboard
Make docs build with Sphinx 3 and fix some typos and incorrect Python module declarations
5.46.3. Features
PropertyandInterpolateobjects can now be compared. This will generate a renderable that will be evaluated at runtime. see Renderable Comparison.Added argument count to lock access to allow a lock to consume a variable amount of units
Added arguments pollRandomDelayMin and pollRandomDelayMax to HgPoller, GitPoller, P4Poller, SvnPoller to spread the polling load
5.46.4. Deprecations and Removals
Removed _skipChecks from LockAccess as it’s obsolete
5.47. Buildbot 2.7.0 ( 2020-02-27 )
5.47.1. Bug fixes
Command buildbot-worker create-worker now supports ipv6 address for buildmaster connection.
Fix crash in latent worker stopService() when the worker is insubstantiating (issue #4935).
Fix race condition between latent worker’s stopService() and substantiate().
GitHubAuthis now using Authorization headers instead of access_token query parameter, as the latter was deprecated by Github. (issue #5188)jQueryand$are available again as a global variable for UI plugins (issue #5161).Latent workers will no longer wait for builds to finish when worker is reconfigured. The builds will still be retried on other workers and the operators will not need to potentially wait multiple hours for builds to finish.
p4poller will no longer override Perforce login ticket handling behavior which fixes random crashes (issue #5042).
5.47.2. Improved Documentation
The procedures of upgrading to Buildbot 1.x and 2.x have been clarified in separate documents.
The layout of the specification of the REST API has been improved.
Updated newsfragments README.txt to no longer refer to renamed class
HttpStatusBaseThe documentation now uses the read-the-docs theme which is more readable.
5.47.3. Features
A new www badges style was added:
badgeioHttpStatusPushBasenow allows you to skip unicode to bytes encoding while pushing data to serverNew
buildbot-worker create-worker --delete-leftover-dirsoption to automatically remove obsolete builder directories
5.48. Buildbot 2.6.0 ( 2020-01-21 )
5.48.1. Bug fixes
Fix a potential deadlock when interrupting a step that is waiting for a lock to become available.
Prepare unique hgpoller name when using multiple hgpoller for multiple branches (issue #5004)
Fix hgpoller crash when force pushing a branch (issue #4876)
Fix mail recipient formatting to make sure address comments are separately escaped instead of escaping the whole To: or CC: header, which is not RFC compliant.
Master side keep-alive requests are now repeated instead of being single-shot (issue #3630).
The message queues will now wait until the delivered callbacks are fully completed during shutdown.
Fix encoding errors during P4Poller ticket parsing issue #5148.
Remove server header from HTTP response served by the web component.
Fix multiple race conditions in Telegram reporter that were visible in tests.
The Telegram reporter will now wait until in-progress polls finish during shutdown.
Improve reliability of timed scheduler.
transfer steps now correctly report errors from workers issue #5058
Warn if Buildbot title in the configuration is too long and will be ignored.
Worker will now wait for any pending keep-alive requests to finish leaving them in indeterminate state during shutdown.
5.48.2. Improved Documentation
Mention that QueueRef.stopConsuming() may return a Deferred.
5.48.3. Features
Add the parameter –use-tls to buildbot-worker create-worker to automatically enable TLS in the connection string
Gerrit reporter now passes a tag for versions that support it. This enables filtering out buildbot’s messages.
GerritEventLogPollerandGerritChangeSourcecoordinate so as not to generate duplicate changes, resolves issue #4786Web front end now allows you to configure the default landing page with c[‘www’][‘default_page’] = ‘name-of-page’.
The new option dumpMailsToLog of MailNotifier allows to dump formatted mails to the log before sending.
bb:cfg:workers will now attempt to read
/etc/os-releaseand stores them into worker info asos_<field>items. Add new interpolationworkerthat can be used for accessing worker info items.
5.49. Buildbot 2.5.1 ( 2019-11-24 )
5.49.1. Bug fixes
Updates supported browser list so that Ubuntu Chromium will not always be flagged as out of date.
Fixed IRC notification color of cancelled builds.
Updated url in description of worker service for Windows (no functionality impact).
Updated templates of www-badges to support additional padding configuration (issue #5079)
Fix issue with custom_templates loading path (issue #5035)
Fix url display when step do not contain any logs (issue #5047)
5.50. Buildbot 2.5.0 ( 2019-10-17 )
5.50.1. Bug fixes
Fix crash when reconfiguring changed workers that have new builders assigned to them (issue #4757, issue #5027).
DockerLatentWorker: Allow to bind the same volume twice into a worker’s container, Buildbot now requires ‘docker-py’ (nowadays ‘docker’) version 1.2.3+ from 2015.
IRC bot can have authz configured to create or stop builds (issue #2957).
Fix javascript exception with grid view tag filtering (issue #4801)
5.50.2. Improved Documentation
Changed PluginList link from trac wiki directly to the GitHub wiki.
5.50.3. Features
Created a TelegramBot for notification and control through Telegram messaging app.
Added support for environment variable P4CONFIG to class
P4SourceAllow to define behavior for GitCommit when there is nothing to commit.
Add support for revision links to Mercurial poller
Support recursive matching (‘**’) in MultipleFileUpload when glob=True (requires python3.5+ on the worker)
5.51. Buildbot 2.4.1 ( 2019-09-11 )
5.51.1. Bug fixes
allow committer of a change to be null for new setups (issue #4987)
custom_templates are now working again.
Locks will no longer allow being acquired more times than the maxCount parameter if this parameter is changed during master reconfiguration.
5.51.2. Features
Improve log cleaning performance by using delete with join on supported databases.
Hiding/showing of inactive builders is now possible in Waterfall view.
5.52. Buildbot 2.4.0 ( 2019-08-18 )
5.52.1. Highlights
Database upgrade may take a while on larger instances on this release due to newly added index.
5.52.2. Bug fixes
Add an index to
steps.started_atto boost expensive SQL queries.Fix handling of the
refs_changedevent in the BitBucket Server web hook.Fix errors when disconnecting a libvirt worker (issue #4844).
Fix Bitbucket Cloud hook crash due to changes in their API (issue #4873).
Fix
GerritEventLogPollerwas using the wrong date format.Fix janitor Exception when there is no logchunk to delete.
Reduced the number of SQL queries triggered by
getPrevSuccessfulBuild()by up to 100.GitStepMixin: Prevent builders from corrupting temporary ssh data path by using builder name as part of the pathGitTag: AllowtagNameto be a renderable.Fix Github error reporting to handle exceptions that happen before the HTTP request is sent.
GitPoller: Trigger on pushes with no commits when the new revision is not the tip of another branch.Git: Fix the invocation ofgit submodule foreachon cleaning.Fix StatsService not correctly clearing old consumers on reconfig.
Fix various errors in try client with Python 3 (issue #4765).
Prevent accidental start of multiple force builds in web UI (issue #4823).
The support for proxying Buildbot frontend to another Buildbot instance during development has been fixed. This feature has been broken since v2.3.0, and is now completely re-implemented for best performance, ease of use and maintainability.
5.52.3. Improved Documentation
Document why some listed icons may not work out-of-the-box when building a custom dashboard (issue #4939).
Improve Vault secrets management documentation and examples.
Link the documentation of
www.portto the capabilities oftwisted.application.strports.Move the documentation on how to submit PRs out of the trac wiki to the documentation shipped with Buildbot, update and enhance it.
5.52.4. Features
Update buildbot worker image to Ubuntu 18.04 (issue #4928).
DockerLatentWorker: Added support for docker build contexts,buildargs, and specifying controlling context.The
GerritChangeFilterandGerritEventLogPollernow populate thefilesattribute of emitted changes when theget_filesargument is true. Enabling this feature triggers an additional HTTP request or SSH command to the Gerrit server for every emitted change.Buildbot now warns users who connect using unsupported browsers.
Boost janitor speed by using more efficient SQL queries.
Scheduler properties are now renderable.
Sphinx: Addedstrict_warningsoption to fail on warnings.UI now shows a paginated view for trigger step sub builds.
5.52.5. Deprecations and Removals
Support for older browsers that were not working since 2.3.0 has been removed due to technical limitations. Notably, Internet Explorer 11 is no longer supported. Currently supported browsers are Chrome 56, Firefox 52, Edge 13 and Safari 10, newer versions of these browsers and their compatible derivatives. This set of browsers covers 98% of users of buildbot.net.
5.53. Buildbot 2.3.1 ( 2019-05-22 )
5.53.1. Bug fixes
Fix vulnerability in OAuth where user-submitted authorization token was used for authentication (https://github.com/buildbot/buildbot/wiki/OAuth-vulnerability-in-using-submitted-authorization-token-for-authentication) Thanks to Phillip Kuhrt for reporting it.
5.54. Buildbot 2.3.0 ( 2019-05-06 )
5.54.1. Highlights
Support for older browsers has been hopefully temporarily broken due to frontend changes in progress. Notably, Internet Explorer 11 is not supported in this release. Currently supported browsers are Chrome 56, Firefox 52, Edge 13 and Safari 10, newer versions of these browsers and their compatible derivatives. This set of browsers covers 98% of users of buildbot.net.
5.54.2. Bug fixes
Fixed
Gitto clean the repository after the checkout when submodules are enabled. Previously this action could lead to untracked module directories after changing branches.Latent workers with negative build_wait_timeout will be shutdown on master shutdown.
Latent worker will now wait until start_instance() before starting stop_instance() or vice-versa. Master will wait for these functions to finish during shutdown.
Latent worker will now correctly handle synchronous exception from the backend worker driver.
Fixed a potential error during database migration when upgrading to versions >=2.0 (issue #4711).
5.54.3. Deprecations and Removals
The implementation language of the Buildbot web frontend has been changed from CoffeeScript to JavaScript. The documentation has not been updated yet, as we plan to transition to TypeScript. In the transitory period support for some browsers, notably IE 11 has been dropped. We hope to bring support for older browsers back once the transitory period is over.
The support for building Buildbot using npm as package manager has been removed. Please use yarn as a replacement that is used by Buildbot developers.
5.55. Buildbot 2.2.0 ( 2019-04-07 )
5.55.1. Bug fixes
Fix passing the verify and debug parameters for the HttpStatusPush reporter
The builder page UI now correctly shows the list of owners for each build.
Fixed bug with tilde in git repo url on Python 3.7 (issue #4639).
Fix secret leak when non-interpolated secret was passed to a step (issue #4007)
5.55.2. Features
Added new
GitCommitstep to perform git commit operationAdded new
GitTagstep to perform git tag operationHgPoller now supports bookmarks in addition to branches.
Buildbot can now monitor multiple branches in a Mercurial repository.
OAuth2Authhave been adapted to support ref:Secret.Buildbot can now get secrets from the unix password store by zx2c4 (https://www.passwordstore.org/).
Added a
basenameproperty to the Github pull request webhook handler.The GitHub change hook secret can now be rendered.
Each build now gets a preparation step which counts the time spend starting latent worker.
Support known_hosts file format as
sshKnownHostsparameter in SSH-related operations (issue #4681)
5.56. Buildbot 2.1.0 ( 2019-03-09 )
5.56.1. Highlights
Worker to Master protocol can now be encrypted via TLS.
5.56.2. Bug fixes
To avoid database corruption, the
upgrade-mastercommand now ignores all signals exceptSIGKILL. It cannot be interrupted withctrl-c(issue #4600).Fixed incorrect tracking of latent worker states that could sometimes result in duplicate
stop_instancecalls and so on.Fixed a race condition that could manifest in cancelled substantiations if builds were created during insubstantiation of a latent worker.
Perforce CLI Rev. 2018.2/1751184 (2019/01/21) is now supported (issue #4574).
Fix encoding issues with Forcescheduler parameters error management code.
5.56.3. Improved Documentation
fix grammar mistakes and use Uppercase B for Buildbot
5.56.4. Features
Workernow have connection_string kw-argument which can be used to connect to a master over TLS.Adding ‘expand_logs’ option for LogPreview related settings.
Force schedulers buttons are now sorted by their name. (issue #4619)
workersnow have a newdefaultPropertiesparameter.
5.57. Buildbot 2.0.1 ( 2019-02-06 )
5.57.1. Bug fixes
Do not build universal python wheels now that Python 2 is not supported.
Print a warning discouraging users from stopping the database migration.
5.58. Buildbot 2.0.0 ( 2019-02-02 )
5.58.1. Deprecations and Removals
Removed support for Python <3.5 in the buildbot master code. Buildbot worker remains compatible with python2.7, and interoperability tests are run continuously.
APIs that are not documented in the official Buildbot documentation have been made private. Users of these undocumented APIs are encouraged to file bugs to get them exposed.
Removed support of old slave APIs from pre-0.9 days. Using old APIs may fail silently. To avoid weird errors when upgrading a Buildbot installation that may use old APIs, first upgrade to 1.8.0 and make sure there are no deprecated API warnings.
Remove deprecated default value handling of the
keypair_nameandsecurity_nameattributes ofEC2LatentWorker.Support for
Hyper.shcontainers cloud provider has been removed as this service has shutdown.
5.58.2. Bug fixes
Fix CRLF injection vulnerability with validating user provided redirect parameters (https://github.com/buildbot/buildbot/wiki/CRLF-injection-in-Buildbot-login-and-logout-redirect-code) Thanks to
mik317andmariadbfor reporting it.Fix lockup during master shutdown when there’s a build with unanswered ping from the worker and the TCP connection to worker is severed (issue:4575).
Fix RemoteUserAuth.maybeAutLogin consumes bytes object as str leading to TypeError during JSON serialization. (issue #4402)
Various database integrity problems were fixed. Most notably, it is now possible to delete old changes without wiping all “child” changes in cascade (issue #4539, pull request 4536).
The GitLab change hook secret is now rendered correctly. (issue #4118).
5.58.3. Features
Identifiers can now contain UTF-8 characters which are not ASCII. This includes worker names, builder names, and step names.
5.59. Release Notes for Buildbot 1.8.2 ( 2019-05-22 )
5.59.1. Bug fixes
Fix vulnerability in OAuth where user-submitted authorization token was used for authentication (https://github.com/buildbot/buildbot/wiki/OAuth-vulnerability-in-using-submitted-authorization-token-for-authentication) Thanks to Phillip Kuhrt for reporting it.
5.60. Release Notes for Buildbot 1.8.1 ( 2019-02-02 )
5.60.1. Bug fixes
Fix CRLF injection vulnerability with validating user provided redirect parameters (https://github.com/buildbot/buildbot/wiki/CRLF-injection-in-Buildbot-login-and-logout-redirect-code) Thanks to
mik317andmariadbfor reporting it.
5.61. Release Notes for Buildbot 1.8.0 ( 2019-01-20 )
5.61.1. Bug fixes
Fix a regression present in v1.7.0 which caused buildrequests waiting for a lock that got released by an unrelated build not be scheduled (issue #4491)
Don’t run builds that request an instance with incompatible properties on Docker, Marathon and OpenStack latent workers.
Gitpoller now fetches only branches that are known to exist on remote. Non-existing branches are quietly ignored.
The demo repo in sample configuration files and the tutorial is now fetched via
https:instead ofgit:to make life easier for those behind firewalls and/or using proxies.buildbot sendchange has been fixed on Python 3 (issue #4138)
5.61.2. Features
Add a
KubeLatentWorkerto launch workers into a kubernetes clusterSimplify/automate configuration of worker as Windows service - eliminate manual configuration of Log on as a service
5.61.3. Deprecations and Removals
The deprecated
BuildMaster.addBuildsetmethod has been removed. UseBuildMaster.data.updates.addBuildsetinstead.The deprecated
BuildMaster.addChangemethod has been removed. UseBuildMaster.data.updates.addChangeinstead.buildbotpackage now requires Twisted versions >= 17.9.0. This is required for Python 3 support. Earlier versions of Twisted are not supported.
5.62. Release Notes for Buildbot 1.7.0 ( 2018-12-21 )
5.62.1. Bug fixes
Fixed JSON decoding error when sending build properties to www change hooks on Python 3.
Buildbot no longer attempts to start builds that it can prove will have unsatisfied locks.
Don’t run builds that request images or sizes on instances started with different images or sizes.
5.62.2. Features
The Buildbot master Docker image at https://hub.docker.com/r/buildbot/ has been upgraded to use Python 3.7 by default.
Builder page has been improved with a smoothed build times plot, and a new success rate plot.
Allow the Buildbot master initial start timeout to be configurable.
An API to check whether an already started instance of a latent worker is compatible with what’s required by a build that is about to be started.
Add support for v2 of the Vault key-value secret engine in the SecretInVault secret provider.
5.62.3. Deprecations and Removals
Build.canStartWithWorkerForBuilder static method has been made private and renamed to _canAcquireLocks.
The Buildbot master Docker image based on Python 2.7 has been removed in favor of a Python 3.7 based image.
Builder.canStartWithWorkerForBuilder method has been removed. Use Builder.canStartBuild.
5.63. Release Notes for Buildbot 1.6.0 ( 2018-11-16 )
5.63.1. Bug fixes
Fixed missing buildrequest owners in the builder page (issue #4207, issue #3904)
Fixed display of the buildrequest number badge text in the builder page when on hover.
Fix usage of master paths when doing Git operations on worker (issue #4268)
5.63.2. Improved Documentation
Misc improvement in Git source build step documentation.
Improve documentation of AbstractLatentWorker.
Improve the documentation of the Buildbot concepts by removing unneeded details to other pages.
5.63.3. Features
Added a page that lists all pending buildrequests (issue #4239)
Builder page now has a chart displaying the evolution of build times over time
Improved FileUpload efficiency (issue #3709)
Add method
getResponsibleUsersForBuildinNotifierBaseso that users can override recipients, for example to skip authors of changes.Add define parameter to RpmBuild to specify additional –define parameters.
Added SSL proxy capability to base web application’s developer test setup (
gulp dev proxy --host the-buildbot-host --secure).
5.63.4. Deprecations and Removals
The Material design Web UI has been removed as unmaintained. It may be brought back if a maintainer steps up.
5.64. Release Notes for Buildbot 1.5.0 ( 2018-10-09 )
5.64.1. Bug fixes
Fix the umask parameter example to make it work with both Python 2.x and 3.x.
Fix build-change association for multi-codebase builds in the console view..
Fixed builders page doesn’t list workers in multi-master configuration (issue #4326)
Restricted groups added by
GitHubAuth’sgetTeamsMembershipoption to only those teams to which the user belongs. Previously, groups were added for all teams for all organizations to which the user belongs.Fix ‘Show old workers’ combo behavior.
5.64.2. Features
GitHub teams added to a user’s
groupsbyGitHubAuth’sgetTeamsMembershipoption are now added by slug as well as by name. This means a team named “Bot Builders” in the organization “buildbot” will be added as bothbuildbot/Bot Buildersandbuildbot/bot-builders.Make
urlTextrenderable for theFileUploadbuild step.Added
noticeOnChanneloption toIRCto send notices instead of messages to channels. This was an option in v0.8.x and removed in v0.9.0, which defaulted to sending notices. The v0.8.x default of sending messages is now restored.
5.64.3. Reverts
Reverted: Fix git submodule support when using sshPrivateKey and sshHostKey because it broke other use cases (issue #4316) In order to have this feature to work, you need to keep your master in 1.4.0, and make sure your worker
buildbot.tacare installed in the same path as your master.
5.65. Release Notes for Buildbot 1.4.0 ( 2018-09-02 )
5.65.1. Bug fixes
Fix Build.getUrl() to not ignore virtual builders.
Fix git submodule support when using sshPrivateKey and sshHostKey settings by passing ssh data as absolute, not relative paths.
Fixed
P4for change in latest version of p4 login -p.buildbot.reporters.irc.IrcStatusBotno longer encodes messages before passing them on to methods of its Twisted base class to avoid posting therepr()of a bytes object when running on Python 3.
5.65.2. Features
5.65.3. Test Suite
Test suite has been improved for readability by adding a lot of
inlineCallbacksFixed tests which didn’t wait for
assertFailure’s returned deferred.The test suite now runs on Python 3.7 (mostly deprecation warnings from dependencies shut down)
5.66. Release Notes for Buildbot 1.3.0 ( 2018-07-13 )
5.66.1. Bug fixes
buildbot-worker docker image no longer use pidfile. This allows to auto-restart a docker worker upon crash.
GitLab v3 API is deprecated and has been removed from http://gitlab.com, so we now use v4. (issue #4143)
5.66.2. Features
-
Gitnow supports sshHostKey parameter to specify ssh public host key for fetch operations.-
Gitnow supports sshPrivateKey parameter to specify private ssh key for fetch operations.-
GitPollernow supports sshHostKey parameter to specify ssh public host key for fetch operations. This feature is supported on git 2.3 and newer.-
GitPollernow supports sshPrivateKey parameter to specify private ssh key for fetch operations. This feature is supported on git 2.3 and newer.Github hook token validation now uses
hmac.compare_digest()for better security
5.66.3. Deprecations and Removals
Removed support for GitLab v3 API ( GitLab < 9 ).
5.67. Release Notes for Buildbot 1.2.0 ( 2018-06-10 )
5.67.1. Bug fixes
Don’t schedule a build when a GitLab merge request is deleted or edited (issue #3635)
Add GitLab source step; using it, we now handle GitLab merge requests from forks properly (issue #4107)
Fixed a bug in
MailNotifier’screateEmailmethod when called with the default builds value which resulted in mail not being sent.Fixed a Github crash that happened on Pull Requests, triggered by Github Web-hooks. The json sent by the API does not contain a commit message. In github.py this causes a crash, resulting into response 500 sent back to Github and building failure.
Speed up generation of api/v2/builders by an order of magnitude. (issue #3396).
5.67.2. Improved Documentation
Added
examples/gitlab.cfgto demonstrate integrating Buildbot with GitLab.
5.67.3. Features
ForceScheduler Parameters now support an
autopopulateparameter.ForceScheduler Parameters
ChoiceParameternow correctly supports thestrictparameter, by allowing free text entry if strict is False.Allow the remote ref to be specified in the GitHub hook configuration (issue #3998)
Added callable to p4 source that allows client code to resolve the p4 user and workspace into a more complete author. Default behaviour is a lambda that simply returns the original supplied who. This callable happens after the existing regex is performed.
5.68. Release Notes for Buildbot 1.1.2 ( 2018-05-15 )
5.68.1. Bug fixes
fix several multimaster issues by reverting issue #3911. re-opens issue #3783. (issue #4067, issue #4062, issue #4059)
Fix
MultipleFileUploadto correctly compute path name when worker and master are on different OS (issue #4019)LDAP bytes/unicode handling has been fixed to work with Python 3. This means that LDAP authentication, REMOTE_USER authentication, and LDAP avatars now work on Python 3. In addition, an of bounds access when trying to load the value of an empty LDAP attribute has been fixed.
Removing
`no-select`rules from places where they would prevent the user from selecting interesting text. (issue #3663)fix
`Maximum recursion depth exceededwhen lots of worker are trying to connect while master is starting or reconfiguring (issue #4042).
5.68.2. Improved Documentation
Document a minimal secure config for the Buildbot web interface. (issue #4026)
5.68.3. Features
The Dockerfile for the buildbot master image has been updated to use Alpine Linux 3.7. In addition, the Python requests module has been added to this image. This makes GitHub authentication work out of the box with this image. (issue #4039)
New steps for Visual Studio 2017 (VS2017, VC141, and MsBuild141).
The smoke tests have been changed to use ES2017 async and await keywords. This requires that the smoke tests run with Node 8 or higher. Use of async and await is recommended by the Protractor team: https://github.com/angular/protractor/blob/master/docs/async-await.md
Allow
urlTextto be set on a url linked to aDirectoryUploadstep (issue #3983)
5.69. Release Notes for Buildbot 1.1.1 ( 2018-04-06 )
5.69.1. Bug fixes
Fix issue which marked all workers dis-configured in the database every 24h (issue #3981 issue #3956 issue #3970)
The
MailNotifierno longer crashes when sending from/to email addresses with “Real Name” parts (e.g.,John Doe <john.doe@domain.tld>).Corrected pluralization of text on landing page of the web UI
5.69.2. Improved Documentation
Corrected typo in description of libvirt
Update sample config to use preferred API
5.69.3. Misc Improvements
Home page now contains links to recently active builders
5.70. Release Notes for Buildbot 1.1.0 ( 2018-03-10 )
5.70.1. Deprecations and Removals
Removed
ramlficationas a dependency to build the docs and run the tests.
5.70.2. Bug fixes
Fixed buildrequests API doesn’t provide properties data (issue #3929)
Fix missing owner on builder build table (issue #3311)
Include hipchat as reporter.
Fix encoding issues of commands with Windows workers (issue #3799).
Fixed Relax builder name length restriction (issue #3413).
Fix the configuration order so that services can actually use secrets (issue #3985)
Partially fix Builder page should show the worker information (issue #3546).
5.70.3. Features
Added the
defaultPropertiesparameter tobuilders.When a build step has a log called “summary” (case-insensitive), the Build Summary page will sort that log first in the list of logs, and automatically expand it.
5.71. Release Notes for Buildbot 1.0.0 ( 2018-02-11 )
Despite the major version bump, Buildbot 1.0.0 does not have major difference with the 0.9 series. 1.0.0 is rather the mark of API stability. Developers do not foresee a major API break in the next few years like we had for 0.8 to 0.9.
Starting with 1.0.0, Buildbot will follow semver versioning methodology.
5.71.1. Bug fixes
Cloning
Gitrepository with submodules now works with Git < 1.7.6 instead of failing due to the use of the unsupported--forceoption.GitHubhook now properly creates a change in case of new tag or new branch.GitHubchanges will have thecategoryset totagwhen a tag was pushed to easily distinguish from a branch push.Fixed issue with
Master.expireMastersnot always honoring itsforceHouseKeepingparameter. (issue #3783)Fixed issue with steps not correctly ending in
CANCELLEDstatus when interrupted.Fix maximum recursion limit issue when transferring large files with
LocalWorker(issue:3014).Added an argument to P4Source that allows users to provide a callable to convert Perforce branch and revision to a valid revlink URL. Perforce supplies a p4web server for resolving urls into change lists.
Fixed issue with
buildbot_pkg`not hanging on yarn step on windows (issue #3890).Fix issue with
workersnotify_on_missingnot able to be configurable as a single string instead of list of string (issue #3913).Fixed Builder page should display worker name instead of id (issue #3901).
5.71.2. Features
Add capability to override the default UI settings (issue #3908)
All Reporters have been adapted to be able to use Secret.
SVNPollerhas been adapted to be able to use Secret.Implement support for Bitbucket Cloud webhook plugin in
BitbucketCloudEventHandlerThe
ownersproperty now includes people associated with the changes of the build (issue #3904).The repo source step now syncs with the
--force-syncflag which allows the sync to proceed when a source repo in the manifest has changed.Add support for compressing the repo source step cache tarball with
pigz, a parallel gzip compressor.
5.72. Release Notes for Buildbot 0.9.15.post1 ( 2018-01-07 )
5.72.1. Bug fixes
Fix worker reconnection fails (issue #3875, issue #3876)
Fix umask set to 0 when using LocalWorker (issue #3878)
Fix Buildbot reconfig, when badge plugin is installed (issue #3879)
Fix (issue #3865) so that now
SVNPollerworks with paths that contain valid UTF-8 characters which are not ASCII.
5.73. Release Notes for Buildbot 0.9.15 ( 2018-01-02 )
5.73.1. Bug fixes
Fix builder page not showing any build (issue #3820)
Fix double Workers button in the menu. (issue #3818)
Fix bad icons in the worker action dialog.
Fix url arguments in Buildbot Badges for python3.
Upgrading to guanlecoja-ui version 1.8.0, fixing two issues. Fixed issue where the console view would jump to the top of page when opening the build summary dialog (issue #3657). Also improved sidebar behaviour by remembering previous pinned vs. collapsed state.
Fixes issue with Buildbot
DockerLatentWorker, where Buildbot can kill running workers by mistake based on the form the worker name (issue #3800).Fixes issue with Buildbot
DockerLatentWorkernot reaping zombies process within its container environment.Update requirement text to use the modern “docker” module from the older “docker-py” module name
When multiple
reporterorservicesare configured with the same name, an error is now displayed instead of silently discarding all but the last one issue #3813.Fixed exception when using
buildbot.www.auth.CustomAuth
5.73.2. Features
New Buildbot SVG icons for web UI. The web UI now uses a colored favicon according to build results (issue #3785).
pausedandgracefulWorkers States are now stored in the database.Workers States are now displayed in the web UI.
Quarantine timers is now using the
pausedworker state.Quarantine timer is now enabled when a build finish on
EXCEPTIONstate.Standalone binaries for buildbot-worker package are now published for windows and linux (
amd64). This allows to run a buildbot-worker without having a python environment.New
buildbot-worker create-worker --maxretriesfor Latent Workers to quit if the master is or becomes unreachable.Badges can now display running as status.
The database schema now supports cascade deletes for all objects instead of raising an error when deleting a record which has other records pointing to it via foreign keys.
Buildbot can properly find its version if installed from a git archive tarball generated from a tag.
Enhanced the test suite to add worker/master protocol interoperability tests between python3 and python2.
5.73.3. Deprecations and Removals
buildbot.util.ascii2unicode() is removed. buildbot.util.bytes2unicode() should be used instead.
5.74. Release Notes for Buildbot 0.9.14 ( 2017-12-08 )
5.74.1. Bug fixes
Compile step now properly takes the decodeRC parameter in account (issue #3774)
Fix duplicate build requests results in
BuildRequestsConnectorComponentwhen querying the database (issue #3712).GitPollernow accepts git branch names with UTF-8 characters (issue #3769).Fixed inconsistent use of pointer style mouse cursor by removing it from the .label css rule and instead creating a new .clickable css rule which is used only in places which are clickable and would not otherwise automatically get the pointer icon, for example it is not needed for hyper-links. (issue #3795).
Rebuilding with the same revision now takes new change properties into account instead of re-using the original build change properties (issue #3701).
Worker authentication is now delayed via a DeferredLock until Buildbot configuration is finished. This fixes UnauthorizedLogin errors during buildbot restart (issue #3462).
Fixes python3 encoding issues with Windows Service (issue #3796)
5.74.2. Features
new :ref`badges` plugin which reimplement the buildbot eight png badge system.
In progress worker control API. Worker can now be stopped and paused using the UI. Note that there is no UI yet to look the status of those actions (issue #3429).
Make maximum number of builds fetched on the builders page configurable.
Include context in the log message for GitHubStatusPush
On ‘Builders’ page reload builds when tags change.
Give reporters access to master single in renderables. This allows access to build logs amongst other things
Added possibility to check www user credentials with a custom class.
5.75. Release Notes for Buildbot 0.9.13 ( 2017-11-07 )
5.75.1. Deprecations and Removals
Following will help Buildbot to leverage new feature of twisted to implement important features like worker protocol encryption.
The
buildbotandbuildbot-workerpackages now requires Python 2.7 or Python 3.4+ – Python 2.6 is no longer supported.buildbotandbuildbot-workerpackages now required Twisted versions >= 16.1.0. Earlier versions of Twisted are not supported.
5.75.2. Bug fixes
Fix Console View forced builds stacking at top (issue:3461)
Improve buildrequest distributor to ensure all builders are processed. With previous version, builder list could be re-prioritized, while running the distributor, meaning some builders would never be run in case of master high load. (issue #3661)
Improve
getOldestRequestTimefunction of buildrequest distributor to do sorting and paging in the database layer (issue #3661).Arguments passed to GitLab push notifications now work with Python 3 (issue #3720).
Web hooks change sources which use twisted.web.http.Request have been fixed to use bytes, not native strings. This ensures web hooks work on Python 3. Please report any issues on web hooks in python3, as it is hard for us to test end to end.
Fixed null value of steps and logs in reporter HttpStatusPush api. Fixes (issue #3180)
EC2LatentBuilder now correctly sets tags on spot instances (issue #3739).
Fixed operation of the Try scheduler for a code checked out from Subversion.
Fix buildbot worker startup when running as a windows service
5.75.3. Features
Make parameters for
WarningCountingShellCommandrenderable. These are suppressionList, warningPattern, directoryEnterPattern, directoryLeavePattern and maxWarnCount.GitHubEventHandlernow supports authentication for GitHub instances that do not allow anonymous accessAdded support for renderable builder locks. Previously only steps could have renderable locks.
Added flag to Docker Latent Worker to always pull images
5.76. Release Notes for Buildbot 0.9.12.post1 ( 2017-10-10 )
This is a release which only exists for the buildbot_grid_view package.
5.76.1. Bug fixes
Fix Grid View plugin broken because of merge resolution mistake ( issue #3603 and issue #3688.)
5.77. Release Notes for Buildbot 0.9.12 ( 2017-10-05 )
5.77.1. Bug fixes
Fixed many issues related to connecting masters and workers with different major version of Python (issue #3416).
Fixed KeyError in the log when two buildrequests of the same buildset are finished at the same time (issue #3472, issue #3591)
Fix for SVN.purge fails when modified files contain non-ascii characters (issue #3576)
Fix the GitHub change hook on Python 3 (issue #3452).
Fix
reporters.gitlabto use correct commit status codes (issue #3641).Fixed deadlock issue, when locks are taken at least 3 times by the 3 Buildstep with same configuration (issue #3650)
Fix the Gerrit source step in the presence of multiple Gerrit repos (issue #3460).
Add empty pidfile option to master and worker start script when –nodaemon option is on. (issue #3012).
5.77.2. Features
Add possibility to specify a
PatchParameterfor anyCodebaseParameterin aForceScheduler(part of issue #3110).Latent Workers will no longer continually retry if they cannot substantiate (issue #3572)
5.77.3. Deprecations and Removals
buildbot.util.encodeString() has been removed. buildbot.util.unicode2bytes() should be used instead.
5.78. Release Notes for Buildbot 0.9.11 ( 2017-09-08 )
5.78.1. Incompatible Changes
Buildbot is not compatible with
python3-ldapanymore. It now requiresldap3package for its ldap operations (issue #3530)
5.78.2. Bug fixes
Fix issue with
logviewerscrolling up indefinitely when loading logs (issue #3154).Do not add the url if it already exists in the step. (issue #3554)
Fix filtering for REST resource attributes when SQL is involved in the backend (eq, ne, and contains operations, when there are several filters) (issue #3526).
The
gitsource step now uses git checkout -B rather than git branch -M to create local branches (issue #3537)Fixed Grid View settings. It is now possible to configure “false” values.
Fix performance issue when remote command does not send any line boundary (issue #3517)
Fix regression in GithHub oauth2 v3 api, when using enterprise edition.
Fix the Perforce build step on Python 3 (issue #3493)
Make REST API’s filter __contains use OR connector rather than AND according to what the documentation suggests.
Fixed secret plugins registration, so that they are correctly available in
import buildbot.plugins.secrets. changes to all secrets plugin to be imported and used.Fix secrets downloaded to worker with too wide permissions.
Fix issue with stop build during latent worker substantiating, the build result was retried instead of cancelled.
pip install 'buildbot[bundle]'now installsgrid_viewplugin. This fixes issues with the tutorial wheregrid_viewis enabled by default.
5.78.3. Improved Documentation
Fixed documentation regarding log obfuscation for passwords.
Improve documentation of REST API’s __contains filter.
5.78.4. Features
Added autopull for Docker images based on config. (issue #3071)
Allow to expose logs to summary callback of
GerritStatusPush.Implement GitHub change hook CI skipping (issue #3443). Now buildbot will ignore the event, if the
[ci skip]keyword (configurable) in commit message. For more info, please check out theskipparameter ofGitHubhook.GitHubStatusPushnow support reporting to ssh style URLs, ie git@github.com:Owner/RepoName.gitAdded the possibility to filter builds according to results in Grid View.
OpenStackLatentWorkernow supports V3 authentication.Buildbot now tries harder at finding line boundaries. It now supports several cursor controlling ANSI sequences as well as use of lots of backspace to go back several characters.
UI Improvements so that Buildbot build pages looks better on mobile.
OpenStackLatentWorkernow supports region attribute.The Schedulers
builderNamesparameter can now be aIRenderableobject that will render to a list of builder names.The
LdapUserInfonow uses the python3-ldap successor ldap3 (issue #3530).Added support for static suppressions parameter for shell commands.
5.79. Release Notes for Buildbot 0.9.10 ( 2017-08-03 )
5.79.1. Bug fixes
Fix ‘reconfig master causes worker lost’ error (issue #3392).
Fix bug where object names could not be larger than 150 characters (issue #3449)
Fix bug where notifier names could not be overridden (issue #3450)
Fix exception when shutting down a master (issue #3478)
Fix Manhole support to work with Python 3 and Twisted 16.0.0+ (issue #3160).
AuthorizedKeysManholeandPasswordManholenow require a directory containing SSH host keys to be specified.Fix python 3 issue with displaying the properties when fetching builders (issue #3418).
Fix bug when
ShellArgarguments were rendered only once during an instance’s lifetime.Fix waterfall tiny size of build status indicators (issue #3475)
Fix waterfall natural order of builder list
Fix builder page use ‘pointer’ cursor style for tags (issue #3473)
Fix builder page update tag filter when using the browser’s back button (issue #3474)
5.79.2. Features
added support for builder names in REST API. Note that those endpoints are not (yet) available from the UI, as the events are not sent to the endpoints with builder names.
Implemented new ability to set from by email domain. Implemented
RolesFromDomain. (issue #3422)
5.80. Release Notes for Buildbot 0.9.9.post2 ( 2017-07-06 )
5.80.1. Bug fixes
Fix
tried to complete 100 buildrequests, but only completed 25issue in buildrequest collapser (issue #3406)Fixed issue when several mail notifiers are used with same parameters, but different modes (issue #3398).
Fixed release scripts for
postNreleases
5.81. Release Notes for Buildbot 0.9.9.post1 ( 2017-07-01 )
5.81.1. Bug fixes
Fix regression with
GitHubAuthwhen API v3 is used.When using the
GitHubAuthv4 API, the generated GraphQL to get the user organizations uses a name alias for each organization. These aliases must not contain dashes.
5.82. Release Notes for Buildbot 0.9.9 ( 2017-06-29 )
5.82.1. Bug fixes
Fixed a regression inn
UserPasswordAuthwhere a list would create an error.Fix non ascii payload handling in base web hook (issue #3321).
Fixed default buildrequest collapsing (issue #3151)
_wait_for_request() would fail to format a log statement due to an invalid type being passed to log.msg (resulting in a broken build)
Fix Windows compatibility with frontend development tool
gulp dev proxy(issue #3359)
5.82.2. Features
New Grid View UI plugin.
The Change Hooks system is now integrated in the Plugin Infrastructure in Buildbot system, making it easier to subclass hooks. There is still the need to re- factor hook by hook to allow better customizability.
The
GitHubAuthnow allows fetching the user team membership for all organizations the user belongs to. This requires access to a V4 GitHub API(GraphQL).GitLab merge request hook now create a change with repository to be the source repository and branch the source branch. Additional properties are created to point to destination branch and destination repository. This makes
GitLabStatusPushpush the correct status to GitLab, so that pipeline report is visible in the merge request page.The
GitHubEventHandlernow allows the inclusion of white-listed properties for push events.Allow sending a comment to a pull request for Bitbucket Server in
BitbucketServerPRCommentPushImplement support for Bitbucket Server webhook plugin in
BitbucketServerEventHandler
5.83. Release Notes for Buildbot 0.9.8 ( 2017-06-14 )
5.83.1. Core Bug fixes
Fix incompatibility issue of
UserPasswordAuthwith python 3.Fix issue with oauth sequence not working with Firefox (issue #3306)
Update old
addChangemethod to accept the new chdict names if only the new name is present. Fixes issue #3191.fix bytes vs string issue on python3 with authorization of rest endpoints.
5.83.2. Core Features
doStepIfis now renderable.Source step codebase is now renderable.
Step names are now renderable.
Added
giturlparseutility function to help buildbot components like reporters to parse git url from change sources.Factorized the mail reporter to be able to write new message based reporters, for other backend than SMTP.
The class
Propertynow allows being used with Python built in comparators. It will return a Renderable which executes the comparison.
5.83.3. Components Bug fixes
GitLab reporter now correctly sets the status to running instead of pending when a build starts.
GitLab reporter now correctly works when there are multiple codebase, and when the projects names contain url reserved characters.
GitLab reporter now correctly reports the status even if there are several sourcestamps. Better parsing of change repository in GitLab reporter so that it understands ssh urls and https url. GitLab reporter do not use the project field anymore to know the repository to push to.
5.83.4. Components Features
GitLab hook now supports the merge_request event to automatically build from a merge request. Note that the results will not properly displayed in merge_request UI due to https://gitlab.com/gitlab-org/gitlab-ce/issues/33293
Added a https://pushjet.io/ reporter as
buildbot.reporters.pushjet.PushjetNotifierNew build step
AssertTests a renderable or constant if it evaluates to true. It will succeed or fail to step according to the result.
5.84. Release Notes for Buildbot 0.9.7 ( 2017-05-09 )
5.84.1. Core Bug fixes
Fix
UserPasswordAuthauthentication onpy3and recent browsers. (issue #3162, issue #3163). Thepy3fix also requires Twisted https://github.com/twisted/twisted/pull/773.Console View now display changes the same way as in Recent Changes page.
Fix issue with Console View when no change source is configured but still builds have
got_revisionproperty
5.84.2. Components Bug fixes
Allow renderables in options and definitions of step
CMake. Currently only dicts and lists with renderables inside are allowed.OAuthAuthentication are now working withRolesFromEmails.DockerLatentWorker:_image_existsdoes not raise anymore if it encounters an image with<none>tagFix command line parameters for
Robocopystepverboseoption
5.84.3. Core Features
Builds
state_stringis now automatically computed according to theBuildStep.getResultSummary,BuildStep.descriptionandupdateBuildSummaryPolicyfrom Parameters Common to all Steps. This allows the dashboards and reporters to get a descent summary text of the build without fetching the steps.New
configuratorssection, which can be used to create higher level configuration modules for Buildbot.New
JanitorConfiguratorwhich can be used to create a builder which save disk space by removing old logs from the database.
5.84.4. Components Features
Added a https://pushover.net/ reporter as
buildbot.reporters.pushover.PushoverNotifierpropertyargument in SetPropery is now renderable.
5.85. Release Notes for Buildbot 0.9.6 ( 2017-04-19 )
5.85.1. Core Bug fixes
buildbot.www.authz.endpointmatchers.AnyControlEndpointMatchernow actually doesn’t match GET requests. Before it would act like an AnyEndpointMatcher since the GET had a different case.Passing
unicodebuilderNamestoForceSchedulerno longer causes an error.Fix issue with :bb:sched::Nightly change classification raising foreign key exceptions (issue #3021)
Fixes an exception found
buildbot_net_usage_data._sendWithUrlibwhen running through the tutorial using Python 3.usePTYconfiguration of theShellCommandnow works as expected with recent version of buildbot-worker.
5.85.2. Components Bug fixes
pollAtLaunchof theGitHubPullrequestPollernow works as expected. Also the author email won’t be displayed as NoneGerritChangeSourceandGerritStatusPushnow use the master’s environment including PATH variable to find the ssh binary.SlaveDirectoryUploadCommandno longer throws exceptions because the file “is used by another process” under Windows
5.85.3. UI Bug fixes
Fix waterfall scrolling and zooming in current browsers
console_viewnow properly usesrevlinkmetadata to link to changes.Fixed Console View infinite loading spinner when no change have been recorded yet (issue #3060).
5.85.4. Core Features
new Virtual Builders concept for better integration of frameworks which store the build config along side the source code.
5.85.5. Components Features
BitBucketnow sets theeventproperty on each change to what theX-Event-Keyheader contains.GitHubPullrequestPollernow adds additional information about the pull request to properties. The property argument is removed and is populated with the repository full name.GitHubnow sets theeventproperty on each change to what theX-GitHub-Eventheader contains.Changed
GitHubAuthnow supports GitHub Enterprise when setting newserverURLargument.GitLabnow sets theeventproperty on each change to what theX-GitLab-Eventheader contains.GitHubnow process git tag push eventsGitHubnow adds more information about the pull request to the properties. This syncs features withGitHubPullrequestPollerGitLabnow process git tag push eventsGitLabnow supports authentication with the secret token
5.85.6. UI Features
Reworked Console View and Waterfall View for better usability and better integration with virtual builders
Javascript Data Module collections now have a
$resolvedattribute which allows dashboard to know when the data is loaded.
5.86. Release Notes for Buildbot 0.9.5 ( 2017-03-18 )
5.86.1. Bug fixes
Fix issue with compressing empty log
Fix issue with db being closed by wrong thread
Fix issue with buildbot_worker not closing file handles when using the transfer steps
Fix issue with buildbot requesting too many permissions from GitHub’s OAuth
Fix
HTTPStepto acceptjsonas keyword argument.Updated
OpenStackLatentWorkerto use keystoneauth1 so it will support latest python-novaclient packages.Include
RpmLintstep in steps plugins.
5.86.2. Core Features
Experimental support for Python 3.5 and 3.6. Note that complete support depends on fixes to be released in Twisted 17.2.0.
New experimental Secret Management framework, which allows to securely declare secrets, reusable in your steps.
New Writing Dashboards with Flask or Bottle plugin, which allows to write custom dashboard with traditional server side web frameworks.
Added
AnyControlEndpointMatcherandEnableSchedulerEndpointMatcherfor better configurability of the access control. If you have access control to your Buildbot, it is recommended you addAnyControlEndpointMatcherat the end of your access control configuration.Schedulers can now be toggled on and off from the UI. Useful for temporarily disabling periodic timers.
5.86.3. Components Features
FileUploadnow supports setting the url title text that is visible in the web UI.FileUploadnow supports custom description and descriptionDone text.EC2LatentWorkernow provides instance id as the instance property enabling use of the AWS toolkit.Add GitHub pull request Poller to list of available changesources.
OAuth2LoginResourcenow supports the token URL parameter. If a user wants to authenticate through OAuth2 with a pre- generated token (such as the access_token provided by GitHub) it can be passed to /auth/login as the token URL parameter and the user will be authenticated to buildbot with those credentials.New reporter
GitHubCommentPushcan comment on GitHub PRsGitPollernow supports polling tags in a git repository.MultipleFilUploadnow supports the glob parameter. If glob is set to True all workersrcs parameters will be run through glob and the result will be uploaded to masterdestChanged
OpenStackLatentWorkerto default to v2 of the Nova API. The novaclient package has had a deprecation warning about v1.1 and would use v2 anyway.
5.86.4. Deprecations and Removals
master/contribandworker/contribdirectories have been moved to their own repository at https://github.com/buildbot/buildbot-contrib/
5.87. Release Notes for Buildbot 0.9.4 ( 2017-02-08 )
5.87.1. Database upgrade
A database upgrade is necessary for this release (see upgrade-master).
5.87.2. Bug fixes
Like for
buildbot start,buildbot upgrade-masterwill now erase an old pidfile if the process is not live anymore instead of just failing.Change properties ‘value’ changed from String(1024) to Text. Requires upgrade master. (bug #3197)
When using REST API, it is now possible to filter and sort in descending order at the same time.
Fix issue with
HttpStatusPushraisingdatetime is not JSON serializableerror.Fix issue with log viewer not properly rendering color codes.
Fixed log viewer selection and copy-paste for Firefox (bug #3662).
Fix issue with
DelayedCalledalready called, and worker missing notification email never received.schedulersandchange_sourceare now properly taking configuration change in account withbuildbot reconfig.setuptoolsis now explicitly marked as required. The dependency was previously implicit.buildbotNetUsageDatanow usesrequestsif available and will default to HTTP if a bogus SSL implementation is found. It will also correctly send information about the platform type.
5.87.3. Features
Buildbot now uses JWT to store its web UI Sessions. Sessions now persist upon buildbot restart. Sessions are shared between masters. Session expiration time is configurable with
c['www']['cookie_expiration_time']seewww.Builders page has been optimized and can now be displayed with 4 http requests whatever is the builder count (previously, there was one http request per builder).
Builder and Worker page build list now have the
numbuilds=option which allows to show more builds.Masters page now shows more information about a master (workers, builds, activity timer)
Workers page improvements:
Shows which master the worker is connected to.
Shows correctly the list of builders that this master is configured on (not the list of
buildermasterwhich nobody cares about).Shows list of builds per worker similar to the builders page.
New worker details page displays the list of builds built by this worker using database optimized query.
5.87.4. Deprecations and Removals
Some deprecated broken Contrib Scripts were removed.
buildbot.www.hooks.googlecodehas been removed, since the Google Code service has been shut down.buildbot.util.jsonhas been deprecated in favor of the standard libraryjson.simplejsonwill not be used anymore if found in the virtualenv.
5.88. Release Notes for Buildbot 0.9.3 ( 2017-01-11 )
5.88.1. Bug fixes
Fix
BitbucketStatusPushep should start with /assertion error.Fix duplicate worker use case, where a worker with the same name would make the other worker also disconnect (bug #3656)
GitPoller:buildPushesWithNoCommitsnow rebuilds for a known branch that was updated to an existing commit.Fix issue with log viewer not staying at bottom of the log when loading log lines.
Fixed addBuildURLs in
Triggerto use results from triggered builds to include in the URL name exposed by API.Fix Wamp
mqsupport by removingdebug,debug_ampanddebug_appfrom themqconfig, which is not available in latest version of Python Autobahn. You can now usewamp_debug_leveloption instead.fix issue with factory.workdir AttributeError are not properly reported.
5.88.2. Features
Optimize the memory consumption of the log compression process. Buildbot do not load the whole log into memory anymore. This should improve a lot buildbot memory footprint.
Changed the build page so that the preview of the logs are shown in live. It is a preview means the last lines of log. How many lines is configurable per user in the user settings page.
Log viewer line numbers are no longer selectable, so that it is easier to copy paste.
DockerLatentWorkeraccepts now renderable DockerfileRenderer function can now return
IRenderableobjects.new
SetPropertieswhich allows to generate and transform properties separately.Handle new workers in windows_service.py script.
Sort the builders in the waterfall view by name instead of ID.
5.89. Release Notes for Buildbot 0.9.2 ( 2016-12-13 )
5.89.1. Bug fixes
Fix
GitHubAuthto retrieve all organizations instead of only those publicly available.Fixed ref to point to branch instead of commit sha in
GitLabStatusPushIRCmaybeColorizeis able to highlight single words and stop colorization at the end. The previous implementation only stopped colorization but not boldface.fix compatibility issue with mysql5 (do not set default value for TEXT column).
Fixed addChange in
Changeto use the revlink configuration option to generate the revlink.fix threading issue in
DockerLatentWorker
5.89.2. Features
Implement
BitbucketAuth.New
GerritEventLogPollerpoller to poll Gerrit changes via http API.New
GerritVerifyStatusPushcan send multiple review status for the same Gerrit change.IRCappends the builder URL to a successful/failed build if availableMailNotifiernow acceptsuseSmtpsparameter for initiating connection over an SSL/TLS encrypted connection (SMTPS)New support for
Mesosand Marathon viaMarathonLatentWorker.Marathonis a production-grade container orchestration platform for Mesosphere’s Data- center Operating System (DC/OS) and ApacheMesos.passwordinDockerLatentWorkerandHyperLatentWorker, can be None. In that case, they will be auto-generated from random number.BitbucketServerStatusPushnow acceptskey,buildName,endDescription,startDescription, andverboseparameters to control the JSON sent to Stash.Buildbot can now be configured to deny read access to REST api resources based on authorization rules.
5.90. Release Notes for Buildbot 0.9.1
The following are the release notes for Buildbot 0.9.1.
This version was released on November 1, 2016.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.90.1. Master
5.90.1.1. Features
Add support for hyper.sh via
HyperLatentWorkerHyper is a CaaS solution for hosting docker container in the cloud, billed to the second. It forms a very cost efficient solution to run your CI in the cloud.The
Triggerstep now supportsunimportantSchedulerNamesadd a UI button to allow to cancel the whole queue for a builder
Buildbot log viewer now support 256 colors ANSI codes
new
GitHubwhich correctly checkout the magic branch likerefs/pull/xx/merge.MailNotifiernow supports a schedulers constructor argument that allows you to send mail only for builds triggered by the specified list of schedulers.MailNotifiernow supports a branches constructor argument that allows you to send mail only for builds triggered by the specified list of branches.Optimization of the data api filtering, sorting and paging, speeding up a lot the UI when the master has lots of builds.
GerritStatusPushnow accepts anotifyparameter to control who gets emailed by Gerrit.Add a
format_fnparameter to theHttpStatusPushreporter to customize the information being pushed.Latent Workers can now start in parallel.
The build started by latent worker will be created while the latent worker is substantiated.
Latent Workers will now report startup issues in the UI.
- Workers will be temporarily put in quarantine in case of build preparation issues.
This avoids master and database overload in case of bad worker configuration. The quarantine is implemented with an exponential back-off timer.
Master Stop will now stop all builds, and wait for all workers to properly disconnect. Previously, the worker connections was stopped, which incidentally made all their builds marked retried. Now, builds started with a
Triggereablescheduler will be cancelled, while other builds will be retried. The master will make sure that all latent workers are stopped.The
MessageFormatterclass also allows inline-templates with thetemplateparameter.The
MessageFormatterclass allows custom mail’s subjects with thesubjectandsubject_nameparameters.The
MessageFormatterclass allows extending the context given to the Templates via thectxparameter.The new
MessageFormatterMissingWorkerclass allows to customize the message sent when a worker is missing.The
OpenStackLatentWorkerworker now supports rendering the block device parameters. Thevolume_sizeparameter will be automatically calculated if it isNone.
5.90.1.2. Fixes
fix the UI to allow to cancel a buildrequest (bug #3582)
GitHubchange hook now correctly use the refs/pull/xx/merge branch for testing PRs.Fix the UI to better adapt to different screen width (bug #3614)
Don’t log
AlreadyClaimedError. They are normal in case ofTriggercancelling, and in a multimaster configuration.Fix issues with worker disconnection. When a worker disconnects, its current buildstep must be interrupted and the buildrequests should be retried.
Fix the worker missing email notification.
Fix issue with worker builder list not being updated in UI when buildmaster is reconfigured (bug #3629)
5.90.1.3. Changes for Developers
5.90.1.4. Features
New
SharedServicecan be used by steps, reporters, etc to implement per master resource limit.New
HTTPClientServicecan be used by steps, reporters, etc to implement HTTP client. This class will automatically choose between treq and txrequests, whichever is installed, in order to access HTTP servers. This class comes with a fake implementation helping to write unit tests.All HTTP reporters have been ported to
HTTPClientService
5.90.1.5. Fixes
5.90.1.6. Deprecations, Removals, and Non-Compatible Changes
By default, non-distinct commits received via
buildbot.status.web.hooks.github.GitHubEventHandlernow get recorded as aChange. In this way, a commit pushed to a branch that is not being watched (e.g. a dev branch) will still get acted on when it is later pushed to a branch that is being watched (e.g. master). In the past, such a commit would get ignored and not built because it was non-distinct. To disable this behavior and revert to the old behavior, install aChangeFilterthat checks thegithub_distinctproperty:
ChangeFilter(filter_fn=lambda c: c.properties.getProperty('github_distinct'))
setup.py ‘scripts’ have been converted to console_scripts entry point. This makes them more portable and compatible with wheel format. Most consequences are for the windows users:
buildbot.batdoes not exist anymore, and is replaced bybuildbot.exe, which is generated by the console_script entrypoint.buildbot_service.pyis replaced bybuildbot_windows_service.exe, which is generated by the console_script entrypoint As this script has been written in 2006, has only inline documentation and no unit tests, it is not guaranteed to be working. Please help improving the windows situation.
The
userandpasswordparameters of theHttpStatusPushreporter have been deprecated in favor of theauthparameter.The
template_nameparameter of theMessageFormatterclass has been deprecated in favor oftemplate_filename.
5.90.2. Worker
5.90.2.1. Fixes
5.90.2.2. Changes for Developers
5.90.2.3. Deprecations, Removals, and Non-Compatible Changes
The worker now requires at least Twisted 10.2.0.
setup.py ‘scripts’ have been converted to console_scripts entry point. This makes them more portable and compatible with wheel format. Most consequences are for the windows users:
buildbot_worker.batdoes not exist anymore, and is replaced bybuildbot_worker.exe, which is generated by the console_script entrypoint.buildbot_service.pyis replaced bybuildbot_worker_windows_service.exe, which is generated by the console_script entrypoint As this script has been written in 2006, has only inline documentation and no unit tests, it is not guaranteed to be working. Please help improving the windows situation.
AbstractLatentWorkeris now inbuildbot.worker.latentinstead ofbuildbot.worker.base.
5.90.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0..v0.9.1
5.91. Release Notes for Buildbot 0.9.0
The following are the release notes for Buildbot 0.9.0.
This version was released on October 6, 2016.
This is a concatenation of important changes done between 0.8.12 and 0.9.0. This does not contain details of the bug fixes related to the nine beta and rc period. This document was written during the very long period of nine development. It might contain some incoherencies, please help us and report them on irc or trac.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.91.1. Master
This version represents a refactoring of Buildbot into a consistent, well-defined application composed of loosely coupled components. The components are linked by a common database backend and a messaging system. This allows components to be distributed across multiple build masters. It also allows the rendering of complex web status views to be performed in the browser, rather than on the buildmasters.
The branch looks forward to committing to long-term API compatibility, but does not reach that goal. The Buildbot-0.9.x series of releases will give the new APIs time to “settle in” before we commit to them. Commitment will wait for Buildbot-1.0.0 (as per http://semver.org). Once Buildbot reaches version 1.0.0, upgrades will become much easier for users.
To encourage contributions from a wider field of developers, the web application is designed to look like a normal AngularJS application. Developers familiar with AngularJS, but not with Python, should be able to start hacking on the web application quickly. The web application is “pluggable”, so users who develop their own status displays can package those separately from Buildbot itself.
Other goals:
An approachable HTTP REST API, with real time event features used by the web application but available for any other purpose.
A high degree of coverage by reliable, easily-modified tests.
“Interlocking” tests to guarantee compatibility. For example, the real and fake DB implementations must both pass the same suite of tests. Then no unseen difference between the fake and real implementations can mask errors that will occur in production.
5.91.1.1. Requirements
The buildbot package requires Python 2.7 – Python 2.5 and 2.6 are no longer supported.
The buildbot-slave package requires Python 2.6 or higher – Python 2.4 and 2.5 are no longer supported.
No additional software or systems, aside from some minor Python packages, are required.
But the devil is in the details:
If you want to do web development, or build the
buildbot-wwwpackage, you’ll need Node. It’s an Angular app, and that’s how such apps are developed. We’ve taken pains to not make either a requirement for users - you can simply ‘pip install’buildbot-wwwand be on your way. This is the case even if you’re hacking on the Python side of Buildbot.For a single master, nothing else is required.
Note for distro package maintainers: The npm dependency hell
In order to build the buildbot-www package, you’ll need Node.
Node has a very specific package manager named npm, which has the interesting property of allowing different version of package to co-exist in the same environment. The node ecosystem also has the habit of creating packages for a few line of code.
Buildbot UI uses the node ecosystem to build its javascript UI.
The buildsystem that we use is called guanlecoja, which is just an integration of various javascript build tools.
Through npm dependency hell, guanlecoja is depending on 625 npm packages/versions. We do not advise you to try and package all those npm build dependencies. They are not required in order to run buildbot.
We do release pre-built packages in the form of the wheel format on PyPI. Those wheels contain the full python source code, and prebuilt javascript source code.
Depending on distro maintainers feedback, we could also release source tarballs with prebuilt javascript, but those would be PyPI packages with different names, e.g. buildbot_www_prebuilt.0.9.0.tar.gz.
Another option would be to package a guanlecoja that would embed all its dependencies inside one package.
Detailed requirements
see Requirements
5.91.1.2. Features
Buildbot-0.9.0 introduces the Data API, a consistent and scalable method for accessing and updating the state of the Buildbot system. This API replaces the existing, ill-defined Status API, which has been removed. Buildbot-0.9.0 introduces new WWW Server Interface using websocket for realtime updates. Buildbot code that interacted with the Status API (a substantial portion!) has been rewritten to use the Data API. Individual features and improvements to the Data API are not described on this page.
Buildbot now supports plugins. They allow Buildbot to be extended by using components distributed independently from the main code. They also provide for a unified way to access all components. When previously the following construction was used:
from buildbot.kind.other.bits import ComponentClass ... ComponentClass ...
the following construction achieves the same result:
from buildbot.plugins import kind ... kind.ComponentClass ...
Kinds of components that are available this way are described in Plugin Infrastructure in Buildbot.
Note
While the components can be still directly imported as
buildbot.kind.other.bits, this might not be the case after Buildbot v1.0 is released.Both the P4 source step and P4 change source support ticket-based authentication.
OpenStack latent slaves now support block devices as a bootable volume.
Add new
Cppcheckstep.Add a new Docker latent Workers.
Add a new configuration for creating custom services in out-of-tree CI systems or plugins. See
buildbot.util.service.BuildbotServiceAdd
try_sshconfiguration file setting and--sshcommand line option for the try tool to specify the command to use for connecting to the build master.GitHub change hook now supports application/json format.
Add support for dynamically adding steps during a build. See Dynamic Build Factories.
GitPollernow supports detecting new branchesGitsupports an “origin” option to give a name to the remote repo.Mercurial hook was updated and modernized. It is no longer necessary to fork. One can now extend PYTHONPATH via the hook configuration. Among others, it permits to use a buildbot virtualenv instead of installing buildbot in all the system. Added documentation inside the hook. Misc. clean-up and reorganization in order to make the code a bit more readable.
UI templates can now be customizable. You can provide html or jade overrides to the www plugins, to customize the UI
The irc command
hellonow returns ‘Hello’ in a random language if invoked more than once.Triggerablenow accepts areasonparameter.GerritStatusPushnow accepts abuildersparameter.StatusPush callback now receives build results (success/failure/etc) with the
buildFinishedevent.There’s a new renderable type, Transform.
GitPollernow has abuildPushesWithNoCommitsoption to allow the rebuild of already known commits on new branches.Add GitLab authentication plugin for web UI. See
buildbot.www.oauth2.GitLabAuth.CMakebuild step is added. It provides a convenience interface to CMake build system.MySQL InnoDB tables are now supported.
HttpStatusPushhas been ported to reporter API.StashStatusPushhas been ported to reporter API.GithubStatusPushhas been ported to reporter API.summaryCB of
GerritStatusPushnow gets not only pre-processed information but the actual build as well.EC2LatentWorker supports VPCs, instance profiles, and advanced volume mounts.
New steps for Visual Studio 2015 (VS2015, VC14, and MsBuild14).
The
P4step now obfuscates the password in status logs.Added support for specifying the depth of a shallow clone in
Git.OpenStackLatentWorkernow uses a single novaclient instance to not require re-authentication when starting or stopping instances.Buildbot UI introduces branch new Authentication, and Authorizations framework.
Please look at their respective guide in WWW Server
buildbot stopnow waits for complete buildmaster stop by default.New
--no-waitargument forbuildbot stopwhich allows not to wait for complete master shutdown.New
LocalWorkerworker to run a worker in the master process, requiresbuildbot-workerpackage installed.GerritStatusPushnow includes build properties in thestartCBandreviewCBfunctions.startCBnow must return a dictionary.add tool to send usage data to buildbot.net
buildbotNetUsageDatanew
GitHubwhich correctly checkout the magic branch likerefs/pull/xx/merge.Enable parallel builds with Visual Studio and MSBuild.
5.91.1.3. Reporters
Status plugins have been moved into the reporters namespace.
Their API has slightly to changed in order to adapt to the new data API.
See respective documentation for details.
GerritStatusPushrenamed toGerritStatusPushMailNotifierrenamed toMailNotifierMailNotifierargumentmessageFormattershould now be aMessageFormatter, due to removal of data api, custom message formatters need to be rewritten.MailNotifierargumentpreviousBuildGetteris not supported anymoreGerritsupports specifying an SSH identity file explicitly.Added StashStatusPush status hook for Atlassian Stash
MailNotifierno longer forces SSL 3.0 whenuseTlsis true.GerritStatusPushcallbacks slightly changed signature, and include a master reference instead of a status reference.new
GitLabStatusPushto report builds results to GitLab.new
HipchatStatusPushto report build results to Hipchat.
5.91.1.4. Fixes
Buildbot is now compatible with SQLAlchemy 0.8 and higher, using the newly-released SQLAlchemy-Migrate.
The version check for SQLAlchemy-Migrate was fixed to accept more version string formats.
The
HTTPStepstep’s request parameters are now renderable.With Git(), force the updating submodules to ensure local changes by the build are overwritten. This both ensures more consistent builds and avoids errors when updating submodules.
Buildbot is now compatible with Gerrit v2.6 and higher.
To make this happen, the return result of
reviewCBandsummaryCBcallback has changed from(message, verified, review)
to
{'message': message, 'labels': {'label-name': value, ... } }
The implications are:
there are some differences in behaviour: only those labels that were provided will be updated
Gerrit server must be able to provide a version, if it can’t the
GerritStatusPushwill not work
Note
If you have an old style
reviewCBand/orsummaryCBimplemented, these will still work, however there could be more labels updated than anticipated.More detailed information is available in
GerritStatusPushsection.P4Source’sserver_tzparameter now works correctly.The
revlinkin changes produced by the Bitbucket hook now correctly includes thechanges/portion of the URL.PBChangeSource’s git hook https://github.com/buildbot/buildbot-contrib/tree/master/master/contrib/git_buildbot.py now supports git tagsA pushed git tag generates a change event with the
branchproperty equal to the tag name. To schedule builds based on buildbot tags, one could use something like this:c['schedulers'].append( SingleBranchScheduler(name='tags', change_filter=filter.ChangeFilter( branch_re='v[0-9]+\.[0-9]+\.[0-9]+(?:-pre|rc[0-9]+|p[0-9]+)?') treeStableTimer=None, builderNames=['tag_build']))
Missing “name” and “email” properties received from Gerrit are now handled properly
Fixed bug which made it impossible to specify the project when using the BitBucket dialect.
The
PyLintstep has been updated to understand newer output.Fixed SVN master-side source step: if a SVN operation fails, the repository end up in a situation when a manual intervention is required. Now if SVN reports such a situation during initial check, the checkout will be clobbered.
The build properties are now stored in the database in the
build_propertiestable.The list of changes in the build page now displays all the changes since the last successful build.
GitHub change hook now correctly responds to ping events.
GitHub change hook now correctly use the refs/pull/xx/merge branch for testing PRs.
buildbot.steps.httpsteps now correctly haveurlparameter renderableWhen no arguments are used
buildbot checkconfignow usesbuildbot.tacto locate the master config file.buildbot.util.flatten now correctly flattens arbitrarily nested lists. buildbot.util.flattened_iterator provides an iterable over the collection which may be more efficient for extremely large lists.
The
PyFlakesandPyLintsteps no longer parse output in Buildbot log headers (bug #3337).GerritChangeSourceis now less verbose by default, and has adebugoption to enable the logs.P4Sourceno longer relies on the perforce server time to poll for new changes.The commit message for a change from
P4Sourcenow matches what the user typed in.Fix incompatibility with MySQL-5.7 (bug #3421)
Fix incompatibility with postgresql driver psycopg2 (bug #3419, further regressions will be caught by travis)
Made
Interpolatesafe for deepcopy or serialization/deserializationsqlite access is serialized in order to improve stability (bug #3565)
5.91.1.5. Deprecations, Removals, and Non-Compatible Changes
Seamless upgrading between buildbot 0.8.12 and buildbot 0.9.0 is not supported. Users should start from a clean install but can reuse their config according to the Upgrading to Buildbot 0.9.0 guide.
BonsaiPoller is removed.
buildbot.ec2buildslaveis removed; usebuildbot.buildslave.ec2instead.buildbot.libvirtbuildslaveis removed; usebuildbot.buildslave.libvirtinstead.buildbot.util.flatten flattens lists and tuples by default (previously only lists). Additionally, flattening something that isn’t the type to flatten has different behaviour. Previously, it would return the original value. Instead, it now returns an array with the original value as the sole element.
buildbot.tacdoes not supportprintstatements anymore. Such files should now useprintas a function instead (see https://docs.python.org/3.0/whatsnew/3.0.html#print-is-a-function for more details). Note that this applies to both python2.x and python3.x runtimes.Deprecated
workdirproperty has been removed,builddirproperty should be used instead.To support MySQL InnoDB, the size of six VARCHAR(256) columns
changes.(author, branch, category, name); object_state.name; user.identifierwas reduced to VARCHAR(255).StatusPushhas been removed from buildbot.Please use the much simpler
HttpStatusPushinstead.
Worker changes described in below worker section will probably impact a buildbot developer who uses undocumented ‘slave’ API. Undocumented APIs have been replaced without failover, so any custom code that uses it shall be updated with new undocumented API.
Web server does not provide /png and /redirect anymore (bug #3357). This functionality is used to implement build status images. This should be easy to implement if you need it. One could port the old image generation code, or implement a redirection to http://shields.io/.
Support of worker-side
usePTYwas removed frombuildbot-worker.usePTYargument was removed fromWorkerForBuilderandWorkerclasses.html is no longer permitted in ‘label’ attributes of forcescheduler parameters.
public_htmldirectory is not created anymore inbuildbot create-master(it’s not used for some time already). Documentation was updated with suggestions to use third party web server for serving static file.usePTYdefault value has been changed fromslave-configtoNone(use ofslave-configwill still work)./jsonweb status was removed. Data API should be used instead.
WebStatus
The old, clunky WebStatus has been removed. You will like the new interface! RIP WebStatus, you were a good friend.
remove it and replace it with www configuration.
Requirements
Support for python 2.6 was dropped from the master.
Buildbot’s tests now require at least Mock-0.8.0.
SQLAlchemy-Migrate-0.6.1 is no longer supported.
Builder names are now restricted to unicode strings or ASCII bytestrings. Encoded bytestrings are not accepted.
Steps
New-style steps are now the norm, and support for old-style steps is deprecated. Upgrade your steps to new-style now, as support for old-style steps will be dropped after Buildbot-0.9.0. See New-Style Build Steps in Buildbot 0.9.0 for details.
Status strings for old-style steps could be supplied through a wide variety of conflicting means (
describe,description,descriptionDone,descriptionSuffix,getText, andsetText, to name just a few). While all attempts have been made to maintain compatibility, you may find that the status strings for old-style steps have changed in this version. To fix steps that callsetText, try setting thedescriptionDoneattribute directly, instead – or just rewrite the step in the new style.
Old-style source steps (imported directly from
buildbot.steps.source) are no longer supported on the master.The monotone source step got an overhaul and can now better manage its database (initialize and/or migrate it, if needed). In the spirit of monotone, buildbot now always keeps the database around, as it’s an append-only database.
Changes and Removals
Buildslave names must now be 50-character identifier. Note that this disallows some common characters in bulidslave names, including spaces,
/, and..Builders now have “tags” instead of a category. Builders can have multiple tags, allowing more flexible builder displays.
ForceSchedulerhas the following changes:The default configuration no longer contains four
AnyPropertyParameterinstances.Configuring
codebasesis now mandatory, and the deprecatedbranch,repository,project,revisionare not supported anymore inForceSchedulerbuildbot.schedulers.forcesched.BaseParameter.updateFromKwargsnow takes acollectorparameter used to collect all validation errors
Periodic,NightlyandNightlyTriggerablehave the following changes:Logs are now stored as Unicode strings, and thus must be decoded properly from the bytestrings provided by shell commands. By default this encoding is assumed to be UTF-8, but the
logEncodingparameter can be used to select an alternative. Steps and individual logfiles can also override the global default.The PB status service uses classes which have now been removed, and anyway is redundant to the REST API, so it has been removed. It has taken the following with it:
buildbot statuslogbuildbot statusgui(the GTK client)buildbot debugclient
The
PBListenerstatus listener is now deprecated and does nothing. Accordingly, there is no external access to status objects via Perspective Broker, aside from some compatibility code for the try scheduler.The
debugPasswordconfiguration option is no longer needed and is thus deprecated.The undocumented and un-tested
TinderboxMailNotifier, designed to send emails suitable for the abandoned and insecure Tinderbox tool, has been removed.Buildslave info is no longer available via Interpolate and the
SetSlaveInfobuildstep has been removed.The undocumented
pathparameter of theMasterShellCommandbuildstep has been renamedworkdirfor better consistency with the other steps.The name and source of a Property have to be unicode or ascii string.
Property values must be serializable in JSON.
IRChas the following changes:categories parameter is deprecated and removed. It should be replaced with tags=[cat]
noticeOnChannel parameter is deprecated and removed.
workdir behavior has been unified:
workdirattribute of steps is now a property inBuildStep, and choose the workdir given following priority:workdir of the step, if defined
workdir of the builder (itself defaults to ‘build’)
setDefaultWorkdir() has been deprecated, but is now behaving the same for all the steps: Setting self.workdir if not already set
Triggernow has agetSchedulersAndPropertiesmethod that can ve overridden to support dynamic triggering.`master.cfgis now parsed from a thread. Previously it was run in the main thread, and thus slowing down the master in case of big config, or network access done to generate the config.SVNPoller’s svnurl parameter has been changed to repourl.Providing Latent AWS EC2 credentials by the
.ec2/aws_idfile is deprecated: Use the standard.aws/credentialsfile, instead.
5.91.1.6. Changes for Developers
Botmaster no longer service parent for workers. Service parent functionality has been transferred to WorkerManager. It should be noted Botmaster no longer has a
slavesfield as it was moved to WorkerManager.The sourcestamp DB connector now returns a
patchidfield.Buildbot no longer polls the database for jobs. The
db_poll_intervalconfiguration parameter and thedbkey of the same name are deprecated and will be ignored.The interface for adding changes has changed. The new method is
master.data.updates.addChange(implemented byaddChange), although the old interface (master.addChange) will remain in place for a few versions. The new method:returns a change ID, not a Change instance;
takes its
when_timestampargument as epoch time (UNIX time), not a datetime instance; anddoes not accept the deprecated parameters
who,isdir,is_dir, andwhen.requires that all strings be unicode, not bytestrings.
Please adjust any custom change sources accordingly.
A new build status, CANCELLED, has been added. It is used when a step or build is deliberately cancelled by a user.
This upgrade will delete all rows from the
buildrequest_claimstable. If you are using this table for analytical purposes outside of Buildbot, please back up its contents before the upgrade, and restore it afterward, translating object IDs to scheduler IDs if necessary. This translation would be very slow and is not required for most users, so it is not done automatically.All of the schedulers DB API methods now accept a schedulerid, rather than an objectid. If you have custom code using these methods, check your code and make the necessary adjustments.
The
addBuildsetForSourceStampmethod has becomeaddBuildsetForSourceStamps, and its signature has changed. TheaddBuildsetForSourceStampSetDetailsmethod has becomeaddBuildsetForSourceStampsWithDefaults, and its signature has changed. TheaddBuildsetForSourceStampDetailsmethod has been removed. TheaddBuildsetForLatestmethod has been removed. It is equivalent toaddBuildsetForSourceStampDetailswithsourcestamps=None. These methods are not yet documented, and their interface is not stable. Consult the source code for details on the changes.The
preStartConsumingChangesandstartTimedSchedulerServicehooks have been removed.The triggerable schedulers
triggermethod now requires a list of sourcestamps, rather than a dictionary.The
SourceStampclass is no longer used. It remains in the codebase to support loading data from pickles on upgrade, but should not be used in running code.The
BuildRequestclass no longer has fullsourceorsourcesattributes. Use the data API to get this information (which is associated with the buildset, not the build request) instead.The undocumented
BuilderControlmethodsubmitBuildRequesthas been removed.The debug client no longer supports requesting builds (the
requestBuildmethod has been removed). If you have been using this method in production, consider instead creating a new change source, using theForceScheduler, or using one of the try schedulers.The
buildbot.misc.SerializedInvocationclass has been removed; usebuildbot.util.debounce.methodinstead.The
progressattributes of bothbuildbot.process.buildstep.BuildStepandbuildbot.process.build.Buildhave been removed. Subclasses should only be accessing the progress-tracking mechanics via thebuildbot.process.buildstep.BuildStep.setProgressmethod.The
BuilderConfignextSlavekeyword argument takes a callable. This callable now receivesBuildRequestinstance in its signature as 3rd parameter. For retro-compatibility, all callable taking only 2 parameters will still work.properties object is now directly present in build, and not in build_status. This should not change much unless you try to access your properties via step.build.build_status. Remember that with PropertiesMixin, you can access properties via getProperties on the steps, and on the builds objects.
5.91.2. Slaves/Workers
5.91.2.1. Transition to “worker” terminology
Since version 0.9.0 of Buildbot “slave”-based terminology is deprecated in favor of “worker”-based terminology.
For details about public API changes see Transition to “worker” terminology in BuildBot 0.9.0, and Release Notes for Buildbot 0.9.0b8 release notes.
The
buildbot-slavepackage has been renamed tobuildbot-worker.Buildbot now requires import to be sorted using isort. Please run
make isortbefore creating a PR or use any available editor plugin in order to reorder your imports.
5.91.2.2. Requirements
buildbot-workerrequires Python 2.6
5.91.2.3. Features
The Buildbot worker now includes the number of CPUs in the information it supplies to the master on connection. This value is autodetected, but can be overridden with the
--numcpusargument tobuildslave create-worker.The
DockerLatentWorkerimage attribute is now renderable (can take properties in account).The
DockerLatentWorkersets environment variables describing how to connect to the master. Example dockerfiles can be found in https://github.com/buildbot/buildbot-contrib/tree/master/master/contrib/docker.DockerLatentWorkernow has ahostconfigparameter that can be used to setup host configuration when creating a new container.DockerLatentWorkernow has anetworking_configparameter that can be used to setup container networks.The
DockerLatentWorkervolumesattribute is now renderable.
5.91.2.4. Fixes
5.91.2.5. Changes for Developers
EC2 Latent Worker upgraded from
boto2toboto3.
5.91.2.6. Deprecations, Removals, and Non-Compatible Changes
buildmaster and worker no longer supports old-style source steps.
On Windows, if a
ShellCommandstep in whichcommandwas specified as a list is executed, and a list element is a string consisting of a single pipe character, it no longer creates a pipeline. Instead, the pipe character is passed verbatim as an argument to the program, like any other string. This makes command handling consistent between Windows and Unix-like systems. To have a pipeline, specifycommandas a string.Support for python 2.6 was dropped from the master.
public_htmldirectory is not created anymore inbuildbot create-master(it’s not used for some time already). Documentation was updated with suggestions to use third party web server for serving static file.usePTYdefault value has been changed fromslave-configtoNone(use ofslave-configwill still work).GithubStatusPushreporter was renamed toGitHubStatusPush.Worker commands version bumped to 3.0.
Master/worker protocol has been changed:
slave_commandskey in worker information was renamed toworker_commands.getSlaveInforemote method was renamed togetWorkerInfo.slave-configvalue ofusePTYis not supported anymore.slavesrccommand argument was renamed toworkersrcinuploadFileanduploadDirectorycommands.slavedestcommand argument was renamed toworkerdestindownloadFilecommand.Previously deprecated
WorkerForBuilder.remote_shutdown()remote command has been removed.
5.91.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.8.12..v0.9.0
5.92. Release Notes for Buildbot 0.9.0rc4
The following are the release notes for Buildbot 0.9.0rc4.
This version was released on September 28, 2016.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.92.1. Master
5.92.1.1. Fixes
Fix the UI to better adapt to different screen width (bug #3614)
Add more REST api documentation (document
/rawendpoints, andPOSTactions)
5.92.2. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0rc3..v0.9.0rc4
5.93. Release Notes for Buildbot 0.9.0rc3
The following are the release notes for Buildbot 0.9.0rc3.
This version was released on September 14, 2016.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.93.1. Master
5.93.1.1. Features
add tool to send usage data to buildbot.net
buildbotNetUsageData
5.93.1.2. Fixes
Publish python module buildbot.buildslave in the dist files
Upgrade to guanlecoja 0.7 (for compatibility with node6)
Fix invocation of trial on windows, with twisted 16+
Fix rare issue which makes buildbot throw a exception when there is a sourcestamp with no change for a particular codebase.
5.93.2. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0rc2..v0.9.0rc3
5.94. Release Notes for Buildbot 0.9.0rc2
The following are the release notes for Buildbot 0.9.0rc2.
This version was released on August 23, 2016.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.94.1. Master
5.94.1.1. Features
add a UI button to allow to cancel the whole queue for a builder
5.94.1.2. Fixes
fix the UI to allow to cancel a buildrequest (bug #3582)
Fix BitbucketPullrequestPoller change detection
Fix customization for template_type in email reporter
fix DockerLatent integration of volumes mounting
misc doc fixes
fix buildbot not booting when builder tags contains duplicates
forcesched: fix owner parameter when no authentication is usedREST: fix problem with twisted 16 error reporting
CORS: format errors according to API type
Dockerfiles fix and upgrade Ubuntu to 16.04
Fixes #3430 Increased size of builder identifier from 20 to 50 (brings it in line to size of steps and workers in same module).
Fix missing VS2015 entry_points
removed the restriction on twisted < 16.3.0 now that autobahn 0.16.0 fixed the issue
5.94.1.3. Changes for Developers
5.94.1.4. Features
5.94.1.5. Fixes
5.94.1.6. Deprecations, Removals, and Non-Compatible Changes
remove repo from worker code (obsoleted by repo master source step)
5.94.2. Worker
5.94.2.1. Fixes
5.94.2.2. Changes for Developers
5.94.2.3. Deprecations, Removals, and Non-Compatible Changes
5.94.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0rc1..v0.9.0rc2
5.95. Release Notes for Buildbot 0.9.0rc1
The following are the release notes for Buildbot 0.9.0rc1.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.95.1. Master
5.95.1.1. Features
new
HipchatStatusPushto report build results to Hipchat.new steps for Visual Studio 2015 (VS2015, VC14, and MsBuild14).
The
P4step now obfuscates the password in status logs.Added support for specifying the depth of a shallow clone in
Git.OpenStackLatentWorkernow uses a single novaclient instance to not require re-authentication when starting or stopping instances.The
distparameter inRpmBuildis now renderable.new
BitbucketStatusPushto report build results to a Bitbucket Cloud repository.
5.95.1.2. Fixes
GerritStatusPushnow includes build properties in thestartCBandreviewCBfunctions.startCBnow must return a dictionary.Fix TypeError exception with
HgPollerifusetimestamps=Falseis used (bug #3562)Fix recovery upon master unclean kill or crash (bug #3564)
sqlite access is serialized in order to improve stability (bug #3565)
Docker latent worker has been fixed (bug #3571)
5.95.1.3. Changes for Developers
5.95.1.4. Features
5.95.1.5. Fixes
5.95.1.6. Deprecations, Removals, and Non-Compatible Changes
Support for python 2.6 was dropped from the master.
public_htmldirectory is not created anymore inbuildbot create-master(it’s not used for some time already). Documentation was updated with suggestions to use third party web server for serving static file.usePTYdefault value has been changed fromslave-configtoNone(use ofslave-configwill still work).GithubStatusPushreporter was renamed toGitHubStatusPush.
5.95.2. Worker
5.95.2.1. Deprecations, Removals, and Non-Compatible Changes
The
buildbot-slavepackage has finished being renamed tobuildbot-worker.
5.95.3. Worker
5.95.3.1. Fixes
runGlob()uses the correct remote protocol for bothCommandMixinandComposititeStepMixin.Rename
glob()torunGlob()inCommandMixin
5.95.3.2. Changes for Developers
EC2 Latent Worker upgraded from
boto2toboto3.
5.95.3.3. Deprecations, Removals, and Non-Compatible Changes
Worker commands version bumped to 3.0.
Master/worker protocol has been changed:
slave_commandskey in worker information was renamed toworker_commands.getSlaveInforemote method was renamed togetWorkerInfo.slave-configvalue ofusePTYis not supported anymore.slavesrccommand argument was renamed toworkersrcinuploadFileanduploadDirectorycommands.slavedestcommand argument was renamed toworkerdestindownloadFilecommand.Previously deprecated
WorkerForBuilder.remote_shutdown()remote command has been removed.
5.95.4. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b9..v0.9.0rc1
Note that Buildbot-0.8.11 was never released.
5.96. Release Notes for Buildbot 0.9.0b9
The following are the release notes for Buildbot 0.9.0b9 This version was released on May 10, 2016.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.96.1. Master
5.96.1.1. Features
new
GitLabStatusPushto report builds results to GitLab.buildbot stopnow waits for complete buildmaster stop by default.New
--no-waitargument forbuildbot stopwhich allows not to wait for complete master shutdown.Builder page is now sorted by builder name
LogViewer page now supports ANSI color codes, and is displayed white on black.
5.96.1.2. Changes for Developers
Speed improvements for integration tests by use of SynchronousTestCase, and in-memory sqlite.
Buildbot now requires import to be sorted using isort. Please run
make isortbefore creating a PR or use any available editor plugin in order to reorder your imports.
5.96.1.3. Fixes
OpenStackLatentWorker uses the novaclient API correctly now.
Scheduler changes are now identified by serviceid instead of objectid (bug #3532)
Make groups optional in LdapUserInfo (bug #3511)
Buildbot nine do not write pickles anymore in the master directory
Fix build page to not display build urls, but rather directly the build-summary, which already contain the URL.
UI Automatically reconnect on disconnection from the websocket. (bug #3462)
5.96.1.4. Deprecations, Removals, and Non-Compatible Changes
The buildmaster now requires at least Twisted-14.0.1.
The web ui has upgrade its web components dependencies to latest versions. This can impact web-ui plugin.
Web server does not provide /png and /redirect anymore (bug #3357). This functionality is used to implement build status images. This should be easy to implement if you need it. One could port the old image generation code, or implement a redirection to http://shields.io/.
Support of worker-side
usePTYwas removed frombuildbot-worker.usePTYargument was removed fromWorkerForBuilderandWorkerclasses.html is no longer permitted in ‘label’ attributes of forcescheduler parameters.
LocalWorkernow requiresbuildbot-workerpackage, instead ofbuildbot-slave.Collapse Request Functions now takes master as first argument. The previous callable contained too few data in order to be really usable. As collapseRequests has never been released outside of beta, backward compatibility with previous release has not been implemented.
This is the last version of buildbot nine which supports python 2.6 for the master. Next version will drop python 2.6 support.
5.96.2. Worker
5.96.2.1. Fixes
buildbot-workerscript now outputs message to terminal.Windows helper script now called
buildbot-worker.bat(wasbuildbot_worker.bat, notice underscore), so thatbuildbot-workercommand can be used in virtualenv both on Windows and POSIX systems.
5.96.2.2. Changes for Developers
SLAVEPASSenvironment variable is not removed in default-generatedbuildbot.tac. Environment variables are cleared in places where they are used (e.g. in Docker Latent Worker contrib scripts).Master-part handling has been removed from
buildbot-workerlog watcher (bug #3482).WorkerDetectedErrorexception type has been removed.
5.96.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b8..v0.9.0b9
5.97. Release Notes for Buildbot 0.9.0b8
The following are the release notes for Buildbot 0.9.0b8 This version was released on April 11, 2016.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.97.1. Master
5.97.1.1. Features
GitPollernow has abuildPushesWithNoCommitsoption to allow the rebuild of already known commits on new branches.Add GitLab authentication plugin for web UI. See
buildbot.www.oauth2.GitLabAuth.DockerLatentWorkernow has ahostconfigparameter that can be used to setup host configuration when creating a new container.DockerLatentWorkernow has anetworking_configparameter that can be used to setup container networks.The
DockerLatentWorkervolumesattribute is now renderable.CMakebuild step is added. It provides a convenience interface to CMake build system.MySQL InnoDB tables are now supported.
HttpStatusPushhas been ported to reporter API.StashStatusPushhas been ported to reporter API.GithubStatusPushhas been ported to reporter API.summaryCB of
GerritStatusPushnow gets not only pre-processed information but the actual build as well.EC2LatentWorker supports VPCs, instance profiles, and advanced volume mounts.
5.97.1.2. Fixes
Fix loading
LdapUserInfoplugin and its documentation (bug #3371).Fix deprecation warnings seen with docker-py >= 1.4 when passing arguments to
docker_client.start().GitHubEventHandlernow uses the['repository']['html_url']key in the webhook payload to populaterepository, as the previously used['url']and['clone_url']keys had a different format between push and pull requests and GitHub and GitHub Enterprise instances.Fix race condition where log compression could lead to empty log results in reporter api
Error while applying db upgrade is now properly reported in the buildbot upgrade-master command line.
Made
Interpolatesafe for deepcopy or serialization/deserializationOptimized UI REST requests for child builds and change page.
Fix
DockerLatentWorkeruse of volume parameter, they now properly manage src:dest syntax.Fix
DockerLatentWorkerto properly create properties so that docker parameters can be renderable.Lock down autobahn version for python 2.6 (note that autobahn and twisted are no longer supporting 2.6, and thus do not receive security fixes anymore).
Fix docs and example to always use port 8020 for the web ui.
5.97.1.3. Deprecations, Removals, and Non-Compatible Changes
Deprecated
workdirproperty has been removed,builddirproperty should be used instead.To support MySQL InnoDB, the size of six VARCHAR(256) columns
changes.(author, branch, category, name); object_state.name; user.identifierwas reduced to VARCHAR(255).StatusPushhas been removed from buildbot.Please use the much simpler
HttpStatusPushinstead.
5.97.1.4. Changes for Developers
Worker changes described in below worker section will probably impact a buildbot developer who uses undocumented ‘slave’ API. Undocumented APIs have been replaced without failover, so any custom code that uses it shall be updated with new undocumented API.
5.97.2. Worker
Package buildbot-slave is being renamed buildbot-worker. As the work is not completely finished, neither buildbot-slave==0.9.0b8 or buildbot-worker==0.9.0b8 have been released.
You can safely use any version of buildbot-slave with buildbot==0.9.0b8, either buildbot-slave==0.8.12 or buildbot-slave==0.9.0b7.
5.97.3. Transition to “worker” terminology
Since version 0.9.0 of Buildbot “slave”-based terminology is deprecated in favor of “worker”-based terminology.
For details about public API changes see Transition to “worker” terminology in BuildBot 0.9.0.
API changes done without providing fallback:
Old name |
New name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Other changes done without providing fallback:
Functions argument
buildslaveNamerenamed toworkerName.Loop variables, local variables, helper functions:
Old name
New name
sworworkerslworworkerbs(“buildslave”)wsbwfb(“worker for builder”)bs1(),bs2()w1(),w2()bslaveworkerBS1_NAME,BS1_ID,BS1_INFOW1_NAME,W1_ID,W1_INFOIn
buildbot.config.BuilderConfig.getConfigDictresult'slavenames'key changed to'workernames';'slavebuilddir'key changed to'workerbuilddir';'nextSlave'key changed to'nextWorker'.buildbot.process.builder.BuilderControl.pingnow generates["ping", "no worker"]event, instead of["ping", "no slave"].buildbot.plugins.util.WorkerChoiceParameter(previouslyBuildslaveChoiceParameter) label was changed fromBuild slavetoWorker.buildbot.plugins.util.WorkerChoiceParameter(previouslyBuildslaveChoiceParameter) default name was changed fromslavenametoworkername.buildbot.status.builder.SlaveStatusfallback was removed.SlaveStatuswas moved tobuildbot.status.builder.slavepreviously, and now it’sbuildbot.status.worker.WorkerStatus.buildbot.status.status_push.StatusPushevents generation changed (this module will be completely removed in 0.9.x):instead of
slaveConnectedwith dataslave=...now generatedworkerConnectedevent with dataworker=...;instead of
slaveDisconnectedwith dataslavename=...now generatedworkerDisconnectedwith dataworkername=...;instead of
slavePausedwith dataslavename=...now generatedworkerPausedevent with dataworkername=...;instead of
slaveUnpausedwith dataslavename=...now generatedworkerUnpausedevent with dataworkername=...;
buildbot.status.build.BuildStatus.asDictreturns worker name under'worker'key, instead of'slave'key.buildbot.status.builder.BuilderStatus.asDictreturns worker names under'workers'key, instead of'slaves'key.Definitely privately used “slave”-named variables and attributes were renamed, including tests modules, classes and methods.
5.97.3.1. Database
Database API changes done without providing fallback.
Old name |
New name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.97.3.2. Data API
Python API changes:
Old name |
New name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Changed REST endpoints:
Old name |
New name |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Changed REST object keys:
Old name |
New name |
|---|---|
|
|
|
|
|
|
|
|
data_module version bumped from 1.2.0 to 2.0.0.
5.97.3.3. Web UI
In base web UI (www/base) and Material Design web UI (www/md_base) all “slave”-named messages and identifiers were renamed to use “worker” names and new REST API endpoints.
5.97.3.4. MQ layer
buildslaveid key in messages were replaced with workerid.
5.97.4. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b7..v0.9.0b8
5.98. Release Notes for Buildbot 0.9.0b7
The following are the release notes for Buildbot 0.9.0b7 This version was released on February 14, 2016.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.98.1. Master
5.98.1.1. Features
5.98.1.2. Fixes
5.98.1.3. Deprecations, Removals, and Non-Compatible Changes
The
buildbotPython dist now (finally) requires SQLAlchemy-0.8.0 or later and SQLAlchemy-Migrate-0.9.0 or later. While the old pinned versions (0.7.10 and 0.7.2, respectively) still work, this compatibility is no longer tested and this configuration should be considered deprecated.
5.98.1.4. Changes for Developers
5.98.2. Slave
5.98.2.1. Features
5.98.2.2. Fixes
5.98.2.3. Deprecations, Removals, and Non-Compatible Changes
5.98.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b6..v0.9.0b7
5.99. Release Notes for Buildbot 0.9.0b6
The following are the release notes for Buildbot 0.9.0b6 This version was released on January 20, 2016.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.99.1. Master
5.99.1.1. Features
Builders ui page has improved tag filtering capabilities
Home page enhanced with the list of recent builds sorted by builder
IRCreporter has been partially ported to work on data api.
5.99.1.2. Fixes
better stability and reliability in the UI thanks to switch to buildbot data-module
fix irc
5.99.1.3. Changes for Developers
properties object is now directly present in build, and not in build_status. This should not change much unless you try to access your properties via step.build.build_status. Remember that with PropertiesMixin, you can access properties via getProperties on the steps, and on the builds objects.
Javascript Data Module is now integrated, which sets a definitive API for accessing buildbot data in angularJS UI.
5.99.2. Slave
5.99.2.1. Features
The
DockerLatentBuildSlaveimage attribute is now renderable (can take properties in account).The
DockerLatentBuildSlavesets environment variables describing how to connect to the master. Example dockerfiles can be found in https://github.com/buildbot/buildbot-contrib/tree/master/master/contrib/docker.
5.99.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b5..v0.9.0b6
5.100. Release Notes for Buildbot 0.9.0b5
The following are the release notes for Buildbot 0.9.0b5. This version was released on October 21, 2015.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.100.1. Master
This version addresses http://trac.buildbot.net/wiki/SecurityAlert090b4 by preventing dissemination of hook information via the web UI.
This also reverts the addition of the frontend data service in 0.9.0b4, as that contained many bugs. It will be re-landed in a subsequent release.
5.100.2. Slave
No changes.
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b4..0.9.0b5
5.101. Release Notes for Buildbot 0.9.0b4
The following are the release notes for Buildbot 0.9.0b4 This version was released on October 20, 2015.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.101.1. Master
This version is very similar to 0.9.0b3, re-released due to issues with PyPI uploads.
5.101.1.1. Changes for Developers
The data API’s
startConsumingmethod has been removed. Instead of calling this method with a data API path, callself.master.mq.startConsumingwith an appropriate message routing pattern.
5.101.2. Slave
No changes since 0.9.0b3.
5.101.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b3..v0.9.0b4
5.102. Release Notes for Buildbot 0.9.0b3
The following are the release notes for Buildbot 0.9.0b3. This version was released on October 18, 2015.
See Upgrading to Buildbot 0.9.0 for a guide to upgrading from 0.8.x to 0.9.x
5.102.1. Master
5.102.1.1. Features
The irc command
hellonow returns ‘Hello’ in a random language if invoked more than once.Triggerablenow accepts areasonparameter.GerritStatusPushnow accepts abuildersparameter.StatusPush callback now receives build results (success/failure/etc) with the
buildFinishedevent.There’s a new renderable type, Transform.
Buildbot now supports wamp as a mq backend. This allows to run a multi-master configuration. See MQ Specification.
5.102.1.2. Fixes
The
PyFlakesandPyLintsteps no longer parse output in Buildbot log headers (bug #3337).GerritChangeSourceis now less verbose by default, and has adebugoption to enable the logs.P4Sourceno longer relies on the perforce server time to poll for new changes.The commit message for a change from
P4Sourcenow matches what the user typed in.
5.102.1.3. Deprecations, Removals, and Non-Compatible Changes
The
buildbot.status.resultsmodule no longer exists and has been renamed tobuildbot.process.results.
5.102.2. Slave
5.102.2.1. Features
The Buildbot slave now includes the number of CPUs in the information it supplies to the master on connection. This value is autodetected, but can be overridden with the
--numcpusargument tobuildslave create-slave.
5.102.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b2..v0.9.0b3
5.103. Release Notes for Buildbot 0.9.0b2
The following are the release notes for Buildbot 0.9.0b2. Buildbot 0.9.0b2 was released on August, 2 2015.
5.103.1. Master
5.103.1.1. Features
Mercurial hook was updated and modernized. It is no longer necessary to fork. One can now extend PYTHONPATH via the hook configuration. Among others, it permits to use a buildbot virtualenv instead of installing buildbot in all the system. Added documentation inside the hook. Misc. clean-up and reorganization in order to make the code a bit more readable.
UI templates can now be customizable. You can provide html or jade overrides to the www plugins, to customize the UI
UI side bar is now fixed by default for large screens.
5.103.1.2. Fixes
Fix setup for missing www.hooks module
Fix setup to install only on recents version of pip (>=1.4). This prevents unexpected upgrade to nine from people who just use
pip install -U buildbotFix a crash in the git hook.
Add checks to enforce slavenames are identifiers.
5.103.1.3. Deprecations, Removals, and Non-Compatible Changes
5.103.1.4. Changes for Developers
The
BuilderConfignextSlavekeyword argument takes a callable. This callable now receivesBuildRequestinstance in its signature as 3rd parameter. For retro-compatibility, all callable taking only 2 parameters will still work.Data api provides a way to query the build list per slave.
Data api provides a way to query some build properties in a build list.
5.103.2. Slave
buildbot-slavenow requires Python 2.6
5.103.2.1. Features
Schedulers: the
codebasesparameter can now be specified in a simple list-of-strings form.
5.103.2.2. Fixes
Fix two race conditions in the integration tests
5.103.2.3. Deprecations, Removals, and Non-Compatible Changes
Providing Latent AWS EC2 credentials by the
.ec2/aws_idfile is deprecated: Use the standard.aws/credentialsfile, instead.
5.103.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.9.0b1..v0.9.0b2
5.104. Release Notes for Buildbot 0.9.0b1
The following are the release notes for Buildbot 0.9.0b1. Buildbot 0.9.0b1 was released on the 25th of June, 2015.
5.104.1. Master
This version represents a refactoring of Buildbot into a consistent, well-defined application composed of loosely coupled components. The components are linked by a common database backend and a messaging system. This allows components to be distributed across multiple build masters. It also allows the rendering of complex web status views to be performed in the browser, rather than on the buildmasters.
The branch looks forward to committing to long-term API compatibility, but does not reach that goal. The Buildbot-0.9.x series of releases will give the new APIs time to “settle in” before we commit to them. Commitment will wait for Buildbot-1.0.0 (as per http://semver.org). Once Buildbot reaches version 1.0.0, upgrades will become much easier for users.
To encourage contributions from a wider field of developers, the web application is designed to look like a normal AngularJS application. Developers familiar with AngularJS, but not with Python, should be able to start hacking on the web application quickly. The web application is “pluggable”, so users who develop their own status displays can package those separately from Buildbot itself.
Other goals:
An approachable HTTP REST API, used by the web application but available for any other purpose.
A high degree of coverage by reliable, easily-modified tests.
“Interlocking” tests to guarantee compatibility. For example, the real and fake DB implementations must both pass the same suite of tests. Then no unseen difference between the fake and real implementations can mask errors that will occur in production.
5.104.1.1. Requirements
The buildbot package requires Python 2.6 or higher – Python 2.5 is no longer supported.
The buildbot-slave package requires Python 2.5 or higher – Python 2.4 is no longer supported.
No additional software or systems, aside from some minor Python packages, are required.
But the devil is in the details:
If you want to do web development, or build the
buildbot-wwwpackage, you’ll need Node. It’s an Angular app, and that’s how such apps are developed. We’ve taken pains to not make either a requirement for users - you can simply ‘pip install’buildbot-wwwand be on your way. This is the case even if you’re hacking on the Python side of Buildbot.For a single master, nothing else is required.
Minor Python Packages
Buildbot requires at least Twisted-11.0.0.
Buildbot works python-dateutil >= 1.5
5.104.1.2. Known Limitations of 0.9.0b1
The following feature will be implemented for Buildbot 0.9.1 Milestone.
Multimaster is not supported as of Buildbot 0.9.0.
Not all status plugin are converted to the new reporter API. Only email and Gerrit reporters are fully supported. Irc support is limited, and not converted to reporter api
5.104.1.3. Features
Buildbot-0.9.0 introduces the Data API, a consistent and scalable method for accessing and updating the state of the Buildbot system. This API replaces the existing, ill-defined Status API, which has been removed. Buildbot-0.9.0 introduces new WWW Server Interface using websocket for realtime updates. Buildbot code that interacted with the Status API (a substantial portion!) has been rewritten to use the Data API. Individual features and improvements to the Data API are not described on this page.
Buildbot now supports plugins. They allow Buildbot to be extended by using components distributed independently from the main code. They also provide for a unified way to access all components. When previously the following construction was used:
from buildbot.kind.other.bits import ComponentClass ... ComponentClass ...
the following construction achieves the same result:
from buildbot.plugins import kind ... kind.ComponentClass ...
Kinds of components that are available this way are described in Plugin Infrastructure in Buildbot.
Note
While the components can be still directly imported as
buildbot.kind.other.bits, this might not be the case after Buildbot v1.0 is released.Both the P4 source step and P4 change source support ticket-based authentication.
OpenStack latent slaves now support block devices as a bootable volume.
Add new
Cppcheckstep.Add a new Docker latent BuildSlave.
Add a new configuration for creating custom services in out-of-tree CI systems or plugins. See
buildbot.util.service.BuildbotServiceAdd
try_sshconfiguration file setting and--sshcommand line option for the try tool to specify the command to use for connecting to the build master.GitHub change hook now supports application/json format.
Add support for dynamically adding steps during a build. See Dynamic Build Factories.
GitPollernow supports detecting new branchesGitsupports an “origin” option to give a name to the remote repo.
5.104.1.4. Reporters
Status plugins have been moved into the reporters namespace.
Their API has slightly to changed in order to adapt to the new data API.
See respective documentation for details.
GerritStatusPushrenamed toGerritStatusPushMailNotifierrenamed toMailNotifierMailNotifierargumentmessageFormattershould now be aMessageFormatter, due to removal of data api, custom message formatters need to be rewritten.MailNotifierargumentpreviousBuildGetteris not supported anymoreGerritsupports specifying an SSH identity file explicitly.Added StashStatusPush status hook for Atlassian Stash
MailNotifierno longer forces SSL 3.0 whenuseTlsis true.GerritStatusPushcallbacks slightly changed signature, and include a master reference instead of a status reference.GitHubStatusnow accepts acontextparameter to be passed to the GitHub Status API.Buildbot UI introduces branch new Authentication, and Authorizations framework.
Please look at their respective guide in WWW Server
5.104.1.5. Fixes
Buildbot is now compatible with SQLAlchemy 0.8 and higher, using the newly-released SQLAlchemy-Migrate.
The version check for SQLAlchemy-Migrate was fixed to accept more version string formats.
The
HTTPStepstep’s request parameters are now renderable.With Git(), force the updating submodules to ensure local changes by the build are overwritten. This both ensures more consistent builds and avoids errors when updating submodules.
Buildbot is now compatible with Gerrit v2.6 and higher.
To make this happen, the return result of
reviewCBandsummaryCBcallback has changed from(message, verified, review)
to
{'message': message, 'labels': {'label-name': value, ... } }
The implications are:
there are some differences in behaviour: only those labels that were provided will be updated
Gerrit server must be able to provide a version, if it can’t the
GerritStatusPushwill not work
Note
If you have an old style
reviewCBand/orsummaryCBimplemented, these will still work, however there could be more labels updated than anticipated.More detailed information is available in
GerritStatusPushsection.P4Source’sserver_tzparameter now works correctly.The
revlinkin changes produced by the Bitbucket hook now correctly includes thechanges/portion of the URL.PBChangeSource’s git hook https://github.com/buildbot/buildbot-contrib/tree/master/master/contrib/git_buildbot.py now supports git tagsA pushed git tag generates a change event with the
branchproperty equal to the tag name. To schedule builds based on buildbot tags, one could use something like this:c['schedulers'].append( SingleBranchScheduler(name='tags', change_filter=filter.ChangeFilter( branch_re='v[0-9]+\.[0-9]+\.[0-9]+(?:-pre|rc[0-9]+|p[0-9]+)?') treeStableTimer=None, builderNames=['tag_build']))
Missing “name” and “email” properties received from Gerrit are now handled properly
Fixed bug which made it impossible to specify the project when using the BitBucket dialect.
The
PyLintstep has been updated to understand newer output.Fixed SVN master-side source step: if a SVN operation fails, the repository end up in a situation when a manual intervention is required. Now if SVN reports such a situation during initial check, the checkout will be clobbered.
The build properties are now stored in the database in the
build_propertiestable.The list of changes in the build page now displays all the changes since the last successful build.
GitHub change hook now correctly responds to ping events.
buildbot.steps.httpsteps now correctly haveurlparameter renderableWhen no arguments are used
buildbot checkconfignow usesbuildbot.tacto locate the master config file.buildbot.util.flatten now correctly flattens arbitrarily nested lists. buildbot.util.flattened_iterator provides an iterable over the collection which may be more efficient for extremely large lists.
5.104.1.6. Deprecations, Removals, and Non-Compatible Changes
BonsaiPoller is removed.
buildbot.ec2buildslaveis removed; usebuildbot.buildslave.ec2instead.buildbot.libvirtbuildslaveis removed; usebuildbot.buildslave.libvirtinstead.
buildbot.util.flatten flattens lists and tuples by default (previously only lists). Additionally, flattening something that isn’t the type to flatten has different behaviour. Previously, it would return the original value. Instead, it now returns an array with the original value as the sole element.
buildbot.tacdoes not supportprintstatements anymore. Such files should now useprintas a function instead (see https://docs.python.org/3.0/whatsnew/3.0.html#print-is-a-function for more details). Note that this applies to both python2.x and python3.x runtimes.
WebStatus
The old, clunky WebStatus has been removed. You will like the new interface! RIP WebStatus, you were a good friend.
remove it and replace it with www configuration.
Requirements
Buildbot’s tests now require at least Mock-0.8.0.
SQLAlchemy-Migrate-0.6.1 is no longer supported.
Builder names are now restricted to unicode strings or ASCII bytestrings. Encoded bytestrings are not accepted.
Steps
New-style steps are now the norm, and support for old-style steps is deprecated. Such support will be removed in the next release.
Status strings for old-style steps could be supplied through a wide variety of conflicting means (
describe,description,descriptionDone,descriptionSuffix,getText, andsetText, to name just a few). While all attempts have been made to maintain compatibility, you may find that the status strings for old-style steps have changed in this version. To fix steps that callsetText, try setting thedescriptionDoneattribute directly, instead – or just rewrite the step in the new style.
Old-style source steps (imported directly from
buildbot.steps.source) are no longer supported on the master.The monotone source step got an overhaul and can now better manage its database (initialize and/or migrate it, if needed). In the spirit of monotone, buildbot now always keeps the database around, as it’s an append-only database.
Changes and Removals
Buildslave names must now be 50-character identifier. Note that this disallows some common characters in bulidslave names, including spaces,
/, and..Builders now have “tags” instead of a category. Builders can have multiple tags, allowing more flexible builder displays.
ForceSchedulerhas the following changes:The default configuration no longer contains four
AnyPropertyParameterinstances.Configuring
codebasesis now mandatory, and the deprecatedbranch,repository,project,revisionare not supported anymore inForceSchedulerbuildbot.schedulers.forcesched.BaseParameter.updateFromKwargsnow takes acollectorparameter used to collect all validation errors
Periodic,NightlyandNightlyTriggerablehave the following changes:Logs are now stored as Unicode strings, and thus must be decoded properly from the bytestrings provided by shell commands. By default this encoding is assumed to be UTF-8, but the
logEncodingparameter can be used to select an alternative. Steps and individual logfiles can also override the global default.The PB status service uses classes which have now been removed, and anyway is redundant to the REST API, so it has been removed. It has taken the following with it:
buildbot statuslogbuildbot statusgui(the GTK client)buildbot debugclient
The
PBListenerstatus listener is now deprecated and does nothing. Accordingly, there is no external access to status objects via Perspective Broker, aside from some compatibility code for the try scheduler.The
debugPasswordconfiguration option is no longer needed and is thus deprecated.The undocumented and un-tested
TinderboxMailNotifier, designed to send emails suitable for the abandoned and insecure Tinderbox tool, has been removed.Buildslave info is no longer available via Interpolate and the
SetSlaveInfobuildstep has been removed.The undocumented
pathparameter of theMasterShellCommandbuildstep has been renamedworkdirfor better consistency with the other steps.The name and source of a Property have to be unicode or ascii string.
Property values must be serializable in JSON.
IRChas the following changes:categories parameter is deprecated and removed. It should be replaced with tags=[cat]
noticeOnChannel parameter is deprecated and removed.
workdir behavior has been unified:
workdirattribute of steps is now a property inBuildStep, and choose the workdir given following priority:workdir of the step, if defined
workdir of the builder (itself defaults to ‘build’)
setDefaultWorkdir() has been deprecated, but is now behaving the same for all the steps: Setting self.workdir if not already set
Triggernow has agetSchedulersAndPropertiesmethod that can ve overridden to support dynamic triggering.`master.cfgis now parsed from a thread. Previously it was run in the main thread, and thus slowing down the master in case of big config, or network access done to generate the config.SVNPoller’s svnurl parameter has been changed to repourl.
5.104.1.7. Changes for Developers
Botmaster no longer service parent for buildslaves. Service parent functionality has been transferred to BuildslaveManager. It should be noted Botmaster no longer has a
slavesfield as it was moved to BuildslaveManager.The sourcestamp DB connector now returns a
patchidfield.Buildbot no longer polls the database for jobs. The
db_poll_intervalconfiguration parameter and thedbkey of the same name are deprecated and will be ignored.The interface for adding changes has changed. The new method is
master.data.updates.addChange(implemented byaddChange), although the old interface (master.addChange) will remain in place for a few versions. The new method:returns a change ID, not a Change instance;
takes its
when_timestampargument as epoch time (UNIX time), not a datetime instance; anddoes not accept the deprecated parameters
who,isdir,is_dir, andwhen.requires that all strings be unicode, not bytestrings.
Please adjust any custom change sources accordingly.
A new build status, CANCELLED, has been added. It is used when a step or build is deliberately cancelled by a user.
This upgrade will delete all rows from the
buildrequest_claimstable. If you are using this table for analytical purposes outside of Buildbot, please back up its contents before the upgrade, and restore it afterward, translating object IDs to scheduler IDs if necessary. This translation would be very slow and is not required for most users, so it is not done automatically.All of the schedulers DB API methods now accept a schedulerid, rather than an objectid. If you have custom code using these methods, check your code and make the necessary adjustments.
The
addBuildsetForSourceStampmethod has becomeaddBuildsetForSourceStamps, and its signature has changed. TheaddBuildsetForSourceStampSetDetailsmethod has becomeaddBuildsetForSourceStampsWithDefaults, and its signature has changed. TheaddBuildsetForSourceStampDetailsmethod has been removed. TheaddBuildsetForLatestmethod has been removed. It is equivalent toaddBuildsetForSourceStampDetailswithsourcestamps=None. These methods are not yet documented, and their interface is not stable. Consult the source code for details on the changes.The
preStartConsumingChangesandstartTimedSchedulerServicehooks have been removed.The triggerable schedulers’
triggermethod now requires a list of sourcestamps, rather than a dictionary.The
SourceStampclass is no longer used. It remains in the codebase to support loading data from pickles on upgrade, but should not be used in running code.The
BuildRequestclass no longer has fullsourceorsourcesattributes. Use the data API to get this information (which is associated with the buildset, not the build request) instead.The undocumented
BuilderControlmethodsubmitBuildRequesthas been removed.The debug client no longer supports requesting builds (the
requestBuildmethod has been removed). If you have been using this method in production, consider instead creating a new change source, using theForceScheduler, or using one of the try schedulers.The
buildbot.misc.SerializedInvocationclass has been removed; usebuildbot.util.debounce.methodinstead.The
progressattributes of bothbuildbot.process.buildstep.BuildStepandbuildbot.process.build.Buildhave been removed. Subclasses should only be accessing the progress-tracking mechanics via thebuildbot.process.buildstep.BuildStep.setProgressmethod.
5.104.2. Slave
5.104.2.1. Features
5.104.2.2. Fixes
5.104.2.3. Deprecations, Removals, and Non-Compatible Changes
buildmaster and buildslave no longer supports old-style source steps.
On Windows, if a
ShellCommandstep in whichcommandwas specified as a list is executed, and a list element is a string consisting of a single pipe character, it no longer creates a pipeline. Instead, the pipe character is passed verbatim as an argument to the program, like any other string. This makes command handling consistent between Windows and Unix-like systems. To have a pipeline, specifycommandas a string.
5.104.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.8.10..v0.9.0b1
5.105. Release Notes for Buildbot 0.8.11
The following are the release notes for Buildbot 0.8.11. This version was released on the 20th of April, 2015.
5.105.1. Master
Requirements:
Buildbot works python-dateutil >= 1.5
5.105.1.1. Features
GitHub change hook now supports application/json format.
Buildbot is now compatible with Gerrit v2.6 and higher.
To make this happen, the return result of
reviewCBandsummaryCBcallback has changed from(message, verified, review)
to
{'message': message, 'labels': {'label-name': value, ... } }
The implications are:
there are some differences in behaviour: only those labels that were provided will be updated
Gerrit server must be able to provide a version, if it can’t the
GerritStatusPushwill not work
Note
If you have an old style
reviewCBand/orsummaryCBimplemented, these will still work, however there could be more labels updated than anticipated.More detailed information is available in
GerritStatusPushsection.Buildbot now supports plugins. They allow Buildbot to be extended by using components distributed independently from the main code. They also provide for a unified way to access all components. When previously the following construction was used:
from buildbot.kind.other.bits import ComponentClass ... ComponentClass ...
the following construction achieves the same result:
from buildbot.plugins import kind ... kind.ComponentClass ...
Kinds of components that are available this way are described in Plugin Infrastructure in Buildbot.
Note
While the components can be still directly imported as
buildbot.kind.other.bits, this might not be the case after Buildbot v1.0 is released.GitPollernow supports detecting new branchesMasterShellCommandnow renders thepathargument.ShellMixin: theworkdircan now be overridden in the call tomakeRemoteShellCommand.GitHub status target now allows to specify a different base URL for the API (usefule for GitHub enterprise installations). This feature requires txgithub of version 0.2.0 or better.
GitHub change hook now supports payload validation using shared secret, see the GitHub hook documentation for details.
Added StashStatusPush status hook for Atlassian Stash
Builders can now have multiple “tags” associated with them. Tags can be used in various status classes as filters (eg, on the waterfall page).
MailNotifierno longer forces SSL 3.0 whenuseTlsis true.GitHub change hook now supports function as codebase argument.
GitHub change hook now supports pull_request events.
Trigger: thegetSchedulersAndPropertiescustomization method has been backported from Nine. This provides a way to dynamically specify which schedulers (and the properties for that scheduler) to trigger at runtime.
5.105.1.2. Fixes
GitHub change hook now correctly responds to ping events.
buildbot.steps.httpsteps now correctly haveurlparameter renderableMasterShellCommandnow correctly logs the working directory where it was run.With Git(), force the updating submodules to ensure local changes by the build are overwritten. This both ensures more consistent builds and avoids errors when updating submodules.
With Git(), make sure ‘git submodule sync’ is called before ‘git submodule update’ to update stale remote urls (bug #2155).
5.105.1.3. Deprecations, Removals, and Non-Compatible Changes
The builder parameter “category” is deprecated and is replaced by a parameter called “tags”.
5.105.1.4. Changes for Developers
Trigger:createTriggerPropertiesnow takes one argument (the properties to generate).Trigger:getSchedulersmethod is no longer used and was removed.
5.105.2. Slave
5.105.2.1. Features
5.105.2.2. Fixes
5.105.2.3. Deprecations, Removals, and Non-Compatible Changes
5.105.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.8.10..532cf49
5.106. Release Notes for Buildbot 0.8.10
The following are the release notes for Buildbot 0.8.10. Buildbot 0.8.10 was released on the 2nd of December, 2014.
5.106.1. Master
5.106.1.1. Features
Both the P4 source step and P4 change source support ticket-based authentication.
Clickable ‘categories’ links added in ‘Waterfall’ page (web UI).
5.106.1.2. Fixes
Buildbot is now compatible with SQLAlchemy 0.8 and higher, using the newly-released SQLAlchemy-Migrate.
The
HTTPStepstep’s request parameters are now renderable.Fixed content spoofing vulnerabilities (bug #2589).
Fixed cross-site scripting in status_json (bug #2943).
GerritStatusPushsupports specifying an SSH identity file explicitly.Fixed bug which made it impossible to specify the project when using the BitBucket dialect.
Fixed SVN master-side source step: if a SVN operation fails, the repository end up in a situation when a manual intervention is required. Now if SVN reports such a situation during initial check, the checkout will be clobbered.
Fixed master-side source steps to respect the specified timeout when removing files.
5.106.1.3. Deprecations, Removals, and Non-Compatible Changes
5.106.1.4. Changes for Developers
5.106.2. Slave
5.106.2.1. Features
5.106.2.2. Fixes
5.106.2.3. Deprecations, Removals, and Non-Compatible Changes
5.106.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.8.9..eight
5.107. Release Notes for Buildbot 0.8.9
The following are the release notes for Buildbot 0.8.9. Buildbot 0.8.9 was released on 14 June, 2014.
5.107.1. Master
5.107.1.1. Features
- The following optional parameters have been added to
EC2LatentBuildSlave Boolean parameter
spot_instance, default False, creates a spot instance.Float parameter
max_spot_pricedefines the maximum bid for a spot instance.List parameter
volumes, takes a list of (volume_id, mount_point) tuples.String parameter
placementis appended to theregionparameter, e.g.region='us-west-2', placement='b'will result in the spot request being placed in us-west-2b.Float parameter
price_multiplierspecifies the percentage bid above the 24-hour average spot price.Dict parameter
tagsspecifies AWS tags as key/value pairs to be applied to new instances.
With
spot_instance=True, anEC2LatentBuildSlavewill attempt to create a spot instance with the provided spot price, placement, and so on.- The following optional parameters have been added to
The web hooks now include support for Bitbucket, GitLab and Gitorious.
The GitHub webhook has been updated to work with v3 of the GitHub webhook API.
The GitHub webhook can now optionally ignore non-distinct commits (bug #1861).
The
HgPollerandGitPollernow split filenames on newlines, rather than whitespace, so files containing whitespace are handled correctly.Add ‘pollAtLaunch’ flag for polling change sources. This allows a poller to poll immediately on launch and get changes that occurred while it was down.
Added the
BitbucketPullrequestPollerchangesource.The
GitPollercan now be configured to poll all available branches (pull request 1010).The
P4Sourcechangesource now supports Perforce servers in a different timezone than the buildbot master (pull request 728).Each Scheduler type can now take a ‘reason’ argument to customize the reason it uses for triggered builds.
A new argument
createAbsoluteSourceStampshas been added toSingleBranchSchedulerfor use with multiple codebases.A new argument
createAbsoluteSourceStampshas been added toNightlyfor use with multiple codebases.The
Periodicscheduler now supports codebases.The
ForceSchedulernow takes abuttonNameargument to specify the name of the button on the force-build form.Master side source checkout steps now support patches (bug #2098). The
GitandMercurialsteps use their inbuilt commands to apply patches (bug #2563).Master side source checkout steps now support retry option (bug #2465).
Master-side source checkout steps now respond to the “stop build” button (bug #2356).
Gitsource checkout step now supports reference repositories.The
Gitstep now uses the git clean option -f twice, to also remove untracked directories managed by another git repository. See bug #2560.The
branchandcodebasearguments to theGitstep are now renderable.Gerrit integration with
GitSource step on master side (bug #2485).P4source step now supports more advanced options.The master-side
SVNstep now supports authentication for mode=export, fixing bug #2463.The
SVNstep will now canonicalize URL’s before matching them for better accuracy.The
SVNstep now obfuscates the password in status logs, fixing bug #2468.SVNsource step and ShellCommand now support password obfuscation. (bug #2468 and bug #1748).CVSsource step now checks for “sticky dates” from a previous checkout before updating an existing source directory.:
Reponow supports adepthflag when initializing the repo. This controls the amount of git history to download.The
manifestBranchof the bb:step:Repo step is now renderableNew source step
Monotoneadded on master side.New source step
Darcsadded on master side.A new
Robocopystep is available for Windows builders (pull request 728).The attributes
description,descriptionDoneanddescriptionSuffixhave been moved fromShellCommandto its superclassBuildStepso that any class that inherits fromBuildStepcan provide a suitable description of itself.A new
FlattenListRenderable has been added which can flatten nested lists.The
modeparameter of the VS steps is now renderable (bug #2592).The
HTTPStepstep can make arbitrary HTTP requests from the master, allowing communication with external APIs. This new feature requires the optionaltxrequestsandrequestsPython packages.A new
MultipleFileUploadstep was added to allow uploading several files (or directories) in a single step.Information about the buildslaves (admin, host, etc) is now persisted in the database and available even if the slave is not connected.
Buildslave info can now be retrieved via Interpolate and a new
SetSlaveInfobuildstep.The
GNUAutotoolsfactory now has a reconf option to run autoreconf before./configure.Builder configurations can now include a
description, which will appear in the web UI to help humans figure out what the builder does.The WebStatus builder page can now filter pending/current/finished builds by property parameters of the form
?property.<name>=<value>.The WebStatus
StatusResourceBuilderpage can now take themaxsearchargumentThe WebStatus has a new authz “view” action that allows you to require users to logged in to view the WebStatus.
The WebStatus now shows revisions (+ codebase) where it used to simply say “multiple rev”.
The Console view now supports codebases.
- The web UI for Builders has been updated:
shows the build ‘reason’ and ‘interested users’
shows sourcestamp information for builders that use multiple codebases (instead of the generic “multiple rev” placeholder that was shown before).
The waterfall and atom/rss feeds can be filtered with the
projecturl parameter.The WebStatus
Authorizationsupport now includes aviewaction which can be used to restrict read-only access to the Buildbot instance.The web status now has options to cancel some or all pending builds.
The WebStatus now interprets ANSI color codes in stdio output.
It is now possible to select categories to show in the waterfall help
The web status now automatically scrolls output logs (pull request 1078).
The web UI now supports a PNG Status Resource that can be accessed publicly from for example README.md files or wikis or whatever other resource. This view produces an image in PNG format with information about the last build for the given builder name or whatever other build number if is passed as an argument to the view.
Revision links for commits on SouceForge (Allura) are now automatically generated.
The ‘Rebuild’ button on the web pages for builds features a dropdown to choose whether to rebuild from exact revisions or from the same sourcestamps (ie, update branch references)
Build status can be sent to GitHub. Depends on txgithub package. See
GitHubStatusPushand GitHub Commit Status.The IRC bot of
IRCwill, unless useRevisions is set, shorten long lists of revisions printed when a build starts; it will only show two, and the number of additional revisions included in the build.A new argument
summaryCBhas been added toGerritStatusPush, to allow sending one review per buildset. Sending a single “summary” review per buildset is now the default if neithersummaryCBnorreviewCBare specified.The
commentsfield of changes is no longer limited to 1024 characters on MySQL and Postgres. See bug #2367 and pull request 736.HTML log files are no longer stored in status pickles (pull request 1077)
Builds are now retried after a slave is lost (pull request 1049).
The buildbot status client can now access a build properties via the
getPropertiescall.The
start,restart, andreconfigcommands will now wait for longer than 10 seconds as long as the master continues producing log lines indicating that the configuration is progressing.Added new config option
protocolswhich allows to configure multiple protocols on single master.RemoteShellCommands can be killed by SIGTERM with the sigtermTime parameter before resorting to SIGKILL (bug #751). If the slave’s version is less than 0.8.9, the slave will kill the process with SIGKILL regardless of whether sigtermTime is supplied.
Introduce an alternative way to deploy Buildbot and try the pyflakes tutorial using Docker.
Added zsh and bash tab-completions support for ‘buildbot’ command.
An example of a declarative configuration is included in
master/contrib/SimpleConfig.py, with copious comments.Systemd unit files for Buildbot are available in the https://github.com/buildbot/buildbot-contrib/tree/master/master/contrib/ directory.
We’ve added some extra checking to make sure that you have a valid locale before starting buildbot (#2608).
5.107.1.2. Forward Compatibility
In preparation for a more asynchronous implementation of build steps in Buildbot 0.9.0, this version introduces support for new-style steps. Existing old-style steps will continue to function correctly in Buildbot 0.8.x releases and in Buildbot 0.9.0, but support will be dropped soon afterward. See New-Style Build Steps in Buildbot 0.9.0, below, for guidance on rewriting existing steps in this new style. To eliminate ambiguity, the documentation for this version only reflects support for new-style steps. Refer to the documentation for previous versions for information on old-style steps.
5.107.1.3. Fixes
Fixes an issue where
GitPollersets the change branch torefs/heads/master- which isn’t compatible withGit(pull request 1069).Fixed an issue where the
GitandCVSsource steps silently changed theworkdirto'build'when the ‘copy’ method is used.The
CVSsource step now respects the timeout parameter.The
Gitstep now uses the git submodule update option –init when updating the submodules of an existing repository, so that it will receive any newly added submodules.The web status no longer relies on the current working directory, which is not set correctly by some initscripts, to find the
templates/directory (bug #2586).The Perforce source step uses the correct path separator when the master is on Windows and the build slave is on a POSIX OS (pull request 1114).
The source steps now correctly interpolate properties in
env.GerritStatusPushnow supports setting scores with Gerrit 2.6 and newerThe change hook no longer fails when passing unicode to
change_hook_auth(pull request 996).The source steps now correctly interpolate properties in
env.Whitespace is properly handled for StringParameter, so that appropriate validation errors are raised for
requiredparameters (pull request 1084).Fix a rare case where a buildtep might fail from a GeneratorExit exception (pull request 1063).
Fixed an issue where UTF-8 data in logs caused RSS feed exceptions (bug #951).
Fix an issue with unescaped author names causing invalid RSS feeds (bug #2596).
Fixed an issue with pubDate format in feeds.
Fixed an issue where the step text value could cause a
TypeErrorin the build detail page (pull request 1061).Fix failures where
git cleanfails but could be clobbered (pull request 1058).Build step now correctly fails when the git clone step fails (pull request 1057).
Fixed a race condition in slave shutdown (pull request 1019).
Now correctly unsubscribes StatusPush from status updates when reconfiguring (pull request 997).
Fixes parsing git commit messages that are blank.
Gitno longer fails when work dir exists but isn’t a checkout (bug #2531).The haltOnFailure and flunkOnFailure attributes of
ShellCommandare now renderable. (bug #2486).The rotateLength and maxRotatedFile arguments are no longer treated as strings in
buildbot.tac. This fixes log rotation. The upgrade_master command will notify users if they have this problem.Buildbot no longer specifies a revision when pulling from a mercurial (bug #438).
The WebStatus no longer incorrectly refers to fields that might not be visible.
The GerritChangeSource now sets a default author, fixing an exception that occurred when Gerrit didn’t report an owner name/email.
Respects the
RETRYstatus when an interrupt occurs.Fixes an off-by-one error when the tryclient is finding the current git branch.
Improve the Mercurial source stamp extraction in the try client.
Fixes some edge cases in timezone handling for python <
2.7.4(bug #2522).The
EC2LatentBuildSlavewill now only consider available AMI’s.Fixes a case where the first build runs on an old slave instead of a new one after reconfig (bug #2507).
The e-mail address validation for the MailNotifier status receiver has been improved.
The
--dbparameter ofbuildbot create-masteris now validated.No longer ignores default choice for ForceScheduler list parameters
Now correctly handles
BuilderConfig(..., mergeRequests=False)(bug #2555).Now excludes changes from sourcestamps when they aren’t in the DB (bug #2554).
Fixes a compatibility issue with HPCloud in the OpenStack latent slave.
Allow
_as a valid character in JSONP callback names.Fix build start time retrieval in the WebStatus grid view.
Increase the length of the DB fields
changes.commentsandbuildset_properties.property_value.
5.107.1.4. Deprecations, Removals, and Non-Compatible Changes
The slave-side source steps are deprecated in this version of Buildbot, and master-side support will be removed in a future version. Please convert any use of slave-side steps (imported directly from
buildbot.steps.source, rather than from a specific module likebuildbot.steps.source.svn) to use master-side steps.Both old-style and new-style steps are supported in this version of Buildbot. Upgrade your steps to new-style now, as support for old-style steps will be dropped after Buildbot-0.9.0. See New-Style Build Steps in Buildbot 0.9.0 for details.
The
LoggingBuildStepclass has been deprecated, and support will be removed along with support for old-style steps after the Buildbot-0.9.0 release. Instead, subclassBuildStepand mix inShellMixinto get similar behavior.
slavePortnumoption deprecated, please usec['protocols']['pb']['port']to set up PB portThe
buildbot.process.mtrlogobservermodule have been renamed tobuildbot.steps.mtrlogobserver.The buildmaster now requires at least Twisted-11.0.0.
The buildmaster now requires at least sqlalchemy-migrate 0.6.1.
The
hgbuildbotMercurial hook has been moved tocontrib/, and does not work with recent versions of Mercurial and Twisted. The runtimes for these two tools are incompatible, yethgbuildbotattempts to run both in the same Python interpreter. Mayhem ensues.The try scheduler’s
--connect=sshmethod no longer supports waiting for results (--wait).The former
buildbot.process.buildstep.RemoteCommandclass and its subclasses are now inbuildbot.process.remotecommand, although imports from the previous path will continue to work. Similarly, the formerbuildbot.process.buildstep.LogObserverclass and its subclasses are now inbuildbot.process.logobserver, although imports from the previous path will continue to work.The undocumented BuildStep method
checkDisconnectis deprecated and now does nothing as the handling of disconnects is now handled in thefailedmethod. Any custom steps adding this method as a callback or errback should no longer do so.The build step
MsBuildis now calledMsBuild4as multiple versions are now supported. An alias is provided so existing setups will continue to work, but this will be removed in a future release.
5.107.1.5. Changes for Developers
The
CompositeStepMixinnow provides arunGlobmethod to check for files on the slave that match a given shell-style pattern.The
BuilderStatusnow allows you to pass afilter_fnargument togenerateBuilds.
5.107.2. Slave
5.107.2.1. Features
Added zsh and bash tab-completions support for ‘buildslave’ command.
RemoteShellCommands accept the new sigtermTime parameter from master. This allows processes to be killed by SIGTERM before resorting to SIGKILL (bug #751)
Commands will now throw a
ValueErrorif mandatory args are not present.Added a new remote command
GlobPaththat can be used to call Python’sglob.globon the slave.
5.107.2.2. Fixes
Fixed an issue when buildstep stop() was raising an exception incorrectly if timeout for buildstep wasn’t set or was None (see pull request 753) thus keeping watched logfiles open (this prevented their removal on Windows in subsequent builds).
Fixed a bug in P4 source step where the
timeoutparameter was ignored.Fixed a bug in P4 source step where using a custom view-spec could result in failed syncs due to incorrectly generated command-lines.
The logwatcher will use
/usr/xpg4/bin/tailon Solaris, it if is available (pull request 1065).
5.107.2.3. Deprecations, Removals, and Non-Compatible Changes
5.107.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.8.8..v0.8.9
5.108. Release Notes for Buildbot v0.8.8
The following are the release notes for Buildbot v0.8.8 Buildbot v0.8.8 was released on August 22, 2013
5.108.1. Master
5.108.1.1. Features
The
MasterShellCommandstep now correctly handles environment variables passed as list.The master now poll the database for pending tasks when running buildbot in multi-master mode.
The algorithm to match build requests to slaves has been rewritten pull request 615. The new algorithm automatically takes locks into account, and will not schedule a build only to have it wait on a lock. The algorithm also introduces a
canStartBuildbuilder configuration option which can be used to prevent a build request being assigned to a slave.buildbot stopandbuildbot restartnow accept--cleanto stop or restart the master cleanly (allowing all running builds to complete first).The
IRCbot now supports clean shutdown and immediate shutdown by using the command ‘shutdown’. To allow the command to function, you must provide allowShutdown=True.CopyDirectoryhas been added.BuildslaveChoiceParameterhas been added to provide a way to explicitly choose a buildslave for a given build.default.css now wraps preformatted text by default.
Slaves can now be paused through the web status.
The latent buildslave support is less buggy, thanks pull request 646.
The
treeStableTimerforAnyBranchSchedulernow maintains separate timers for separate branches, codebases, projects, and repositories.SVNhas a new option preferLastChangedRev=True to use the last changed revision forgot_revisionThe build request DB connector method
getBuildRequestscan now filter by branch and repository.A new
SetPropertystep has been added inbuildbot.steps.masterwhich can set a property directly without accessing the slave.The new
LogRenderablestep logs Python objects, which can contain renderables, to the logfile. This is helpful for debugging property values during a build.‘buildbot try’ now has an additional option –property option to set properties. Unlike the existing option –properties option, this new option supports setting only a single property and therefore allows commas to be included in the property name and value.
The
Gitstep has a newconfigoption, which accepts a dict of git configuration options to pass to the low-level git commands. SeeGitfor details.In
ShellCommandShellCommand now validates its arguments during config and will identify any invalid arguments before a build is started.The list of force schedulers in the web UI is now sorted by name.
OpenStack-based Latent Buildslave support was added. See pull request 666.
Master-side support for P4 is available, and provides a great deal more flexibility than the old slave-side step. See pull request 596.
Master-side support for Repo is available. The step parameters changed to camelCase.
repo_downloads, andmanifest_override_urlproperties are no longer hardcoded, but instead consult as default values via renderables. Renderable are used in favor of callables forsyncAllBranchesandupdateTarball.Builder configurations can now include a
description, which will appear in the web UI to help humans figure out what the builder does.GNUAutoconf and other pre-defined factories now work correctly (bug #2402)
The pubDate in RSS feeds is now rendered correctly (bug #2530)
5.108.1.2. Deprecations, Removals, and Non-Compatible Changes
The
split_filefunction forSVNPollermay now return a dictionary instead of a tuple. This allows it to add extra information about a change (such asprojectorrepository).The
workdirbuild property has been renamed tobuilddir. This change accurately reflects its content; the term “workdir” means something different.workdiris currently still supported for backwards compatibility, but will be removed eventually.The
Blockerstep has been removed.Several polling ChangeSources are now documented to take a
pollIntervalargument, instead ofpollinterval. The old name is still supported.StatusReceivers’ checkConfig method should no longer take an errors parameter. It should indicate errors by calling
error.Build steps now require that their name be a string. Previously, they would accept anything, but not behave appropriately.
The web status no longer displays a potentially misleading message, indicating whether the build can be rebuilt exactly.
The
SetPropertystep inbuildbot.steps.shellhas been renamed toSetPropertyFromCommand.The EC2 and libvirt latent slaves have been moved to
buildbot.buildslave.ec2andbuildbot.buildslave.libirtrespectively.Pre v0.8.7 versions of buildbot supported passing keyword arguments to
buildbot.process.BuildFactory.addStep, but this was dropped. Support was added again, while still being deprecated, to ease transition.
5.108.1.3. Changes for Developers
Added an optional build start callback to
buildbot.status.status_gerrit.GerritStatusPushThis release includes the fix for bug #2536.An optional
startCBcallback toGerritStatusPushcan be used to send a message back to the committer. See the linked documentation for details.bb:sched:ChoiceStringParameter has a new method
getChoicesthat can be used to generate content dynamically for Force scheduler forms.
5.108.2. Slave
5.108.2.1. Features
The fix for Twisted bug #5079 is now applied on the slave side, too. This fixes a perspective broker memory leak in older versions of Twisted. This fix was added on the master in Buildbot-0.8.4 (see bug #1958).
The
--nodaemonoption tobuildslave startnow correctly prevents the slave from forking before running.
5.108.2.2. Deprecations, Removals, and Non-Compatible Changes
5.108.3. Details
For a more detailed description of the changes made in this version, see the git log itself:
git log v0.8.7..v0.8.8
5.109. Release Notes for Buildbot v0.8.7
The following are the release notes for Buildbot v0.8.7. Buildbot v0.8.7 was released on September 22, 2012. Buildbot 0.8.7p1 was released on November 21, 2012.
5.109.1. 0.8.7p1
In addition to what’s listed below, the 0.8.7p1 release adds the following.
The
SetPropertiesFromEnvstep now correctly gets environment variables from the slave, rather than those set on the master. Also, it logs the changes made to properties.The master-side
Gitsource step now doesn’t try to clone a branch calledHEAD. This is whatgitdoes by default, and specifying it explicitly doesn’t work as expected.The
Gitstep properly deals with the case when there is a file calledFETCH_HEADin the checkout.Buildbot no longer forks when told not to daemonize.
Buildbot’s startup is now more robust. See bug #1992.
The
Triggerstep uses the provided list of source stamps exactly, if given, instead of adding them to the sourcestamps of the current build. In 0.8.7, they were combined with the source stamps for the current build.The
Triggerstep again completely ignores the source stamp of the current build, ifalwaysUseLatestis set. In 0.8.7, this was mistakenly changed to only ignore the specified revision of the source stamp.The
Triggerablescheduler is again properly passing changes through to the scheduled builds. See bug #2376.Web change hooks log errors, allowing debugging.
The
basechange hook now properly decodes the provided date.CVSMailDirhas been fixed.Importing
buildbot.testno longer causes python to exit, ifmockisn’t installed. The fixespydoc -kwhen buildbot is installed.Mercurialproperly updates to the correct branch, when usinginrepobranches.Buildbot now doesn’t fail on invalid UTF-8 in a number of places.
Many documentation updates and fixes.
5.109.2. Master
5.109.2.1. Features
Buildbot now supports building projects composed of multiple codebases. New schedulers can aggregate changes to multiple codebases into source stamp sets (with one source stamp for each codebase). Source steps then check out each codebase as required, and the remainder of the build process proceeds normally. See the Multiple-Codebase Builds for details.
The format of the
got_revisionproperty has changed for multi-codebase builds. It is now a dictionary keyed by codebase.
SourceandShellCommandsteps now have an optionaldescriptionSuffix, a suffix to thedescription/descriptionDonevalues. For example this can help distinguish between multipleCompilesteps that are applied to different codebases.The
Gitstep has a newgetDescriptionoption, which will rungit describeafter checkout normally. SeeGitfor details.A new interpolation placeholder Interpolate, with more regular syntax, is available.
A new ternary substitution operator
:?and:#?is available with theInterpolateclass.IRenderable.getRenderingForcan now return a deferred.The Mercurial hook now supports multiple masters. See pull request 436.
There’s a new poller for Mercurial:
HgPoller.The new
HTPasswdAprAuthuses libaprutil (through ctypes) to validate the password against the hash from the .htpasswd file. This adds support for all hash types htpasswd can generate.GitPollerhas been rewritten. It now supports multiple branches and can share a directory between multiple pollers. It is also more resilient to changes in configuration, or in the underlying repository.Added a new property
httpLoginUrltobuildbot.status.web.authz.Authzto render a nice Login link in WebStatus for unauthenticated users ifuseHttpHeaderandhttpLoginUrlare set.ForceSchedulerhas been updated:support for multiple codebases via the
codebasesparameterNestedParameterto provide a logical grouping of parameters.CodebaseParameterto set the branch/revision/repository/project for a codebasenew HTML/CSS customization points. Each parameter is contained in a
rowwith multiple ‘class’ attributes associated with them (eg, ‘force-string’ and ‘force-nested’) as well as a unique id to use with Javascript. Explicit line-breaks have been removed from the HTML generator and are now controlled using CSS.
The
SVNPollernow supports multiple projects and codebases. See pull request 443.The
MailNotifiernow takes a callable to calculate the “previous” build for purposes of determining status changes. See pull request 489.The
copy_propertiesparameter, given a list of properties to copy into the new build request, has been deprecated in favor of explicit use ofset_properties.
5.109.2.2. Deprecations, Removals, and Non-Compatible Changes
Buildbot master now requires at least Python-2.5 and Twisted-9.0.0.
Passing a
BuildStepsubclass (rather than instance) toaddStepis no longer supported. TheaddStepmethod now takes exactly one argument.Buildbot master requires
python-dateutilversion 1.5 to support the Nightly scheduler.ForceSchedulerhas been updated to support multiple codebases. The branch/revision/repository/project are deprecated; if you have customized these values, simply provide them ascodebases=[CodebaseParameter(name='', ...)].The POST URL names for
AnyPropertyParameterfields have changed. For example, ‘property1name’ is now ‘property1_name’, and ‘property1value’ is now ‘property1_value’. Please update any bookmarked or saved URL’s that used these fields.forcesched.BaseParameterAPI has changed quite a bit and is no longer backwards compatible. Updating guidelines:get_from_postis renamed togetFromKwargsupdate_from_postis renamed toupdateFromKwargs. This function’s parameters are now called via named parameters to allow subclasses to ignore values it doesn’t use. Subclasses should add**unusedfor future compatibility. A new parametersourcestampsetis provided to allow subclasses to modify the sourcestamp set, and will probably require you to add the**unusedfield.
The parameters to the callable version of
build.workdirhave changed. Instead of a single sourcestamp, a list of sourcestamps is passed. Each sourcestamp in the list has a different codebaseThe undocumented renderable
_ComputeRepositoryURLis no longer imported tobuildbot.steps.source. It is still available atbuildbot.steps.source.oldsource.IProperties.rendernow returns a deferred, so any code rendering properties by hand will need to take this into account.baseURLhas been removed inSVNto use justrepourl- see bug #2066. Branch info should be provided withInterpolate.from buildbot.steps.source.svn import SVN factory.append(SVN(baseURL="svn://svn.example.org/svn/"))
can be replaced with
from buildbot.process.properties import Interpolate from buildbot.steps.source.svn import SVN factory.append(SVN(repourl=Interpolate("svn://svn.example.org/svn/%(src::branch)s")))
and
from buildbot.steps.source.svn import SVN factory.append(SVN(baseURL="svn://svn.example.org/svn/%%BRANCH%%/project"))
can be replaced with
from buildbot.process.properties import Interpolate from buildbot.steps.source.svn import SVN factory.append(SVN(repourl=Interpolate( "svn://svn.example.org/svn/%(src::branch)s/project")))
and
from buildbot.steps.source.svn import SVN factory.append(SVN(baseURL="svn://svn.example.org/svn/", defaultBranch="branches/test"))
can be replaced with
from buildbot.process.properties import Interpolate from buildbot.steps.source.svn import SVN factory.append(SVN(repourl=Interpolate( "svn://svn.example.org/svn/%(src::branch:-branches/test)s")))
The
P4Syncstep, deprecated since 0.8.5, has been removed. TheP4step remains.The
fetch_specargument toGitPolleris no longer supported.GitPollernow only downloads branches that it is polling, so specifies a refspec itself.The format of the changes produced by
SVNPollerhas changed: directory pathnames end with a forward slash. This allows thesplit_filefunction to distinguish between files and directories. Customized split functions may need to be adjusted accordingly.FlattenList has been deprecated in favor of Interpolate. Interpolate doesn’t handle functions as keyword arguments. The following code using
WithPropertiesfrom buildbot.process.properties import WithProperties def determine_foo(props): if props.hasProperty('bar'): return props['bar'] elif props.hasProperty('baz'): return props['baz'] return 'qux' WithProperties('%(foo)s', foo=determine_foo)
can be replaced with
from zope.interface import implementer from buildbot.interfaces import IRenderable from buildbot.process.properties import Interpolate @implementer(IRenderable) class determineFoo(object): def getRenderingFor(self, props): if props.hasProperty('bar'): return props['bar'] elif props.hasProperty('baz'): return props['baz'] return 'qux' Interpolate('%s(kw:foo)s', foo=determineFoo())
5.109.2.3. Changes for Developers
BuildStep.startcan now optionally return a deferred and any errback will be handled gracefully. If you useinlineCallbacks, this means that unexpected exceptions and failures raised will be captured and logged and the build shut down normally.The helper methods
getStateandsetStatefromBaseSchedulerhave been factored intobuildbot.util.state.StateMixinfor use elsewhere.
5.109.3. Slave
5.109.3.1. Features
5.109.3.2. Deprecations, Removals, and Non-Compatible Changes
The
P4Syncstep, deprecated since 0.8.5, has been removed. TheP4step remains.
5.109.4. Details
For a more detailed description of the changes made in this version, see the Git log itself:
git log v0.8.6..v0.8.7
5.109.5. Older Versions
Release notes for older versions of Buildbot are available in the master/docs/relnotes/ directory of the source tree. Starting with version 0.8.6, they are also available under the appropriate version at http://buildbot.net/buildbot/docs.
5.110. Release Notes for Buildbot v0.8.6p1
The following are the release notes for Buildbot v0.8.6p1. Buildbot v0.8.6 was released on March 11, 2012. Buildbot v0.8.6p1 was released on March 25, 2012.
5.110.1. 0.8.6p1
In addition to what’s listed below, the 0.8.6p1 release adds the following.
Builders are no longer displayed in the order they were configured. This was never intended behavior, and will become impossible in the distributed architecture planned for Buildbot-0.9.x. As of 0.8.6p1, builders are sorted naturally: lexically, but with numeric segments sorted numerically.
Slave properties in the configuration are now handled correctly.
The web interface buttons to cancel individual builds now appear when configured.
The ForceScheduler’s properties are correctly updated on reconfig - bug #2248.
If a slave is lost while waiting for locks, it is properly cleaned up - bug #2247.
Crashes when adding new steps to a factory in a reconfig are fixed - bug #2252.
MailNotifier AttributeErrors are fixed - bug #2254.
Cleanup from failed builds is improved - bug #2253.
5.110.2. Master
If you are using the GitHub hook, carefully consider the security implications of allowing un-authenticated change requests, which can potentially build arbitrary code. See bug #2186.
5.110.2.1. Deprecations, Removals, and Non-Compatible Changes
Forced builds now require that a
ForceSchedulerbe defined in the Buildbot configuration. For compatible behavior, this should look like:from buildbot.schedulers.forcesched import ForceScheduler c['schedulers'].append(ForceScheduler( name="force", builderNames=["b1", "b2", ... ]))
Where all of the builder names in the configuration are listed. See the documentation for the much more flexible configuration options now available.
This is the last release of Buildbot that will be compatible with Python 2.4. The next version will minimally require Python-2.5. See bug #2157.
This is the last release of Buildbot that will be compatible with Twisted-8.x.y. The next version will minimally require Twisted-9.0.0. See bug #2182.
buildbot startno longer invokes make if aMakefile.buildbotexists. If you are using this functionality, consider invoking make directly.The
buildbot sendchangeoption--usernamehas been removed as promised in bug #1711.StatusReceivers’ checkConfig method should now take an additional errors parameter and call its
addErrormethod to indicate errors.The Gerrit status callback now gets an additional parameter (the master status). If you use this callback, you will need to adjust its implementation.
SQLAlchemy-Migrate version 0.6.0 is no longer supported.
Older versions of SQLite which could limp along for previous versions of Buildbot are no longer supported. The minimum version is 3.4.0, and 3.7.0 or higher is recommended.
The master-side Git step now checks out ‘HEAD’ by default, rather than master, which translates to the default branch on the upstream repository. See pull request 301.
The format of the repository strings created by
hgbuildbothas changed to contain the entire repository URL, based on theweb.baseurlvalue inhgrc. To continue the old (incorrect) behavior, sethgbuildbot.baseurlto an empty string as suggested in the Buildbot manual.Master Side
SVNStep has been corrected to properly use--revisionwhenalwaysUseLatestis set toFalsewhen in thefullmode. See bug #2194Master Side
SVNStep parameter svnurl has been renamed repourl, to be consistent with other master-side source steps.Master Side
Mercurialstep parameterbaseURLhas been merged withrepourlparameter. The behavior of the step is already controlled bybranchTypeparameter, so just use a single argument to specify the repository.Passing a
buildbot.process.buildstep.BuildStepsubclass (rather than instance) tobuildbot.process.factory.BuildFactory.addStephas long been deprecated, and will be removed in version 0.8.7.The hgbuildbot tool now defaults to the ‘inrepo’ branch type. Users who do not explicitly set a branch type would previously have seen empty branch strings, and will now see a branch string based on the branch in the repository (e.g., default).
5.110.2.2. Changes for Developers
The interface for runtime access to the master’s configuration has changed considerably. See Configuration for more details.
The DB connector methods
completeBuildset,completeBuildRequest, andclaimBuildRequestnow take an optionalcomplete_atparameter to specify the completion time explicitly.Buildbot now sports sourcestamp sets, which collect multiple sourcestamps used to generate a single build, thanks to Harry Borkhuis. See pull request 287.
Schedulers no longer have a
schedulerid, but rather anobjectid. In a related change, theschedulerstable has been removed, along with thebuildbot.db.schedulers.SchedulersConnectorComponent.getSchedulerIdmethod.The Dependent scheduler tracks its upstream buildsets using
buildbot.db.schedulers.StateConnectorComponent, so thescheduler_upstream_buildsetstable has been removed, along with corresponding (undocumented)buildbot.db.buildsets.BuildsetsConnectormethods.Errors during configuration (in particular in
BuildStepconstructors), should be reported by callingbuildbot.config.error.
5.110.2.3. Features
The IRC status bot now display build status in colors by default. It is controllable and may be disabled with useColors=False in constructor.
Buildbot can now take advantage of authentication done by a front-end web server - see pull request 266.
Buildbot supports a simple cookie-based login system, so users no longer need to enter a username and password for every request. See the earlier commits in pull request 278.
The master-side SVN step now has an export method which is similar to copy, but the build directory does not contain Subversion metadata. (bug #2078)
Propertyinstances will now render any properties in the default value if necessary. This makes possible constructs likecommand=Property('command', default=Property('default-command'))
Buildbot has a new web hook to handle push notifications from Google Code - see pull request 278.
Revision links are now generated by a flexible runtime conversion configured by
revlink- see pull request 280.Shell command steps will now “flatten” nested lists in the
commandargument. This allows substitution of multiple command-line arguments using properties. See bug #2150.Steps now take an optional
hideStepIfparameter to suppress the step from the waterfall and build details in the web. (bug #1743)Triggersteps withwaitForFinish=Truenow receive a URL to all the triggered builds. This URL is displayed in the waterfall and build details. See bug #2170.The
master/contrib/fakemaster.pyscript allows you to run arbitrary commands on a slave by emulating a master. See the file itself for documentation.MailNotifier allows multiple notification modes in the same instance. See bug #2205.
SVNPoller now allows passing extra arguments via argument
extra_args. See bug #1766
5.110.3. Slave
5.110.3.1. Deprecations, Removals, and Non-Compatible Changes
BitKeeper support is in the “Last-Rites” state, and will be removed in the next version unless a maintainer steps forward.
5.110.3.2. Features
5.110.4. Details
For a more detailed description of the changes made in this version, see the Git log itself:
git log buildbot-0.8.5..buildbot-0.8.6
5.110.5. Older Versions
Release notes for older versions of Buildbot are available in the master/docs/relnotes/ directory of the source tree, or in the archived documentation for those versions at http://buildbot.net/buildbot/docs.
Note that Buildbot-0.8.11 was never released.
6. API Indices
Copyright
This documentation is part of Buildbot.
Buildbot is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, version 2.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
Copyright Buildbot Team Members
2.5.4.3. Comments
The Change also has a
commentsattribute, which is a string containing any checkin comments.